
Single Image Atmospheric Veil Removal Using New Priors for Better Genericity



Abstract
:1. Introduction
- The use of a Naka–Rushton function in the inference of the atmospheric veil to restore the fog near the horizon without restoring the part near the camera. The parameters of this function are estimated from the characteristics of the input foggy image.
- The proposed algorithms also address spatially uniform veils, and generalize to different kinds of fog, by the help of an interpolation function.
- Applying our method on each color channel addresses the local variations of the color of the fog. This allows for restoring images with color distortions due to dust and pollution, as well as nighttime and underwater images.
2. Related Works
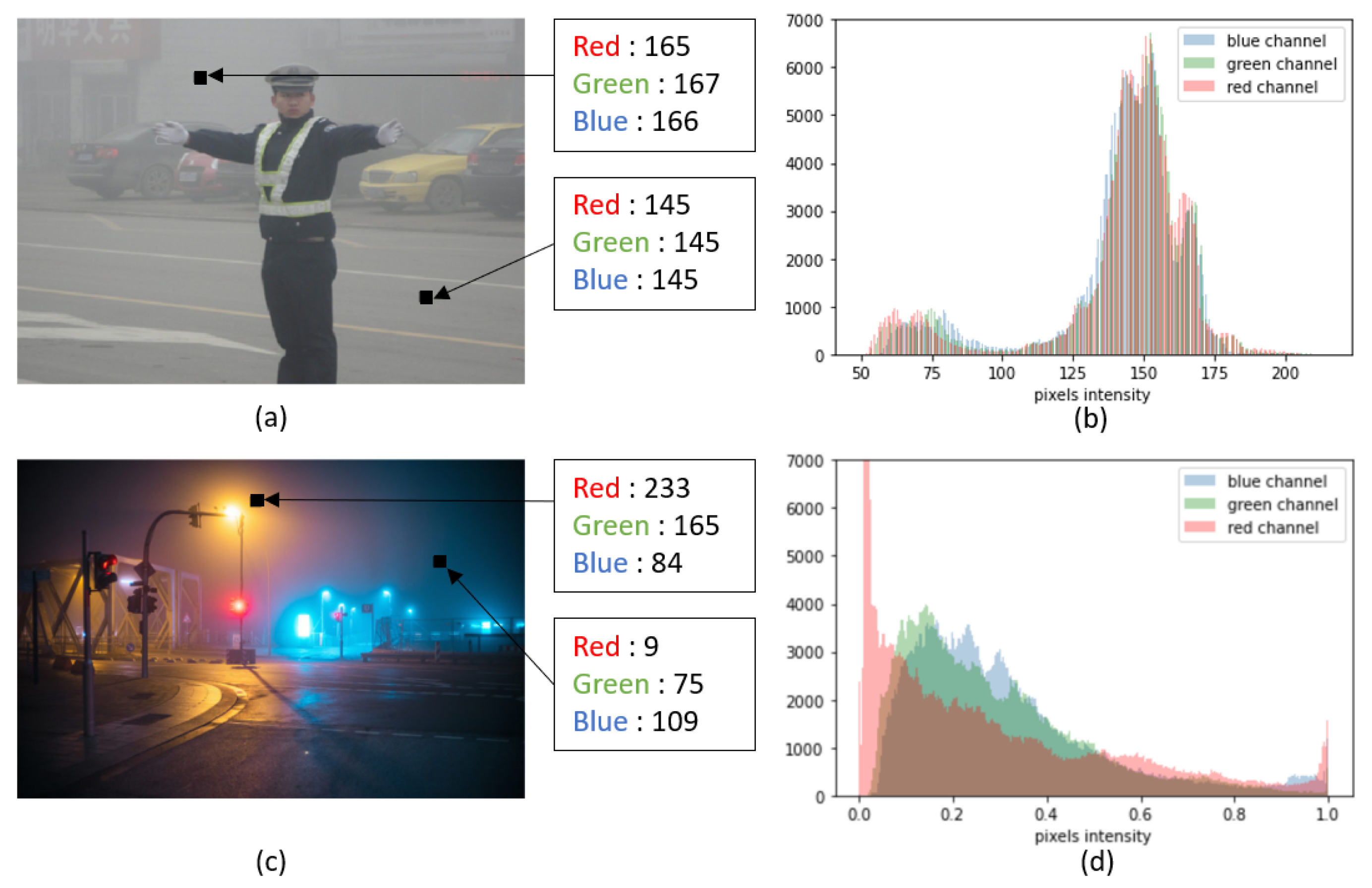
2.1. Fog Visual Effect
2.2. Daytime Image Defogging
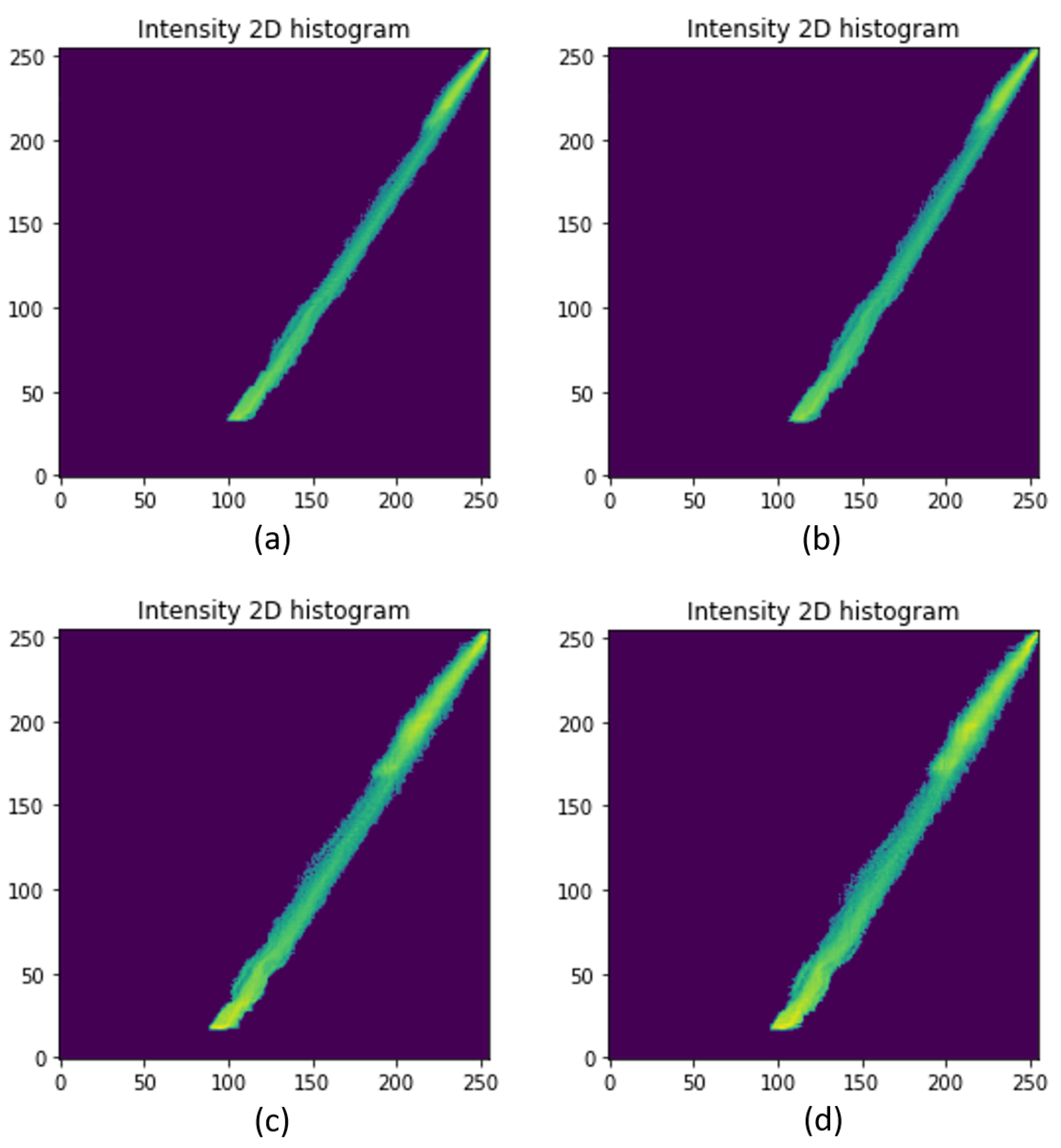
