
Road Extraction Method of Remote Sensing Image Based on Deformable Attention Transformer
 , ,
, ,
Abstract
:1. Introduction
- -
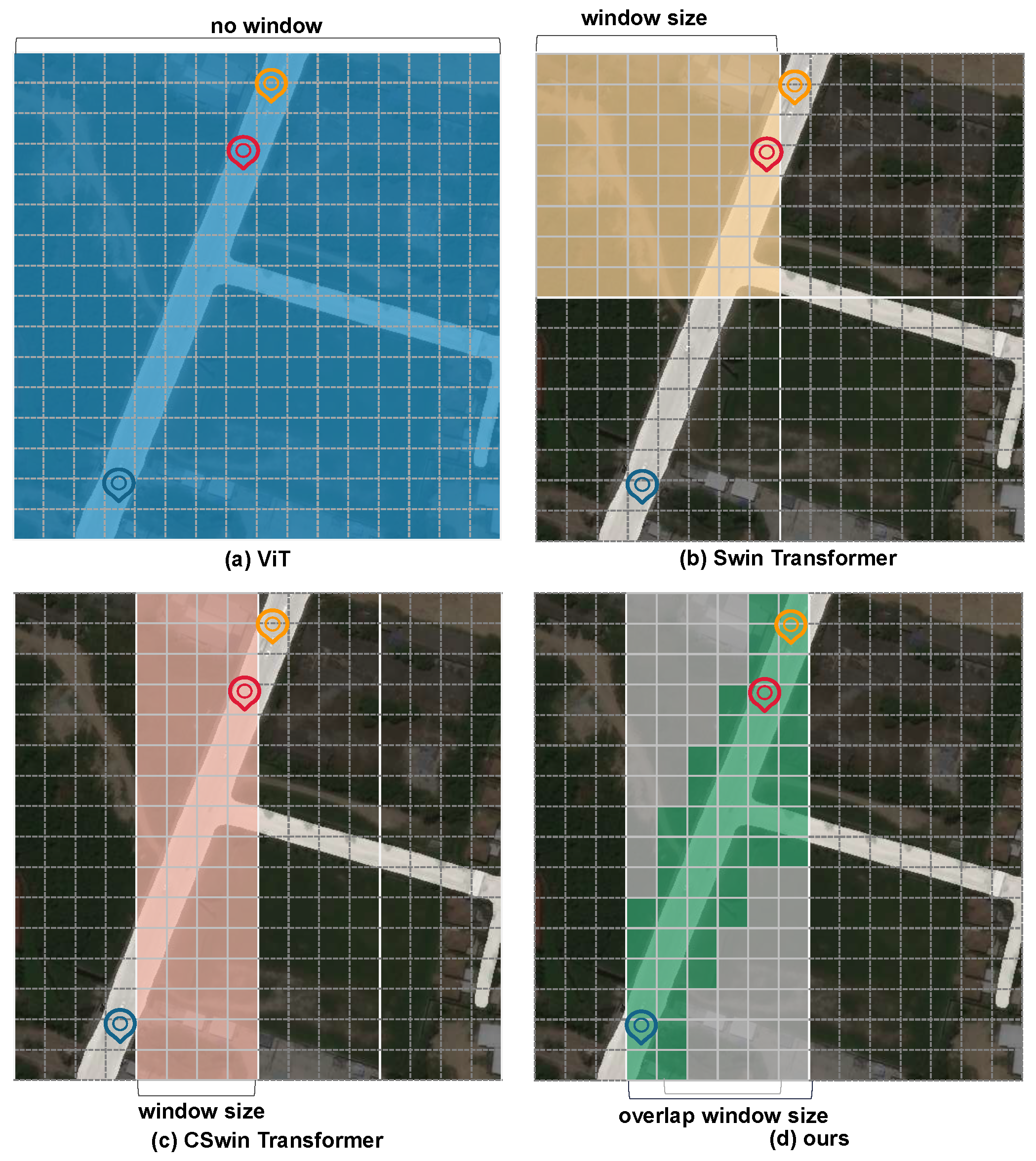
- We propose an overlapped window, which uses key and value patches larger than the query patch during attention computation. It can facilitate information exchange between adjacent windows in both horizontal and vertical directions, completing road details effectively.
