
Rainfall Forecast Model Based on the TabNet Model

Abstract
1. Introduction
- (1)
- We proposed a self-supervised pre-training method for rainfall prediction, which would help the model to accelerate the convergence speed and maintain stability. This method could also provide a reference for self-supervised pre-training of tabular data.
- (2)
- We proposed feature engineering methods and training strategies that could alleviate the adverse effects of seasonal changes on rainfall prediction.
- (3)
- We proposed a new method that combined satellite observation of rainfall with machine learning to predict rainfall.
2. Data
3. Methodology
3.1. TabNet
- (1)
- The tree model has a decision manifold [23], which approximates the boundary of the hyperplane. The boundary of the hyperplane can effectively divide the data so that the tree model has an efficient representation of tabular data.
- (2)
- Good interpretability.
- (3)
- Fast training speed.
3.1.1. Feature Selection
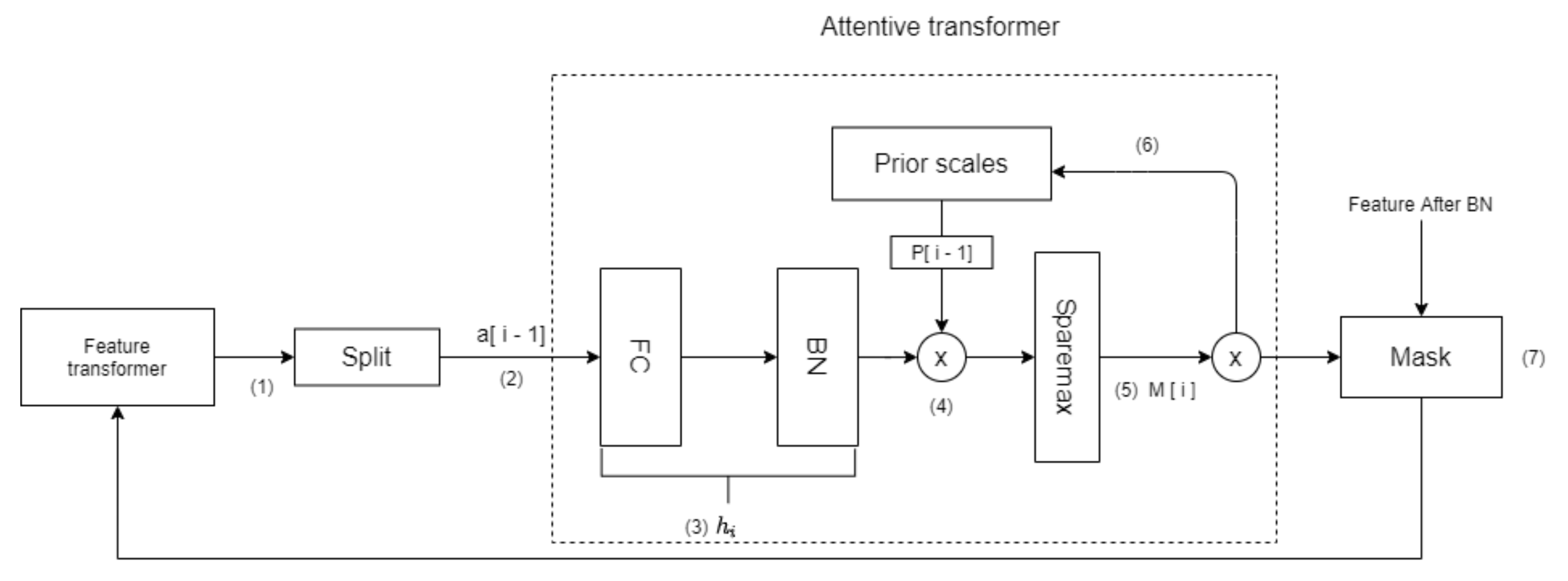
- (1)
- First, the Feature transformer of the previous decision step outputs the tensor and sends it to the Split module.
- (2)
- The Split module splits the tensor in step 1 and obtains .
- (3)
- passes through the layer, which represents a fully-connected (FC) layer and a BN layer. The role of is to achieve the linear combination of features, thereby extracting higher-dimensional and more abstract features.
- (4)
- The output of the layer is multiplied by the prior scale of the previous decision step. The prior scale represents the use of features in previous decision steps. The more features used in the previous decision step, the smaller the weight in the current decision step.