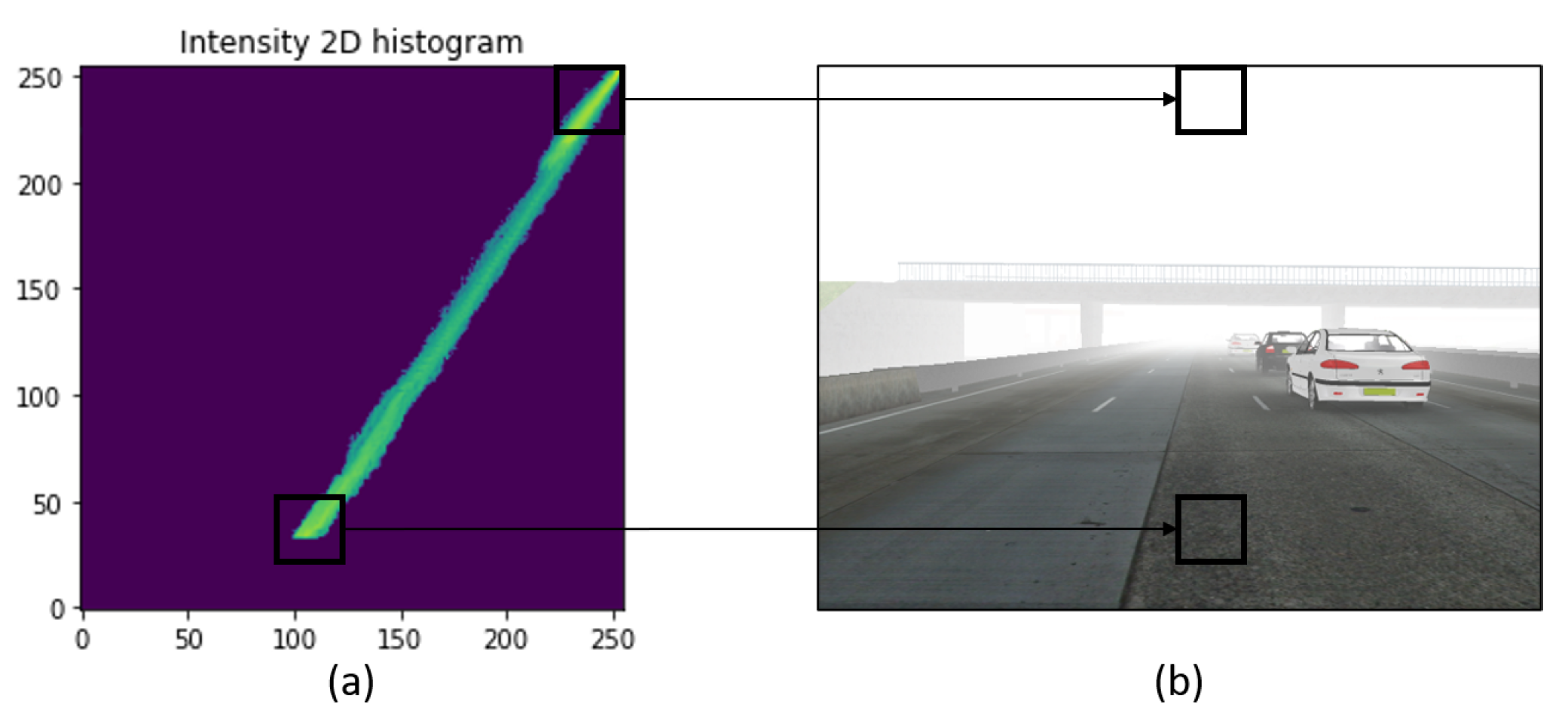
2.3. Hidden Priors in the DCP Method
3. Single Image Atmospheric Veil Removal
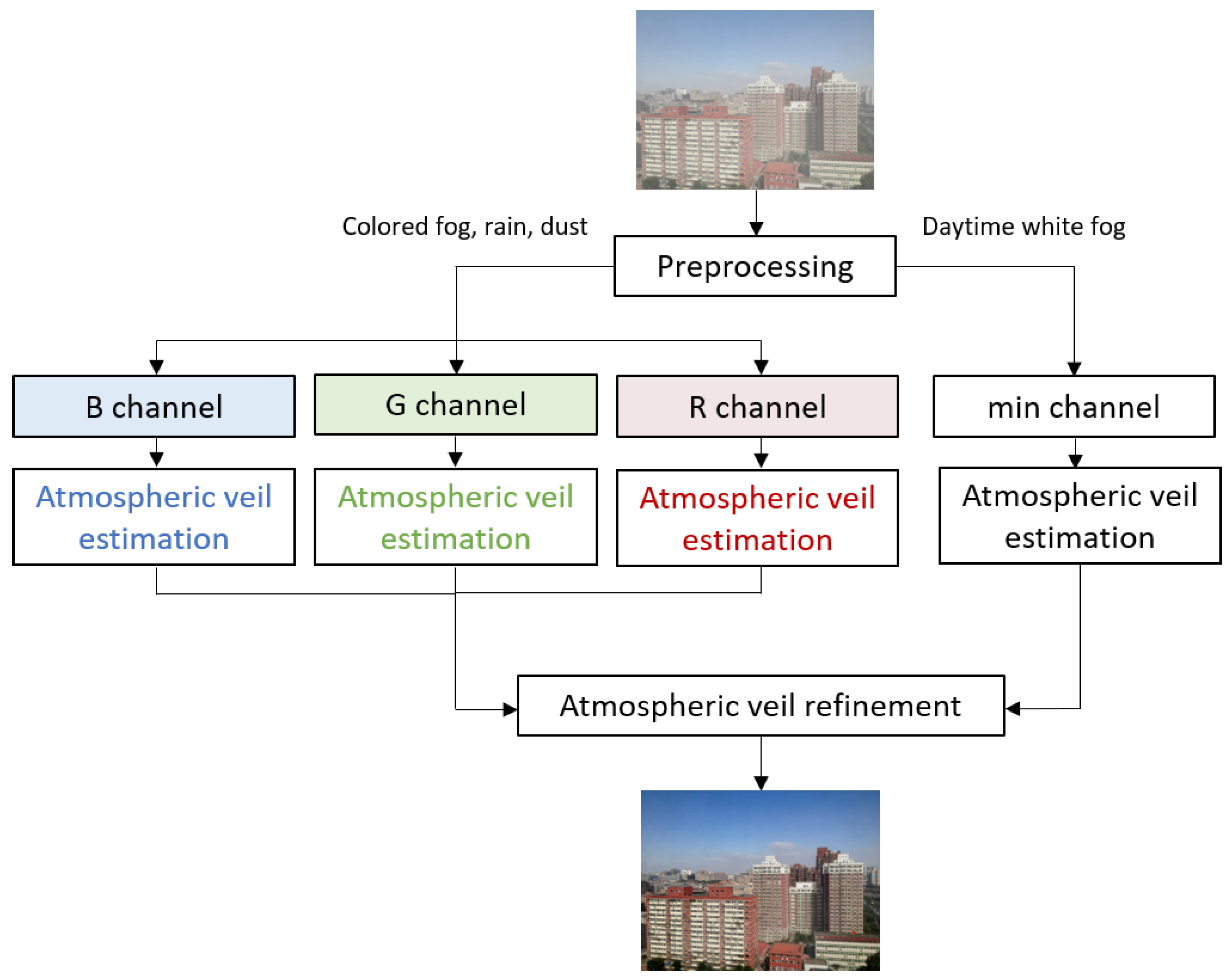
3.1. Algorithm Flowchart
- Daytime white fog: the pre-veil is computed from the color channel that has the minimum intensity. The fog is assumed to be homogeneous or may vary slowly in density from one pixel to another, but not in the viewing frustum of a pixel.
- Colored fog, rain, smoke, dust: the airlight cannot be assumed to be pure white, so color channels are processed separately by simply splitting the images into RGB channels. Then, the atmospheric veil is computed on each color channel. The density of airborne particles may vary slowly from a pixel to another.
3.2. Is the Use of ω a Valid Prior?
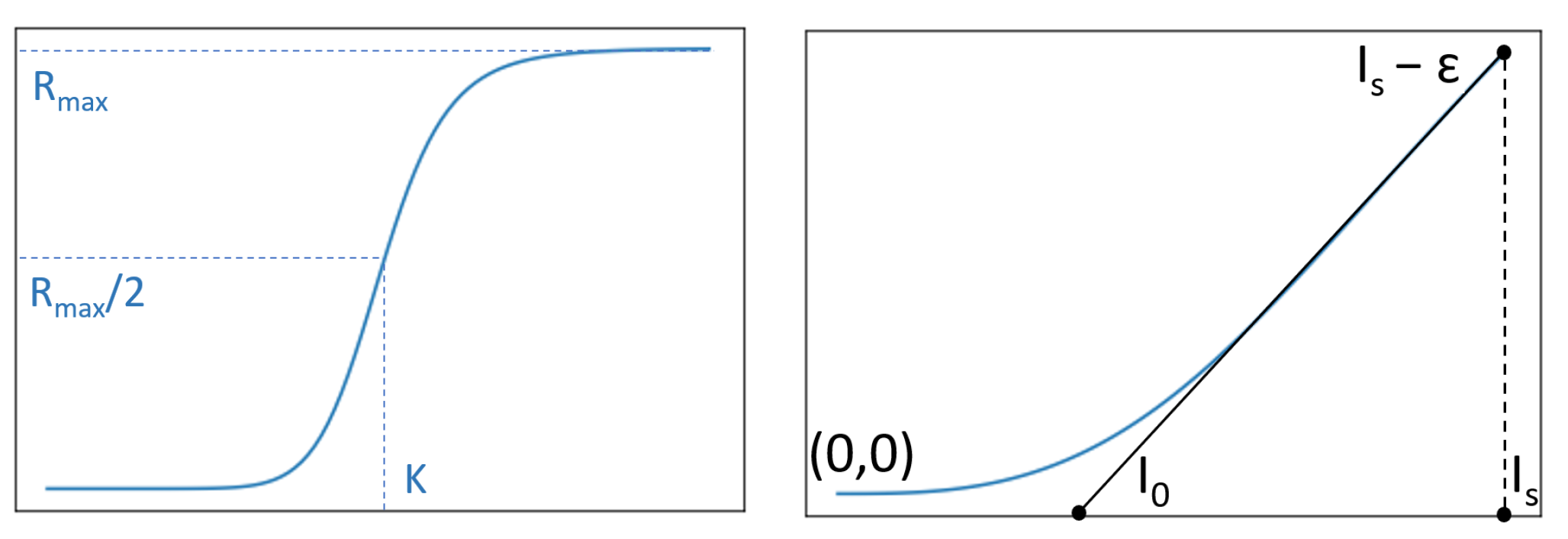
3.3. Modulation Function as a Prior
- The function f should be roughly linear on a large range of intensities. This range is denoted . We introduce here the slope a of f at , i.e., .
- The function is close to zero on the intensity range , i.e., for the intensities of pixels looking at objects that are close to the camera.
- The function and the restored image must not be negative.
- is the intensity of the clearest (sky) region. To avoid too dark values in the corresponding areas, should be a little lower than .We thus introduce a parameter such that in order to preserve the sky. is smoothly estimated as a function of .= 0.3 when is high ( > 0.8), = 0.05 when is low ( < 0.6). Between these values,
3.4. Naka–Rushton Function Parameters
3.5. Interpolation between Two Models
- Our modulation function: ;
- An interpolated function between and ;
- An interpolated function between and ;
- A switch between and at the threshold ;
- A switch between and at the threshold .
