Abstract
Breast cancer, a common cancer type, is a major health concern in women. Recently, researchers used convolutional neural networks (CNNs) for medical image analysis and demonstrated classification performance for breast cancer diagnosis from within histopathological image datasets. However, the parameter settings of a CNN model are complicated, and using Breast Cancer Histopathological Database data for the classification is time-consuming. To overcome these problems, this study used a uniform experimental design (UED) and optimized the CNN parameters of breast cancer histopathological image classification. In UED, regression analysis was used to optimize the parameters. The experimental results indicated that the proposed method with UED parameter optimization provided 84.41% classification accuracy rate. In conclusion, the proposed method can improve the classification accuracy effectively, with results superior to those of other similar methods.
1. Introduction
Breast cancer is a commonly diagnosed cancer in women worldwide. In Taiwan (with a population of 23 million), 1 in 120 women are diagnosed as having breast cancer annually, and the breast cancer incidence is increasing [1]. The accuracy of histopathological image classification is essential for early breast cancer diagnosis. The techniques of breast cancer diagnosis depend on investigation of histopathological images such as mammography, magnetic resonance imaging (MRI), ultrasound, positron emission tomography (PET), thermography, and surgical incision [2,3]. However, in the early stages, detecting breast cancer from histopathological images is difficult because these images cannot convey warning signs and symptoms [4]. Therefore, various computer-assisted systems have been developed to overcome the drawbacks of histopathological image analysis. Generally adopted workflows in computer-aided diagnosis image tools for breast cancer diagnosis have focused on quantitative image analysis [5]. Recently, advanced engineering techniques have been used by research groups such as the Visual Geometry Group and Google, which have modeled the VGG-16, ResNet and GoogleNet models [6]. These engineering techniques include deep learning models based on convolution neural networks (CNNs), used to improve breast cancer diagnosis efficiency [7]. For instance, the public dataset Breast Cancer Histopathological Database (BreakHis) comprises microscopic images under different magnifying factors of breast tumor tissues collected from patients, with each sample labeled as either benign or malignant [8]. However, Lin et al. [9] achieved an accuracy rate of 83% by using BreakHis. This was achieved by optimizing the hyperparameters. This study uses deep learning networks based on a CNN with parameter optimization to improve the accuracy achieved in studies using BreakHis for image classification.
In medicine, deep learning networks achieve outstanding results in image analysis applications. CNN, a deep learning network type, has emerged as a powerful tool in the automated classification of human cancer histopathology images [10]. The LeNet-5 system represents an effective network for CNN application, with a high recognition rate. Other deep learning networks include single-layer CNN [11], RF classifier + PFTAS [12], LeNet-5(Sgdm) [13], LeNet-5(Adam) [14], and LeNet-5(RMSprop) [15]. The training of a CNN requires excessive computations with large sample and parameter settings to solve practical problems [16]. This enables for a reduction in the number of network computing samples and meets the basic parameter settings for CNN application. The most applicable CNN model is identified through experimentation [17,18]. In addition, Lin et al. [19] used a uniform experimental design (UED) to determine network parameters and improved the overall accuracy. Zhou et al. [20] used a UED to obtain parameters optimization of the formula of Xiaokeyinshui extract combination treating diabetes and to assess predicted values of selected equations in optimized doses of herb extracts. However, this study uses a uniform experimental design (UED) and optimizes the CNN parameters of breast cancer histopathological image classification.
To optimize CNN parameters, UED—A technique based on probability theory, mathematical statistics, and statistical experimental design [21]—was used to reduce the computation time of the experiment. UED can be used to select representative sample sets and arrange all possible experimental parameters found in few experiments uniformly distributed within the parameter space [22]. A series of UED tables indicate that the number of levels is equal to the number of experimental runs [23]. In addition, UED evaluates the factors affecting the results within a minimum number of experiments to obtain sufficiently accurate predictions [24]. Wang et al. [25] used UED to optimize parameters and obtain valuable results from few experiments. In this study, the UED method is used to optimize the parameters of CNN architecture for the application of breast cancer histopathological image classification.
To enhance the classification accuracy, the current study developed a CNN based on UED to solve the complicated parameter setting problem. The main purpose of this study was to use UED to optimize CNN parameters for breast cancer histopathological image classification. Therefore, the main contribution of this study used the UED method to find the optimal parameter combination of the CNN architecture for performing the fewest required experiments and time. In the UED method, the regression analysis was used to find optimization parameters in CNN architecture. Experimental results show that the proposed CNN based UED parameter optimization surpasses the existing techniques with high accuracy, making it more practical in clinical diagnosis.
