1. Introduction
In a (real) Hilbert space
, we focus on resolving the monotone inclusion problem, which entails the sum of three operators, as follows:
where
is maximal monotone,
is monotone
L-Lipschitz continuous with
, and
is
-cocoercive, for some
. Moreover, let
be maximal monotone and assume that it has a solution, namely,
Problem (
1) captures numerous significant challenges in convex optimization problems, signal and image processing, saddle point problems, variational inequalities, partial differential equations, and similar problems. For example, see [
1,
2,
3,
4].
In recent years, many popular algorithms dealing with monotone inclusion problems involving the sum of three or more operators have been covered in the literature. Although traditional splitting algorithms [
5,
6,
7,
8] play an indispensable part in addressing monotone inclusions that include the sum of two operators, they cannot be directly applied to solve problems beyond the sum of two operators. A generalized forward–backward splitting (GFBS) method [
3] is designed to address the monotone inclusion problem:
where
,
indicate maximal monotone operators, and
is the same as (
1). A subsequent work by Raguet and Landrieu [
9] addressed (
2) using a preconditioned generalized forward–backward splitting algorithm. An equivalent form of Equation (
2) can be expressed as the following monotone inclusion formulated in the product space:
where
and
are the same as (
1), and
denotes the normal cone of a closed vector subspace
V. Two novel approaches for solving (
3) are presented in [
10], where the two methods are equivalent under appropriate conditions. Interestingly,
can be extended to a maximal monotone operator. However, the resolvent in this case is no longer linear, necessitating more complicated work to establish convergence. In [
11], Davis and Yin finished this work by a three-operator splitting method. In a sense, it extends the GFBS method. It is a remarkable fact that the links between the above methods were precisely studied by Raguet [
12], who also derived a new approach to solve (
2) along with an extra maximal monotone operator
M. Note that the case of (
3) occurs when
is generalized as a maximal monotone operator and
C is relaxed to monotone Lipschitz continuous. A new approach [
13] has been established to deal with this case within the computer-assisted skill. In contrast to [
13], two new schemes [
14] were discovered for tackling the same problem through discretising a continuous-time dynamical system. If
is replaced by a monotone Lipschitz operator
B, (
3) can be translated into (
1). Concerning (
1), a forward–backward–half-forward (FBHF) splitting method was derived by Briceño-Arias and Davis [
15], who exploited the cocoercivity of
C by only utilizing it once in every iteration with great ingenuity. See also [
16,
17,
18] for recent advances in four-operator methods.
Designed as an acceleration method, the inertial scheme is a powerful approach that leverages the characteristic of each new iteration being defined by fully using the previous two iterations. The basic idea was first considered in [
19] as a heavy ball method, which was further developed in [
20]. Later, Güler [
21] and Alvarez et al. [
22] generalized the accelerated scheme in [
20] for addressing the proximal point scheme and maximal monotone problem, respectively. After that, numerous works involving inertial features were discussed and studied in [
23,
24,
25,
26,
27,
28,
29].
Relaxation approaches, a principal part of resolving monotone inclusions, offer greater flexibility to the iterative schemes (see [
4,
30]). In particular, it makes sense to unite inertial and relaxation parameters in a way that enjoys their advantages. Motivated by the inertial proximal algorithm [
31], a relaxed inertial proximal algorithm (RIPA) was reported to find the zero of a maximal monotone operator by Attouch and Cabot [
32], who also exploited RIPA to address non-smooth convex minimization problems and studied convergence rates in [
33]. Further research was made on the more general structure of approaching the solution of the sum of two operators with one being the cocoercive operator [
34]. Meanwhile, the idea of combining inertial effect and relaxation method has also been used in the context of the Douglas–Rachford algorithm [
35], Tseng’s forward–backward–forward algorithm [
36], and alternating minimization algorithm [
37].
This paper aims to develop a relaxed inertial forward–backward–half-forward (RIFBHF) scheme that serves as an extension of the FBHF method [
15] by combining inertial effects and relaxation parameters to solve (
1). It is noteworthy that the FBHF method [
15] was considered in a set constraint (
) of the monotone inclusion (
1). For simplicity, we only study (
1). Specifically, the relaxed inertial algorithm is derived from the perspective of discretisations of the continuous-time dynamical system [
38], and its convergence is analysed under certain assumptions. We also discuss the relationship between the relaxed parameters and inertial effects. Since estimation of the resolvent of
is generally challenging, solving the composite monotone inclusion is not straightforward. By drawing upon the primal–dual idea introduced in [
39], the composite monotone inclusion can be reformulated equivalently as presented in (
1), which can be addressed by our scheme. Similarly, a convex minimization problem is also solved accordingly. At last, numerical tests are designed to validate the effectiveness of the proposed algorithm.
