1. Introduction
The fruit industry is a combination of labor-intensive and technology-intensive industries. Fruit picking is a complex and low-automation step that is time-consuming and labor-intensive in agricultural production processes. China is the largest fruit production and consumption country in the world, but the lack of an implementable automatic fruit-picking system means manual labor still predominates. The 21st century marks a critical period for the transition from agricultural mechanization to intelligent automation, necessitating the development of accurate and implementable equipment for fruit picking [
1].
In the process of intelligent picking, target detection and three-dimensional coordinate positioning of fruit are important steps. Fruit-picking equipment needs to recognize fruits in complex environments and calculate their three-dimensional coordinates through three-dimensional positioning algorithms [
2]. Target detection can classify and detect fruits and obtain their plane coordinates. Deep learning has two common types of target-detection methods: one-stage detectors, which have high inference speed, such as SSD (Single Shot MultiBox Detector) and YOLO (You Only Look Once), and two-stage detectors, which have high positioning and recognition accuracy, such as Faster R-CNN (Convolutional Neural Network), Mask R-CNN, and Cascade RCNN. S Zheng et al. utilized the YOLOv4 object detection algorithm to effectively and reliably complete target recognition tasks in complex scenes, achieving a mAP of 88.36%. However, this study did not consider recognition performance under different occlusion conditions and different lighting conditions [
3]. Arunabha M. Roy et al. proposed a real-time object detection framework, Dense-YOLOv4, which optimizes feature transfer and reuse by incorporating DenseNet into the backbone. This model has been applied to detect different growth stages of highly concealed mangoes in complex orchards [
4]. H Peng et al. proposed an improved feature extraction network model YOLOv3_ Litchi [
5]. This method introduces residual networks in YOLOv3, effectively avoiding the problem of decreased detection accuracy caused by too-deep network layers and reducing model parameters [
5]. Zhipeng Wang et al. optimized YOLOv5s using layer modification and channel construction, and the model parameters and weight volumes were reduced by about 71%, while the average mean accuracy was reduced by only 1.57%, respectively [
6]. T Liu et al. improved the YOLOv4 detection model based on the CSP Darknet5 framework. Under different occlusion conditions, the mAP reached over 90%, and the detection speed met the requirements [
7]. Wu Yijing et al. proposed a fig recognition method based on YOLOv4 deep learning technology to achieve fast and accurate recognition and localization of figs in complex environmental images [
8]. Defang Xu et al. proposed the YOLO-Jujube network to realize the automatic detection of date fruit ripeness under inhomogeneous environmental conditions [
9]. YOLO-Jujube outperforms the YOLOv3-tiny, YOLOv4-tiny, YOLOv5s, and YOLOv7-tiny networks. Zhujie Xu et al. designed a feature-enhanced recognition deep learning model for YOLO v4-SE [
10]. Combining the multi-channel inputs of RGB and depth images, the occluded or overlapped grapes are identified, and the upward picking point in the prediction box is inferred synchronously. The average localization success rate is 93.606%, which meets the harvesting requirements of a high-speed cut-and-receive cutting robot.
At present, common methods for 3D positioning include monocular cameras, binocular stereo vision matching, depth cameras [
11], laser ranging, and multi-sensor fusion. For 3D positioning, it is more important to obtain depth information of the object, that is, depth estimation. David Eigen et al. proposed a multi-scale deep neural network to regress the depth [
12]. Reza Mahjourian et al. proposed a method for unsupervised monocular depth estimation using monocular video. The authors assume that the scene is static, and the change of the image comes from the movement of the camera. The disadvantage of this method is that the depth cannot be estimated for the moving frame [
13]. Clement Godard et al. proposed the monodepth algorithm. This algorithm generates disparity maps of left and right images through a convolutional neural network to predict left or right images, obtain loss, and continue back propagation training to generate unsupervised depth estimation. However, training relies on left and right views, so monocular image prediction cannot be used [
14]; Clement Godard proposed a self-supervised method of monodepth2, which solves the pixel occlusion problem during monocular supervision [
15]. The advantage of monocular depth estimation is that it has low requirements for equipment environment, is easier to set up, and is more suitable for mass production requirements.
