Abstract
We propose a new iterative method for solving a generalized Sylvester matrix equation with given square matrices and an unknown rectangular matrix X. The method aims to construct a sequence of approximated solutions converging to the exact solution, no matter the initial value is. We decompose the coefficient matrices to be the sum of its diagonal part and others. The recursive formula for the iteration is derived from the gradients of quadratic norm-error functions, together with the hierarchical identification principle. We find equivalent conditions on a convergent factor, relied on eigenvalues of the associated iteration matrix, so that the method is applicable as desired. The convergence rate and error estimation of the method are governed by the spectral norm of the related iteration matrix. Furthermore, we illustrate numerical examples of the proposed method to show its capability and efficacy, compared to recent gradient-based iterative methods.
Keywords:
generalized Sylvester matrix equation; iterative method; gradient; Kronecker product; matrix norm MSC:
65F45; 15A12; 15A60; 15A69
1. Introduction
In control engineering, certain problems concerning the analysis and design of control systems can be formulated as the Sylvester matrix equation:
where is an unknown matrix, and are known matrices of appropriate dimensions. Here, stands for the set of real matrices. Let us denote by the transpose of a matrix. When , the equation is reduced to the Lyapunov equation, which is often found in continuous- and discrete-time stability analysis [1,2]. The Sylvester equation is a special case of a generalized Sylvester matrix equation:
where is unknown, and are known constant matrices of appropriate dimensions. This equation also includes the equation and the Kalman–Yakubovich equation as special cases. All of these equations have profound applications in linear system theory and related areas.
Normally, a direct way to solve the generalized Sylvester Equation (2) is to reduce it to a linear system by taking the vector operator. Then, Equation (2) reduces to where
Here, is the vector operator and the operation ⊗ is the Kronecker multiplication. So, Equation (2) has a unique solution if and only if the square matrix P is invertible. However, it is not easy to compute when the sizes of are not small, since the size of P can be very large. Such a size problem leads to computation difficulty in that excessive computer memory is required for the inversion of large matrices. Thus, another way exists which transform the matrix cofficients into a Schur or Hessenberg form, for which solutions may be readily computed—see [3,4].
For matrix equations of large dimensions, iterative algorithms to find an approximated/exact solution are remarkable. There are many techniques to construct an iterative procedure for Equation (2) or its special cases—e.g., matrix sign function [5], block successive over-relaxation [6], block recursion [7,8], Krylov subspace [9,10], and truncated low-rank algorithm [11]. Lately, there have been some variants of Hermitian and skew-Hermitian splitting—e.g., a generalized modified Hermitian and skew-Hermitian splitting algorithm [12], accelerated double-step scale splitting algorithm [13], PHSS algorithm [14], and the four parameter PSS algorithm [15]. Furthermore, the idea of conjugate gradient leads to finite-step iterative methods to find the exact solution such as the generalized conjugated direction algorithm [16], the conjugated gradient least-squares algorithm [17], and generalized product-type methods based on the Bi-conjugate gradient algorithm [18].
In the last decade, many authors have developed gradient-based iterative (GI) algorithms for certain linear matrix equations that satisfy the asymptotic stability (AS) in the following meaning:
(AS): The sequence of approximated solutions converges to the exact solution, no matter the initial value is.
The first GI algorithm for solving (1) was developed by Ding and Chen [19]. In that paper, a sufficient condition in terms of a convergence factor is determined so that the algorithm satisfies (AS) property. By introducing of a relaxation parameter, Niu et al. [20] suggested a relaxed gradient iterative (RGI) gradient algorithm to overcome (1). Numerical studies show that when the relaxation factor is correctly selected the convergent behavior of the Niu’s algorithm is stronger than the Ding’s algorithm. Zhang and Sheng [21] introduced an RGI algorithm for finding the symmetric (skew-symmetric) solution of Equation (1). Xie et al. [22] improved the RGI algorithm to become an accelerated GI (AGBI) algorithm, on the basis of the information generated in the previous half-step and a relaxation factor. Ding and Chen [23] also applied the ideas of gradients and least-squares to formulate the least-squares iterative (LSI) algorithm. In [24], Fan et al. realized that multiplication of the matrix in GI would take great time and space if and were big and dense, so they proposed the following Jacobi-gradient iterative (JGI) method.
