


Super-Resolution Processing of Synchrotron CT Images for Automated Fibre Break Analysis of Unidirectional Composites
 , ,
, ,  , and
, and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Materials and Manufacturing
2.2. Synchrotron-Radiation Computed Tomography Experiments
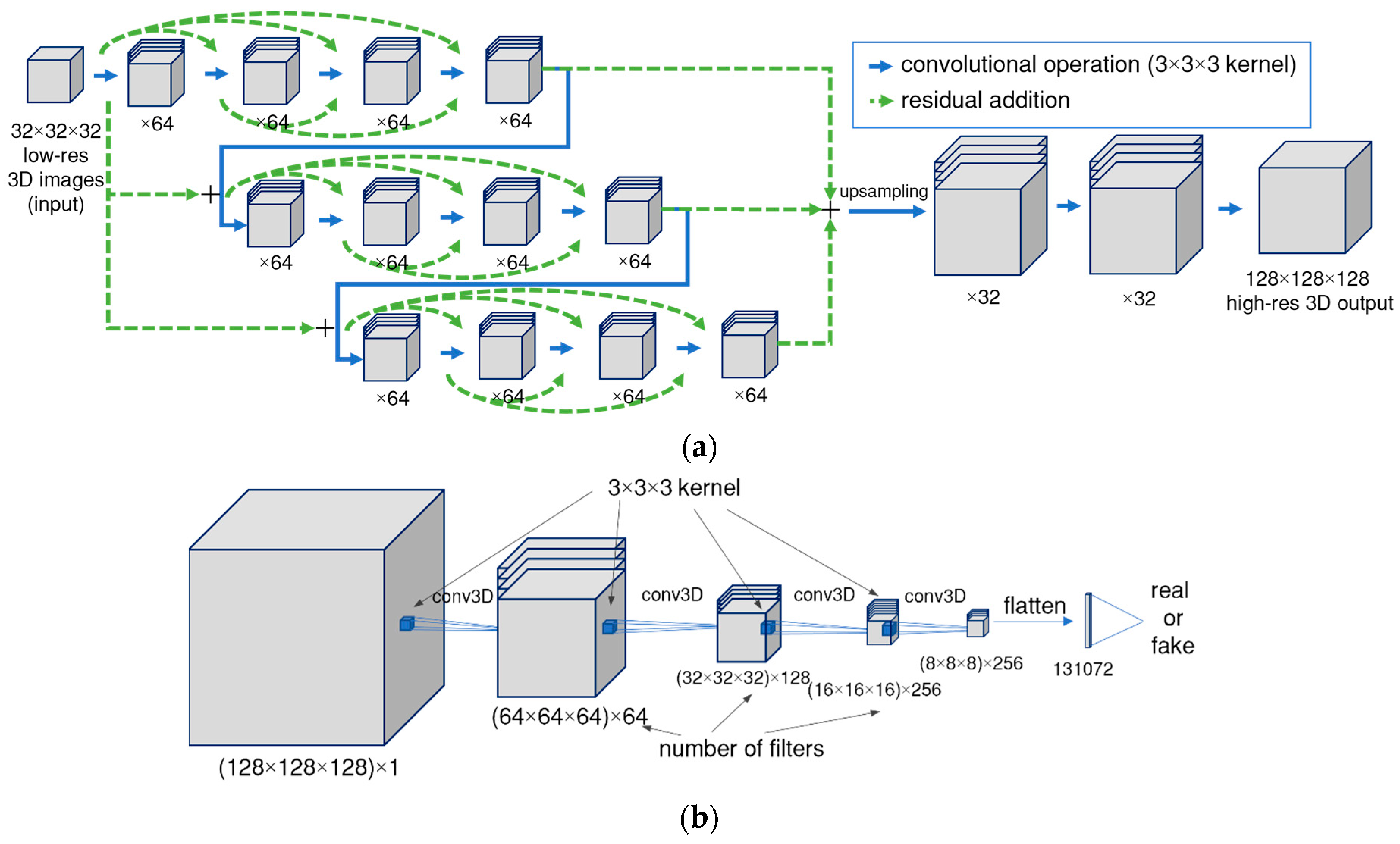
2.3. Super-Resolution Algorithm
2.4. Data Processing and Neural Network Training
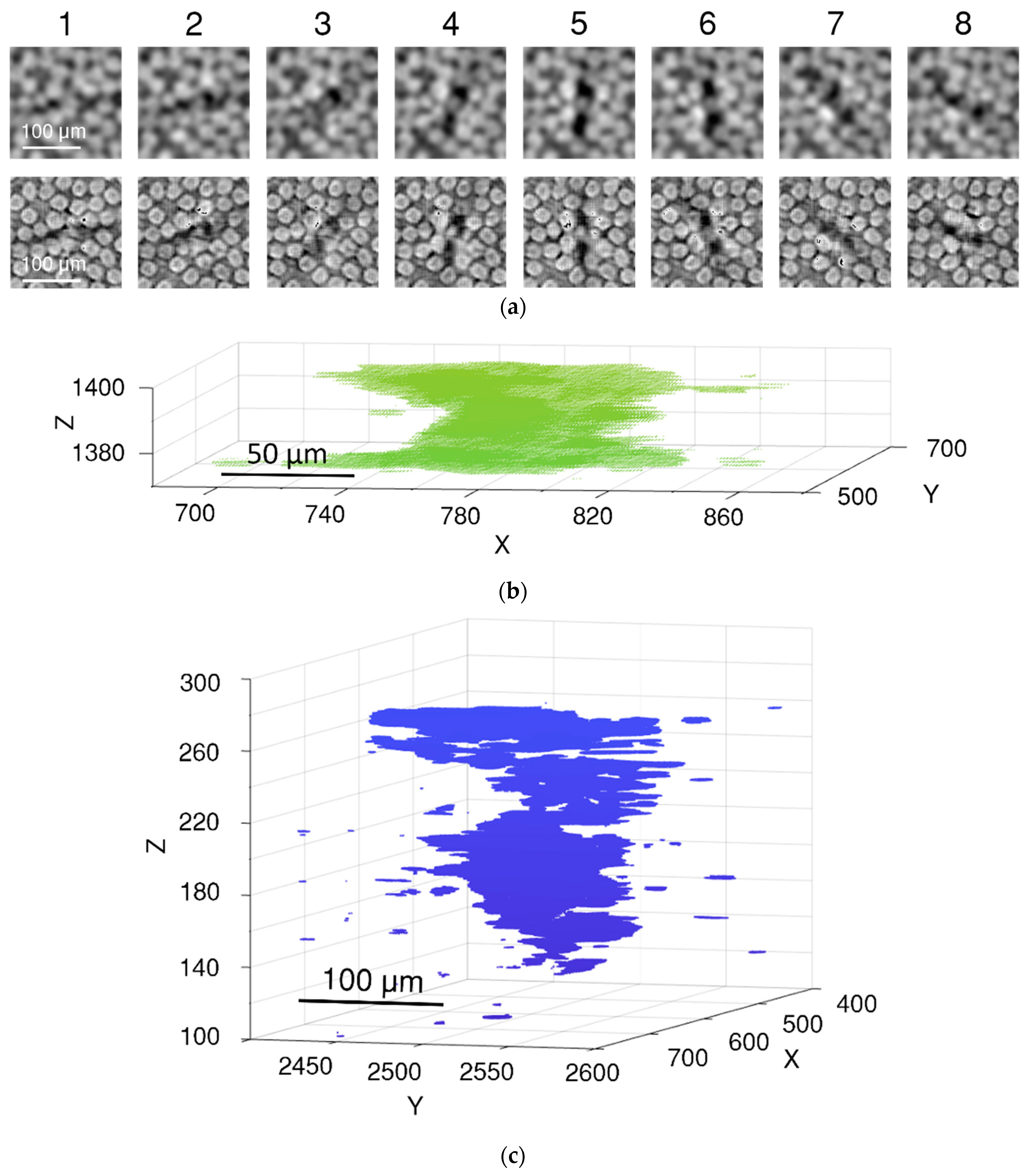
2.5. Fibre Break Identification
3. Results and Discussions
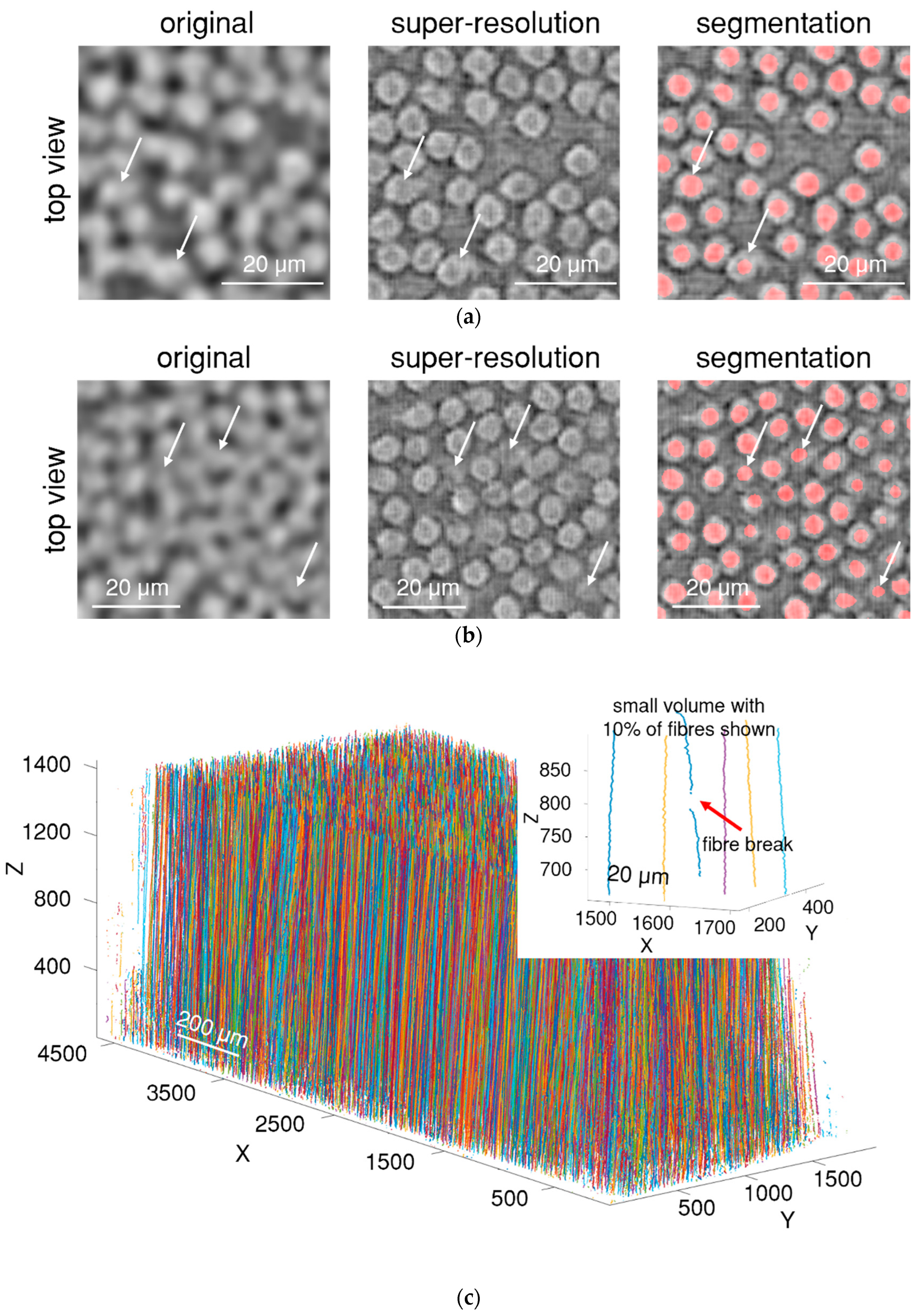
3.1. Image Processing
3.2. Fibre Break Identification
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xian, G.; Guo, R.; Li, C.; Hong, B. Mechanical Properties of Carbon/Glass Fiber Reinforced Polymer Plates with Sandwich Structure Exposed to Freezing-Thawing Environment: Effects of Water Immersion, Bending Loading and Fiber Hybrid Mode. Mech. Adv. Mater. Struct. 2023, 30, 814–834. [Google Scholar] [CrossRef]
- Breite, C.; Melnikov, A.; Turon, A.; de Morais, A.B.; Le Bourlot, C.; Maire, E.; Schöberl, E.; Otero, F.; Mesquita, F.; Sinclair, I.; et al. Detailed Experimental Validation and Benchmarking of Six Models for Longitudinal Tensile Failure of Unidirectional Composites. Compos. Struct. 2022, 279, 114828. [Google Scholar] [CrossRef]
- Tavares, R.P.; Otero, F.; Baiges, J.; Turon, A.; Camanho, P.P. A Dynamic Spring Element Model for the Prediction of Longitudinal Failure of Polymer Composites. Comput. Mater. Sci. 2019, 160, 42–52. [Google Scholar] [CrossRef]
- Guerrero, J.M.; Mayugo, J.A.; Costa, J.; Turon, A. A 3D Progressive Failure Model for Predicting Pseudo-Ductility in Hybrid Unidirectional Composite Materials under Fibre Tensile Loading. Compos. Part A Appl. Sci. Manuf. 2018, 107, 579–591. [Google Scholar] [CrossRef]
