An Efficient and Automated Image Preprocessing Using Semantic Segmentation for Improving the 3D Reconstruction of Soybean Plants at the Vegetative Stage


 ,
,
Abstract
:1. Introduction
- Rule-based methods. For instance, Favre et al. [2] developed the L-studio-based simulator, which was used by Kaya Turgut et al. [3] to generate synthetic rose tree models. Despite the method being less affected by environmental factors and having lower reconstruction costs, it has problems such as large errors and low reconstruction accuracy.
- Image-based methods. Zhu et al. [4] established a soybean digital image acquisition platform by employing a multiple-view stereo (MVS) vision system with digital cameras positioned at varying angles. Such an approach effectively addressed the issue of mutual occlusion among soybean leaves, resulting in the acquisition of a sequence of morphological images of the target plant for subsequent 3D reconstruction of soybean plants. Jorge Martinez-Guanter et al. [5] used the Sfm method for model reconstruction. A set of images covering each crop plant was used and the dataset was composed of approximately 30 to 40 images per sample for full coverage of each plant based on its size, thereby guaranteeing a proper reconstruction. Based on MVS technology, Sun et al. [6] reconstructed 3D models of soybean plants and created 102 original models.
- Instrument-based methods. Due to the rapid advancements and widespread adoption of 3D laser scanning technology, researchers and practitioners have begun utilizing scanning techniques to reconstruct accurate crop models. To illustrate, Boxiang Xiao et al. [7] used a 3D digitizer to obtain spatial structure and distribution data of wheat canopy. After data processing, a 3D model of the plant organs was built, including stems and leaves, based on surface modeling algorithms. Laser scanning has emerged as a novel technology and tool for the next generation of plant phenotyping applications [8]. Jingwen Wu et al. [9] successfully generated a 3D point cloud representation of a plant by utilizing a multi-view image sequence as the basis. An optimized iterative closest point registration method was used to calibrate the point cloud data obtained from laser scanning, thereby improving the plant’s detailed features and establishing a 3D model. Instrument-based 3D reconstruction methods can directly capture point cloud data of ground crops at a faster speed [10]. However, such methods also have some challenges such as large cloud data volume, long processing time, high equipment costs and difficulty in point cloud denoising. In consideration of the accuracy, speed and cost factors of crop 3D reconstruction, image-based MVS technology was selected to reconstruct the 3D models of soybean plants during the seedling stage.
- Sheng Wu et al. [11] used MVS technology for reconstruction and proposed a region-growing denoising algorithm constrained by color difference. In the algorithm, a low-cost approximate color metric model is used to improve the denoising efficiency.
- Yuchao Li et al. [12] applied the Euclidean clustering algorithm for background removal and used a color threshold-based segmentation method to remove noise points on the plant edges.
- Peng Song et al. [13] first used statistical filters to remove noise values and obvious outliers from point clouds. Subsequently, the topological structure of the point cloud was defined using a radius filter, the number of points within 0.002 m of each point was calculated and points with less than 12 neighboring points were filtered out. Finally, the point cloud was packed into 0.001 m voxel grids using a voxel filter, and the coordinate positions of points in each voxel were averaged to obtain an accurate point.
- Tianyu Zhu et al. [14] proposed a high-throughput detection method for tomato canopy phenotypic traits based on multi-view 3D reconstruction. A full-range point cloud of the tomato canopy was first acquired before background and interference noise was removed through conditional filtering and statistical outlier removal (SOR).
- Yadong Liu et al. [15] proposed a fast and accurate 3D reconstruction method for peanut plants based on dual RGB-D cameras. Two Kinect V2 cameras were symmetrically placed on both sides of a peanut plant, and the point cloud data obtained were filtered twice to remove noise interference.
- According to the existing research, an observation can be made that denoising in crop 3D reconstruction is generally performed on the 3D point cloud after generating the point cloud model using relevant algorithms. The process of noise reduction in 3D point clouds presents challenges such as algorithm complexity and high computational requirements. However, in the present study, the denoising task was performed on the 2D image data. For image data, preprocessing typically involves a sequence of basic transformations such as cropping, filtering, rotating, or flipping images [16]. Since 2D images contain less information, they are more computationally efficient for this task. This study aimed to improve image preprocessing efficiency by using semantic segmentation on raw soybean plant images.