Method 1
(Jacobi-Gradient based Iterative (JGI) algorithm [24]). For , let be the diagonal part of . Given any initial matrices . Set and compute . For , do:
After that, Tian et al. [25] proposed that an accelerated Jacobi-gradient iterative (AJGI) algorithm for solving the Sylvester matrix equation relies on two relaxation factors and the half-step update. However, the parameter values to apply to the algorithm are difficult to find since they are given in terms of a nonlinear inequality. For the generalized Sylvester Equation (2), the gradient iterative (GI) algorithm [19] and the least-squares iterative (LSI) algorithm [26] were established as follows.
Method 2
(GI algorithm [19]). Given any two initial matrices . Set and compute . For , do:
A sufficient condition for which the algorithm satisfies (AS) is
Method 3
(LSI algorithm [26]). Given any two initial matrices . Set and compute . For , do:
If , then the algorithm satisfies (AS).
In this paper, we shall propose a new iterative method for solving the generalized Sylvester matrix Equation (2), when , and . This algorithm requires only one initial value and only one parameter, called a convergence factor. We decompose the coefficient matrices to be the sum of its diagonal part and others. The recursive formula for iteration is derived from the gradients of quadratic norm-error functions together with hierarchical identification principle. Under assumptions on the real-parts sign of eigenvalues of matrix coefficients, we find necessary and sufficient conditions on a convergent factor for which (AS) holds. The convergence rate and error estimates are regulated by the iteration matrix spectral radius. In particular, when the iteration matrix is symmetric, we obtain a convergence criteria, error estimates and the optimal convergent factor in terms of spectral norms and condition number. Moreover, numerical simulations are also provided to illustrate our results for (2) and (1). We compare the efficiency of our algorithm to LSI, GI, RGI, AGBI and JGI algorithms.
Let us recall some terminology from matrix analysis—see e.g., [27]. For any square matrix X, denote its spectrum, its spectral radius, and its trace. Let us denote the largest and the smallest eigenvalues of a matrix by and , respectively. Recall that the spectral norm and the Frobenius norm of are, respectively, defined by
The condition number of is defined by
Denote the real part of a complex number z by .
The rest of paper is organized as follows. We propose a modified Jacobi-gradient iterative algorithm in Section 2. Convergence criteria, convergence rate, error estimates, and optimal convergence factor are discussed in Section 3. In Section 4, we provide numerical simulations of the algorithm. Finally, we conclude the paper in Section 5.
2. A Modified Jacobi-Gradient Iterative Method for the Generalized Sylvester Equation
In this section, we propose an iterative algorithm for solving the generalized Sylvester equation, called a modified Jacobi-gradient iterative algorithm.
Throughout, let and , and . We would like to find a matrix , such that
Write , where are the diagonal parts of , respectively. A necessary and sufficient condition for (3) to have a unique solution is the invertibility of the square matrix
In this case, the solution is given by .
To obtain an iterative algorithm for solving (3), we recall the hierarchical identification principle in [19]. We write (3) to
Define two matrices
From (4) and (5), we shall find the approximated solution of the following two subsystems
so that the following norm-error functions are minimized:
From the gradient formula
we can deduce the gradient of the error as follows:
Similarly, we have
Let and be the estimates or iterative solutions of the system (6) at k-th iteration. The recursive formulas of and come from the gradient formulas (8) and (9), as follows:
Based on the hierarchical identification principle, the unknown variable X is replaced by its estimates at the -th iteration. To avoid duplicated computation, we introduce a matrix
so we have
Since any diagonal matrix is sparse, the operation counts in the computation (10) can be substantially reduced. Let us denote , , and for each . Indeed, the multiplication of results in a matrix whose -th entry is the product of the i-th entry in the diagonal of , the -th entry of , and the j-th entry of —i.e., . Similarly, . Thus,
The above discussion leads to the following Algorithm 1.
| Algorithm 1: Modified Jacobi-gradient based iterative (MJGI) algorithm |
 |
The complexity analysis for each step of the algorithm is given by . When , the complexity analysis is , so that the algorithm runtime complexity is cubic time. The convergence property of the algorithm relies on the convergence factor . The appropriate value of this parameter is determined in the next section.