- Pimenta, S. A Computationally-Efficient Hierarchical Scaling Law to Predict Damage Accumulation in Composite Fibre-Bundles. Compos. Sci. Technol. 2017, 146, 210–225. [Google Scholar] [CrossRef]
- Swolfs, Y.; Verpoest, I.; Gorbatikh, L. Issues in Strength Models for Unidirectional Fibre-Reinforced Composites Related to Weibull Distributions, Fibre Packings and Boundary Effects. Compos. Sci. Technol. 2015, 114, 42–49. [Google Scholar] [CrossRef]
- Swolfs, Y.; Fazlali, B.; Melnikov, A.; Mesquita, F.; Feyen, V.; Breite, C.; Gorbatikh, L.; Lomov, S. V State-of-the-Art Models for Mechanical Performance of Carbon-Glass Hybrid Composites in Wind Turbine Blades. IOP Conf. Ser. Mater. Sci. Eng. 2020, 942, 012005. [Google Scholar] [CrossRef]
- Breite, C.; Melnikov, A.; Turon, A.; de Morais, A.B.; Le Bourlot, C.; Maire, E.; Schöberl, E.; Otero, F.; Mesquita, F.; Sinclair, I.; et al. A Synchrotron Computed Tomography Dataset for Validation of Longitudinal Tensile Failure Models Based on Fibre Break and Cluster Development. Data Brief 2021, 39, 107590. [Google Scholar] [CrossRef] [PubMed]
- Breite, C.; Melnikov, A.; Turon, A.; de Morais, A.B.; Otero, F.; Mesquita, F.; Costa, J.; Mayugo, J.A.; Guerrero, J.M.; Gorbatikh, L.; et al. Blind Benchmarking of Seven Longitudinal Tensile Failure Models for Two Virtual Unidirectional Composites. Compos. Sci. Technol. 2021, 202, 108555. [Google Scholar] [CrossRef]
- Garcea, S.C.; Wang, Y.; Withers, P.J. X-ray Computed Tomography of Polymer Composites. Compos. Sci. Technol. 2018, 156, 305–319. [Google Scholar] [CrossRef]
- Badel, P.; Vidal-Sallé, E.; Maire, E.; Boisse, P. Simulation and Tomography Analysis of Textile Composite Reinforcement Deformation at the Mesoscopic Scale. Compos. Sci. Technol. 2008, 68, 2433–2440. [Google Scholar] [CrossRef]
