
Melanoma Detection Using XGB Classifier Combined with Feature Extraction and K-Means SMOTE Techniques



Abstract
:1. Introduction
- Dermoscopy images (2299) were used for MM CAD, a dermatologist handcrafted feature method was used as a comparison base, and four classification efficiency improvement strategies were proposed: (1) a comparison of different transfer learning techniques for automatic image FE; (2) the addition of the metadata of gender and age; (3) a comparison of the class balance of the training data with different oversampling techniques; and (4) a comparison of the classification performance of different ML algorithms. According to the experimental results, the four proposed strategies are statistically significant for MM detection;
- We combined the DL and ML methods to automatically extract the features directly from the dermoscopy images and perform benign and MM diagnosis. The experimental results show that our proposed model combining metadata, K-means SMOTE, and an extreme gradient boosting (XGB) classifier can achieve higher classification and predictability than using only the MELA-CNN feature extractor.
2. Methods
2.1. MM Dataset
2.2. FE Techniques
- (1)
- Handcraft: We employed five handcrafted characteristics provided by dermatologists [30]: pigment networks; negative networks; streaks; globules; and milia-like cysts. A pigment network is a grid comprising many brown lines crossing each other; a negative network is a curve formed by many hyperpigmented cell connections; a streak comprises pigmented projections surrounding a melanocytic lesion; a globule comprises multiple brown circles; a milia-like cyst comprises many white, yellowish circles or ovals;
- (2)
- VGG16: VGG16 is a DL CNN model proposed by Karen Simonyan et al. [35]. They used the ImageNet dataset of one million images to classify one thousand classes. VGG16 takes 224 × 224 RGB images as the input and comprises 13 convolutional layers and 3 fully connected layers, as well as a nonlinear activation function—rectified linear unit (ReLU). All of the layers used three × three small convolution kernels, to avoid too many parameters. This DL model can automatically extract 512 features from the dermoscopy images;
- (3)
