
Research on Knowledge Graphs with Concept Lattice Constraints

Abstract
:1. Introduction
- (1)
- The theory connects formal concept analysis and a knowledge graph, which provides a novel method to construct knowledge graphs based on attribute implications.
- (2)
- We analyze the mutual transformation between the attribute implication, the formal context and the concept lattice, which realizes the closed cycle between the three.
- (3)
- We put forward an IFC-A to generate an implication formal context, which can supplement the domain knowledge based on attribute implications.
- (4)
- We show that the theory we present has many application possibilities, and have given one application as an illustration. We apply the theory on knowledge graph completion to CN-DBpedia and Probase datasets, which shows that the theory is applicable and effective.
2. Related Work
2.1. Formal Concept Analysis
2.2. Mapping from Concept Lattice to Knowledge Graph
3. Methodology
3.1. Basic Concept of FCA
- (1)
- Reflexivity: ;
- (2)
- Anti-symmetry: ;
- (3)
- Transitivity: .
3.2. The AIs-KG Theory
3.2.1. Formal Context Generation Algorithm Based on Attribute Implication
| Algorithm1. Pseudocode of the augment algorithm. | |
| Algorithm implementation: | |
| Input: Output: Begin | Attribute implication set: Implication formal context , , For count ()//Count the number of attributes in each implication. add into //Add attributes into . End For obtain from //Obtain object sets. obtain //Generate initial formal context according to . For If is in If is not in update Else Continue//The formal context remains the same. Else Continue//The formal context remains the same. End If End For //Get the implication formal context according to the last updated . |
| End | |
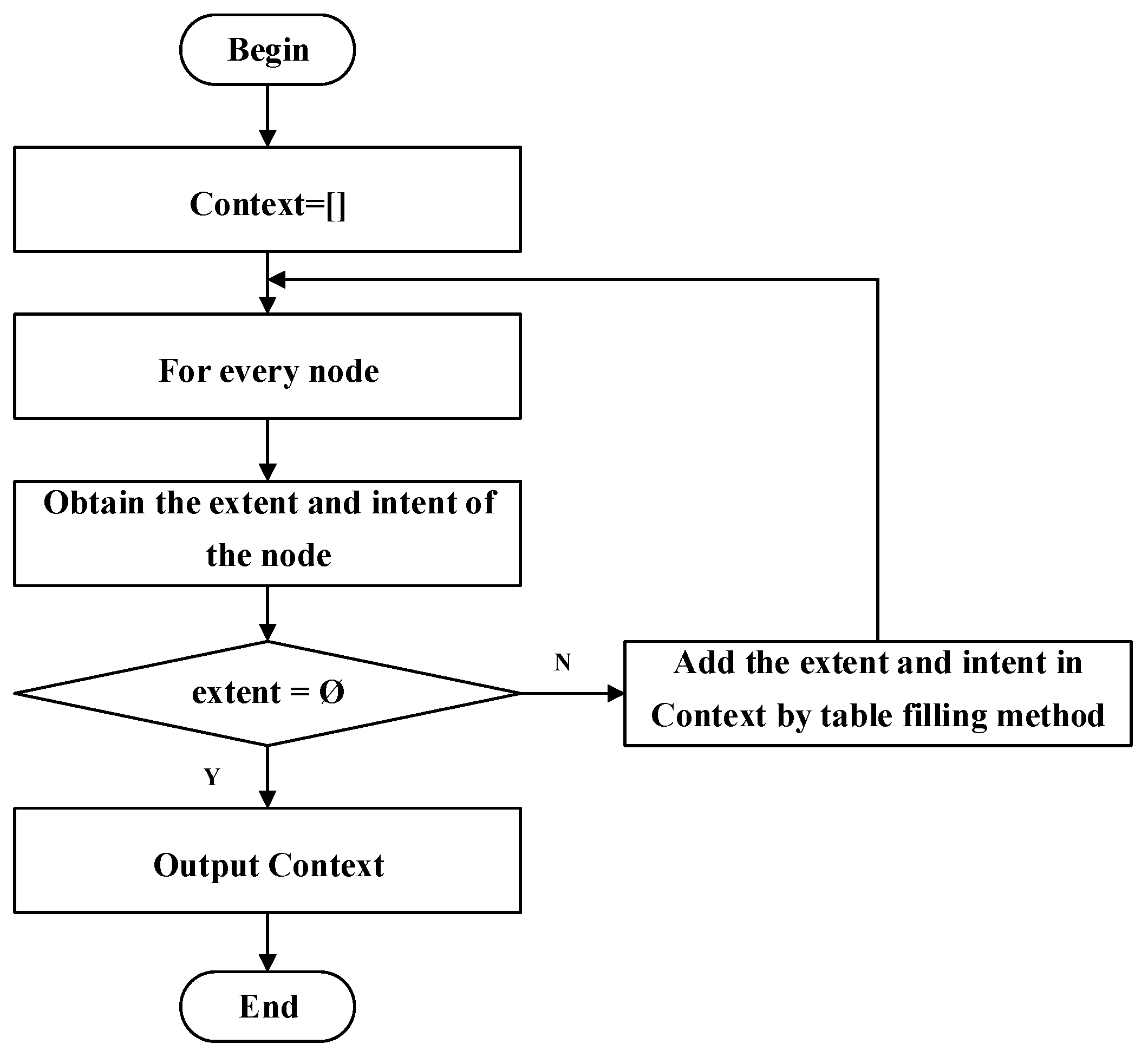
3.2.2. Mutual Transformation
| Algorithm2. Pseudocode of the augment algorithm. | |
| Algorithm implementation: | |
| Input: Concept lattice. | |
| Output: Formal context. | |
| 1 | array = ;//Define an empty table to store the formal context. |
| 2 | queue_1 = ; queue_2 = ; |
| 3 | Queue<TreeNode> queue = new Linkedlist<>(); |