- -
- The proposed deformable window introduces adaptive offset to flexibly resample key and value elements in attention computation, which can reduce attention allocation biases caused by excessive noise in the background. The purpose is to overcome the problem of the asymmetrical number of samples of road and background categories as much as possible.
- -
- Our proposed network can achieve significant performance enhancement compared with state-of-the-art deep-learning-based road extraction methods on two popular datasets (i.e., DeepGlobe and Massachusetts datasets).
2. Related Works
2.1. Road Extraction Method
2.2. Vision Transformer
2.3. Deformable CNN and Attention
3. Method
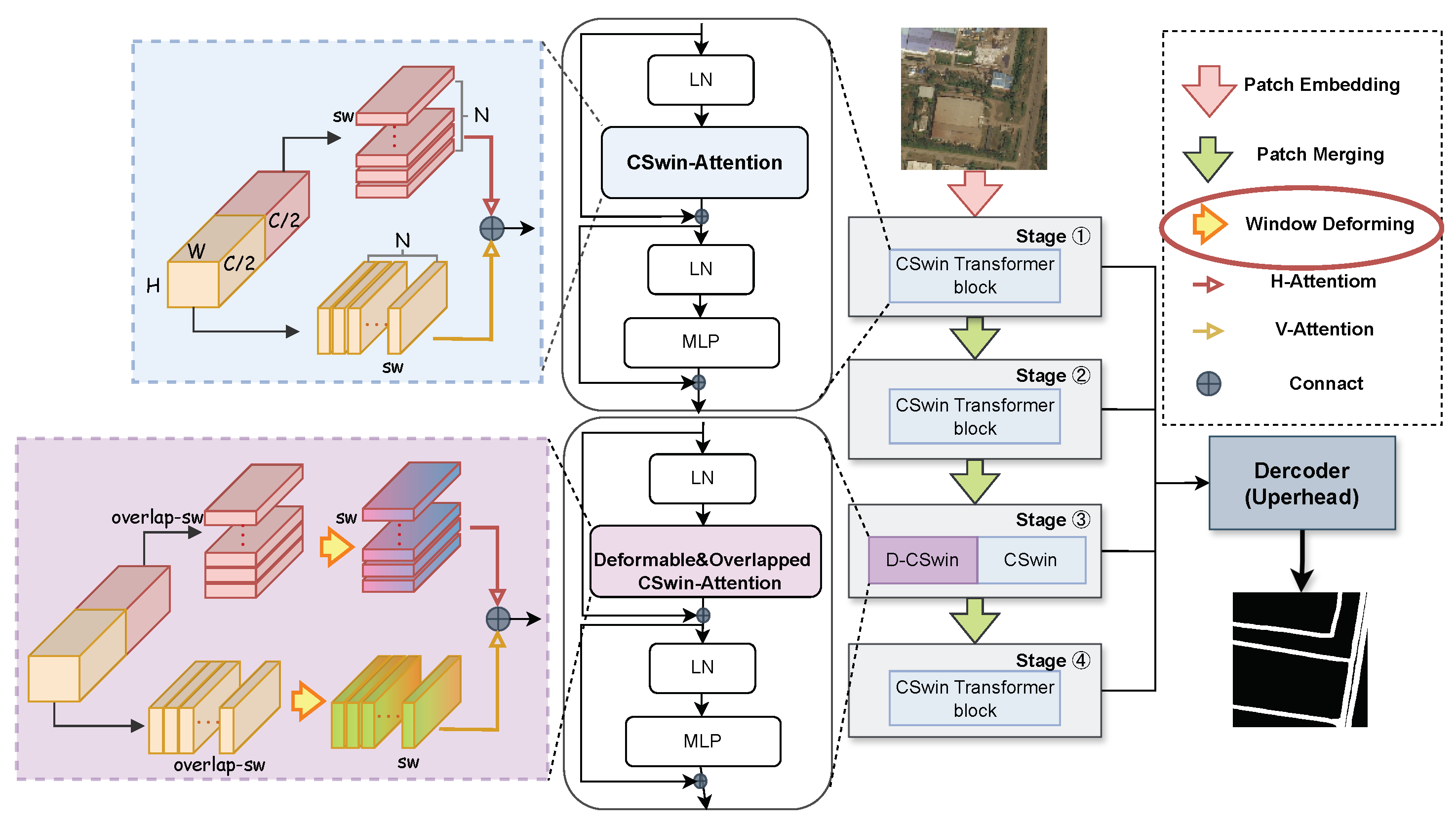
3.1. Encoder
3.1.1. Cswin-Transformer Block
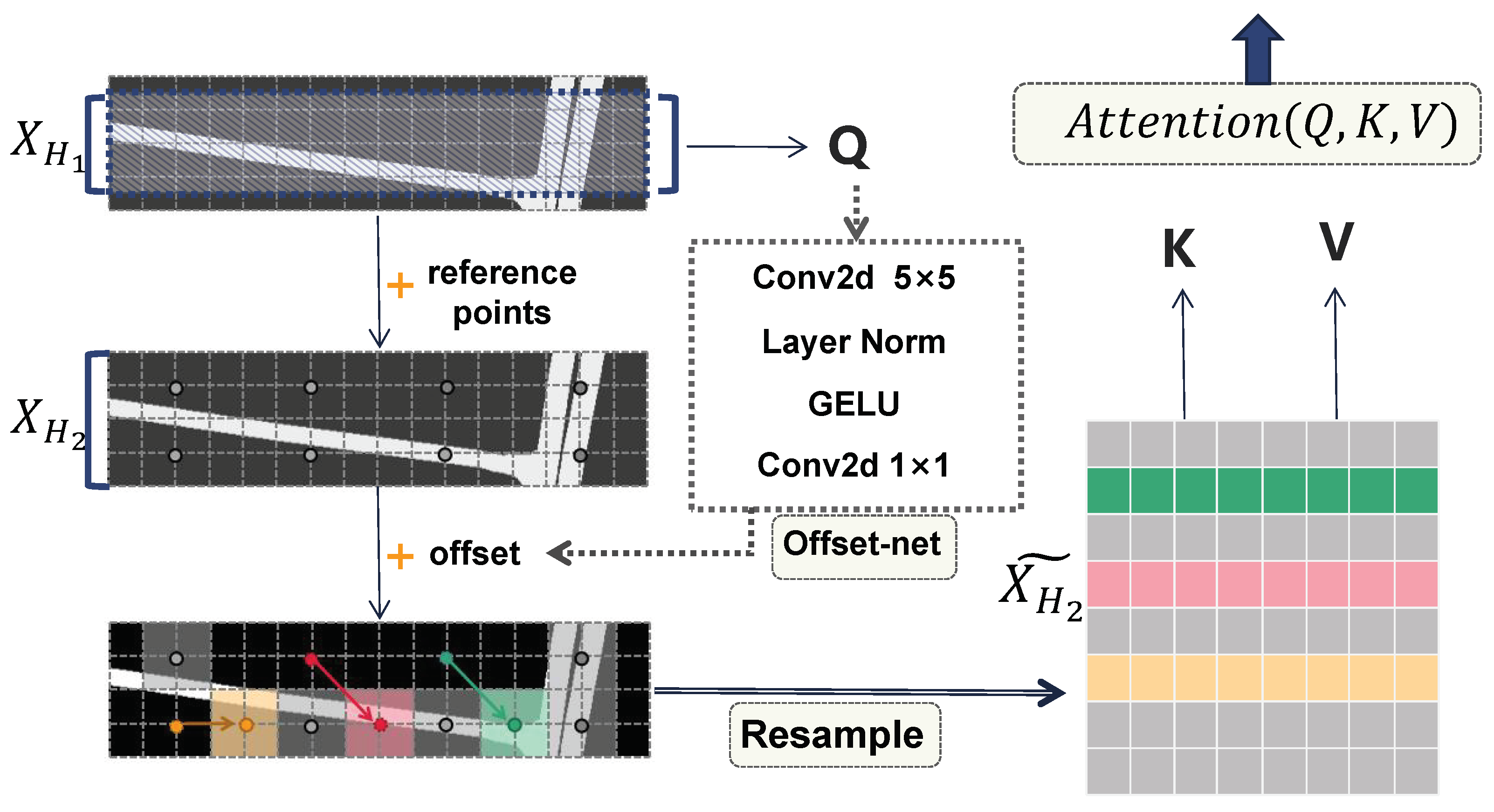
3.1.2. DOC-Transformer Block
- -
- Offset network: The middle part of Figure 3 shows the offset prediction network. Its specific implementation includes a nonlinear activation function GELU and two convolution structures, in which convolution is used to extract global and local features, and the role of the convolution kernel is to adjust the output dimensionality to 2 dimensions as the offset in the two directions of .
