


V-YOLO: A Lightweight and Efficient Detection Model for Guava in Complex Orchard Environments


Abstract
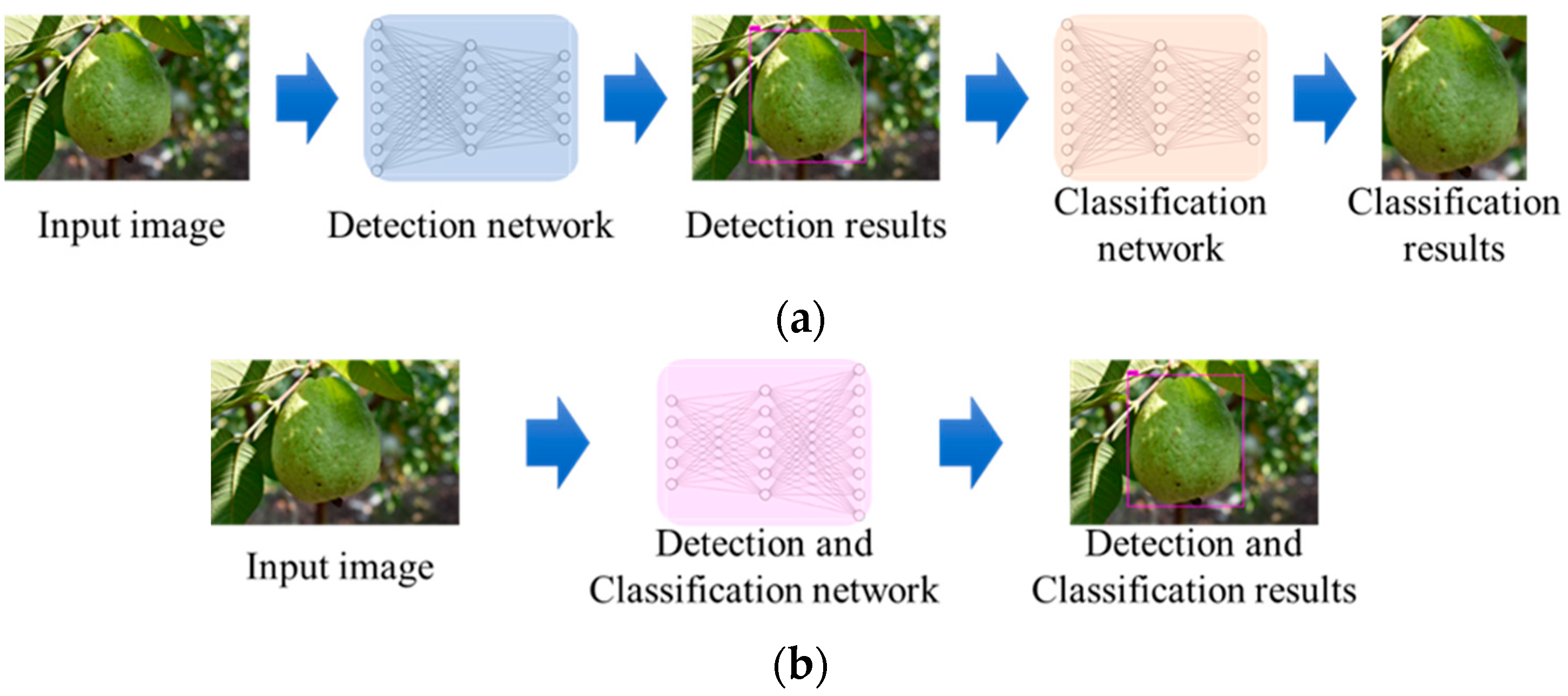
:1. Introduction
2. Materials and Methods
2.1. Image Acquisition
2.2. Data Set Making and Partitioning
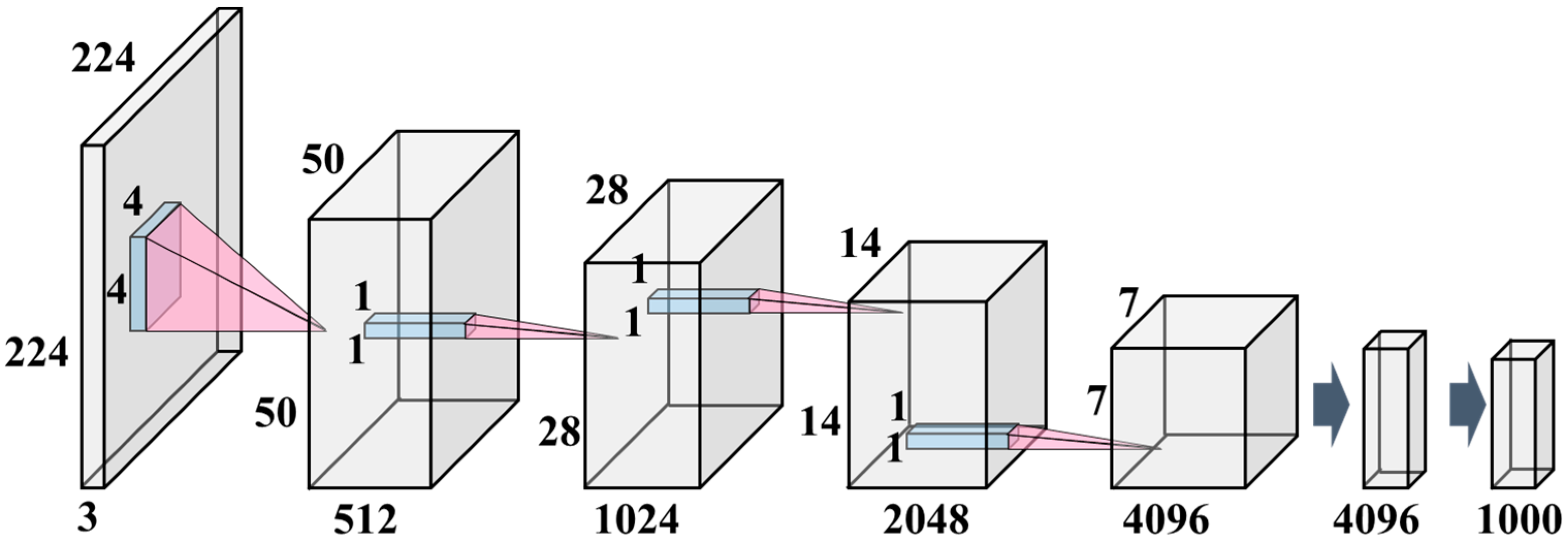
2.3. Standard YOLOv10 Model
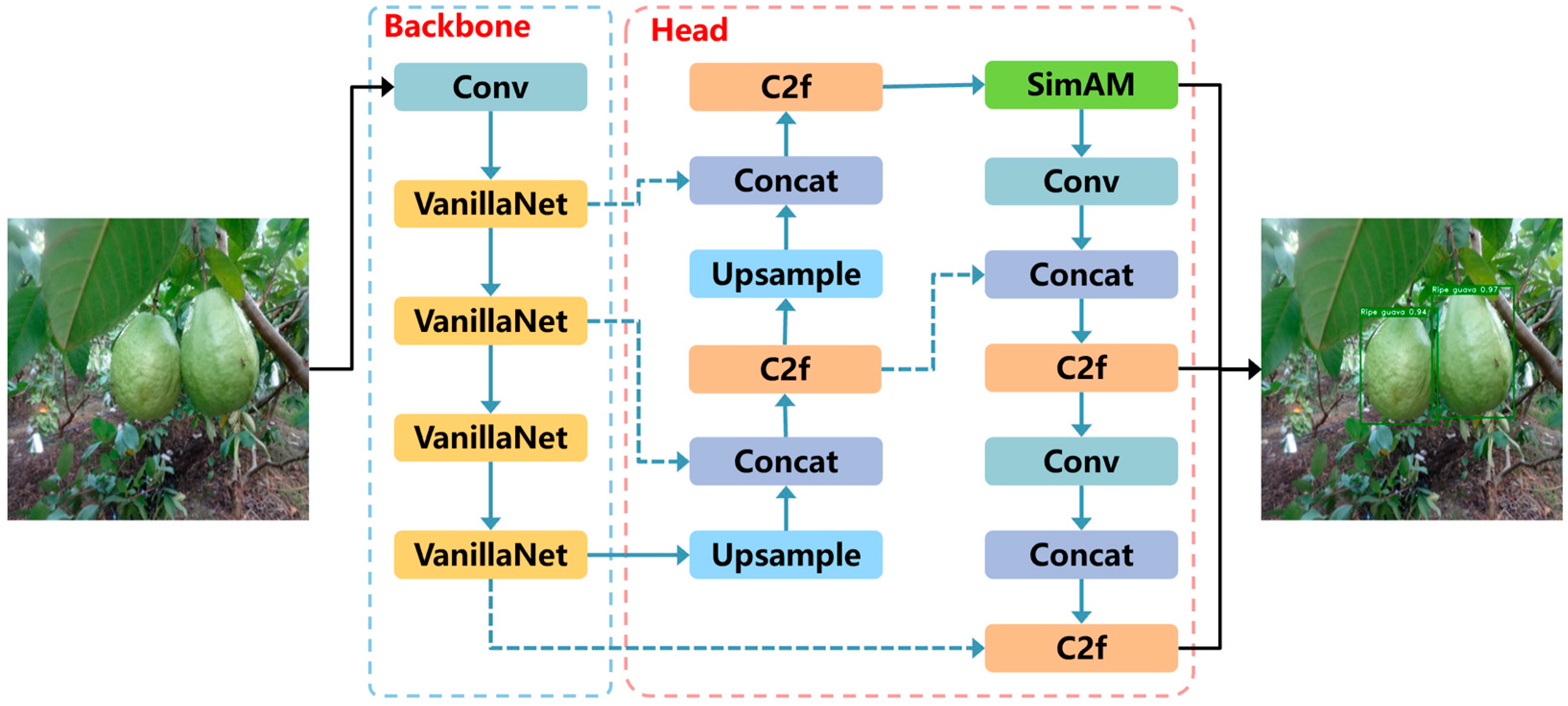
2.4. V-YOLO
2.4.1. Backbone
2.4.2. Attention Mechanism
2.4.3. Head
2.5. Model Evaluation Metrics
2.6. Experiment Settings
3. Result
3.1. Ablation Experiments
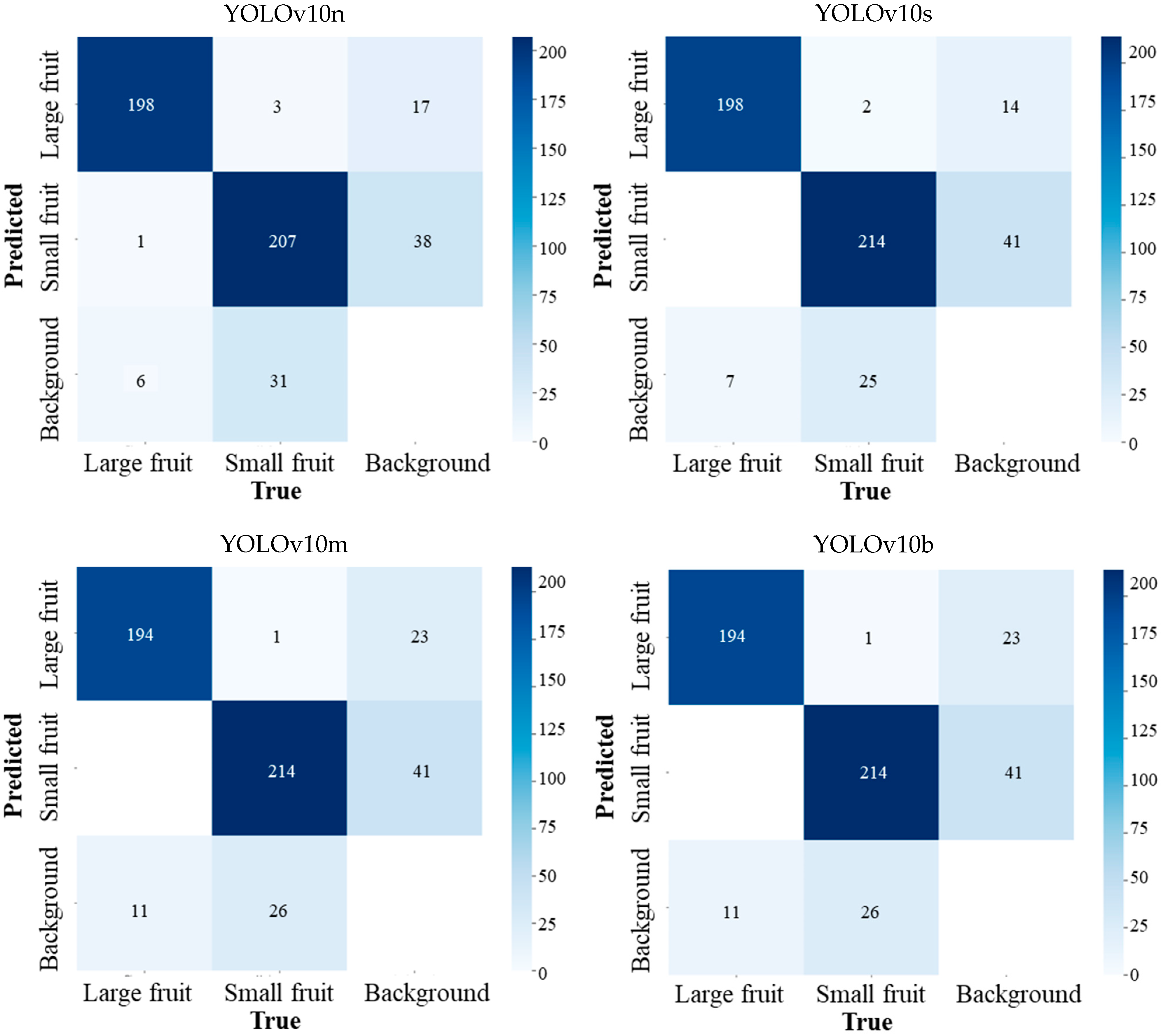
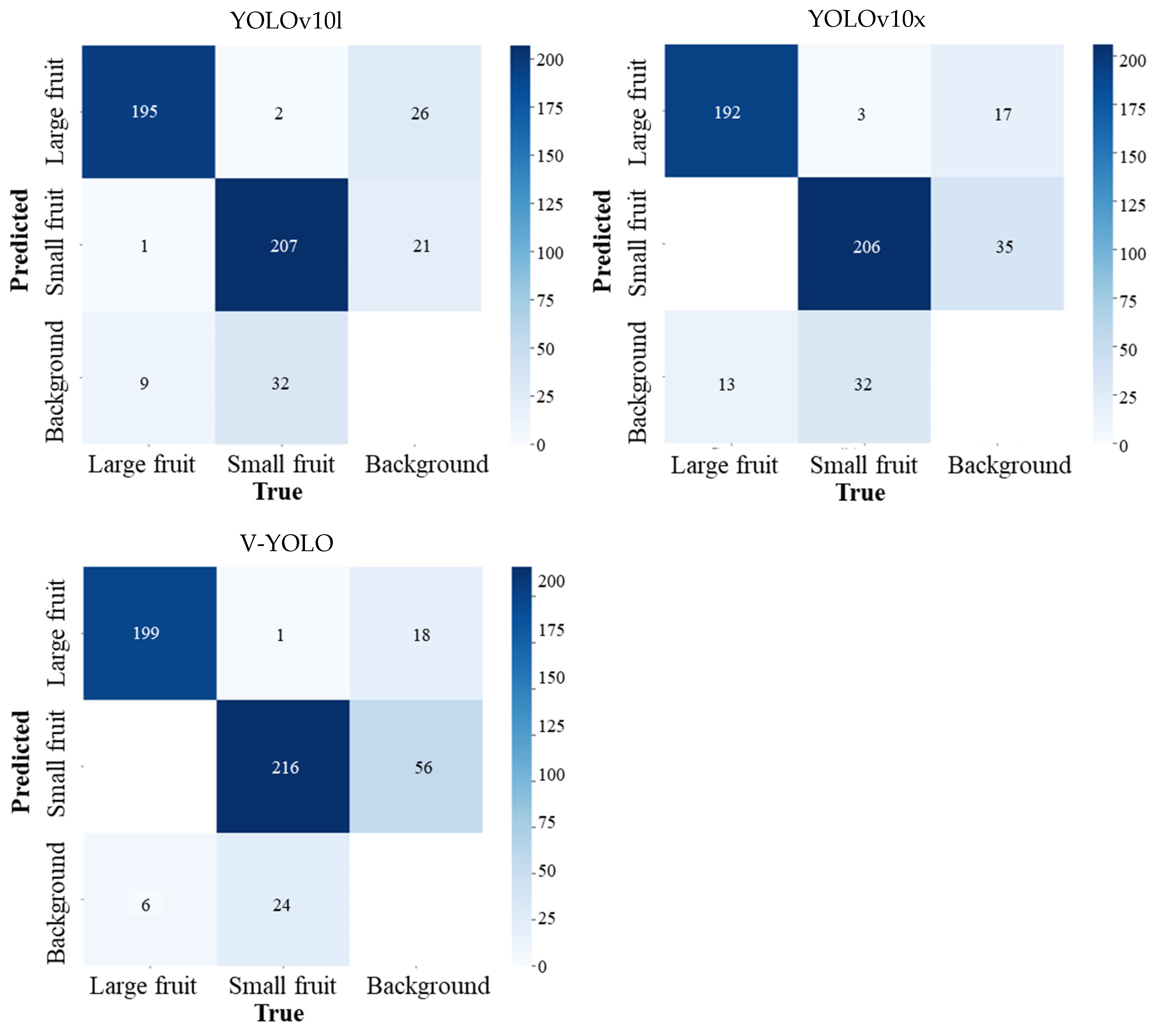
3.2. Guava Detection Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Aditya, R.; Sadia, S.; Rashiduzzaman, S.; Bonna, A.; Umme, S. A comprehensive guava leaves and fruits dataset for guava disease recognition. Data Brief 2022, 42, 108174. [Google Scholar] [CrossRef]
- Li, H.; Lee, W.S.; Wang, K. Identifying blueberry fruit of different growth stages using natural outdoor color images. Comput. Electron. Agric. 2014, 106, 91–101. [Google Scholar] [CrossRef]
- Li, P.; Lee, S.H.; Hsu, H.Y. Review on fruit harvesting method for potential use of automatic fruit harvesting systems. Procedia Eng. 2011, 23, 351–366. [Google Scholar] [CrossRef]