- Amenabar, I.; Mendikute, A.; López-Arraiza, A.; Lizaranzu, M.; Aurrekoetxea, J. Comparison and Analysis of Non-Destructive Testing Techniques Suitable for Delamination Inspection in Wind Turbine Blades. Compos. B Eng. 2011, 42, 1298–1305. [Google Scholar] [CrossRef]
- Centea, T.; Hubert, P. Measuring the Impregnation of an Out-of-Autoclave Prepreg by Micro-CT. Compos. Sci. Technol. 2011, 71, 593–599. [Google Scholar] [CrossRef]
- Schilling, P.J.; Karedla, B.P.R.; Tatiparthi, A.K.; Verges, M.A.; Herrington, P.D. X-ray Computed Microtomography of Internal Damage in Fiber Reinforced Polymer Matrix Composites. Compos. Sci. Technol. 2005, 65, 2071–2078. [Google Scholar] [CrossRef]
- Straumit, I.; Lomov, S.V.; Wevers, M. Quantification of the Internal Structure and Automatic Generation of Voxel Models of Textile Composites from X-ray Computed Tomography Data. Compos. Part A Appl. Sci. Manuf. 2015, 69, 150–158. [Google Scholar] [CrossRef]
- Maire, E.; Withers, P.J. Quantitative X-ray Tomography. Int. Mater. Rev. 2014, 59, 1–43. [Google Scholar] [CrossRef]
- Wu, S.C.; Xiao, T.Q.; Withers, P.J. The Imaging of Failure in Structural Materials by Synchrotron Radiation X-ray Microtomography. Eng. Fract. Mech. 2017, 182, 127–156. [Google Scholar] [CrossRef]
- Scott, A.E.; Mavrogordato, M.; Wright, P.; Sinclair, I.; Spearing, S.M. In Situ Fibre Fracture Measurement in Carbon-Epoxy Laminates Using High Resolution Computed Tomography. Compos. Sci. Technol. 2011, 71, 1471–1477. [Google Scholar] [CrossRef]
- Li, P.; Li, Z.; Pang, X.; Wang, H.; Lin, W.; Wu, W. Multi-Scale Residual Denoising GAN Model for Producing Super-Resolution CTA Images. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 1515–1524. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar] [CrossRef]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image Super-Resolution via Sparse Representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar] [CrossRef]