The structure of the paper is outlined as follows.
Section 2 provides an introduction to fundamental definitions and lemmas.
Section 3 presents the development of a relaxed inertial forward–backward–half-forward splitting algorithm through discretisations of a continuous-time dynamical system, accompanied by a comprehensive convergence analysis. In
Section 4, we apply the proposed algorithm to solve the composite monotone inclusion and the convex minimization problem.
Section 5 presents several numerical experiments to demonstrate the effectiveness of the proposed algorithm. Finally, conclusions are given in the last section.
2. Preliminaries
In the following discussion, and are real Hilbert spaces equipped with an inner product and corresponding norms , and represents the set of nonnegative integers. The ⇀ and → signify weak and strong convergence, respectively. denotes the Hilbert direct sum of and . The set of proper lower semicontinuous convex functions from to is denoted by . The followings are denoted:
The set of zeros of A is zer .
The domain of A is dom .
The range of A is ran .
The graph set A is gra .
The definitions and lemmas that follow are among the most commonly encountered, as documented in the monograph referenced as [
4].
Let an operator be a set-valued map; then,
A is characterized as monotone if it satisfies the inequality for all and belonging to the graph of A.
A is called maximal monotone if no other monotone operator exists for which its graph strictly encompasses the graph of A.
A is called -strongly monotone with if for all and , there holds that .
A is said to be -cocoercive with if for all .
The resolvent of
A is defined by
where
is identity mapping, and
. The mapping
is
L-Lipschitz continuous with
if for every pair of points
x and
y in
, the inequality
holds. Specifically,
A is referred to as nonexpansive when
.
Let
; the subdifferential of
f, denoted by
, is defined as
. It is well-known that
is maximal monotone. The proximity operator of
is then defined as:
The well-established relationship
holds. According to the Baillon–Haddad theorem, if
is a convex and differentiable function with a gradient that is Lipschitz continuous with constant
for some
, then
is said to be
-cocoercive. The following equation will be employed later:
for all
,
, and
.
The subsequent two lemmas will play a crucial role in the convergence analysis of the proposed algorithm.
Lemma 1 ([
23], Lemma 2.3).
Assume , , and are the sequences in such that for each ,and there exists a real number α satisfying for all . Thus, the following assertions hold:- (i)
, where ;
- (ii)
There exists such that .
Lemma 2 ((Opial) [
4]).
Let be a nonempty subset of , and let be a sequence in satisfying the following conditions:- (1)
For all , exists;
- (2)
Every weak sequential cluster point of belongs to .
Then converges weakly to a point in .
3. The RIFBHF Algorithm
We establish the RIFBHF algorithm from the perspective of discretisations of continuous-time dynamical systems. First, we pay attention to the second-order dynamical system of the FBHF method studied in [
15]:
where
indicate Lebesgue measurable functions,
and
and
L are as in (
1), and
. Let
Note that the cocoercivity of an operator implies its Lipschitz continuity, which implies, in turn, that
is Lipschitz continuous with the Lipschitz constant
. One can find that
T is Lipschitz continuous by Proposition 1 in [
36]. Therefore, by the Cauchy–Lipschitz theorem for absolutely continuous trajectories, it can be deduced that the trajectory of (
4) exists and is unique.
Next, the trajectories of (
5) are approximated at the time point
using discrete trajectories
. Specifically, we employ the central discretisation
and the backward discretisation
. Let
be an extrapolation of
and
; one gets
which implies
where
and
. Define that
for all
; then, one gets the following RIFBHF iterative for all
:
Remark 1. The subsequent iterative algorithms can be regarded as specific instances of the proposed algorithm:
- (i)
FBHF method [15]: assume and when , - (ii)
Inertial forward–backward–half-forward scheme [40]: assume when , - (iii)
Relaxed forward–backward–half-forward method: assume when ,
Furthermore, the convergence results of the proposed algorithm will be established. The convergence analysis relies heavily on the following properties.
