
Extraction of Crop Row Navigation Lines for Soybean Seedlings Based on Calculation of Average Pixel Point Coordinates

 , , and
, , and
Abstract
1. Introduction
2. Materials and Methods
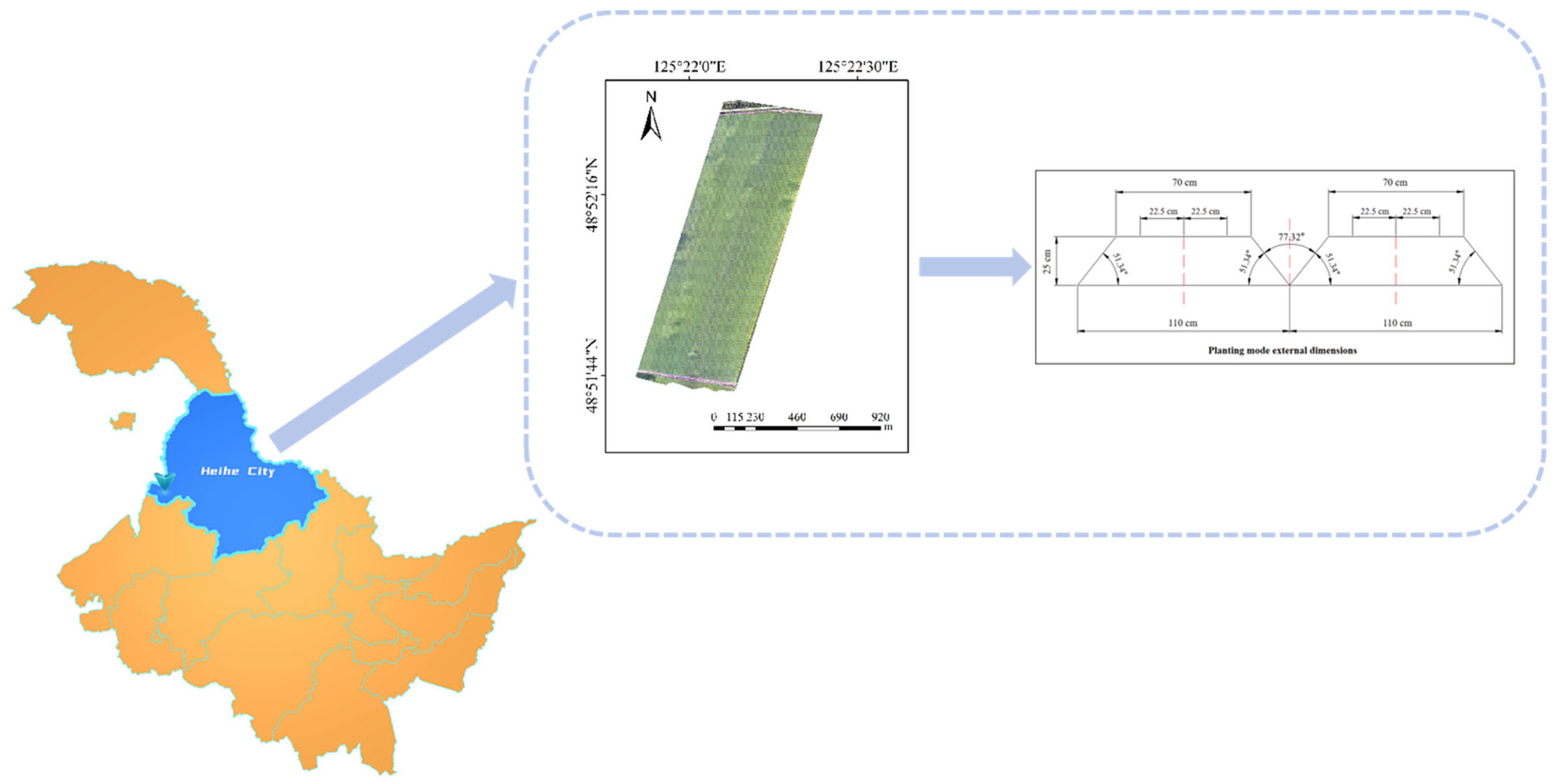
2.1. Image Acquisition
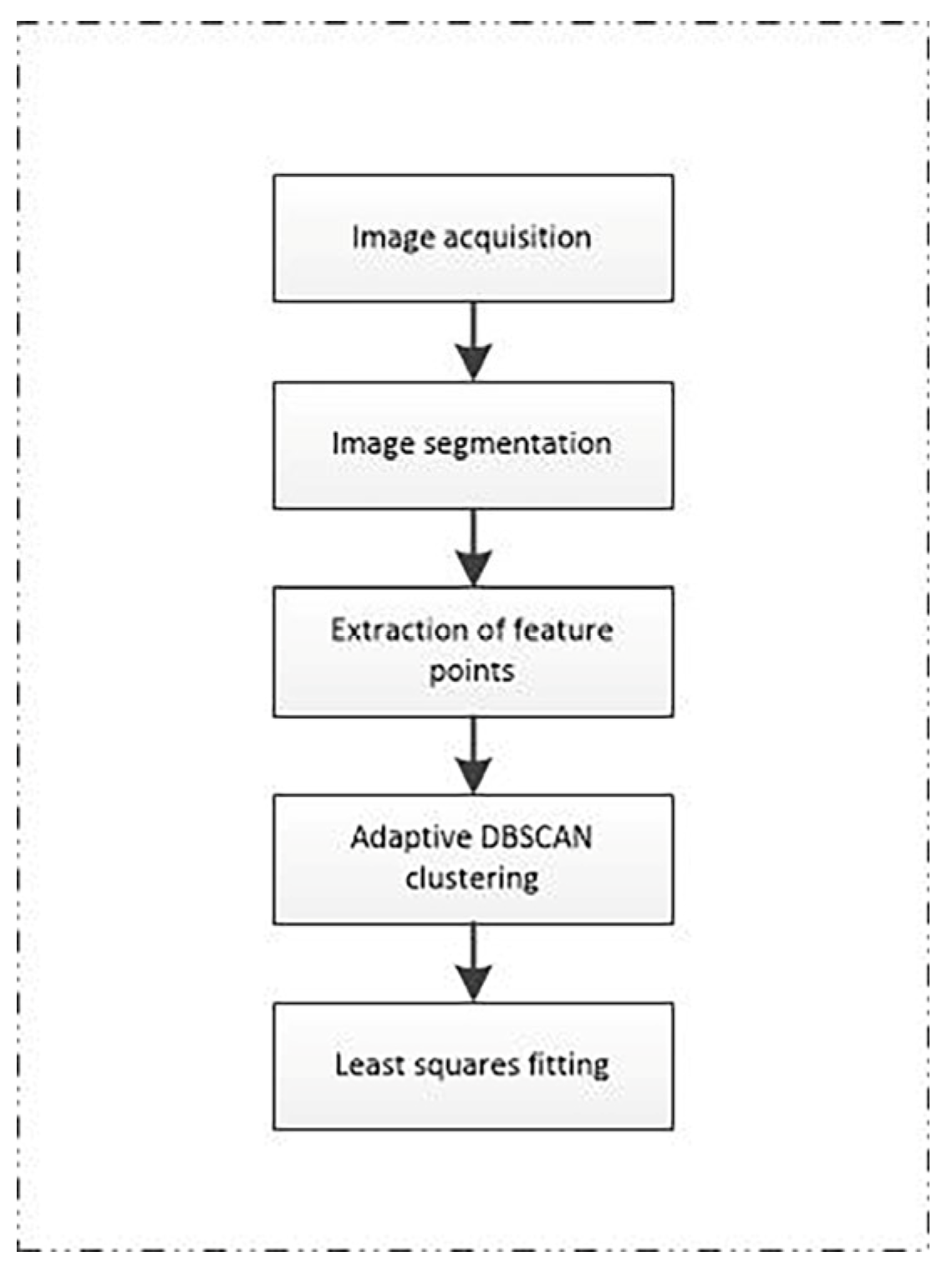
2.2. Algorithm for Soybean Seedling Navigation Line Extraction
2.3. Image Segmentation
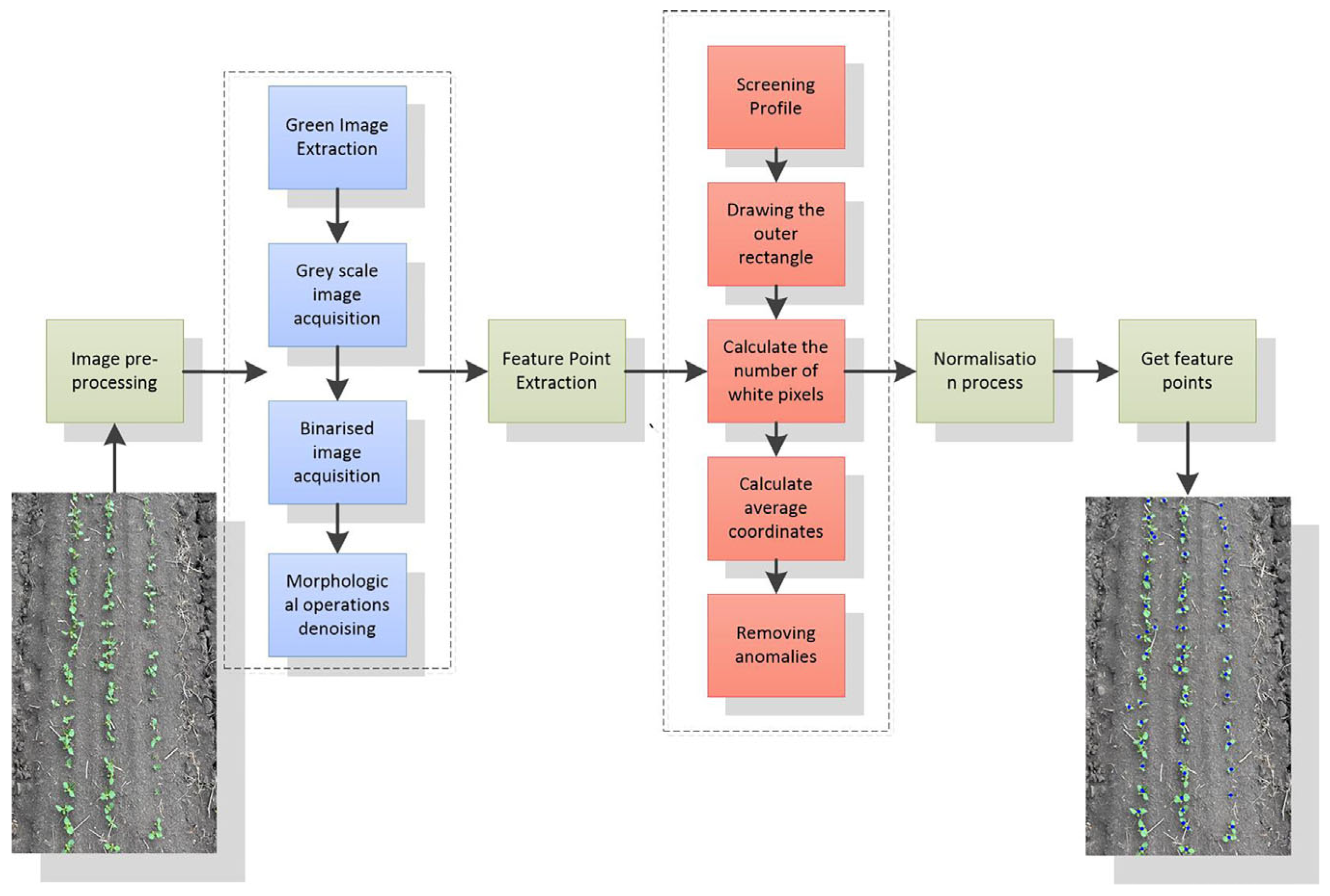
2.3.1. Image Greyscaling and Binarisation
maxGreen = [H_max,S_max,V_max]
2.3.2. Morphological Operations
2.4. Feature Point Extraction
- A suitable threshold value, Thresh, is set according to the size of the binarised image of soybean seedlings. The seedlings in the binarised image that meet this specific threshold value are calculated. The contours of each soybean seedling in the binarised image are traversed and compared with the specific threshold value. Contours smaller than the set threshold value are ignored.
- Iterate over the contour that meets the set threshold, use the OpenCV function to calculate the coordinates and dimensions of the rectangular box for this contour, and calculate the area of the binarised image contour that satisfies these conditions. The minimum value of the binarised image contour area is denoted as St, and the eligible contour area is denoted as S. The width and height of the bounding rectangle, denoted as w and h, respectively, can be calculated for an image contour with an area of S. The top-left corner coordinates (x, y) represent the offset. Figure 5 shows the result of drawing a bounding rectangle on a binary image of soybean seedlings after traversing the contours.