- InceptionV3: InceptionV3 is a CNN-based DL model of the inception series. The inception series includes InceptionV1, InceptionV2, InceptionV3, InceptionV4, and InceptionResNet series. InceptionV3 was proposed by Szegedy et al. [36] as an improved InceptionV2. They used the ImageNet dataset of one million images to classify one thousand classes. InceptionV3 takes 224 × 224 RGB images as input and comprises 47 layers. In addition, this model adopts the batch normalization of InceptionV2 to accelerate the model training. This DL model can automatically extract 2048 features from dermoscopy images;
- (4)
- InceptionResNetV2: InceptionResNetV2 is an Inception module-based DL model. It uses 299 × 299 RGB images as input. In addition, it replaces the pooling layers in the Inception modules A, B, and C, with ResNet connections to accelerate the training [37]. This DL model can automatically extract 1536 features from dermoscopy images;
- (5)
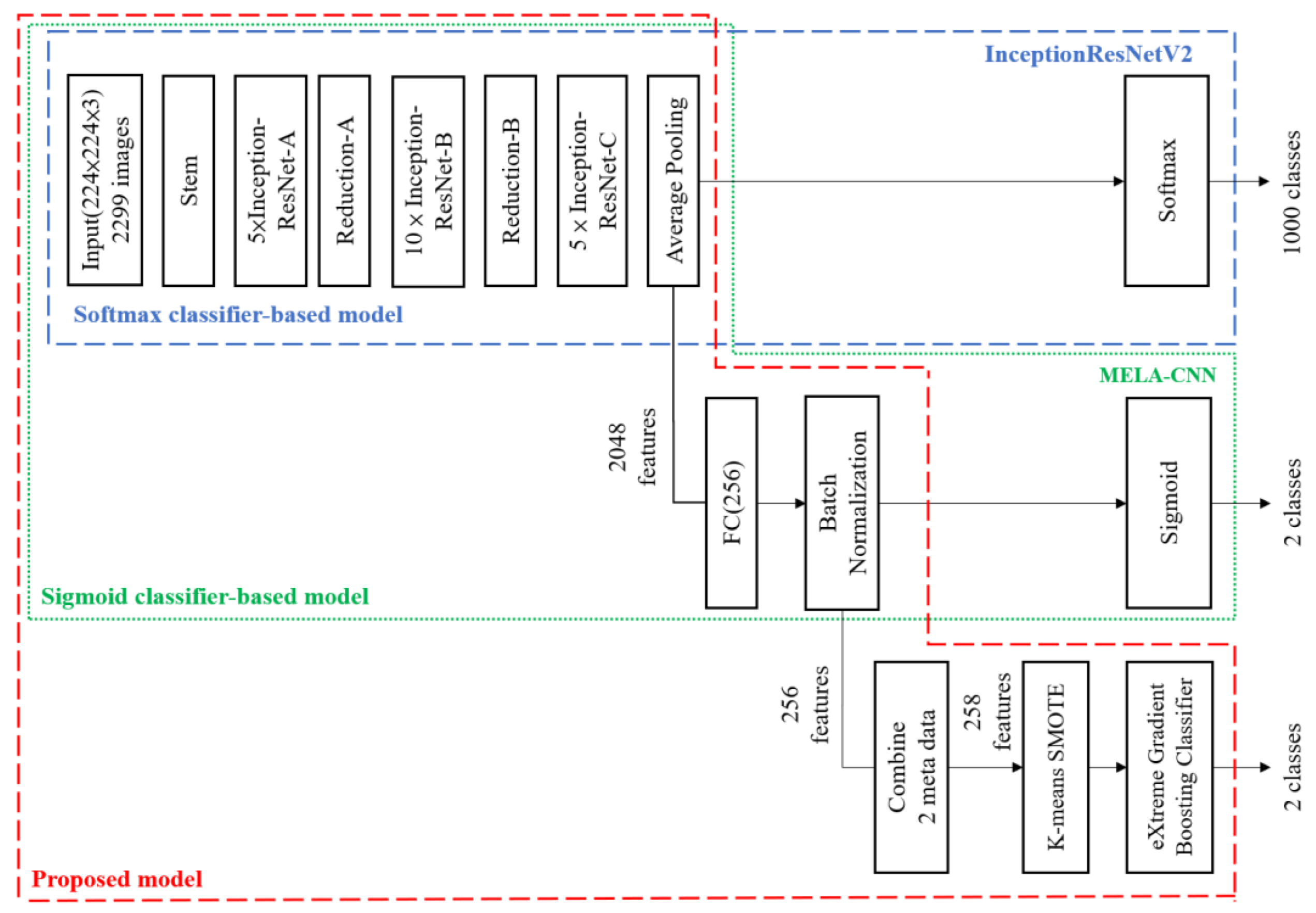
- MELA-CNN: Based on the transfer learning technique [34], we used the InceptionResNetV2 architecture as the backbone to develop MELA-CNN (Figure 1). After retrieving the feature maps of the average pooling layer of InceptionResNetV2, a fully connected layer of 256 nodes is added, and ReLU is used. Further, batch normalization and Sigmoid layers are introduced, and MELA-CNN trained weights are obtained after the fine-tuning process using the target dataset. This DL model can automatically extract 256 features from dermoscopy images.
2.3. SMOTE
2.4. XGB
2.5. Evaluation Metrics
2.6. Stratified K-Fold Validation
2.7. Paired T-Test
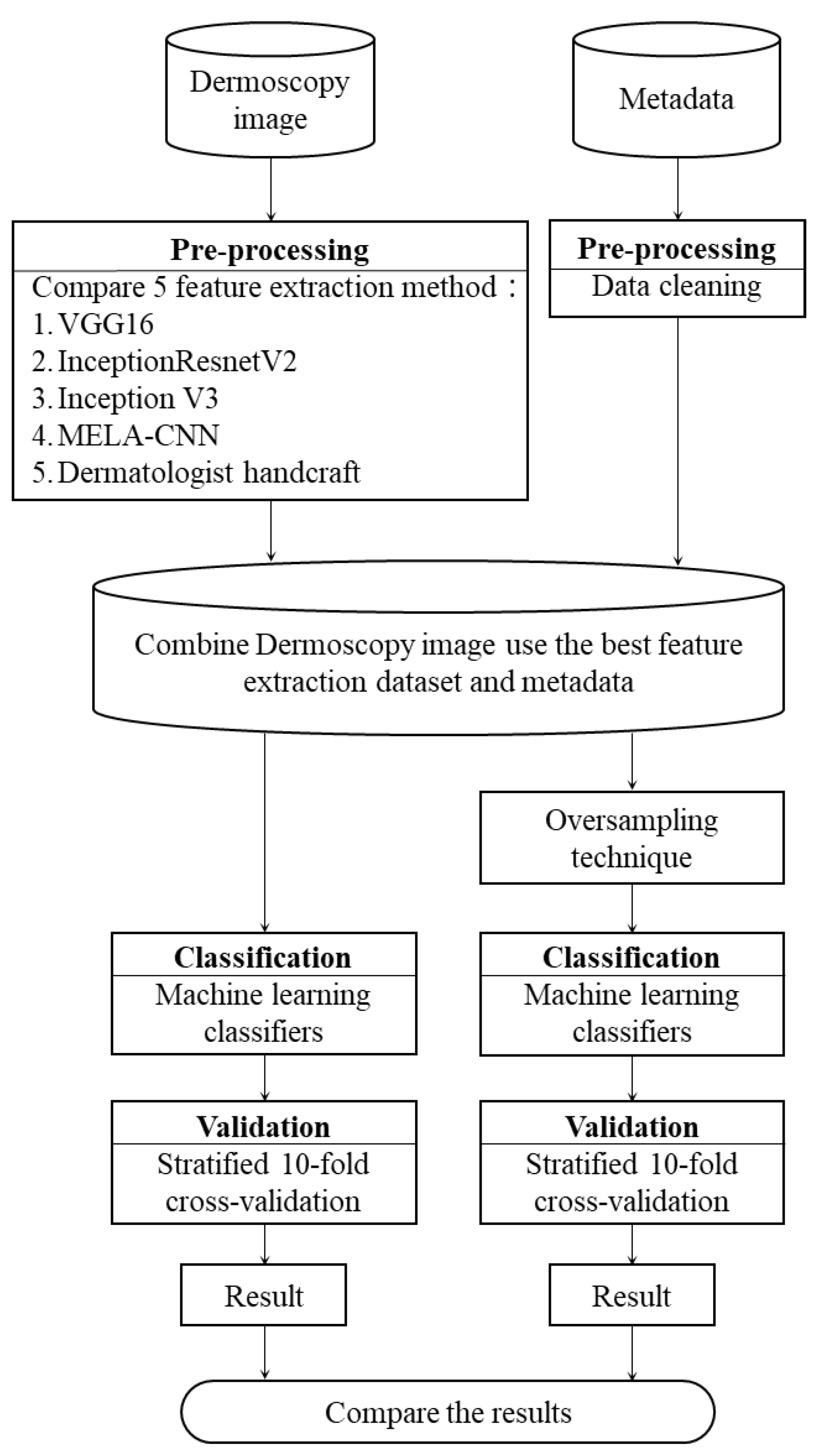
3. Proposed Framework
4. Experimental Result
4.1. FE Techniques
4.2. Metadata
4.3. SMOTE
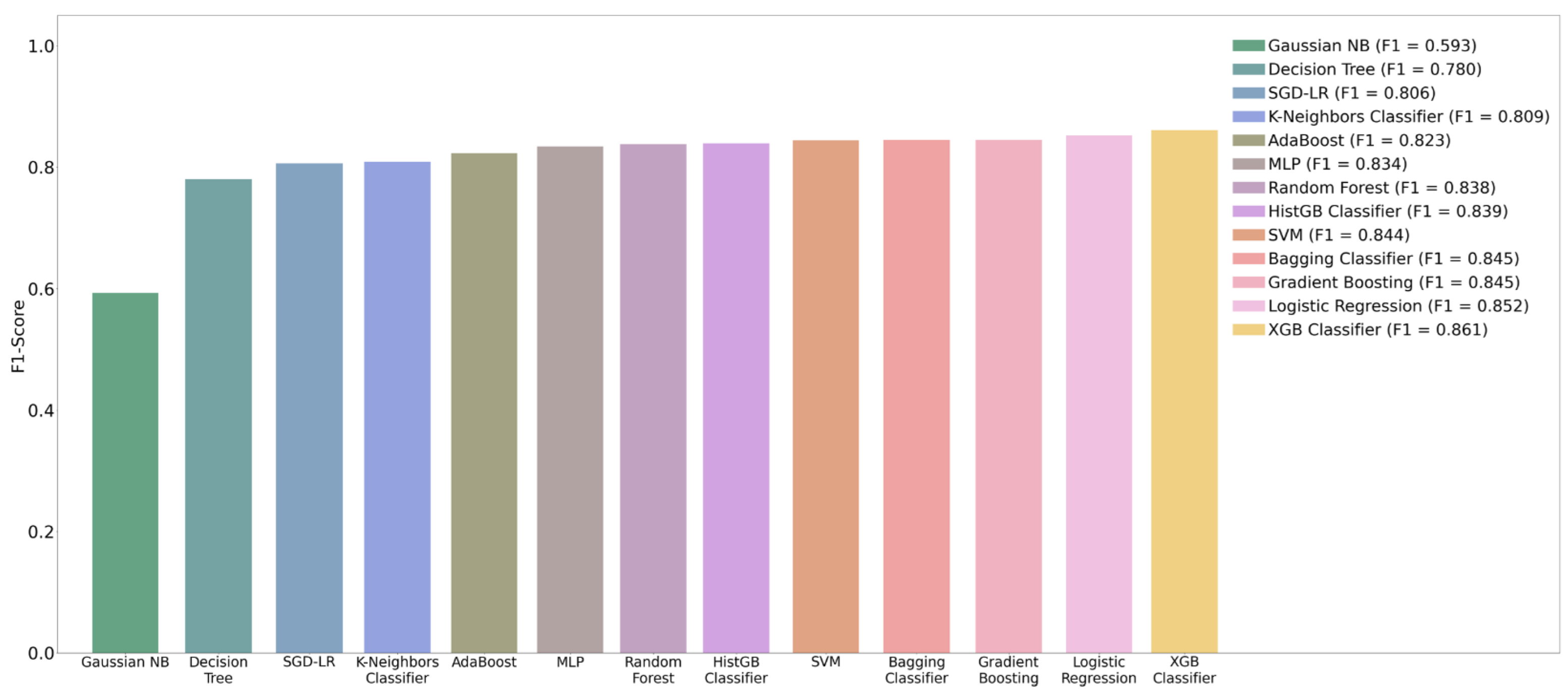
4.4. ML Algorithms (Classifiers)
5. Discussion
5.1. Effect of FE and Metadata
5.2. Effect of Oversampling Techniques
5.3. Effect of ML Algorithms (Classifiers)
5.4. Significance Test for Performance Improvement
5.5. Performance Comparison with Previous Related Studies
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Saginala, K.; Barsouk, A.; Aluru, J.S.; Rawla, P.; Barsouk, A. Epidemiology of Melanoma. Med. Sci. 2021, 9, 63. [Google Scholar] [CrossRef] [PubMed]
- Rigel, D.S.; Carucci, J.A. Malignant melanoma: Prevention, early detection and treatment in the 21st century. CA A Cancer J. Clin. 2000, 50, 215–236. [Google Scholar] [CrossRef] [PubMed]
- Carr, S.; Smith, C.; Wernberg, J. Epidemiology and risk factors of melanoma. Surg. Clin. N. Am. 2020, 100, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Zaenker, P.; Lo, J.; Pearce, R.; Cantwell, P.; Cowell, L.; Lee, M.; Quirk, C.; Law, H.; Gray, E.; Ziman, M. A diagnostic autoantibody signature for primary cutaneous melanoma. Oncotarget 2018, 9, 30539–30551. [Google Scholar] [CrossRef] [Green Version]