- You, C.; Cong, W.; Vannier, M.W.; Saha, P.K.; Hoffman, E.A.; Wang, G.; Li, G.; Zhang, Y.; Zhang, X.; Shan, H.; et al. CT Super-Resolution GAN Constrained by the Identical, Residual, and Cycle Learning Ensemble (GAN-CIRCLE). IEEE Trans. Med. Imaging 2020, 39, 188–203. [Google Scholar] [CrossRef]
- Gu, Y.; Zeng, Z.; Chen, H.; Wei, J.; Zhang, Y.; Chen, B.; Li, Y.; Qin, Y.; Xie, Q.; Jiang, Z.; et al. MedSRGAN: Medical Images Super-Resolution Using Generative Adversarial Networks. Multimed. Tools Appl. 2020, 79, 21815–21840. [Google Scholar] [CrossRef]
- Song, T.A.; Chowdhury, S.R.; Yang, F.; Dutta, J. PET Image Super-Resolution Using Generative Adversarial Networks. Neural Netw. 2020, 125, 83–91. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. In Proceedings of the Computer Vision–ECCV 2018 Workshops, Munich, Germany, 8–14 September 2019; pp. 63–79. [Google Scholar] [CrossRef]
- Vo, N.T.; Atwood, R.C.; Drakopoulos, M. Radial Lens Distortion Correction with Sub-Pixel Accuracy for X-ray Micro-Tomography. Opt. Express 2015, 23, 32859. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef]
- Park, J.; Hwang, D.; Kim, K.Y.; Kang, S.K.; Kim, Y.K.; Lee, J.S. Computed Tomography Super-Resolution Using Deep Convolutional Neural Network. Phys. Med. Biol. 2018, 63, 145011. [Google Scholar] [CrossRef]
- Xie, H.; Lei, Y.; Wang, T.; Tian, Z.; Roper, J.; Bradley, J.D.; Curran, W.J.; Tang, X.; Liu, T.; Yang, X. High Through-Plane Resolution CT Imaging with Self-Supervised Deep Learning. Phys. Med. Biol. 2021, 66, 145013. [Google Scholar] [CrossRef]