- Calculate the number of white pixels, n, within the bounding rectangle. Meanwhile, soybean seedlings exhibit diverse plant morphologies during their growth process. To avoid issues such as feature point displacement caused by small plants, a specific threshold, Threshi, is set again. If the number of white pixels within the bounding rectangle exceeds this threshold, further processing will be applied to contours that meet this condition.
- The non-zero pixel points within the outer rectangle that satisfy the given conditions should be identified, and their average coordinates should be calculated. The average value of these coordinates (a, b) should then be computed and added to the offsets x and y of the rectangular box as stated in Equation (5).where N is the total number of non-zero pixel points; and are the x and y coordinates of the ith non-zero point, respectively, to obtain the feature point coordinates (a,b).
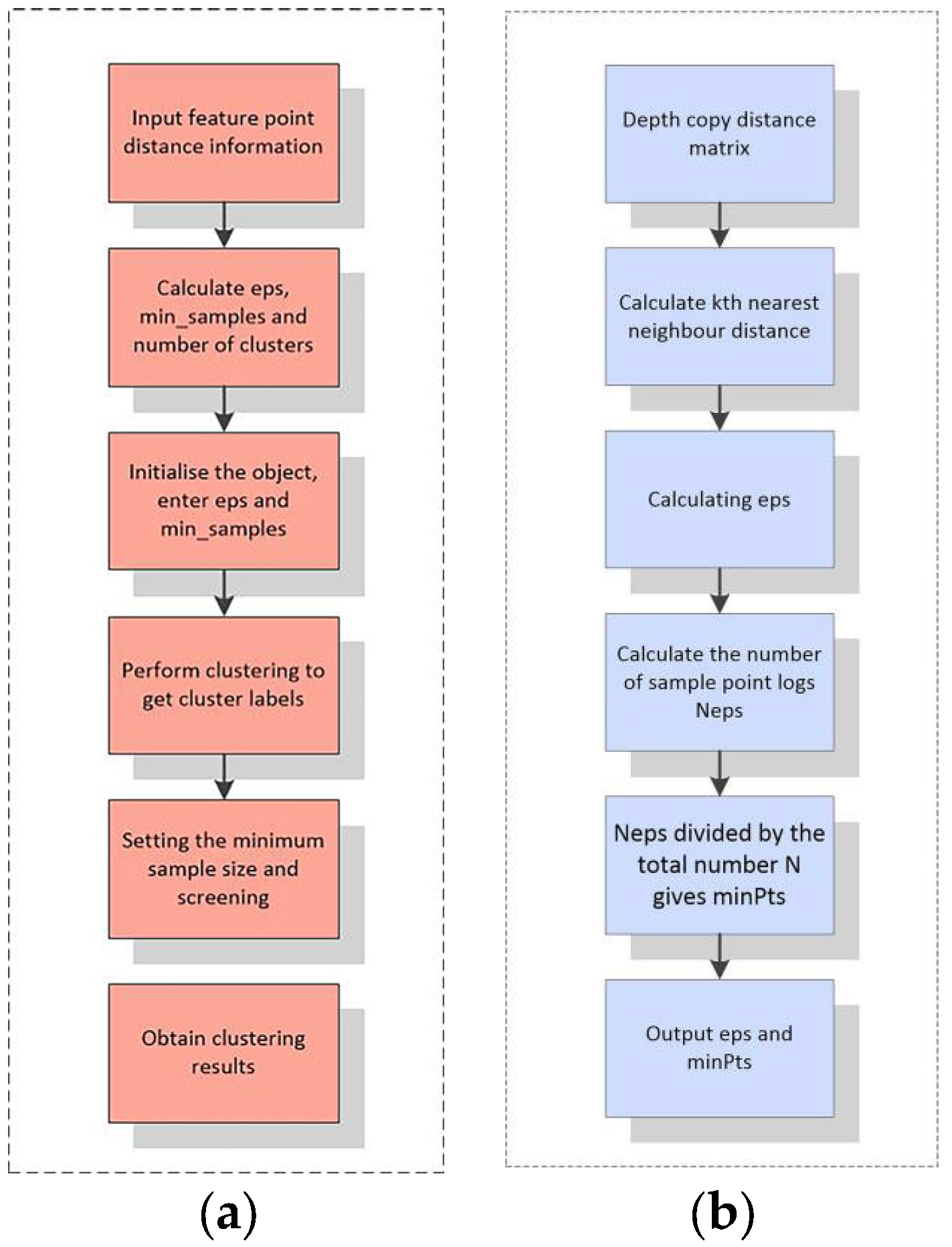
- The process of extracting the feature points will be affected by problems such as weeds, more seedlings, poor neatness, etc., and will be judged as an outlier based on the mean and standard deviation of the distance to the feature points, assuming that the distance is a P = {p1, p2, …, pn} set of points, where each point pi is a d-dimensional vector. Calculate the distance matrix D, where Dij denotes the distance between point pi and point pj:
2.5. Navigation Line Extraction
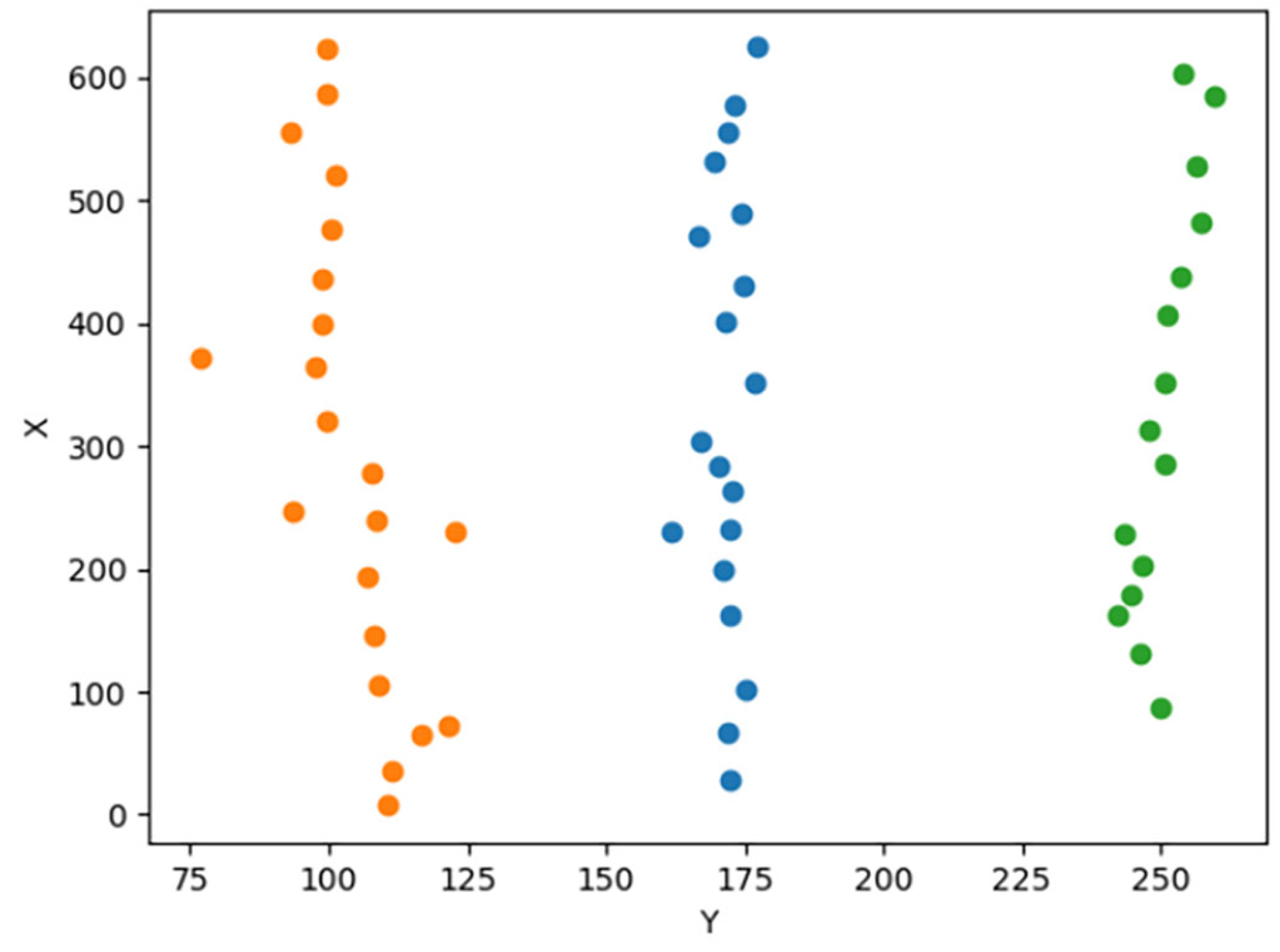
2.5.1. Feature Point Clustering