- Wong, T.Y.; Bressler, N.M. Artificial intelligence with deep learning technology looks into diabetic retinopathy screening. JAMA 2016, 316, 2366–2367. [Google Scholar] [CrossRef]
- Hosny, A.; Parmar, C.; Quackenbush, J.; Schwartz, L.H.; Aerts, H. Artificial intelligence in radiology. Nat. Rev. Cancer 2018, 18, 500–510. [Google Scholar] [CrossRef]
- Popescu, D.; El-Khatib, M.; El-Khatib, H.; Ichim, L. New Trends in Melanoma Detection Using Neural Networks: A Systematic Review. Sensors 2022, 22, 496. [Google Scholar] [CrossRef]
- Adjed, F.; Safdar Gardezi, S.J.; Ababsa, F.; Faye, I.; Chandra Dass, S. Fusion of structural and textural features for melanoma recognition. IET Comput. Vis. 2018, 12, 185–195. [Google Scholar] [CrossRef]
- Salido, J.A.A.; Ruiz, C.R. Using Deep Learning for Melanoma Detection in Dermoscopy Images. Int. J. Mach. Learn. Comput. 2018, 8, 61–68. [Google Scholar] [CrossRef] [Green Version]
- Warsi, F.; Khanam, R.; Kamya, S.; Suárez-Araujo, C.P. An efficient 3D color-texture feature and neural network technique for melanoma detection. Inform. Med. 2019, 17, 100176. [Google Scholar] [CrossRef]
- El-Khatib, H.; Popescu, D.; Ichim, L. Deep Learning-Based Methods for Automatic Diagnosis of Skin Lesions. Sensors 2020, 20, 1753. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Al-masni, M.A.; Kim, D.H.; Kim, T.S. Multiple skin lesions diagnostics via integrated deep convolutional networks for segmentation and classification. Comput. Methods Progr. Biomed. 2020, 190, 105351. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Shen, L. Skin Lesion Analysis towards Melanoma Detection Using Deep Learning Network. Sensors 2018, 18, 556. [Google Scholar] [CrossRef] [Green Version]
- Iqbal, I.; Younus, M.; Walayat, K.; Kakar, M.U.; Ma, J.W. Automated multi-class classification of skin lesions through deep convolutional neural network with dermoscopic images. Comput. Med. Imaging Graph. 2021, 88. [Google Scholar] [CrossRef]
- Li, X.; Wu, J.; Jiang, H.; Chen, E.Z.; Dong, X.; Rong, R. Skin Lesion Classification Via Combining Deep Learning Features and Clinical Criteria Representations. bioRxiv 2018. [Google Scholar]
- Gessert, N.; Sentkerac, T.; Madestaac, F.; Schmitz, R.; Kniepag, H.; Baltruschataef, I.; Werner, R.; Schlaeferb, A. Skin Lesion Diagnosis using Ensembles, Unscaled Multi-Crop Evaluation and Loss Weighting. arXiv 2018, arXiv:1808.01694. [Google Scholar]