- (5)
- The is then generated through Sparsemax [25]. Equation (1) represents this process of learning a mask:Sparsemax encourages sparsity by mapping the Euclidean projection onto the probabilistic simplex, make feature selection more sparse. Sparsemax can make , where D represents the dimension of the feature. Sparsemax implements weight distribution for each feature, j, of each sample, b, and makes the sum of the weights of all features of each sample to 1, thus realizing instance-wise [26] feature selection which makes TabNet use the most beneficial features for the model in each decision step. To control the sparsity of the selected features, TabNet uses the sparse regular term:When most of the features of the data set are redundant, the sparsity of feature selection can provide better inductive bias for convergence to a higher accuracy rate.
- (6)
- uses Equation (3) to update :When γ = 1, it means that each feature can only appear in one decision step.
- (7)
- and feature elements are multiplied to realize the feature selection of the current decision step.
- (8)
- The selected features are then inputted into the feature transformer of the current decision step, and a new decision step loop is started.
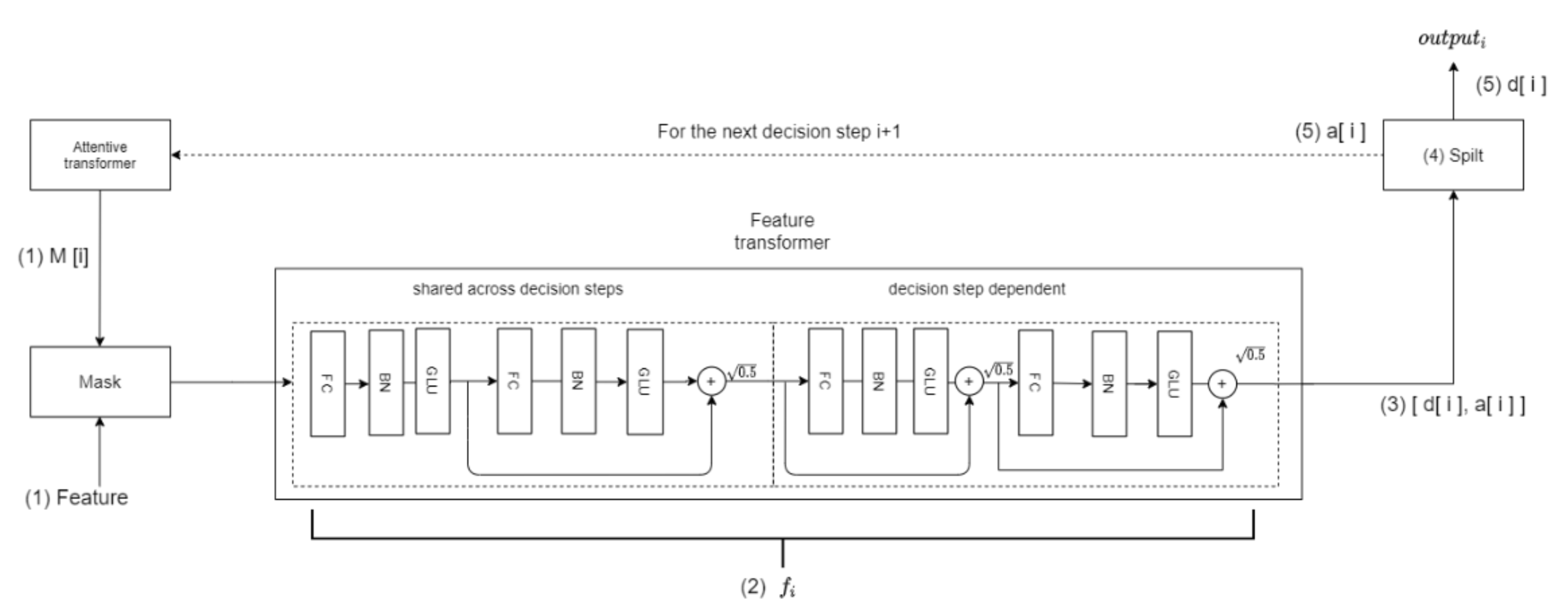
3.1.2. Feature Processing
3.1.3. TabNet Decoder Architecture
3.2. Feature Engineering
3.2.1. Feature Construction
3.2.2. Statistical Features
3.3. Self-Supervised Pretraining
4. Model Evaluations
5. Results
5.1. Hyperparameter
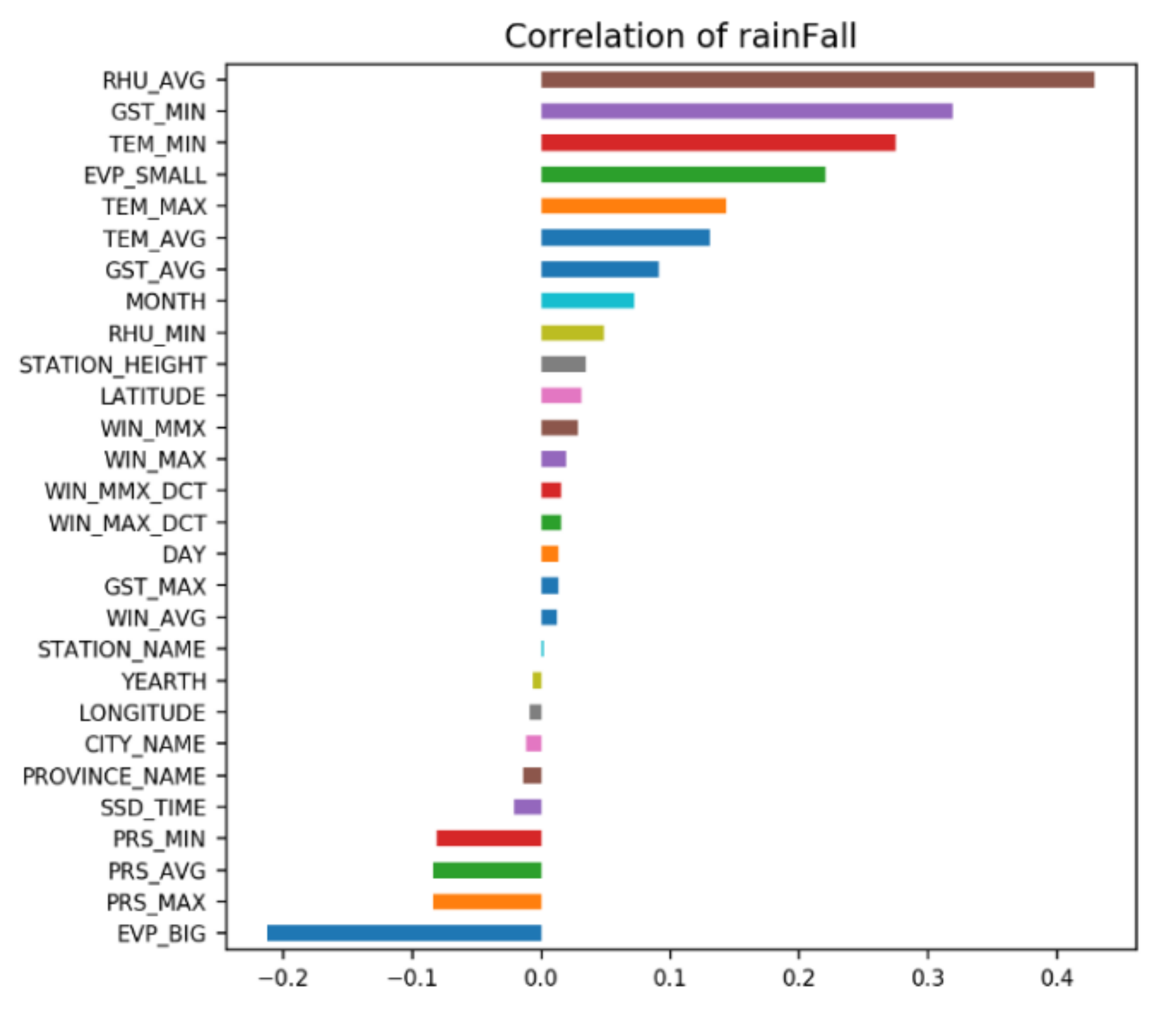
5.2. The Result of Feature Selection
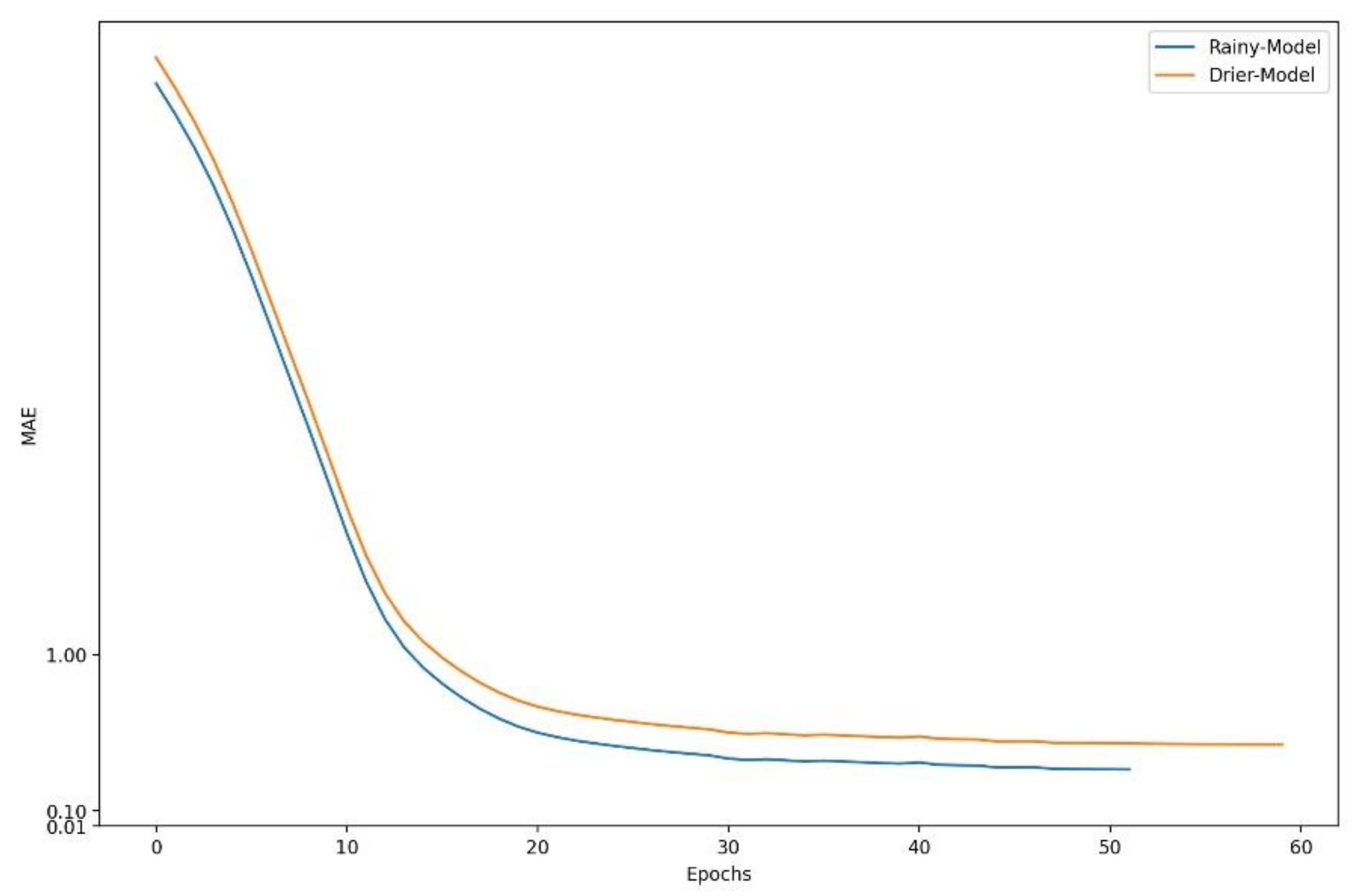
5.3. Convergence
6. Discussion
6.1. Extreme Rainfall
6.2. The Final Model
6.3. Comparative Experiments
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jiang, T.; Su, B.; Hartmann, H. Temporal and spatial trends of precipitation and river flow in the Yangtze River Basin, 1961–2000. Geomorphology 2007, 85, 143–154. [Google Scholar] [CrossRef]