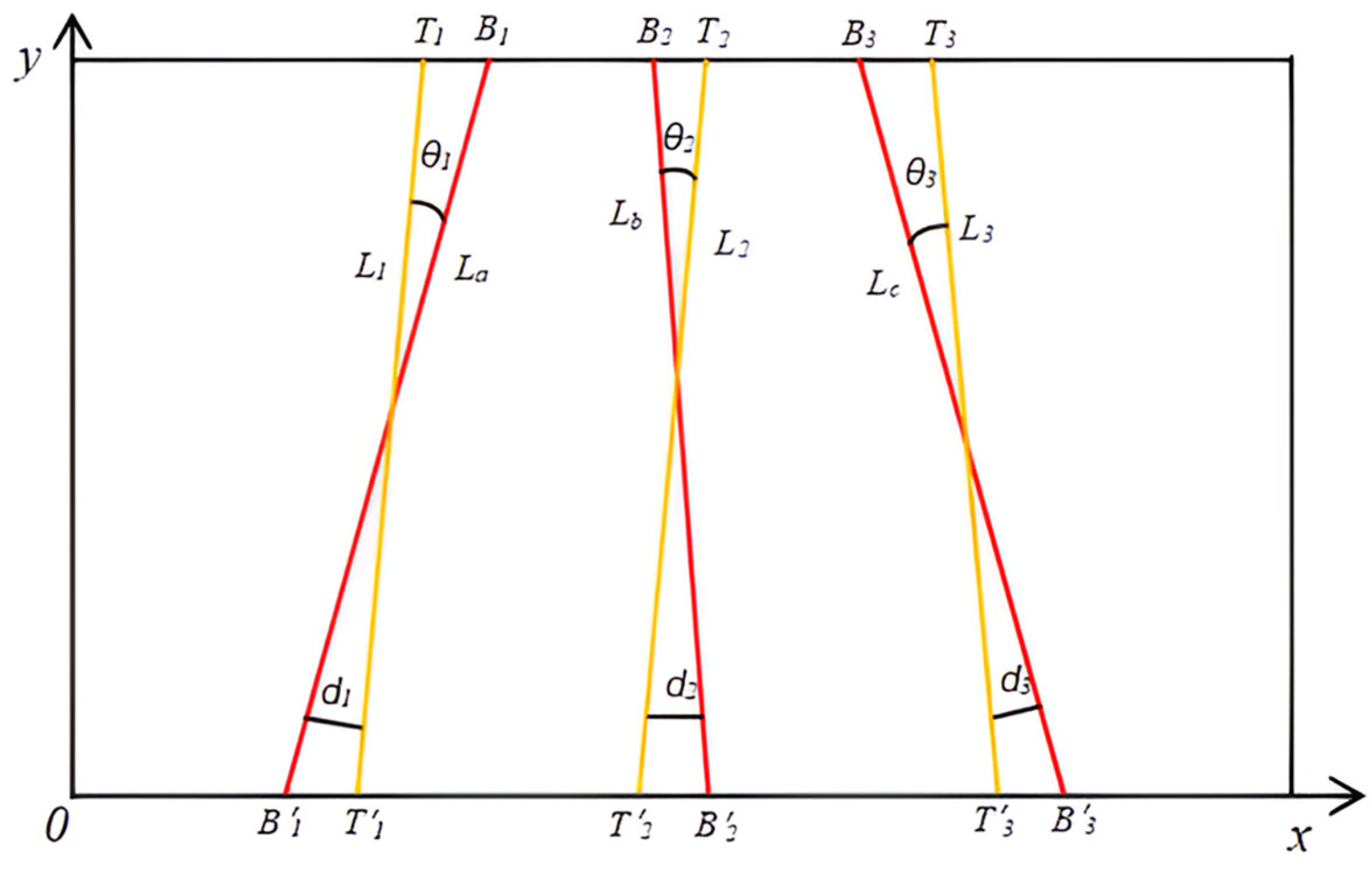
2.5.2. Crop Row Centreline Fitting and Navigation Line Extraction
3. Results
3.1. Acquisition of Visible Light Images of Soybean Seedling Strips
3.2. Image Pre-Processing
3.3. Feature Point Extraction and Clustering
3.4. Experimental Results of the Verification of the Accuracy of the Fitting of the Navigation Line
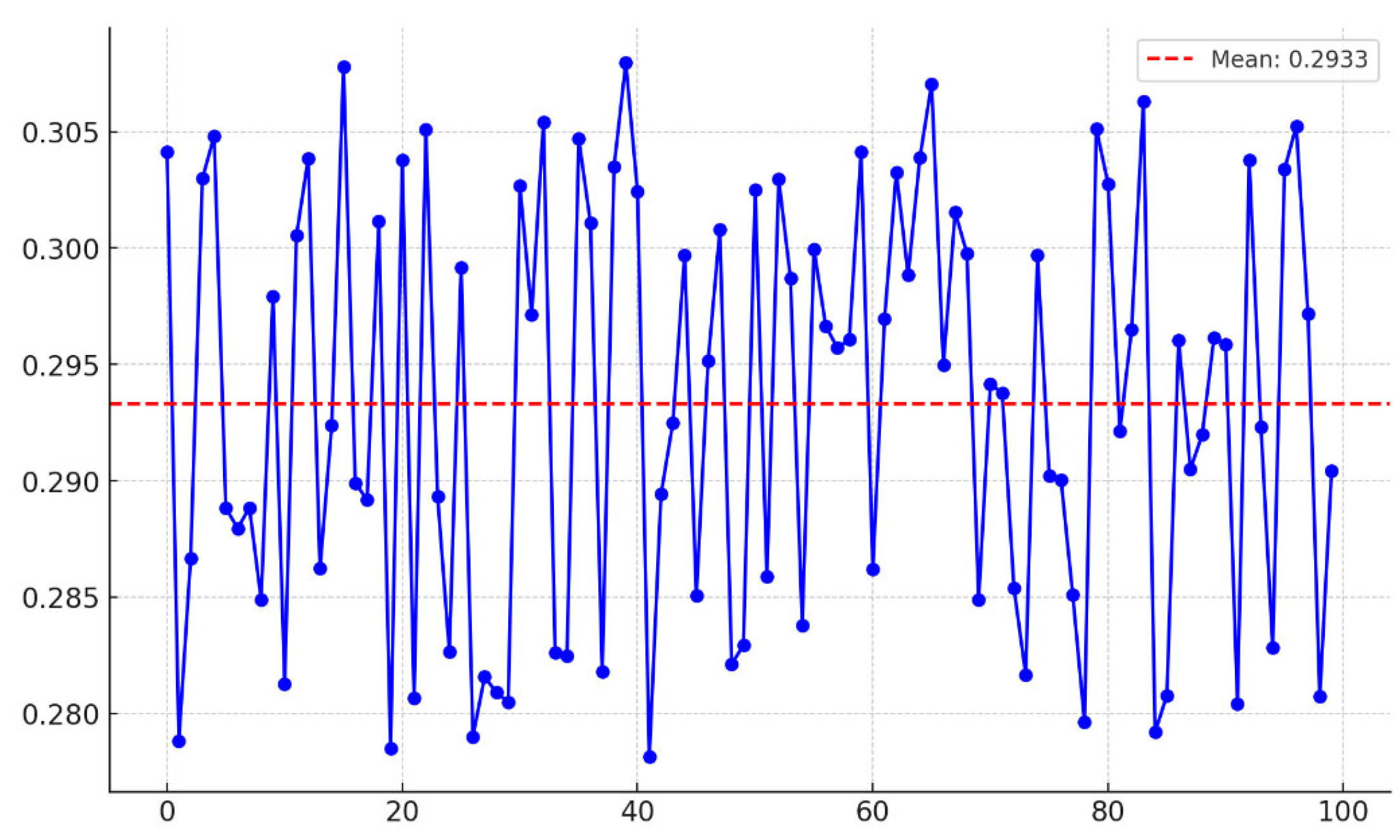
3.5. Timeliness Verification Test
4. Discussion
4.1. Comparative Analysis of Related Studies
4.2. Algorithm Implementation Analysis
4.3. Challenges and Prospects
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jing, Y.; Li, Q.; Ye, W.; Liu, G. Development of a GNSS/INS-based automatic navigation land levelling system. Comput. Electron. Agric. 2023, 213, 108187. [Google Scholar] [CrossRef]
- Romeo, J.; Pajares, G.; Montalvo, M.; Guerrero, J.M.; Guijarro, M.; Ribeiro, A. Crop row detection in maize fields inspired on the human visual perception. Sci. World J. 2012, 2012, 484390. [Google Scholar] [CrossRef]
- Han, Y.; Wang, Y.; Sun, Q.; Zhao, Y. Crop Row Detection Based on Wavelet Transformation and Otsu Segmentation Algorithm. J. Electron. Inf. Technol. 2016, 38, 63–70. [Google Scholar]
- Pang, Y.; Shi, Y.; Gao, S.; Jiang, F.; Veeranampalayam-Sivakumar, A.N.; Thompson, L.; Luck, J.; Liu, C. Improving crop row detection of early-season maize plants in UAV images using deep neural networks. Agric. Comput. Electron. 2022, 178, 105766. [Google Scholar] [CrossRef]