- Bissoto, A.; Perez, F.; Ribeiro, V.; Fornaciali, M.; Avila, S.; Valle, E. Deep-Learning Ensembles for Skin-Lesion Segmentation, Analysis, Classification: RECOD Titans at ISIC Challenge 2018. arXiv 2018, arXiv:1808.08480. [Google Scholar]
- Zhuang, J.; Li, W.; Manivannan, S.; Wang, R.; Zhang, J.; Liu, J.; Pan, J.; Jiang, G.; Yin, Z. Skin Lesion Analysis Towards Melanoma Detection Using Deep Neural Network Ensemble. ISIC Chall. 2018, 1–6. [Google Scholar]
- Almaraz-Damian, J.A.; Ponomaryov, V.; Sadovnychiy, S.; Castillejos-Fernandez, H. Melanoma and Nevus Skin Lesion Classification Using Handcraft and Deep Learning Feature Fusion via Mutual Information Measures. Entropy 2020, 22, 484. [Google Scholar] [CrossRef] [Green Version]
- Gong, A.; Yao, X.; Lin, W. Classification for Dermoscopy Images Using Convolutional Neural Networks Based on the Ensemble of Individual Advantage and Group Decision. IEEE Access 2020, 8, 155337–155351. [Google Scholar] [CrossRef]
- Lucius, M.; De All, J.; De All, J.A.; Belvisi, M.; Radizza, L.; Lanfranconi, M.; Lorenzatti, V.; Galmarini, C.M. Deep Neural Frameworks Improve the Accuracy of General Practitioners in the Classification of Pigmented Skin Lesions. Diagnostics 2020, 10, 969. [Google Scholar] [CrossRef]
- Adegun, A.; Viriri, S. Deep Learning Model for Skin Lesion Segmentation: Fully Convolutional Network; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 232–242. [Google Scholar]
- Alfi, I.A.; Rahman, M.M.; Shorfuzzaman, M.; Nazir, A. A Non-Invasive Interpretable Diagnosis of Melanoma Skin Cancer Using Deep Learning and Ensemble Stacking of Machine Learning Models. Diagnostics 2022, 12, 726. [Google Scholar] [CrossRef] [PubMed]
- Abbes, W.; Sellami, D. Deep Neural Network for Fuzzy Automatic Melanoma Diagnosis; Science and Technology Publications: Setúbal, Portugal, 2019; pp. 47–56. [Google Scholar]
- Abbas, Q.; Celebi, M.E. DermoDeep-A classification of melanoma-nevus skin lesions using multi-feature fusion of visual features and deep neural network. Multimed. Tools Appl. 2019, 78, 23559–23580. [Google Scholar] [CrossRef]
- Nasr-Esfahani, E.; Samavi, S.; Karimi, N.; Soroushmehr, S.M.; Jafari, M.H.; Ward, K.; Najarian, K. Melanoma detection by analysis of clinical images using convolutional neural network. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 1373–1376. [Google Scholar] [CrossRef]