- Through experimental evidence, it was determined that using semantic segmentation for image preprocessing can improve the efficiency of image preprocessing while maintaining good model accuracy and reducing model reconstruction time. Semantic segmentation provides an important foundation for efficient and automated image preprocessing in the 3D reconstruction of soybean plants during the vegetative stage.
2. Materials and Methods
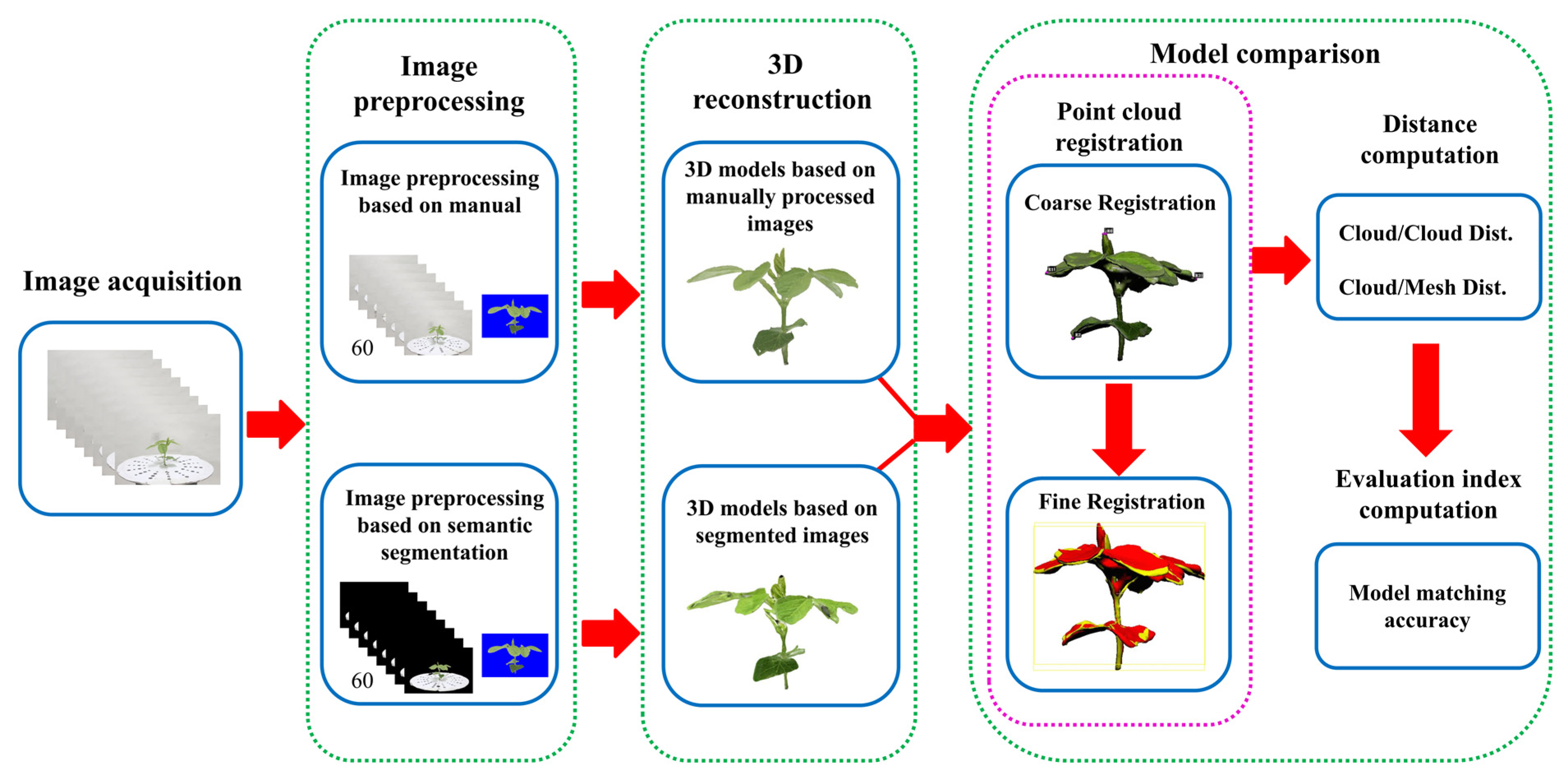
2.1. Overview of Method
- Image data acquisition;
- Manual image preprocessing and semantic-segmentation-based image preprocessing;
- Model establishment using both methods;
- Model accuracy comparison (coarse point cloud registration, fine point cloud registration, distance calculation and model matching accuracy calculation).
