1. Introduction
The current social context requires an increase in food production, improvement of its quality characteristics and greater environmental sustainability in the management of agricultural systems. Technological innovation plays a great role in making agriculture more efficient and sustainable.
On the 1 June 2018, the European Commission set goals for the new Common Agricultural Policy (CAP) for beyond 2020, focusing on the contribution of innovation and sustainability of crop production in Italy (through Regional Agricultural Policies), as for the rest of Europe (EIP-AGRI partnership). One of the key points reported is the necessity of effective nutrient management, more specifically, avoiding environmental losses and preserving yields [
1].
Uniform management of fields does not consider spatial variability, and it is not the most effective management strategy. Precision agriculture is considered the most viable approach for achieving sustainable agriculture [
2]. Soil is the temporal result of several factors such as the atmosphere, biosphere, lithosphere and hydrosphere [
3]. Such variability may act over different spatial and temporal scales and affects crop yield both quantitatively and qualitatively [
4].
The use of precision farming techniques (PA) is proposed as a solution, which would combine proximal and remote sensors [
5] to follow and measure the spatial-temporal variability of the soil and crop during all growing seasons. Therefore, the soil plays a crucial role in the identification of zones within the field [
6].
Among the different geophysical properties to better understand spatial variability of the soil, apparent electrical conductivity of the soil (ECa) is widely used by scientists [
2,
7,
8] and is generally measured by electromagnetic induction (EMI) sensors. EMI has the advantages over traditional methods to collect soil information quickly, easily, at a relatively low cost and with a large volume of data collected [
9].
The correct definition of management zones constitutes an important task to manage spatial variability within the field properly [
10]. There are different techniques to delineate management zones taking into account soil or vegetation properties separately [
11,
12,
13] or in combination, through classification techniques [
10,
13,
14,
15,
16] or informed clustering based on functional relations [
17,
18], to account for response space-time dependence with spatially dense data, data misalignment in both space and time and repeated covariate measurements [
18].
However, cluster analysis algorithms [
19,
20] are the basis of a direct approach to dividing a field using different layers of information stored in a geographical information system (GIS). Taking into account that data used to define management zones are usually related [
15], it is possible to summarize the information by means of principal component analysis. Finally, the values of the main principal components can be interpolated and mapped, and these surfaces can be used to generate management zones by cluster analysis [
11,
12].
Irrespective of the approach used, defining an algorithm that will effectively partition a field in homogeneous zones remains one of the main challenges for precision agriculture [
21]. Creating an algorithm requires the discretization and clustering of one or more continuous mapped variables that may influence yield in various, possibly non-linear ways. Several approaches were proposed in the literature, such as k-clustering, multivariate geostatistical methods [
22,
23], and GIS layering [
24]. These approaches are powerful in their capacity to cluster high-dimensional datasets (i.e., including multiple variables), but they may not be easy to use because they do not offer a direct association of the classes to productivity or variability.
The cost-effectiveness of precision agriculture depends upon the cost of defining zones within fields, the temporal stability of these zones and the differences in responsiveness (yield and quality) of the zones submitted to differential treatment.
Delineation of management zones can be based on spatial variation in either crop yield or factors affecting the yield locally [
23,
25].
PA requires high-resolution spatial and temporal information, but traditional soil sampling and laboratory analyses are expensive, labor-intensive and require many samples [
5].
By means of continuous soil and crop monitoring activity, the site-specific-nitrogen-management (SSNM) can be applied [
23]. The SSNM is based on the delineation of homogeneous zones within the field, between which different doses of fertilizer should be applied [
9].
Particularly, SSNM is a form of precision agriculture whereby decisions on resource application and agronomic practices are improved to match soil and crop requirements better. The SSNM allows the division of a field into areas that have internally the same characteristics but differ from each other [
19].
In order to produce the homogeneous zone map, we need to monitor the field over time by using several sensors. Depending on the type of sensor used and analysis performed, several authors provided different approaches to define the homogeneous zones.
The authors of [
26] proposed a multi-source geostatistical approach, [
27] evaluated 20 different unsupervised machine learning algorithms, while [
28] used the Self-Organizing Maps.
The aim of our contribution is to validate the k-means algorithm to delineate homogeneous management zones. The k-means algorithm uses low-cost resistivity maps created by an electromagnetic induction method as a source of data. The proposed approach could be used to easily reconduct the spatial variability of the soil in homogeneous management zones statistically different from each other for high-quality prescriptions maps for the precision farming application.