- Harangi, B. Skin lesion classification with ensembles of deep convolutional neural networks. J. Biomed. Inform. 2018, 86, 25–32. [Google Scholar] [CrossRef] [PubMed]
- Kalwa, U.; Legner, C.; Kong, T.; Pandey, S. Skin cancer diagnostics with an all-inclusive smartphone application. Symmetry 2019, 11, 790. [Google Scholar] [CrossRef] [Green Version]
- Magalhaes, C.; Tavares, J.M.R.; Mendes, J.; Vardasca, R. Comparison of machine learning strategies for infrared thermography of skin cancer. Biomed. Signal Proc. Control. Proc. 2021, 69, 102872. [Google Scholar] [CrossRef]
- Codella, N.; Rotemberg, V.; Tschandl, P.; Celebi, M.E.; Dusza, S.; Gutman, D.; Helba, B.; Kalloo, A.; Liopyris, K.; Marchetti, M. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (ISIC). arXiv 2018, arXiv:03368. [Google Scholar]
- Tschandl, P.; Rosendahl, C.; Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data 2018, 5, 180161. [Google Scholar] [CrossRef]
- Codella, N.C.; Gutman, D.; Celebi, M.E.; Helba, B.; Marchetti, M.A.; Dusza, S.W.; Kalloo, A.; Liopyris, K.; Mishra, N.; Kittler, H. Skin lesion analysis toward melanoma detection: A challenge at the 2017 international symposium on biomedical imaging (isbi), hosted by the international skin imaging collaboration (isic). In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 168–172. [Google Scholar]
- Combalia, M.; Codella, N.C.; Rotemberg, V.; Helba, B.; Vilaplana, V.; Reiter, O.; Carrera, C.; Barreiro, A.; Halpern, A.C.; Puig, S. Bcn20000: Dermoscopic lesions in the wild. arXiv 2019, arXiv:1908.02288. [Google Scholar]
- Fan, J.; Lee, J.; Lee, Y. A Transfer Learning Architecture Based on a Support Vector Machine for Histopathology Image Classification. Appl. Sci. 2021, 11, 6380. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Douzas, G.; Bacao, F.; Last, F. Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE. Inf. Sci. 2018, 465, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Tianqi Chen, C.G. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Bisla, D.; Choromanska, A.; Berman, R.S.; Stein, J.A.; Polsky, D. Towards Automated Melanoma Detection with Deep Learning: Data Purification and Augmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 2720–2728. [Google Scholar]
- Daghrir, J.; Tlig, L.; Bouchouicha, M.; Sayadi, M. Melanoma skin cancer detection using deep learning and classical machine learning techniques: A hybrid approach. In Proceedings of the 2020 5th International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Sfax, Tunisia, 2–5 September 2020; pp. 1–5. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Dataset | AUC | ACC | SEN | SPE | PRE | F1 |