- -
- Re-sample: The purpose of re-sample is to reconstruct the feature vector based on the offset coordinates, and since the probability will be out of the integer coordinate points, we employ bilinear interpolation. This involves linear interpolation separately in the horizontal and vertical directions, based on the values of the four-neighboring pixels. This operation involves the distance from each point as a weight in the calculation, which ensures a reasonable correlation of the predicted vector values in terms of spatial location.
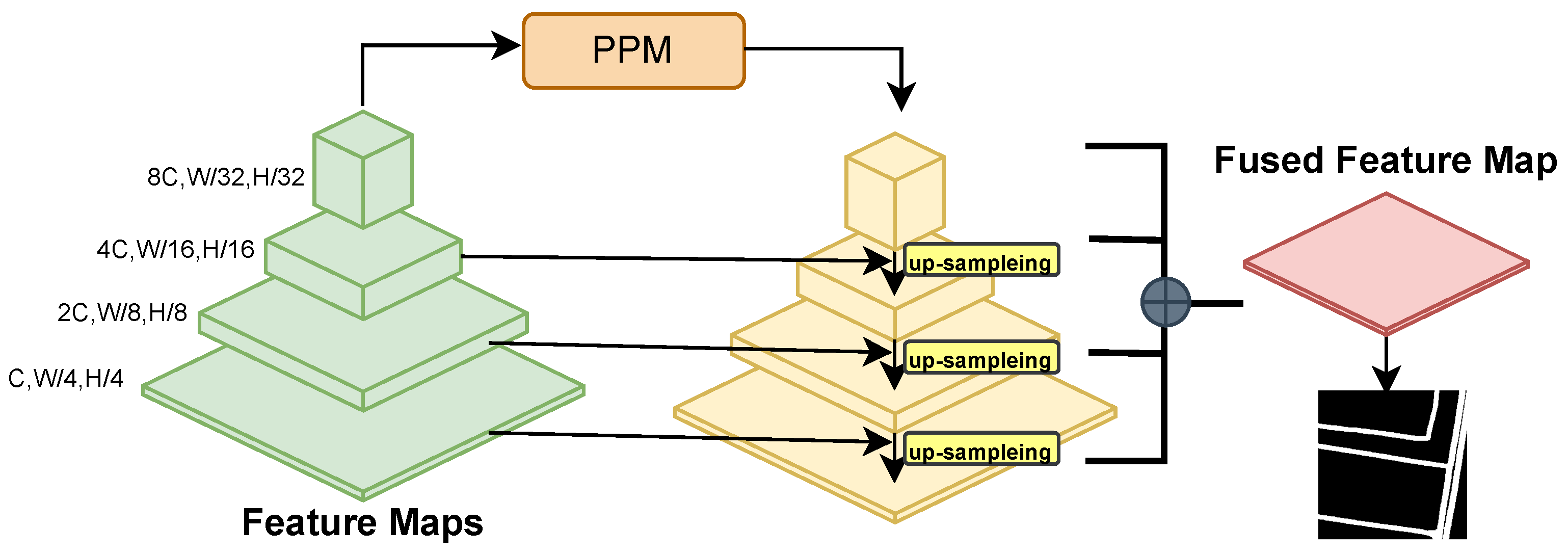
3.2. Decoder
4. Results
4.1. Datasets
4.2. Evaluation Metrics
4.3. Experimental Details
4.4. Result on Deepglobe Dataset
4.5. Result on Massachusetts Road Dataset
4.6. Parameter Experiment
4.7. Ablation Study
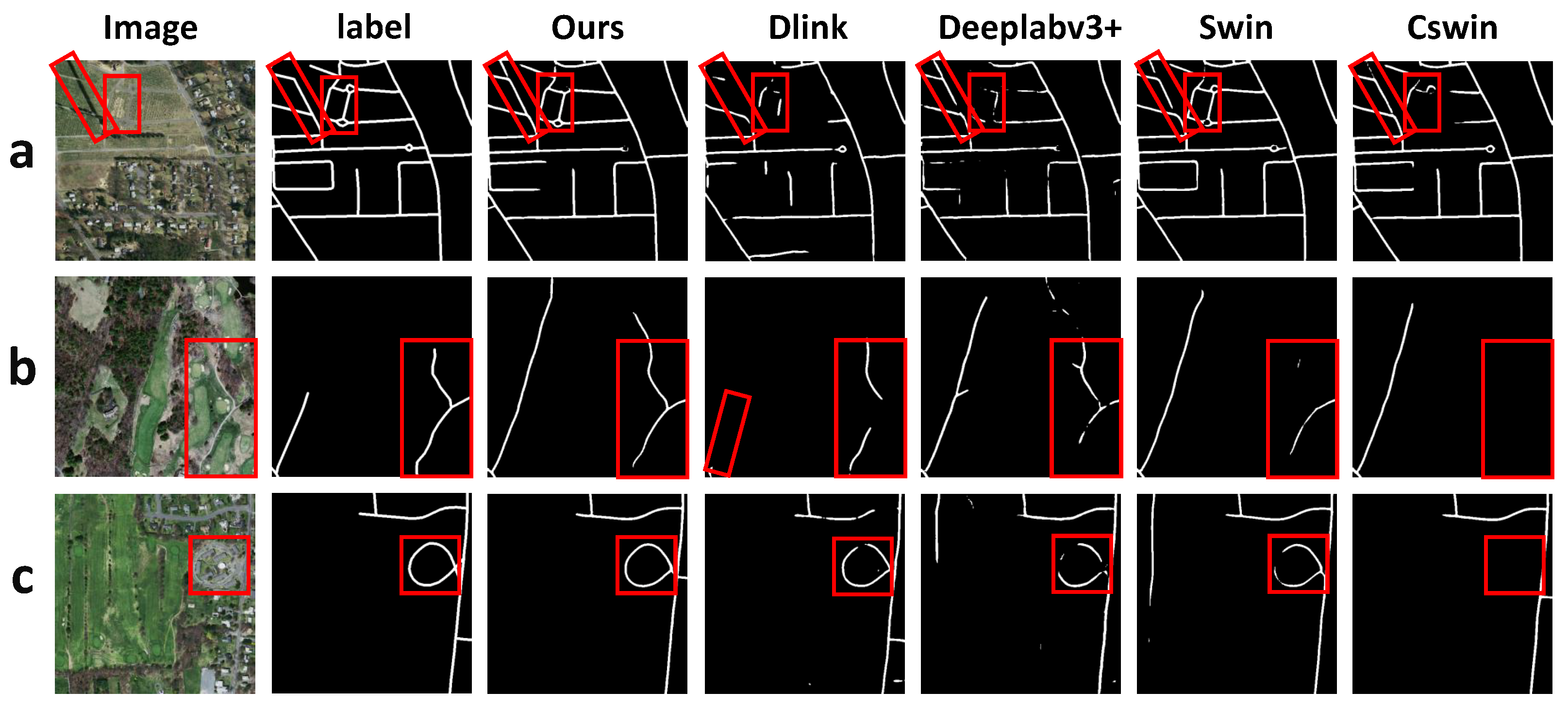
4.8. Heat Map Visualization
5. Discussion
5.1. Conclusions
5.2. Future Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cheng, G.; Zhu, F.; Xiang, S.; Pan, C. Road centerline extraction via semisupervised segmentation and multidirection nonmaximum suppression. IEEE Geosci. Remote Sens. Lett. 2016, 13, 545–549. [Google Scholar] [CrossRef]
- Song, Y.; Ju, Y.; Du, K.; Liu, W.; Song, J. Online road detection under a shadowy traffic image using a learning-based illumination-independent image. Symmetry 2018, 10, 707. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Alamri, A. VNet: An end-to-end fully convolutional neural network for road extraction from high-resolution remote sensing data. IEEE Access 2020, 8, 179424–179436. [Google Scholar] [CrossRef]
- Singh, P.P.; Garg, R.D. Automatic road extraction from high resolution satellite image using adaptive global thresholding and morphological operations. J. Indian Soc. Remote Sens. 2013, 41, 631–640. [Google Scholar] [CrossRef]
- Shi, W.; Miao, Z.; Debayle, J. An integrated method for urban main-road centerline extraction from optical remotely sensed imagery. IEEE Trans. Geosci. Remote Sens. 2013, 52, 3359–3372. [Google Scholar] [CrossRef]
