1. Introduction
Regression is a widely employed statistical methodology across various fields with different variants, including parametric, semi-, and non-parametric approaches. Linear models remain attractive due to their interpretability and the availability of tools to handle diverse data types and validate theoretical assumptions. In practice, the model predicts a response variable as a linear function of one or more predictors, for example, modelling the influence of smoking and biking habits (predictors) on the likelihood of heart disease (response). It finds application across diverse domains, including the sciences, social sciences, and the arts.
While utilizing numerous explanatory variables provides a more accurate view of the response variable, it introduces the challenge of redundant information stemming from correlations among predictors. The issue of collinearity among predictors poses a significant problem in linear regression, impacting least squares estimates, standard errors, computational accuracy, fitted values, and predictions [
1,
2,
3,
4]. Various diagnostic methods, such as the condition number, correlation analysis, eigenvalues, condition index, and the variance inflation factor, are commonly employed to identify collinearity.
Additionally, several proposed methods exist in addressing the collinearity problem, ranging from component-based methods like partial least squares regression (PLS) and principal component regression (PCR) to techniques involving penalizing solutions using the L2 norm [
5,
6]. The widely recognized ridge regression [
7] is one such method. Different modifications to ridge regression have led to several others. These include the Liu estimator, the modified ridge-type estimator, the Kibria–Lukman estimator, the two-parameter estimator, the Stein estimator, and others [
8,
9,
10,
11,
12,
13]. Generally, a unanimous agreement on the optimal method is lacking, as each approach proves effective under distinct circumstances.
Recently, Wang et al. [
14] developed a novel method to address multicollinearity in linear models called average least squares method (LSM)-centered penalized regression (ALPR). This method utilizes the weighted average of ordinary least squares estimators as the central point for shrinkage. Wang et al.’s [
14] investigation demonstrated that ALPR outperformed ridge estimation (RE) in accuracy when the signs of the regression coefficients were consistent. Thus, ALPR is a promising method to effectively mitigate multicollinearity, especially when the signs of the regression coefficients are consistent.
Recent studies have enhanced model predictions by integrating principal components regression with some L2 norms such as ridge regression and the Stein estimator [
15,
16]. The PCR estimation technique stands out as a potent solution for addressing dimensionality challenges in estimation problems [
17]. Known for its transparency and ease of implementation, PCR involves two pivotal steps, where the initial step applies principal component analysis (PCA) to the predictor matrix. The subsequent step entails regressing the response variable on the first principal components, which capture the most variability.
In a groundbreaking contribution, Baye and Parker [
15] introduced the r-k class estimator, ingeniously combining PCR with ridge regression, resulting in a remarkable performance boost compared to using each estimator individually. This pioneering work has ignited further research, inspiring researchers to explore new avenues [
18,
19,
20,
21,
22]. This paper extends the principles of PCR to the realm of average least squares method (LSM)-centered penalized regression (ALPR), giving rise to a novel method named principal component average least squares method (LSM)-centered penalized regression (PC_ALPR). The approach shares the initial step of principal component regression while diverging in the second step, where average least squares method (LSM)-centered penalized regression is used instead of the classical least squares method (LSM) to regress the response variable on the principal components.
Thus, in this study, we propose a new method to account for multicollinearity in the linear regression model by integrating principal component regression with average least squares method-centered penalized regression. This article is structured as follows:
Section 2 provides a detailed review of existing methods, while
Section 3 introduces a new estimator. In
Section 4, we rigorously assess the new estimator’s performance through a Monte Carlo simulation study. Additionally,
Section 5 showcases the practical relevance of the proposed estimator, featuring a compelling numerical example. Finally,
Section 5 summarizes this research’s key findings, emphasizing the contributions of the new estimator and discussing its implications for future advancements in estimation techniques.
2. A Brief Overview of Existing Methods
Regression analysis models the connection between a response variable and one or more predictors. In this section, we will delve into the linear model, offering brief overviews of estimation methods, both with and without consideration of multicollinearity.
2.1. Least Squares Method
The linear model is a fundamental concept in statistical modelling, offering a versatile framework for understanding the relationship between a response variable and one or more predictors through a linear equation. This equation, often represented as
captures the linear association between the response variable and predictors. In this formulation,
is the
vector of the response variable,
is the
matrix of predictors, and β is
vector of the coefficients that quantify the impact of each predictor on the response. The linear model assumes a linear and additive relationship between the predictors and the response variable. ε is an
vector of the disturbance terms, such that
The least squares method (LSM) stands as a cornerstone in statistical modelling, offering a powerful approach to estimating the parameters of the linear model defined in Equation (1). The primary goal of the LSM is to find the coefficients that minimize the sum of the squared differences between the observed and predicted values of the dependent variable. The vector of estimates,
is given by
The variance–covariance matrix of the LSM is defined as follows:
where the mean squared error is
. The scalar mean squared error (SMSE) of (3) is as follows:
where
is the eigenvalues of matrix
.
The issue of collinearity arises when there are linear or nearly linear relationships among predictors. When exact linear relationships exist, meaning one predictor is an exact linear combination of others, the matrix becomes singular, preventing a unique estimate. When near-linear dependence exists among predictors, is nearly singular, leading to an ill-conditioned estimation equation for regression parameters. Consequently, the parameter estimates, become unstable. The variances in the regression coefficients become inflated, resulting in larger confidence intervals. In summary, the presence of collinearity, whether exact or near-linear, jeopardizes the stability of parameter estimates, leading to increased uncertainty in understanding the relationships between predictors and the response variable.