- Payne, A.B.; Walsh, K.B.; Subedi, P.P.; Jarvis, D. Estimation of mango crop yield using image analysis—Segmentation method. Comput. Electron. Agric. 2013, 91, 57–64. [Google Scholar] [CrossRef]
- Yamamoto, K.; Guo, W.; Yoshioka, Y.; Ninomiya, S. On plant detection of intact tomato fruits using image analysis and machine learning methods. Sensors 2014, 14, 12191–12206. [Google Scholar] [CrossRef]
- Dorj, U.O.; Lee, M.; Yun, S.S. An yield estimation in citrus orchards via fruit detection and counting using image processing. Comput. Electron. Agric. 2017, 140, 103–112. [Google Scholar] [CrossRef]
- Qureshi, W.S.; Payne, A.; Walsh, K.B.; Linker, R.; Cohen, O.; Dailey, M.N. Machine vision for counting fruit on mango tree canopies. Precis. Agric. 2017, 18, 224–244. [Google Scholar] [CrossRef]
- Malik, Z.; Ziauddin, S.; Shahid, A.R.; Safi, A. Detection and counting ofon-tree citrus fruit for crop yield estimation. Int. J. Adv. Comput. Sci. 2016, 7, 519–523. [Google Scholar] [CrossRef]
- Mehta, S.S.; Ton, C.; Asundi, S.; Burks, T.F. Multiple camera fruit localization using a particle filter. Comput. Electron. Agric. 2017, 142, 139–154. [Google Scholar] [CrossRef]