- Shanmugam, L.; Kaliaperumal, V. Junction-aware water flow approach for urban road network extraction. Iet Image Process. 2016, 10, 227–234. [Google Scholar] [CrossRef]
- Mu, H.; Zhang, Y.; Li, H.; Guo, Y.; Zhuang, Y. Road extraction base on Zernike algorithm on SAR image. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1274–1277. [Google Scholar]
- Singh, P.P.; Garg, R.D. A two-stage framework for road extraction from high-resolution satellite images by using prominent features of impervious surfaces. Int. J. Remote Sens. 2014, 35, 8074–8107. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, D.; Liu, X. Road extraction in high resolution images from Google Earth. In Proceedings of the 2009 7th International Conference on Information, Communications and Signal Processing (ICICS), Macau, China, 8–10 December 2009; pp. 1–5. [Google Scholar]
- Ali, I.; Rehman, A.U.; Khan, D.M.; Khan, Z.; Shafiq, M.; Choi, J.G. Model selection using K-means clustering algorithm for the symmetrical segmentation of remote sensing datasets. Symmetry 2022, 14, 1149. [Google Scholar] [CrossRef]
- Miao, Z.; Wang, B.; Shi, W.; Zhang, H. A semi-automatic method for road centerline extraction from VHR images. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1856–1860. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 182–186. [Google Scholar]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, DC, USA, 14–19 June 2020; pp. 6881–6890. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Yang, Z.; Wu, Q.; Zhang, F.; Zhang, X.; Chen, X.; Gao, Y. A New Semantic Segmentation Method for Remote Sensing Images Integrating Coordinate Attention and SPD-Conv. Symmetry 2023, 15, 1037. [Google Scholar] [CrossRef]
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12124–12134. [Google Scholar]
- Li, J.; Liu, Y.; Zhang, Y.; Zhang, Y. Cascaded attention DenseUNet (CADUNet) for road extraction from very-high-resolution images. Isprs Int. J.-Geo-Inf. 2021, 10, 329. [Google Scholar] [CrossRef]
- Cao, Y.; Liu, S.; Peng, Y.; Li, J. DenseUNet: Densely connected UNet for electron microscopy image segmentation. Iet. Image Process. 2020, 14, 2682–2689. [Google Scholar] [CrossRef]
