Garlic Crops’ Mapping and Change Analysis in the Erhai Lake Basin Based on Google Earth Engine


Abstract
:1. Introduction
2. Materials and Methods
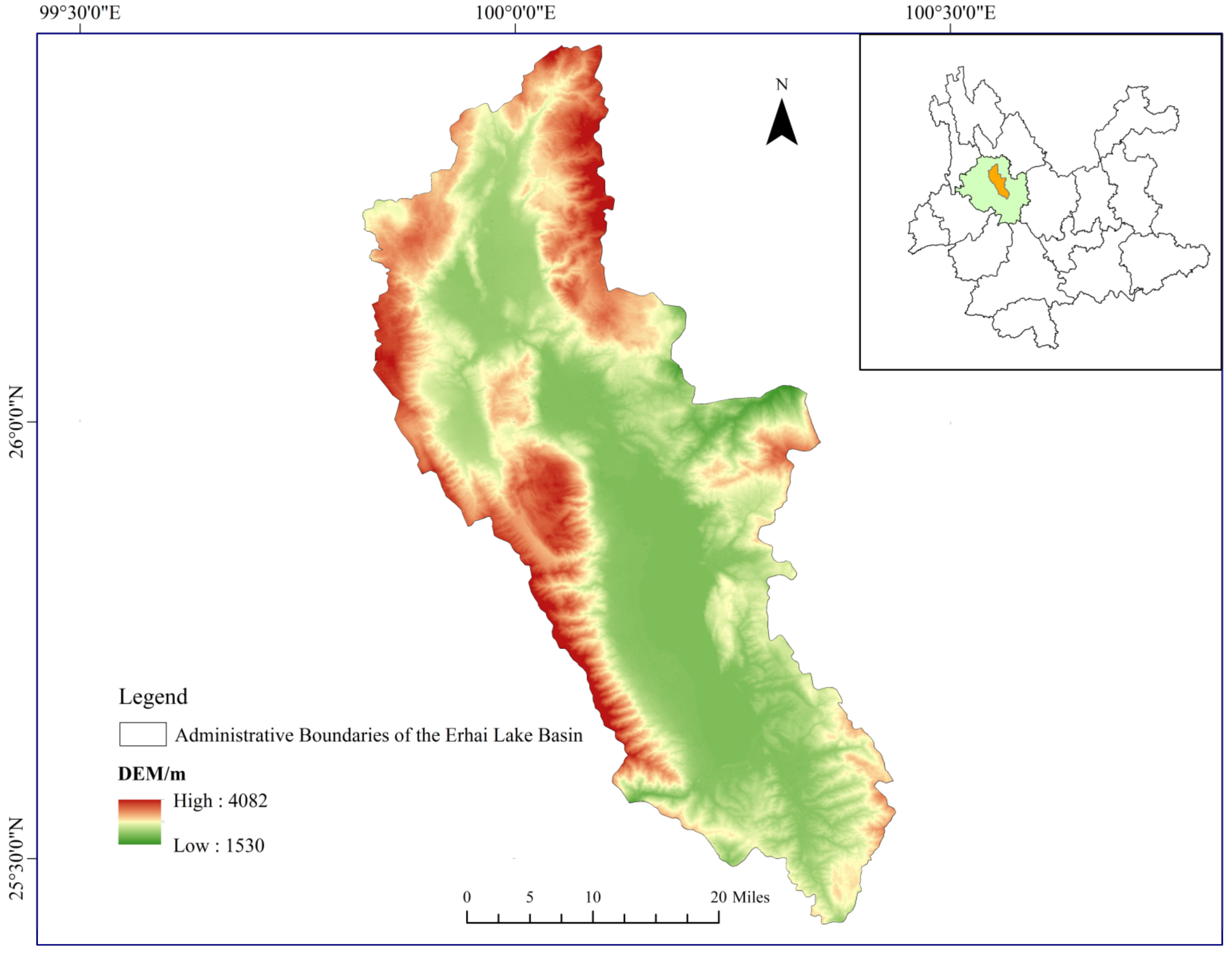
2.1. Study Area
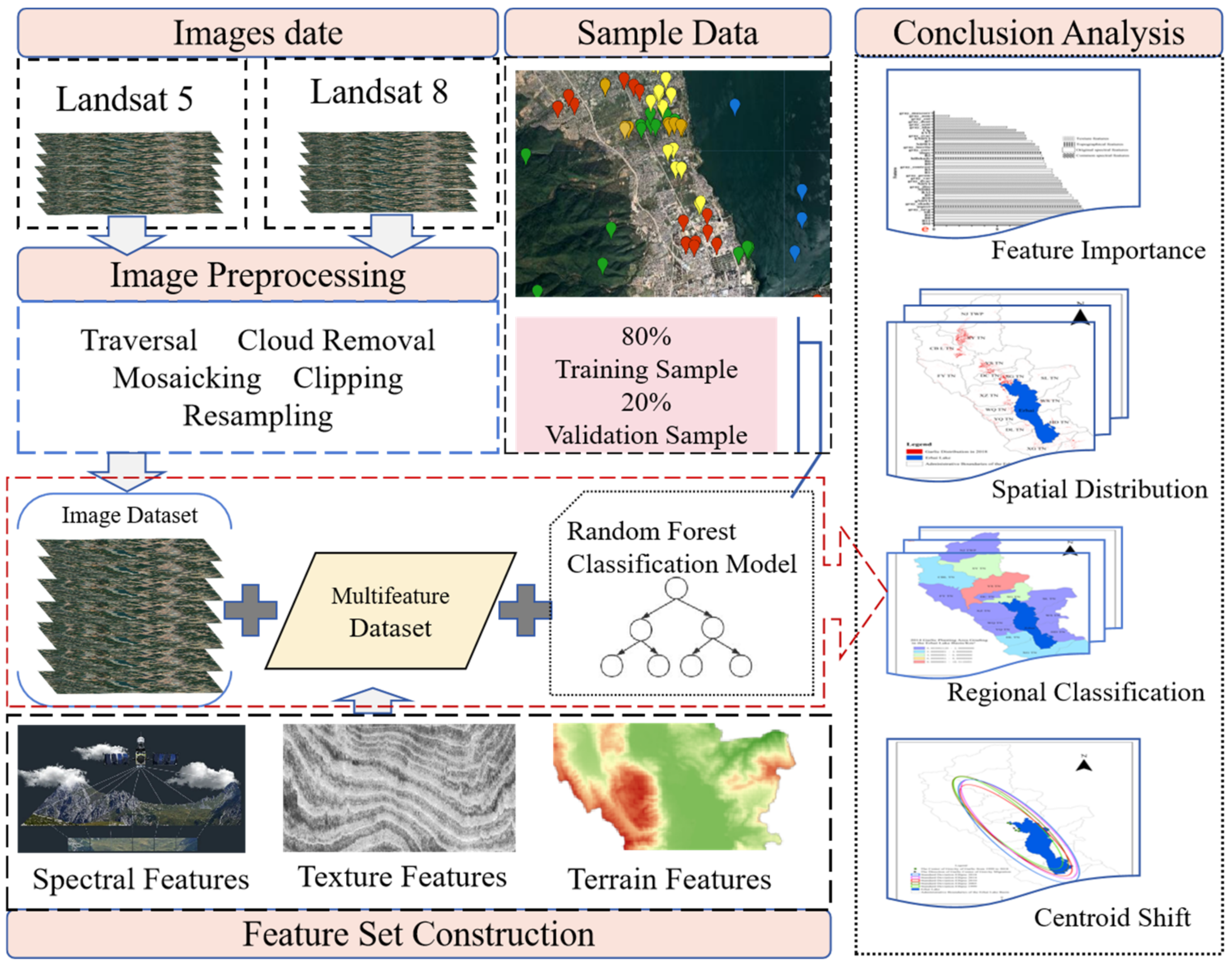
2.2. Methods
2.3. Data Acquisition and Preprocessing
2.3.1. Image Data
2.3.2. DEM Data
2.3.3. Sample Data