- Yasar, G.H.; Akdemir, B. Estimating yield for fruit trees using image processing and artificial neural network. Int. J. Adv. Agric. Environ. Engg IJAAEE 2017, 4, 8–11. [Google Scholar]
- Zhao, C.; Lee, W.S.; He, D. Immature green citrus detection based on colour feature and sum of absolute transformed difference (SATD) using colour images in the citrus grove. Comput. Electron. Agric. 2016, 124, 243–253. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldu, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, G. Deep learning—Method overview and review of use for fruit detection and yield estimation. Comput. Electron. Agric. 2019, 162, 219–234. [Google Scholar] [CrossRef]
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning for real-time fruit detection and orchard fruit load estimation: Benchmarking of ‘MangoYOLO’. Precis. Agric. 2019, 20, 1107–1135. [Google Scholar] [CrossRef]
- Liang, C.; Xiong, J.; Zheng, Z.; Zhong, Z.; Li, Z.; Chen, S.; Yang, Z. A visual detection method for nighttime litchi fruits and fruiting stems. Comput. Electron. Agric. 2020, 169, 105192. [Google Scholar] [CrossRef]
- Ganesh, P.; Volle, K.; Burks, T.F.; Mehta, S.S. Deep orange: Mask R-CNN based orange detection and segmentation. IFAC PapersOnLine 2019, 52, 70–75. [Google Scholar] [CrossRef]