In summary, these studies on fruit target detection mainly rely on YOLOv3, v4, and v5 algorithms to quickly recognize fruits under different occlusions and illumination intensities. Regarding depth estimation, these studies have progressed from moving frame-based disparity calculation to CNN-based prediction to a fusion of laser ranging and attention mechanism, gradually improving the accuracy and resolution of depth-estimation algorithms. However, many factors affect the accuracy of fruit target detection and positioning, such as fruit overlap in captured images, branch or leaf occlusion, and changes in illumination intensity. Therefore, further research is needed to improve the speed and accuracy of recognition in complex field scenes. In this study, the latest YOLOv8s was selected as the target-detection algorithm for fruits, and this version is the type of target detection with the smallest structure and highest accuracy of the YOLOv8 series. We have improved the YOLOv8s network because of the number of small individual targets, cluster structure, and overlapping occlusion within the citrus images taken in the natural environment. This improved method uses the attention mechanism BiFormer block, which perceives sparsity via dynamic query; as the backbone feature extractor, adds a small-target-detection layer in Neck; and uses EIoU (Efficient Intersection over Union) Loss as the loss function. In addition, most of the related studies on depth estimation are based on binocular stereo vision and RGB-D (object detection in RGB-D images) depth cameras, which have the disadvantages of high cost and high computational overhead. The monocular depth-estimation method is low in cost, simple in structure, and low in computational overhead. However, due to its ranging method being a geometric measurement still based on focal length, the field of view, and fruit size, the fruit size change will lead to a large error in monocular depth estimation. Therefore, this study proposes a monocular depth-estimation algorithm based on multi-resolution fusion, which uses the ResNeXt-101 network to obtain the pre-trained model, and then through content adaptive multi-resolution fusion, allows the model to take into account both high-frequency details and low-frequency structures, thus enabling the algorithm to obtain higher-resolution pixel depth information while performing depth estimation without being constrained by the size of the fruit.
3. System Implementation Method
The proposed spatial coordinate positioning algorithm of fruits fusing the improved YOLOv8s and the adaptive multi-resolution model is illustrated in
Figure 3. In this study, an improved YOLOv8s network was utilized to detect and extract fruit species and target locations. The depth-estimation model uses the ResNeXt101 network to obtain a pre-training model for depth estimation, and then the pre-training model is used to generate a fusion of low-resolution and high-resolution estimates to obtain the basic estimates, which are combined with patch estimates to obtain depth estimates at different resolutions. Further, the pixel coordinates of target detection and depth estimation are fused in the same coordinate system, and the relative depths are calibrated according to different distances in the space. Finally, the absolute depth of each pixel is obtained, and the 3D coordinates of the target fruit are obtained by transforming the pixel coordinate system to the camera coordinate system according to the camera calibration.
3.1. Improved YOLOv8s Target-Detection Model Construction
YOLOv8 is a single-stage target-detection algorithm that improves on YOLOv5. YOLOv8 uses a more complex network architecture that includes multiple residual units and multiple branches, and it is slightly faster and more accurate than YOLOv5. The algorithm structure of YOLOv8 is divided into four main parts: input side, backbone, Neck, and prediction in four parts. Compared with YOLOv5, YOLOv8 differs in the following points: The C3 module is replaced by the C2f module in the backbone layer, which achieves further lightweighting. In PAN (Path Aggregation Network)-FPN (Feature Pyramid Network), the convolution structure in the upsampling stage in YOLOv5 is removed, and C3 is replaced with C2f. YOLOv8 uses the idea of Anchor-Free. In the loss function, YOLOv8 uses VFL (VariFocal Loss) Loss as the classification loss function and DFL (Distribution Focal Loss) Loss+CIoU (Complete Intersection over Union) Loss as the classification loss sample-matching function. In the sample matching, YOLOv8 discards the previous IOU matching or one-sided proportional assignment but uses Task-Aligned Assigner matching.