- Xingchuang, X.U.; Xuezhen, Z.; Erfu, D.; Wei, S. Research of trend variability of precipitation intensity and their contribution to precipitation in China from 1961 to 2010. Geogr. Res. 2014, 33, 1335–1347. [Google Scholar]
- Pranatha, M.D.A.; Pramaita, N.; Sudarma, M.; Widyantara, I.M.O. Filtering Outlier Data Using Box Whisker Plot Method for Fuzzy Time Series Rainfall Forecasting. In Proceedings of the 2018 4th International Conference on Wireless and Telematics (ICWT), Bali, Indonesia, 12–13 July 2018. [Google Scholar]
- Maheswaran, R.; Khosa, R. A Wavelet-Based Second Order Nonlinear Model for Forecasting Monthly Rainfall. Water Resour. Manag. 2014, 28, 5411–5431. [Google Scholar] [CrossRef]
- Qiu, J.; Shen, Z.; Wei, G.; Wang, G.; Lv, G. A systematic assessment of watershed-scale nonpoint source pollution during rainfall-runoff events in the Miyun Reservoir watershed. Environ. Sci. Eur. 2018, 25, 6514. [Google Scholar] [CrossRef] [PubMed]
- Chau, K.W.; Wu, C.L. A hybrid model coupled with singular spectrum analysis for daily rainfall prediction. J. Hydroinform. 2010, 12, 458–473. [Google Scholar] [CrossRef]
- Zhang, L.; Dai, A.; Hove, T.V.; Baelen, J.V. A near-global, 2-hourly data set of atmospheric precipitable water from ground-based GPS measurements. J. Geophys. Res. Atmos. 2007, 112. [Google Scholar] [CrossRef]
- He, C.; Wu, S.; Wang, X.; Hu, A.; Wang, Q.; Zhang, K. A new voxel-based model for the determination of atmospheric weighted mean temperature in GPS atmospheric sounding. Atmos. Meas. Tech. 2017, 10, 2045–2060. [Google Scholar] [CrossRef]
- Benevides, P.; Catalao, J.; Miranda, P. On the inclusion of GPS precipitable water vapour in the nowcasting of rainfall. Nat. Hazards Earth Syst. Sci. 2015, 3, 3861–3895. [Google Scholar]
- Yin, J.; Guo, S.; Gu, L.; Zeng, Z.; Xu, C.Y. Blending multi-satellite, atmospheric reanalysis and gauge precipitation products to facilitate hydrological modelling. J. Hydrol. 2020, 593, 125878. [Google Scholar] [CrossRef]
- Zhou, Y.; Qin, N.; Tang, Q.; Shi, H.; Gao, L. Assimilation of Multi-Source Precipitation Data over Southeast China Using a Nonparametric Framework. Remote Sens. 2021, 13, 1057. [Google Scholar] [CrossRef]