- Wan, S.; Goudos, S. Faster R-CNN for multi-class fruit detection using a robotic vision system. Comput. Netw. 2020, 168, 107036. [Google Scholar] [CrossRef]
- Tu, S.; Xue, Y.; Chan, Z.; Yu, Q.; Liang, M. Detection of passion fruits and maturity classification using red-green-blue depth images. Biosyst. Eng. 2018, 175, 156–167. [Google Scholar] [CrossRef]
- Tan, K.; Lee, W.; Gan, H.; Wang, S. Recognising blueberry fruit of different maturity using histogram oriented gradients and colour features in outdoor scenes. Biosyst. Eng. 2018, 176, 59–72. [Google Scholar] [CrossRef]
- Chen, S.; Xiong, J.; Jiao, J.; Xie, Z.; Huo, Z.; Hu, W. Citrus fruits maturity detection in natural environments based on convolutional neural networks and visual saliency map. Precis. Agric. 2022, 23, 1515–1531. [Google Scholar] [CrossRef]
- Kao, I.H.; Hsu, Y.W.; Yang, Y.Z.; Chen, Y.L.; Lai, Y.H.; Perng, J.W. Determination of lycopersicon maturity using convolutional autoencoders. Sci. Hortic. 2019, 256, 108538. [Google Scholar] [CrossRef]
- Wu, X.; Tang, R. Fast Detection of Passion Fruit with Multi-class Based on YOLOv3. In Proceedings of the 2020 Chinese Intelligent Systems Conference, Shenzhen, China, 24–25 October 2020; pp. 818–825. [Google Scholar] [CrossRef]