2. Materials and Methods
2.1. Experimental Sites Description
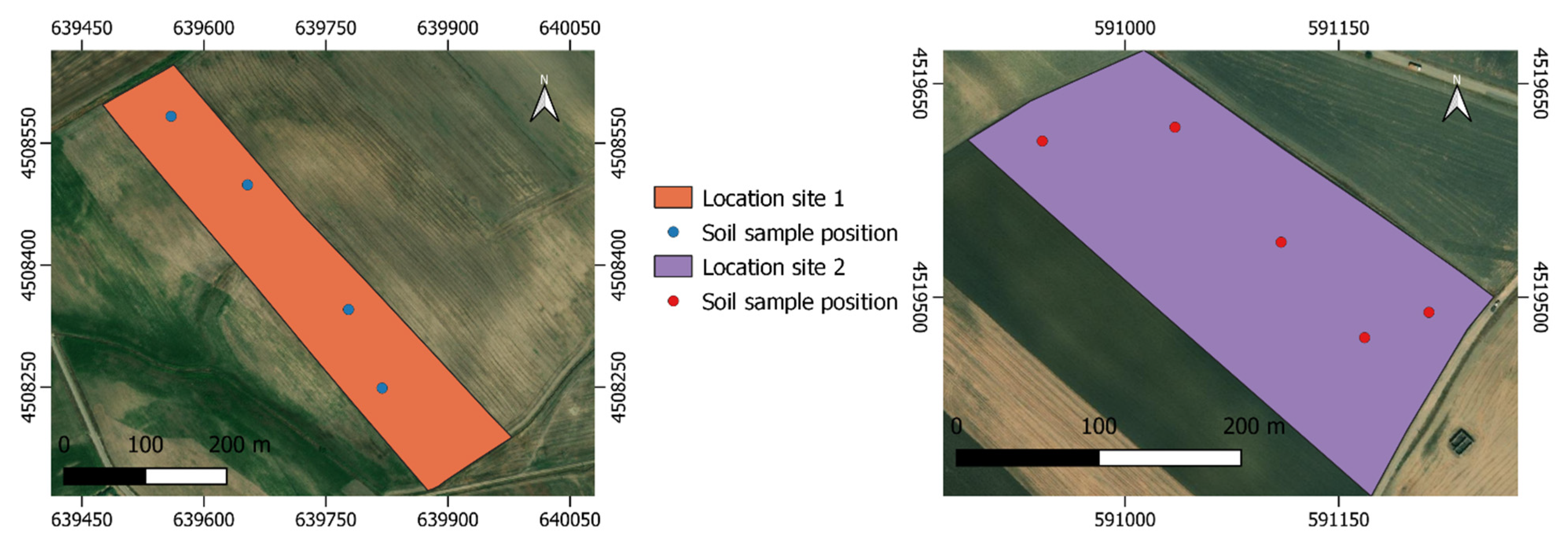
The method was tested on two experimental sites (
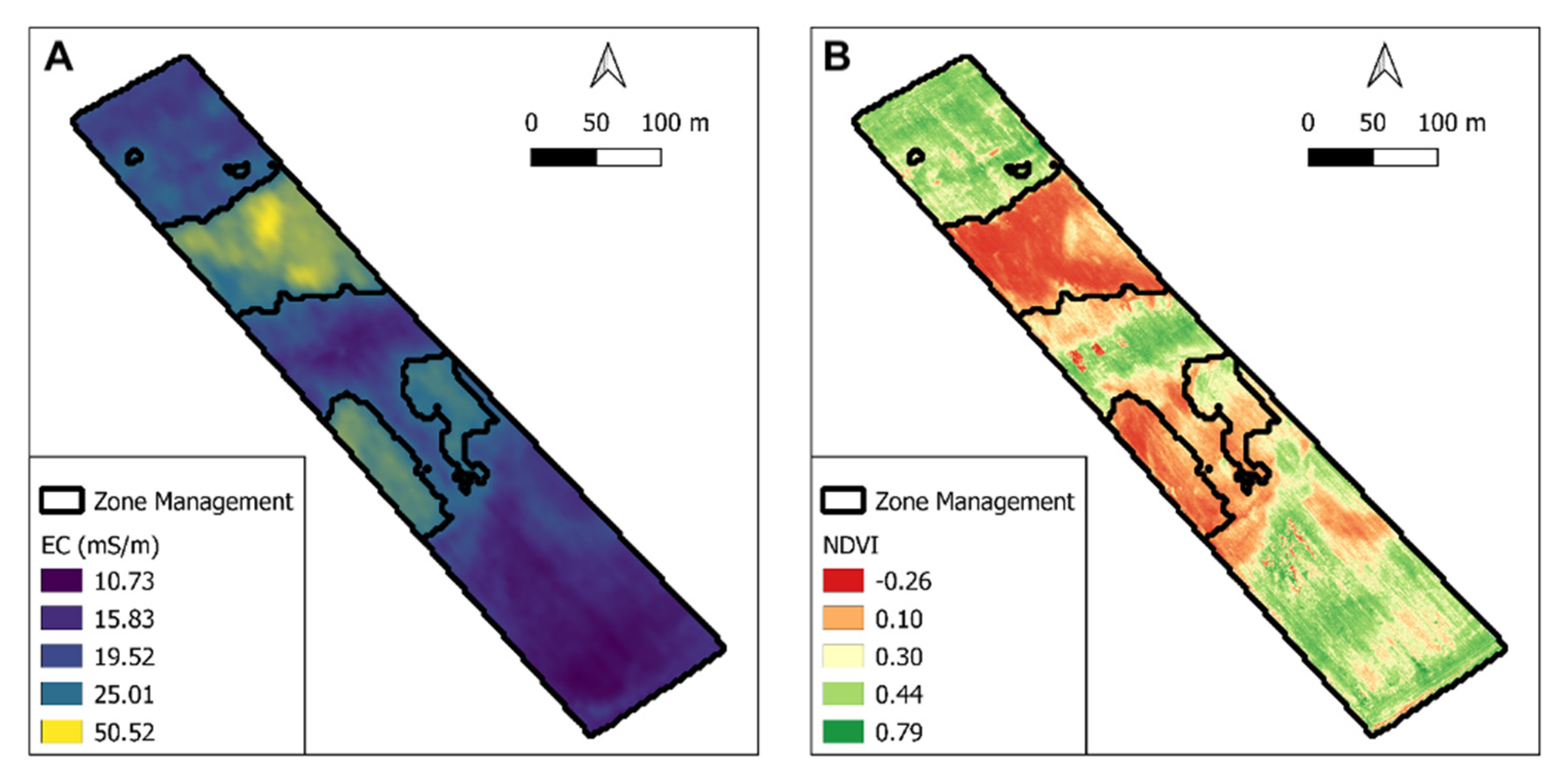
Figure 1). In both sites, three different homogeneous zones (ZH) were identified by resistivity maps created by an electromagnetic induction (EMI), which were subsequently identified with the letters a, b, c. In these three areas, two different fertilization applications were tested: variable rate (VRT) and uniform (UA).
In 2019–2020 at site 1 Az. Agricola F.lli Lillo (Matera) latitude: 40.712640° longitude 16.656343° (
Figure 2) on a study area of 6.65 ha, the experiment was conducted with durum wheat (
Triticum durum L., var PR22D89) with sod seeding (7 January 2020).
In 2018–2019 at site 2 Genzano di Lucania (PZ) latitude: 40.82° N, longitude: 16.08° N (
Figure 2), the study area (4.93 ha) was located on the clayey hills of the Bradanica grave and the basin of Sant’Arcangelo. The experiment was conducted with durum wheat (
Triticum durum L., var Tirex). The inter-row spacing of 0.13 m and 250 kg ha
−1 of seeds was used. Soil tillage consisted of a 40 cm deep plowing (28 August 2018) and two harrowing (11 November 2018 and 5 December 2018) (
Figure 2).
For the VRT treatment, the N doses applied in each area through a variable rate spreader are reported in
Table 1 for site 1 and
Table 2 for site 2. For each treatment, plots of 2 m × 2 m replicated three times inside each of the homogeneous areas identified in the field were established. In all such plots, a dose of N uniform was applied, which corresponds to the amount generally applied by the farmer and slightly over the average of the dose of N applied in the three zones. The fertilizer was manually spread in UA.
2.2. Soil and Crop Samples Position
The soil spatial variability was detected by means of low induction electromagnetic technique of CMD miniexplorer (GF Instruments, s.r.o., Brno, Czech Republic) with 6 m between transects and an average measurement distance of 0.8 m along transects.
The CMD miniexplorer returns data must be interpolated; in this case, the inverse distance squared method was performed by using Qgis [
29,
30,
31].