| 4 | List<TreeNode> list = new Linkedlist<>(); |
| 5 | Queue.add(treeNode); |
| 6 | while (queue.size()>0): |
| 7 | TreeNode node = queue.poll();//node contains extent and intent. |
| 8 | if (queue.size() = 1 and node_extent = ): |
| 9 | return array; |
| 10 | if (node_intent ! = ): |
| 11 | queue_1.add(node_extent); |
| 12 | queue_2.add(node_intent); |
| 13 | while(queue_1.size()>0): |
| 14 | while(queue_2.size()>0): |
| 15 | array[queue_1.poll()][queue_2.poll()] = 1; |
| 16 | list<TreeNode> childrens = node.childrens; |
| 17 | for (TreeNode childNode: childrens): |
| 18 | Queue.add(childNode); |
| 19 | end |
| Algorithm3. Pseudocode of the augment algorithm. | |
| Algorithm implementation: | |
| Input: A concept lattice . | |
| Output: A set of implications. | |
| 1 2 | FunctionGenerateRulesForNode ().//Returns the complete set of rules generated from the node N. |
| 3 | ; |
| 4 | if and then//discard some trivial rules such as |
| 5 | for each nonempty set in ascending do; |
| 6 | if parent on such that then |
| 7 | if such that then |
| 8 | |
| 9 | end if |
| 10 | end if |
| 11 | end for |
| 12 | end if |
| 13 | return () |
| 14 | end |
| 15 | ;//the cumulative set of implication rules. |
| 16 | for each node in ascending do |
| 17 | GenerateRulesForNode(H) |
| 18 | ; |
| 19 | end for |
| 20 | return (∑) |
| 21 | end |
- (1)
- In the process of constructing the initial ontology, we must strictly follow the principles and methods of ontology construction; in the process of ontology update, in order to prevent the error of ontology update caused by artificial subjective interference during the ontology update, we should also strictly abide by the ontology update method proposed in this paper, and cannot ignore any link due to human intervention.
- (2)
- The construction of the domain ontology does not depend on one person, but on collective efforts, and the constructed domain ontology needs to be recognized by everyone.
- (3)
- In the process of transforming the concept lattice into an ontology, the mapping rules should be strictly followed, and the visualization of the concept lattice and the ontology should be realized by computer.