Various methods are available for detecting collinearity in linear regression models, providing insights into the interdependence among predictors. Key techniques include the following:
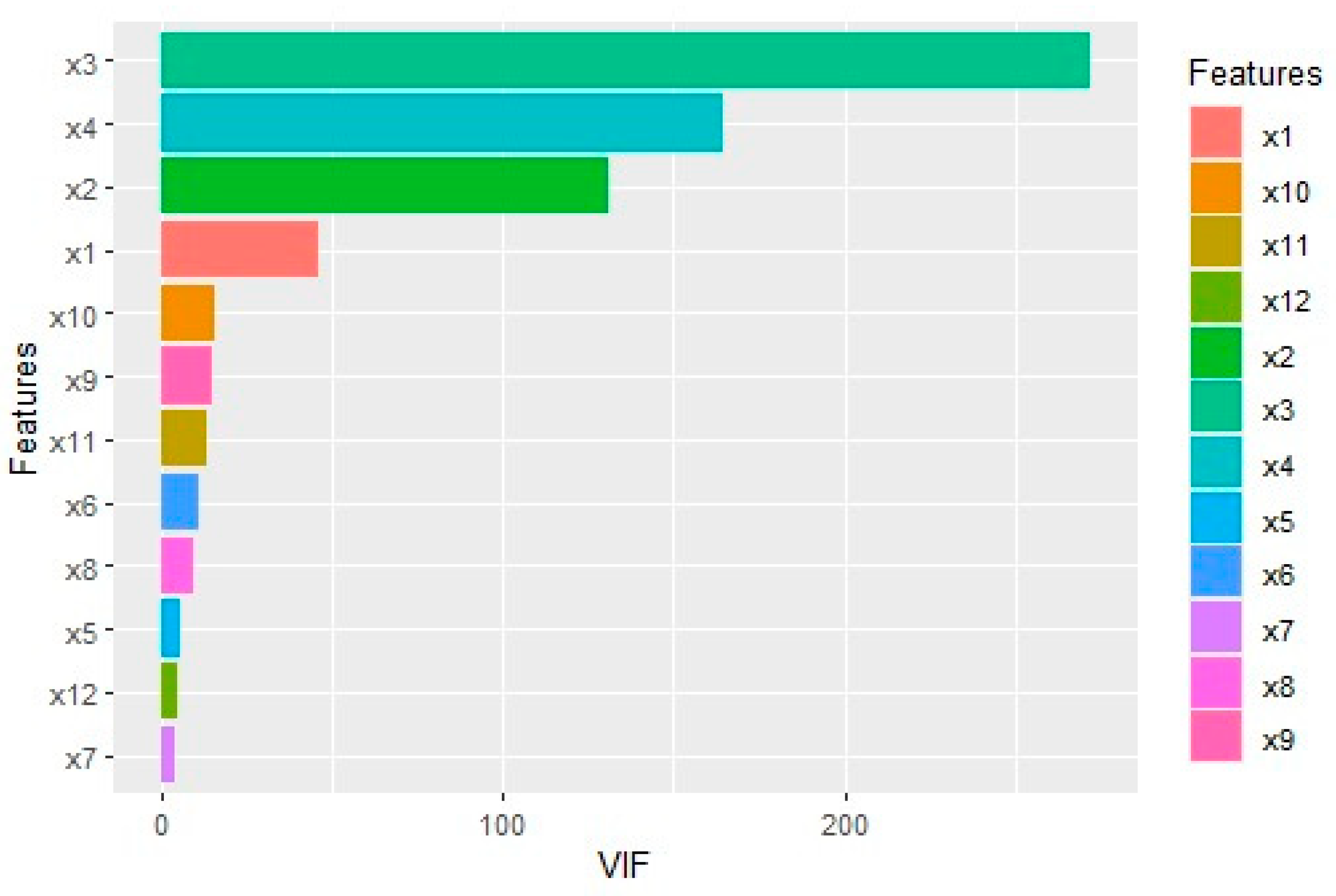
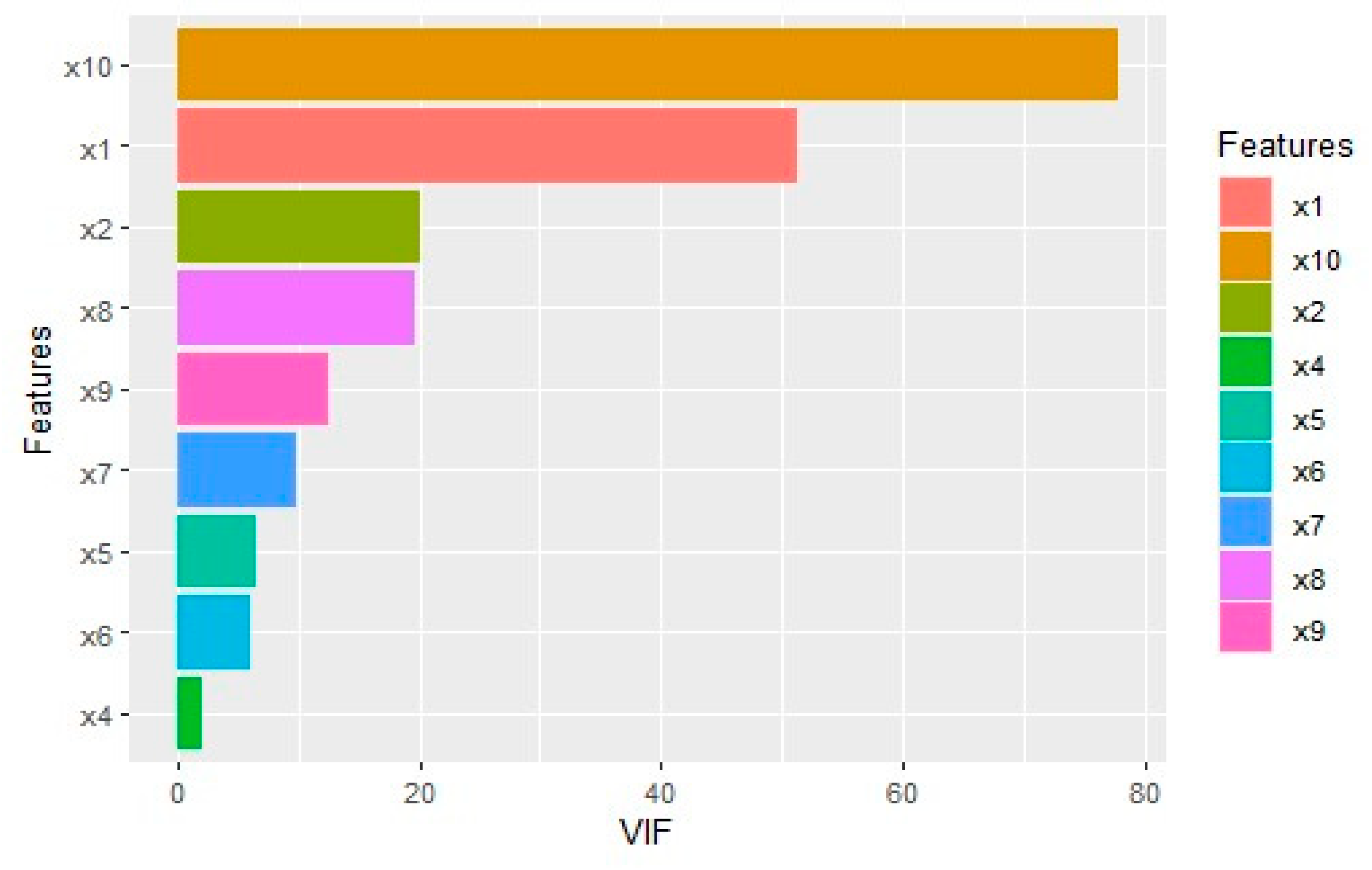
Variance inflation factor (VIF): The VIF measures how much the variance of an estimated regression coefficient becomes inflated due to collinearity. A widely accepted rule of thumb suggests collinearity concerns when VIF values exceed 10.