In this study, citrus images were captured in a natural environment with a large number of small individual targets, cluster structures, and overlapping occlusions. In the forward propagation of the YOLO network, the semantic features of the feature map become stronger as the convolution-pooling advances, while the visual features, i.e., the visibility of small targets, become weaker. Most scenarios of fruit target detection are binary classification problems, i.e., in most scenarios, there is only one type of fruit in the image, and the network has to divide only the foreground (citrus) and background, so visual features are more important than semantic features in this study. Therefore, the attention to the target is enhanced in the design of the network, and the utilization of the shallow features of the network is strengthened.
This paper thus improves the YOLOv8s network based on the direction of small-target detection. The structure of the improved YOLOv8s target-detection algorithm is shown in
Figure 4, with the color differentiated part as the improved part. Firstly, the backbone feature extraction module with BiFormerblock as the core is constructed, which is based on a dynamic sparse attention mechanism to achieve more flexible content perception without distracting the attention of irrelevant markers with the target. A shallow detection layer is added to the target fusion extraction part used to obtain a shallower feature map, and the high resolution of the shallow features are combined with the high semantic aspects of the underlying features to achieve accurate localization and prediction of small-target citrus.
The backbone network employs the BiFormer block as the feature extractor. As shown in
Figure 5, the BiFormer block is first convolved via a 3 × 3 depth convolution, and it is then added to the BRA (Bi-Level Routing Attention) module and MLP (Multi-Layer Perceptron) module and LN (Layer Normalization). Deep Convolution DWconv (Depth-Wise Convolution) is used to implicitly encode relative position information. BRA is a dynamic query-aware sparse attention mechanism that enables more flexible computational allocation and content awareness. The key idea is to filter out the most irrelevant key-value pairs at the coarse region level to retain only a small portion of routing regions. BRA preserves fine-grained details via sparse sampling instead of downsampling, and it thus can improve the detection accuracy of small targets.
Due to the small size of the target sample of citrus taken at a distance and the fact that the downsampling multiplier of YOLOv8s is relatively large, it is difficult for the deeper feature map to learn the feature information of the small-target citrus, so the small-target-detection layer is added in Neck. The 15th layer in Neck is fused with the features extracted from the first BiFormer block to obtain a shallower feature map. Up to this detection layer is considered four, and the shallower feature map is detected after stitching with the deep feature map during detection. In summary, adding small-target-detection layers allows the network to focus more on the detection of small targets and improve the detection effect.
Finally, the network loss function is replaced by EIoU Loss. EIoU Loss splits the influence factor of the aspect ratio and calculates the width and height of target frame and anchor frame separately, which solves the fuzzy definition of the aspect ratio based on CIOU and makes the prediction frame converge more accurately. The loss function equation of EIoU Loss is as in Equation (1).
EIoU Loss [
22] consists of three parts, which include overlap loss
, center distance loss
, and width–height loss
. IoU is the intersection ratio between the predicted bounding box and the true bounding box,
is the centroid of the predicted bounding box and the true bounding box,
is the width of the predicted bounding box and the true bounding box, and
is the height of the predicted bounding box and the true bounding box.
is used to calculate the Euclidean distance, and c is the diagonal length of the predicted bounding box and the true bounding box.
and
are the width and height of the smallest rectangle of the two bounding boxes.
3.2. Monocular Estimation Network Construction
In monocular depth-estimation networks, it is crucial to obtain accurate depth values for detection targets under different scenarios. Studies have shown that compared to models such as ResNet-101, ResNeXt-101, and DenseNet-161, ResNeXt-101 has relatively better performance due to the use of WSL (Weakly Supervised Learning) pre-training. This study adopts ResNeXt-101 for pre-training, and weakly supervised training is conducted before pre-training. Since the existing deep datasets do not provide a sufficiently rich set of training data that can be applied in multiple scenarios, this study fuses multiple datasets that can make full use of the complementarity among different datasets, as shown in
Table 1. Due to the inconsistency in the expression of each dataset, only some datasets provide relative depth; thus, depths across datasets cannot be transformed. Therefore, this study uses the single-sample and shift-invariant loss localization method proposed by MIDAS [
18], as shown in Equation (2), to solve the problem of incompatibility between datasets.
where M is the number of pixels in the image with the true value of the valid surface; parallax prediction
is the prediction model parameter, relative to the true parallax
of the ground, indexed under a single pixel box; rho defines a specific loss function type; and
and
represent the scale and shift transformation of the predicted value and the ground true value. Loss is defined in parallax space, and scale and shift transformations make data compatible across different datasets.