After obtaining the electrical resistivity map, the cluster analysis was performed to identify the zones, and then for each zone, soil samples at the depths of 0–40 cm were collected and characterized by conventional analytical methods according to [
32]. All samples were air-dried, and 2-mm sieved before laboratory analyses.
The organic carbon (OC) content was measured by the Walkley–Black method, and the total Kjeldahl nitrogen was determined by the Kjeldahl method. The available phosphorus (Pava) was determined by ultraviolet and visible (UV–vis) spectrophotometry according to the Olsen method. The total content of CaCO3 was determined by the gas-volumetric methods (Freuling calcimeter method), whereas the active lime was extracted with 0.1 M ammonium oxalate and determined by titration with 0.1 M KMnO4.
At crop maturity, the grain yield (t ha−1) and protein content (%) was measured on a sample area of 4 m2 replicated three times. The protein content (%) was measured by the FOSS Infratec 1241.
2.3. Management Zone Delineation Approach
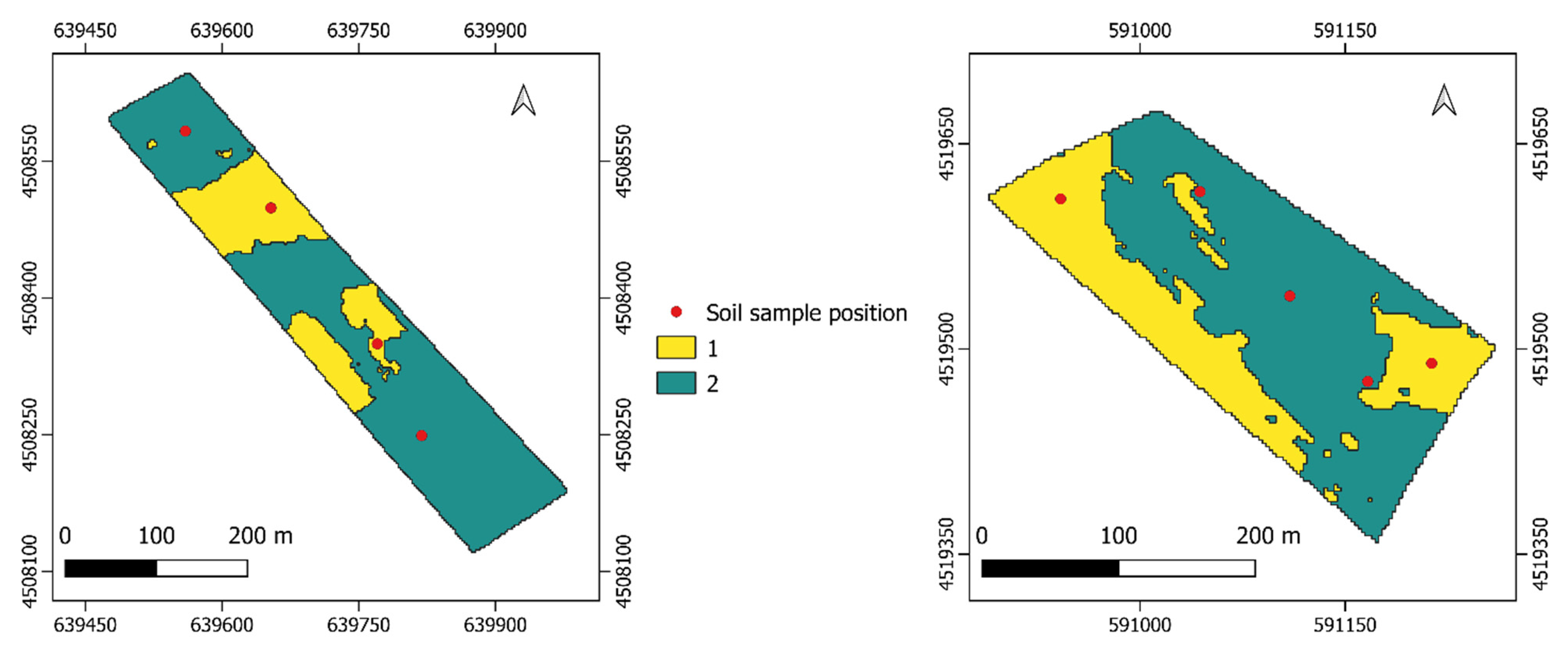
The management zones map creation workflow was entirely performed with R statistical software [
33]. The workflow to generate the management zone map is composed of several steps, which could be summarized as (1) import resistivity map, (2) raster to dataframe conversion, (3) cluster analysis, (4) management zone map creation and (5) export.