- Shi, J.; Bai, Y.; Diao, Z.; Zhou, J.; Yao, X.; Zhang, B. Row detection BASED navigation and guidance for agricultural robots and autonomous vehicles in row-crop fields: Methods and applications. Agronomy 2023, 13, 1780. [Google Scholar] [CrossRef]
- Diao, Z.; Guo, P.; Zhang, B.; Zhang, D.; Yan, J.; He, Z.; Zhao, S.; Zhao, C. Maize crop row recognition algorithm based on improved UNet network. Comput. Electron. Agric. 2023, 210, 107940. [Google Scholar] [CrossRef]
- Liu, X.; Qi, J.; Zhang, W.; Bao, Z.; Wang, K.; Li, N. Recognition method of maize crop rows at the seedling stage based on MS-ERFNet model. Comput. Electron. Agric. 2023, 211, 107964. [Google Scholar] [CrossRef]
- Zhou, J.; Geng, S.; Qiu, Q.; Shao, Y.; Zhang, M. A Deep-Learning Extraction Method for Orchard Visual Navigation Lines. Agriculture 2022, 12, 1650. [Google Scholar] [CrossRef]
- Li, X.; Peng, X.; Fang, H.; Niu, M.; Kang, J.; Jian, S. Navigation path detection of plant protection robot based on RANSAC algorithm. Trans. Chin. Soc. Agric. Mach. 2020, 51, 40–46. [Google Scholar]
- Zhou, Y.; Yang, Y.; Zhang, B.; Wen, X.; Yue, X.; Chen, L. Autonomous detection of crop rows based on adaptive multi-ROI in maize fields. Int. J. Agric. Biol. Eng. 2021, 14, 217–225. [Google Scholar] [CrossRef]
- Zhou, X.; Zhang, X.; Zhao, R.; Chen, Y.; Liu, X. Navigation Line Extraction Method for Broad-Leaved Plants in the Multi-Period Environments of the High-Ridge Cultivation Mode. Agriculture 2023, 13, 1496. [Google Scholar] [CrossRef]
- Li, X.; Zhao, W.; Zhao, L. Extraction algorithm of the center line of maize row in case of plants lacking. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2021, 37, 203–210. [Google Scholar]