Proposition 1. Consider the problem (1). Suppose is a sequence of positive numbers, and , , and are the sequences generated by (6). Assume that in (6) for all . For all , thenwhere , and Proof. By definition, we get
and
such that
and
. Therefore, in view of the monotonicity of
A and
B, one has
and
Using (7) and (8), we yield
Since
C is cocoercive, one gets for all
:
Thus, in view of (
9), (
10), and the Lipschitz continuity of
B, then
Similar to [
15], let
for
, allowing us to determine the widest interval for
such that the second and third terms on the right-hand side of (
11) are negative. □
Proposition 2. Consider the problem (1) and assume that . Suppose that , , and χ is defined as in Proposition 1. Assume is nondecreasing and satisfies . Let denote the sequence generated by (6). Then - (i)
where .
- (ii)
Thenwhere . Proof. - (i)
According to the Lipschitz continuity of
B,
which implies that
Combining (
13) and (
14), we have
- (ii)
It follows from the definition of
and the Cauchy–Schwartz inequality that
By Propositions 2(i), (
15), and (
16), we have
where
and
. Furthermore, we define that
Now, by (
17) and
, we obtain
If follows from
that
Let
; we obtain
The proof is completed.
□
Furthermore, seeking to ensure the convergence of (
6), let
,
and
by the idea of Boţ et al. [
36]. Proposition 2(ii) implies that
Since
, we have
Then, to ensure
, the following holds:
Next, we establish the principal convergence theorem.
Theorem 1. In problem (1), we assume that . Let a nondecreasing sequence satisfy . Assume that , , and χ is defined as in Proposition 1. In addition, let be nonnegative, andwhere . Then, the sequence obtained by (6) converges weakly to a solution of . Proof. For any
, by (
19), we have
. This implies the existence of
such that for every
,
As a result, the sequence
is nonincreasing, and the bound for
yields
which indicates that
Combining (
20)–(
22) and
, we have
which indicates that
. Since
, this yields
. Let us take account of (
17) and Lemma 1 and observe that
exists.
Meanwhile,
which implies that
. In addition, for every
, we have
Due to
, we deduce that
Assume
is a weak limit point of the sequence
. Since
is bounded, there exists a subsequence
that converges weakly to
. In view of (
23) and (
24),
and
also converge weakly to
. Next, since
, we have
. Therefore, utilizing (
24), the fact that
, and combined with the Lipschitz continuity of
, we conclude that
. Due to the maximal monotonicity of
and the cocoercivity of
C, it follows that
is maximal monotone, and its graph is closed in the weak–strong topology in
(see Proposition 20.37(ii) in [
4]). As a result,
. Following Lemma 2, we conclude that the sequence
weakly converges to an element of
. This completes the proof. □
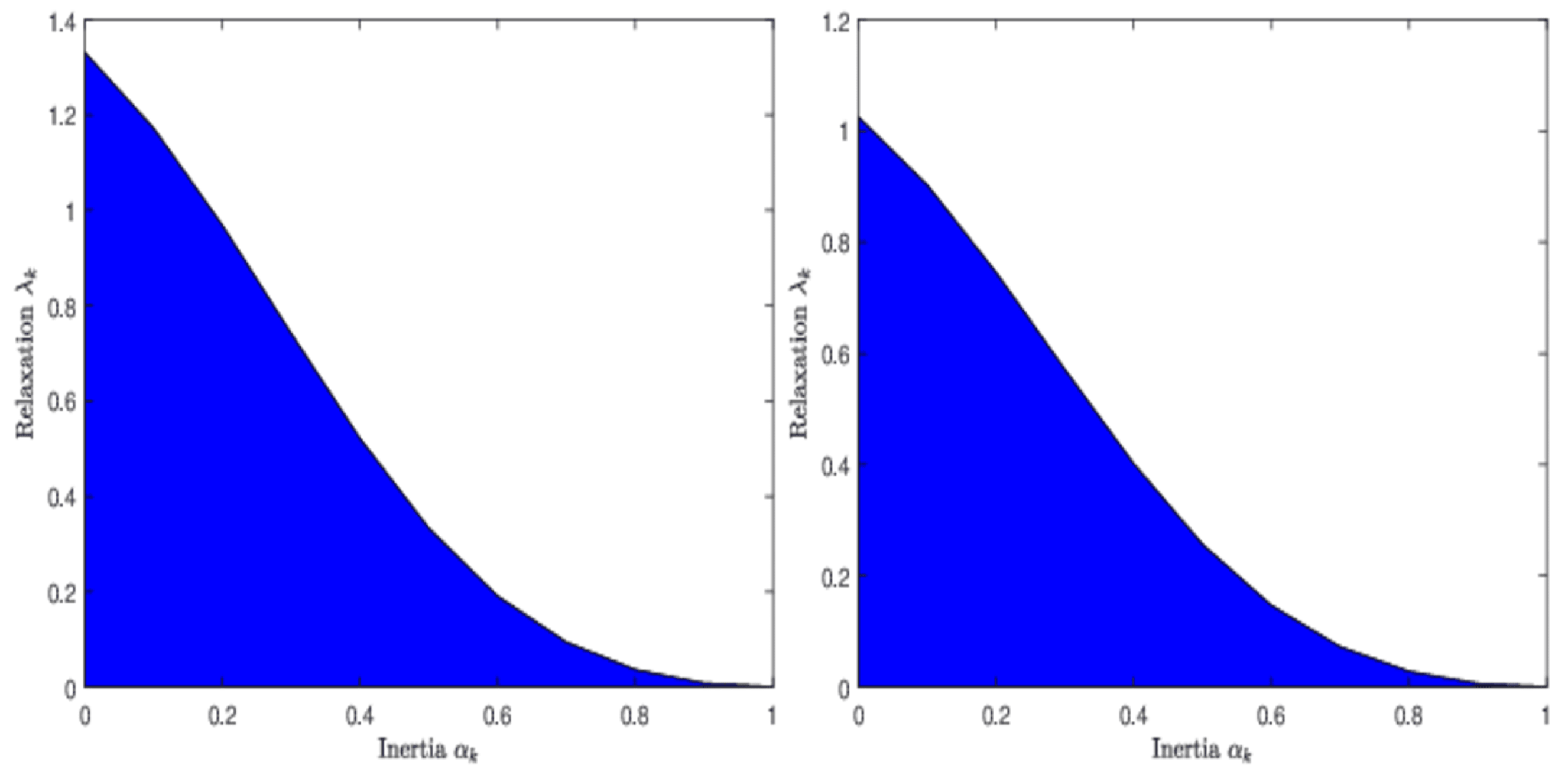