4. Experiment
4.1. Implication Formal Context Generation Based on IFC-A
4.2. Mapping from Implication Formal Context to Knowledge Graph Based on AIs-KG
4.3. One Application of the AIs-KG Theory
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, X.; Jia, S.; Xiang, Y. A review: Knowledge reasoning over knowledge graph. Expert Syst. Appl. 2020, 141, 112948. [Google Scholar] [CrossRef]
- Namata, G.M.; London, B.; Getoor, L. Collective graph identification. ACM Trans. Knowl. Discov. Data 2016, 10, 2818378. [Google Scholar] [CrossRef]
- Grangel-González, I. A Knowledge Graph Based Integration Approach for Industry 4.0. Ph.D. Thesis, Universitäts-und Landesbibliothek Bonn, Bonn, Germany, 2019. [Google Scholar]
- Yang, S.; Shu, K.; Wang, S. Unsupervised fake news detection on social media: A generative approach. Artif. Intell. 2019, 33, 5644–5651. [Google Scholar] [CrossRef] [Green Version]
- Zhao, X.; Jia, Y.; Li, A. Multi-source knowledge fusion: A survey. World Wide Web 2020, 23, 2567–2592. [Google Scholar] [CrossRef] [Green Version]
- Ganter, B.; Wille, R.; Franzke, C. Formal Concept Analysis: Mathematical Foundations; Springer: Berlin/Heidelberg, Germany, 1997. [Google Scholar]
- Ganter, B.; Wille, R.; Wille, R. Formal Concept Analysis; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Ganter, B.; Wille, R. Applied lattice theory: Formal concept analysis. In General Lattice Theory; Grätzer, G., Ed.; Birkhäuser: Basel, Switzerland, 1997. [Google Scholar]
- Chein, M. Algorithme de recherche des sou-matrices premières d’une matrice. Bull. Math. 1969, 13, 21–25. [Google Scholar]
- Bordat, J.P. Calcul pratique du treillis de Galois d’une correspondence. Math. Inform. Et Ences Hum. 1986, 96, 31–47. [Google Scholar]
- Ganter, B. Two Basic Algorithms in Concept Analysis. In Formal Concept Analysis; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Zhi, H.; Qi, J.; Qian, T. Three-way dual concept analysis. Int. J. Approx. Reason. 2019, 114, 151–165. [Google Scholar] [CrossRef]
- Zhi, H.; Qi, J.; Qian, T. Conflict analysis under one-vote veto based on approximate three-way concept lattice. Inf. Sci. 2020, 516, 316–330. [Google Scholar] [CrossRef]
- Merwe, D.; Obiedkov, S.; Kourie, D. AddIntent: A New Incremental Algorithm for Constructing Concept Lattices. In Formal Concept Analysis; Springer: Berlin/Heidelberg, Germany, 2004; pp. 372–385. [Google Scholar]
- Gruber, T.R. Toward Principles for the Design of Ontologies Used for Knowledge Sharing. Int. J. Hum.-Comput. Stud. 1995, 43, 907–928. [Google Scholar] [CrossRef]
- Jindal, R.; Seeja, K.R.; Jain, S. Construction of domain ontology utilizing formal concept analysis and social media analytics. Int. J. Cogn. Comput. Eng. 2020, 1, 62–69. [Google Scholar] [CrossRef]
- Shubhra, G.J.; Arvinder, K. Information Retrieval from Software Bug Ontology Exploiting Formal Concept Analysis. Comput. Sist. 2020, 24, 3368. [Google Scholar]
- Priya, M.; Aswani, K.C. A novel method for merging academic social network ontologies using formal concept analysis and hybrid semantic similarity measure. Libr. Hi. Tech. 2020, 38, 399–419. [Google Scholar] [CrossRef]
- Cimiano, P.; Stumme, G.; Hotho, A.; Tane, J. Conceptual knowledge processing with formal concept analysis and ontologies. Form. Concept Anal. 2004, 11, 189–207. [Google Scholar]
- Cimiano, P.; Staab, S.; Tane, J. Automatic Acquisition of Taxonomies from Text: FCA meets NLP. Workshop Adapt. Text. Extr. Min. 2003, 11, 10–17. [Google Scholar]
- Tao, G. Using Formal Concept Analysis for Ontology Structuring and Building. Master’s Thesis, Nanyang Technological University, Singapore, 2003. [Google Scholar]
- Haav, H.M. A Semi-automatic Method to Ontology Design by Using FCA. CLA 2004, 13–15. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.92.6057&rep=rep1&type=pdf (accessed on 3 November 2021).