- Montalvo, M.; Pajares, G.; Guerrero, J.M.; Romeo, J.; Guijarro, M.; Ribeiro, A.; Ruz, J.J.; Cruz, J.M. Automatic detection of crop rows in maize fields with high weeds pressure. Expert Syst. Appl. 2012, 39, 11889–11897. [Google Scholar] [CrossRef]
- Zhang, Q.; Chen, S.; Li, B. A visual navigation algorithm for paddy field weeding robot based on image understanding. Comput. Electron. Agric. 2017, 143, 66–78. [Google Scholar] [CrossRef]
- Zhai, Z.; Zhu, Z.; Du, Y.; Zhang, S.; Mao, E. Binocular Visual Crop Row Recognition Based on Census Transformation. Trans. Chin. Soc. Agric. Eng. 2016, 32, 205–213. [Google Scholar]
- Zhang, X.; Li, X.; Zhang, B.; Zhou, J.; Tian, G.; Xiong, Y.; Gu, B. Automated robust crop-row detection in maize fields based on position clustering algorithm and shortest path method. Comput. Electron. Agric. 2018, 154, 165–175. [Google Scholar] [CrossRef]
- He, J.; Zang, Y.; Luo, X.; Zhao, R.; He, J.; Jiao, J. Visual detection of rice rows based on Bayesian decision theory and robust regression least squares method. Int. J. Agric. Biol. Eng. 2021, 14, 199–206. [Google Scholar] [CrossRef]
- Garcia-Santillan, I.; Guerrero, J.M.; Montalvo, M.; Pajares, G. Curved and straight crop row detection by accumulation of green pixels from images in maize fields. Precis. Agric. 2018, 19, 18–41. [Google Scholar] [CrossRef]
- Vidović, I.; Cupec, R.; Hocenski, Ž. Crop row detection by global energy minimization. Pattern Recognit. 2016, 55, 68–86. [Google Scholar] [CrossRef]