Remark 2 (Inertia versus relaxation).
The inequation (19) establishes a relationship between inertial and relaxation parameters. Figure 1 displays the relationship between and by a graphical representation for some given values of γ and ε, which has a similar graphical representation to Figure 1 in [36]. It is noteworthy that the expression of the upper bound for resembles that in ([36], Remark 2) if . Assume that is constant; it follows from (19) that the upper bound of takes the form of with . Further, note that the relaxation parameter is a decreasing function with respect to inertial parameter α on the interval : for example, when , then . Of course, we can also get when , and is also decreasing on because of limiting values as and as . Remark 3. The parameters for FBHF [15] and RIFBHF are given in Table 1, which shows that the two schemes have the same range of step sizes. Different from FBHF [15], RIFBHF introduces relaxation parameter and inertial parameter . Note that RIFBHF can reduce to FBHF [15] if and . Remark 4. The existence of the over-relaxation for RIFBHF deserves further discussion. If with for , we conclude that has over-relaxation. In addition, observe that the over-relaxation in [36] exists when for . Although the upper bounds of α for the two approaches are different, the over-relaxation for the two methods is possible when α is in a small range. 4. Composite Monotone Inclusion Problem
The aim of this section is to use the proposed algorithm to solve a more generalized inclusion problem, which is outlined as follows:
where
and
represent two maximal monotone operators,
is a
-cocoercive operator with
, and
is a bounded linear operator. In addition, the following assumption is given:
The key to solving (
25) is to know the exact resolvent
. As we know,
can be estimated exactly using only the resolvent of the operator
B, the linear operator
L, and its adjoint
when
for some
. However, this condition usually does not hold in our interesting problems, such as total variation regularization. To address this challenge, we introduce an efficient iterative algorithm to tackle (
25) by combining the primal–dual approach [
39] and (
6). Specifically, drawing inspiration from the fully splitting primal–dual algorithm studied by Briceño-Arias and Combettes [
39], we naturally rewrite (
25) as the following problem, letting
:
where
Notice that
M is maximal monotone and
S is monotone Lipschitz continuous within a constant
, as stated in Proposition 2.7 of [
39]. This implies that
is also maximal monotone since
S is skew-symmetric. A result yields the cocoercivity of
N by the cocoercivity of
C. Therefore, it follows from (
6) and (
27) that the following convergence analysis can deal with (
26), which implies that (
25) is also solved.