|---|---|---|---|---|---|---|---|
| [8,9,10] | PH2 | NA | 0.861~0.975 | 0.790~0.981 | 0.925~0.938 | NA | NA |
| [11] | Subset of PH2 | NA | 0.950 | 0.925 | 0.966 | NA | NA |
| [12] | ISIC 2016 | 0.766 | 0.818 | 0.818 | 0.714 | NA | 0.826 |
| [12,13,14] | ISIC 2017 | 0.870~0.964 | 0.857~0.933 | 0.490~0.933 | 0.872~0.961 | 0.940 | 0.813~0.935 |
| [14,15,16,17,18,19,20,21] | ISIC 2018 | 0.847~0.989 | 0.803~0.931 | 0.484~0.888 | 0.957~0.978 | 0.860~0.905 | 0.491~0.891 |
| [22,23] | Subset of ISIC 2018 | 0.970 | 0.880~0.910 | 0.920~0.960 | NA | 0.840~0.910 | 0.880~0.910 |
| [14,20] | ISIC 2019 | 0.919~0.991 | 0.896~0.924 | 0.483~0.896 | 0.976~0.977 | 0.907 | 0.488~0.898 |
| [11] | Subset of ISIC 2019 | NA | 0.930 | 0.925 | 0.933 | NA | NA |
| [16,17,24,25] | Combined | 0.880~0.960 | 0.803~0.950 | 0.851~0.930 | 0.844~0.950 | NA | NA |
| [26] | MED-NODE | 0.810 | NA | 0.810 | 0.800 | NA | NA |
| [27] | Subset of ISBI 2017 | 0.891 | 0.866 | 0.556 | 0.785 | NA | NA |
| NA = Metrics not mentioned in the paper | |||||||
| Feature Extract | Features | ACC | PRE | REC | AUC | F1 |
|---|---|---|---|---|---|---|
| Handcrafted | 5 | 0.800 | 0.401 | 0.036 | 0.613 | 0.064 |
| MELA-CNN | 256 | 0.913 | 0.837 | 0.693 | 0.830 | 0.756 |
| VGG16 | 512 | 0.814 | 0.569 | 0.189 | 0.738 | 0.282 |
| InceptionResnet V2 | 1536 | 0.822 | 0.655 | 0.204 | 0.752 | 0.309 |
| Inception V3 | 2048 | 0.819 | 0.641 | 0.198 | 0.746 | 0.295 |
| Features | ACC | PRE | REC | AUC | F1 |
|---|---|---|---|---|---|
| 5 | 0.800 | 0.401 | 0.036 | 0.613 | 0.064 |
| 7 | 0.821 | 0.582 | 0.327 | 0.789 | 0.415 |
| 256 | 0.913 | 0.837 | 0.693 | 0.830 | 0.756 |
| 258 | 0.926 | 0.844 | 0.764 | 0.865 | 0.800 |
| Oversampling Technique | ACC | PRE | REC | AUC | F1 |
|---|---|---|---|---|---|
| Original | 0.926 | 0.844 | 0.764 | 0.864 | 0.800 |
| K-Means SMOTE | 0.946 | 0.873 | 0.853 | 0.970 | 0.861 |
| RandomOverSampler | 0.939 | 0.862 | 0.822 | 0.964 | 0.840 |
| SMOTE | 0.937 | 0.833 | 0.849 | 0.966 | 0.839 |
| SVMSMOTE | 0.934 | 0.825 | 0.851 | 0.967 | 0.835 |
| SMOTETomek | 0.934 | 0.829 | 0.844 | 0.967 | 0.835 |
| BorderlineSMOTE | 0.933 | 0.811 | 0.862 | 0.967 | 0.834 |
| SMOTE- RandomUnderSampler | 0.933 | 0.821 | 0.844 | 0.966 | 0.831 |
| SMOTENC | 0.932 | 0.820 | 0.849 | 0.968 | 0.830 |