Condition number: The condition number assesses the sensitivity of the regression coefficients to small changes in the data. A condition number of 15 raises concerns about multicollinearity, while a number exceeding 30 indicates severe multicollinearity [
3].
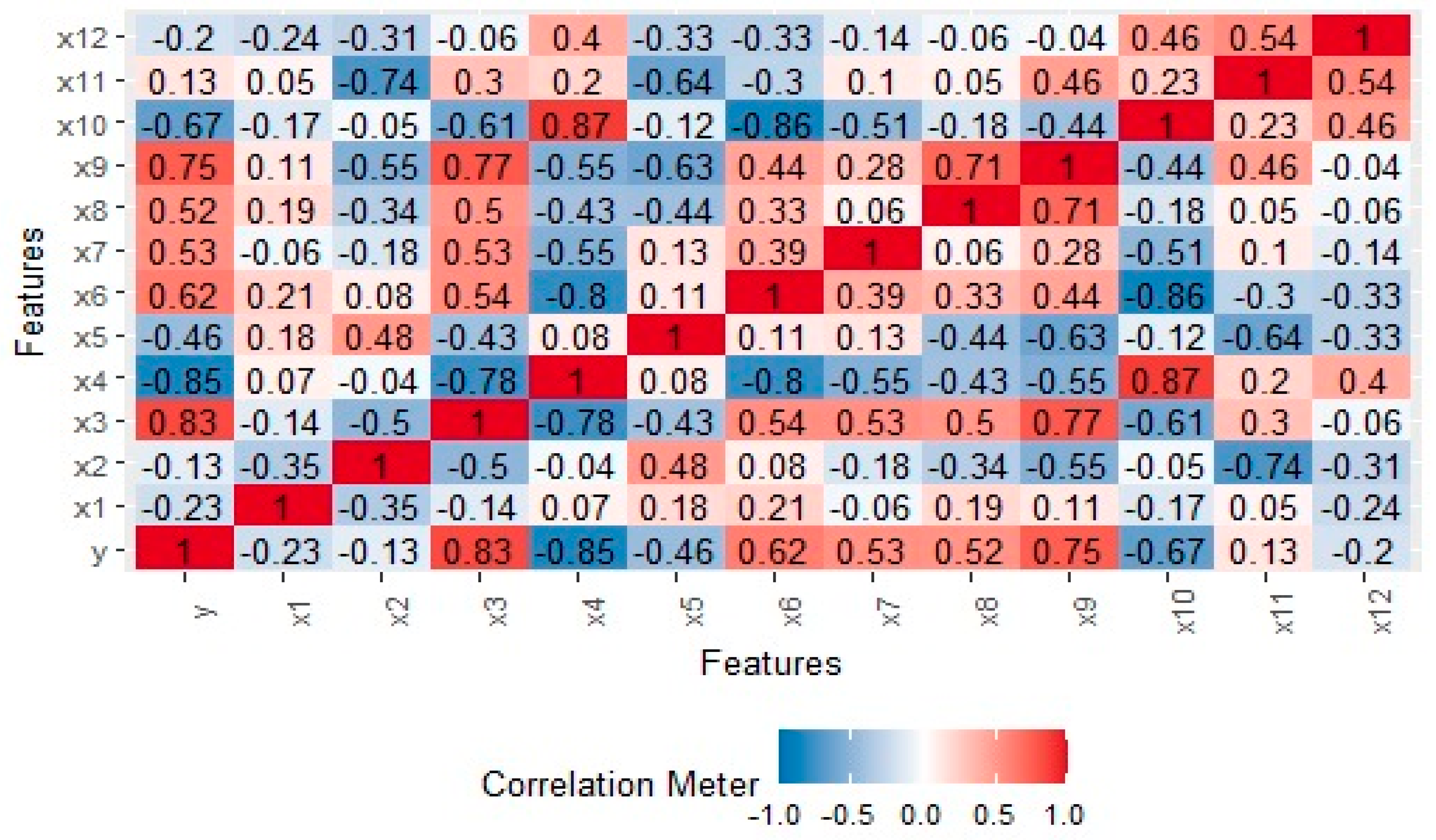
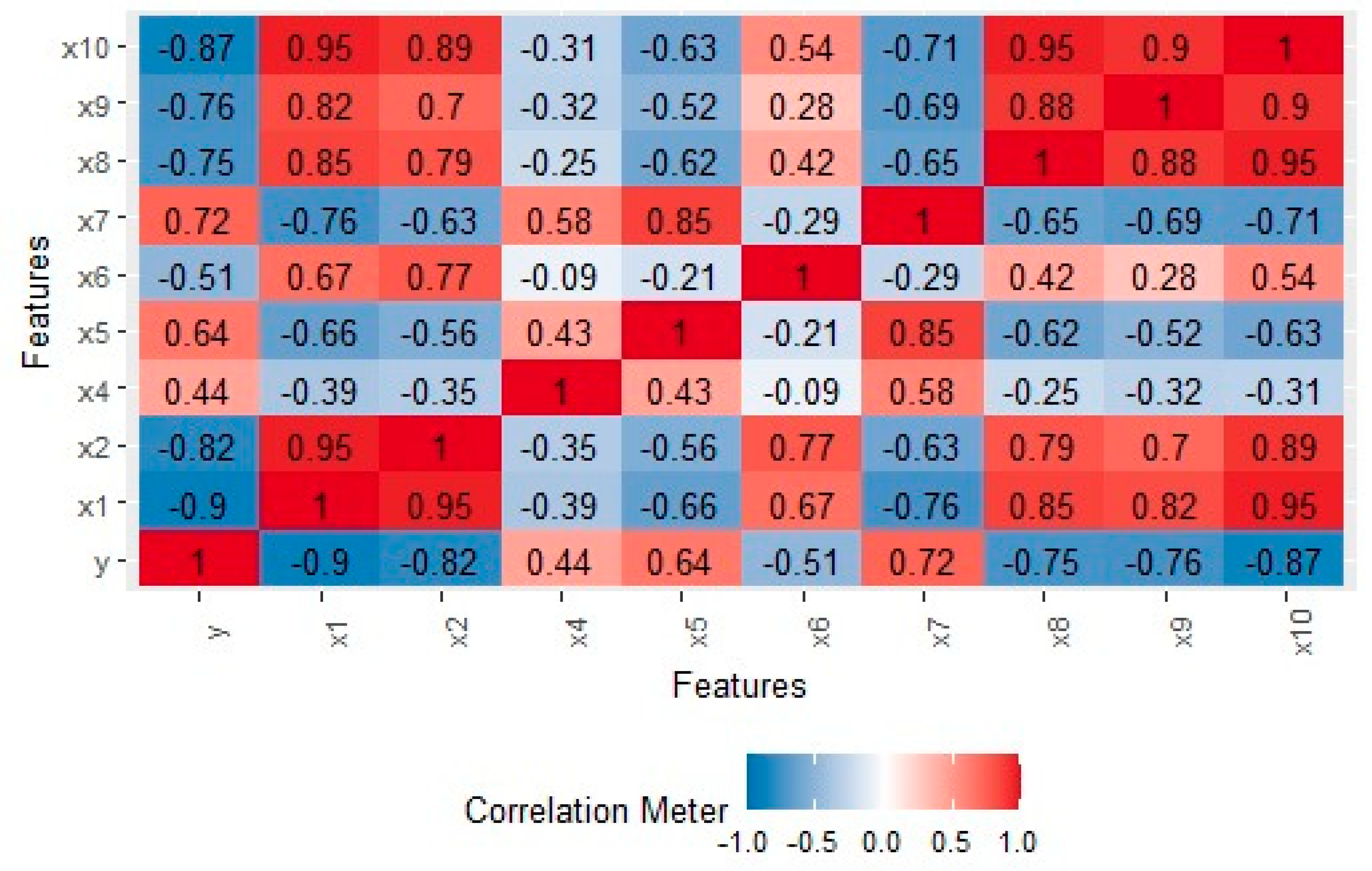
Correlation matrix: Analyzing the correlation matrix of predictors helps to identify high correlations between variables. A high correlation coefficient, particularly close to 1, suggests the potential presence of collinearity.
Eigenvalues: Investigating the eigenvalues of the predictor matrix provides insights into multicollinearity. Small eigenvalues, especially near zero, indicate a higher risk of multicollinearity.
In addition to the methods for detecting collinearity in linear regression, several approaches have been proposed to address this issue effectively. These methods span a spectrum of techniques, from component-based strategies like partial least squares regression (PLS) and principal component regression (PCR) to regularization techniques involving penalizing solutions using the L2 norm. The upcoming section will offer a concise overview of a few methods developed to address collinearity. Specifically, the focus will be on techniques such as principal component regression (PCR) and the regularization methods utilizing the L2 norm.
2.2. Principal Component Regression
Principal component analysis (PCA) is a widely used dimension reduction technique to transform the original variables into a new set of uncorrelated variables, called principal components, while retaining as much of the original variability as possible [
17]. The first principal component captures the maximum amount of variance in the data. Subsequent principal components capture the remaining variance while being orthogonal to each other. By retaining only the most significant principal components, PCA reduces the dimensionality of the dataset while preserving most of the original information. It is applicable in various fields, including image and signal processing, finance, and genetics. The model structure for principal component regression is obtained by transforming model (1) as follows:
where
is a
orthogonal matrix with
and
is a
diagonal matrix of eigenvalues of
. The score matrix T
has dimensions n × m, where n represents the number of observations and m represents the number of principal components. The PCR estimator of
is obtained by excluding one or more of the principal components,
, applying least squares method (LSM) regression to the resulting model, and then transforming the coefficients back to the original parameter space. Principal components whose eigenvalues are less than one should be excluded. These components contribute less to the overall variability of the data and can be considered less influential for prediction. However, according to Cliff [
23], all components with eigenvalues greater than one should be kept for statistical inference, as they explain more variability in the data. Thus, the PCR estimator of
is defined as follows:
2.3. Regularization Techniques
L2 norms regularization, ridge regression, is used in linear regression to address multicollinearity by penalizing the regression coefficients [
7]. It involves adding a regularization term to the objective function of the least squares method (LSM). The objective function of ridge regression (RR) combines the LSM loss function with the L2 regularization term as follows:
where y is the vector of the response variable, X is the matrix of predictors,
denotes the L2 norm,
is the vector of regression coefficients, and k is the regularization parameter. The regularization term penalizes regression coefficients, effectively shrinking them towards zero. Thus, there is a reduction in the variance of the parameter estimates and improved model stability, especially when there is collinearity among the predictors. The objective function in Equation (7) is expanded as follows:
Differentiate Equation (8) with respect to
and equate to zero. Consequently,
According to Hoerl et al. [
24], the regularization parameter, k, is defined as follows:
The variance–covariance matrix of the ridge regression is defined as follows:
The bias of the estimator is obtained as follows:
Hence, the matrix mean squared error (MMSE) is given as
The scalar mean squared error (SMSE) of (13) is as follows:
where
is the eigenvalues of matrix
, and
.
