
A Machine Learning Model for Predicting Unscheduled 72 h Return Visits to the Emergency Department by Patients with Abdominal Pain

 , , ,
, , ,
Abstract
:1. Introduction
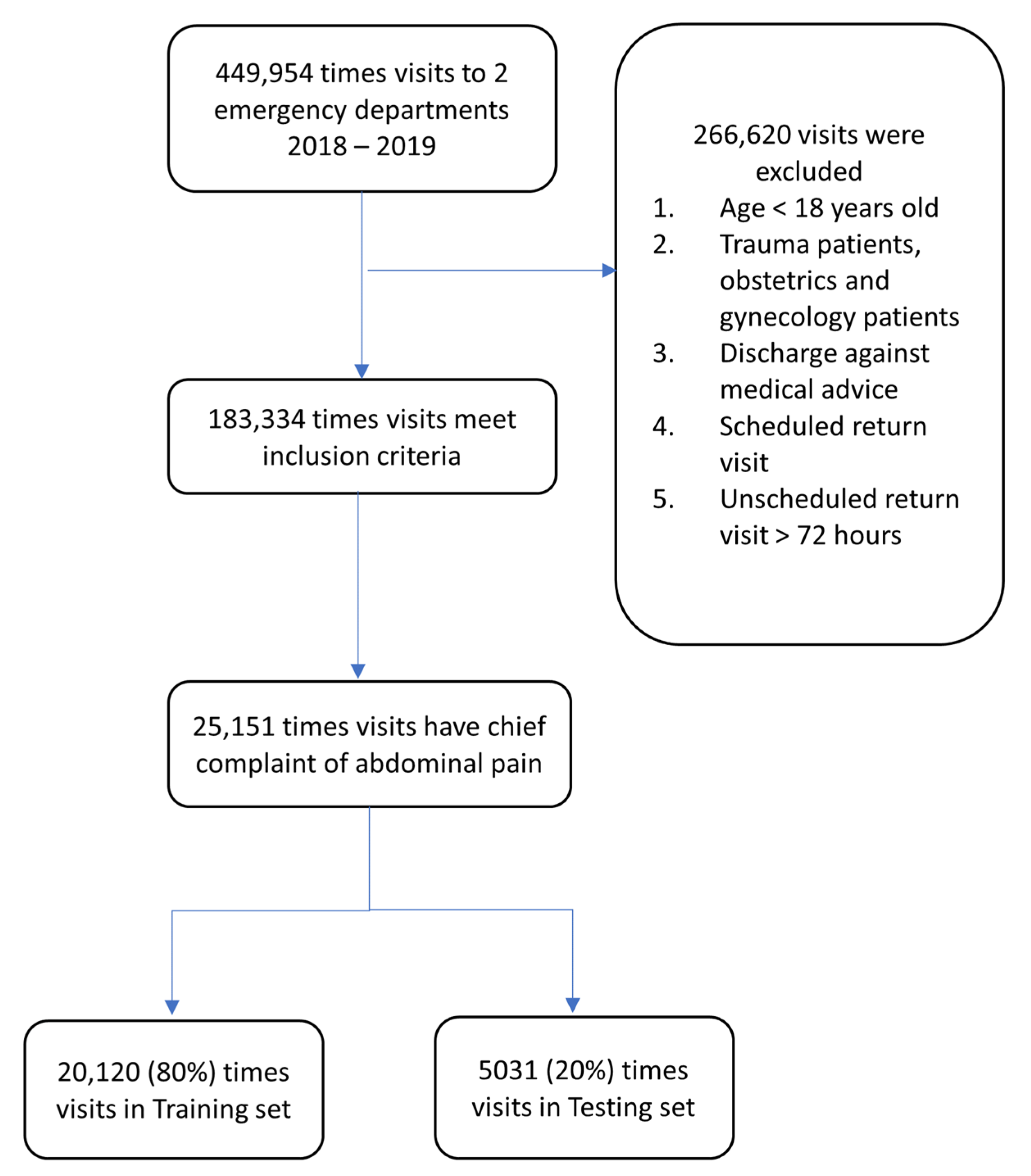
2. Materials and Methods
2.1. Study Design
2.2. Data Source and Preprocessing
2.3. Machine Learning Model and Training
2.4. Hyperparameter Tuning and VC
2.5. Reduced-Features Models
2.6. Outcome Measurement and Statistical Analysis
3. Results
3.1. Characteristic Description
3.2. Performance of the All-Features Models
3.3. Reduced-Features Models Performance
3.4. Comparison of All-Features and Reduced-Features Models
4. Discussion
Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Navanandan, N.; Schmidt, S.K.; Cabrera, N.; Topoz, I.; Distefano, M.C.; Mistry, R.D. Seventy-two-hour return initiative: Improving emergency department discharge to decrease returns. Pediatr. Qual. Saf. 2020, 5, e342. [Google Scholar] [CrossRef] [PubMed]
- Lindsay, P.; Schull, M.; Bronskill, S.; Anderson, G. The development of indicators to measure the quality of clinical care in emergency departments following a modified-delphi approach. Acad. Emerg. Med. 2002, 9, 1131–1139. [Google Scholar] [CrossRef]
- Schenkel, S. Promoting patient safety and preventing medical error in emergency departments. Acad. Emerg. Med. 2000, 7, 1204–1222. [Google Scholar] [CrossRef] [Green Version]
- Chan, A.H.S.; Ho, S.F.; Fook-Chong, S.M.C.; Lian, S.W.Q.; Liu, N.; Ong, M.E.H. Characteristics of patients who made a return visit within 72 h to the emergency department of a Singapore tertiary hospital. Singap. Med. J. 2016, 57, 301–306. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martin-Gill, C.; Reiser, R.C. Risk factors for 72-h admission to the ED. Am. J. Emerg. Med. 2004, 22, 448–453. [Google Scholar] [CrossRef]
- Ws, K. Emergency unscheduled returns: Can we do better? Singap. Med. J. 2009, 50, 1068–1071. [Google Scholar]
- Abualenain, J.; Frohna, W.J.; Smith, M.; Pipkin, M.; Webb, C.; Milzman, D.; Pines, J.M. The Prevalence of Quality Issues and Adverse Outcomes among 72-Hour Return Admissions in the Emergency Department. J. Emerg. Med. 2013, 45, 281–288. [Google Scholar] [CrossRef] [PubMed]
- Graff, L.G.; Robinson, D. Robinson, Abdominal pain and emergency department evaluation. Emerg. Med. Clin. N. Am. 2001, 19, 123–136. [Google Scholar] [CrossRef]
- Kamin, R.A.; Nowicki, T.A.; Courtney, D.S.; Powers, R.D. Pearls and pitfalls in the emergency department evaluation of abdominal pain. Emerg. Med. Clin. 2003, 21, 61–72. [Google Scholar] [CrossRef]