- Habaragamuwa, H.; Ogawa, Y.; Suzuki, T.; Shiigi, T.; Ono, M.; Kondo, N. Detecting greenhouse strawberries (mature and immature), using deep convolutional neural network. Eng. Agric. Environ. Food 2018, 11, 127–138. [Google Scholar] [CrossRef]
- Gao, F.; Fu, L.; Zhang, X.; Majeed, Y.; Zhang, Q. Multi-class fruit-on-plant detection for apple in snap system using faster r-cnn. Comput. Electron. Agric. 2020, 176, 105634. [Google Scholar] [CrossRef]
- Lv, J.; Xu, H.; Xu, L.; Zou, L.; Rong, H.; Yang, B.; Niu, L.; Ma, Z. Recognition of fruits and vegetables with similar-color background in natural environment: A survey. J. Field Robot. 2022, 39, 888–904. [Google Scholar] [CrossRef]
- Lin, G.; Tang, Y.; Zou, X.; Wang, C. Three-dimensional reconstruction of guava fruits and branches using instance segmentation and geometry analysis. Comput. Electron. Agric. 2021, 184, 106107. [Google Scholar] [CrossRef]
- Zhang, Q.; Chen, Q.; Xu, W.; Xu, L.; Lu, E. Prediction of Feed Quantity for Wheat Combine Harvester Based on Improved YOLOv5s and Weight of Single Wheat Plant without Stubble. Agriculture 2024, 14, 1251. [Google Scholar] [CrossRef]