2. Materials and Methods
Here, a CNN paired with UED parameter optimization is proposed to improve classification performance. The framework of the proposed method is illustrated in Figure 1. Herein, the framework of the proposed method is discussed: The breast cancer histopathological images in BreakHis is presented in Section 2.1, the CNN model’s ability to classify benign and malignant tissue is described in Section 2.2, and the UED method’s ability to adjust the parameters of the CNN architecture and evaluate the optimal parameter combinations is presented in Section 2.3.
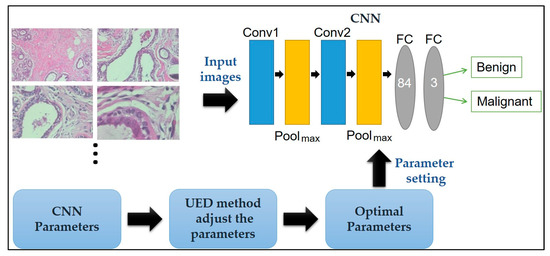
Figure 1.
Framework of the proposed method for breast cancer histopathological image classification.
2.1. Materials
In this study, the experimental images were collected from BreakHis, for which the breast tissue samples were obtained from 82 patients at Pathological Anatomy and Cytopathology Laboratory in Brazil [8]. For each patient, several breast tissue samples were aspired using a fine biopsy needle in the operating room. Each sample was prepared as follows: First, formalin fixation and embedding in paraffin blocks was performed to preserve the original tissue structure and its molecular composition. Then, the 3-μm-thick sections were cut from the paraffin blocks on a high precision microtome. Finally, the sections were mounted on covered glass slides for visualization under light microscope [26].
BreakHis contains 7909 700×460-pixel histopathological images of breast cancer at four ascending magnifications (40×, 100×, 200×, and 400×); of them, 2480 and 5429 images are of benign and malignant cancers, respectively. Table 1 and Figure 2 show the 3-channel RGB images with 8-bit color depth in each channel and the various magnifications. However, the class imbalance issue could bias the discriminative capability of CNN classification; this is the BreakHis dataset limitation, and it would tend towards predicting images as malignant. Therefore, the collected data were divided into training and validation sets: The first 70% of images were for training the network, and the remaining 30% were for validating it.

Table 1.
BreakHis dataset image distribution in terms of class and magnification factor.
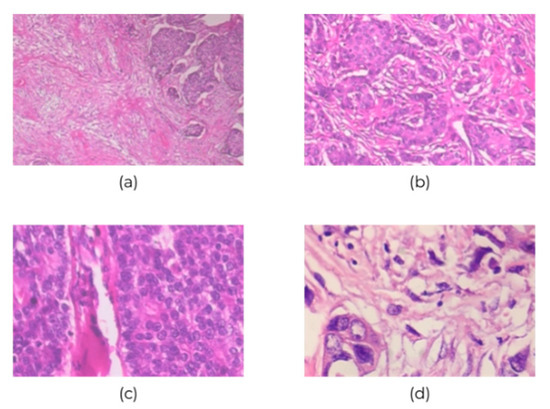
Figure 2.
Sample images of breast cancer histopathological at (a) 40×, (b) 100×, (c) 200×, and (d) 400× magnification.
2.2. The CNN Architecture
A CNN based on deep learning networks learns a hierarchy of increasingly complex features by successive convolution, pooling, and nonlinear activation operations [27,28]. This study designed the architecture of a CNN based on the LeNet network structure including an input three-layer convolutional layer, a two-layer max-pooling layer, a fully connected layer, and final classification. The kernel size, stride, padding, and filters are described in Figure 3 and Table 2.
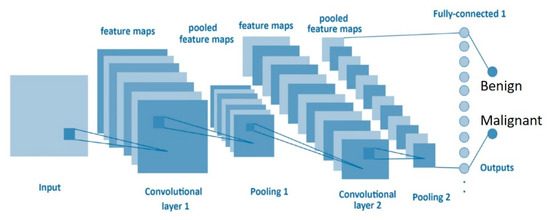
Figure 3.
Convolutional neural network (CNN) structure.
Table 2.
The proposed CNN architecture.
- (a)
- Input layer: The input image size in this study was 50 × 50 × 3, and the first convolutional layer has six filters of 5 × 5-sized feature maps from the previous layer to input layer.