2.4. Average Least Squares Method (LSM)-Centered Penalized Regression [ALPR]
Wang et al. [
14] introduced an enhanced estimator that refines the approach of ridge regression by penalizing the regression coefficients towards a predetermined constant,
, diverging from the traditional ridge regression method that shrinks its coefficients towards zero. This modification offers a more flexible penalization framework by allowing the shrinkage target to be adjusted away from zero. The objective function of ALPR combines the LSM loss function with the L2 regularization term, which is penalized to a specific constant,
, as follows:
The objective function in Equation (15) is expanded as follows:
Differentiate Equation (16) with respect to
and equate to zero. Consequently,
Define the distance from to
to
as g =
. Consequently, the objective function can be expressed as the minimization of
, akin to the formulation of ridge regression. Let
. Thus, the scalar mean squared error (SMSE) is as follows:
Consequently, as
increases, the
also increases. Equation (18), being independent of F, roughly indicates that a smaller g, i.e., the closer
is to c, resulting in a smaller
, implying better estimation. While least squares method (LSM) estimators may suffer from instability when there is significant multicollinearity among explanatory variables, their average values demonstrate reduced susceptibility to multicollinearity effects. As an alternative to the conventional shrinkage center of zero used in ridge regression (RR), employing the average value of
as a shrinkage center offers a more appropriate solution. This innovative approach, termed Average OLS Penalized Regression (AOPR), relies on a p-dimensional vector, d, where all elements are set to 1, to define
as the average of the
. Consequently, the shrinkage center for ALPR,
, is established as
. To ensure a stable estimation of
that maximizes explanatory power for the observed,
can be estimated through a specific procedure designed to enhance its stability and explanatory capacity. This meticulous procedure ensures that AOPR provides robust and effective regression results, particularly in scenarios with high multicollinearity among predictor variables. Thus,
is estimated by minimizing
Let
replace the constant
in Equation (17); then, we have
The covariance matrix of
is as follows:
Following Wang et al. [
14], let
and
, where
is the ith row vector of h. Consequently, the SMSE of
is as follows:
where
Set
Wang et al. [
14] proposed that setting k =
serves as the optimal choice for the shrinkage parameter in ALPR. For further insights, we advise consulting the works of Wang et al. [
14,
25]. These references provide an in-depth exploration and analysis of the optimal shrinkage parameter selection in ALPR.
2.5. Principal Component Average LSM-Centered Penalized Regression
In this section, we introduce a novel hybrid estimation approach that integrates principal component regression (PCR) with average LSM-centered penalized regression (ALPR) to create the principal component average LSM-centered penalized regression method. We aim to capitalize on the strengths of PCR and ALPR to enhance the modelling process and boost predictive accuracy by combining these two techniques. The methodology comprises the following steps:
Standardization of predictor variables to ensure comparability, with a mean of zero and unit variance.
Perform principal component analysis (PCA) on the predictor variables.
Selection of principal components corresponding to eigenvalues exceeding 1, as they explain more variance than an individual predictor variable [
23,
26].
Regression of the response variable on the chosen principal components to derive fitted values.
Replace the original response variable with the fitted values obtained from the PCR model.
Utilization of average LSM-centered penalized regression to regress the transformed response variable (fitted values from step iv) along with the original predictor variables.
Evaluation of the combined approach’s performance using appropriate metrics such as the scalar mean squared error (SMSE) and predicted mean squared error.
Mathematically, Baye and Parker [
15] integrated the principal component with the ridge estimator to form principal component ridge regression (PCRR). PCRR according to Chang and Yang [
19] is defined as follows:
The scalar mean squared error (SMSE) is as follows:
where r
Thus, the proposed estimator is defined as follows:
The scalar mean squared error (SMSE) is as follows:
3. Simulation
This section will examine a simulation study that evaluates the performance of the proposed estimator in comparison to existing estimators, across various levels of multicollinearity. The simulation study is conducted using RStudio, a popular integrated development environment for R programming. We follow a specific data generation mechanism to account for the number of correlated variables. We generate the number of
observations with
explanatory variables using the following scheme:
where
represents independent standard normal pseudo-random numbers;
is the number of correlated variables. The variables are standardized, and thus,
shows the correlation. Furthermore, we consider moderate and strong collinearity levels using
. We generate the model observations following Equation (1) with
,
. The response variable is a linear function of the predictors generated in (26) with coefficients
The model assumes a zero intercept, and the values of
are chosen such that
. We repeat the whole data generation process 1000 times and evaluate the estimator’s performance using the mean squared error (MSE) and prediction mean squared error (PMSE), respectively, given by
where
is any of the existing estimators or the proposed estimator. Further,
.