2.2. Experimental Material
2.3. Image Acquisition
- First, the reconstruction target was placed on the turntable in the photo booth, and a circular calibration mat was placed at the base of the plant. The position and brightness of the lighting were adjusted to ensure a good environment for target reconstruction.
- Second, the camera was placed approximately 90 cm away from the reconstruction target and the camera height was adjusted to the lowest position.
- Third, circular photography was used and the turntable was manually rotated every 24° (determined by the black dot on the calibration mat) to capture 15 images per revolution.
- Finally, the camera height was adjusted three times from low to high to obtain a sequence of 60 images of soybean plant morphology.
- Figure 2 shows the soybean image acquisition platform and image acquisition method flowchart. Such a method can effectively alleviate the problem of mutual occlusion between soybean leaves. Additionally, in this study, MVS technology was used to capture images of soybean plants during the vegetative stage.
2.4. Image Preprocessing
2.4.1. Manual-Based Image Preprocessing
2.4.2. Image Preprocessing Based on Semantic Segmentation
- DeepLabv3+. The DeepLab series of networks are models specifically designed for semantic segmentation and were proposed by Liang Chieh Chen [23] and the Google team. The encoder–decoder structure used in DeepLabv3+ is innovative. The encoder is mainly responsible for encoding rich contextual information, while the concise and efficient decoder is used to recover the boundaries of the detected objects. Further, the network utilizes Atrous convolutions to achieve feature extraction at any resolution, enabling a more optimal balance between detection speed and accuracy.
- Unet. Unet is a model that was proposed by Olaf Ronneberger et al. [24] in 2015 for solving medical image segmentation problems. Unet consists of a contracting path, which serves as a feature extraction network to extract abstract features from the image, and an expansive path, which performs feature fusion operations. Compared with other segmentation models, Unet has a simple structure and larger operation space.
- PSPnet. The Pyramid Scene Parsing Network (PSPnet), proposed by Hengshuang Zhao et al. [25], is a model designed to address scene analysis problems. PSPnet is a neural network that uses the Pyramid Pooling Module to fuse features at four different scales. These pooling layers pool the original feature map, generating feature maps at various levels. Subsequently, convolution and upsampling operations are applied to restore the feature maps to their original size. By combining local and global information, PSPnet improves the reliability of final predictions.
- HRnet. The HRnet model, proposed by Ke Sun et al. [26], is composed of multiple parallel subnetworks with decreasing resolutions, which exchange information through multi-scale fusion. The depth of the network is represented horizontally, while the change in feature map (resolution) size is represented vertically. Such an approach allows for the preservation of high-resolution features throughout the process, without the need for resolution upsampling. As a result, the predicted keypoint heatmaps have a more accurate spatial distribution.
2.5. 3D Reconstruction
- First, the shooting direction of the corresponding image is determined by the position of different points on the calibration pad, and the multi-angle image obtained is calibrated.
- Second, under the conditions of two different image preprocessing methods, images with purified backgrounds were obtained, retaining only the complete information about the soybean plants.
- Third, based on the partial information about the target object from multi-angle images, several polygonal approximations of the contours were obtained. Each approximation was assigned a number, and three vertices were calculated from the polygonal contour. The information about each vertex was recorded.