Corollary 1. Suppose that is maximal monotone; let be maximal monotone, and assume that is β-cocoercive with . Let be a nonzero bounded linear operator. Given initial data and , the iteration sequences are defined:where , , χ is defined in Proposition 1, and is non-decreasing such that . Assume that the sequence fulfils the conditionwhere . Therefore, the iterative sequence generated by (28) weakly converges to a solution of . Proof. Using Proposition 2.7 in [
39], we observe that
M is maximal monotone and
S is Lipschitz continuous together with
. Considering the
-cocoercivity of
C, it follows that
N is also
-cocoercive. Additionally, for arbitrary
, let
Therefore, using (
27) and Proposition 2.7 (iv) in [
39], we can rewrite (
28) in the following form:
which has the same structure as (
6). Meanwhile, our assumptions guarantee that the conditions of Theorem 1 are held. Hence, according to Theorem 1, the sequence
generated by (
28) weakly converges to an element of
. □
In the following, we apply the results of Corollary 1 to tackle the convex minimization problem.
Corollary 2. Consider the convex optimization problem as follows:where , , is convex differentiable with -Lipschitz continuous gradient for some , and is a bounded linear operator. For (29), given initial data and , iteration sequences are presented for :where , , χ is defined in Proposition 1, and is nondecreasing such that . Assume that the sequence satisfies thatwhere . If is nonempty, then the sequence weakly converges to a minimizer of (29). Proof. According to [
4],
and
are maximal monotone. In view of the Baillon–Haddad theorem,
is indicated to be
-cocoercive. Thus, solving (
29) with our algorithm is equivalent to (
25) under suitable qualification conditions, which gives
Therefore, it follows from the same arguments as the proof of Corollary 1 that we arrive at the conclusions of Corollary 2. □
5. Numerical Experiments
This section reports the feasibility and efficiency of (
6). In particular, we discuss the impact of parameters on (
6). All experiments were conducted using MATLAB on a standard Lenovo machine equipped with an Intel(R) Core(TM) i5-8265U CPU @ 1.60 GHz with 1.80 GHz boost. Our objective is to address the following constrained total variation (TV) minimization problem:
in which
represents the blurring matrix,
z signifies the unknown original image in
, and
D indicates a nonempty closed convex set and represents the prior information regarding the deblurred images. Specifically,
D is selected as a nonnegative constraint set,
indicates the regularization parameter,
denotes the total variation term, and
d stands for the recorded blurred image data.
Notice that (
31) can be equivalently written with the following structure:
where
represents the indicator function, which equals 0 when
and
otherwise. The term
can be expressed as a combination of a convex function
(either using
for the anisotropic total-variation or
for the isotropic total-variation) with a first-order difference matrix
H, denoted as
(refer to Section 4 in [
41]), where
H represents a
matrix written as:
where
denotes the
identity matrix, and ⨂ is the Kronecker product. Consequently, it is evident that (
32) constitutes a special instance of (
29).
In order to assess the quality of the deblurred images, we employ the signal-to-noise ratio (SNR) [
40], which is defined by
where
x is the original image, and
is the deblurred image. The following stopping criterion is utilized to terminate iterative algorithms by the relative error between adjacent iterative steps. We choose test image “Barbara" with a size of
and use four typical image blurring scenarios as in
Table 2. In addition, the range of the values in the original images is
, and the norm of operator
A in (
31) is equal to 1 for the selected experiments. The cocoercive coefficient
is 1, and
for the total variation, as estimated in [
41], where
H is the linear operator. We terminate the iterative algorithms if the relative error is less than
or if the maximum number of iterations reaches 1000.