3.6. Beyond the White Fog Prior
4. Experimental Results
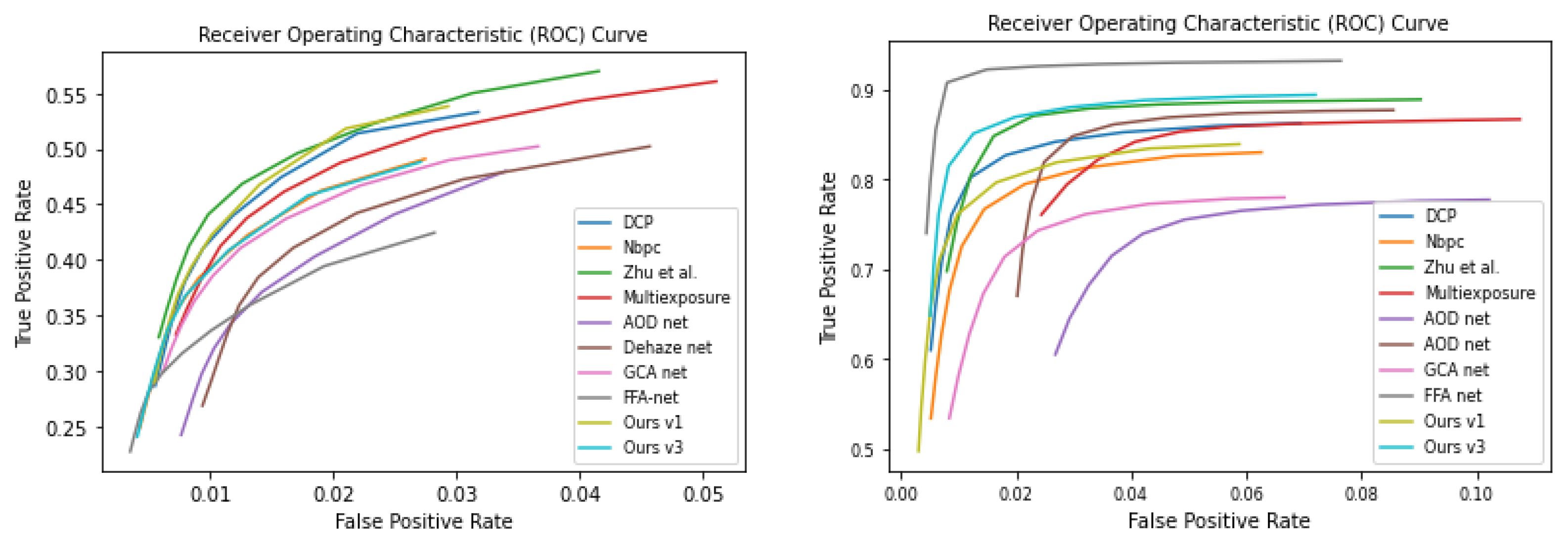
4.1. Quantitative Evaluation
4.1.1. Evaluation on Standard Metrics
4.1.2. Evaluation on Additional Metrics
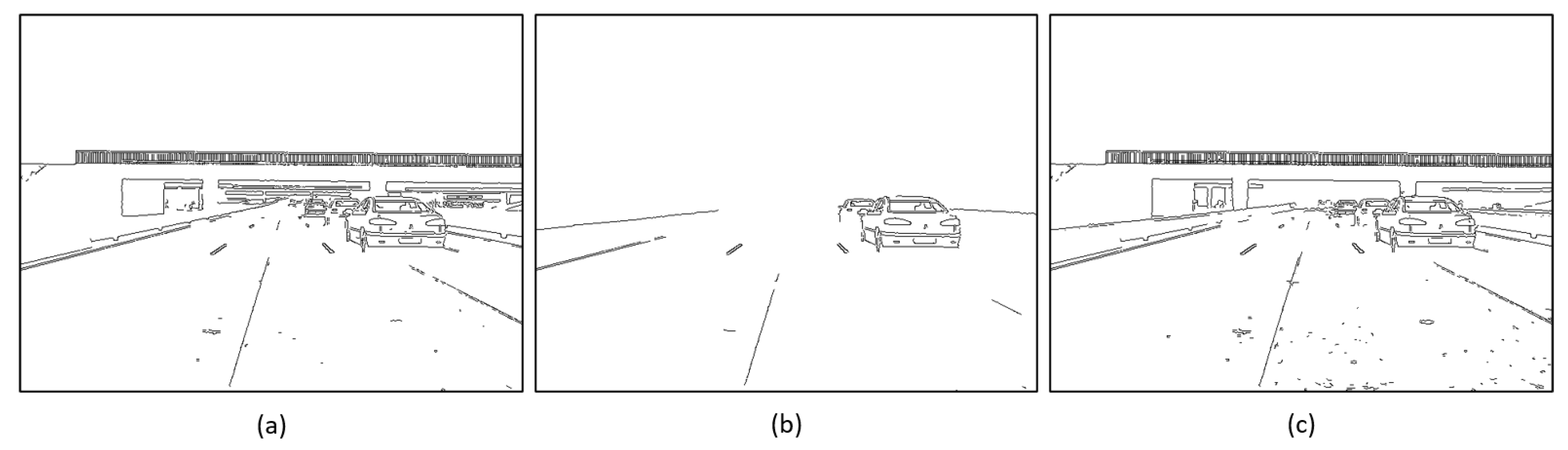
- d1: Weighted distance between the SSIM of the ground truth and the SSIM of the restored images (Figure 11a).
- d2: Weighted distance between the gradient of the ground truth and the gradient of the restored images (Figure 11b).
- d3: Weighted distance between the ground truth and the restored images (Figure 11c).
