5.1. Datasets
We collect real historical data to train and evaluate the model for applying our models to the customs declaring scene. We select 84 chapter that is representative and have enough samples as the research object. HS-codes are usually 10-bit codes, and it is hard to be classified directly for their large number of categories. Considering reducing the complexity of the experiment implementation and improving the effect of classification, the classification experiments of 2-bit to 4-bit, 4-bit to 6-bit and 6-bit to 8-bit are carried out from the perspective of hierarchy. Two Chinese commodity declaration datasets used in this paper are HS-Dataset1 and HS-Dataset2. Data details of the two datasets are shown in
Table 1.
HS-Dataset1 contains 226,528 samples collected from some cooperative companies and websites, which are divided into 181,213 train samples and 45,315 test samples according to the proportion of 8:2. After sample filtering, there are 19 categories of 4-bit codes, 66 categories of 6-bit codes and 105 categories of 8-bit codes. The maximum length of the sample is 126 words and the minimum length is three words.
HS-Dataset2 contains 8899 samples gathered from a third party company, which are used as test samples. After sample filtering, there are eight categories of 4-bit codes, 12 categories of 6-bit codes and 15 categories of 8-bit codes. The maximum length of the sample is 142 words and the minimum length is 26 words.
Table 2 depicts some samples of raw data in Chinese and
Table 3 depicts these samples in English that is the explanations for
Table 2. We have made the datasets publicly available for follow-up researchers to continue their related work on commodity trade declaration [
35].
5.2. Implementation Details
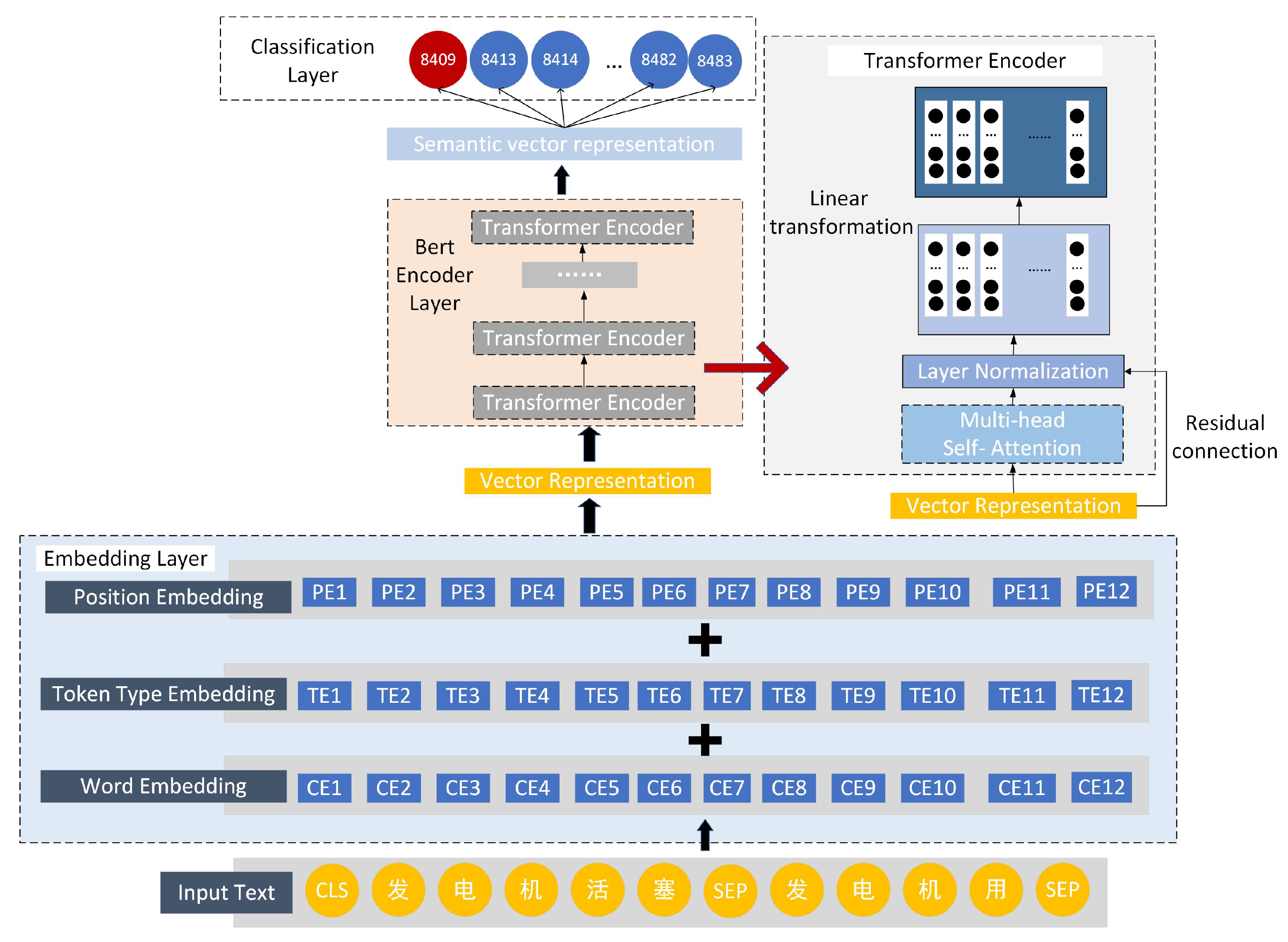
HSBert is composed of embedding layer, Bert encoder layer and classification layer. We use Chinese pre-trained model of Bert to initial it (Devlin et al. [
28]). The vocabulary size of the pre-training model is 21,128. The embedding layer includes three kinds of embedding, namely embedding, position embedding and token type embedding. The three types of embedding are set to 768 dimensions. The Encoder layer includes 12 transformer’s encoder layers, and each layer adopts multi-headed attention mechanism, in which the number of self-attention head is 12. The pooling layer is a linear map function that collects the hidden state corresponding to the first token, and then sets a Tanh function [
36] to activate. The Classification layer is a fully connected layer. There is a dropout layer with a rate of 0.1 in front of the Classification layer to avoid overfitting (Krizhevsky et al. [
37]). The maximum sentence length of the input model is set to 128, and the batch size is set to 16. The model is trained using BertAdam with an initial learning rate of
which can be optimized by a warmup mechanism (He et al. [
38]).
HSCNN-rand and HSCNN-word2vec consist of embedding layer, convolutional layer and classification layer. The embedding layer’s word embedding is set to 128 dimensions. The convolution layer consists of three different one-dimensional convolution kernels, whose sizes are 1, 3 and 5 respectively, and the number of output channels is set to 256. The classification layer is a fully connected linear mapping layer. There is a dropout layer with a rate of 0.2 in front of the classifier layer to avoid overfitting (Krizhevsky et al. [