- Macaluso, C.R.; McNamara, R.M. Evaluation and management of acute abdominal pain in the emergency department. Int. J. Gen. Med. 2012, 5, 789. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hastings, R.S.; Powers, R.D. Powers, Abdominal pain in the ED: A 35 year retrospective. Am. J. Emerg. Med. 2011, 29, 711–716. [Google Scholar] [CrossRef] [PubMed]
- de Groot, B.; Stolwijk, F.; Warmerdam, M.; Lucke, J.A.; Singh, G.K.; Abbas, M.; Mooijaart, S.P.; Ansems, A.; Esteve Cuevas, L.; Rijpsma, D. The most commonly used disease severity scores are inappropriate for risk stratification of older emergency department sepsis patients: An observational multi-centre study. Scand. J. Trauma Resusc. Emerg. Med. 2017, 25, 1–11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Johnson, A.E.W.; Ghassemi, M.M.; Nemati, S.; Niehaus, K.E.; Clifton, D.A.; Clifford, G. Machine learning and decision support in critical care. Proc. IEEE 2016, 104, 444–466. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.H.; Asch, S.M. Machine learning and prediction in medicine—beyond the peak of inflated expectations. N. Engl. J. Med. 2017, 376, 2507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jordan, M.I.; Mitchell, T.M. Mitchell, Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Deo, R.C. Machine learning in medicine. Circulation 2015, 132, 1920–1930. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rajkomar, A.; Dean, J.; Kohane, I. Machine learning in medicine. N. Engl. J. Med. 2019, 380, 1347–1358. [Google Scholar] [CrossRef]
- Hong, W.S.; Haimovich, A.D.; Taylor, R.A. Predicting 72-h and 9-day return to the emergency department using machine learning. JAMIA Open 2019, 2, 346–352. [Google Scholar] [CrossRef] [PubMed]
- Pellerin, G.; Gao, K.; Kaminsky, L. Predicting 72-hour emergency department revisits. Am. J. Emerg. Med. 2018, 36, 420–424. [Google Scholar] [CrossRef]
- Huda, S.M.A.; Ila, I.J.; Sarder, S.; Shamsujjoha, M.; Ali, N.Y.M. An improved approach for detection of diabetic retinopathy using feature importance and machine learning algorithms. In Proceedings of the 2019 7th International Conference on Smart Computing & Communications (ICSCC), Sarawak, Malaysi, 28–30 June 2019. [Google Scholar]
- Rodríguez-Pérez, R.; Bajorath, J. Feature importance correlation from machine learning indicates functional relationships between proteins and similar compound binding characteristics. Sci. Rep. 2021, 11, 1–9. [Google Scholar]
- Tsai, M.-S.; Lin, M.-H.; Lee, C.-P.; Yang, Y.-H.; Chen, W.-C.; Chang, G.-H.; Tsai, Y.-T.; Chen, P.-C.; Tsai, Y.-H. Chang Gung Research Database: A multi-institutional database consisting of original medical records. Biomed. J. 2017, 40, 263–269. [Google Scholar] [CrossRef]