3. Convergence Analysis of the Proposed Method
In this section, we make convergence analysis of Algorithm 1. First, we transform it into a linear iterative method of the first order: where is a vector variable and T is a matrix. The iteration matrix T will reflect convergence criteria, convergence rate, and error estimates of the algorithm.
3.1. Convergence Criteria
Theorem 1.
Assume that the generalized Sylvester matrix Equation (3) has a unique solution. Denoteand write. Letbe a sequence generated from Algorithm 1.
- (1)
- Then, (AS) holds if and only if.
- (2)
- Iffor all, then (AS) holds if and only if
- (3)
- Iffor all, then (AS) holds if and only if
- (4)
- If H is symmetric, then (AS) holds if and only ifandhave the same sign, and μ is chosen so that
Proof.
From Algorithm 1, we start with considering the error matrices
We will show that or equivalently, as . A direct computation reveals that
By taking the vector operator and using properties of the Kronecker product, we have
Let us denote the diagonal part of P by . Indeed,
Thus, we arrive at a linear iterative process
where . Hence, the following statements are equivalent:
- (i)
- for any initial value .
- (ii)
- System (11) has an asymptotically-stable zero solution.
- (iii)
- The iteration matrix has spectral radius less than 1.
Indeed, since is a polynomial of H, we get
Thus, if and only if for all . Write where . It follows that the condition is equivalent to , or
Thus, we arrive at two alternative conditions:
- (i)
- and for all ;
- (ii)
- and for all .
- Case 1
- for all j. In this case, if and only if
- Case 2
- for all j. In this case, if and only if
Now, suppose that H is a symmetric matrix. Then is also symmetric, and thus all its eigenvalue are real. Hence,
It follows that if and only if
So, and cannot be zero.
- Case 1
- If then the condition (16) is equivalent to
- Case 2
- If then the condition (16) is equivalent to
- Case 3
- If , thenwhich is a contradiction.
Therefore, the condition (16) holds if and only if and have the same sign and is chosen according to the above condition. □
3.2. Convergence Rate and Error Estimate
We now discuss the convergence rate and error estimates of Algorithm 1 from the iterative process (11).
Suppose that Algorithm 1 satisfies the (AS) property—i.e., . From (11), we have
It follows inductively that for each ,
Hence, the spectral norm of describes how fast the approximated solutions converges to the exact solution . The smaller spectral radius, the faster goes to . In that case, since , if (i.e., is not the exact solution) then
Thus, the error at each iteration gets smaller than the previous one.
The above discussion is summarized in the following theorem.
Theorem 2.
Suppose that the parameter μ is chosen as in Theorem 1 so that Algorithm 1 satisfies (AS). Then, the convergence rate of the algorithm is governed by the spectral radius (16). Moreover, the error estimate compared to the previous step and the fast step are provided by (17) and (18), respectively. In particular, the error at each iteration gets smaller than the previous one, as in (19).
From (16), if the eigenvalues of are close to 1, then the spectral radius of the iteration matrix is close to 0, and hence, the error or converge faster to 0.
Remark 1.
The convergence criteria and the convergence rate of Algorithm 1 depend on A, B, C and D but not on E. However, the matrix E can be used for the stopping criteria.
The next proposition determines the iteration number for which the approximated solution is close to the exact solution so that .
Proposition 1.
According to Algorithm 1, for each given error , we have after iterations for any , such that
Proof.
From the estimation (18), we have
This means precisely that for each given , there is a such that for all ,
Taking logarithms, we have that the above condition is equivalent to (20). Thus, if we run Algorithm 1 times, then we get as desired. □
3.3. Optimal Parameter
We discuss the fastest convergence factor for Algorithm 1.
Theorem 3.
The optimal convergence factor μ for which Algorithm 1 satisfies (AS) is one that minimizes . If, in addition, H is symmetric, then the optimal convergence factor for which the algorithm satisfies (AS) is determined by
In this case, the convergence rate is governed by
where κ denotes be condition number of H, and we have the following estimates:
Proof.