- Bhuiyan, A.E.; Yang, F.; Biswas, N.K.; Rahat, S.H.; Neelam, T.J. Machine Learning-Based Error Modeling to Improve GPM IMERG Precipitation Product over the Brahmaputra River Basin. Forecasting 2020, 2, 248–266. [Google Scholar] [CrossRef]
- Derin, Y.; Bhuiyan, M.; Anagnostou, E.; Kalogiros, J.; Anagnostou, M.N. Modeling Level 2 Passive Microwave Precipitation Retrieval Error Over Complex Terrain Using a Nonparametric Statistical Technique. IEEE 2020. [Google Scholar] [CrossRef]
- Xiang, B.; Zeng, C.; Dong, X.; Wang, J. The Application of a Decision Tree and Stochastic Forest Model in Summer Precipitation Prediction in Chongqing. Atmosphere 2020, 11, 508. [Google Scholar] [CrossRef]
- Lee, Y.-M.; Ko, C.-M.; Shin, S.-C.; Kim, B.-S. The Development of a Rainfall Correction Technique based on Machine Learning for Hydrological Applications. J. Environ. Sci. Int. 2019, 28, 125–135. [Google Scholar] [CrossRef]
- Zhang, L.; Li, X.; Zheng, D.; Zhang, K.; Ge, Y. Merging multiple satellite-based precipitation products and gauge observations using a novel double machine learning approach. J. Hydrol. 2021, 594, 125969. [Google Scholar] [CrossRef]
- Arik, S.O.; Pfister, T. TabNet: Attentive Interpretable Tabular Learning. arXiv 2019, arXiv:1908.07442. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Conneau, A.; Schwenk, H.; Barrault, L.; Lecun, Y. Very Deep Convolutional Networks for Text Classification. arXiv 2016, arXiv:1606.01781. [Google Scholar]
- Amodei, D.; Anubhai, R.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Chen, J.; Chrzanowski, M.; Coates, A.; Diamos, G.; et al. Deep Speech 2: End-to-End Speech Recognition in English and Mandarin. arXiv 2015, arXiv:1512.02595. [Google Scholar]
- Chen, T.Q.; Guestrin, C. XGBoost: A Scalable Tree Boosting System; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2018. [Google Scholar]
- Polzlbauer, G.; Lidy, T.; Rauber, A. Decision Manifolds—A Supervised Learning Algorithm Based on Self-Organization. IEEE Trans. Neural Netw. 2008, 19, 1518–1530. [Google Scholar] [CrossRef]