The resistivity maps were imported to R by using the “raster” function of the raster R package [
34]. After checking the geographical reference system and the spatial resolution, the resistivity maps were converted to “dataframe” R object by using the “as.data.frame” function of the raster R package.
The cluster analysis was performed by using the “kmeans” function of the stats R package [
33]. The “kmeans” function requires the number of “centers” as a mandatory parameter, which defines the number of clusters that the algorithm must perform.
The optimal number of “centers” was defined by performing the gap statistic index, which calculates the goodness of clustering by comparing the total intra-cluster variation for different values of k with their expected values under the null reference distribution of the data. The gap statistic index was performed by using the “clusGap” function of the cluster R package [
35].
Based on the gap statistic index, the k-means cluster analysis was performed, and the zone management map was created and converted to the spatialpolygonsdataframe R object by using the “df_to_SpatialPolygons” function of the FRK package [
36]. The spatialpolygonsdataframe was exported by using the “writeOGR” function of the rgdal R package [
37] in an ESRI Shapefile file format.
2.4. UAV Images Acquisition
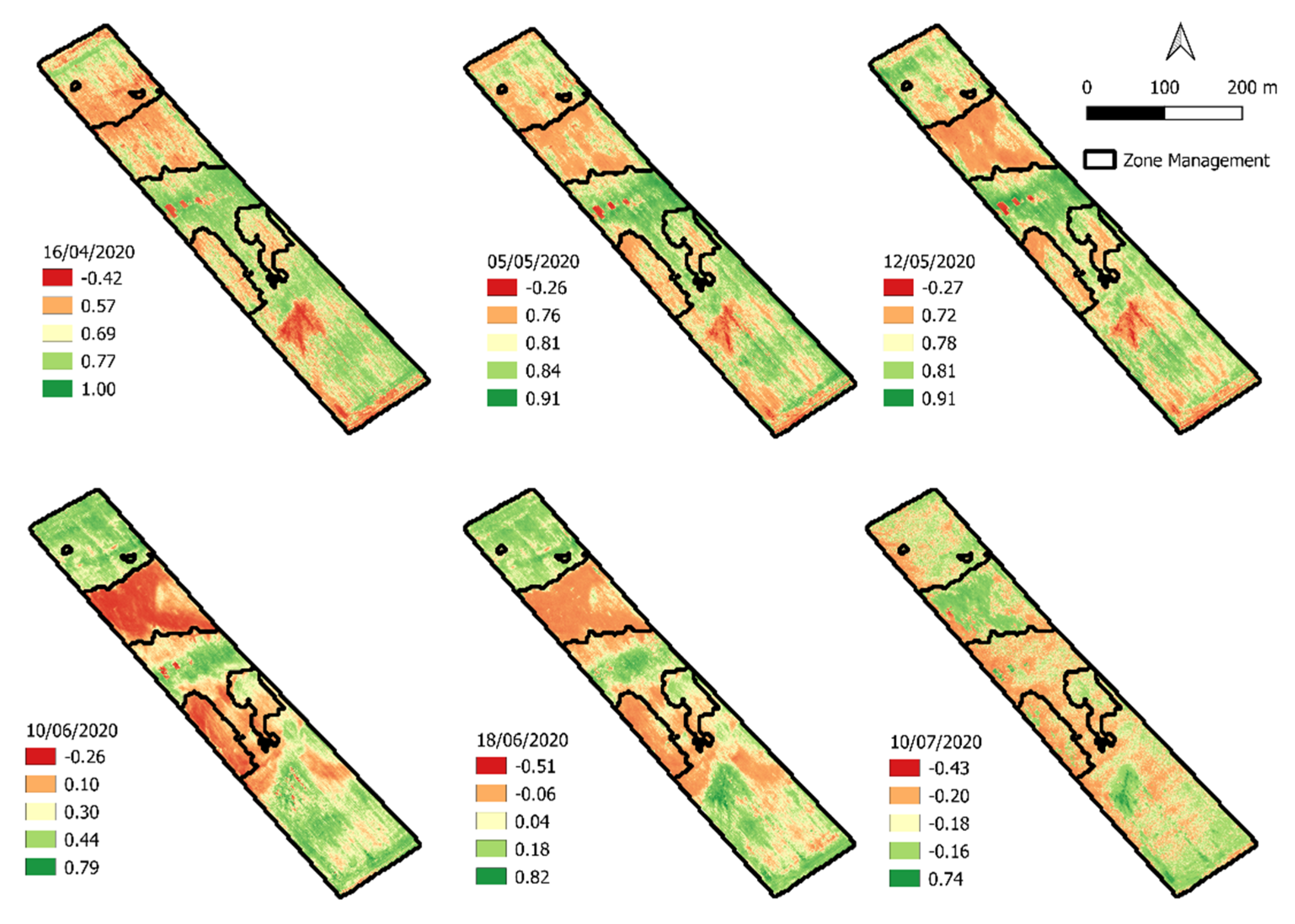
The UAV images acquisition was conducted in 2019–2020 at site 1. The images were acquired using a Parrot Bluegrass drone with a Parrot Sequoia multispectral sensor, and the flight plan was set using Pix4Dcapute. Six flight missions were carried out throughout the durum wheat crop cycle (
Table 3).