- Rintaari, K.M.; Kimani, R.W.; Musembi, H.M.; Gatimu, S.M. Characteristics and outcomes of patients with an unscheduled return visit within 72 h to the Paediatric Emergency Centre at a Private Tertiary Referral Hospital in Kenya. Afr. J. Emerg. Med. 2021, 11, 242–247. [Google Scholar] [CrossRef]
- Lee, E.K.; Yuan, F.; Hirsh, D.A.; Mallory, M.D.; Simon, H.K. A clinical decision tool for predicting patient care characteristics: Patients returning within 72 h in the emergency department. AMIA Annu. Symp. Proc. 2012, 2012, 495–504. [Google Scholar]
- Oh, B.Y.; Kim, K. Factors associated with the undertriage of patients with abdominal pain in an emergency room. Int. Emerg. Nurs. 2021, 54, 100933. [Google Scholar] [CrossRef]
- Wu, T.-Y.; Majeed, A.; Kuo, K.N. An overview of the healthcare system in Taiwan. Lond. J. Prim. Care 2010, 3, 115–119. [Google Scholar] [CrossRef] [Green Version]
- Stoltzfus, J.C. Logistic regression: A brief primer. Acad. Emerg. Med. 2011, 18, 1099–1104. [Google Scholar] [CrossRef] [PubMed]
- Zemek, R.; Barrowman, N.; Freedman, S.B.; Gravel, J.; Gagnon, I.; McGahern, C.; Aglipay, M.; Sangha, G.; Boutis, K.; Beer, D.; et al. Clinical Risk Score for Persistent Postconcussion Symptoms Among Children With Acute Concussion in the ED. JAMA 2016, 315, 1014–1025. [Google Scholar] [CrossRef] [PubMed]
- Pregibon, D. Logistic Regression Diagnostics. Ann. Stat. 1981, 9, 705–724. [Google Scholar] [CrossRef]
- Song, J.; Gao, Y.; Yin, P.; Li, Y.; Li, Y.; Zhang, J.; Su, Q.; Fu, X.; Pi, H. The Random Forest Model Has the Best Accuracy Among the Four Pressure Ulcer Prediction Models Using Machine Learning Algorithms. Risk Manag. Healthc. Policy 2021, 14, 1175–1187. [Google Scholar] [CrossRef] [PubMed]
- Alam, Z.; Rahman, M.S. A Random Forest based predictor for medical data classification using feature ranking. Inform. Med. Unlocked 2019, 15, 100180. [Google Scholar] [CrossRef]
- Hancock, J.; Khoshgoftaar, T.M. Performance of catboost and xgboost in medicare fraud detection. In Proceedings of the 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 14–17 December 2020. [Google Scholar]
- Wang, C.; Deng, C.; Wang, S. Imbalance-XGBoost: Leveraging weighted and focal losses for binary label-imbalanced classification with XGBoost. Pattern Recognit. Lett. 2020, 136, 190–197. [Google Scholar] [CrossRef]