- Hao, X.; Jia, J.; Gao, W.; Guo, X.; Zhang, W.; Zheng, L.; Wang, M. MFC-CNN: An automatic grading scheme for light stress levels of lettuce (Lactuca sativa L.) leaves. Comput. Electron. Agric. 2020, 179, 105847. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE T. Pattern Anal. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; NanoCode012; Kwon, Y.; Michael, K.; Tao, X.; Fang, J.; Imyhxy; et al. Ultralytics. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 9 November 2022).
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Huang, X.; Wang, X.; Lv, W.; Bai, X.; Yoshie, O. PP-YOLOv2: A practical object detector. arXiv 2021, arXiv:2104.10419. [Google Scholar] [CrossRef]
- Long, X.; Deng, K.; Wang, G.; Zhang, Y.; Wen, S. PP-YOLO: An effective and efficient implementation of object detector. arXiv 2020, arXiv:2007.12099. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Geng, Y.; Jiang, H.; Cheng, M.; Zhang, B.; Ke, Z.; Xu, X.; Chu, X. Yolov6 v3.0: A full-scale reloading. arXiv 2023, arXiv:2301.05586. [Google Scholar] [CrossRef]
- Wang, C.; Bochkovskiy, A.; Liao, H. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar] [CrossRef]
- Rizwan, M.; Glenn, J. Ultralytics. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 January 2023).