Although a pre-trained model is obtained, it is important to consider how to improve the performance of depth estimation in the overlapping dense regions of tree leaves and fruits in the fruit localization scenario. In this study, the monocular depth estimation model is improved to a depth-estimation model with both high-frequency details and low-frequency structures via content-adaptive multi-resolution merging. The network characteristics of the monocular estimated depth vary with the input image. At low resolutions close to the training resolution, the depth estimates have consistent structure but lack high-frequency details. When the same image is fed into the network at a higher resolution, high-frequency details can be better captured, while structural consistency will be reduced. This property stems from the limitation of the model’s capacity and perceptual field size. In this study, a dual estimation framework is used to fuse two adaptive depth estimates of the same image at different resolutions to produce high-frequency details while ensuring structural consistency. As shown in
Figure 6, after obtaining the low-resolution depth map, the pix2pix [
27] architecture is used to transfer the high-resolution fine-grained details y1 to the low-resolution input using a model with 10-layer U-Net [
28] as the generator to obtain the basic estimate [
29]. The results obtained from the dual estimation can be further optimized for high-frequency details, and the process is to generate depth estimates of different resolutions for different regions of the image, which are then combined to obtain a consistent and complete result. Experiments were performed with basic resolution tiled images, tiled images equal to the receptive field size, with one third overlap for each patch. The edge density in the patches is compared with the edge density of the whole image. If the former is smaller, it is discarded; otherwise, the patch is expanded until the edge density in the patch is the same as the edge density of the whole image. Finally, the image with regional high-frequency details is extracted, and then the high-frequency details y3 are transferred to the input of the basic estimation to obtain the depth estimation.
3.3. Model Fusion Construction
The construction of the object detection and localization model is shown in
Figure 7, which mainly includes the unification of target detection and monocular estimation coordinates, camera calibration, distance calibration, and the transformation between pixel coordinate system and world coordinate system.
Based on the improved YOLOv8s model, the type of each fruit, the upper-left corner coordinates (
u1,
v1), and the lower-right coordinates (
u2,
v2) of the target box in the image are obtained. Finally, the central coordinates are (
x,
y), calculated using Equation (3).
The (x, y) obtained using Equation (3) is input into the monocular estimated depth map of the image to obtain the relative depth, which is used for subsequent calculation of absolute depth.
Zhang Zhengyou’s calibration method [
30] was used to calibrate the camera, and the internal reference matrix of the camera was obtained, using Equation (4).
In depth estimation, the relative depth of the object is obtained, and the true distance of each point can be calibrated to complete the conversion from relative depth to absolute depth [
31]. Based on the imaging principle of the Kinetic depth camera [
32], the relationship between the original depth, i.e., the relative depth, and the metric depth in meters,
d, was determined as in Equation (5).
In Equation (5),
B = 0.075 m corresponds to the distance (baseline) from the infrared projector to the infrared camera,
Fx is the horizontal focal length of the infrared camera with a value of 367.749,
Vmax represents the maximum relative depth, and
v is the relative depth. As shown in
Table 2, in the region where the deepest distance of the experiment scene is 180 cm, the actual depth d and relative depth
v of 30 cm to 150 cm are selected to calibrate the
Vmax. The maximum depth value in the depth image of the fruit plant at different increasing distances is determined, and this result is used to calculate the absolute distance
d, as described later in this article.
Step 4: Transformation of pixel coordinate system to world coordinate system [
33].
In this study, the O point of the camera coordinate system is the camera light center, the o point of the world coordinate system is the center point of the base of the robotic arm, and the camera coordinate system is located on the robotic arm. The transformation from the world coordinate system to the camera coordinate system is calculated using Equation (6).
The transformation from the pixel coordinate system to the camera coordinate system is shown in
Figure 8. Equations (7)–(9) can be derived from ΔABO’~ΔOCO’ and ΔBPO’~Δ CP’O’.
Then we get Equation (10).
This gives the coordinates p(
x, y) in the two-dimensional imaging plane. The image coordinate system in
Figure 8 is transformed into a pixel coordinate system by translating and scaling, as expressed in Equation (11); then, after combining Equations (10) and (11), Equation (12) can be derived.