- (b)
- Convolutional layer: Here, the network architecture contained three convolutional layers. The second convolutional layer has 16 filters of 5 × 5-sized feature maps connected to the previous layer. The third convolutional layer has 120 filters of 1 × 1-sized feature maps used from the previous layer. In our model, the stride is 1, so the size of zero padding (zp) is given by the following formula:where k is the filter size.
- (c)
- Pooling layer: According to the network architecture of LeNet, two pooling layers were inserted between the three convolutional layers. This experiment did not adjust the parameter of the pooling layer and maintains its size of 2 × 2.
- (d)
- Output layer: A fully connected layer adopts the ReLU nonlinear function, which is used to categorize samples as benign or malignant. To compute the output size for a convolutional layer, we adopt the following formula:where w is the input size. The padding is p = 0 as the padding and convolution are performed in two separate steps. The ReLU activation function is defined by the following formula:where x is the inputs of a neural network.
2.3. UED Method
In this study, the UED method is proposed to adjust the parameters of the CNN architecture and find the optimal parameter combinations. The UED method is used to replace the combination of all possible experimental parameters with few experimental trials uniformly distributed within the parameter space [29]. The flow of the UED method is illustrated in Figure 4.
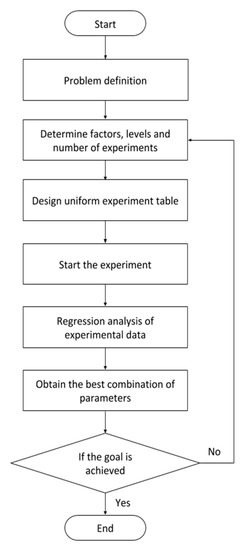
Figure 4.
Uniform experimental design (UED) method flow.
Step 1: Define the experimental conditions.
Step 2: Determine the factors, levels, and numbers of experiments.
Eight affecting factors and mixed levels 2 and 3 are identified herein: A–D and E–H represent first and second convolution layers parameters, respectively. The factors, levels and number of experiments are provided in Table 3.
Table 3.
Affecting factor parameters of the CNN.
Step 3: Design a uniform experiment table.
High-level designs and the corresponding optimization methods used to construct the designs have smaller CD2 values. This assumption allows for the measuring of a design, the uniformity of the double design in terms of the centered L2-discrepancy (CD2) and wrap-around L2-discrepancy (WD2), and sets the lower bounds of the centered L2-discrepancy in double designs [30,31]. UED tables are used to evaluate the data from UED experiments. The form of UED tables is defined by , where U denotes uniform design; n the number of runs, s the number of factors, and q the number of levels [32]. A U17 (178) design table was used to arrange the experiments, where U represents the uniform design, the subscripted 17 the test number, the superscripted 8 the maximum factor number, and 17 the level number. Table 4 and Table 5 present CD2, WD2, and U17 (178) values, with the least deviation.
Table 4.
Squared values of centered L2-discreapncy (CD2) and wrap-around L2-discrepancy (WD2) of the U17 (178).
Table 5.
UED table of U17 (178).
Step 4: Start the experiment.
Step 5: Analyze the experimental data.
To find the optimization parameters for using a regression analysis during the optimization process, the response variables are fitted by a quadratic model [17], as shown in Equation (1).
where is the error, Y is the accuracy, the factors, n the number of affecting factors, the constant, and the coefficients of X.
Step 6: Obtain the best combination of parameters.
Step 7: End the experiment if the goal is achieved; otherwise, repeat the experiment beginning from step 2.
3. Experimental Results
In this experiment, the UED method was used to optimize the CNN architecture. The minimum number of experiments was 17 to evaluate the parameter optimization of the CNN. BreakHis is used to verify breast cancer histopathological image classification. The uniform layout (UL) of U17 (178) was used to allocate the eight factors with 17 levels as shown in Table 6. Table 7 provides the observed results for each experiment. The three tests could be performed with the identical parameter combination, and each observation was recorded independently. The average classification accuracy of the CNN is 83.4% on run 2 of this experiment. In addition, by using UED based on regression analysis for parameter optimization combination of CNN architecture, the average classification accuracy of the optimized structure in BreakHis has improved by 1.01% (Table 8). Therefore, the optimal parameter combination for the conv1_Kernel size, conv1_Filter, conv1_Stride, conv1_Padding, conv2_Kernel size, conv2_Filter, conv2_Stride, and conv2_Padding is 7, 12, 2, 1, 3, 8, 1, and 1, respectively.