- Zhang, Y.; Noack, M.A.; Vagovic, P.; Fezzaa, K.; Garcia-Moreno, F.; Ritschel, T.; Villanueva-Perez, P. PhaseGAN: A Deep-Learning Phase-Retrieval Approach for Unpaired Datasets. Opt. Express 2020, 29, 19593–19604. [Google Scholar] [CrossRef]
- Wang, Y.; Teng, Q.; He, X.; Feng, J.; Zhang, T. CT-Image of Rock Samples Super Resolution Using 3D Convolutional Neural Network. Comput. Geosci. 2019, 133, 104314. [Google Scholar] [CrossRef]
- Mehdikhani, M.; Breite, C.; Swolfs, Y.; Wevers, M.; Lomov, S.V.; Gorbatikh, L. Combining Digital Image Correlation with X-ray Computed Tomography for Characterization of Fiber Orientation in Unidirectional Composites. Compos. Part A Appl. Sci. Manuf. 2021, 142, 106234. [Google Scholar] [CrossRef]
- Guo, R.; Stubbe, J.; Zhang, Y.; Schlepütz, C.M.; Gomez, C.R.; Mehdikhani, M.; Breite, C.; Swolfs, Y.; Villanueva-Perez, P. Deep-Learning Image Enhancement and Fibre Segmentation from Time-Resolved Computed Tomography of Fibre-Reinforced Composites. Compos. Sci. Technol. 2023. in Submission. [Google Scholar]
- Mehdikhani, M.; Breite, C.; Swolfs, Y.; Wevers, M.; Lomov, S.V.; Gorbatikh, L. A Dataset of Micro-Scale Tomograms of Unidirectional Glass Fiber/Epoxy and Carbon Fiber/Epoxy Composites Acquired via Synchrotron Computed Tomography during in-Situ Tensile Loading. Data Brief 2021, 34, 106672. [Google Scholar] [CrossRef]
- Guo, R.; Stubbe, J.; Zhang, Y.; Schlepütz, C.M.; Rojas, C.; Mehdikhani, M.; Breite, C.; Swolfs, Y.; Villanueva-Perez, P. Unpaired Fast- and Slow-Acquisition MicroCT Scans of Carbon-Fibre-Reinforced Composites. Zenodo 2023. [Google Scholar] [CrossRef]
- North Thin Ply Technology (N.T.P.T.). ThinPreg, 736LT Data Sheet; North Thin Ply Technology: Renens, Switzerland, 2017. [Google Scholar]
- Mitsubishi Chemical. GRAFILTM 34-700 12K & 24K Product Data Sheet; Mitsubishi Chemical: Tokyo, Japan, 2017. [Google Scholar]