- Sherazi, S.W.A.; Bae, J.-W.; Lee, J.Y. A soft voting ensemble classifier for early prediction and diagnosis of occurrences of major adverse cardiovascular events for STEMI and NSTEMI during 2-year follow-up in patients with acute coronary syndrome. PLoS ONE 2021, 16, e0249338. [Google Scholar] [CrossRef]
- Hayward, J.; Hagtvedt, R.; Ma, W.; Gauri, A.; Vester, M.; Holroyd, B.R. Predictors of Admission in Adult Unscheduled Return Visits to the Emergency Department. West. J. Emerg. Med. 2018, 19, 912–918. [Google Scholar] [CrossRef] [PubMed]
- Madsen, T.E.; Bennett, A.; Groke, S.; Zink, A.; McCowan, C.; Hernandez, A.; Knapp, S.; Byreddy, D.; Mattsson, S.; Quick, N. Emergency department patients with psychiatric complaints return at higher rates than controls. West. J. Emerg. Med. 2009, 10, 268. [Google Scholar] [PubMed]
- Manterola, C.; Vial, M.; Moraga, J.; Astudillo, P. Analgesia in patients with acute abdominal pain. Cochrane Database Syst. Rev. 2011. [Google Scholar] [CrossRef] [PubMed]
- Brewster, G.S.; Herbert, M.E.; Hoffman, J.R. Medical myth: Analgesia should not be given to patients with an acute abdomen because it obscures the diagnosis. West. J. Med. 2000, 172, 209. [Google Scholar] [CrossRef] [Green Version]
- Thomas, S.; Silen, W. Effect on diagnostic efficiency of analgesia for undifferentiated abdominal pain. J. Br. Surg. 2003, 90, 5–9. [Google Scholar] [CrossRef] [PubMed]
- Sung, C.-W.; Lu, T.-C.; Fang, C.-C.; Lin, J.-Y.; Yeh, H.-F.; Huang, C.-H.; Tsai, C.-L. Factors associated with a high-risk return visit to the emergency department: A case-crossover study. Eur. J. Emerg. Med. 2021, 28, 394–401. [Google Scholar] [CrossRef] [PubMed]
- Goto, T.; Camargo, C.A., Jr.; Faridi, M.K.; Yun, B.J.; Hasegawa, K. Machine learning approaches for predicting disposition of asthma and COPD exacerbations in the ED. Am. J. Emerg. Med. 2018, 36, 1650–1654. [Google Scholar] [CrossRef]
- Rajpurkar, P.; O’Connell, C.; Schechter, A.; Asnani, N.; Li, J.; Kiani, A.; Ball, R.L.; Mendelson, M.; Maartens, G.; Van Hoving, D.J.; et al. CheXaid: Deep learning assistance for physician diagnosis of tuberculosis using chest x-rays in patients with HIV. NPJ Digit. Med. 2020, 3, 115. [Google Scholar] [CrossRef]
- Dias, R.D.; Gupta, A.; Yule, S.J. Using machine learning to assess physician competence: A systematic review. Acad. Med. 2019, 94, 427–439. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arbabshirani, M.R.; Fornwalt, B.K.; Mongelluzzo, G.J.; Suever, J.D.; Geise, B.D.; Patel, A.A.; Moore, G.J. Advanced machine learning in action: Identification of intracranial hemorrhage on computed tomography scans of the head with clinical workflow integration. NPJ Digit. Med. 2018, 1, 1–7. [Google Scholar] [CrossRef]