From Theorem 2, it is clear that the fastest convergence factor is attained at a convergence factor that minimizes . Now, assume that H is symmetric. Then, is also symmetric, thus all its eigenvalues are real and
For convenience, denote , , and
First, we consider the case . To obtain the fastest convergence factor, according to (15), we must solve the following optimization problem
We obtain that the minimizer is given by , so that . For the case , we solve the following optimization problem
A similar argument yields the same minimizer (21) and the same convergence rate (22). From (17), (18) and (25), we obtain the bounds (23) and (24). □
4. Numerical Simulations
In this section, we report numerical results to illustrate the effectiveness of Algorithm 1. We consider various sizes of matrix systems, namely, small , medium and large . For the generalized Sylvester equation, we compare the performance of Algorithm 1 to the GI and LSI algorithms. For the Sylvester equation, we compare our algorithm with GI, RGI, AGBI and JGI algorithms. All iterations have been carried out the same environment: MATLAB R2017b, Intel(R) Core(TM) i7-7660U CPU @ 2.5GHz, RAM 8.00 GB Bus speed 2133 MHz. We abbreviate IT and CPU for iteration time and CPU time (in seconds), respectively. As step k-th of the iteration, we consider the following error:
where is the k-th approximated solution of the corresponding system.
4.1. Numerical Simulation for the Generalized Sylvester Matrix Equation
Example 1.
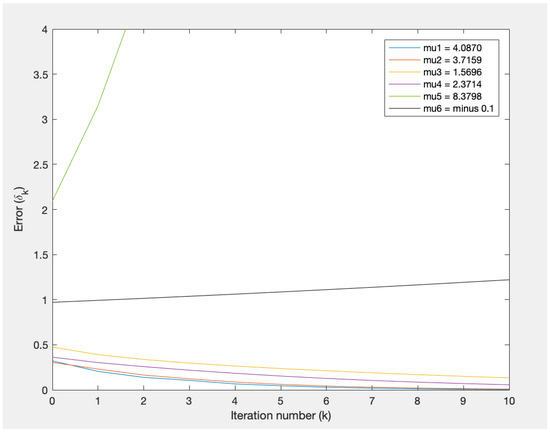
Consider the matrix equation where
Then, the exact solution of X is
Choose . In this case, all eigenvalues of H have positive real parts. The effect of changing the convergence factor μ is illustrated in Figure 1. According to Theorem 1, the criteria for the convergence of is that . Since satisfy this criteria, the error is becoming smaller and goes to zero as k increase, as in Figure 1. Among them, gives the fastest convergence. For and , which do not meet the criteria, the error does not converge to zero.
Figure 1.
Error of Example 1.
Example 2.

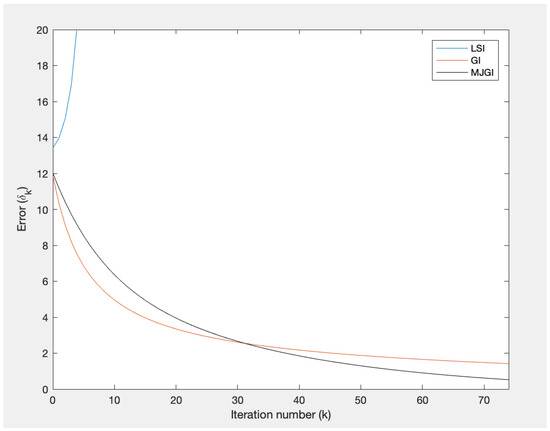
Suppose that where are matrices where
Here, E is a heptadiagonal matrix—i.e., a band matrix with bandwidth 3. Choose an initial matrix where is an n-by-n matrix that contains 0 for every position. We compare Algorithm 1 with the direct method, LSI and GI algorithms. Table 1 shows the errors at the final step of iteration as well as the computation time after 75 iterations. Figure 2 illustrates that the approximated solutions via LSI diverge, while those via GI and MJGI converge. Table 1 and Figure 2 imply that our algorithm takes significantly less computational time and error than others.
Table 1.
Computational time and error for Example 2.
Figure 2.
Error of Example 2.
Example 3.

We consider the equation in which are matrices determined by
The initial matrix is given by We run LSI, GI and MJGI algorithms by using
respectively. The reported result in Table 2 and Figure 3 illustrate that the approximated solution generated from LSI diverges, while those from GI or MJGI converge. Both computational time and the error from MJGI are less than those from GI.
Table 2.