- Maire, E.; le Bourlot, C.; Adrien, J.; Mortensen, A.; Mokso, R. 20 Hz X-ray Tomography during an In Situ Tensile Test. Int. J. Fract. 2016, 200, 3–12. [Google Scholar] [CrossRef]
- Mokso, R.; Schlepütz, C.M.; Theidel, G.; Billich, H.; Schmid, E.; Celcer, T.; Mikuljan, G.; Sala, L.; Marone, F.; Schlumpf, N.; et al. GigaFRoST: The Gigabit Fast Readout System for Tomography. J. Synchrotron Radiat. 2017, 24, 1250–1259. [Google Scholar] [CrossRef] [PubMed]
- Marone, F.; Stampanoni, M. Regridding Reconstruction Algorithm for Real-Time Tomographic Imaging. J. Synchrotron Radiat. 2012, 19, 1029–1037. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2014, 63, 139–144. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Jolicoeur-Martineau, A. The Relativistic Discriminator: A Key Element Missing from Standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Micikevicius, P.; Narang, S.; Alben, J.; Diamos, G.; Elsen, E.; Garcia, D.; Ginsburg, B.; Houston, M.; Kuchaiev, O.; Venkatesh, G.; et al. Mixed Precision Training. arXiv 2017, arXiv:1710.03740. [Google Scholar]
- Smith, A.G.; Han, E.; Petersen, J.; Olsen, N.A.F.; Giese, C.; Athmann, M.; Dresbøll, D.B.; Thorup-Kristensen, K. RootPainter: Deep Learning Segmentation of Biological Images with Corrective Annotation. New. Phytol. 2022, 236, 774–791. [Google Scholar] [CrossRef] [PubMed]
- Arganda-carreras, I.; Kaynig, V.; Rueden, C.; Eliceiri, K.W.; Schindelin, J.; Cardona, A.; Seung, H.S. Trainable Weka Segmentation: A Machine Learning Tool for Microscopy Pixel Classification. Bioin-Form. 2018, 33, 2424–2426. [Google Scholar] [CrossRef] [PubMed]