- Fourth, by using a triangular grid, the complete surface was divided to outline surface details. At this point, the basic skeleton of the soybean three-dimensional plant model was generated;
- Finally, texture mapping was performed. Using the orientation information extracted from the three-dimensional surface contour model of the soybean plant and incorporating orientation details from various multi-angle images, texture mapping was employed to enhance the visualization features of the surface. The aim of such a process is to provide a more comprehensive depiction of the actual object’s characteristics.
2.6. Model Comparison
2.6.1. Point Cloud Registration
- Select at least three corresponding point pairs. Randomly choose three non-collinear data points {q1, q2, q3} from the source cloud Q, and select the corresponding point set {p1, p2, p3} from the target cloud P.
- Calculate the rotation and translation matrix H using the least squares method for these two point sets.
- Transform the source cloud Q into a new three-dimensional point cloud dataset Q′ using the transformation matrix H. Compare Q′ with P and extract all points (inliers) of which the distance deviation is less than a given threshold k to form a consistent point cloud set S1’. Record the number of inliers.
- Set a threshold K and repeat the above process. After performing the operation K times, if a consistent point cloud set cannot be obtained, the model parameter estimation fails. If a consistent point cloud set is obtained, select the one with the maximum number of inliers. The corresponding rotation and translation matrix H at this point is the optimal model parameter.
- Based on the approximate parameter values of R and t obtained from the coarse registration of the point cloud, the corresponding points are directly searched for by identifying the closest points in the two point clouds;
- The least squares method is used to construct an objective function and iteratively minimize the overall distance between the corresponding points until the termination condition is met (either the maximum number of iterations or the error is below a threshold). This ultimately allows for the rigid transformation matrix to be obtained.
- Compute the centroids of the two sets of corresponding points;
- Obtain the point sets without centroids;
- Calculate the 3 × 3 matrix H;
- Perform SVD decomposition on H;
- Calculate the optimal rotation matrix;
- Calculate the optimal translation vector.
2.6.2. Distance Calculation
2.7. Evaluation Index of Automatic Image Preprocessing and Model Effect
2.7.1. Semantic Segmentation
2.7.2. Point Cloud Registration
2.7.3. Distance between Models
2.7.4. Model Matching Accuracy
3. Results
3.1. Semantic Segmentation
3.2. Model Distance Comparison
- First, for soybean plants of the same variety, the distance between the plant models increased with the stage of growth;
- Second, for soybean plants at the same stage of growth, the distance between models of different varieties remained approximately the same;
- Third, the time required to establish soybean plant models based on segmented images was significantly shorter than the time needed for models based on manual image preprocessing;
- Such findings indicate that in image-based crop 3D reconstruction, semantic segmentation can effectively improve the difficulties and long reconstruction time associated with preprocessing images of soybean plants of different varieties at different stages, greatly enhance the robustness to noisy input and ensure the accuracy of the models.
3.3. Model Matching Accuracy
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A



References
- Guan, H.; Liu, M.; Ma, X.; Yu, S. Three-Dimensional Reconstruction of Soybean Canopies Using Multisource Imaging for Phenotyping Analysis. Remote Sens. 2018, 10, 1206. [Google Scholar] [CrossRef]