2.4. Feature Extraction
2.4.1. Feature Set Construction
2.4.2. Gray-Level Co-Occurrence Matrix (GLCM) Algorithm
2.4.3. Random Forest Algorithm and Feature Selection
2.4.4. Accuracy Assessment
3. Results and Analysis
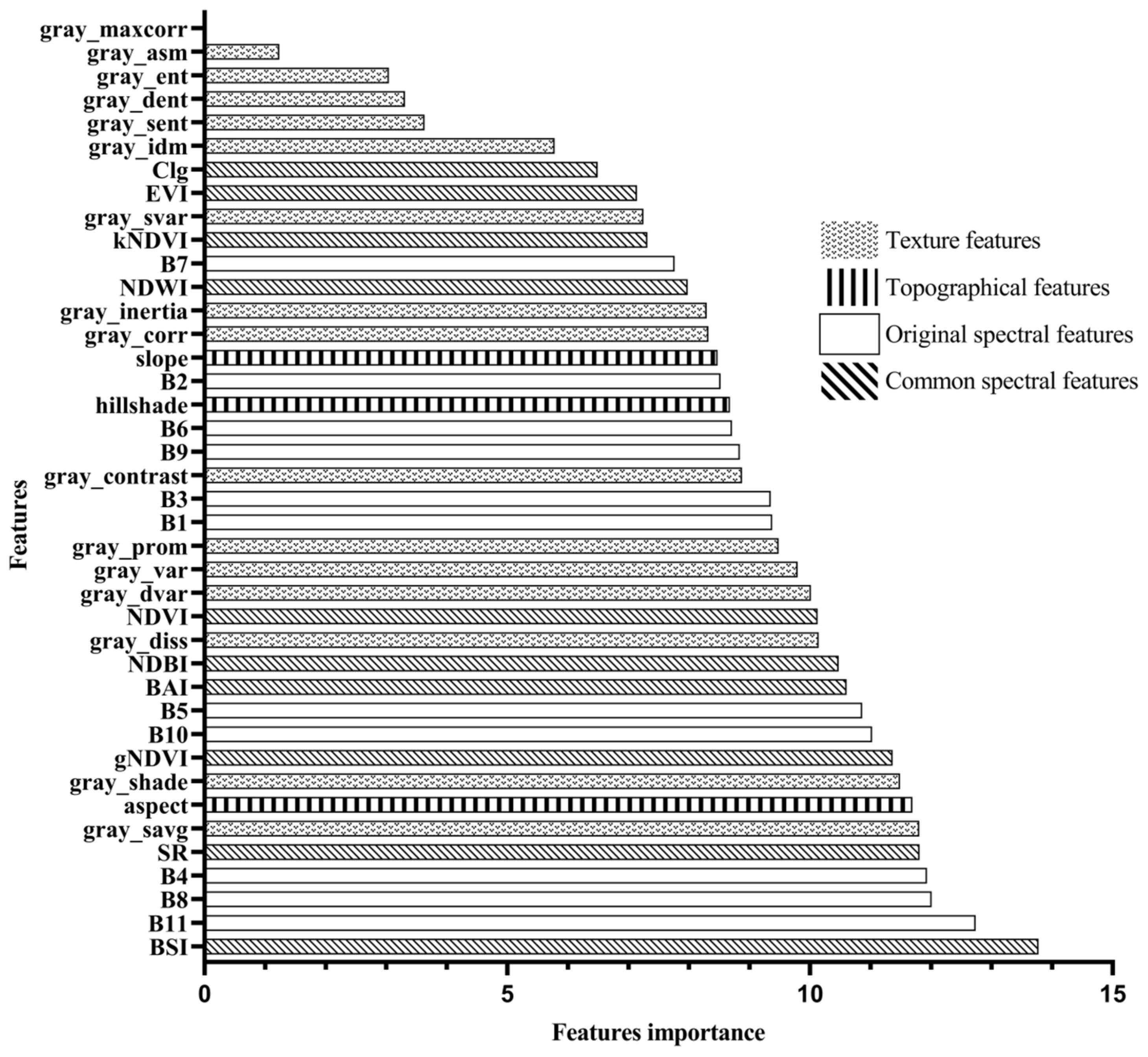
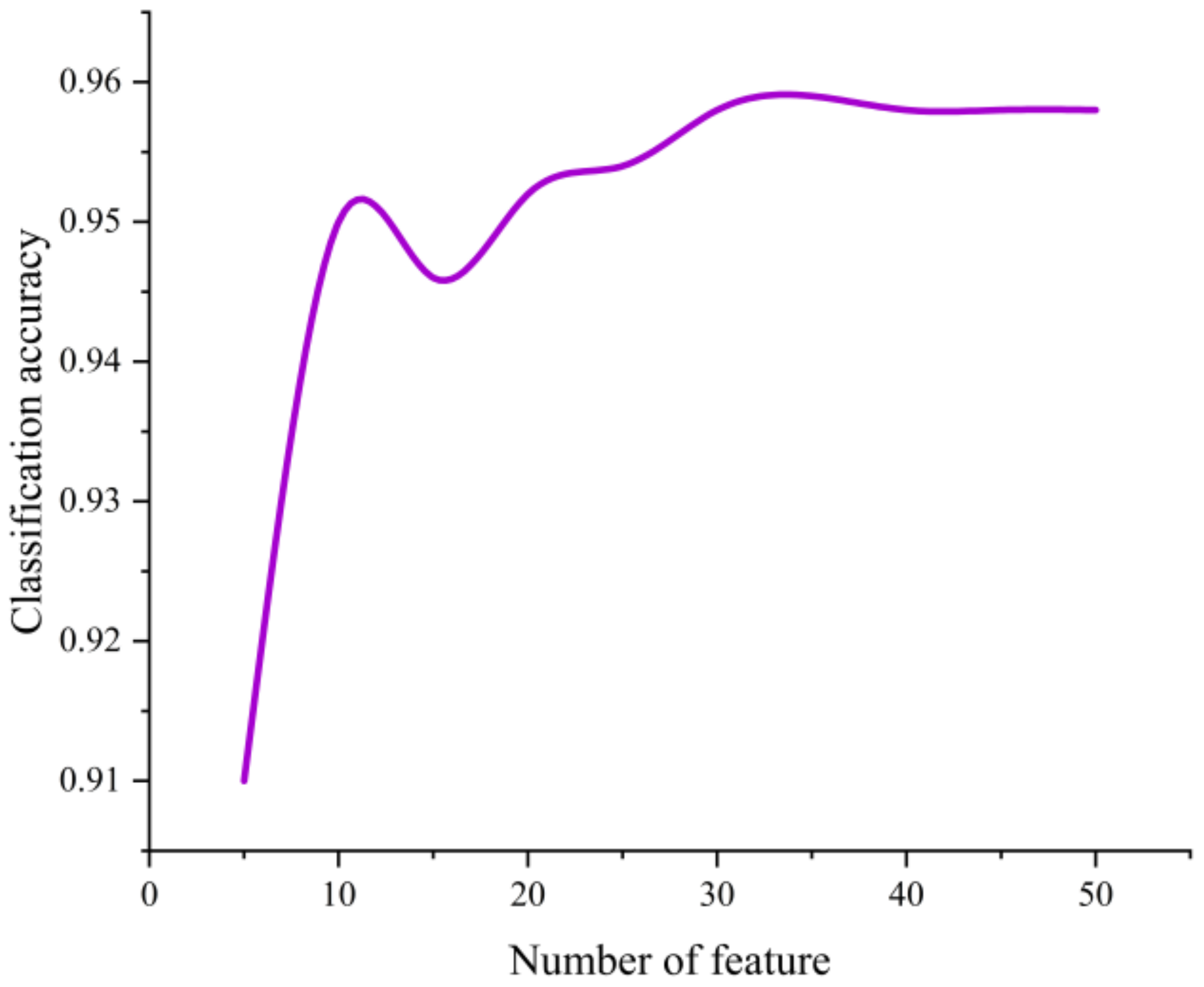
3.1. Feature Selection Analysis
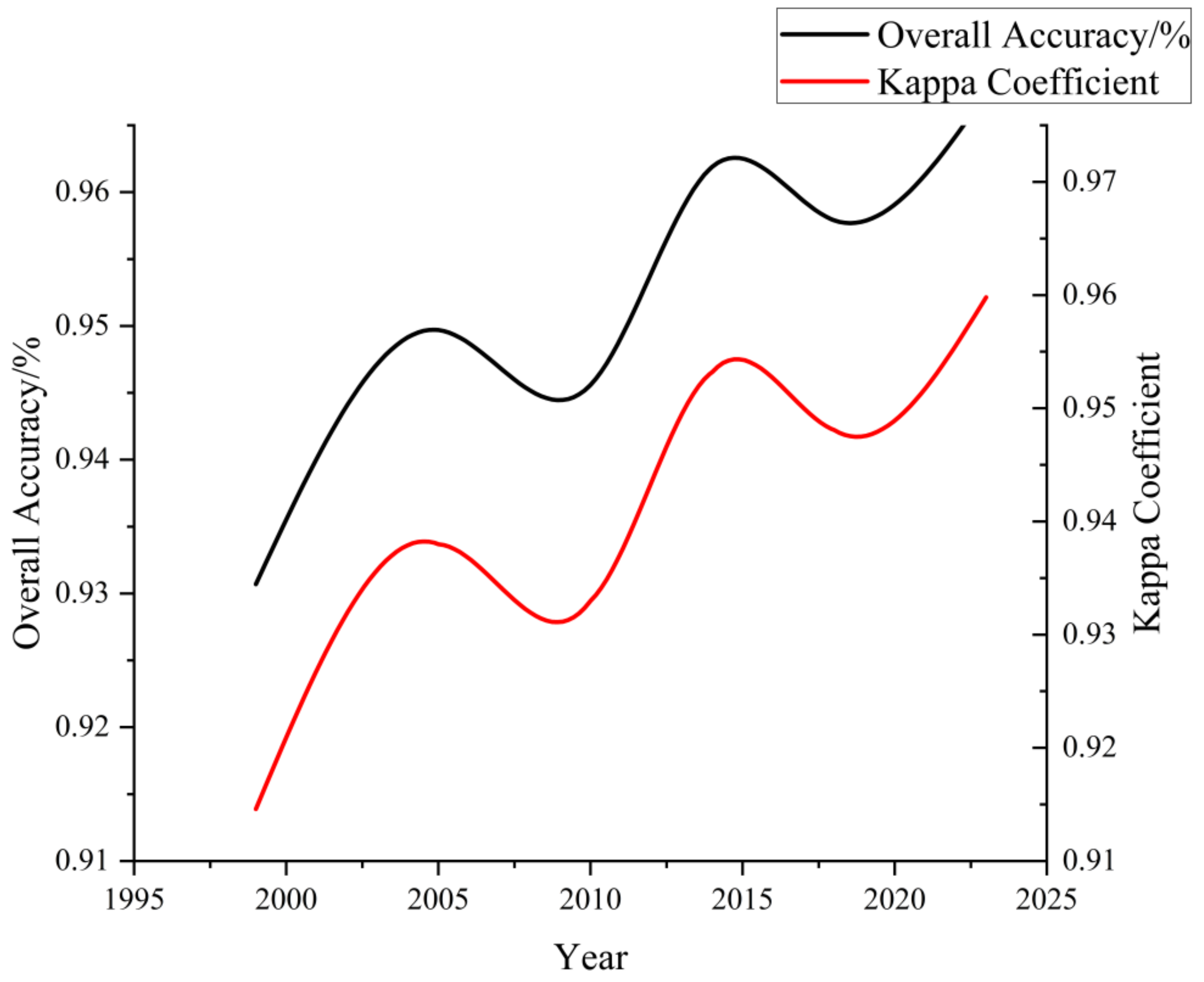