Table 6.
UL of U17 (178) used to allocate the eight factors with 17 levels.
Table 7.
Results of the CNN in BreakHis.
Table 8.
Comparison results between run 2 and the UED with the best parameters in the experiment.
Performance of the proposed CNN with UED parameter optimization is evaluated using a confusion matrix as shown in Figure 5a, and the ROC curve is also shown in Figure 5b. The confusion matrix shows 1997 correct classifications (521 of benign and 1476 of malignant) among 2373 validation images, and the AUC is 0.842 in the ROC curve.
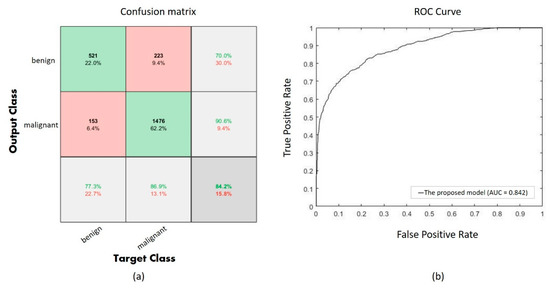
Figure 5.
(a) The confusion of the proposed model, (b) the ROC curve of the proposed model.
Table 9 provides a comparison of the proposed CNN paired with UED parameter optimization and the alternative methods, such as the single-layer CNN [9], RF classifier + PFTAS [10], LeNet-5(Sgdm) [11], LeNet-5(Adam) [12], LeNet-5(RMSprop) [13], and CNN with Taguchi method [7]. This table illustrates that the accuracy of the optimized network architecture is 84.41%, and it has an accuracy superior to other methods.
Table 9.
Comparison results of the various methods.
Comparison results of advanced engineering techniques, such as the VGG-16, ResNet-101 and GoogleNet, are shown in Table 10. The highest average accuracy rate of GoogleNet is 85.46%, but the computational time for training is 33 min 27 s. However, the proposed CNN with UED parameter optimization obtains 84.41% average accuracy rate, and the computational time for training is only 13 min 41 s and fewer than other methods.
Table 10.
Comparison results of advanced engineering techniques.
4. Conclusions
This study proposes UED parameter optimization for deep learning networks used to perform experiments on breast cancer histopathological image classification. In the proposed UED approach, uniform experiment table and regression analysis were used to adjust CNN architecture to optimize the parameter combination. Based on the experimental design in this study, the optimal parameter combination of a CNN is achieved when the optimum parameters are as follows: the conv1_Kernel size, conv1_Filter, conv1_Stride, conv1_Padding, conv2_Kernel size, conv2_Filter, conv2_Stride, and conv2_Padding is 7, 12, 2, 1, 3, 8, 1, and 1, respectively. The experimental results indicated that the average accuracy of the proposed method (using BreakHis) is 84.41%, and this is 1.01% higher than the accuracy of a CNN without using UED. In addition, the classification accuracies of the proposed method were 6.91%, 3.13%, 3.72%, 2.19%, 1.83%, and 1.22% higher than the single-layer CNN, RF classifier + PFTAS, LeNet-5(Sgdm), LeNet-5(Adam), LeNet-5(RMSprop), and CNN with Taguchi methods, respectively. The experimental results present that the proposed CNN based on UED parameter optimization improves the network performance and is superior to other methods.
The contributions of this study include providing users in modeling with a small number of experiments to find the most efficient parameter combination of CNN architecture, thus reducing experimental times and improving classification accuracy. The limitations of this study are that only the first and second convolutional layers are used as affecting factors. Nevertheless, a CNN with UED parameter optimization demonstrated future learning potential and can process the variable size of training and test data sets. Future studies should focus on the optimal size of input patches for deep learning algorithm development of new architectural structures. This enables researchers to efficiently identify the factors influencing parameter optimization and potentially consider multiple-input CNNs in the future. In addition, the limitation of the BreakHis dataset is the imbalance issue between benign and malignant dataset. Therefore, we will used Generative Adversarial Network (GAN) model to extend the benign dataset in the future work.
Author Contributions
Conceptualization, C.-J.L.; data curation, S.-Y.J.; funding acquisition, C.-J.L.; methodology, C.-J.L.; software, S.-Y.J.; writing—original draft, S.-Y.J. Both authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Ministry of Science and Technology of the Republic of China, grant number MOST 108-2221-E-167-026.