- Favre, P.; Gueritaine, G.; Andrieu, B.; Boumaza, R.; Demotes-Mainard, S.; Fournier, C.; Galopin, G.; Huche-Thelier, L.; Morel-Chevillet, P.; Guérin, V. Modelling the architectural growth and development of rosebush using L-Systems. In Proceedings of the Growth Phenotyping and Imaging in Plants, Montpellier, France, 17–19 July 2007. [Google Scholar]
- Turgut, K.; Dutagaci, H.; Galopin, G.; Rousseau, D. Segmentation of structural parts of rosebush plants with 3D point-based deep learning methods. Plant Methods 2022, 18, 20. [Google Scholar] [CrossRef]
- Zhu, R.; Sun, K.; Yan, Z.; Yan, X.; Yu, J.; Shi, J.; Hu, Z.; Jiang, H.; Xin, D.; Zhang, Z.; et al. Analysing the phenotype development of soybean plants using low-cost 3D reconstruction. Sci. Rep. 2020, 10, 7055. [Google Scholar] [CrossRef]
- Martinez-Guanter, J.; Ribeiro, Á.; Peteinatos, G.G.; Pérez-Ruiz, M.; Gerhards, R.; Bengochea-Guevara, J.M.; Machleb, J.; Andújar, D. Low-Cost Three-Dimensional Modeling of Crop Plants. Sensors 2019, 19, 2883. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, Z.; Sun, K.; Li, S.; Yu, J.; Miao, L.; Zhang, Z.; Li, Y.; Zhao, H.; Hu, Z.; et al. Soybean-MVS: Annotated Three-Dimensional Model Dataset of Whole Growth Period Soybeans for 3D Plant Organ Segmentation. Agriculture 2023, 13, 1321. [Google Scholar] [CrossRef]
- Xiao, B.; Wu, S.; Guo, X.; Wen, W. A 3D Canopy Reconstruction and Phenotype Analysis Method for Wheat. In Proceedings of the 11th International Conference on Computer and Computing Technologies in Agriculture (CCTA), Jilin, China, 12–15 August 2017; pp. 244–252. [Google Scholar]
- Bietresato, M.; Carabin, G.; Vidoni, R.; Gasparetto, A.; Mazzetto, F. Evaluation of a LiDAR-based 3D-stereoscopic vision system for crop-monitoring applications. Comput. Electron. Agric. 2016, 124, 1–13. [Google Scholar] [CrossRef]
- Wu, J.; Xue, X.; Zhang, S.; Qin, W.; Chen, C.; Sun, T. Plant 3D reconstruction based on LiDAR and multi-view sequence images. Int. J. Precis. Agric. Aviat. 2018, 1, 37–43. [Google Scholar] [CrossRef]
- Pan, Y.; Han, Y.; Wang, L.; Chen, J.; Meng, H.; Wang, G.; Zhang, Z.; Wang, S. 3d reconstruction of ground crops based on airborne lidar technology—Sciencedirect. IFAC-PapersOnLine 2019, 52, 35–40. [Google Scholar] [CrossRef]
- Wu, S.; Wen, W.; Wang, Y.; Fan, J.; Wang, C.; Gou, W.; Guo, X. MVS-Pheno: A Portable and Low-Cost Phenotyping Platform for Maize Shoots Using Multiview Stereo 3D Reconstruction. Plant Phenomics 2020, 2020, 1848437. [Google Scholar] [CrossRef]
- Li, Y.; Liu, J.; Zhang, B.; Wang, Y.; Yao, J.; Zhang, X.; Fan, B.; Li, X.; Hai, Y.; Fan, X. Three-dimensional reconstruction and phenotype measurement of maize seedlings based on multi-view image sequences. Front Plant Sci. 2022, 13, 974339. [Google Scholar] [CrossRef]
- Song, P.; Li, Z.; Yang, M.; Shao, Y.; Pu, Z.; Yang, W.; Zhai, R. Dynamic detection of three-dimensional crop phenotypes based on a consumer-grade RGB-D camera. Front Plant Sci. 2023, 14, 1097725. [Google Scholar] [CrossRef]
- Zhu, T.; Ma, X.; Guan, H.; Wu, X.; Wang, F.; Yang, C.; Jiang, Q. A calculation method of phenotypic traits based on three-dimensional reconstruction of tomato canopy. Comput. Electron. Agric. 2023, 204, 107515. [Google Scholar] [CrossRef]
- Liu, Y.; Yuan, H.; Zhao, X.; Fan, C.; Cheng, M. Fast reconstruction method of three-dimension model based on dual RGB-D cameras for peanut plant. Plant Methods 2023, 19, 17. [Google Scholar] [CrossRef]
- Minh, T.N.; Sinn, M.; Lam, H.T.; Wistuba, M. Automated image data preprocessing with deep reinforcement learning. arXiv 2018, arXiv:1806.05886. [Google Scholar]
- Chang, S.G.; Yu, B. Adaptive wavelet thresholding for image denoising and compression. IEEE Trans. Image Process. 2000, 9, 1532. [Google Scholar] [CrossRef]
- Smith, A.R.; Blinn, J.F. Blue screen matting. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; Association for Computing Machinery: New York, NY, USA, 1996; pp. 259–268. [Google Scholar]
- DeepLabv3+. Available online: https://github.com/18545155636/Deeplabv3.git (accessed on 4 August 2023).