The simulation results are available in
Table 1,
Table 2,
Table 3 and
Table 4. The results from the simulation study offer a comprehensive view of how different regression estimators perform under varying conditions of multicollinearity and noise levels. The comparison includes the traditional least squares method (LSM), ridge regression (RR), principal components ridge regression (PCRR), average least squares method-centered penalized regression (ALPR), and the novel principal component average least squares method-centered penalized regression (PCALPR). Under moderate to strong multicollinearity scenarios (ρ = 0.8 to ρ = 0.99), the PCALPR estimator consistently outperformed the other estimators in terms of mean squared error (MSE). This indicates a superior capability in accurately estimating the regression coefficients, which directly contributes to better model prediction accuracy. However, as the multicollinearity level is severe, i.e., when ρ = 0.999, other estimators compete favorably.
A key observation is a significant deterioration in the performance of the LSM as the level of multicollinearity increases, illustrating the well-known vulnerability of ordinary least squares to collinear predictors. This highlights the necessity for alternative estimation techniques in practical applications where predictors are often correlated to some degree.
Both RR and PCRR showed improvements over LSM, affirming the value of penalization and dimensionality reduction techniques in mitigating multicollinearity effects. However, the standout performance of ALPR and PCALPR underscores the effectiveness of centering the penalization around a more robust estimate than ordinary least squares, particularly under high multicollinearity.
PCALPR’s edge over ALPR in almost all scenarios suggests that the integration of principal component analysis not only helps in addressing multicollinearity by reducing the dimensionality of the predictor space but also enhances the penalization strategy by focusing on the most informative components of the predictors.
When examining the impact of different noise levels (σ
2 = 25 vs. σ
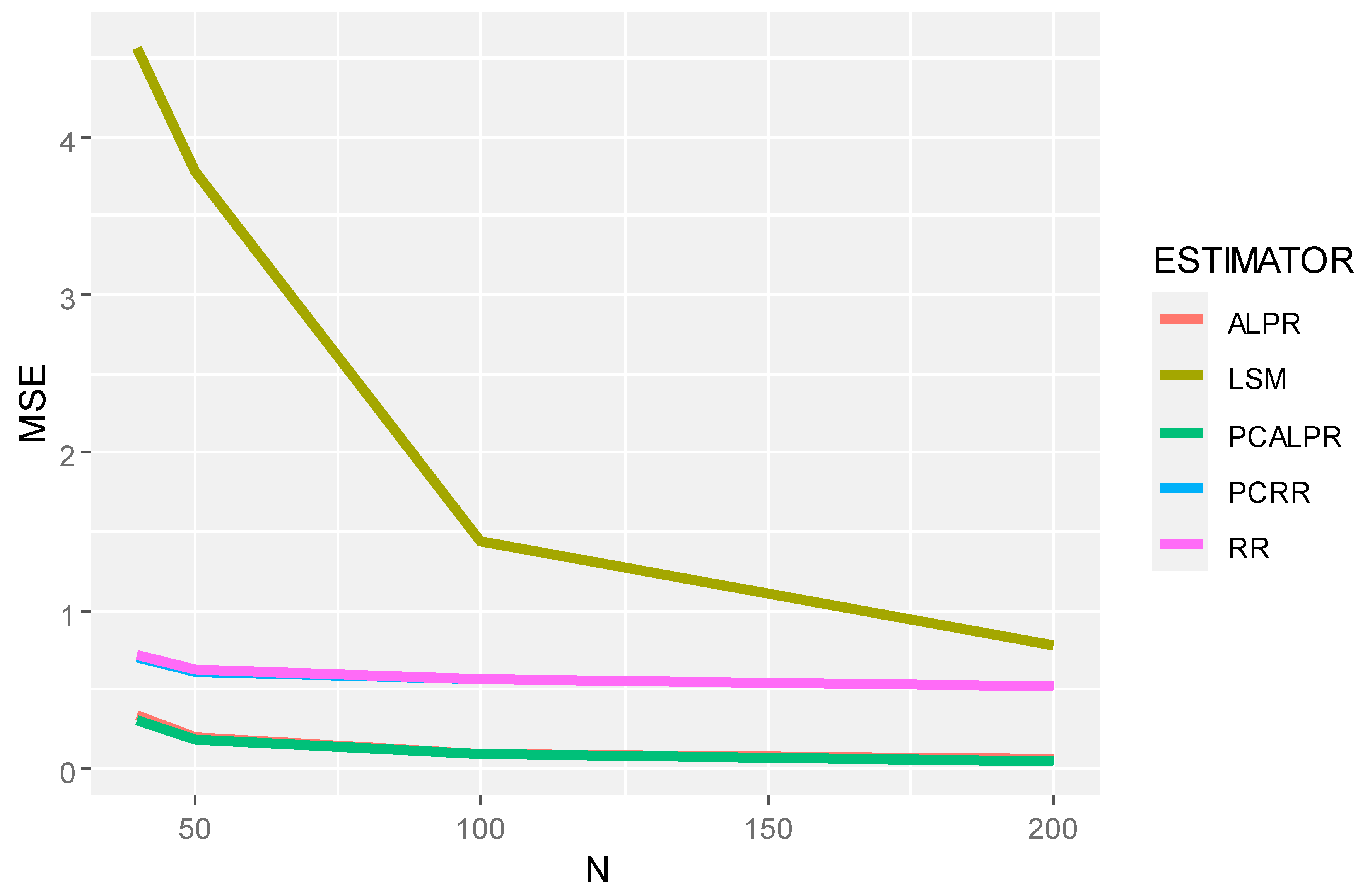
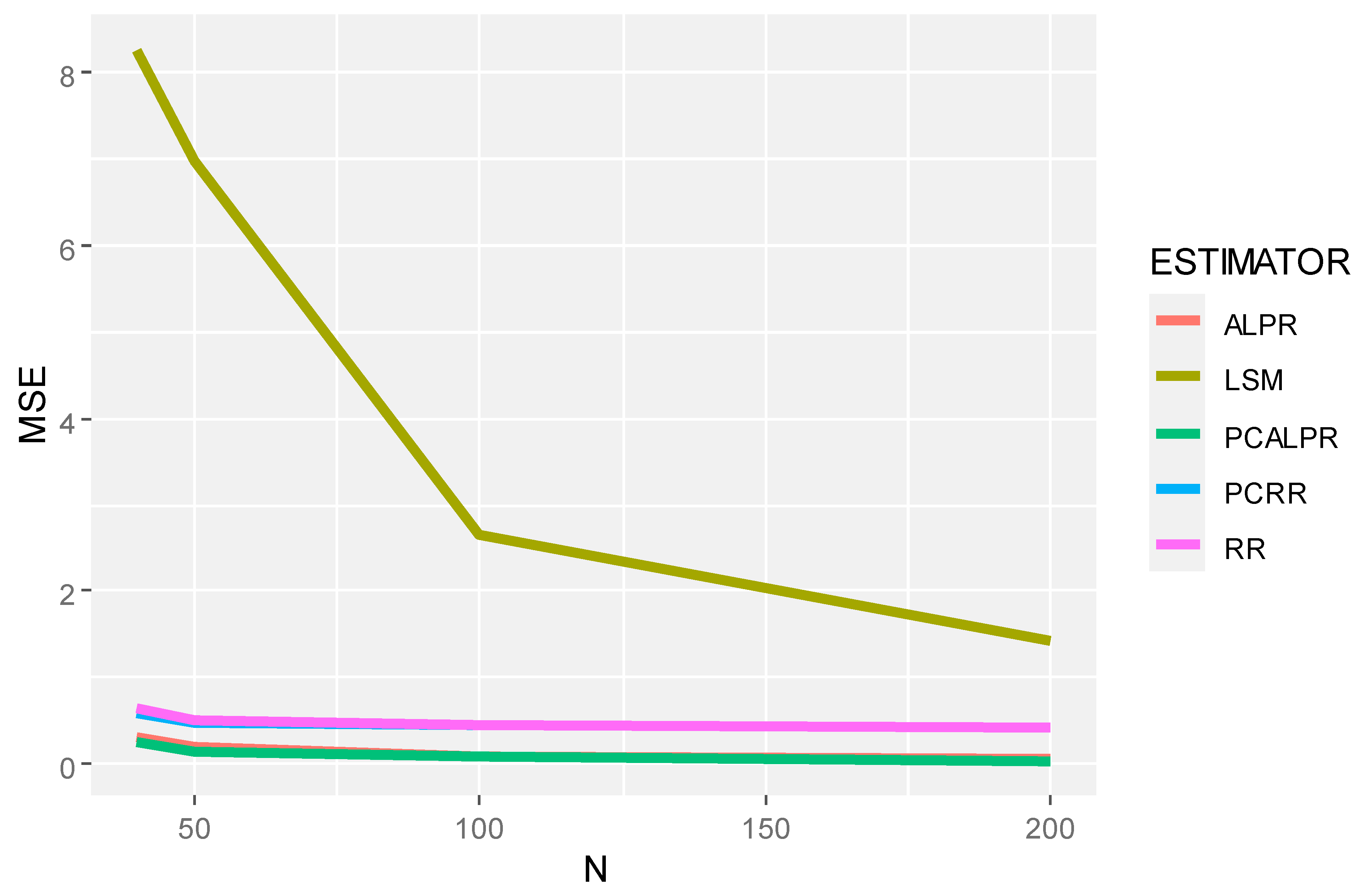
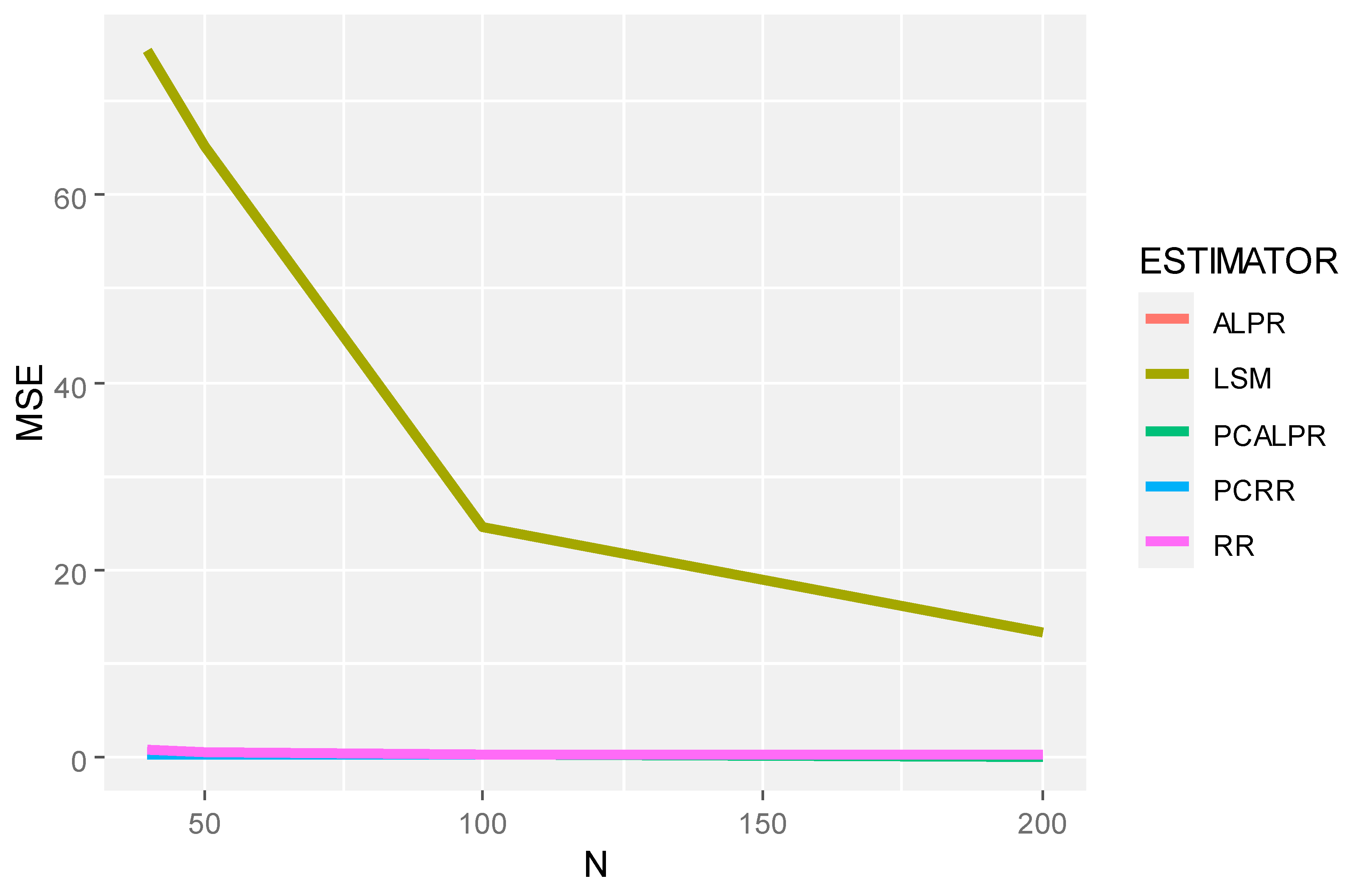