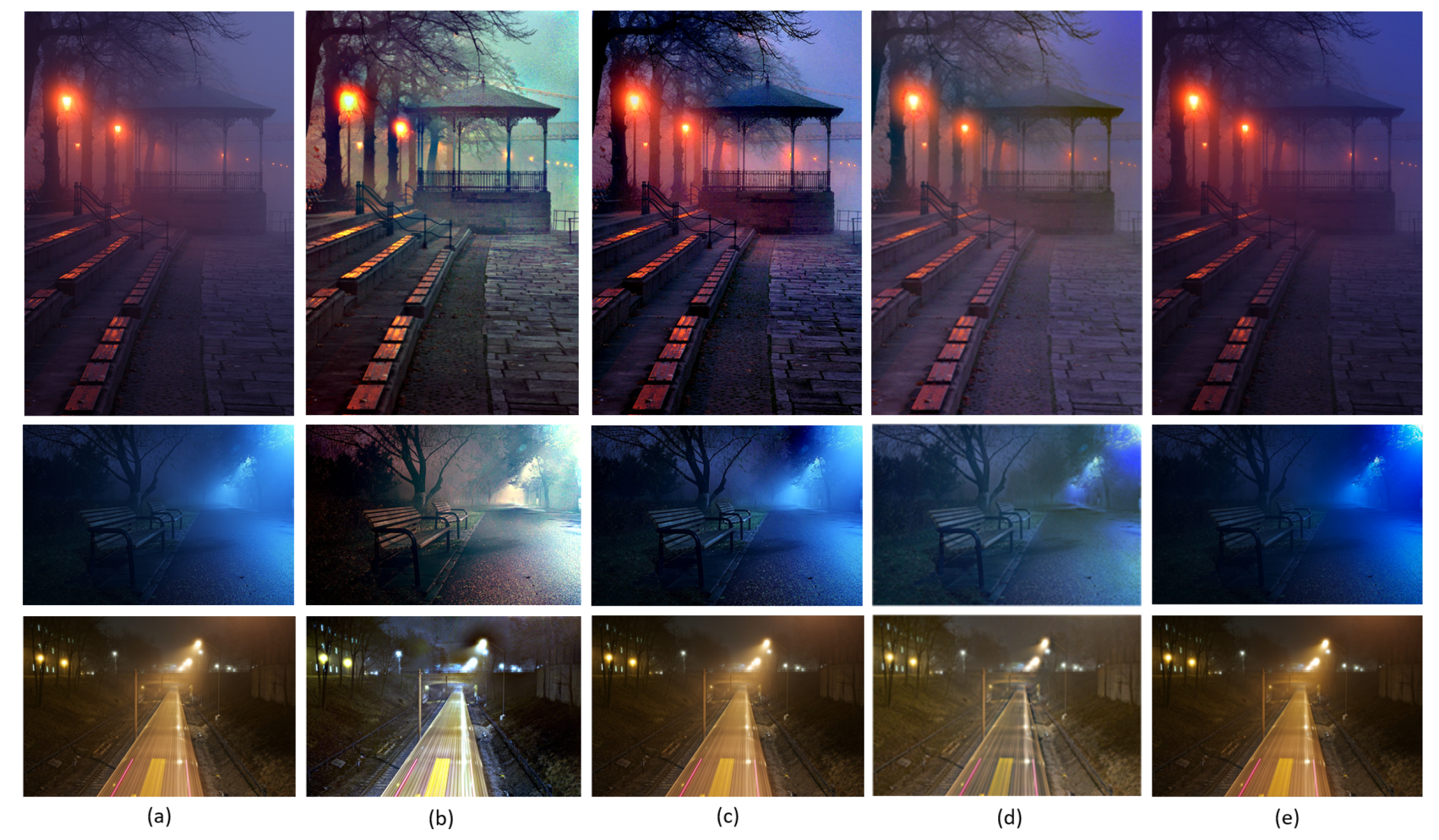
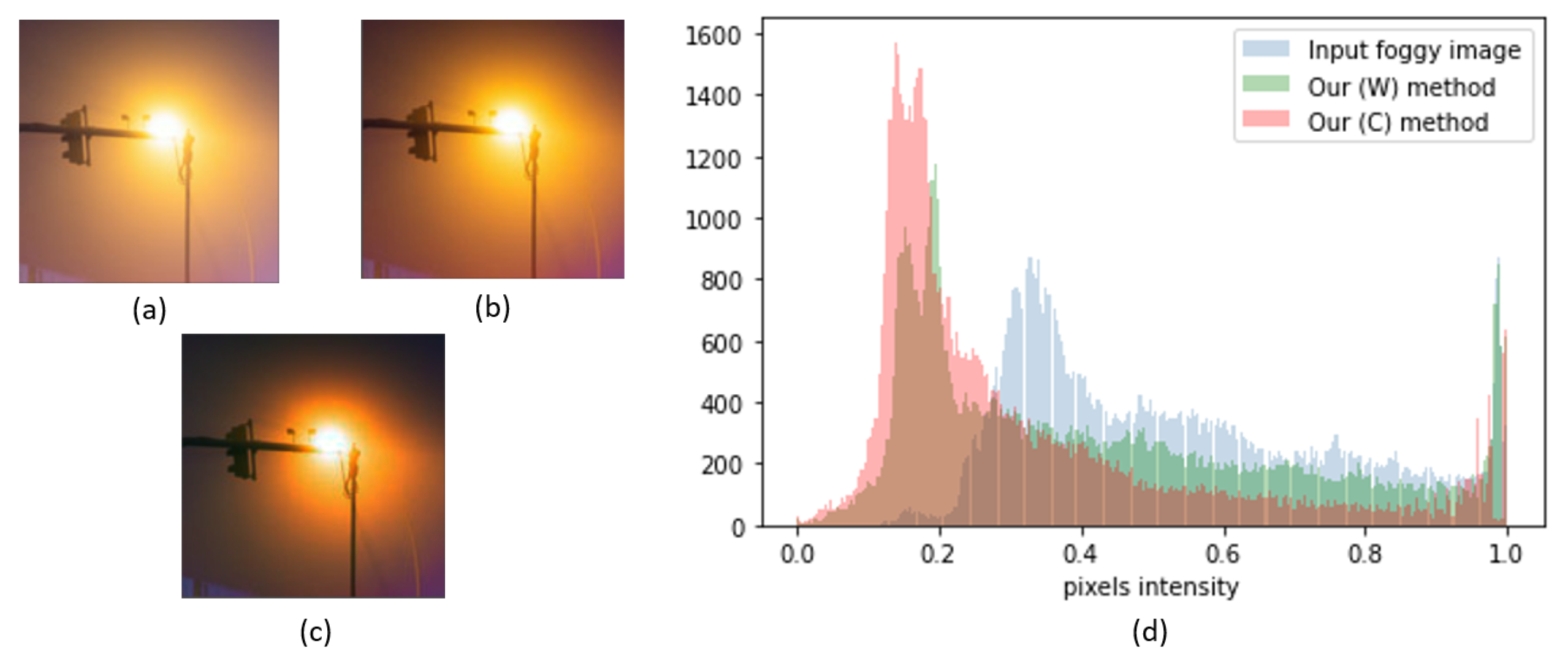
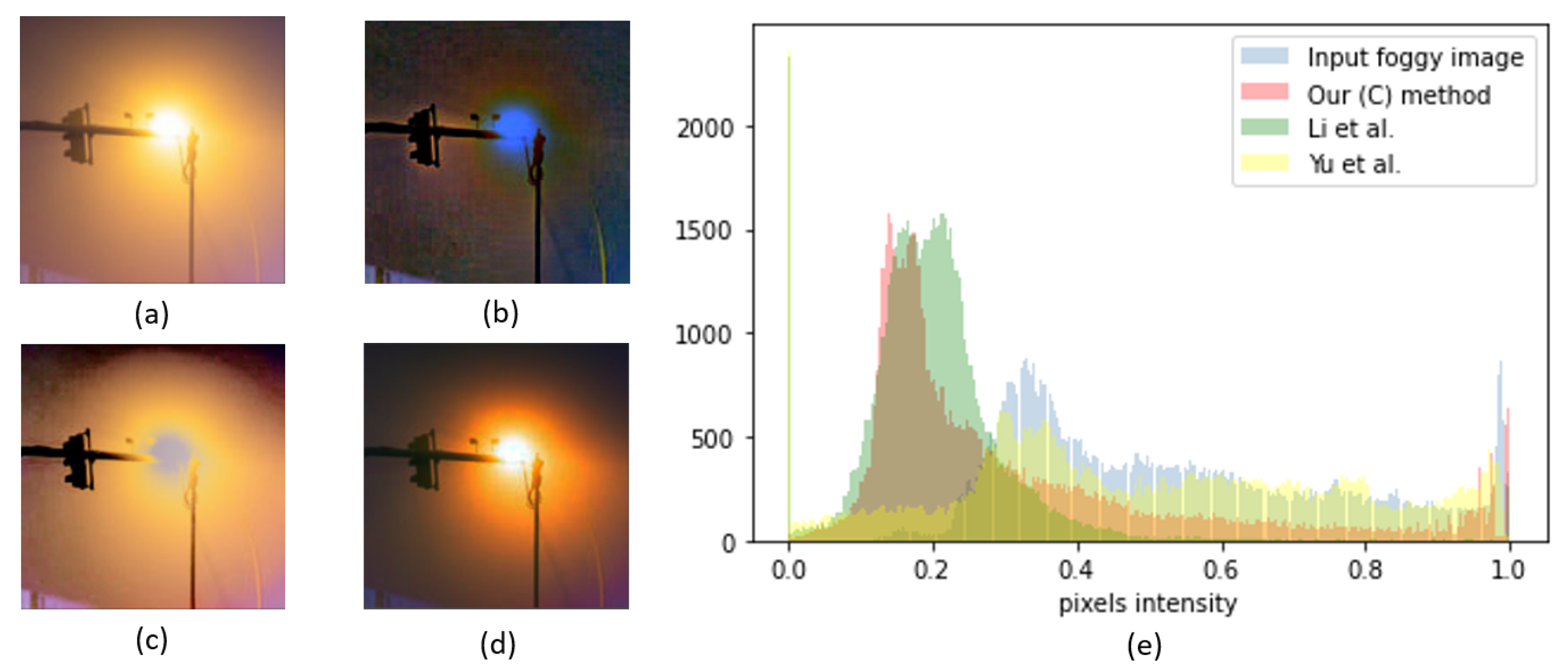
4.2. Qualitative Evaluation
4.3. Robustness of the Proposed Algorithm
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tremblay, M.; Halder, S.; De Charette, R.; Lalonde, J.F. Rain Rendering for Evaluating and Improving Robustness to Bad Weather. Int. J. Comput. Vis. Vol. 2020, 129, 341–360. [Google Scholar] [CrossRef]
- Huang, S.C.; Le, T.H.; Jaw, D.W. DSNet: Joint Semantic Learning for Object Detection in Inclement Weather Conditions. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 1. [Google Scholar] [CrossRef]
- Hautière, N.; Tarel, J.P.; Aubert, D. Towards Fog-Free In-Vehicle Vision Systems through Contrast Restoration. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Duminil, A.; Tarel, J.P.; Brémond, R. Single Image Atmospheric Veil Removal Using New Priors. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 1956–1963. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Guided image filtering. In Proceedings of the 2010 European Conference on Computer Vision (ECCV), Crete, Greece, 5–11 September 2010; pp. 1–14. [Google Scholar]
- Caraffa, L.; Tarel, J.P.; Charbonnier, P. The Guided Bilateral Filter: When the Joint/Cross Bilateral Filter Becomes Robust. IEEE Trans. Image Process. 2015, 24, 1199–1208. [Google Scholar] [CrossRef] [Green Version]
- Xu, H.; Guo, J.; Liu, Q.; Ye, L. Fast image dehazing using improved dark channel prior. In Proceedings of the 2012 IEEE International Conference on Information Science and Technology, Wuhan, China, 23–25 March 2012; pp. 663–667. [Google Scholar] [CrossRef]
- Meng, G.; Wang, Y.; Duan, J.; Xiang, S.; Pan, C. Efficient Image Dehazing with Boundary Constraint and Contextual Regularization. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 617–624. [Google Scholar] [CrossRef]
- Li, Z.; Zheng, J. Edge-Preserving Decomposition-Based Single Image Haze Removal. IEEE Trans. Image Process. 2015, 24, 5432–5441. [Google Scholar] [CrossRef]
- Zhu, M.; He, B.; Wu, Q. Single Image Dehazing Based on Dark Channel Prior and Energy Minimization. IEEE Signal Process. Lett. 2018, 25, 174–178. [Google Scholar] [CrossRef]
- Jackson, J.; Kun, S.; Agyekum, K.O.; Oluwasanmi, A.; Suwansrikham, P. A Fast Single-Image Dehazing Algorithm Based on Dark Channel Prior and Rayleigh Scattering. IEEE Access 2020, 8, 73330–73339. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, Y.; Lu, J. Single image dehazing using a novel criterion based segmenting dark channel prior. In Proceedings of the 2019 Eleventh International Conference on Graphics and Image Processing (ICGIP); Pan, Z., Wang, X., Eds.; SPIE: Hangzhou, China, 2020; p. 121. [Google Scholar] [CrossRef]
- Tarel, J.P.; Hautiere, N. Fast visibility restoration from a single color or gray level image. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009; pp. 2201–2208. [Google Scholar] [CrossRef]
- Tarel, J.P.; Hautiere, N.; Caraffa, L.; Cord, A.; Halmaoui, H.; Gruyer, D. Vision Enhancement in Homogeneous and Heterogeneous Fog. IEEE Intell. Transp. Syst. Mag. 2012, 4, 6–20. [Google Scholar] [CrossRef] [Green Version]
- Negru, M.; Nedevschi, S.; Peter, R.I. Exponential Contrast Restoration in Fog Conditions for Driving Assistance. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2257–2268. [Google Scholar] [CrossRef]