- Burgos-Artizzu, X.P.; Ribeiro, A.; Guijarro, M.; Pajares, G. Real-time image processing for crop/weed discrimination in maize fields. Comput. Electron. Agric. 2011, 75, 337–346. [Google Scholar] [CrossRef]
- Jiang, G.; Wang, Z.; Liu, H. Automatic detection of crop rows based on multi-ROIs. Expert Syst. Appl. 2015, 42, 2429–2441. [Google Scholar] [CrossRef]
- Yang, Z.; Yang, Y.; Li, C.; Zhou, Y.; Zhang, X.; Yu, Y.; Liu, D. Tasseled crop rows detection based on micro-region of interest and logarithmic transformation. Front. Plant Sci. 2022, 13, 916474. [Google Scholar] [CrossRef] [PubMed]
- Tenhunen, H.; Pahikkala, T.; Nevalainen, O.; Teuhola, J.; Mattila, H.; Tyystjärvi, E. Automatic detection of cereal rows by means of pattern recognition techniques. Comput. Electron. Agric. 2019, 162, 677–688. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. Automatica 1975, 11, 23–27. [Google Scholar] [CrossRef]
- Ruan, Z.; Chang, P.; Cui, S.; Luo, J.; Gao, R.; Su, Z. A precise crop row detection algorithm in complex farmland for unmanned agricultural machines. Biosyst. Eng. 2023, 232, 1–12. [Google Scholar] [CrossRef]
- Zhao, R.; Yuan, X.; Yang, Z.; Zhang, L. Image-based crop row detection utilizing the Hough transform and DBSCAN clustering analysis. IET Image Process. 2024, 18, 1161–1177. [Google Scholar] [CrossRef]
- Shi, J.; Bai, Y.; Zhou, J.; Zhang, B. Multi-Crop Navigation Line Extraction Based on Improved YOLO-v8 and Threshold-DBSCAN under Complex Agricultural Environments. Agriculture 2023, 14, 45. [Google Scholar] [CrossRef]
