Abstract
This paper is an attempt to study the Xgamma–Weibull distribution using an adaptive progressive type-II censoring plan. This scheme effectively ensures that the experimental time does not exceed a predetermined time limit. Using two classical estimation methods—namely, maximum likelihood and maximum product of spacing—both point and interval estimations for the unknown model parameters, as well as some parameters of life—namely, reliability and hazard rate functions—were obtained. The asymptotic normality of both classical methods was used to determine the approximate confidence intervals for the various parameters. Based on the two conventional methodologies, Bayesian estimations were also investigated using the MCMC technique under the squared error loss function. In addition, the credible intervals of the different parameters were also obtained. To compare the performance of the various approaches, a thorough simulation study was carried out. Furthermore, we propose using several optimality criteria to select the best sampling technique. Finally, two real-world datasets were used to demonstrate how the suggested estimators and optimality criteria operate in real-world circumstances.
1. Introduction
A new one-parameter Xgamma (XG) distribution has been introduced by Sen et al. [1] as a special, finite mixture of exponential and gamma distributions. Recently, using the XG density, Yousof et al. [2] proposed and studied a new extension of the one-parameter Weibull distribution named the two-parameter Xgamma–Weibull (XGW) distribution. They derived several properties of the XGW distribution and also showed that its density can be represented as a mixture of exponentiated Weibull densities. Moreover, they estimated the XGW parameters using uncensored samples via the maximum likelihood estimation method. Cordeiro et al. [3] further proposed the three-parameter XGW distribution as a member of the XG family of distributions. However, we assume here that X is a lifetime random variable of an experimental unit(s) test that follows a two-parameter XGW distribution denoted by , where is the parameter vector. Consequently, the respective probability density function (PDF), cumulative distribution function (CDF), reliability function (RF) and hazard function (HF) for X are given, respectively, by
and
where and are the scale and shape parameters, respectively. Using Equation (1), Yousof et al. [2] stated that the XGW distribution may be used as a generalized form of three new one-parameter lifetime distributions, which act as sub-models, namely:
- Xgamma–Rayleigh distribution if setting ;
- Xgamma–exponential type-I distribution if setting ;
- Xgamma–exponential type-II distribution if setting .
Utilizing various parameter choices for and based on their domains, several shapes for density and hazard functions for the XGW distribution are shown in Figure 1. This shows that the XGW density can be concave-down or left- or right-skewed, while the XGW hazard shapes can be bathtub-shaped or decreasing or increasing.
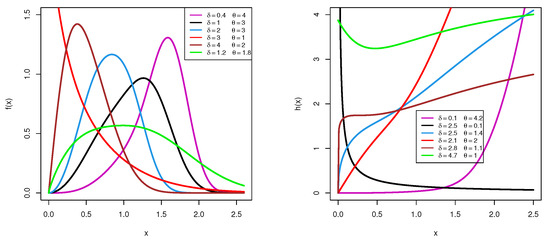
Figure 1.
Plots of density (left) and hazard (right) functions for the XGW distribution.
Censored data are commonly used in studies on reliability and life testing. Due to factors like preserving working experimental units for future use, reducing overall time for the test and financial limits, investigators have to gather data using censored samples. Time-censoring (type-I) and failure-censoring (type-II) strategies are the two widely used censoring strategies in life-testing and reliability studies (see, for additional details, the work by Bain and Engelhardt [4]). These methods are not flexible enough to allow units to be removed from the experiment at any point other than the terminal point. To overcome this shortcoming, a more adaptable censoring scheme known as progressive type-II censoring has been developed. Kundu and Joarder [5] proposed a progressive type-I hybrid censoring (P-I-HC) scheme in which n identical products undergo testing via a specific progressive censoring scheme and the examination terminates at an arbitrary time , where T is a time that is predetermined. The drawback of the P-I-HC plan is that the effective sample size is random and it may be a very small number or equal to zero. As a consequence of this, statistical inference techniques will be ineffective. To address this limitation, Ng et al. [6] presented an adaptive progressive type-II hybrid censoring (AP-II-HC) strategy to improve statistical examination efficiency. In this framework, the number of failures m is specified in advance, and the duration of the test is allowed to exceed the predetermined time T. Furthermore, we have the progressive censoring scheme , but the values of some of the may change as a result of the test. This scheme can be summarized as follows: Suppose that n units are subjected to a life test and is the desired total number of failures. At the time of the ith failure , units are eliminated from the test at random. If the mth failure occurs before time T (i.e., ), the experiment terminates and we have the regular progressive type-II censoring. If, on the other hand, , where and correspond to the dth failure time and occur before time T, then we will not remove any living item from the experiment by placing and . This setting assures that we finish the test when we attain the desired number of failures m and that the overall test duration does not deviate too much from the optimal time T. Figure 2 presents a diagrammatic representation of the AP-II-HC strategy.
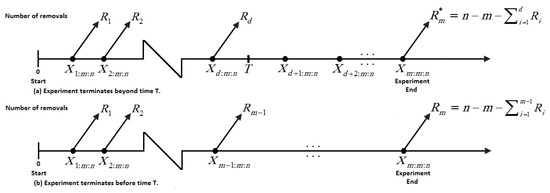
Figure 2.
Diagram of AP-II-HC strategy.
Let be an AP-II-HC sample from a population with a PDF and CDF ; then, the LF for the observed data can be written according to Ng et al. [6] as
where C is a constant. Numerous studies have been conducted based on the AP-II-HC scheme; for example, the work by Al Sobhi and Soliman [7], Nassar et al. [8,9], Panahi and Moradi [10], Elshahhat and Nassar [11], Panahi and Asadi [12], Alotaibi et al. [13] and Nassar et al. [14].