- Ancuti, C.O.; Ancuti, C.; Bekaert, P. Effective single image dehazing by fusion. In Proceedings of the 2010 IEEE International Conference on Image Processing (ICIP), Hong Kong, China, 26–29 September 2010; pp. 3541–3544. [Google Scholar] [CrossRef]
- Ancuti, C.O.; Ancuti, C. Single Image Dehazing by Multi-Scale Fusion. IEEE Trans. Image Process. 2013, 22, 3271–3282. [Google Scholar] [CrossRef]
- Wang, Q.; Zhao, L.; Tang, G.; Zhao, H.; Zhang, X. Single-Image Dehazing Using Color Attenuation Prior Based on Haze-Lines. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 5080–5087. [Google Scholar] [CrossRef]
- Zheng, M.; Qi, G.; Zhu, Z.; Li, Y.; Wei, H.; Liu, Y. Image Dehazing by an Artificial Image Fusion Method Based on Adaptive Structure Decomposition. IEEE Sens. J. 2020, 20, 8062–8072. [Google Scholar] [CrossRef]
- Zhu, Z.; Wei, H.; Hu, G.; Li, Y.; Qi, G.; Mazur, N. A Novel Fast Single Image Dehazing Algorithm Based on Artificial Multiexposure Image Fusion. IEEE Trans. Instrum. Meas. 2021, 70, 1–23. [Google Scholar] [CrossRef]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. DehazeNet: An End-to-End System for Single Image Haze Removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.H. Single Image Dehazing via Multi-scale Convolutional Neural Networks. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; pp. 154–169. [Google Scholar] [CrossRef]
- Meinhardt, T.; Moeller, M.; Hazirbas, C.; Cremers, D. Learning Proximal Operators: Using Denoising Networks for Regularizing Inverse Imaging Problems. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1799–1808. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. An All-in-One Network for Dehazing and Beyond. arXiv 2017, arXiv:1707.06543. [Google Scholar]
- Chen, D.; He, M.; Fan, Q.; Liao, J.; Zhang, L.; Hou, D.; Yuan, L.; Hua, G. Gated Context Aggregation Network for Image Dehazing and Deraining. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1375–1383. [Google Scholar] [CrossRef] [Green Version]
- Engin, D.; Genc, A.; Ekenel, H.K. Cycle-Dehaze: Enhanced CycleGAN for Single Image Dehazing. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 938–9388. [Google Scholar] [CrossRef] [Green Version]
- Zhu, H.; Peng, X.; Chandrasekhar, V.; Li, L.; Lim, J.H. DehazeGAN: When Image Dehazing Meets Differential Programming. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Stockholm, Sweden, 13–19 July 2018; p. 7. [Google Scholar]
- Naka, K.I.; Rushton, W.A.H. S-potentials from color units in the retina of fish (Cyprinidae). J. Physiol. 1966, 185. [Google Scholar] [CrossRef]
- Li, Y.; Tan, R.T.; Brown, M.S. Nighttime Haze Removal with Glow and Multiple Light Colors. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 226–234. [Google Scholar] [CrossRef]
- Ancuti, C.; Ancuti, C.O.; De Vleeschouwer, C.; Bovik, A.C. Night-time dehazing by fusion. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 2256–2260. [Google Scholar] [CrossRef]
- Zhang, J.; Cao, Y.; Fang, S.; Kang, Y.; Chen, C.W. Fast Haze Removal for Nighttime Image Using Maximum Reflectance Prior. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7016–7024. [Google Scholar] [CrossRef]
- Lou, W.; Li, Y.; Yang, G.; Chen, C.; Yang, H.; Yu, T. Integrating Haze Density Features for Fast Nighttime Image Dehazing. IEEE Access 2020, 8, 113318–113330. [Google Scholar] [CrossRef]
- Petzold, D. What the Fog-Street Photography by Mark Broyer. WE AND THE COLOR. 2017. Available online: https://weandthecolor.com/what-the-fog-street-photography-mark-broyer/92328 (accessed on 29 April 2021).