Computational time and error for Example 3.
Figure 3.
Comparison of Example 3.
4.2. Numerical Simulation for Sylvester Matrix Equation
Assume that the Sylvester equation
has a unique solution. This condition is equivalent to that the Kronecker sum is invertible, or all possible sums between eigenvalues of and are nonzero. To solve (26), the Algorithm 2 is proposed:
| Algorithm 2: Modified Jacobi-gradient based iterative (MJGI) algorithm for Sylvester equation |
 |
Example 4.

Consider the equation in which E is the same matrix as in the previous example,
In this case, all eigenvalues of the iteration matrix have positive real parts, so that we can apply our algorithm. We compare our algorithm with GI, RGI, AGBI and JGI algorithms. The results after running 100 iterations are shown in Figure 4 and Table 3. According to the error and CT in Table 3 and Figure 4, our algorithm uses less computational time and has smaller errors than others.
Figure 4.
Errors of Example 4.
Table 3.
CTs and errors for Example 4.
5. Conclusions and Suggestion
A modified Jacobi-gradient (MJGI) algorithm (Algorithm 1) is proposed for solving the generalized Sylvester matrix Equation (3). In order to have MJGI algorithm applicable for any sizes of matrix system and any initial matrices, the convergence factor must be chosen properly according to Theorem 1. In this case, the iteration matrix has a spectral radius less than 1. When the iteration matrix is symmetric, we determine the optimal convergent factor which enhances the algorithm reaching the fastest rate of convergence. The asymptotic convergence rate of the algorithm is governed by the spectral radius of . So, if the eigenvalue H is close to 1, then the algorithm converges faster in the long run. The numerical examples reveal that our algorithm is suitable for small (), medium () and large () sizes of matrix systems. In addition, the MJGI algorithm performs well compared to recent gradient iterative algorithms. For future works, we may add another parameter for an updating step to make the algorithm converge faster—see [25]. Another possible way is to apply the idea in this paper to derive an iterative algorithm for nonlinear matrix equations.
Author Contributions
Supervision, P.C.; software, N.S.; writing—original draft preparation, N.S.; writing—review and editing, P.C. All authors contributed equally and significantly in writing this article. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
The first author received financial support from the RA-TA graduate scholarship from the faculty of Science, King Mongkut’s Institute of Technology Ladkrabang, Grant. No. RA/TA-2562-M-001 during his Master’s study.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Shang, Y. Consensus seeking over Markovian switching networks with time-varying delays and uncertain topologies. Appl. Math. Comput. 2016, 273, 1234–1245. [Google Scholar] [CrossRef]
- Shang, Y. Average consensus in multi-agent systems with uncertain topologies and multiple time-varying delays. Linear Algebra Appl. 2014, 459, 411–429. [Google Scholar] [CrossRef]
- Golub, G.H.; Nash, S.; Van Loan, C.F. A Hessenberg-Schur method for the matrix AX + XB = C. IEEE Trans. Automat. Control. 1979, 24, 909–913. [Google Scholar] [CrossRef]
- Ding, F.; Chen, T. Hierarchical least squares identification methods for multivariable systems. IEEE Trans. Automat. Control 1997, 42, 408–411. [Google Scholar] [CrossRef]
- Benner, P.; Quintana-Orti, E.S. Solving stable generalized Lyapunov equations with the matrix sign function. Numer. Algorithms 1999, 20, 75–100. [Google Scholar] [CrossRef]
- Starke, G.; Niethammer, W. SOR for AX − XB = C. Linear Algebra Appl. 1991, 154–156, 355–375. [Google Scholar] [CrossRef]
- Jonsson, I.; Kagstrom, B. Recursive blocked algorithms for solving triangular systems—Part I: One-sided and coupled Sylvester-type matrix equations. ACM Trans. Math. Softw. 2002, 28, 392–415. [Google Scholar] [CrossRef]