A very competitive estimating technique, the maximum product of spacing estimation method, has lately acquired prominence as an alternative to the standard maximum likelihood approach. Cheng and Amin [15] initially presented the maximum product of spacing technique, demonstrating that the maximum product of spacing estimators (MPSEs) and maximum likelihood estimators (MLEs) have identical asymptotic sufficiency, consistency and efficiency features. The MPSEs are calculated by maximizing the product of the differences between the CDF values at close-ordered locations. Anatolyev and Kosenok [16] investigated the invariance property of MPSEs and discovered that it is the same as that of MLEs. The spacing function (SF) to be maximized can be written using an observed AP-II-HC sample as
Among others, Basu et al. [17,18], Nassar et al. [19] and Okasha and Nassar [20] have all used the maximum product of spacing estimation approach to estimate the unknown parameters of several lifetime distributions.
Though the XGW distribution is very useful in reliability analysis because its hazard shapes can be bathtub-shaped or decreasing or increasing, the problem of estimating the XGW parameters and/or the reliability and hazard rate parameters in the presence of incomplete data, such as the proposed censored sampling, has yet to be investigated. Therefore, the impetus for this study stemmed from (i) the XGW distributions’ applicability to modeling various data types with varying HRFs; (ii) the AP-II-HC scheme’s capacity to improve the accuracy of statistical estimates; and (iii) the fact that statistical and reliability scientists are interested in the performance of various estimation methods for unknown parameters, as well as the reliability and hazard rate functions of the XGW distribution. Our research objectives were as follows:
- Derive and explore the MLEs and MPSEs of unknown parameters, as well as the reliability metrics and accompanying approximate confidence intervals (ACIs);
- Investigate the Bayes estimators and Bayes credible intervals (BCIs) when observed data are gathered using both LFs and SFs and develop the MCMC method based on the squared error (SE) loss function;
- Carry out a full simulation examination to analyze the performance of the various estimations, as it is impossible to tell which approach theoretically generates the best estimates;
- Discuss the best progressive sampling plane for the AP-II-HC scheme when dealing with the XGW distribution;
- Present two applications based on real-life engineering and medical datasets to show the superiority and flexibility of the XGW model compared to five lifetime distributions (as competitors); namely, Xgamma, gamma, generalized exponential, Weibull and exponential Weibull distributions.
The remainder of the article is organized as follows: The MLEs and the associated ACIs of the model parameters, as well as the reliability indices, are provided in Section 2. Section 3 presents the MPSEs and ACIs using the maximum product of spacing approach. Section 4 discusses Bayesian estimations using the LF and SF. Section 5 summarizes the simulation outcomes. In Section 6, optimal censoring plans based on three optimality criteria are presented. Section 7 examines two applications to real data. Finally, in Section 8, some final observations are made.
2. Likelihood Estimation
Let be an AP-II-HC sample taken from a population with a CDF, as given by Equation (2), with a progressive censoring scheme . Then, based on Equations (1), (2) and (5), the LF, ignoring the constant term, can be written as
where , , and .
Taking the natural logarithm of Equation (7), the log-LF can be expressed as
By solving the following two normal equations simultaneously with respect to and , one can obtain the MLEs of and , denoted by and , respectively, as:
and
where , and . It is noted that the MLEs cannot be acquired from Equations (9) and (10) explicitly. Therefore, one can utilize any numerical procedure to obtain the needed estimates.
Upon obtaining the MLEs and , and based on the invariance property of the MLEs, the MLEs of the RF and HRF can be derived directly from Equations (2) and (4) at mission time t, respectively, as given below
and
Remark 1.
Using Equation (7), several results from the literature can be easily obtained as special cases, such as
- The estimation results presented by Sen et al. [21] in the case of the XG distribution based on progressive type-II censored sampling by setting and ;
- The estimation results presented by Sen et al. [1] and Saha et al. [22] in the case of the XG distribution based on complete sampling by setting , , and for ;
- The estimation results presented by Elshahhat and Elemary [23] in the case of the XG distribution based on AP-II-HC sampling by setting ;
- The estimation results presented by Yousof et al. [2] in the case of the XGW distribution by setting , and for .
Regarding the interval estimation of the unknown parameters, as well as the RF and HRF, we employ the asymptotic properties of the MLEs to construct the ACIs of various parameters. We first use the observed Fisher information matrix to estimate the variance-covariance matrix, which is expressed as and given by
where
and
where , , and .
Based on the asymptotic normality of the MLEs, one can construct the ACIs of and at the confidence level as follows
where is the upper th percentile point of the standard normal distribution. In order to create the ACIs for the RF and HRF, we must also establish the variances for their estimators. In our case, the delta technique is used to approximate the variances of and (see the work by Greene [24] for additional information). We must first obtain the quantities and , which are the first-order derivatives of the RF and HRF with respect to and , respectively, to achieve the necessary estimated variances as follows
and
where .
Now, let and as evaluated at the MLEs and . Then, we can obtain the approximate estimates of the variances of and , respectively, as
Consequently, the ACIs of RF and HRF can be expressed as
respectively.
3. Product of Spacing Estimation
Let be an AP-II-HC sample from the XGW population with a CDF as given by Equation (2). Then, from Equations (2) and (6), the SF, without the constant term, can be expressed as follows with
where . The natural logarithm of Equation (17) is expressed as
The MPSEs of the parameters and , denoted by and , can be acquired by solving the following normal equations
and
where , , and . As in the case of the MLEs, one should utilize numerical procedures to solve Equations (19) and (20) to determine the MPSEs of and . According to Cheng and Traylor [25], the MPSEs possess the same invariance property as the MLEs. Therefore, we can obtain the MPSEs of the RF and HRF using this property as follows
and
Cheng and Amin [15] and Cheng and Traylor [25] stated that MPSEs have the same asymptotic properties as MLEs. As a result, we can employ these properties to obtain the ACIs of the different unknown parameters based on the MPSEs. We first estimate the variance-covariance matrix based on and , denoted by , as follows
where
and
where , , and .
Now, the ACIs of and can be computed respectively as
By approximating the estimated variances of the RF and HRF using the delta method, we can obtain the ACIs of and , respectively, as follows
where and are evaluated at the MPSEs of and as defined in Equation (16).