- Haav, H.M. An application of inductive concept analysis to construction of domain-specific ontologies. In Proceedings of the VLDB Pre-conference Workshop on Emerging Database Research in East Europe, Berlin, Germany, 9–12 September 2003; pp. 63–67. [Google Scholar]
- Obitko, M.; Snasel, V.; Smid, J. Ontology Design with Formal Concept Analysis, Edited by Vaclav Snasel, Radim Belohlavek. Workshop Concept Lattices Appl. Ostrav. 2004, 11, 111–119. [Google Scholar]
- Fawei, B.; Pan, J.Z.; Kollingbaum, M. A Semi-automated Ontology Construction for Legal Question Answering. New Gener. Comput. 2019, 9, 145. [Google Scholar] [CrossRef] [Green Version]
- Moreira, A.; Filho, J.L.; Oliveira, A. Automatic Creation of Ontology Using a Lexical Database: An Application for the Energy Sector; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Han, P.; Li, Y.; Yin, Y. Ontology Construction for Eldercare Services with an Agglomerative Hierarchical Clustering Method; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Vairavasundaram, S.; Logesh, R. Applying Semantic Relations for Automatic Topic Ontology Construction. Dev. Trends Intell. Technol. Smart Syst. 2018, 14, 48–77. [Google Scholar]
- Geng, Q.; Deng, S.; Jia, D. Cross-domain ontology construction and alignment from online cust-omer product reviews. Inf. Sci. 2020, 531, 47–67. [Google Scholar] [CrossRef]
- Al-Aswadi, F.N.; Chan, H.Y.; Gan, K.H. Automatic ontology construction from text: A review from shallow to deep learning trend. Artif. Intell. Rev. 2020, 53, 3901–3928. [Google Scholar] [CrossRef]
- Zeng, W.; Liu, H.; Feng, H. Construction of Scenic Spot Knowledge Graph Based on Ontology. Int. Symp. Distrib. Comput. Appl. Bus. Eng. Sci. 2019, 75, 120–123. [Google Scholar] [CrossRef]
- Varma, S.; Shivam, R.; Jamaiyar, A.; Anukriti, S.; Kashyap, A.S. Link Prediction Using Semi-Automated Ontology and Knowledge Graph in Medical Sphere. India Counc. Int. 2020, 5, 9342301. [Google Scholar]
- Dou, J.; Qin, J.; Jin, Z. Knowledge graph based on domain ontology and natural language processing technology for Chinese intangible cultural heritage. J. Vis. Lang. Comput. 2018, 48, 19–28. [Google Scholar] [CrossRef]
- Amador-Domínguez, E.; Hohenecker, P.; Lukasiewicz, T. An ontology-based deep learning approach for knowledge graph completion with fresh entities. In International Symposium on Distributed Computing and Artificial Intelligence; Springer: Cham, Switzerland, 2019; pp. 125–133. [Google Scholar]
- Paulheim, H. Knowledge graph refinement: A survey of approaches and evaluation methods. Semant. Web 2017, 8, 489–508. [Google Scholar] [CrossRef] [Green Version]
- Uschold, M. Ontologies Principles, Methods and Applications. Knowl. Eng. Rev. 1996, 11, 93–155. [Google Scholar] [CrossRef] [Green Version]
- Zwass, V. Expert System. Encyclopedia Britannica. 2016. Available online: https://www.britannica.com/technology/expert-system (accessed on 12 June 2021).