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking Single-Image Dehazing and Beyond. IEEE Trans. Image Process. 2019, 28, 492–505. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature Fusion Attention Network for Single Image Dehazing. Proc. AAAI Conf. Artif. Intell. 2020, 34, 11908–11915. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A Feature Similarity Index for Image Quality Assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [Green Version]
- Ancuti, C.O.; Ancuti, C.; Timofte, R.; De Vleeschouwer, C. O-HAZE: A Dehazing Benchmark With Real Hazy and Haze-Free Outdoor Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 754–762. [Google Scholar]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar] [CrossRef] [PubMed]
- Yu, T.; Song, K.; Miao, P.; Yang, G.; Yang, H.; Chen, C. Nighttime Single Image Dehazing via Pixel-Wise Alpha Blending. IEEE Access 2019, 7, 114619–114630. [Google Scholar] [CrossRef]
- Zhang, J.; Cao, Y.; Zha, Z.J.; Tao, D. Nighttime Dehazing with a Synthetic Benchmark. In Proceedings of the 28th ACM International Conference on Multimedia (ICM), Seattle, WA, USA, 12–16 October 2020; pp. 2355–2363. [Google Scholar]
- Hirschmüller, H.; Scharstein, D. Evaluation of cost functions for stereo matching. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2007), Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar]
- Wang, Y.; Song, W.; Fortino, G.; Qi, L.Z.; Zhang, W.; Liotta, A. An Experimental-Based Review of Image Enhancement and Image Restoration Methods for Underwater Imaging. IEEE Access 2019, 7, 140233–140251. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SSIM|PSNR | ||||
|---|---|---|---|---|
| Functions | FRIDA | SOTS | NTIRE20 | O-HAZE |
| 0.81|13.34 | 0.85|18.40 | 0.50|13.22 | 0.64|16.32 | |
| 0.78|11.65 | 0.93|24.40 | 0.49|12.75 | 0.66|16.57 | |
| 0.78|11.74 | 0.93|24.00 | 0.48|12.57 | 0.66|16.47 | |
| 0.79|13.09 | 0.91|23.01 | 0.49|12.85 | 0.66|16.62 | |
| 0.79|13.29 | 0.88|21.62 | 0.46|12.01 | 0.64|16.07 | |
| PSNR | ||||
|---|---|---|---|---|
| Methods | FRIDA | SOTS | NTIRE20 | O-HAZE |
| DCP [6] | 12.26 (1.55) | 18.91 (3.85) | 12.77 (1.67) | 16.95 (2.38) |
| NBPC [15] | 11.59 (1.73) | 18.07 (2.46) | 12.24 (1.51) | 15.85 (1.78) |
| Zhu et al. [12] | 12.15 (1.77) | 16.06 (2.74) | 11.98 (1.67) | 16.58 (2.53) |
| Zhu et al. [22] | 11.93 (1.73) | 19.13 (2.52) | 13.29 (1.48) | 16.81 (2.58) |
| AOD-Net [26] | 10.73 (1.84) | 19.39 (2.32) | 11.98 (1.57) | 15.04 (1.65) |
| Dehaze-Net [23] | 10.87 (1.52) | 23.41 (3.54) | 12.33 (1.56) | 15.41 (2.75) |
| GCA-Net [27] | 12.79 (1.49) | 22.68 (4.97) | 12.82 (2.23) | 16.43 (2.78) |
| FFA-Net [37] | 10.38 (1.96) | 34.10 (3.51) | 12.40 (1.64) | 16.19 (3.18) |
| W | 12.62 (2.05) | 18.40 (2.90) | 13.16 (1.45) | 17.02 (2.66) |
| C | 12.27 (2.04) | 16.77 (2.86) | 13.90 (1.57) | 18.32 (2.74) |
| I | 11.65 (1.93) | 24.40 (3.94) | 12.69 (1.57) | 16.57 (3.29) |
| SSIM | ||||
|---|---|---|---|---|
| Methods | FRIDA | SOTS | NTIRE20 | O-HAZE |
| DCP [6] | 0.70 (0.06) | 0.89 (0.06) | 0.44 (0.10) | 0.66 (0.10) |
| NBPC [15] | 0.75 (0.07) | 0.89 (0.03) | 0.41 (0.09) | 0.61 (0.09) |
| Zhu et al. [12] | 0.72 (0.06) | 0.88 (0.04) | 0.45 (0.10) | 0.66 (0.10) |
| Zhu et al. [22] | 0.75 (0.06) | 0.86 (0.07) | 0.55 (0.09) | 0.67 (0.10) |
| AOD-Net [26] | 0.73 (0.07) | 0.85 (0.05) | 0.41 (0.09) | 0.54 (0.01) |
| Dehaze-Net [23] | 0.65 (0.07) | 0.90 (0.09) | 0.44 (0.10) | 0.60 (0.10) |