The transposed camera intrinsic matrix is obtained using Equation (4), and the true depth of the fruit is obtained from step 3 of the model fusion, and then the under the world coordinate system can be solved from the pixel coordinate in the pixel coordinate system.
4. Results and Analysis
4.1. Results and Analysis of Target Detection
In this experiment, the model was trained on AlamLinux, GeForce RTX3090 Ti with 24 G video memory. The framework used was PyTorch, with the Epoch set to 200; Batch Size was set to 32; and the input image size was 640 pixels*640 pixels. The numbers of training images, validation images, and test images are 1936, 242, and 242, respectively.
The results of the improved network model training are shown in
Figure 9, where the horizontal coordinate is the number of iterations, and the vertical coordinate is the performance of the network. The curves in the figure are recall, precision, mAP_0.5, and mAP_0.5:0.95, respectively. The mAP_0.5 gradually tends to 1 as the number of training rounds increases. When the training reaches 200 rounds, precision, recall, and mAP_0.5:0.95 reach 97.7%, 97.3%, and 88.45%, respectively.
To verify the detection performance of the improved YOLOv8s network on citrus fruits, we tested the improved algorithm under six different scenes: single target, multiple target, smooth light, backlight, light obscuration, and heavy obscuration. To better demonstrate the detection performance of the algorithm, we have illustrated and compared the recognition results of the improved network in these six scenes with the results before improvement in
Figure 10.
Figure 10a,d show the recognition results under a single target. By comparing them, it can be seen that, firstly, the improved network has improved the confidence level of recognition of citrus by 1%. Moreover, the citrus that is defocused in the lower left corner of the subplot with less than one fourth of its volume is also correctly identified, although with a lower confidence of only 39.2%.
Figure 10b,e present the recognition results under multiple small targets, and it can be seen that the improved network has increased confidence of citrus recognition under both small targets, and the model could identify the small target in the middle of the image where the rightmost part is two-thirds obscured by a citrus. However, the improved model also shows false positives with a confidence level not exceeding 40%. For example, the improved network misidentified the small leaf at the bottom right corner of the picture as a citrus, but with a confidence level of only 36.1%. Moreover, both the pre- and post-improvement models are prone to mislabeling a single citrus fruit as multiple objects when the single citrus fruit object is heavily occluded, which is more prevalent in the improved model.
Figure 10c,f depict the recognition results under good lighting conditions, with the accuracy of the improved network increasing by almost 3% relative to before improvement. Also, it can be observed from
Figure 10f that the improved network has marked one target in the middle of the image with two boxes.
Figure 10d,j illustrate the recognition performance under backlighting conditions. A small target located in the lower left portion of the image, with approximately 80% of its volume obscured, is not recognized in
Figure 10j but is identified in
Figure 10d.
Figure 10h,k present the recognition performance under mild occlusion. By comparing them, we can see that the recognition accuracy of the smaller fruits is improved significantly after the modification, which is about 8% compared to that of the original one.
Figure 10i,l show the recognition performance under severe occlusion. The improved model recognizes the small target located in the lower middle of the picture that is not recognized in
Figure 10i, and the confidence level is 87.3%. However, the case of being marked as multiple target frames also occurs in heavy occlusion because the target is segmented into multiple regions.
In summary, it is evident that the improved network effectively improves the confidence of citrus recognition in various scenarios, albeit with some limitations:
- (1)
The improved model occasionally produces false detections in small-target scenes due to its heightened sensitivity to small-target components in the image that are similar to citrus. However, the confidence level of recognition in such cases is generally low. To mitigate this issue during practical usage of the model, a detection threshold of 0.5 or higher can be set to eliminate false detections.
- (2)
In some partially obscured scenarios, where the target citrus subject is divided into separate parts by the obstruction, both the improved and original models may erroneously label a single target as multiple ones. However, since the improved model is more sensitive to small targets, such mislabeling is more pronounced (as shown in
Figure 10e,f,j,l. Similarly, setting the confidence threshold above 0.7 can reduce the occurrence of this issue.