- Unet. Available online: https://github.com/18545155636/Unet.git (accessed on 4 August 2023).
- PSPnet. Available online: https://github.com/18545155636/PSPnet.git (accessed on 4 August 2023).
- HRnet. Available online: https://github.com/18545155636/HRnet.git (accessed on 4 August 2023).
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision–ECCV 2018, Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5686–5696. [Google Scholar]
- Baumberg, A.; Lyons, A.; Taylor, R. 3d s.o.m.—A commercial software solution to 3d scanning. Graph. Models 2005, 67, 476–495. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Chen, C.S.; Hung, Y.P.; Cheng, J.B. Ransac-based darces: A new approach to fast automatic registration of partially overlapping range images. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 21, 1229–1234. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. A Method for Registration of 3-D Shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Attari, H.; Ghafari-Beranghar, A. An Efficient Preprocessing Algorithm for Image-based Plant Phenotyping. Preprints 2018, 20180402092018. [Google Scholar] [CrossRef]
- Rzanny, M.; Seeland, M.; Waldchen, J.; Mader, P. Acquiring and preprocessing leaf images for automated plant identification: Understanding the tradeoff between effort and information gain. Plant Methods 2017, 13, 97. [Google Scholar] [CrossRef]
- Milioto, A.; Lottes, P.; Stachniss, C. Real-time Semantic Segmentation of Crop and Weed for Precision Agriculture Robots Leveraging Background Knowledge in CNNs. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 2229–2235. [Google Scholar]
- Wang, X.-B.; Liu, Z.-X.; Yang, C.-Y.; Xu, R.; Lu, W.-G.; Zhang, L.-F.; Wang, Q.; Wei, S.-H.; Yang, C.-M.; Wang, H.-C.; et al. Stability of growth periods traits for soybean cultivars across multiple locations. J. Integr. Agric. 2016, 15, 963–972. [Google Scholar] [CrossRef]
- Schapaugh, W.T. Variety Selection. In Soybean Production Handbook; Publication C449; K-State Research and Extension: Manhattan, KS, USA, 2016. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| mIoU | mPA | mPrecision | mRecall | |
|---|---|---|---|---|
| DeepLabv3+ | 0.9887 | 0.9948 | 0.9938 | 0.9948 |
| Unet | 0.9919 | 0.9953 | 0.9965 | 0.9953 |
| PSPnet | 0.9624 | 0.9794 | 0.9819 | 0.9794 |
| HRnet | 0.9883 | 0.9943 | 0.9939 | 0.9943 |
| Variety | Period | RMS (Align) | RMS (Fine Registration) |
|---|---|---|---|
| DN251 | V1 | 1.95626 | 1.19971 |
| V2 | 2.09126 | 1.35077 | |
| V3 | 4.58306 | 2.58519 | |
| V4 | 4.46901 | 2.65409 | |
| V5 | 3.18775 | 2.87697 | |
| DN252 | V1 | 2.63826 | 1.48934 |
| V2 | 7.80912 | 3.23065 | |
| V3 | 1.80913 | 2.89284 | |
| V4 | 1.69937 | 5.33 | |
| V5 | 6.16305 | 13.713 | |