- Wang, C.; Yeh, I.; Liao, H. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Y.; Guo, J.; Tao, D. Vanillanet: The power of minimalism in deep learning. arXiv 2023, arXiv:2305.12972. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 11863–11874. Available online: https://proceedings.mlr.press/v139/yang21o (accessed on 6 July 2024).
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 16965–16974. Available online: https://openaccess.thecvf.com/content/CVPR2024/html/Zhao_DETRs_Beat_YOLOs_on_Real-time_Object_Detection_CVPR_2024_paper.html (accessed on 6 July 2024).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total | Training Set | Verification Set | Test Set | |
|---|---|---|---|---|
| Images of large fruit | 510 | 351 | 81 | 78 |
| Images of small fruit | 580 | 412 | 82 | 86 |
| Total | 1090 | 763 | 163 | 164 |
| Modified Part | Parameters | FLOPs | FPS | P | R | mAP | ||
|---|---|---|---|---|---|---|---|---|
| Backbone | SimAM | Head | ||||||
| × | × | × | 2,695,196 | 8.2 G | 625 | 90.0% | 89.9% | 95.0% |
| √ | × | × | 1,147,684 | 4.1 G | 1000 | 89.1% | 89.0% | 93.7% |
| √ | √ | × | 1,147,684 | 4.1 G | 1000 | 91.0% | 86.7% | 93.8% |
| √ | √ | √ | 1,165,118 | 3.4 G | 1666 | 93.3% | 89.3% | 95.0% |
| Model | Parameters | FLOPs | FPS | P | R | mAP |
|---|---|---|---|---|---|---|
| YOLOv10n | 2,695,196 | 8.2 G | 625 | 90.0% | 89.9% | 95.0% |
| YOLOv10s | 8,036,508 | 24.4 G | 400 | 90.7% | 90.1% | 94.9% |
| YOLOv10m | 16,452,700 | 63.4 G | 192 | 89.9% | 90.4% | 93.6% |
| YOLOv10b | 20,414,236 | 97.9 G | 149 | 92.8% | 87.4% | 94.2% |
| YOLOv10l | 25,719,452 | 126.3 G | 122 | 90.7% | 87.9% | 93.9% |
| YOLOv10x | 31,587,932 | 169.8 G | 79. | 91.6% | 88.0% | 94.1% |
| RT-DETR-l | 31,987,850 | 103.4 G | 135 | 87.6% | 85.1% | 91.6% |
| RT-DETR-R50 | 41,938,794 | 125.6 G | 114 | 84.4% | 81.7% | 88.1% |
| RT-DETR-R101 | 60,904,810 | 186.2 G | 75 | 87.0% | 85.9% | 91.2% |
| RT-DETR-x | 65,471,546 | 222.5 G | 83 | 83.9% | 86.0% | 90.6% |
| V-YOLO | 1,165,118 | 3.4 G | 1666 | 93.3% | 89.3% | 95.0% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Xiong, J.; Cai, M.; Li, X.; Tan, X. V-YOLO: A Lightweight and Efficient Detection Model for Guava in Complex Orchard Environments. Agronomy 2024, 14, 1988. https://doi.org/10.3390/agronomy14091988
Liu Z, Xiong J, Cai M, Li X, Tan X. V-YOLO: A Lightweight and Efficient Detection Model for Guava in Complex Orchard Environments. Agronomy. 2024; 14(9):1988. https://doi.org/10.3390/agronomy14091988
Chicago/Turabian StyleLiu, Zhen, Juntao Xiong, Mingrui Cai, Xiaoxin Li, and Xinjie Tan. 2024. "V-YOLO: A Lightweight and Efficient Detection Model for Guava in Complex Orchard Environments" Agronomy 14, no. 9: 1988. https://doi.org/10.3390/agronomy14091988
APA StyleLiu, Z., Xiong, J., Cai, M., Li, X., & Tan, X. (2024). V-YOLO: A Lightweight and Efficient Detection Model for Guava in Complex Orchard Environments. Agronomy, 14(9), 1988. https://doi.org/10.3390/agronomy14091988