3.2. Accuracy Analysis
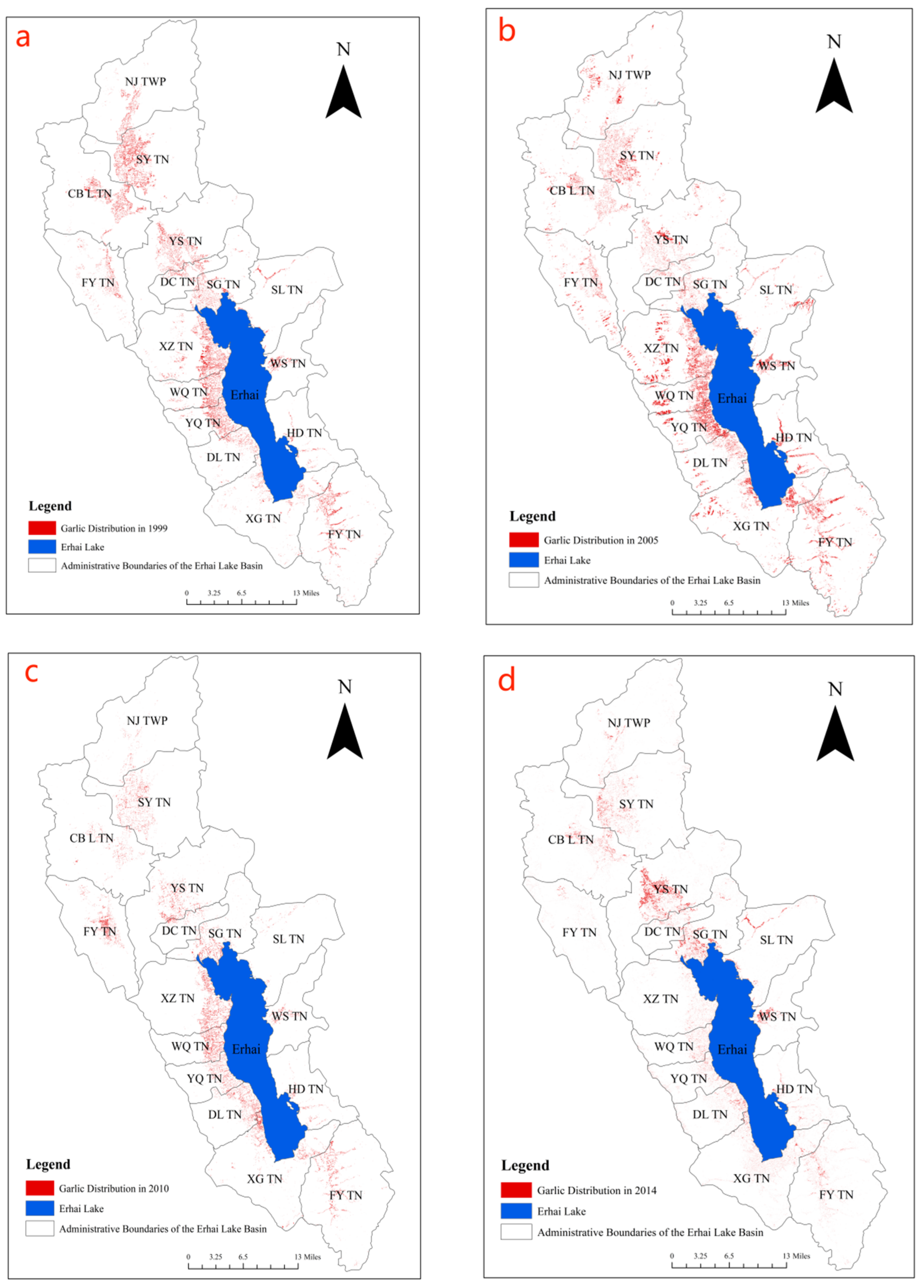
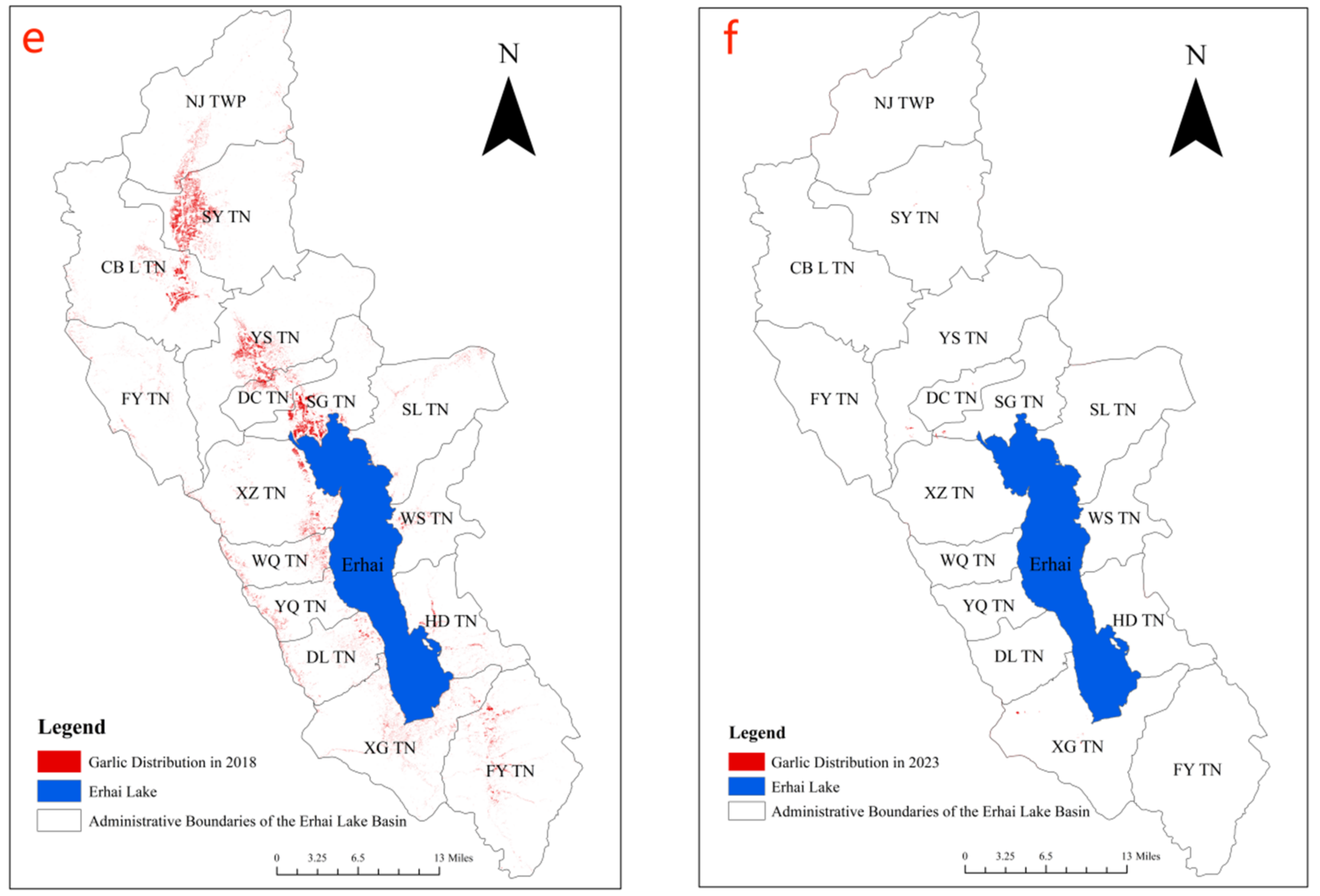
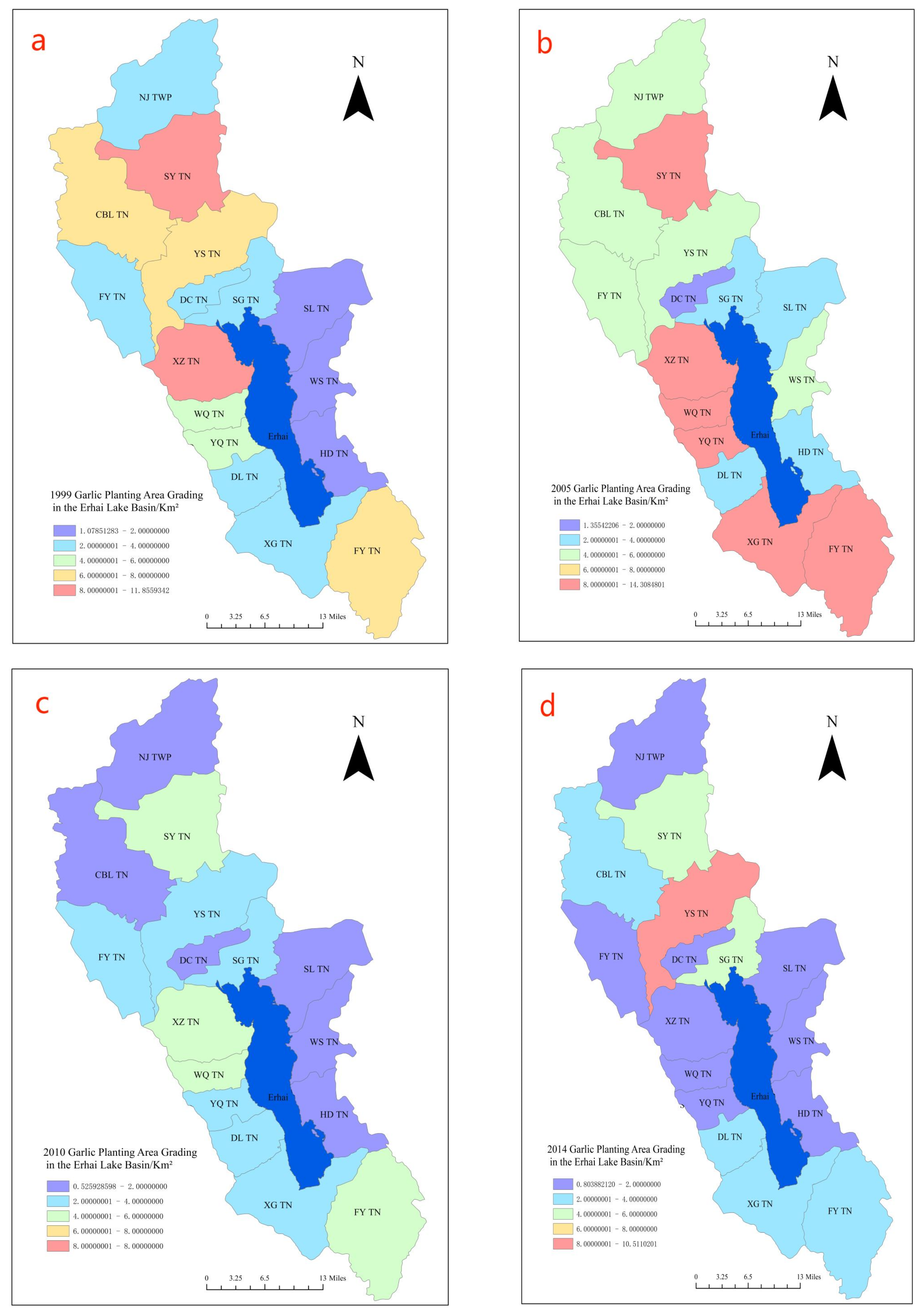
3.3. Classification Analysis
4. Discussion
5. Conclusions
- (1)
- In the land-use classification of the Erhai Lake Basin, the random forest algorithm selected feature bands with the following importance ranking: spectral features > vegetation features > texture features > terrain features. Through feature selection analysis, the number of features was reduced from 40 to 35. Having too many features can burden the model, making it prone to overfitting and decreasing the accuracy.
- (2)
- The random forest method based on feature selection achieved high accuracy in the land-use classification in the Erhai Lake Basin, Yunnan Province. The overall classification accuracy reached 95.79%, with a Kappa coefficient of 0.95. Specifically, the garlic mapping accuracy reached 99.16%, and the user accuracy reached 96.71%. The land-use classification accuracy from 1999 to 2018 consistently exceeded 93%, meeting the good classification standard.