- Mosinska, A.; Marquez-Neila, P.; Koziński, M.; Fua, P. Beyond the pixel-wise loss for topology-aware delineation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3136–3145. [Google Scholar]
- Khan, M.J.; Singh, P.P.; Pradhan, B.; Alamri, A.; Lee, C.W. Extraction of Roads Using the Archimedes Tuning Process with the Quantum Dilated Convolutional Neural Network. Sensors 2023, 23, 8783. [Google Scholar] [CrossRef]
- Khan, M.J.; Singh, P.P. Advanced road extraction using CNN-based U-Net model and satellite imagery. Prime-Adv. Electr. Eng. Electron. Energy 2023, 5, 100244. [Google Scholar] [CrossRef]
- Tao, C.; Qi, J.; Li, Y.; Wang, H.; Li, H. Spatial information inference net: Road extraction using road-specific contextual information. ISPRS J. Photogramm. Remote Sens. 2019, 158, 155–166. [Google Scholar] [CrossRef]
- Zhang, Z.; Miao, C.; Liu, C.; Tian, Q. DCS-TransUperNet: Road segmentation network based on CSwin transformer with dual resolution. Appl. Sci. 2022, 12, 3511. [Google Scholar] [CrossRef]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 22–31. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Yue, X.; Sun, S.; Kuang, Z.; Wei, M.; Torr, P.H.; Zhang, W.; Lin, D. Vision transformer with progressive sampling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 21–27 October 2021; pp. 387–396. [Google Scholar]
- Chen, Z.; Zhu, Y.; Zhao, C.; Hu, G.; Zeng, W.; Wang, J.; Tang, M. Dpt: Deformable patch-based transformer for visual recognition. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 2899–2907. [Google Scholar]
- Xia, Z.; Pan, X.; Song, S.; Li, L.E.; Huang, G. Vision transformer with deformable attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4794–4803. [Google Scholar]
- Patel, K.; Bur, A.M.; Li, F.; Wang, G. Aggregating global features into local vision transformer. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 1141–1147. [Google Scholar]