Acknowledgments
The authors would like to thank the Ministry of Science and Technology of the Republic of China, Taiwan, for financially supporting this research under Contract No. MOST 108-2221-E-167-026.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Diaby, V.; Alqhtani, H.; Boemmel-Wegmann, S.V.; Wang, C.Y.; Ali, A.A.; Balkrishnan, R.; Ko, Y.; Palacio, S.; Lopes, G.D.L. A cost-effectiveness analysis of trastuzumab-containing treatment sequences for HER-2 positive metastatic breast cancer patients in Taiwan. Breast 2020, 49, 141–148. [Google Scholar] [CrossRef]
- Mehra, R. Breast cancer histology images classification: Training from scratch or transfer learning? ICT Express 2018, 4, 247–254. [Google Scholar]
- Tan, M.; Zheng, B.; Leader, J.K.; Gur, D. Association between changes in mammographic image features and risk for near-term breast cancer development. IEEE Trans. Med. Imaging 2016, 35, 1719–1728. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Singh, S.K.; Saxena, S.; Lakshmanan, K.; Sangaiah, A.K.; Chauhan, H.; Shrivastava, S.; Singh, R.K. Deep feature learning for histopathological image classification of canine mammary tumors and human breast cancer. Inf. Sci. 2020, 508, 405–421. [Google Scholar] [CrossRef]
- Madabhushi, A.; Lee, G. Image analysis and machine learning in digital pathology: Challenges and opportunities. Med. Image Anal. 2016, 33, 170–175. [Google Scholar] [CrossRef] [PubMed]
- Nahid, A.A.; Kong, Y. Histopathological Breast-Image Classification Using Local and Frequency Domains by Convolutional Neural Network. Information 2018, 9, 19. [Google Scholar] [CrossRef]
- Toğaçar, M.; Özkurt, K.B.; Ergen, B.; Cömert, Z. BreastNet: A novel convolutional neural network model through histopathological images for the diagnosis of breast cancer. Physica A 2020, 545, 123592. [Google Scholar] [CrossRef]
- Spanhol, F.A.; Oliveira, L.S.; Heutte, L. A dataset for breast cancer histopathological image classification. IEEE Trans. Biomed. Eng. 2016, 63, 1455–1462. [Google Scholar] [CrossRef] [PubMed]
- Lin, C.J.; Lee, C.L.; Jeng, S.Y. Using hyper-parameter optimization of deep learning networks for classification of breast histopathology images. In Proceedings of the 2nd Eurasia Conference on Biomedical Engineering, Healthcare and Sustainability, Tainan, Taiwan, 29–31 May 2020. [Google Scholar]
- Khosravi, P.E.; Imielinski, M.O.; Hajirasouliha, I. Deep convolutional neural networks enable discrimination of heterogeneous digital pathology images. EBioMedicine 2018, 27, 317–328. [Google Scholar] [CrossRef] [PubMed]
- Nejad, M.E.; Affendey, L.S.; Latip, R.B.; Ishak, I.B. Classification of histopathology images of breast into benign and malignant using a single-layer convolutional neural network. Paper presented at the 2017 ACM International Conference on Interactive Surfaces and Spaces, Brighton, UK, 17–20 October 2017; pp. 50–53. [Google Scholar]
- Sharma, M.; Singh, R.; Bhattacharya, M. Classification of breast tumors as benign and malignant using textural feature descriptor. In Proceedings of the 2017 IEEE International Conference on Bioinformatics and Biomedicine, Kansas City, MO, USA, 13–16 November 2017; pp. 1110–1113. [Google Scholar]
- Darken, C.; Chang, J.; Moody, J. Learning rate schedules for faster stochastic gradient search. In Proceedings of the Neural Networks for Signal Processing II Proceedings of the 1992 IEEE Workshop, Helsingoer, Denmark, 31 August–2 September 1992; pp. 3–12. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Mukkamala, M.C.; Hein, M. Variants of RMSProp and Adagrad with logarithmic regret bounds. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2545–2553. [Google Scholar]
- Sabeena, B.K.; Madhu, S.N.B.; Bindu, G.R. Automatic mitosis detection in breast histopathology images using convolutional neural network based deep transfer learning. Biocyberntics Biomed. Eng. 2019, 39, 214–223. [Google Scholar] [CrossRef]