| GCA-Net [27] | 0.70 (0.08) | 0.91 (0.06) | 0.47 (0.10) | 0.61 (0.10) |
| FFA-Net [37] | 0.73 (0.08) | 0.98 (0.01) | 0.46 (0.10) | 0.63 (0.10) |
| W | 0.81 (0.07) | 0.85 (0.08) | 0.51 (0.09) | 0.65 (0.11) |
| C | 0.81 (0.07) | 0.82 (0.08) | 0.51 (0.09) | 0.67 (0.11) |
| I | 0.78 (0.07) | 0.93 (0.05) | 0.48 (0.09) | 0.66 (0.12) |
| FSIMc | ||||
|---|---|---|---|---|
| Methods | FRIDA | SOTS | NTIRE20 | O-HAZE |
| DCP [6] | 0.83 (0.06) | 0.96 (0.02) | 0.55 (0.07) | 0.85 (0.06) |
| NBPC [15] | 0.81 (0.06) | 0.96 (0.01) | 0.53 (0.06) | 0.80 (0.08) |
| Zhu et al. [12] | 0.82 (0.06) | 0.96 (0.01) | 0.55 (0.06) | 0.82 (0.08) |
| Zhu et al. [22] | 0.81 (0.06) | 0.95 (0.02) | 0.73 (0.05) | 0.85 (0.08) |
| AOD-Net [26] | 0.79 (0.06) | 0.93 (0.02) | 0.67 (0.06) | 0.78 (0.08) |
| Dehaze-Net [23] | 0.81 (0.06) | 0.98 (0.01) | 0.53 (0.07) | 0.78 (0.09) |
| GCA-Net [27] | 0.80 (0.05) | 0.97 (0.02) | 0.74 (0.06) | 0.87 (0.06) |
| FFA-Net [37] | 0.79 (0.06) | 0.99 (0.004) | 0.66 (0.07) | 0.80 (0.09) |
| W | 0.83 (0.06) | 0.95 (0.02) | 0.70 (0.06) | 0.84 (0.07) |
| C | 0.83 (0.06) | 0.95 (0.02) | 0.71 (0.06) | 0.85 (0.07) |
| I | 0.82 (0.06) | 0.98 (0.01) | 0.69 (0.06) | 0.83 (0.08) |
| Methods | d1 | d2 | d3 |
|---|---|---|---|
| DCP [6] | 0.01 (0.05) | 0.08 (0.003) | 24.3 (8.6) |
| NBPC [15] | 0.08 (0.02) | 0.01 (0.003) | 23.4 (10.8) |
| Zhu et al. [12] | 0.60 (0.03) | 0.05 (0.02) | 67.7 (12.7) |
| Zhu et al. [22] | 0.10 (0.05) | 0.01 (0.004) | 33.5 (15.8) |
| AOD-Net [26] | 0.12 (0.04) | 0.01 (0.003) | 28.4 (16.6) |
| Dehaze-Net [23] | 0.06 (0.05) | 0.006 (0.002) | 24.0 (15.6) |
| GCA-Net [27] | 0.08 (0.04) | 0.01 (0.004) | 22.7 (15.6) |
| FFA-Net [37] | 0.01 (0.005) | 0.004 (0.001) | 4.97 (2.3) |
| W (white fog) | 0.10 (0.06) | 0.009 (0.002) | 42.0 (16.8) |
| C (color) | 0.08 (0.06) | 0.01(0.002) | 30.3 (16.8) |
| I (interpolation) | 0.04(0.03) | 0.006(0.003) | 23.5 (14.9) |
| Methods | d1 | d2 | d3 |
|---|---|---|---|
| DCP [6] | 0.09 (0.05) | 0.01 (0.003) | 16.4 (6.5) |
| NBPC [15] | 0.10 (0.04) | 0.01 (0.003) | 15.0 (4.5) |
| Zhu et al. [12] | 0.70 (0.05) | 0.05 (0.002) | 54.5 (5.25) |
| Zhu et al. [22] | 0.15 (0.08) | 0.02 (0.005) | 19.8 (5.0) |
| AOD-Net [26] | 0.20 (0.06) | 0.02 (0.004) | 18.7 (6.9) |
| Dehaze-Net [23] | 0.12 (0.1) | 0.007 (0.002) | 14.8 (6.6) |
| GCA-Net [27] | 0.11 (0.05) | 0.01 (0.005) | 15.4 (8.2) |
| FFA-Net [37] | 0.01 (0.008) | 0.005 (0.001) | 4.40 (1.9) |
| W (white fog) | 0.20 (0.1) | 0.009 (0.003) | 24.5 (5.7) |
| C (color) | 0.11 (0.1) | 0.01 (0.003) | 18.8 (5.9) |
| I (interpolation) | 0.08 (0.06) | 0.006 (0.002) | 14.2 (6.1) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duminil, A.; Tarel, J.-P.; Brémond, R. Single Image Atmospheric Veil Removal Using New Priors for Better Genericity. Atmosphere 2021, 12, 772. https://doi.org/10.3390/atmos12060772
Duminil A, Tarel J-P, Brémond R. Single Image Atmospheric Veil Removal Using New Priors for Better Genericity. Atmosphere. 2021; 12(6):772. https://doi.org/10.3390/atmos12060772
Chicago/Turabian StyleDuminil, Alexandra, Jean-Philippe Tarel, and Roland Brémond. 2021. "Single Image Atmospheric Veil Removal Using New Priors for Better Genericity" Atmosphere 12, no. 6: 772. https://doi.org/10.3390/atmos12060772
APA StyleDuminil, A., Tarel, J.-P., & Brémond, R. (2021). Single Image Atmospheric Veil Removal Using New Priors for Better Genericity. Atmosphere, 12(6), 772. https://doi.org/10.3390/atmos12060772