- Vaswani, A.; Ramachandran, P.; Srinivas, A.; Parmar, N.; Hechtman, B.; Shlens, J.R. Scaling local self-attention for parameter efficient visual backbones. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12894–12904. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. Deepglobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–181. [Google Scholar]
- Friedland, M.L. The University of Toronto: A History; University of Toronto Press: Toronto, ON, Canada, 2013. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Precision | Recall | F1 | IoU | mPrecision | mRecall | mF1 | mIoU |
|---|---|---|---|---|---|---|---|---|
| D-Linknet | 77.53 | 73.30 | 75.36 | 60.46 | 88.21 | 86.21 | 87.18 | 79.24 |
| Deeplabv3+ | 79.84 | 71.17 | 75.26 | 60.33 | 89.32 | 85.21 | 87.14 | 79.20 |
| Swin + Uperhead | 82.42 | 74.30 | 78.15 | 64.14 | 90.68 | 86.82 | 88.64 | 81.21 |
| Cswin + Uperhead | 82.06 | 75.37 | 78.57 | 64.71 | 90.52 | 87.34 | 88.86 | 81.50 |
| Ours + Uperhead | 82.24 | 76.08 | 79.04 | 65.34 | 90.62 | 87.69 | 89.10 | 81.83 |
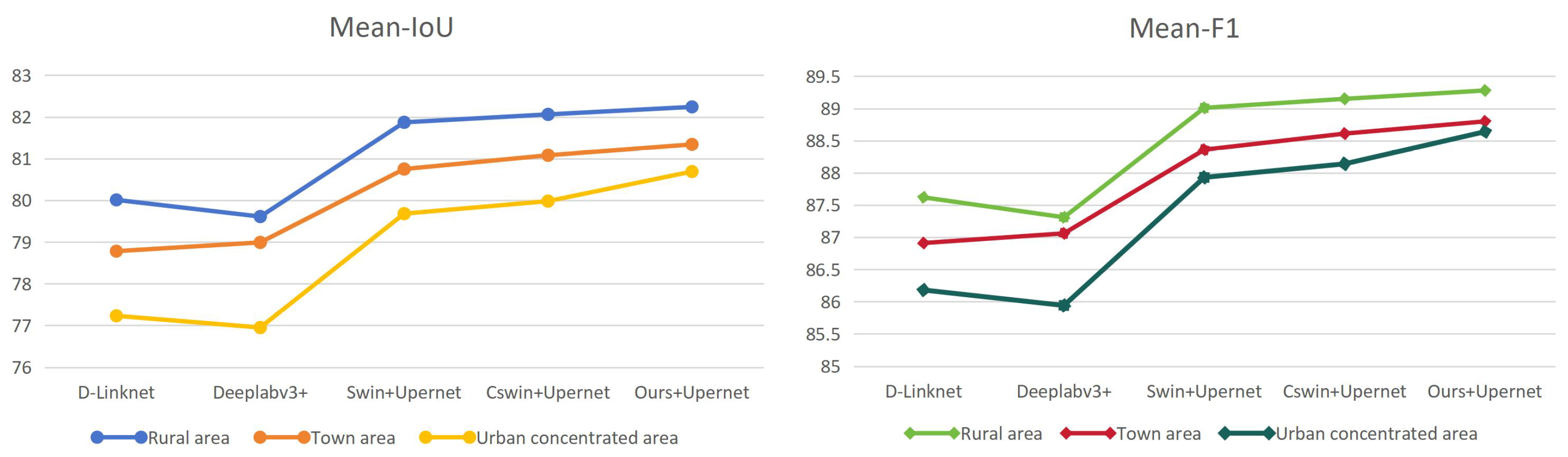
| Method | Rural Area | Town Area | Urban Concentrated Area | |||
|---|---|---|---|---|---|---|
| mIoU | mF1 | mIoU | mF1 | mIoU | mF1 | |
| D-Linknet | 80.01 | 87.62 | 78.78 | 86.91 | 77.23 | 86.18 |
| Deeplabv3+ | 79.61 | 87.31 | 78.99 | 87.06 | 76.95 | 85.94 |
| Swin+Uperhead | 81.87 | 89.01 | 80.75 | 88.36 | 79.68 | 87.93 |
| CSWin+Uperhead | 82.06 | 89.15 | 81.08 | 88.61 | 79.98 | 88.14 |
| Ours+Uperhead | 82.24 | 89.28 | 81.34 | 88.8 | 80.69 | 88.64 |
| Method | Precision | Recall | F1 | IoU | mPrecision | mRecall | mF1 | mIoU |
|---|---|---|---|---|---|---|---|---|
| D-Linknet | 79.86 | 62.52 | 70.14 | 54.01 | 88.93 | 80.83 | 84.35 | 75.59 |
| Deeplabv3+ | 79.53 | 64.96 | 71.51 | 55.65 | 88.82 | 82.03 | 85.06 | 76.45 |
| Swin + Uperhead | 81.3 | 67.21 | 73.59 | 58.21 | 89.77 | 83.19 | 86.14 | 77.82 |
| CSWin + Uperhead | 79.15 | 70.91 | 74.80 | 59.75 | 88.79 | 84.95 | 86.76 | 78.60 |
| Ours + Uperhead | 80.37 | 70.64 | 75.19 | 60.25 | 89.40 | 84.85 | 86.97 | 78.88 |
| Method | Hidden Size | Block Number | Head Number | Window Size | Param |
|---|---|---|---|---|---|
| CSWin-tiny | 64 | 1, 2, 21, 1 | 2, 4, 8, 16 | 1, 2, 7, 7 | 23 M |