4. Bayesian Estimation
In this section, we look at the Bayesian estimation approach to estimate the XGW distribution’s parameters (the RF and HRF). The point and interval estimates of the various parameters are obtained in this section using both the LF and SF. The Bayes estimates are calculated by taking into account the SE loss function and assuming that the parameters and are independent and a priori distributed as gamma distributions. The combined prior distribution of and , where , can be expressed as follows
Here, we assume gamma priors, which adapt to the support of the XGW distribution’s parameters and are thought to be more flexible than other prior distributions. Based on the LF given by Equation (7) and the joint prior in Equation (22), one can write the joint posterior distribution of and based on the LF as
where
Similarly, by combining the SF given by Equation (17) and the joint prior in Equation (22), one can write the joint posterior distribution of and using the SP as follows
where
Under the SE loss function, the Bayes estimator of any function of the unknown parameters—say, —using both posterior distributions can be derived, respectively, as follows
and
The integrals offered by Equations (25) and (26) are not available in closed forms. As a result of this, in this scenario, we must think about using the MCMC approach to generate samples from the posterior distributions and then compute the Bayes estimates for the unknown parameters, as well as the related credible intervals. To use the MCMC technique, we first need to derive the full conditional distributions of the various parameters. Based on the posterior distribution derived based on the LF as displayed in Equation (23), the full conditional distributions of and are given, respectively, by
and
In a similar way, we can derive the full conditional distributions of the unknown parameters and from the posterior distribution obtained based on the SF as given by Equation (24) as follows
and
respectively.
Although the full conditional distributions derived based on both the LF and SF cannot be represented in standard forms, their graphs are equivalent to the normal distribution. Using, for example, , , and progressive censoring (where means that 1 is repeated 50 times), Figure 3 shows that the full conditional distributions in Equations (27)–(30) of and behave like normal densities. Therefore, we can employ the Metropolis–Hastings (M-H) technique with a normal proposal distribution to generate random samples from these distributions in order to obtain the required estimates.
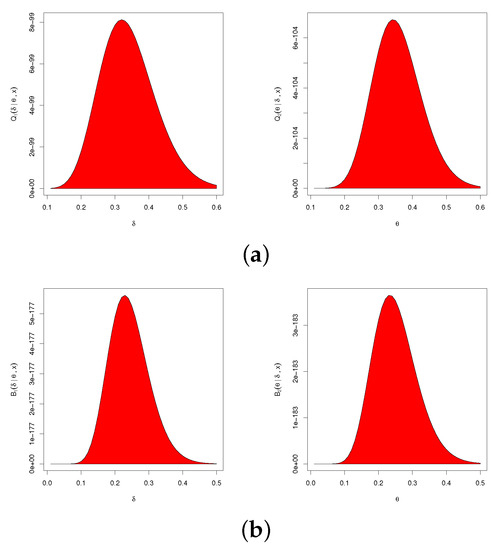
Figure 3.
Conditional PDFs of (left) and (right): (a) posterior LF-based distribution; (b) posterior SF-based distribution.
The procedures below demonstrate how to obtain the necessary samples and the required point and credible interval estimates. It is important to mention here that the following steps are evaluated based on the LF, and one can easily use the same steps to obtain the Bayes estimates using the SF, as follows
- Step 1.
- Start with the first chain ;
- Step 2.
- Specify the initial values
- Step 3.
- Employ Equation (27) to simulate with a normal proposal distribution with mean and variance by using the M-H algorithm;
- Step 4.
- Use Equation (28) and the M-H steps to obtain with a normal proposal distribution with mean and variance ;
- Step 5.
- Use the obtained samples to compute and ;
- Step 6.
- Set ;
- Step 7.
- Redo steps 3–6 M times to obtainwhere or ;
- Step 8.
- Compute the Bayes estimate of using the SE loss function aswhere is the burn-in period.
5. Monte Carlo Simulations
To highlight the actual behavior of the offered estimators of , , and , based on 1000 AP-II-HC samples generated from the distribution, extensive simulations were conducted. For the distinct time , the plausible values for and were taken as 0.9854 and 0.1087, respectively. Various choices for T (the threshold point), n (the full sample size) and m (the effective censored size) and different censoring schemes were also utilized, such as , and m being determined as a failure percentage (FP) for each n as and . Remember that, as soon as the number of failed units reached a specific value m, the experiment was stopped. Moreover, to highlight the performance of removal methods, several designs for … were used as follows
To obtain AP-II-HC data from the XGW model, for pre-specific values of T, n, m and , we implemented the following generation process:
- Step 1:
- Simulate traditional progressive type-II censored order statistics as follows:
- a.
- Create independent variates of size m from a uniform distribution;
- b.
- Set ;
- c.
- Obtain for ;
- d.
- Obtain from Equation (2);
- Step 2:
- Find d, where , and ignore the other staying items ;
- Step 3:
- From , obtain the first-order statistics.
Once the 1000 desired AP-II-HC samples were obtained, the classical point estimates (including ML and MPS estimates), as well as 95% classical interval estimates (including ACI-LF and ACI-SF estimates), were developed. To judge the performance of the proposed density priors, we considered two separate informative sets for the hyperparameters namely:
- Prior one: ;
- Prior two: .
Following Section 4, we repeated the MCMC procedure 12,000 times and eliminated the first 2000 times as burn-in. After collecting 10,000 MCMC samples, based on the Bayes procedures from both likelihood-based and spacings-based estimates, the Bayes and 95% credible interval estimates of , , and were obtained. Using 4.2.2 software, all frequentist and Bayes evaluations were performed using the "" (developed by Henningsen and Toomet [26]) and "" (developed by Plummer et al. [27]) packages.
Specifically, the comparison between point estimates of (as an example) was undertaken based on the following criteria:
- Root-mean-squared error (RMSE):
- Mean relative absolute bias (MRAB):where is the calculated estimate of at ith simulated sample.