- Grbovic, M.; Cheng, H.B. Real-Time Personalization using Embeddings for Search Ranking at Airbnb; Association for Computing Machinery: New York, NY, USA, 2018; pp. 311–320. [Google Scholar]
- Martins, A.F.T.; Fernandez Astudillo, R. From Softmax to Sparsemax: A Sparse Model of Attention and Multi-Label Classification. arXiv 2016, arXiv:1602.02068. [Google Scholar]
- Yoon, J.; Jordon, J.; van der Schaar, M. INVASE: Instance-Wise Variable Selection using Neural Networks. In Proceedings of the Seventh International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Shilpa, M.; Hui, L.Y.; Song, M.Y.; Feng, Y.; Teong, O.J. GPS-Derived PWV for Rainfall Nowcasting in Tropical Region. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4835–4844. [Google Scholar]
- Li, P.; Wang, X.; Chen, Y.; Lai, S. Use of GPS Signal Delay for Real-time Atmospheric Water Vapour Estimation and Rainfall Nowcast in Hong Kong. In Proceedings of the The First International Symposium on Cloud-Prone and Rainy Areas Remote Sensing, Chinese University of Hong Kong, Hong Kong, 6–8 October 2005; pp. 6–8. [Google Scholar]
- Saastamoinen, J.H. Atmospheric Correction for the Troposphere and the Stratosphere in Radio Ranging Satellites. In The Use of Artificial Satellites for Geodesy; American Geophysical Union: Washington, DC, USA, 1972; Volume 15. [Google Scholar]
- Gupta, H.V.; Kling, H.; Yilmaz, K.K.; Martinez, G.F. Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling. J. Hydrol. 2009, 377, 80–91. [Google Scholar] [CrossRef]
- Kling, H.; Fuchs, M.; Paulin, M. Runoff conditions in the upper Danube basin under an ensemble of climate change scenarios. J. Hydrol. 2012, 424–425, 264–277. [Google Scholar] [CrossRef]
- Liu, X.S.; Deng, Z.; Wang, T.L. Real estate appraisal system based on GIS and BP neural network. Trans. Nonferrous Met. Soc. China 2011, 21, s626–s630. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Description | Value | Unit |
|---|---|---|---|
| ID | Data identifier | 54602_2012_01_01 | |
| STATION_NAME | Name of the station | Bao_Ding | |