37]). The input of the model is a sentence with a fixed length of 64, and the batch size is set to 16. The model is trained using Adam [
39] with an initial learning rate of
.
HSNet is a combination of Bert and CNN which consists of Embedding layer, Convolution layer and Classification layer. The Embedding layer’s sentence embedding is set to 128 dimensions. The convolution layer and the Classification layer are the same as HS-CNN. In order to avoid overfitting, there is a dropout layer with a rate of 0.2 in front of the classifier layer. The input of the model is a sentence with a fixed length of 64, and the batch size is set to 16. The model is trained using Adam with initial learning rate of .
5.3. Evaluation Metrics
We use Accuracy(Acc), Precision (Prec), Recall (Rec) and F1-score to calculate model results. In order to evaluate the classification effect more objectively, Weighted F1 and Averaged F1 are obtained by weighting F1-score with the number of samples and categories. The details of evaluation metrics are as follows.
Figure 6 is a confusion matrix. Each column of confusion matrix represents the prediction category, and the total number of each column represents the number of data predicted as the category; each row represents the real belonging category of data, and the total number of data in each row represents the number of data instances of the category. Each part is explained as follows:
TP: The actual sample class is positive, and the prediction result of the model is also positive.
TN: The actual sample class is negative, and the prediction result of the model is also negative.
FP: The actual sample class is positive, and the prediction result of the model is also negative.
FN: The actual sample class is negative, and the prediction result of the model is also positive.
Accuracy: The proportion of the correct samples predicted by model among the total samples. The calculation is shown in Equation (
20):
Precision: The proportion of the positive samples predicted by the model correctly among the total positive samples. The calculation is shown in Equation (
21):
Recall: The proportion of the the positive samples predicted by the model correctly among the total positive samples predicted by the model. The calculation is shown in Equation (
22):
F1-score: The F1 score is a weighted average of accuracy and recall. The calculation is shown in Equation (
23):
Weighted F1: Weighted F1 is obtained by weighting the F1-score with the proportion of different categories of samples to the total number of samples. The calculation is shown in Equation (
24):
where
,
represents number of
i-sample.
Averaged F1: Averaged F1 is obtained by weighting the F1-score with the number of categories of samples. The calculation is shown in Equation (
25):
where
is number of categories.
5.4. Results and Discussion
This section shows the HS-code classification results of all models described in
Section 4. We compared the performance of different models. Due to the space limitation, we selected some representative results to explain.