Furthermore, the comparison of the interval estimates of was undertaken based on the following criteria:
- Average confidence length (ACL):
- Coverage percentages (CPs):where is the indicator, and (,) denotes the two-sided asymptotic (or Bayes credible) interval estimates of . In the same way, the simulated RMSE, MRAB, ACL and CP results for , or can be easily calculated.
A heat map is a graphical representation of data where the individual values contained in a matrix can be represented by some specific colors. Thus, in Figure 4, Figure 5, Figure 6 and Figure 7, the simulated results for , , and are plotted, respectively. Also, all simulation tables are provided in the Supplementary File. For instance, for prior one (P1), some abbreviations are used in Figure 4, Figure 5, Figure 6 and Figure 7, such as: Bayes estimates from likelihood function (BLF-P1), Bayes estimates from spacings function (BSF-P1), Bayes credible interval from likelihood function (BCI-LF-P1) and Bayes credible interval from spacings function (BCI-SF-P1).
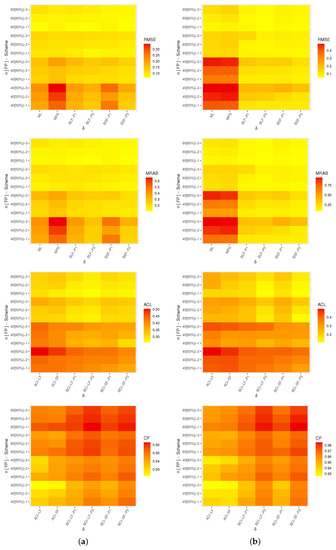
Figure 4.
Heat map for the simulation outcomes of . (a) ; (b) .
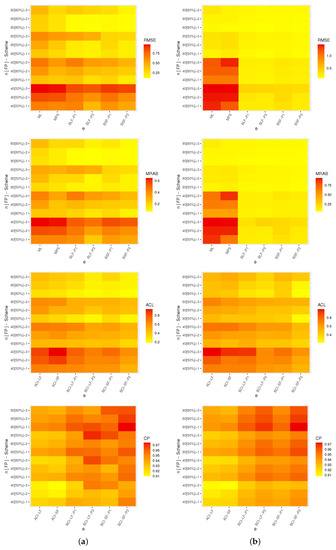
Figure 5.
Heat map for the simulation outcomes of . (a) ; (b) .
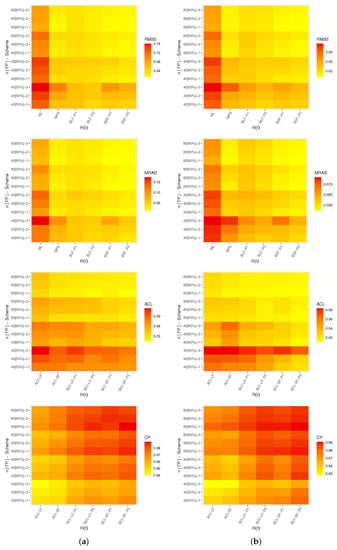
Figure 6.
Heat map for the simulation outcomes of . (a) T = 5.
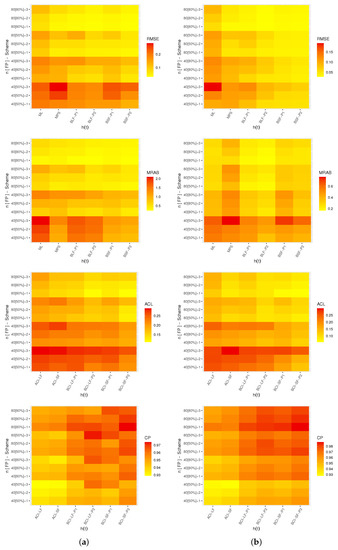
Figure 7.
Heat map for the simulation outcomes of . (a) ; (b) .
From Figure 4, Figure 5, Figure 6 and Figure 7, in terms of the smallest levels for the RMSEs, MRABs, ACLs and CPs, we can note the following observations:
- As a general note, when n (or m) increased, all proposed point/interval estimates performed better. A similar finding was also noted when was narrowed down;
- As T increased, it can be seen that:
- –
- Both the RMSEs and MRABs for and increased while those associated with and decreased;
- –
- The ACLs for , and decreased while those associated with decreased;
- –
- The opposite behavior was observed for all unknown parameters based on CP values;
- Comparing the proposed censoring plans, the calculated estimates of , , and were more efficient with Scheme-1 than with the others;
- Comparing the Bayesian and frequentist estimates of , , and , it is clear that the point (or interval) estimates from the former were better than those obtained from the latter;
- Considering the behavior of the suggested priors, the Bayes inferences from prior two were better than those created from prior one since prior two’s variance was smaller than prior one’s;
- Comparing the proposed point estimation approaches, in most cases, the simulation results showed that:
- –
- For estimating the reliability time parameters and , it was noted that the MPS (along with its "BSF" ) method performed better than the likelihood estimation (along with its "BLF") method;
- –
- For estimating the shape parameter , the ML and BSF methods performed better than the others;
- –
- For estimating the scale parameter , the MPS and BLF methods performed better than the others;
- Comparing the proposed interval estimation approaches, based on the product of spacings methodology, the simulation results showed that the interval estimates obtained from both asymptotic and credible interval methods for , , and were better than the others.