- Bai, Y.; Zhang, B.; Xu, N.; Zhou, J.; Shi, J.; Diao, Z. Vision-based navigation and guidance for agricultural autonomous vehicles and robots: A review. Comput. Electron. Agric. 2023, 205, 107584. [Google Scholar] [CrossRef]
- Yu, Y.; Bao, Y.; Wang, J.; Chu, H.; Zhao, N.; He, Y.; Liu, Y. Crop row segmentation and detection in paddy fields based on treble-classification otsu and double-dimensional clustering method. Remote Sens. 2021, 13, 901. [Google Scholar] [CrossRef]
- García-Santillán, I.D.; Montalvo, M.; Guerrero, J.M.; Pajares, G. Automatic detection of curved and straight crop rows from images in maize fields. Biosyst. Eng. 2017, 156, 61–79. [Google Scholar] [CrossRef]
- Zheng, L.Y.; Xu, J.X. Multi-crop-row detection based on strip analysis. In Proceedings of the 2014 International Conference on Machine Learning and Cybernetics, Lanzhou, China, 13–16 July 2014. [Google Scholar]
- Ma, Z.; Tao, Z.; Du, X.; Yu, Y.; Wu, C. Automatic detection of crop root rows in paddy fields based on straight-line clustering algorithm and supervised learning method. Biosyst. Eng. 2021, 211, 63–76. [Google Scholar] [CrossRef]
- Jiang, G.; Wang, X.; Wang, Z.; Liu, H. Wheat rows detection at the early growth stage based on Hough transform and vanishing point. Comput. Electron. Agric. 2016, 123, 211–223. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Avgθ | absAvgθ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| a | −0.10 | 0.10 | −0.03 | 0.14 | 0.30 | 0.17 | 0.10 | 0.04 | 0.20 | 0.30 |
| b | −0.21 | 0.17 | 0.57 | 0.26 | −0.02 | 0.53 | 0.31 | 0.57 | 0.32 | 0.20 |
| c | −0.23 | 0.01 | 0.27 | −0.42 | −0.40 | 0.33 | 0.18 | 0.31 | 0.86 | 0.68 |