- (3)
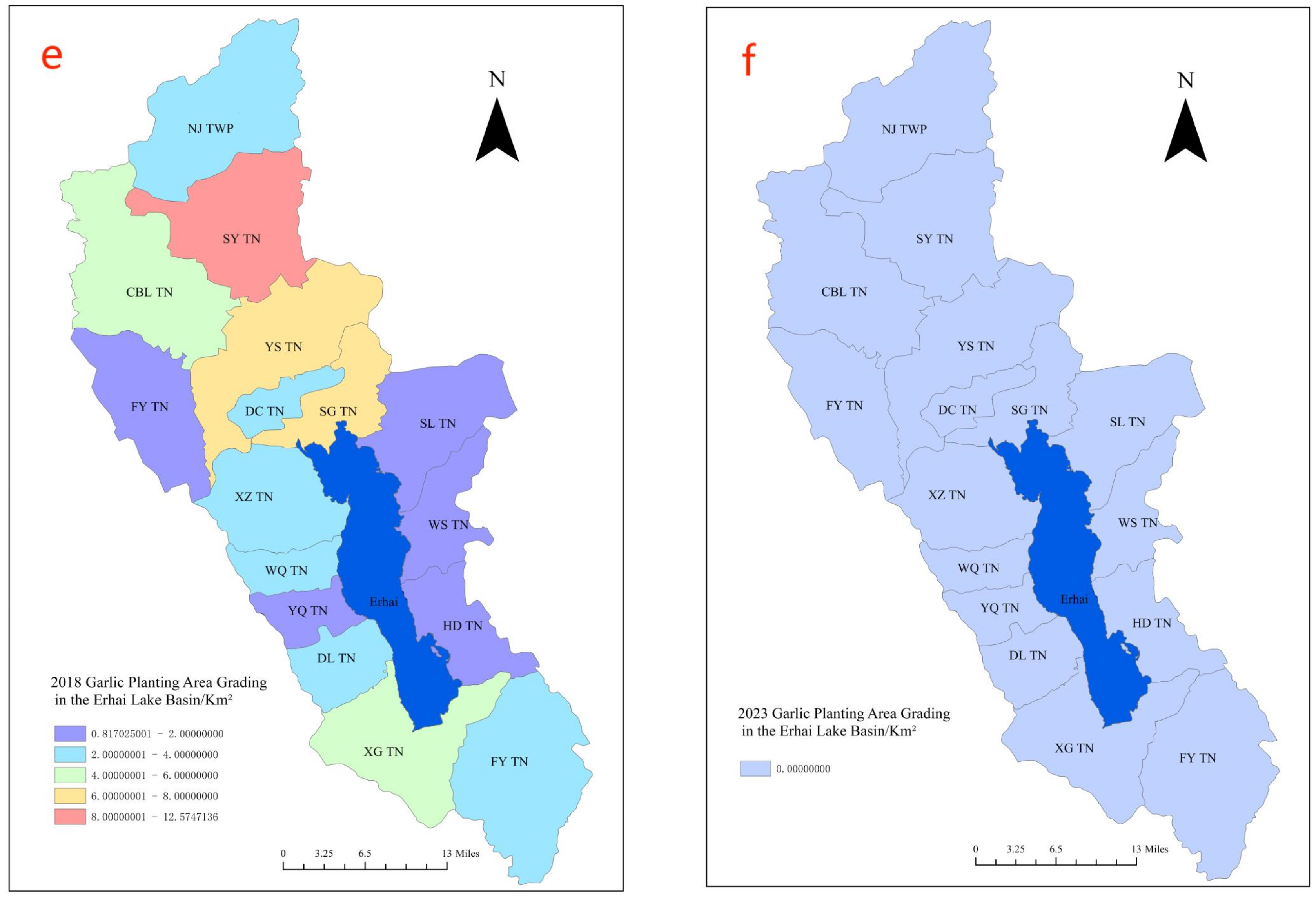
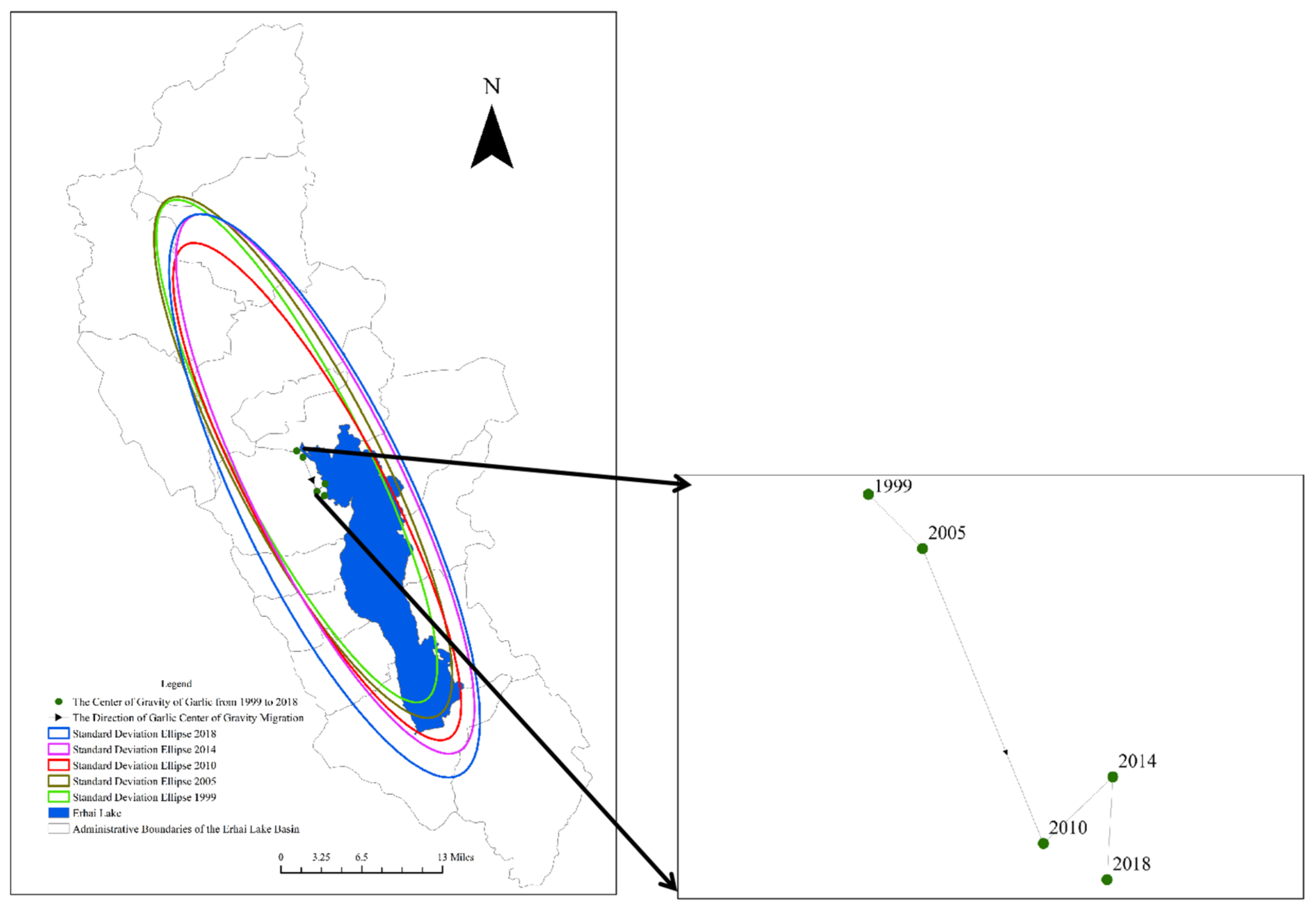
- The expansion directionality of the garlic cultivation in the Erhai Lake Basin increased first and then decreased from 1999 to 2018. From 2005 to 2018, garlic cultivation showed a saturation trend in the longitudinal direction, slowly exhibiting a trend of lateral development. Over the past 20 years, the center of garlic cultivation has gradually shifted in the southeast direction, and garlic cultivation in various towns in the Erhai Lake Basin has gradually shifted from a relatively even distribution to a concentration in the upstream region of the Erhai Lake Basin.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Weiss, M.; Jacob, F.; Duveiller, G. Remote sensing for agricultural applications: A meta-review. Remote Sens. Environ. 2020, 236, 111402. [Google Scholar] [CrossRef]
- Pan, H.; Chen, Z.; Ren, J.; Li, H.; Wu, S. Modeling winter wheat leaf area index and canopy water content with three different approaches using Sentinel-2 multispectral instrument data. IEEE J. Stars 2018, 12, 482–492. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Z.; Ren, T.W.; Liu, D.; Ma, Z.; Tong, L.; Zhang, C.; Zhou, T.; Zhang, X.; Li, S. Identification of seed maize fields with high spatial resolution and multiple spectral remote sensing using random forest classifier. Remote Sens. 2020, 12, 362. [Google Scholar] [CrossRef]
- Zhao, Y.Y.; Feng, D.L.; Jayaraman, D.; Belay, D.; Sebrala, H.; Ngugi, J.; Maina, E.; Akombo, R.; Otuoma, J.; Mutyaba, J.; et al. Bamboo mapping of Ethiopia, Kenya and Uganda for the year 2016 using multi-temporal Landsat imagery. Int. J. Appl. Earth Obs. Geoinf. 2018, 66, 116–125. [Google Scholar] [CrossRef]
- Li, F.; Ren, J.; Wu, S.; Zhang, N.; Zhao, H. Effects of NDVI time series similarity on the mapping accuracy controlled by the total planting area of winter wheat. Trans. Chin. Soc. Agric. Eng. 2021, 37, 127–239. [Google Scholar]
- Qiu, B.; Li, W.; Tang, Z.; Chen, C.; Qi, W. Mapping paddy rice areas based on vegetation phenology and surface moisture conditions. Ecol. Indic. 2015, 56, 79–86. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Liao, A.P.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global land cover map-ping at 30 m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- Wessel, M.; Brandmeier, M.; Tiede, D. Evaluation of different machine learning algorithms for scalable classification of tree types and tree species based on Sentinel-2 Data. Remote Sens. 2018, 10, 1419. [Google Scholar] [CrossRef]
- Varin, M.; Chalghaf, B.; Joanisse, G. Object-based approach using very high spatial resolution 16-band Worldview-3 and LIDAR data for tree species classification in a broadleaf forest in Quebec, Canada. Remote Sens. 2020, 12, 3092. [Google Scholar] [CrossRef]
- Dong, J.; Xiao, X.; Menarguez, M.A.; Zhang, G.; Qin, Y.; Thau, D.; Biradar, C.; Moore, B., III. Mapping paddy rice planting area in northeastern Asia with Landsat 8 images, phenology-based algorithm and Google Earth Engine. Remote Sens. Environ. 2016, 185, 142–154. [Google Scholar] [CrossRef]
- Heng, Y.; Yu, L.; Cracknell, A.P.; Gong, P. Oil palm mapping using Landsat and PALSAR: A case study in Malaysia. Int. J. Remote Sens. 2016, 37, 5431–5442. [Google Scholar]
- Xu, W.Y.; Sun, R.; Jin, Z.F. Extracting tea plantations based on ZY- 3 satellite data. Trans. Chin. Soc. Agric. Eng. 2016, 32, 161–168. [Google Scholar]
- Ma, Z.; Xue, H.; Liu, C. Identification of garlic based on active and passive remote sensing data and object-oriented technology. Trans. Chin. Soc. Agric. Eng. 2022, 38, 210–222. [Google Scholar]