| CSWin-small | 64 | 2, 4, 32, 2 | 2, 4, 8, 16 | 1, 2, 7, 7 | 35 M |
| CSWin-base | 96 | 2, 4, 32, 2 | 4, 8, 16, 32 | 1, 2, 7, 7 | 78 M |
| Method | Precision | Recall | F1 | IoU | mPrecision | mRecall | mF1 | mIoU |
|---|---|---|---|---|---|---|---|---|
| CSWin-tiny | 80.61 | 75.07 | 77.74 | 63.59 | 89.79 | 87.16 | 88.42 | 80.91 |
| CSWin-small | 80.97 | 76.43 | 78.63 | 64.79 | 89.99 | 87.84 | 88.88 | 81.54 |
| CSWin-base | 82.06 | 75.37 | 78.57 | 64.71 | 90.52 | 87.34 | 88.86 | 81.50 |
| Ours-tiny | 80.43 | 75.71 | 78.00 | 63.93 | 89.71 | 87.47 | 88.55 | 81.08 |
| Ours-small | 81.37 | 76.82 | 79.03 | 65.33 | 90.20 | 88.04 | 89.09 | 81.82 |
| Ours-base | 82.24 | 76.08 | 79.04 | 65.34 | 90.62 | 87.69 | 89.10 | 81.83 |
| Method | DOC-Number | Precision | Recall | F1 | IoU | Inference |
|---|---|---|---|---|---|---|
| Ours-base | 0 | 82.06 | 75.37 | 78.57 | 64.71 | 0.255 |
| 4 | 81.61 | 76.45 | 78.94 | 65.21 | 0.328 | |
| 8 | 82.24 | 76.08 | 79.04 | 65.34 | 0.373 | |
| 16 | 81.57 | 75.71 | 78.53 | 64.65 | 0.515 | |
| 32 | 81.46 | 70.0 | 75.29 | 60.38 | 0.736 |
| Method | Deformable Window | Overlapped Window | Precision | Recall | F1 | IoU |
|---|---|---|---|---|---|---|
| CSWin-base | × | × | 82.06 | 75.37 | 78.57 | 64.71 |
| Ours-base | ✓ | × | 81.58 | 76.25 | 78.82 | 65.05 |
| Ours-base | × | ✓ | 80.80 | 76.88 | 78.79 | 65.00 |
| Ours-base | ✓ | ✓ | 82.24 | 76.08 | 79.04 | 65.34 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Zhang, J.; Meng, X.; Zhou, W.; Zhang, Z.; Peng, C. Road Extraction Method of Remote Sensing Image Based on Deformable Attention Transformer. Symmetry 2024, 16, 468. https://doi.org/10.3390/sym16040468
Zhao L, Zhang J, Meng X, Zhou W, Zhang Z, Peng C. Road Extraction Method of Remote Sensing Image Based on Deformable Attention Transformer. Symmetry. 2024; 16(4):468. https://doi.org/10.3390/sym16040468
Chicago/Turabian StyleZhao, Ling, Jianing Zhang, Xiujun Meng, Wenming Zhou, Zhenshi Zhang, and Chengli Peng. 2024. "Road Extraction Method of Remote Sensing Image Based on Deformable Attention Transformer" Symmetry 16, no. 4: 468. https://doi.org/10.3390/sym16040468