- Liu, N.; Xu, Y.; Tian, Y.; Ma, H.; Wen, S. Background classification method based on deep learning for intelligent automotive radar target detection. Future Gener. Comput. Syst. 2019, 94, 524–535. [Google Scholar] [CrossRef]
- Le, N.Q.K.; Yapp, E.K.Y.; Ou, Y.Y.; Yeh, H.Y. iMotor-CNN: Identifying molecular functions of cytoskeleton motor proteins using 2D convolutional neural network via Chou’s 5-step rule. Anal. Biochem. 2019, 575, 214–223. [Google Scholar] [CrossRef] [PubMed]
- Lin, C.J.; Lin, C.H.; Jeng, S.Y. Using feature fusion and parameter optimization of dual-input convolutional neural network for face gender recognition. Appl. Sci. 2020, 10, 3166. [Google Scholar] [CrossRef]
- Zhou, J.; Pan, J.; Xiang, Z.; Wang, Q.; Tong, Q.; Fang, J.; Wan, L.; Chen, J. Data on the optimization of the formula of Xiaokeyinshui extract combination treating diabetes mellitus using uniform experimental design in mice. Data Brief 2020, 32, 106134. [Google Scholar] [CrossRef]
- Xiong, Q.; Li, Z.; Luo, H.; Zhao, Z. Wind tunnel test study on wind load coefficients variation law of heliostat based on uniform design method. Sol. Energy 2019, 184, 209–229. [Google Scholar] [CrossRef]
- Guan, J.; Han, C.; Guan, Y.; Zhang, S.; Junxian, Y.; Yao, S. Optimizational production of phenyllactic acid by a Lactobacillus buchneri strain via uniform design with overlay sampling methodology. Chin. J. Chem. Eng. 2019, 27, 418–425. [Google Scholar] [CrossRef]
- Ping, H.; Xu, G.; Wu, S. System optimization of cyclohexane dehydrogenation under multiphase reaction conditions using the uniform design method. Int. J. Hydrogen Energy 2015, 40, 15923–15932. [Google Scholar] [CrossRef]
- Li, T.Z.; Yang, X.L. An efficient uniform design for Kriging-based response surface method and its application. Comput. Geotech. 2019, 109, 12–22. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, L.; Li, G.; Rogers, K.; Lin, H.; Seers, P.; Ledan, T.; Ng, S.; Zheng, Y. Application of uniform design experimental method in waste cooking oil (WCO) co-hydroprocessing parameter optimization and reaction route investigation. Fuel 2017, 210, 390–397. [Google Scholar] [CrossRef]
- Benhammou, Y.; Achchab, B.; Herrera, F.; Tabik, S. BreakHis based breast cancer automatic diagnosis using deep learning: Taxonomy, survey and insights. Neurocomputing 2020, 375, 9–24. [Google Scholar] [CrossRef]
- Dolz, J.; Desrosiers, C.; Wang, L.; Yuan, J.; Shen, D.; Ayed, I.B. Deep CNN ensembles and suggestive annotations for infant brain MRI segmentation. Comput. Med Imaging Graph. 2020, 79, 101660. [Google Scholar] [CrossRef] [PubMed]
- Suredh, S.; Mohan, S. NROI based feature learning for automated tumor stage classification of pulmonary lung nodules using deep convolutional neural networks. J. King Saud Univ. Comput. Inf. Sci. 2019. [Google Scholar] [CrossRef]
- Song, G.; Xu, G.; Quan, Y.; Yuan, Q.; Davies, P.A. Uniform design for the optimization of Al2O3 nanofilms produced by electrophoretic deposition. Surf. Coat. Technol. 2016, 286, 268–278. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, J.; Tang, Y. Level permutation method for constructing uniform designs under the wrap-around L2-discrepancy. J. Complex. 2014, 30, 46–53. [Google Scholar] [CrossRef]
- Zou, N.; Qin, H. Some properties of double designs in terms of lee discrepancy. Acta Math. Sci. 2017, 37B, 477–487. [Google Scholar] [CrossRef]
- Yu, Y.; Zhu, X.; Zhu, J.; Li, L.; Zhang, X.; Xiang, M.; Ma, R.; Yu, L.; Yu, Z.; Wang, Z. Rapid and simultaneous analysis of tetrabromobisphenol A and hexabromocyclododecane in water by direct immersion solid phase microextraction: Uniform design to explore factors. Ecotoxicol. Environ. Saf. 2019, 176, 364–369. [Google Scholar] [CrossRef]





© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).