- You, H.T.; Huang, Y.W.; Qin, Z.G.; Chen, J.; Liu, Y. Forest Tree Species Classification based on Sentinel-2 images and auxiliary data. Forests 2022, 13, 1416. [Google Scholar] [CrossRef]
- Tassi, A.; Vizzari, M. Object-orientied LULC classification in Google earth engine combining SNIC, GLCM, and machine learning algorithms. Remote Sens. 2020, 12, 3776. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Stromann, O.; Nascetti, A.; Yousif, O.; Ban, Y. Di-mensionality reduction and feature selection for object-based land cover classification based on Sentinel-1 and Sentinel-2 time series using Google Earth Engine. Romote Sens. 2019, 12, 76. [Google Scholar] [CrossRef]
- Mitzer, M.; Atzberger, C.; Koukal, T. Treespecies classification with random forest using very high spatial resolution 8—Band World View—2 satellite data. Remote Sens. 2012, 4, 2661–2693. [Google Scholar] [CrossRef]
- Kolluru, V.; John, R.; Saraf, S.; Chen, J.; Hankerson, B.; Robinson, S.; Kussainova, M.; Jain, K. Gridded livestock density database and spatial trends for Kazakhstan. Sci. Data 2023, 10, 839. [Google Scholar] [CrossRef]
- Wang, J.Y.; Liu, Y.S. The changes of grain output center of gravity and its driving forces in China since 1990 to 2005. Resour. Sci. 2009, 31, 1188–1194. (In Chinese) [Google Scholar]
- Xiao, O.; Xiang, Z. Spatiotemporal Dynamics of Urban Land Expansion in Chinese Urban Agglomerations. Acta Geogr. Sin. 2020, 75, 571–588. [Google Scholar]
- Wu, S.; Lu, H.; Guan, H.; Chen, Y.; Qiao, D.; Deng, L. Optimal bands combination selection for extracting garlic planting area with multi-temporal sentinel-2 imagery. Sensors 2021, 21, 5556. [Google Scholar] [CrossRef] [PubMed]
- Mukhibah, D.; Imas, S.S. Classification of Garlic Land Based on Growth Phase using Convolutional Neural Network. Int. J. Adv. Comput. Sci. Appl. 2023, 14, 945–951. [Google Scholar] [CrossRef]
- Sitanggang, I.S.; Rahmani, I.A.; Caesarendra, W.; Agmalaro, M.A.; Annisa, A.; Sobir, S. Garlic Field Classification Using Machine Learning and Statistic Approaches. AgriEngineering 2023, 5, 631–645. [Google Scholar] [CrossRef]
- Tian, H.; Pei, J.; Huang, J.; Li, X.; Wang, J.; Zhou, B.; Qin, Y.; Wang, L. Garlic and winter wheat identification based on active and passive satellite imagery and the google earth engine in northern China. Remote Sens. 2020, 12, 3539. [Google Scholar] [CrossRef]
- Liu, Y.; Xiao, D.; Yang, W. An algorithm for early rice area mapping from satellite remote sensing data in southwestern Guangdong in China based on feature optimization and random Forest. Ecol. Inform. 2022, 72, 101853. [Google Scholar] [CrossRef]
- He, Y.; Huang, C.; Li, H.; Liu, Q.S.; Liu, G.H.; Zhou, Z.C.; Zhang, C.C. Land-cover classification of random forest based on Sentinel-2A image feature optimization. Resour. Sci. 2019, 41, 992–1001. [Google Scholar] [CrossRef]
- Zhang, Y.Q.; Ren, H.R. Remote sensing extraction of paddy rice in Northeast China from GF-6 images by combining feature optimization and random forest. Natl. Remote Sens. Bull. 2023, 27, 2153–2164. [Google Scholar] [CrossRef]
- Xie, Z.L.; Chen, Y.L.; Lu, D.S.; Li, G.; Chen, E. Classification of land cover, forest, and tree species classes with ZiYuan-3 multispectral and stereo data. Remote Sens. 2019, 11, 164. [Google Scholar] [CrossRef]