| PROVINCE_NAME | Name of the province | He_Bei | |
| CITY_NAME | Name of the city | Bao_Ding | |
| LATITUDE | Latitude | 38.849976 | |
| LONGITUDE | Longitude | 115.516667 | |
| YEARTH | Year of observation | 2012 | |
| Month | Month of observation | 1 | |
| Day | Day of observation | 1 | |
| STATION_HEIGHT | Height of the station | 1.72 | m |
| EVP_SMALL | Small evaporation | 0.4 | mm |
| EVP_BIG | Big evaporation | 3276.6 | mm |
| GST_AVG | Average surface temperature | −3.9 | °C |
| GST_MAX | Maximum surface temperature | 8.7 | °C |
| GST_MIN | Minimum surface temperature | −9.5 | °C |
| PRS_AVG | Average air pressure | 1031 | hPa |
| PRS_MAX | Maximum air pressure | 1034.7 | hPa |
| PRS_MIN | Minimum air pressure | 1027.5 | hPa |
| RHU_AVG | Average humidity | 7.1 | % |
| RHU_MIN | Minimum humidity | 3 | % |
| SSD_TIME | Sunshine time | 5.6 | h |
| TEM_AVG | Average temperature | −4.9 | °C |
| TEM_MAX | Maximum temperature | 1.9 | °C |
| TEM_MIN | Minimum temperature | −9.1 | °C |
| WIN_AVG | Average wind speed | 1.2 | m/s |
| WIN_MAX | Maximum wind speed | 3.3 | m/s |
| WIN_MAX_DCT | Wind direction of max wind speed | 4 | |
| WIN_MMX | Maximum wind speed | 4.4 | m/s |
| WIN_MMX_DCT | Wind direction of maximum wind speed | 4 | |
| Rainfall | Rainfall | 0.00 | mm |
| Data Set Type | Quantity | Date |
|---|---|---|
| Training set | 14,300 | 2012–2015 (June–September) 2016 (June–July) |
| Training set | 780 | 2016 (August) |
| Test set | 780 | 2016 (September) |
| Data Set Type | Quantity | Date |
|---|---|---|
| Training set | 31,299 | 2012–2015 (January–May, October–December) 2016 (January–May, October) |
| Training set | 780 | 2016 (November) |
| Test set | 780 | 2016 (December) |
| Hyperparameter | Description | Value |
|---|---|---|
| N_d | Width of the decision prediction layer | 8 |
| N_a | Width of the attention embedding for each mask | 8 |
| N_steps | Number of steps in the architecture | 3 |
| Lr | Learning_rate | 0.01 |
| optimizer_fn | Optimizer | Adam |
| ID | Date | Actual value | Predictive Value |
|---|---|---|---|