- Emerson, M.J.; Jespersen, K.M.; Dahl, A.B.; Conradsen, K.; Mikkelsen, L.P. Individual Fibre Segmentation from 3D X-ray Computed Tomography for Characterising the Fibre Orientation in Unidirectional Composite Materials. Compos. Part A Appl. Sci. Manuf. 2017, 97, 83–92. [Google Scholar] [CrossRef]
- Stehman, S.V. Selecting and Interpreting Measures of Thematic Classification Accuracy. Remote. Sens. Env. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Karamov, R.; Lomov, S.V.; Sergeichev, I.; Swolfs, Y.; Akhatov, I. Inpainting Micro-CT Images of Fibrous Materials Using Deep Learning. Comput. Mater. Sci. 2021, 197, 110551. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
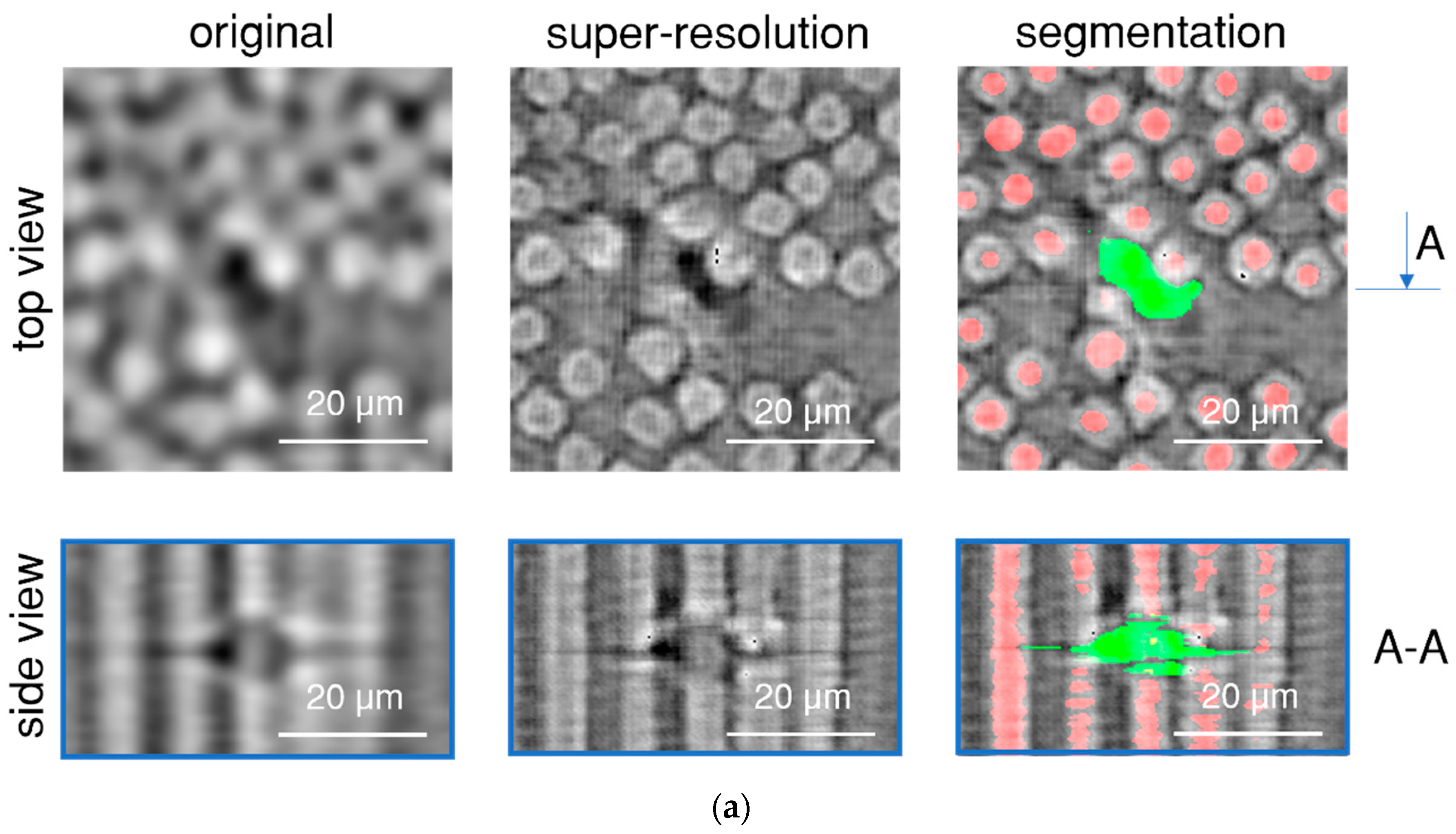{kind=link}
{kind=link}
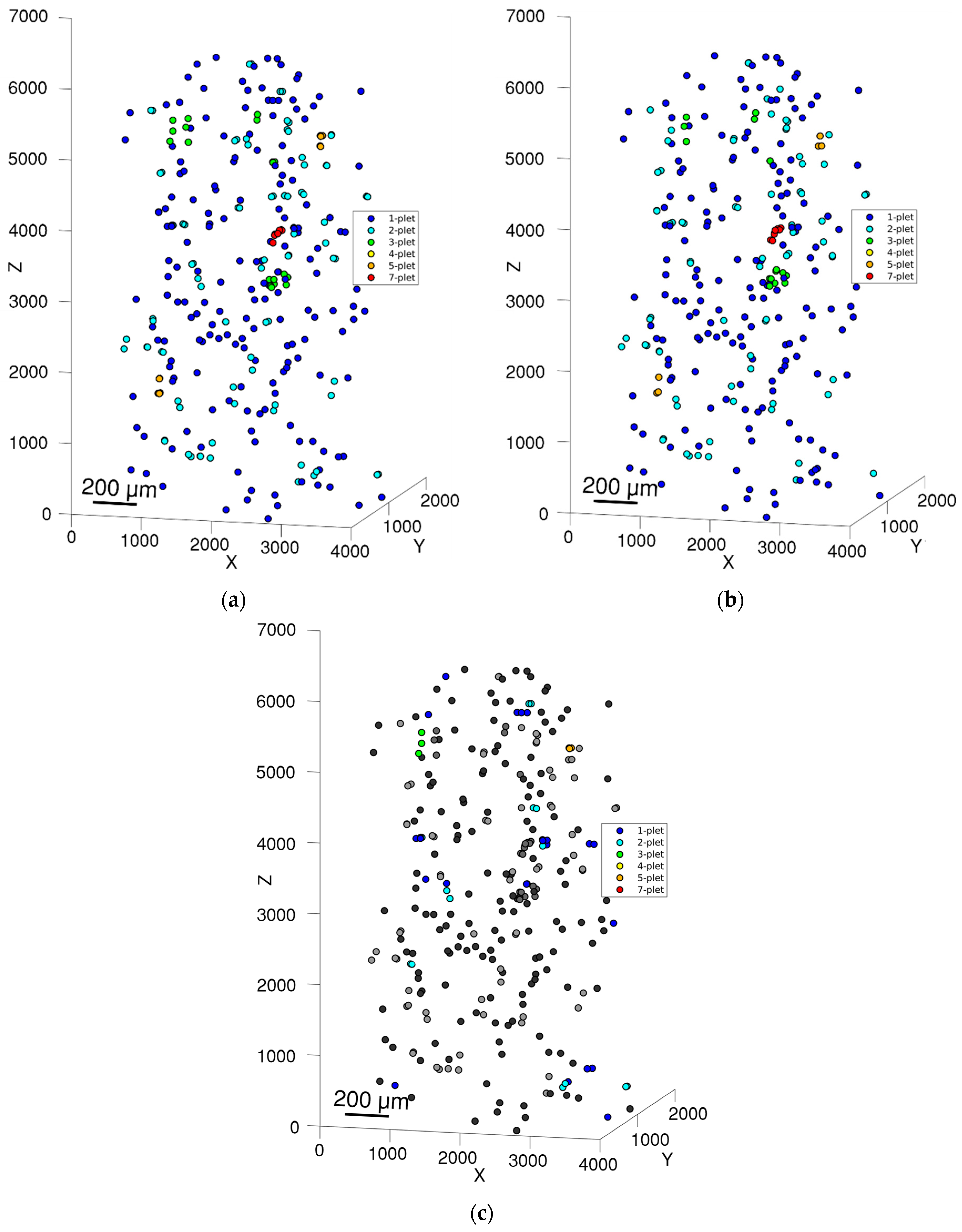{kind=link}
| Purpose | Training Set, Stationary | Validation Set, Continuous Loading | |
|---|---|---|---|
| High-Resolution | Low-Resolution | ||
| Material | T700SC | T700SC | 34-700 |
| Sensor size (px2) | 2560 × 2160 | 2560 × 2160 | 2016 × 1716 |
| Sensor pixel size (µm) | 6.5 | 6.5 | 11.0 |
| Energy (kV) | 15 | 15 | 20 |
| Exposure time (ms) | 250 | 80 | 9 |
| Microscope magnification | 20× | 4× | 10× |
| Voxel size (µm) | 0.325 | 1.625 | 1.1 |
| Number of projections per volume | 2000 | 2000 | 1000 |
| Propagation distance (mm) | 30 | 100 | 60 |
| Displacement rate (µm/s) | - | - | 1.4–1.6 |
| Number of volumes acquired before failure | 1 | 1 | 17 |
| Testing time per scan (s) | 500 | 160 | 9 |
| 98% Load Method 1 (Stat.) | 98% Load Method 1 (Opt.) | 98% Load Method 2 | 94% Load Method 1 (Opt.) | 94% Load Method 2 | 75% Load Method 1 (Opt.) | 75% Load Method 2 | |
|---|---|---|---|---|---|---|---|
| Manual | 299 | 299 | 299 | 248 | 248 | 78 | 78 |
| True positive | 258 | 266 | 272 | 225 | 230 | 74 | 75 |
| False positive | 70 | 51 | 33 | 43 | 25 | 14 | 6 |
| False negative | 41 | 33 | 27 | 23 | 18 | 4 | 3 |