| SMOTEENN | 0.924 | 0.770 | 0.889 | 0.967 | 0.822 |
| ADASYN | 0.924 | 0.788 | 0.847 | 0.966 | 0.814 |
| Classifiers | ACC | PRE | REC | AUC | F1 |
|---|---|---|---|---|---|
| XGB Classifier | 0.946 | 0.873 | 0.853 | 0.970 | 0.861 |
| Logistic Regression | 0.941 | 0.841 | 0.864 | 0.969 | 0.852 |
| Gradient Boosting | 0.940 | 0.851 | 0.842 | 0.965 | 0.845 |
| Bagging Classifier | 0.939 | 0.837 | 0.851 | 0.965 | 0.845 |
| SVM | 0.939 | 0.859 | 0.833 | 0.968 | 0.844 |
| HistGB Classifier | 0.939 | 0.861 | 0.822 | 0.968 | 0.839 |
| Random Forest | 0.936 | 0.837 | 0.842 | 0.964 | 0.838 |
| MLP | 0.937 | 0.862 | 0.811 | 0.963 | 0.834 |
| AdaBoost | 0.929 | 0.806 | 0.844 | 0.961 | 0.823 |
| K-Neighbors Classifier | 0.925 | 0.808 | 0.816 | 0.922 | 0.809 |
| SGD-LR | 0.922 | 0.783 | 0.836 | 0.956 | 0.806 |
| Decision Tree | 0.911 | 0.759 | 0.804 | 0.871 | 0.780 |
| Gaussian NB | 0.766 | 0.452 | 0.867 | 0.846 | 0.593 |
| Fold | 5 Features REC | 256 Features REC | Difference between REC | Paired t-Test |
|---|---|---|---|---|
| 1 | 0.022 | 0.578 | 0.556 | p = 1.81 × 10−9 Average difference between REC 0.658 |
| 2 | 0.111 | 0.622 | 0.511 | |
| 3 | 0.044 | 0.756 | 0.712 | |
| 4 | 0.044 | 0.644 | 0.600 | |
| 5 | 0.044 | 0.800 | 0.756 | |
| 6 | 0.044 | 0.600 | 0.556 | |
| 7 | 0.000 | 0.733 | 0.733 | |
| 8 | 0.022 | 0.689 | 0.667 | |
| 9 | 0.000 | 0.756 | 0.756 | |
| 10 | 0.022 | 0.756 | 0.734 |
| Fold | 256 Features REC | 258 Feature REC | Difference between REC | Paired t-Test |
|---|---|---|---|---|
| 1 | 0.578 | 0.844 | 0.267 | p = 2.03 × 10−2 Average difference between REC 0.071 |
| 2 | 0.622 | 0.756 | 0.133 | |
| 3 | 0.756 | 0.778 | 0.022 | |
| 4 | 0.644 | 0.644 | 0.000 | |
| 5 | 0.800 | 0.778 | −0.022 | |
| 6 | 0.600 | 0.756 | 0.156 | |
| 7 | 0.733 | 0.733 | 0.000 | |
| 8 | 0.689 | 0.778 | 0.089 | |
| 9 | 0.756 | 0.733 | −0.022 | |
| 10 | 0.756 | 0.844 | 0.089 |
| Fold | 258 Features REC | 258 Features with K-Means SMOTE REC | Difference between REC | Paired t-Test |
|---|---|---|---|---|
| 1 | 0.844 | 0.933 | 0.089 | p = 7.07 × 10−4 Average difference between REC 0.089 |
| 2 | 0.756 | 0.867 | 0.111 | |
| 3 | 0.778 | 0.778 | 0.000 | |
| 4 | 0.644 | 0.844 | 0.200 | |
| 5 | 0.778 | 0.911 | 0.133 | |
| 6 | 0.756 | 0.889 | 0.133 | |
| 7 | 0.733 | 0.844 | 0.111 | |
| 8 | 0.778 | 0.800 | 0.022 | |
| 9 | 0.733 | 0.800 | 0.067 | |
| 10 | 0.844 | 0.867 | 0.022 |
| Fold | 5 Features F1 | 256 Features F1 | Difference between F1 | Paired t-Test |