To better evaluate the performance of the improved network, 100 images from each of the above six scenes were taken, and the images were tested using the improved model and the original YOLOv8s. After eliminating values with a confidence score below 0.7, the average values of the confidence of the two models under different scenarios, i.e., the recognition accuracy results, were calculated, as shown in
Table 3. The model shows a relative improvement in accuracy of 0.9%, 3.2%, 1.7%, 4.5%, 4.7%, and 1.1% for the single target, multiple small target, down-light, backlight, light obscuration, and heavy obscuration scenes, respectively. The average accuracy of the improved model is 94.7%, representing a 2.7% improvement. This indicates that the new model can identify more accurately in a variety of natural environments compared to the original model.
4.2. Monocular Depth-Estimation Results and Analysis
To verify the accuracy of the monocular depth estimation in this experiment, a USB 90-degree distortion-free 720P monocular camera was used to acquire citrus at different depths and under different illumination in a natural environment. Firstly, citrus were photographed in 10 sets with increasing distance. Secondly, citrus were photographed in 10 sets under different illumination conditions. The depth-estimation data under the aforementioned two conditions were measured. The results were evaluated and analyzed using MAE (Mean Absolute Error) and RMSE (Root Mean Squared Error).
- (1)
The effects of different distances on the monocular depth estimation were calculated, and the results of MAE and RMSE measurements for citrus at different distances are shown in
Table 4.
The measured distance range from 30 cm to 150 cm, increased by 15 cm increments each time. The experiment has ten sets of images, with nine sets each.
Figure 11 shows a set of depth-estimation images at different distances. In the figure, it can be seen that the depth image detail is more complete at close range, and the absolute depths between fruit, leaves, branches, and background are clearly distinguished. The details become more and more blurred as the distance grows farther and farther away.
Figure 11a–i are the fruit images at different distances with the corresponding depth-estimation maps. The image capture distances in
Figure 11a–i are 30 cm, 45 cm, 60 cm, 75 cm, 90 cm, 105 cm, 120 cm, 135 cm, and 150 cm, in that order.
The average distances, MAE, and RSME were calculated based on 10 sets of data. The average values of MAE and RSME of depth-estimation results were 1.39 and 2.05 in the detection range of 30 cm to 150 cm, respectively. The average values of MAE and RSME of depth-estimation results were 0.53 and 0.53 in the detection range of 30 cm to 60 cm, respectively. This illustrates that the positioning is more accurate at close range.
- (2)
The depth information was measured at a distance of 60 cm from the citrus under different illumination intensities, as shown in
Figure 12.
Figure 12 shows the citrus depth-estimation images under different illuminations. It can be seen that at lower illuminations, the target fruit is not distinctly separated from the background, and even some branches and leaves blend into the background. When the illumination is normal or high, the target is distinctly separated from the background, and the levels of objects at different distances are clearly visible. The following results were obtained after measuring 10 groups of citrus’s monocular depth estimates with different illuminations. The mean (MAE, RSME) depth-estimation results for citrus with illumination below 1000 lx were 2.39 and 6.05. The mean (MAE, RSME) depth-estimation results for citrus in illumination from 1000 lx to 5000 lx were 0.49 and 0.64, respectively. The mean (MAE, RSME) depth-estimation results for citrus with illumination above 5000 lx were 0.79 and 1.05. Therefore, it is more effective when the illumination is normal and higher.
The results of this method for different depths are compared with those of conventional methods of monocular estimation and binocular stereo matching. For monocular geometric estimation, the coordinates of the upper-left and lower-right corners of the target are first obtained as
and
, respectively, using the target-detection model, and then the distance d is finally calculated via Euclidean distance based on the focal length and fruit size. For binocular stereo matching, a binocular camera with a baseline of 120.0 mm is used in experiments to capture the left and right views simultaneously [
34]. Then, the stereo matching method is applied to obtain the parallax; improve the parallax map accuracy by adding a WSL [
35] filter; and finally calculate the depth based on the parallax, focal length, and baseline.