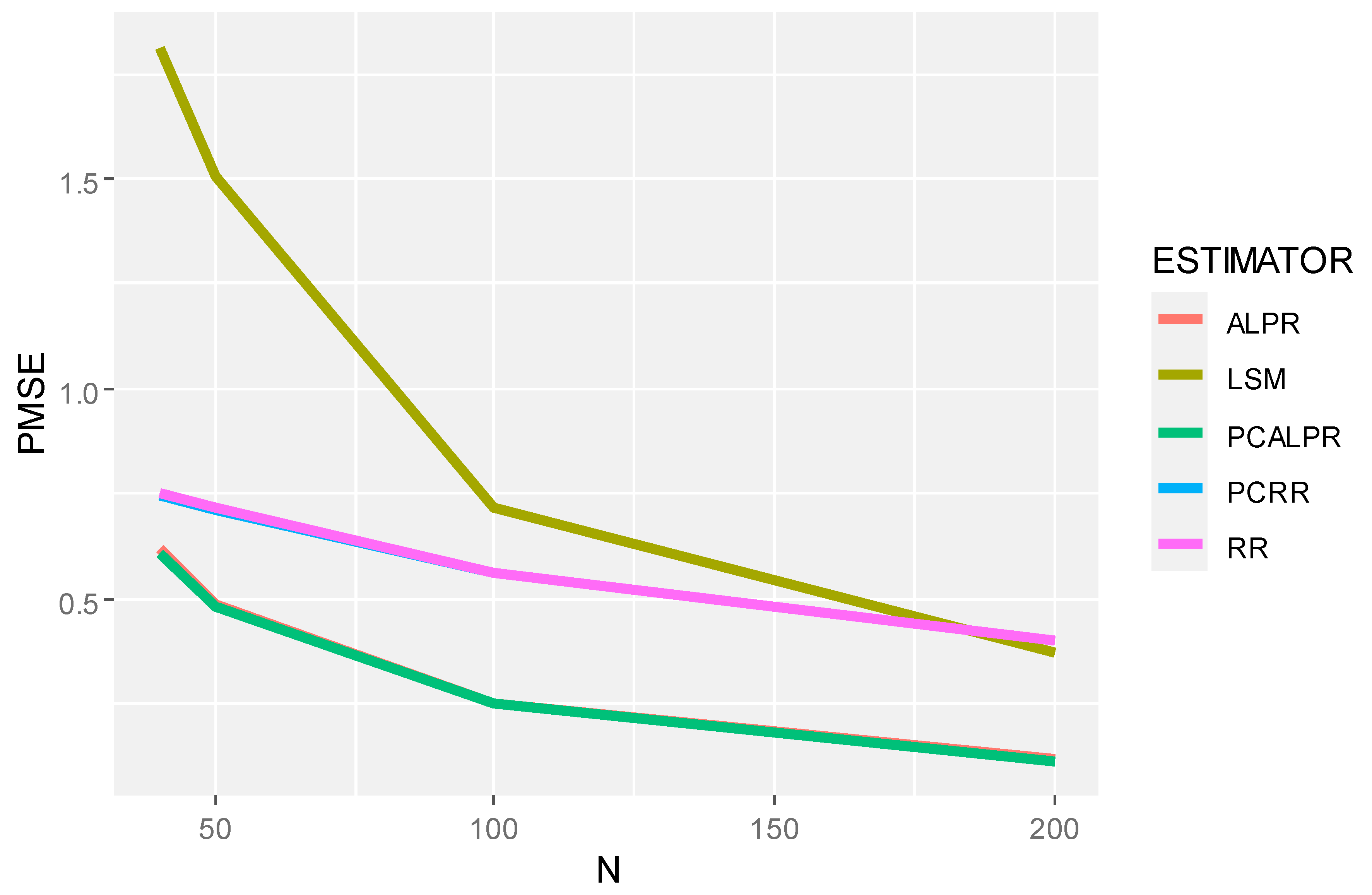
2 = 100), it is evident that all estimators perform worse as noise increases, as expected. However, the relative performance rankings remain roughly consistent, with PCALPR maintaining its superiority. This resilience to increased noise levels further supports the robustness of the proposed method. The mean squared error and prediction mean squared error decrease as the sample size increases, as demonstrated in
Figure 1,
Figure 2,
Figure 3 and
Figure 4.
The findings from this study suggest that PCALPR is a highly promising approach for handling multicollinearity in linear regression models, particularly in situations where predictors have high multicollinearity and when the model is subjected to significant noise. The method not only leverages the strengths of penalized regression techniques to reduce the bias introduced by multicollinearity but also capitalizes on the dimensionality reduction capability of principal component analysis to focus the model estimation on the most relevant information contained within the predictor variables.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}