6. Optimum Progressive Censoring Plans
In earlier sections, we looked at classical and Bayesian estimations of the XGW parameters when samples were collected under AP-II-HC censoring. In a reliability context, selecting the best censoring scheme from a collection of all feasible schemes that give an extensive amount of information about the model parameter(s) of interest is an important goal for any reliability practitioner. For this objective, Balakrishnan and Aggarwala [28] first examined the topic of selecting the optimum life-testing censoring using various setups. The term "potential schemes" in this context refers to the several choices. According to Ng et al. [29], when the values for n (total experimental units), m (effective sample size) and (removal pattern) are prefixed in advance, one can select the optimal progressive type-II censoring design. Some prominent criteria were applied to discover the best progressive censoring scheme and are given in Table 1. Table 1 shows that criteria A-optimality and D-optimality attempt to reduce the trace and determinant of the estimated variance–covariance matrices obtained based on both the LF and SF methods. Furthermore, in terms of the F-optimality criterion, we want to maximize the observed Fisher’s information values in relation to the offered MLEs (or MPSEs). The criteria in Table 1 are evaluated with the MLEs, and one can obtain them with the MPSEs by replacing the MLEs with the MPSEs.

Table 1.
Metrics for optimum progressive plans.
7. Real-Life Applications
To demonstrate the significance and application of the presented approaches in real-world settings and to highlight the usefulness and flexibility of the proposed model, this section examines two real-world datasets from the engineering and medical areas.
7.1. Electronic Devices
This application involved analyzing the failure times of 18 electronic devices reported by Wang [30] and reanalyzed by Elshahhat and Abu El Azm [31]. Each data point was divided, for instance, by 10 as follows: 0.5, 1.1, 2.1, 3.1, 4.6, 7.5, 9.8, 12.2, 14.5, 16.5, 19.6, 22.4, 24.5, 29.3, 32.1, 33, 35, 42.
We first compared the XGW distribution from the complete electronic devices data with five lifetime models employing various hazard rates as their competitors; namely, the XG, gamma (G), generalized–exponential (GE), Weibull (W) and exponential–Weibull (EW) distributions. In Table 2, all the densities of the competing models (for and ), along with their author(s), are presented. To monitor the best model, six criteria for model selection were used; namely, the (1) Kolmogorov–Smirnov () (the statistic and its p-value), (2) negative-log-likelihood (), (3) Akaike (), (4) consistent Akaike (), (5) Bayesian (), and (6) Hannan–Quinn () measures.
Table 2.
Several competitors of the Xgamma–Weibull distribution.
Using the "" package developed by Marinho et al. [36] in 4.2.2 software, the ML estimators with their standard errors (St.Es) for the model parameters, as well as the fitted criteria, were acquired (see Table 3). Since the XGW distribution had the smallest values with respect to the , , , , and statistics, although it also had the highest p-value, Table 3 shows that the XGW distribution provided the best fit compared to all the competitor distributions. Moreover, based on the electronic devices data, we demonstrate the superiority of the proposed model via some useful plots; namely: (i) probability–probability (PP) plots; (ii) estimated PDFs; and (iii) estimated/empirical RFs (see Figure 8). From Figure 8, it can be seen that the graphical presentations support the same numerical findings as listed in Table 3. To examine the existence and uniqueness of the calculated ML estimates of the XGW parameters, the contour of the log-likelihood function for different choices of and based on the complete electronic devices dataset was also plotted and is displayed in Figure 8. It indicated that the ML estimates and existed and were unique. Henceforward, to run any additional calculations based on electronic devices data, we propose considering these values as suitable starting points.
Table 3.
Summary fit of the XGW distribution and its competitors with electronic devices.
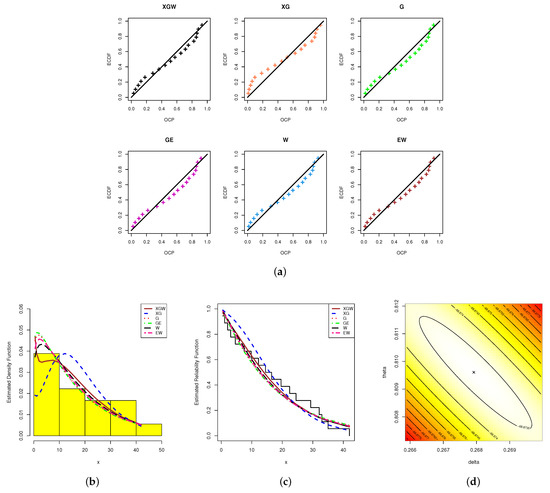
Figure 8.
The PP plots (a), fitted PDF (b), fitted RF (c) and contour of the log-likelihood (d) from the electronic devices data.
In Table 4, using the complete electronic devices data and based on with different choices for T and R, the results for different AP-II-HC samples are reported. For example, censoring scheme is denoted as . For the point classical (including ML and MPS) estimates with their St.Es and 95% asymptotic interval (including ACI-LF and ACI-SF) estimates with their interval widths (IWs) were calculated and are provided in Table 5. Using the M-H algorithm steps, from the proposed posterior PDFs, we simulated 50,000 MCMC iterations and discarded the first 10,000 of them. Based on the non-informative priors of and , the Bayes estimates (with their St.Es) of and and and (at the distinct time ) were also obtained (see Table 5). Moreover, from the 40,000 MCMC variates retained, 95% asymptotic interval (including BCI-LF and BCI-SF) estimates with their IWs for the same unknown quantities were also computed and are presented in Table 5. These findings show that, with regard to the lowest levels for the St.E and IW values, the estimates created from the Bayes MCMC approach through MCMC-LF (or MCMC-SF) methods for , , and performed better than the others. A similar conclusion was also reached when the asymptotic intervals were compared with the credible intervals.
Table 4.
Three AP-II-HC samples from electronic devices data.
Table 5.
Estimates of , , and from electronic devices data.
To evaluate the convergence of the 40,000 MCMC variates simulated with the LF and SF approaches, using data as an example, the traces and Gaussian kernel densities are shown in Figure 9 with histogram plots of , , and . In each plot, the sample mean is highlighted by a solid blue line. In each histogram, 95% BCI bounds are highlighted by dashed lines. Figure 9 indicates that the proposed MCMC samplers converged adequately. It also indicates that the generated posterior estimates of and were very close to being symmetric, while those of and were negatively and positively skewed, respectively. Moreover, using datasets, the trace and histogram plots for , , and are presented in the Supplementary File for easy access.