Firstly, we concluded the classification results of all levels of HS-codes in
Table 4. They consist of 2-bit to 4-bit level, 4-bit to 6-bit level and 6-bit to 8-bit level.
Table 4 shows the evaluation indexes of the single model HSBert and the Fusion model on HS-Dataset1 (
Table 4a) and HS-Dataset2 (
Table 4b). The Acc, Prec, Rec and Weighted-F1 of HS-Dataset1 attained over 95% in each level, and the comprehensive results of the three levels are over 85%. Averaged-F1 is slightly lower than others. This is due to the imbalanced data in each category. The experiment on HS-Dataset2 indicates a better performance that every metric except Averaged-F1 can reach a high index about 99% in each level.
Comparing the comprehensive performance of the two models, the Fusion Model is slightly higher than HSBert. It proves the effectiveness of taking the prediction probability of HSBert and HSNet models as the prediction weight of each category. From the perspective of metrics, Fusion Model can make better decisions than HSBert. HSBert and Fusion Model all achieved excellent results in HS-Dataset2. We try to consider from the perspective of the original data specification, and find that the latter is more standardized from
Table 2 and
Table 3, so we speculate that our model can achieve better results on the standardized data. The more standard the data format is, the better performance the model gets. It also explains why the model can do much better for practical use when the data quality is better.
Table 5 shows the number of categories of HS-code 84145990 and 84799090 in each level.
Table 6 depicts results of different models. Combining the results of
Table 4,
Table 6 and class number of each level in
Table 5, it can be concluded that results of 6-bit to 8-bit are much better than 2-bit to 4-bit and 4-bit to 6-bit. It shows that with the increasing of the number of class, the models’ performance will also be affected, which also proves the practicability and superiority of hierarchical experiment of HS-code proposed by us.
Then, in order to observe the HS-code classification results output from each model and compare their differences, we randomly select the outputs of two HS-code ‘84145990’ and ‘84799090’ in
Table 6 and
Table 7 and
Figure 7. We can find that HSBert and Fusion Model perform better at each level of these two codes. The HSBert model overwhelmingly outperforms over CNN-based and ML models in two datasets and achieves encouraging 83.54%, 100.00%, 81.78% and 99.56% of F1* in the code 84145990 and 84799090, respectively. HSNet’s performance is second only to HSBert, and it also has a good score. Fusion Model also achieves slightly better results than HSBert, which also proves that the fusion of HSBert and HSNet can produce better decision results. HSCNN-rand has a stable performance on both datasets. In contrast, the methods based on ML models are unstable in different datasets, so it suggests that the methods based on Bert and CNN have better performance and transferability than the methods based on ML.
After describing the detailed results of some specific codes, we depict the entire results of all models in this paper.
Table 8 shows the global results of all methods on two datasets. Combined with the comprehensive performance of the two datasets, DL-based models have a better identification ability than traditional ML-based ones especially in HS-Dataset2. It can be concluded that fusion model comes off best in almost all metrics, which clarified that the model obtains the advantages of two sub models by symmetrical decision fusion described in
Section 4.4. Particularly in the averaged-F1, the progress of the fusion model is very obvious. It can be seen from the results of all models that averaged-f1 is much lower than weighted-f1. This is because the data are extremely imbalanced and the single models have poor performances on average-f1. However, through the symmetrical decision fusion, we can summarize that the averaged-f1 value has increased significantly, which indicates that the problem of data imbalance is solved obviously.
Table 8 also shows that there is a significant gap between the performance on HS-Dataset1 and HS-Dataset2 for all models. The major reason is that HS-Dataset2 possesses a more standardized data format. This suggests that, in the actual application scenario, the probability of more standardized data being correctly classified is higher. At the same time, it proves that the proposed model can obtain perfect results if there is a high level of the original data quality in practice use.
Figure 8 shows the Weighted-F1 and Averaged-F1 results output from each models on HS-Dataset1 and HS-Dataset2. It explains the effects among all methods clearly. Weighted-F1 is higher than Averaged-F1. This is also an impact of data imbalance. The model has better recognition ability for the categories with large amount of data, and it will lose the accuracy of a small number of samples. However, it can also be concluded that fusion model can reduce this impact by the weight superposition of different models.
We tested the computational efficiency of the models to evaluate its feasibility in practical application. Time consumption of training process depends on the complexity of the model structure and the amount of training data. In this paper, we used about 180,000 training samples. We evaluated our method on one 2080ti GPU. It needs about 280–300 min to complete the training process with HSCNN, HSBert and HSNet. The fusion model need 2 GPUs to finish the training task within the same time. During the test, the identification process of a sample costs about 32 millisecond, which can fully meet the needs of practical application scenarios.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}