For the agriculture domain sector, each image acquired by UAV flight required an image processing workflow to compute the vegetation index (VI). The image processing is composed of three main steps: (1) orthomosaic reflectance map generation; (2) computation of VI maps; (3) data extraction.
Starting from the raw tiff files acquired by the UAV, the orthomosaic reflectance map was generated by using structure from motion (SfM) software [
38], which in this case was PIX4D.
In order to complete the second main step, the orthomosaic reflectance map was imported in R statistical software [
33], and the VI shown in
Table 4 was calculated [
39].
In order to define the relationship between the previous VI and the resistivity map, the coefficient of determination (R
2) was computed. (1) The VI maps were scaled at the same resolution as the resistivity map by using the “resample” function of the raster R Package [
34]. (2) After obtaining raster files with the same resolution, they were converted to a data frame by using the “as.data.frame” function of the raster R Package [
34]. (3) Then, a linear model was fitted by using the “lm” function of the stats R Package [
33] in order to compute the R
2.
2.5. Statistical Analysis
All the statistical analyses were performed with R statistical software [
33].
Before performing any analysis, a descriptive statistics analysis was performed on the resistivity maps; the range and the coefficient of variation (CoV) to describe the spatial variability of both sites were calculated.
In order to validate the zone management map creation workflow, the statistical analysis was performed on the soil samples, which were assigned an experimental factor in relation to the zone management area previously defined.
In order to perform the statistical analysis, a one-factor linear model was built by using the “lm” function of the stats R package [
33], on which the cluster was considered the main factor.
Before performing the Analysis of Variance (ANOVA), whether the model met the three assumptions of the ANOVA was verified [
45]. The Normality distribution of the model residual was checked both graphically (QQ-plot) and by performing the Shapiro–Wilk normality test. Moreover, the homoscedasticity was checked using the Levene test. The last ANOVA assumption was satisfied by the experimental design and the random sampling.
When all the three ANOVA assumptions were met, the ANOVA was applied to the model. Only when the ANOVA showed a significant difference (
p-value < 0.05), the estimated marginal means post hoc analysis was performed by using the “emmeans” function with the Bonferroni adjustment of the emmeans R package [
46].
For the yield dataset, the same procedure of the soil samples dataset was performed, except that the statistical analysis was performed on a full factorial model where the site and zone management were set as experimental factors.
5. Conclusions
Two sites were mapped through an electromagnetic induction sensor to measure the electric conductivity map. An unsupervised machine learning approach was applied to the resistivity maps to detect the presence of different zones. Based on the results of the classification algorithm, multiple soil and crop samples were taken to validate the difference of the zones agronomically.
The algorithm used was able to detect the presence of the two zones for both sites. The soil samples acquired showed a significant difference between zones and not within zones for organic matter, nitrogen and the ratio of carbon–nitrogen. The differences reported on the soil proprieties led to a statistical difference in the grain yield obtained between the zones detected by the k-means algorithm.
This approach could be used to provide a high-quality prescription map to apply the precision agriculture applications. This approach could be scaled at the farm level; one resistivity survey and a few soil samples could generate a high-quality prescription map, containing costs and falling within the farm-year budget. Future work will focus on creating an automated nitrogen fertilization determination method starting from the acquired soil data.
Moreover, the correlation between the VI and resistivity map depends strongly on the phenological and developmental stage of the durum wheat. Therefore, we suggest performing the UAV multispectral images acquisition during the flowering phenological stages to attribute the crop spatial variability to different soil conditions.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}