| 54406_2016_12_03 | 2016/12/03 | 0.00 | 0.12 |
| 54406_2016_12_04 | 2016/12/04 | 0.00 | 0.04 |
| 54406_2016_12_05 | 2016/12/05 | 72.00 | 62.65 |
| 54602_2012_05_10 | 2012/05/10 | 0.00 | 0.71 |
| 54602_2012_05_11 | 2012/05/11 | 0.00 | 0.09 |
| 54602_2012_05_12 | 2012/05/12 | 112.00 | 101.99 |
| ID | Date | Actual Value | Predictive Value |
|---|---|---|---|
| 54602_2016_09_01 | 2016/09/01 | 0.00 | 0.00 |
| 54602_2016_09_02 | 2016/09/02 | 0.00 | 0.07 |
| 54602_2016_09_03 | 2016/09/03 | 3.83 | 4.02 |
| 54602_2016_09_04 | 2016/09/04 | 3.79 | 3.93 |
| 54602_2016_09_05 | 2016/09/05 | 14.25 | 13.88 |
| 54602_2016_09_06 | 2016/09/06 | 0.14 | 0.12 |
| 54602_2016_09_07 | 2016/09/07 | 0.58 | 0.77 |
| 54602_2016_09_08 | 2016/09/08 | 0.00 | 0.11 |
| 54602_2016_09_09 | 2016/09/09 | 0.00 | 0.00 |
| 54602_2016_09_10 | 2016/09/10 | 0.00 | 0.03 |
| Model | Test MAE | Test RMSE | KGE | Test MAPE |
|---|---|---|---|---|
| Rainy-Model | 0.3373 | 0.5561 | 0.84 | 3.8% |
| Drier-Model | 0.4825 | 0.6812 | 0.92 | 5.1% |
| Model | Training MAE | Test MAE | KGE | RMSE | MAPE |
|---|---|---|---|---|---|
| BP-NN | 1.8961 | 2.101 | 0.71 | 4.751 | 19% |
| LSTM | 1.199 | 1.374 | 0.75 | 2.098 | 13% |
| Lightgbm | 0.9677 | 1.279 | 0.77 | 1.6781 | 9.87% |
| TabNet | 0.8277 | 0.9176 | 0.82 | 1.4844 | 8.52% |
| TabNet-P | 0.7581 | 0.8033 | 0.83 | 1.2172 | 7.81% |
| TabNet-PB | 0.3923 | 0.4099 | 0.88 | 0.6187 | 4.45% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, J.; Xu, T.; Yu, Y.; Xu, H. Rainfall Forecast Model Based on the TabNet Model. Water 2021, 13, 1272. https://doi.org/10.3390/w13091272
Yan J, Xu T, Yu Y, Xu H. Rainfall Forecast Model Based on the TabNet Model. Water. 2021; 13(9):1272. https://doi.org/10.3390/w13091272
Chicago/Turabian StyleYan, Jianzhuo, Tianyu Xu, Yongchuan Yu, and Hongxia Xu. 2021. "Rainfall Forecast Model Based on the TabNet Model" Water 13, no. 9: 1272. https://doi.org/10.3390/w13091272
APA StyleYan, J., Xu, T., Yu, Y., & Xu, H. (2021). Rainfall Forecast Model Based on the TabNet Model. Water, 13(9), 1272. https://doi.org/10.3390/w13091272