- Anderson, R.E. Billions for defense: The pervasive nature of defensive medicine. Arch. Intern. Med. 1999, 159, 2399–2402. [Google Scholar] [CrossRef] [PubMed]
- Mosquera, C.; Binder, F.; Diaz, F.N.; Seehaus, A.; Ducrey, G.; Ocantos, J.A.; Aineseder, M.; Rubin, L.; Rabinovich, D.A.; Quiroga, A.E.; et al. Integration of a deep learning system for automated chest x-ray interpretation in the emergency department: A proof-of-concept. Intell.-Based Med. 2021, 5, 100039. [Google Scholar] [CrossRef]
- Hao, S.; Jin, B.; Shin, A.Y.; Zhao, Y.; Zhu, C.; Li, Z.; Hu, Z.; Fu, C.; Ji, J.; Wang, Y.; et al. Risk prediction of emergency department revisit 30 days post discharge: A prospective study. PLoS ONE 2014, 9, e112944. [Google Scholar] [CrossRef] [PubMed] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set | Testing Set | All Encounters | |||||
|---|---|---|---|---|---|---|---|
| No 72 h Return Visit N = 18,943 | 72 h Return Visit N = 1177 | No 72 h Return Visit N = 4737 | 72 h Return Visit N = 294 | No 72 h Return Visit N = 23,680 | 72 h Return Visit N = 1471 | p-Value | |
| Demographic Age, Mean (SD), years | 46.44 (18.12) | 52.15 (18.22) | 46.44 (18.26) | 52.02 (18.31) | 46.44 (18.15) | 52.13 (18.23) | <0.001 |
| Male, No. % | 7811 (41.23%) | 567 (48.17%) | 1897(40.05%) | 165 (56.12%) | 9708 (41.0%) | 732 (49.8%) | <0.001 |
| ED related features Arrival by ambulance, No. % | 140 (0.74%) | 7 (0.59%) | 36 (0.76%) | 3 (1.02%) | 176 (0.7%) | 10 (0.7%) | 0.255 |
| Previous ED visits in the past year, Median (IQR) | 0 (0–1) | 1 (0–3) | 0 (0–1) | 1 (0–3) | 0 (0–1) | 1 (0–3) | <0.001 |
| Triage level > 3, No. % | 959 (5.07%) | 50 (4.25%) | 295 (6.23%) | 10 (3.4%) | 1254 (5.3%) | 60 (4.1%) | 0.013 |
| Length of stay, minutes, Median (IQR) | 106.2 (67.2–198) | 115.2 (75–193.8) | 103.8 (64.2–190.8) | 115.8 (73.4–197.7) | 106.2 (66–196.8) | 115.2 (74.4–196.5) | 0.237 |
| Vital signs Body temperature at triage, Median (IQR) | 36.3 (35.9–36.7) | 36.3 (35.9–36.8) | 36.3 (36–36.8) | 36.3 (35.8–36.7) | 36.3 (35.9–36.8) | 36.3 (35.9–36.8) | 0.066 |
| Heart rate at triage, Median (IQR) | 83 (73–94) | 83.5 (73–96) | 83 (73–95) | 83 (71–95) | 83 (73–95) | 83 (73–96) | 0.113 |
| Respiratory rate at triage, Median (IQR) | 18 (17–19) | 18 (17–19) | 18 (17–18) | 18 (17–19) | 18 (17–18) | 18 (17–19) | <0.001 |
| Systolic blood pressure, Median (IQR) | 131 (116–149) | 136 (120–155) | 131 (116–149) | 135.5 (119–153) | 131 (116–149) | 136 (120–155) | <0.001 |
| Diastolic blood pressure, Median (IQR) | 80 (70–90) | 83 (72.2–93) | 80 (69–90) | 82 (71–90) | 80 (70–90) | 83 (72–93) | 0.005 |