Table 5 shows the results of measurements for this method, the monocular geometric algorithm, and the binocular stereo matching algorithm at the same distance range. At distances from 30 m to 60 cm, the average values of MAE for ranging using this method, the monocular geometric algorithm, and the binocular stereo matching algorithm were 0.56 cm, 1.28 cm, and 1.54 cm, respectively. The value of distance d in monocular geometric ranging is related to the size of the fruit, but only the average size of the fruit can be used in the actual calculation, so the error is larger. In binocular stereo matching, due to the constraint of the baseline of the binocular camera, measurement at close range is poor, and when the fruits are more concentrated, the parallax map of the image appears hollow, which results in poor measurement. In this experiment, the adaptive resolution fusion algorithm has the advantages of high-resolution depth estimation, unconstrained by camera parameters and fruit size, thus reducing the error by 2–3 times.
4.3. Results and Analysis of Model Fusion
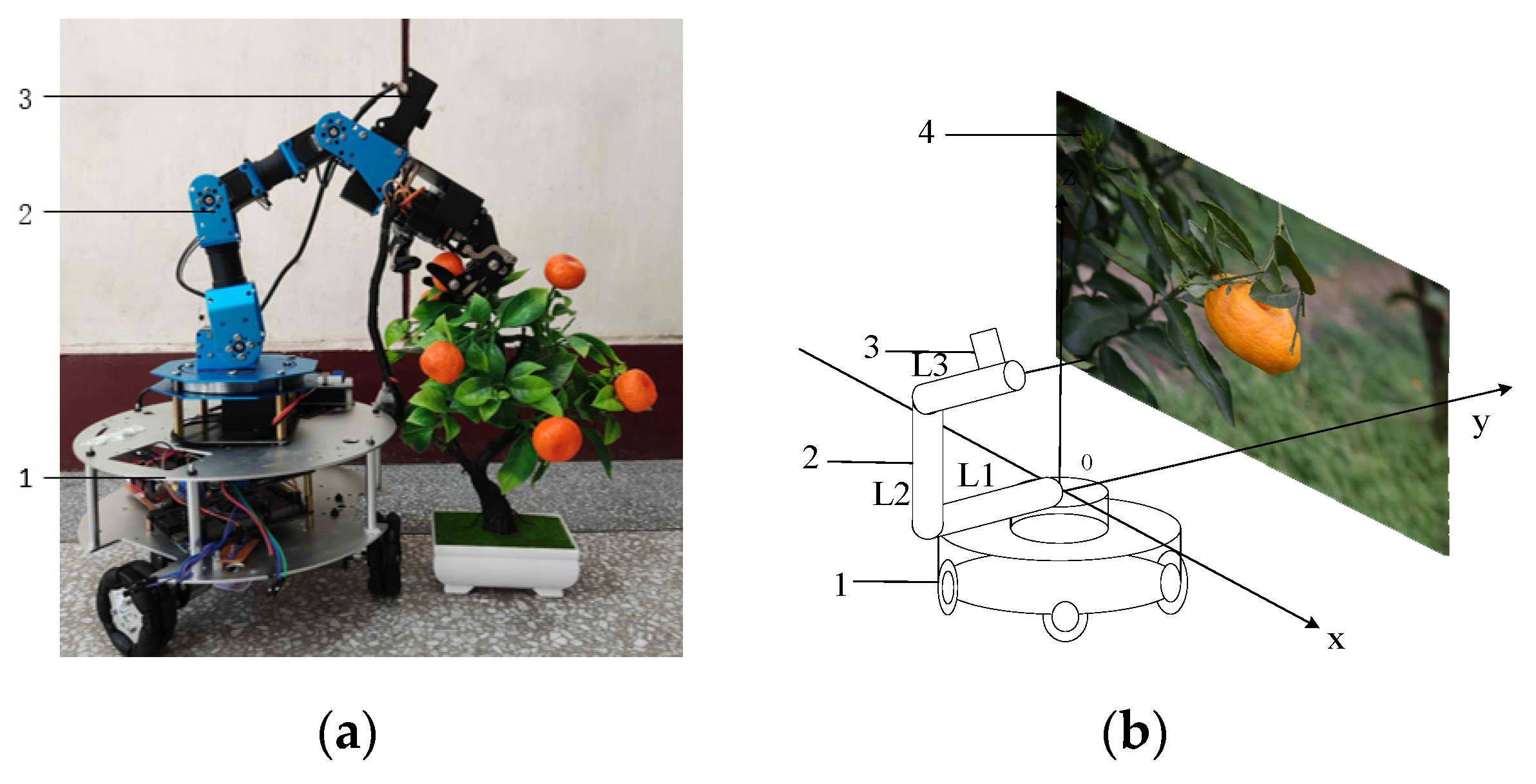
This study uses the robot arm of the experimental platform for picking and calculates the success rate to measure the accuracy of 3D positioning picking. The test procedure was carried out in the laboratory using the experimental platform and simulated fruit shown in
Figure 1. The target-detection algorithm is fused with the monocular depth-estimation algorithm to obtain the 3D coordinates of the object, and then the computed 3D coordinates are solved using inverse kinematics [
36] to obtain the corresponding joint rotation angle to control the fruit grasping.