| d | 0.16 | −0.06 | 0.10 | −0.22 | −0.18 | 0.16 | 0.12 | 0.42 | 0.38 | 0.22 |
| Group | Avgd | A | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| a | 4.82 | 12.49 | 1.80 | 4.00 | 6.38 | 98.09% | 98.40% | 99.11% | 97.96% | 96.73% |
| b | 10.64 | 6.62 | 12.38 | 7.28 | 5.02 | 94.74% | 96.65% | 93.65% | 96.29% | 97.50% |
| c | 7.61 | 4.63 | 6.42 | 16.30 | 12.56 | 96.26% | 97.69% | 96.71% | 91.97% | 93.83% |
| d | 3.34 | 2.88 | 8.92 | 7.94 | 5.50 | 98.29% | 98.57% | 95.51% | 96.09% | 97.30% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, B.; Zhao, D.; Chen, C.; Li, J.; Zhang, W.; Qi, L.; Wang, S. Extraction of Crop Row Navigation Lines for Soybean Seedlings Based on Calculation of Average Pixel Point Coordinates. Agronomy 2024, 14, 1749. https://doi.org/10.3390/agronomy14081749
Zhang B, Zhao D, Chen C, Li J, Zhang W, Qi L, Wang S. Extraction of Crop Row Navigation Lines for Soybean Seedlings Based on Calculation of Average Pixel Point Coordinates. Agronomy. 2024; 14(8):1749. https://doi.org/10.3390/agronomy14081749
Chicago/Turabian StyleZhang, Bo, Dehao Zhao, Changhai Chen, Jinyang Li, Wei Zhang, Liqiang Qi, and Siru Wang. 2024. "Extraction of Crop Row Navigation Lines for Soybean Seedlings Based on Calculation of Average Pixel Point Coordinates" Agronomy 14, no. 8: 1749. https://doi.org/10.3390/agronomy14081749
APA StyleZhang, B., Zhao, D., Chen, C., Li, J., Zhang, W., Qi, L., & Wang, S. (2024). Extraction of Crop Row Navigation Lines for Soybean Seedlings Based on Calculation of Average Pixel Point Coordinates. Agronomy, 14(8), 1749. https://doi.org/10.3390/agronomy14081749