Prior to the comparisons, we do a test to display how the performance of RIFBHF is affected by different parameters. For simplicity, we set
for all
. In view of (
19), the relationship between inertial parameter
and relaxation parameter
is presented as follows:
where
, and
. As we know, the upper boundedness of
is similar to the one of ([
36], Remark 2) if
. Firstly, we assume
,
, and
, or
and
for RIFBHF. The SNR values and the numbers of iterations used with various
for RIFBHF are recorded in
Table 3 and
Table 4. Observe that the SNR values in image blurring scenarios 1 and 2 are the best when
, while the SNR values in image blurring scenarios 3 and 4 are the best when
. Therefore, we choose
for image blurring scenarios 1 and 2 and
for image blurring scenarios 3 and 4. For the case of
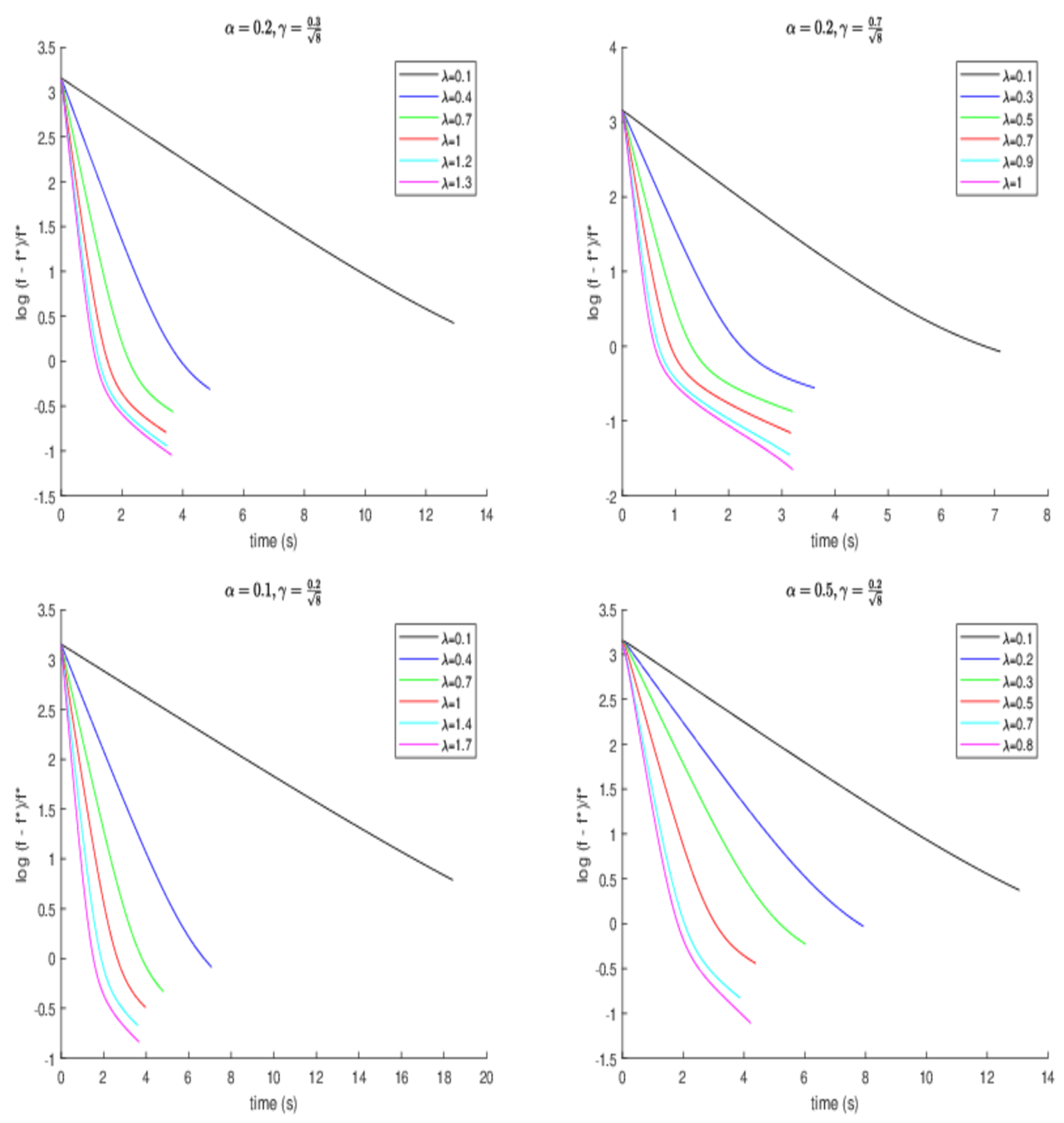
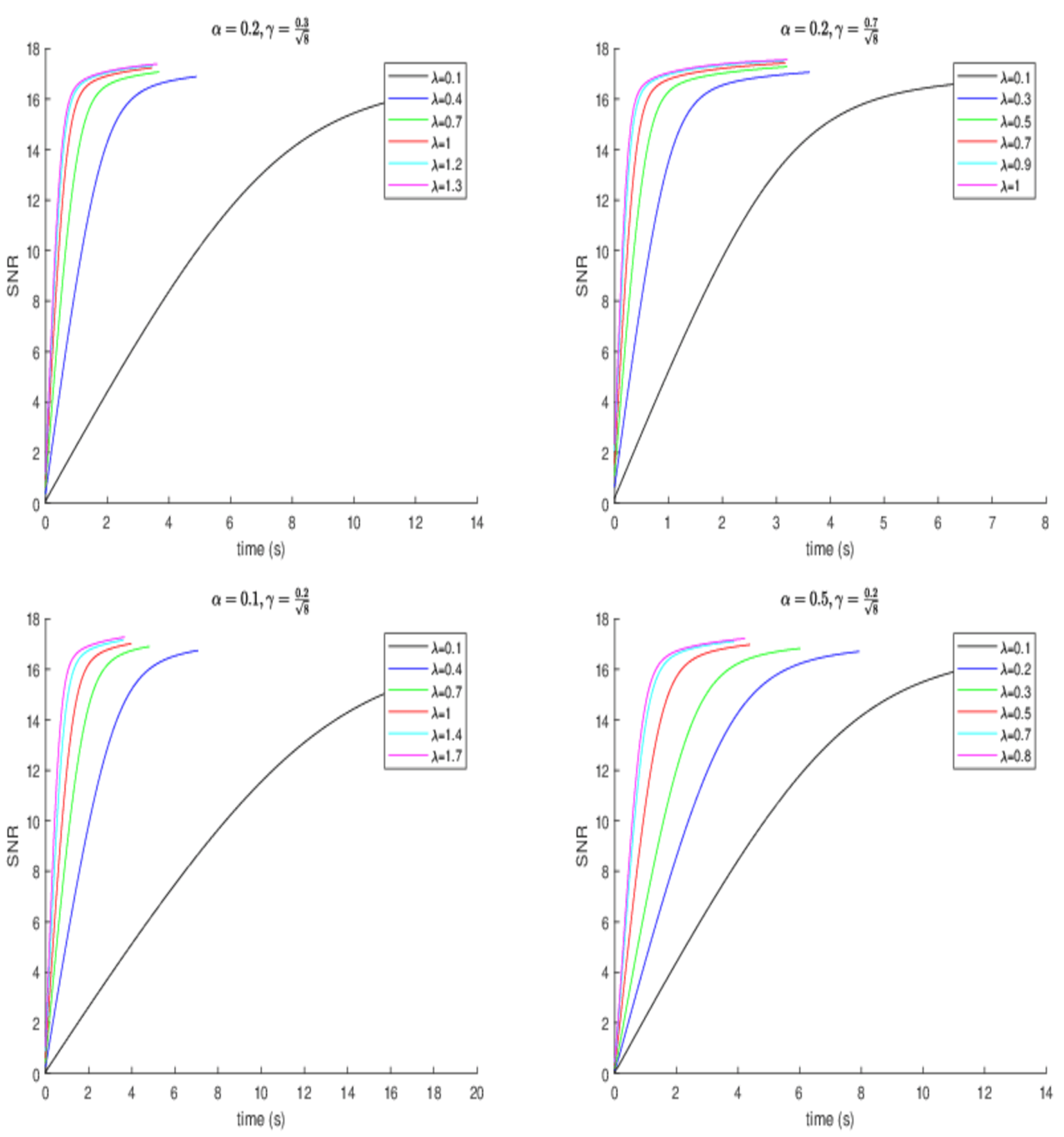
in image blurring scenario 1, we further study the effect of the other parameters. The development of the SNR value and the normalized error of the objective function
along the running time are considered; here,
f represents the present objective value, while
signifies the optimal objective value. To obtain an approximation of the optimal objective value, we set the function value given by running experimental algorithms for 5000 iterations as an estimate of the optimal value. One can observe that a larger
results in better error when
and
, and a larger
also brings better error when
and
in
Figure 2. Of course,
and
also affect the value of
. Meanwhile, a conclusion that a larger
allows for better error can be given. It is worth noting that over-relaxation (
) exists, and it enjoys a better effect.
Figure 3 shows the development of SNR for different parameters; the experiment results are similar to those in
Figure 2.