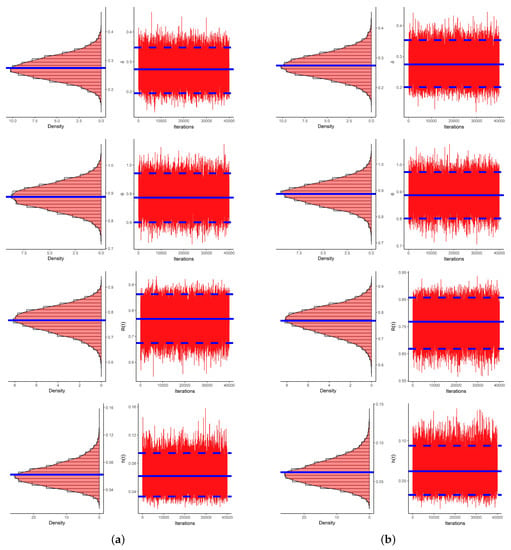
Figure 9.
Histogram (left) and trace (right) plots for , , and from electronic devices data. (a) LF approach; (b) SF approach.
Following the optimum criteria provided in Table 1, from the evaluated variances and covariances of the ML and MPS estimates obtained from the generated samples , the best progressive censoring was determined (see Table 6). For both LF and SF approaches, the censoring scheme used with sample was the best censoring plan for all given criteria. The optimum progressive censoring suggested in this application supported the results obtained in the simulation experiments.
Table 6.
Optimum censoring from electronic devices data.
7.2. Head and Neck Cancer
This application involved examining the survival periods (in days) of 44 individuals with cancer of the head and neck (CHN) (see Table 7). These patients were treated using a combination of radiotherapy and chemotherapy. This dataset was first published by Efron [37] and previously reanalyzed by Elshahhat and Rastogi [38].
Table 7.
Survival times of 44 CHN patients.
To compare the XGW distribution with the other competitive models presented in Table 2, based on the complete CHN dataset, the evaluated values for the , , , , , and (p-value) statistics are reported in Table 8. The ML estimates (along with their St.Es) of all competing models were also computed (see Table 8). It is obvious from the complete CHN data that the XGW distribution had the highest p-value and the smallest values with respect to the other fitted criteria. Thus, the XGW distribution was the best choice compared to the others. Also, it is clear from Table 3 and Table 8 that the best competitive lifetime model close to the proposed XGW distribution was the two-parameter W lifetime model. Again, based on the CHN data, the PP plots, estimated PDF and estimated/empirical RF, as well as the contour plot of the log-likelihood function, were plotted and are displayed in Figure 10. As we anticipated, the data in Figure 10 supported the results presented in Table 8. Moreover, the data in Figure 10d showed that the ML estimates and existed and were unique.
Table 8.
Summary fit of the XGW distribution and its competitors from CHN data.
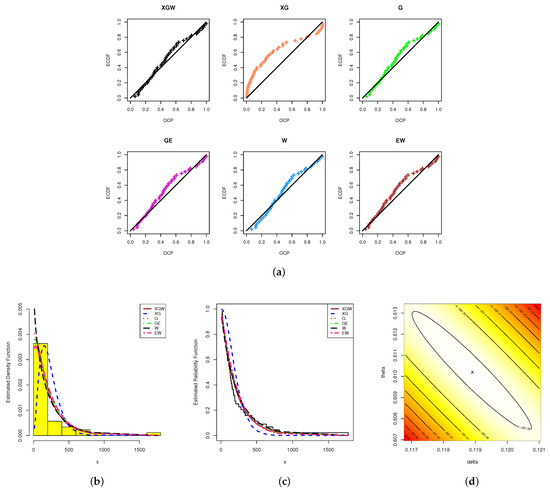
Figure 10.
The PP plots (a), fitted PDF (b), fitted RF (c) and contour of the log-likelihood (d) from CHN data.
Next, from the full CHN data, various artificial AP-II-HC samples were generated and are reported in Table 9. Using Table 9, the offered point estimates (with their St.Es) and the offered interval estimates (with their IWs) of , , and at could be calculated and are listed in Table 10. Just like our settings for the MCMC sampler described in Section 7.1, to perform the Bayesian calculations, we generated 40,000 MCMC variates after ignoring the first 10,000 variates.
Table 9.
Three AP-II-HC samples from CHN data.
Table 10.
Estimates of , , and from CHN data.
From Table 10, it can be seen the Bayes (point/interval) estimates of , , and were quite close to the frequentist (point/interval) estimates. As an example, both trace and density plots for the 40,000 MCMC estimates of , , and based on the data are displayed in Figure 11. They show that the simulated MCMC samples converged sufficiently. They also support the facts displayed in Figure 9. Additionally, the trace and histogram plots for the same parameters using the and datasets were also plotted and are given in the Supplementary File.
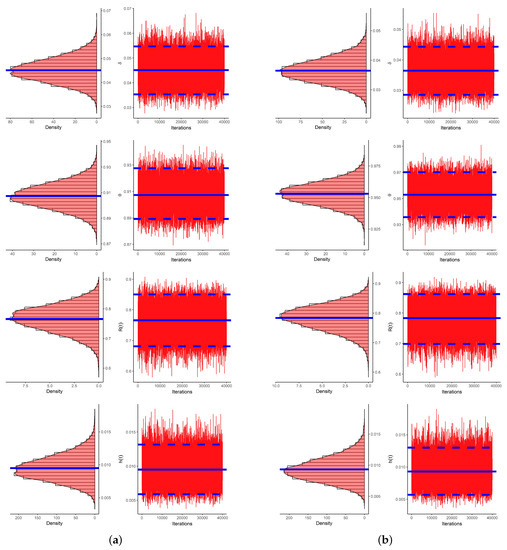
Figure 11.
Histogram (left) and trace (right) plots for , , and from CHN data. (a) LF approach; (b) SF approach.