| DN253 | V1 | 0.738292 | 1.02404 |
| V2 | 1.27929 | 1.06568 | |
| V3 | 1.6837 | 2.40657 | |
| V4 | 1.91016 | 3.61526 | |
| V5 | 5.73199 | 4.7968 | |
| HN48 | V1 | 1.26657 | 0.909976 |
| V2 | 1.4727 | 1.18007 | |
| V3 | 1.04926 | 1.63755 | |
| V4 | 0.0957965 | 4.35126 | |
| V5 | 6.02313 | 11.6697 | |
| HN51 | V1 | 1.30144 | 0.569594 |
| V2 | 2.33492 | 0.940522 | |
| V3 | 0.529973 | 1.44398 | |
| V4 | 1.44441 | 1.85106 | |
| V5 | 2.88033 | 5.97911 |
| Variety | Period | Cloud/Cloud Dist. | Cloud/Mesh Dist. | ||
|---|---|---|---|---|---|
| Mean Dist. | Std Deviation | Mean Dist. | Std Deviation | ||
| DN251 | V1 | 1.145612 | 0.900235 | 1.130519 | 0.911150 |
| V2 | 1.158162 | 1.030425 | 1.076919 | 1.069205 | |
| V3 | 2.262815 | 1.887179 | 2.183569 | 1.938041 | |
| V4 | 2.088518 | 1.881370 | 2.000282 | 1.930785 | |
| V5 | 1.998276 | 1.548111 | 1.836738 | 1.619279 | |
| DN252 | V1 | 1.026802 | 0.780924 | 0.966741 | 0.809431 |
| V2 | 2.971597 | 2.662797 | 2.926895 | 2.695811 | |
| V3 | 2.404866 | 2.627851 | 2.391443 | 2.635576 | |
| V4 | 4.052322 | 4.064967 | 3.960502 | 4.120001 | |
| V5 | 11.601336 | 11.490972 | 11.523714 | 11.549747 | |
| DN253 | V1 | 0.674987 | 0.562897 | 0.649014 | 0.576336 |
| V2 | 1.034015 | 0.763250 | 0.952814 | 0.804699 | |
| V3 | 1.903690 | 1.582029 | 1.831233 | 1.623182 | |
| V4 | 2.693205 | 2.117353 | 2.610196 | 2.164421 | |
| V5 | 3.555374 | 4.216107 | 3.449008 | 4.265732 | |
| HN48 | V1 | 0.776107 | 0.563027 | 0.756657 | 0.575204 |
| V2 | 1.033295 | 0.750766 | 0.959216 | 0.783948 | |
| V3 | 1.223996 | 0.939598 | 1.175414 | 0.966041 | |
| V4 | 3.412442 | 3.460865 | 3.362041 | 3.494898 | |
| V5 | 7.974715 | 8.950619 | 7.871541 | 9.018435 | |
| HN51 | V1 | 0.493069 | 0.353827 | 0.468149 | 0.365837 |
| V2 | 0.765773 | 0.473434 | 0.697317 | 0.506449 | |
| V3 | 1.233639 | 0.917520 | 1.170139 | 0.948327 | |
| V4 | 1.647804 | 1.188333 | 1.571436 | 1.227389 | |
| V5 | 4.725530 | 4.344229 | 4.691150 | 4.369667 | |
| V1 | V2 | V3 | V4 | V5 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Cloud/Cloud | Cloud/Mesh | Cloud/Cloud | Cloud/Mesh | Cloud/Cloud | Cloud/Mesh | Cloud/Cloud | Cloud/Mesh | Cloud/Cloud | Cloud/Mesh | |
| DN251 | 0.7525 | 0.7516 | 0.8574 | 0.8564 | 0.6908 | 0.6894 | 0.7745 | 0.7750 | 0.8654 | 0.8659 |
| DN252 | 0.7771 | 0.7804 | 0.6658 | 0.6620 | 0.8445 | 0.8441 | 0.8396 | 0.8387 | 0.6958 | 0.6951 |
| DN253 | 0.8754 | 0.8741 | 0.6842 | 0.6893 | 0.8438 | 0.8417 | 0.7312 | 0.7336 | 0.8736 | 0.8734 |
| HN48 | 0.5698 | 0.5747 | 0.6173 | 0.6222 | 0.6751 | 0.6808 | 0.7967 | 0.7960 | 0.8303 | 0.8298 |
| HN51 | 0.6710 | 0.6793 | 0.6112 | 0.6285 | 0.6933 | 0.6988 | 0.6467 | 0.6553 | 0.7423 | 0.7414 |