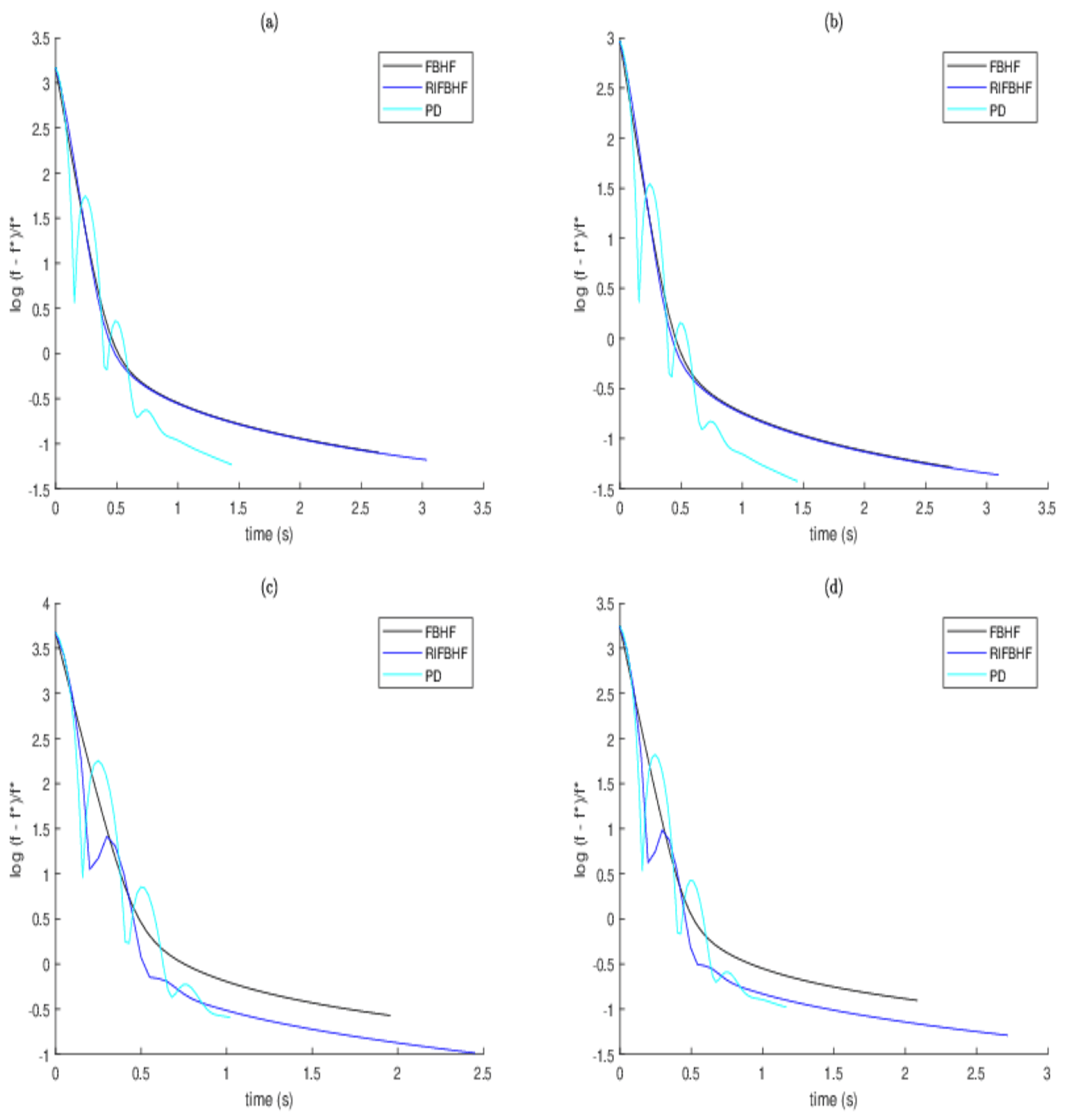
To further validate the rationality and efficiency of (
30), the following algorithms and parameter settings are utilized:
Figure 4 plots the normalized error of the objective function of FBHF, PD, and RIFBHF along the running time. Note that PD appears to be the fastest algorithm. FBHF and RIFBHF are almost the same in image blurring scenarios 1 and 2, while in image blurring scenarios 3 and 4, the effect of RIFBHF is better than that of FBHF, which shows that our algorithm is acceptable. Meanwhile, to succinctly illustrate the deblurring impact of the proposed algorithm, the deblurred results of image blurring scenario 4 are shown in
Figure 5. One can observe visually the better deblurred images generated by RIFBHF.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}