- Jonsson, I.; Kagstrom, B. Recursive blocked algorithms for solving triangular systems—Part II: Two-sided and generalized Sylvester and Lyapunov matrix equations. ACM Trans. Math. Softw. 2002, 28, 416–435. [Google Scholar] [CrossRef]
- Kaabi, A.; Kerayechian, A.; Toutounian, F. A new version of successive approximations method for solving Sylvester matrix equations. Appl. Math. Comput. 2007, 186, 638–648. [Google Scholar] [CrossRef]
- Lin, Y.Q. Implicitly restarted global FOM and GMRES for nonsymmetric matrix equations and Sylvester equations. Appl. Math. Comput. 2005, 167, 1004–1025. [Google Scholar] [CrossRef]
- Kressner, D.; Sirkovic, P. Truncated low-rank methods for solving general linear matrix equations. Numer. Linear Algebra Appl. 2015, 22, 564–583. [Google Scholar] [CrossRef]
- Dehghan, M.; Shirilord, A. A generalized modified Hermitian and skew-Hermitian splitting (GMHSS) method for solving complex Sylvester matrix equation. Appl. Math. Comput. 2019, 348, 632–651. [Google Scholar] [CrossRef]
- Dehghan, M.; Shirilord, A. Solving complex Sylvester matrix equation by accelerated double-step scale splitting (ADSS) method. Eng. Comput. 2019. [Google Scholar] [CrossRef]
- Li, S.Y.; Shen, H.L.; Shao, X.H. PHSS iterative method for solving generalized Lyapunov equations. Mathematics 2019, 7, 38. [Google Scholar] [CrossRef]
- Shen, H.L.; Li, Y.R.; Shao, X.H. The four-parameter PSS method for solving the Sylvester equation. Mathematics 2019, 7, 105. [Google Scholar] [CrossRef]
- Hajarian, M. Generalized conjugate direction algorithm for solving the general coupled matrix equations over symmetric matrices. Numer. Algorithms 2016, 73, 591–609. [Google Scholar] [CrossRef]
- Hajarian, M. Extending the CGLS algorithm for least squares solutions of the generalized Sylvester-transpose matrix equations. J. Frankl. Inst. 2016, 353, 1168–1185. [Google Scholar] [CrossRef]
- Dehghan, M.; Mohammadi-Arani, R. Generalized product-type methods based on Bi-conjugate gradient (GPBiCG) for solving shifted linear systems. Comput. Appl. Math. 2017, 36, 1591–1606. [Google Scholar] [CrossRef]
- Ding, F.; Chen, T. Gradient based iterative algorithms for solving a class of matrix equations. IEEE Trans. Automat. Control 2005, 50, 1216–1221. [Google Scholar] [CrossRef]
- Niu, Q.; Wang, X.; Lu, L.-Z. A relaxed gradient based algorithm for solving Sylvester equation. Asian J. Control 2011, 13, 461–464. [Google Scholar] [CrossRef]
- Zhang, X.D.; Sheng, X.P. The relaxed gradient based iterative algorithm for the symmetric (skew symmetric) solution of the Sylvester equation AX + XB = C. Math. Probl. Eng. 2017, 2017, 1624969. [Google Scholar] [CrossRef]
- Xie, Y.J.; Ma, C.F. The accelerated gradient based iterative algorithm for solving a class of generalized Sylvester-transpose matrix equation. Appl. Math. Comput. 2012, 218, 5620–5628. [Google Scholar] [CrossRef]
- Ding, F.; Chen, T. Iterative least-squares solutions of coupled Sylvester matrix equations. Syst. Control Lett. 2005, 54, 95–107. [Google Scholar] [CrossRef]
- Fan, W.; Gu, C.; Tian, Z. Jacobi-gradient iterative algorithms for Sylvester matrix equations. In Proceedings of the 14th Conference of the International Linear Algebra Society, Shanghai University, Shanghai, China, 16–20 July 2007. [Google Scholar]
- Tian, Z.; Tian, M.; Gu, C.; Hao, X. An accelerated Jacobi-gradient based iterative algorithm for solving Sylvester matrix equations. Filomat 2017, 31, 2381–2390. [Google Scholar] [CrossRef]
- Ding, F.; Liu, P.X.; Chen, T. Iterative solutions of the generalized Sylvester matrix equations by using the hierarchical identification principle. Appl. Math. Comput. 2008, 197, 41–50. [Google Scholar] [CrossRef]
- Horn, R.A.; Johnson, C.R. Topics in Matrix Analysis; Cambridge University Press: New York, NY, USA, 1991. [Google Scholar]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).