| Large objects | 79 | 79 | 79 | 39 | 39 | 1 | 1 |
| Breaks from large objects | 18 | 18 | 18 | 12 | 12 | 1 | 1 |
| Automatic accuracy | 0.70 | 0.76 | 0.82 | 0.77 | 0.84 | 0.80 | 0.89 |
| Semi-automatic accuracy | 0.79 | 0.86 | 0.92 | 0.85 | 0.93 | 0.82 | 0.92 |
| Miss rate (%) | 8.2 | 5.3 | 3.2 | 4.7 | 2.5 | 3.9 | 2.6 |
| 1-Plet | 2-Plet | 3-Plet | 4-Plet | 5-Plet | 7-Plet | ||
|---|---|---|---|---|---|---|---|
| 98% load | manual | 175 | 43 | 7 | 0 | 2 | 1 |
| auto | 170 | 41 | 7 | 0 | 2 | 1 | |
| 94% load | manual | 145 | 34 | 6 | 0 | 2 | 1 |
| auto | 147 | 29 | 6 | 0 | 2 | 1 | |
| 75% load | manual | 45 | 10 | 1 | 0 | 2 | 0 |
| auto | 42 | 9 | 2 | 0 | 2 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karamov, R.; Breite, C.; Lomov, S.V.; Sergeichev, I.; Swolfs, Y. Super-Resolution Processing of Synchrotron CT Images for Automated Fibre Break Analysis of Unidirectional Composites. Polymers 2023, 15, 2206. https://doi.org/10.3390/polym15092206
Karamov R, Breite C, Lomov SV, Sergeichev I, Swolfs Y. Super-Resolution Processing of Synchrotron CT Images for Automated Fibre Break Analysis of Unidirectional Composites. Polymers. 2023; 15(9):2206. https://doi.org/10.3390/polym15092206
Chicago/Turabian StyleKaramov, Radmir, Christian Breite, Stepan V. Lomov, Ivan Sergeichev, and Yentl Swolfs. 2023. "Super-Resolution Processing of Synchrotron CT Images for Automated Fibre Break Analysis of Unidirectional Composites" Polymers 15, no. 9: 2206. https://doi.org/10.3390/polym15092206
APA StyleKaramov, R., Breite, C., Lomov, S. V., Sergeichev, I., & Swolfs, Y. (2023). Super-Resolution Processing of Synchrotron CT Images for Automated Fibre Break Analysis of Unidirectional Composites. Polymers, 15(9), 2206. https://doi.org/10.3390/polym15092206