Furthermore, using all samples for presented in Table 9, the best progressive censoring was determined and is provided in Table 11. The progressive design used with sample was the best censoring plan with respect to all the optimum criteria considered in Table 1. Table 11 also supports the findings reported in Section 5.
Table 11.
Optimum censoring from CHN data.
Ultimately, in the presence of adaptive type-II progressive hybrid censored information, we can state that the analysis of the given real datasets showed that the proposed estimation methodologies can be easily used in practical scenarios and provide a good demonstration of the XGW distribution.
8. Concluding Remarks
This paper addressed the estimation issues involving unknown parameters, reliability and hazard rate functions with the Xgamma–Weibull distribution using an adaptive progressive type-II censoring strategy. For this goal, traditional estimating methods, such as likelihood and product of spacings estimates, were applied, and then Bayesian estimates were also used based on these two methodologies. The Bayesian estimates were calculated using independent gamma priors and the squared error loss function. The asymptotic properties of the acquired frequentist estimates were used to create the asymptotic confidence intervals for all unknown quantities. In the Bayes framework, point estimates were obtained using MCMC techniques, and the credible intervals were calculated using the same methodology. A simulation study was conducted under various conditions to compare the outcomes of the various estimations. According to the simulation results, Bayesian estimates outperformed conventional estimates in terms of the root-mean-squared error, the relative absolute bias, the confidence length and the coverage percentage. Furthermore, we provided an optimal censoring strategy based on several information measures. Finally, two real-world datasets were analyzed to show how the proposed approaches can be used in practice.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/sym15071428/s1, Table S1: Average estimates (1st column), RMSEs (2nd column) and MRABs (3rd column) of ; Table S2: Average estimates (1st column), RMSEs (2nd column) and MRABs (3rd column) of ; Table S3: Average estimates (1st column), RMSEs (2nd column) and MRABs (3rd column) of ; Table S4: Average estimates (1st column), RMSEs (2nd column) and MRABs (3rd column) of ; Table S5: The ACLs (1st column) and CPs (2nd column) of asymptotic/credible intervals of ; Table S6: The ACLs (1st column) and CPs (2nd column) of asymptotic/credible intervals of ; Table S7: The ACLs (1st column) and CPs (2nd column) of asymptotic/credible intervals of ; Table S8: The ACLs (1st column) and CPs (2nd column) of asymptotic/credible intervals of ; Figure S1: Histogram (left) and Trace (right) plots of , , and based on sample from electronic devices data; Figure S2: Histogram (left) and Trace (right) plots of , , and based on sample from electronic devices data; Figure S3: Histogram (left) and Trace (right) plots of , , and based on sample from CHN data; Figure S4: Histogram (left) and Trace (right) plots of , , and based on sample from CHN data.
Author Contributions
Methodology, H.S.M. and M.N.; Funding acquisition, H.S.M.; Software, A.E.; Supervision, M.N. and A.E.; Writing—original draft, H.S.M. and A.E.; Writing—review and editing, A.E. and M.N. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Princess Nourah bint Abdulrahman University Researchers Supporting Project (number PNURSP2023R175), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Data Availability Statement
The authors confirm that the data supporting the findings of this study are available within the article.
Acknowledgments
The authors would like to express their thanks to the editor and anonymous referees for helpful comments and observations. The authors would like to thank the Princess Nourah bint Abdulrahman University for supporting (number PNURSP2023R175) this work.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Sen, S.; Maiti, S.S.; Chandra, N. The xgamma distribution: Statistical properties and application. J. Mod. Appl. Stat. Methods 2016, 15, 38. [Google Scholar] [CrossRef]
- Yousof, H.M.; Korkmaz, M.Ç.; Sen, S. A new two-parameter lifetime model. Ann. Data Sci. 2021, 8, 91–106. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Altun, E.; Korkmaz, M.C.; Pescim, R.R.; Afify, A.Z.; Yousof, H.M. The xgamma family: Censored regression modelling and applications. Revstat-Stat. J. 2020, 18, 593–612. [Google Scholar]
- Bain, L.J.; Engelhardt, M. Statistical Analysis of Reliability and Life-Testing Models, 2nd ed.; Marcel Dekker: New York, NY, USA, 1991. [Google Scholar]
- Kundu, D.; Joarder, A. Analysis of Type-II progressively hybrid censored data. Comput. Stat. Data Anal. 2006, 50, 2509–2528. [Google Scholar] [CrossRef]
- Ng, H.K.T.; Kundu, D.; Chan, P.S. Statistical Analysis of Exponential Lifetimes under an Adaptive Type-II Progressive Censoring Scheme. Nav. Res. Logist. 2009, 56, 687–698. [Google Scholar] [CrossRef]
- Al Sobhi, M.M.A.; Soliman, A.A. Estimation for the exponentiated Weibull model with adaptive Type-II progressive censored schemes. Appl. Math. Model. 2016, 40, 1180–1192. [Google Scholar] [CrossRef]
- Nassar, M.; Abo-Kasem, O.E. Estimation of the inverse Weibull parameters under adaptive type-II progressive hybrid censoring scheme. J. Comput. Appl. Math. 2017, 315, 228–239. [Google Scholar] [CrossRef]