Due to the limited motion range of the robotic arm, the fruit tree model was placed at distances of 30 cm and 45 cm in this study. The target detection and depth estimations are performed for citrus at different distances and under normal light, and then the 3D coordinates of the fruit are calculated using this method. Finally the robotic arm is controlled to grasp the target fruit.
It was concluded that the success rate of picking at 30 cm reached 80.6%, and the accuracy rate of picking at 45 cm reached 85.1%, indicating the feasibility of this method of fruit picking. There were picking failures in this experiment for the following reasons:
- (1)
The error introduced during the process of transformation from the relative depth to absolute depth may cause picking failures since this experiment simulates the conversion of relative depth to absolute depth using manual calibration in a limited space, but the manual calibration requires the measurement of absolute depth, and the maximum depth value in the depth image of the fruit plant is affected by light. This results in the existence of errors in the transformation, which in turn transmits errors to the positioning results and causes picking errors.
- (2)
Errors introduced by the hardware platform may also cause picking failures. The errors of the robot arm servo rotation accuracy, linkage distance measurement, and its control algorithm lead to deviations in the actual picking motion of the robot arm, which consequently affects the picking accuracy.
5. Conclusions and Discussion
To meet the needs of automation in the fruit industry for automatic fruit recognition and picking, a method based on YOLOv8s and monocular adaptive multi-resolution fusion is proposed in this study. The main findings are as follows:
(1) This method can identify fruit species more accurately and calculate the plane coordinates of target fruits in small targets and with occlusion. In this study, citrus was detected using the improved YOLOv8s algorithm, and the final accuracy was improved by 0.9%, 3.2%, 1.7%, 4.5%, 4.7%, and 1.1% in single target, multiple small target, down-light, backlight, lightly occluded, and heavily occluded scenes, respectively. The average accuracy of the improved model was 94.7%, representing a 2.7% improvement.
(2) This method is able to extract depth information from monocular images with greater accuracy. The average values of MAE and RSME of depth-estimation results were 0.53 and 0.53 in the detection range of 30 cm to 60 cm. The mean (MAE, RSME) depth estimates for citrus in illumination ranging from 1000 lx to 5000 lx were 0.49 and 0.64, respectively, indicating that the method is generalizable at close range with normal light intensity.
(3) The adaptive resolution fusion method used in this study can improve the accuracy of low-resolution image depth estimation. Compared to monocular geometric and binocular ranging algorithms, this method has the advantage of obtaining higher-resolution depth estimates from low-resolution images, and it is not constrained by camera parameters or fruit size, thus reducing errors by a factor of 2–3.
(4) This method can realize the localization of multiple targets from monocular images, and it can complete more accurate spatial coordinate measurement under the influence of close distance and strong normal illumination. However, when the distance is far, the light intensity is low, and the fruit overlaps and obscures the error is relatively larger, so this study needs further improvement for fruit localization.
In summary, in this study, we successfully developed a method for spatial localization of citrus fruits. Next, we will try to validate and further optimize our method through field experiments. Meanwhile, we will continue to optimize the model structure and reduce the model size. We will also build a wider range of datasets to improve the adaptability and anti-interference ability of the algorithm for spatial localization of citrus in more scenarios. In future research, we are committed to applying the localization algorithms to real standardized orchard picking to promote agricultural modernization and intelligence.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}