- Zhang, H.X.; Wangy, J.; Shang, J.L.; Liu, M.; Li, Q. Investigating the impact of classification features and classifiers on crop mapping performance in heterogeneous agricultural landscapes. Int. J. Appl. Earth Obs. Geo Inf. 2021, 102, 102388. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Campos-Taberner, M.; Moreno-Martínez, Á.; Walther, S.; Duveiller, G.; Cescatti, A.; Mahecha, M.D.; Muñoz-Marí, J.; García-Haro, F.J.; Guanter, L.; et al. A unified vegetation index for quantifying the terrestrial biosphere. Sci. Adv. 2021, 7, eabc7447. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Biederman, J.A.; Knowles, J.F.; Scott, R.L.; Turner, A.J.; Dannenberg, M.P.; Köhler, P.; Frankenberg, C.; Litvak, M.E.; Flerchinger, G.N.; et al. Satellite solar-induced chlorophyll fluorescence and near-infrared reflectance capture complementary aspects of dry-land vegetation productivity dynamics. Remote Sens. Environ. 2022, 270, 112858. [Google Scholar] [CrossRef]
- Wang, Q.; Moreno-Martínez, Á.; Muñoz-Marí, J.; Campos-Taberner, M.; Camps-Valls, G. Estimation of vegetation traits with kernel NDVI. ISPRS J. Photogramm. Remote Sens. 2023, 195, 408–417. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Garlic | Water | Construction Land | Woodland | Green House | Not Garlic | Grassland |
|---|---|---|---|---|---|---|---|
| 1999 | 302 | 105 | 100 | 140 | 100 | 100 | 43 |
| 2005 | 307 | 102 | 105 | 143 | 100 | 100 | 40 |
| 2010 | 300 | 100 | 110 | 145 | 100 | 105 | 45 |
| 2014 | 306 | 104 | 105 | 140 | 100 | 100 | 47 |
| 2018 | 310 | 100 | 110 | 145 | 100 | 110 | 45 |
| 2023 | 305 | 100 | 110 | 140 | 100 | 103 | 46 |
| Acronym | Formula |
|---|---|
| NDVI | (NIR − RED)/(NIR + RED) |
| NDWI | (Green − NIR) −/− (Green + NIR) |
| NDBI | (SWIR2 − NIR) −/− (SWIR2 + NIR) |
| BSI | ((RED + SWIR1) − (NIR + BLUE)) −/− ((RED + SWIR1) + (NIR + BLUE)) |
| BAI | (BLUE − NIR) −/− (NIR + BLUE) |
| g NDVI | (NIR − Green) −/− (NIR + Green) |
| EVI | 2.5 * ((NIR − RED) −/− (NIR + 6 * RED − 7.5 * BLUE + 1)) |
| SR | NIR −/− RED |
| Clg | (NIR/Green)/−1 |
| kNDVI | Tanh(NDVI2) |
| Garlic | Waterbody | Construction Land | Woodland | Greenhouse | Not Garlic | Grassland | |
|---|---|---|---|---|---|---|---|
| Garlic | 235 | 0 | 2 | 0 | 0 | 0 | 0 |
| Water | 0 | 79 | 0 | 0 | 0 | 0 | 0 |
| Construction land | 4 | 0 | 82 | 0 | 1 | 2 | 1 |
| Woodland | 0 | 0 | 1 | 121 | 0 | 1 | 0 |
| Green house | 3 | 0 | 0 | 0 | 71 | 4 | 0 |
| Not garlic | 1 | 0 | 0 | 1 | 6 | 83 | 2 |
| Grassland | 0 | 1 | 0 | 0 | 0 | 1 | 34 |
| Producer accuracy (%) | 99.16 | 100.0 | 91.11 | 98.37 | 91.03 | 89.25 | 94.44 |
| User accuracy (%) | 96.71 | 98.75 | 96.47 | 99.18 | 91.02 | 91.21 | 91.89 |
| Year | CenterX | CenterY | XStdDist | YStdDist | Rotation | XSid/YStd |
|---|---|---|---|---|---|---|
| 1999 | 100.09 | 25.93 | 0.08 | 0.33 | 152.87 | 4.30 |
| 2005 | 100.09 | 25.93 | 0.08 | 0.34 | 152.51 | 4.01 |
| 2010 | 100.12 | 25.89 | 0.08 | 0.32 | 151.92 | 4.21 |
| 2014 | 100.13 | 25.89 | 0.09 | 0.35 | 153.56 | 3.98 |
| 2018 | 100.13 | 25.88 | 0.10 | 0.36 | 154.16 | 3.64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Pan, J.; Peng, W.; Li, Y.; Li, C. Garlic Crops’ Mapping and Change Analysis in the Erhai Lake Basin Based on Google Earth Engine. Agronomy 2024, 14, 755. https://doi.org/10.3390/agronomy14040755
Li W, Pan J, Peng W, Li Y, Li C. Garlic Crops’ Mapping and Change Analysis in the Erhai Lake Basin Based on Google Earth Engine. Agronomy. 2024; 14(4):755. https://doi.org/10.3390/agronomy14040755
Chicago/Turabian StyleLi, Wenfeng, Jiao Pan, Wenyi Peng, Yingzhi Li, and Chao Li. 2024. "Garlic Crops’ Mapping and Change Analysis in the Erhai Lake Basin Based on Google Earth Engine" Agronomy 14, no. 4: 755. https://doi.org/10.3390/agronomy14040755