- Nassar, M.; Abo-Kasem, O.; Zhang, C.; Dey, S. Analysis of Weibull distribution under adaptive Type-II progressive hybrid censoring scheme. J. Indian Soc. Probab. Stat. 2018, 19, 25–65. [Google Scholar] [CrossRef]
- Panahi, H.; Moradi, N. Estimation of the inverted exponentiated Rayleigh distribution based on adaptive Type II progressive hybrid censored sample. J. Comput. Appl. Math. 2020, 364, 112345. [Google Scholar] [CrossRef]
- Elshahhat, A.; Nassar, M. Bayesian survival analysis for adaptive Type-II progressive hybrid censored Hjorth data. Comput. Stat. 2021, 36, 1965–1990. [Google Scholar] [CrossRef]
- Panahi, H.; Asadi, S. On adaptive progressive hybrid censored Burr type III distribution: Application to the nano droplet dispersion data. Qual. Technol. Quant. Manag. 2021, 18, 179–201. [Google Scholar] [CrossRef]
- Alotaibi, R.; Elshahhat, A.; Rezk, H.; Nassar, M. Inferences for Alpha Power Exponential Distribution Using Adaptive Progressively Type-II Hybrid Censored Data with Applications. Symmetry 2022, 14, 651. [Google Scholar] [CrossRef]
- Nassar, M.; Alotaibi, R.; Dey, S. Estimation Based on Adaptive Progressively Censored under Competing Risks Model with Engineering Applications. Math. Probl. Eng. 2022, 2022, 6731230. [Google Scholar] [CrossRef]
- Cheng, R.C.H.; Amin, N.A.K. Estimating parameters in continuous univariate distributions with a shifted origin. J. R. Stat. Soc. Ser. 1983, 45, 394–403. [Google Scholar] [CrossRef]
- Anatolyev, S.; Kosenok, G. An alternative to maximum likelihood based on spacings. Econom. Theory 2005, 21, 472–476. [Google Scholar] [CrossRef]
- Basu, S.; Singh, S.K.; Singh, U. Parameter estimation of inverse Lindley distribution for Type-I censored data. Comput. Stat. 2017, 32, 367–385. [Google Scholar] [CrossRef]
- Basu, S.; Singh, S.K.; Singh, U. Estimation of inverse Lindley distribution using product of spacings function for hybrid censored data. Methodol. Comput. Appl. Probab. 2019, 21, 1377–1394. [Google Scholar] [CrossRef]
- Nassar, M.; Dey, S.; Wang, L.; Elshahhat, A. Estimation of Lindley Constant-Stress Model via Product of Spacing with Type-II Censored Accelerated Life Data. Commun. Stat.-Simul. Comput. 2021. [Google Scholar] [CrossRef]
- Okasha, H.; Nassar, M. Product of spacing estimation of entropy for inverse Weibull distribution under progressive type-II censored data with applications. J. Taibah Univ. Sci. 2022, 16, 259–269. [Google Scholar] [CrossRef]
- Sen, S.; Chandra, N.; Maiti, S.S. Survival estimation in xgamma distribution under progressively Type-II right censored scheme. Model Assist. Stat. Appl. 2018, 13, 107–121. [Google Scholar] [CrossRef]
- Saha, M.; Yadav, A.S. Estimation of the reliability characteristics by using classical and Bayesian methods of estimation for xgamma distribution. Life Cycle Reliab. Saf. Eng. 2021, 10, 303–317. [Google Scholar] [CrossRef]
- Elshahhat, A.; Elemary, B.R. Analysis for Xgamma parameters of life under Type-II adaptive progressively hybrid censoring with applications in engineering and chemistry. Symmetry 2021, 13, 2112. [Google Scholar] [CrossRef]
- Greene, W.H. Econometric Analysis, 4th ed.; Prentice-Hall: New York, NY, USA, 2000. [Google Scholar]
- Cheng, R.C.H.; Traylor, L. Non-regular maximum likelihood problems. J. R. Stat. Soc. Ser. (Methodol.) 1995, 57, 3–24. [Google Scholar] [CrossRef]
- Henningsen, A.; Toomet, O. maxLik: A package for maximum likelihood estimation in R. Comput. Stat. 2011, 26, 443–458. [Google Scholar] [CrossRef]
- Plummer, M.; Best, N.; Cowles, K.; Vines, K. CODA: Convergence diagnosis and output analysis for MCMC. R News 2006, 6, 7–11. [Google Scholar]
- Balakrishnan, N.; Aggarwala, R. Progressive Censoring, Theory, Methods and Applications; Birkhauser: Boston, MA, USA, 2000. [Google Scholar]
- Ng, H.K.T.; Chan, P.S.; Balakrishnan, N. Optimal progressive censoring plans for the Weibull distribution. Technometrics 2004, 46, 470–481. [Google Scholar] [CrossRef]
- Wang, F.K. A new model with bathtub-shaped failure rate using an additive Burr XII distribution. Reliab. Eng. Syst. Saf. 2000, 70, 305–312. [Google Scholar] [CrossRef]
- Elshahhat, A.; Abu El Azm, W.S. Statistical reliability analysis of electronic devices using generalized progressively hybrid censoring plan. Qual. Reliab. Eng. Int. 2022, 38, 1112–1130. [Google Scholar] [CrossRef]
- Johnson, N.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions, 2nd ed.; John Wiley & Sons: New York, NY, USA, 1994. [Google Scholar]
- Gupta, R.D.; Kundu, D. Generalized exponential distribution: Different method of estimations. J. Stat. Comput. Simul. 2001, 69, 315–337. [Google Scholar] [CrossRef]
- Weibull, W. A statistical distribution function of wide applicability. J. Appl. Mech. 1951, 18, 293–297. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Ortega, E.M.; Lemonte, A.J. The exponential–Weibull lifetime distribution. J. Stat. Comput. Simul. 2014, 84, 2592–2606. [Google Scholar] [CrossRef]
- Marinho, P.R.D.; Silva, R.B.; Bourguignon, M.; Cordeiro, G.M.; Nadarajah, S. AdequacyModel: An R package for probability distributions and general purpose optimization. PLoS ONE 2019, 14, e0221487. [Google Scholar] [CrossRef] [PubMed]
- Efron, B. Logistic regression, survival analysis, and the Kaplan-Meier curve. J. Am. Stat. Assoc. 1988, 83, 414–425. [Google Scholar] [CrossRef]
- Elshahhat, A.; Rastogi, M.K. Bayesian Life Analysis of Generalized Chen’s Population Under Progressive Censoring. Pak. J. Stat. Oper. Res. 2022, 18, 675–702. [Google Scholar] [CrossRef]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).