| V1 | V2 | V3 | V4 | V5 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Cloud/Cloud | Cloud/Mesh | Cloud/Cloud | Cloud/Mesh | Cloud/Cloud | Cloud/Mesh | Cloud/Cloud | Cloud/Mesh | Cloud/Cloud | Cloud/Mesh | |
| DN251 | 0.9082 | 0.9079 | 0.9295 | 0.9293 | 0.8369 | 0.8360 | 0.8985 | 0.8980 | 0.9513 | 0.9512 |
| DN252 | 0.9202 | 0.9215 | 0.8262 | 0.8264 | 0.9311 | 0.9311 | 0.9348 | 0.9341 | 0.7918 | 0.7915 |
| DN253 | 0.9587 | 0.9584 | 0.8257 | 0.8218 | 0.9471 | 0.9463 | 0.8941 | 0.8947 | 0.9196 | 0.9196 |
| HN48 | 0.7526 | 0.7534 | 0.7865 | 0.7871 | 0.8434 | 0.8454 | 0.9093 | 0.9090 | 0.8972 | 0.8969 |
| HN51 | 0.8543 | 0.8584 | 0.8241 | 0.8274 | 0.8624 | 0.8645 | 0.8376 | 0.8400 | 0.8503 | 0.8498 |
| V1 | V2 | V3 | V4 | V5 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Cloud/Cloud | Cloud/Mesh | Cloud/Cloud | Cloud/Mesh | Cloud/Cloud | Cloud/Mesh | Cloud/Cloud | Cloud/Mesh | Cloud/Cloud | Cloud/Mesh | |
| DN251 | 0.9767 | 0.9767 | 0.9679 | 0.9679 | 0.9241 | 0.9225 | 0.9510 | 0.9508 | 0.9811 | 0.9812 |
| DN252 | 0.9680 | 0.9681 | 0.8912 | 0.8906 | 0.9667 | 0.9667 | 0.9665 | 0.9661 | 0.8736 | 0.8736 |
| DN253 | 0.9853 | 0.9852 | 0.9189 | 0.9132 | 0.9847 | 0.9843 | 0.9529 | 0.9534 | 0.9388 | 0.9385 |
| HN48 | 0.8754 | 0.8760 | 0.8886 | 0.8886 | 0.9273 | 0.9283 | 0.9544 | 0.9541 | 0.9331 | 0.9330 |
| HN51 | 0.9485 | 0.9503 | 0.9407 | 0.9389 | 0.9334 | 0.9342 | 0.9332 | 0.9338 | 0.9219 | 0.9218 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Miao, L.; Zhao, Z.; Pan, T.; Wang, X.; Guo, Y.; Xin, D.; Chen, Q.; Zhu, R. An Efficient and Automated Image Preprocessing Using Semantic Segmentation for Improving the 3D Reconstruction of Soybean Plants at the Vegetative Stage. Agronomy 2023, 13, 2388. https://doi.org/10.3390/agronomy13092388
Sun Y, Miao L, Zhao Z, Pan T, Wang X, Guo Y, Xin D, Chen Q, Zhu R. An Efficient and Automated Image Preprocessing Using Semantic Segmentation for Improving the 3D Reconstruction of Soybean Plants at the Vegetative Stage. Agronomy. 2023; 13(9):2388. https://doi.org/10.3390/agronomy13092388
Chicago/Turabian StyleSun, Yongzhe, Linxiao Miao, Ziming Zhao, Tong Pan, Xueying Wang, Yixin Guo, Dawei Xin, Qingshan Chen, and Rongsheng Zhu. 2023. "An Efficient and Automated Image Preprocessing Using Semantic Segmentation for Improving the 3D Reconstruction of Soybean Plants at the Vegetative Stage" Agronomy 13, no. 9: 2388. https://doi.org/10.3390/agronomy13092388
APA StyleSun, Y., Miao, L., Zhao, Z., Pan, T., Wang, X., Guo, Y., Xin, D., Chen, Q., & Zhu, R. (2023). An Efficient and Automated Image Preprocessing Using Semantic Segmentation for Improving the 3D Reconstruction of Soybean Plants at the Vegetative Stage. Agronomy, 13(9), 2388. https://doi.org/10.3390/agronomy13092388