| Examinations Blood test, No. % | 10,251 (54.11%) | 677 (57.52%) | 2539 (53.6%) | 164 (55.78%) | 12,790 (54.0%) | 841 (57.2%) | 0.020 |
| X-ray, No. % | 9794 (51.7%) | 635 (53.95%) | 2411 (50.9%) | 147 (50%) | 12,205 (51.5%) | 782 (53.2%) | 0.238 |
| Abdominal echo, No. % | 391 (2.06%) | 18 (1.53%) | 105 (2.22%) | 6 (2.04%) | 496 (2.1%) | 24 (1.6%) | 0.264 |
| CT, No. % | 2565 (13.54%) | 143 (12.15%) | 626 (13.22%) | 41 (13.95%) | 3191 (13.5%) | 184 (12.5%) | 0.309 |
| Model Name | Accuracy | AUC | Sensitivity | Specificity | Precision | F1 Score |
|---|---|---|---|---|---|---|
| LR | 0.75 | 0.73 (0.7–0.76) | 0.59 | 0.76 | 0.13 | 0.22 |
| RF | 0.85 | 0.71 (0.69–0.75) | 0.33 | 0.88 | 0.14 | 0.20 |
| XGB | 0.94 | 0.74 (0.7–0.76) | 0.04 | 0.99 | 0.92 | 0.07 |
| VC | 0.86 | 0.74 (0.69–0.76) | 0.39 | 0.89 | 0.18 | 0.25 |
| Model Name | Accuracy | AUC | Sensitivity | Specificity | Precision | F1 Score |
|---|---|---|---|---|---|---|
| LR | 0.74 | 0.70 (0.68–0.73) | 0.54 | 0.75 | 0.12 | 0.19 |
| RF | 0.87 | 0.70 (0.68–0.73) | 0.31 | 0.91 | 0.17 | 0.22 |
| XGB | 0.94 | 0.73 (0.68–0.75) | 0.03 | 0.99 | 0.91 | 0.07 |
| VC | 0.85 | 0.72 (0.69–0.74) | 0.39 | 0.88 | 0.17 | 0.24 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsu, C.-C.; Chu, C.-C.J.; Lin, C.-H.; Huang, C.-H.; Ng, C.-J.; Lin, G.-Y.; Chiou, M.-J.; Lo, H.-Y.; Chen, S.-Y. A Machine Learning Model for Predicting Unscheduled 72 h Return Visits to the Emergency Department by Patients with Abdominal Pain. Diagnostics 2022, 12, 82. https://doi.org/10.3390/diagnostics12010082
Hsu C-C, Chu C-CJ, Lin C-H, Huang C-H, Ng C-J, Lin G-Y, Chiou M-J, Lo H-Y, Chen S-Y. A Machine Learning Model for Predicting Unscheduled 72 h Return Visits to the Emergency Department by Patients with Abdominal Pain. Diagnostics. 2022; 12(1):82. https://doi.org/10.3390/diagnostics12010082
Chicago/Turabian StyleHsu, Chun-Chuan, Cheng-C.J. Chu, Ching-Heng Lin, Chien-Hsiung Huang, Chip-Jin Ng, Guan-Yu Lin, Meng-Jiun Chiou, Hsiang-Yun Lo, and Shou-Yen Chen. 2022. "A Machine Learning Model for Predicting Unscheduled 72 h Return Visits to the Emergency Department by Patients with Abdominal Pain" Diagnostics 12, no. 1: 82. https://doi.org/10.3390/diagnostics12010082
APA StyleHsu, C.-C., Chu, C.-C. J., Lin, C.-H., Huang, C.-H., Ng, C.-J., Lin, G.-Y., Chiou, M.-J., Lo, H.-Y., & Chen, S.-Y. (2022). A Machine Learning Model for Predicting Unscheduled 72 h Return Visits to the Emergency Department by Patients with Abdominal Pain. Diagnostics, 12(1), 82. https://doi.org/10.3390/diagnostics12010082