- Xia, M. Implementation of an animal recognition expert system by Prolog. J. Chengdu Univ. Inf. Technol. 2003, 14, 245. [Google Scholar]
- Bo, X.; Yong, X.; Liang, J. CN-DBpedia: A Never-Ending Chinese Knowledge Extraction System. Ind. Eng. Other Appl. Appl. Intell. Syst. 2017, 52, 428–438. [Google Scholar]
- Wu, W.; Li, H.; Wang, H. Probase: A probabilistic taxonomy for text understanding. Manag. Data 2012, 119, 481–492. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classical Research | Limitations |
|---|---|
| Cimiano et al. [19,20] |
|
| |
| |
| GuTao et al. [21] |
|
| |
| Haav et al. [22,23] |
|
| |
| |
| Marek Obitko et al. [24] |
|
|
| Research | Completeness of Documents | Mapping Rules |
|---|---|---|
| Cimiano et al. [19,20] | Incomplete | Intent → Ontology concept Extent → Ontology sub-concept |
| GuTao et al. [21] | Incomplete | Not specific |
| Haav et al. [22,23] | Incomplete | Intent → Ontology concept |
| Marek Obitko et al. [24] | Incomplete | Node concept → Ontology concept |
| Our method | More complete | Node concept → Ontology concept Intent → Ontology concept Extent → Ontology sub-concept Relation → Ontology relation |
| 1 | 1 | 1 | 0 | 0 | 0 |
| 2 | 0 | 1 | 0 | 1 | 1 |
| 3 | 0 | 1 | 1 | 1 | 0 |
| 4 | 0 | 0 | 1 | 0 | 1 |
| 5 | 0 | 0 | 0 | 1 | 1 |
| a | b | c | d | e | f | g | h | |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 |
| 3 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 |
| 4 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| 5 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 |
| a | b | c | d | e | f | g | h | i | j | k | l | m | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cheetah | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 |
| Tiger | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 |
| Giraffe | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| Zebra | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| Ostrich | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| Penguin | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Albatross | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cheetah | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 |
| Tiger | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 |
| Giraffe | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| Zebra | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| Ostrich | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| Penguin | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| Albatross | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| Dataset | #E | #R |
|---|---|---|
| CN-DBpedia | 9,000,000+ | 67,000,000+ |
| Probase | 5,376,526 | 85,101,174 |
| Entity | Attribute | Entity | Attribute | Entity | Attribute |
|---|---|---|---|---|---|
| Cheetah | hairy | Cheetah | has dark sports | Tiger | eats meat |
| Cheetah | gives milk | Zebra | chew cud | Tiger | has sharp teeth |
| Cheetah | has sharp teeth | Tiger | hairy | Tiger | has claws |
| Cheetah | has forward eyes | Tiger | gives milk | Tiger | has forward eyes |
| Cheetah | has tawny color |
| Entity | Attribute | Entity | Attribute | Entity | Attribute |
|---|---|---|---|---|---|
| Cheetah | hairy | Tiger | gives milk | Zebra | chews cud |
| Cheetah | give milk | Tiger | eats meat | Zebra | has black stripes |
| Cheetah | eats meat | Tiger | has sharp teeth | Ostrich | lays eggs |
| Cheetah | has sharp teeth | Tiger | has forward eyes | Ostrich | has long legs |
| Cheetah | has forward eyes | Tiger | has tawny color | Ostrich | black and white |
| Cheetah | has tawny color | Tiger | has black stripes | Penguin | lays eggs |
| Cheetah | has dark sports | Giraffe | chews cud | Penguin | black and white |
| Tiger | hairy | Giraffe | has black stripes | Albatross | has feathers |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lan, N.; Yang, S.; Yin, L.; Gao, Y. Research on Knowledge Graphs with Concept Lattice Constraints. Symmetry 2021, 13, 2363. https://doi.org/10.3390/sym13122363
Lan N, Yang S, Yin L, Gao Y. Research on Knowledge Graphs with Concept Lattice Constraints. Symmetry. 2021; 13(12):2363. https://doi.org/10.3390/sym13122363
Chicago/Turabian StyleLan, Ning, Shuqun Yang, Ling Yin, and Yongbin Gao. 2021. "Research on Knowledge Graphs with Concept Lattice Constraints" Symmetry 13, no. 12: 2363. https://doi.org/10.3390/sym13122363
APA StyleLan, N., Yang, S., Yin, L., & Gao, Y. (2021). Research on Knowledge Graphs with Concept Lattice Constraints. Symmetry, 13(12), 2363. https://doi.org/10.3390/sym13122363