|---|---|---|---|---|
| 1 | 0.042 | 0.658 | 0.616 | p = 4.56 × 10−10 Average difference between F1 0.692 |
| 2 | 0.185 | 0.718 | 0.533 | |
| 3 | 0.083 | 0.810 | 0.727 | |
| 4 | 0.083 | 0.773 | 0.690 | |
| 5 | 0.083 | 0.818 | 0.735 | |
| 6 | 0.077 | 0.692 | 0.615 | |
| 7 | 0.000 | 0.767 | 0.767 | |
| 8 | 0.042 | 0.713 | 0.671 | |
| 9 | 0.000 | 0.810 | 0.810 | |
| 10 | 0.043 | 0.800 | 0.757 |
| Fold | 256 Features F1 | 258 Features F1 | Difference between F1 | Paired t-Test |
|---|---|---|---|---|
| 1 | 0.658 | 0.826 | 0.168 | p = 3.40 × 10−2 Average difference between F1 0.040 |
| 2 | 0.718 | 0.791 | 0.073 | |
| 3 | 0.810 | 0.833 | 0.024 | |
| 4 | 0.773 | 0.734 | −0.039 | |
| 5 | 0.818 | 0.795 | −0.023 | |
| 6 | 0.692 | 0.810 | 0.117 | |
| 7 | 0.767 | 0.759 | −0.009 | |
| 8 | 0.713 | 0.814 | 0.101 | |
| 9 | 0.810 | 0.815 | 0.005 | |
| 10 | 0.800 | 0.826 | 0.026 |
| Fold | 258 Features F1 | 258 Features with K-Means SMOTE F1 | Difference between F1 | Paired t-Test |
|---|---|---|---|---|
| 1 | 0.826 | 0.913 | 0.087 | p = 3.35 × 10−4 Average difference between F1 0.061 |
| 2 | 0.791 | 0.813 | 0.022 | |
| 3 | 0.833 | 0.843 | 0.010 | |
| 4 | 0.734 | 0.874 | 0.139 | |
| 5 | 0.795 | 0.891 | 0.096 | |
| 6 | 0.810 | 0.870 | 0.060 | |
| 7 | 0.759 | 0.817 | 0.059 | |
| 8 | 0.814 | 0.857 | 0.043 | |
| 9 | 0.815 | 0.857 | 0.042 | |
| 10 | 0.826 | 0.876 | 0.050 |
| Kalwa et al. (2019) [28] | Proposed Model | ||||||
|---|---|---|---|---|---|---|---|
| SVM (Kernel = RBF) | XGB Classifier | ||||||
| Holdout (7:3) | Holdout (7:3) | ||||||
| Original | SMOTE | Handcrafted | DL-TL | DL-FE | DL-FE+ Metadata | K-Means SMOTE | |
| Number of samples | 200 | 2299 | |||||
| Number of features | 4 | 4 | 5 | 1536 | 256 | 258 | 258 |
| ACC | 0.860 | 0.880 | 0.804 | 0.836 | 0.914 | 0.923 | 0.958 |
| AUC | 0.720 | 0.850 | 0.585 | 0.780 | 0.936 | 0.948 | 0.971 |
| PRE | 0.125 | 0.667 | 0.500 | 0.720 | 0.806 | 0.820 | 0.914 |
| REC | 0.500 | 0.800 | 0.030 | 0.267 | 0.741 | 0.778 | 0.867 |
| F1 | 0.200 | 0.727 | 0.056 | 0.389 | 0.772 | 0.798 | 0.890 |
| Magalhaes et al. (2021) [29] | Proposed Model | ||||||
|---|---|---|---|---|---|---|---|
| SVM + Random Forest | XGB Classifier | ||||||
| Holdout (8:2) | Holdout (8:2) | ||||||
| Original | SMOTE | Handcrafted | DL-TL | DL-FE | DL-FE+ Metadata | K-Means SMOTE | |
| Number of samples | 287 | 2299 | |||||
| Number of features | 40 | 40 | 5 | 1536 | 256 | 258 | 258 |
| ACC | 0.426 | 0.585 | 0.807 | 0.839 | 0.904 | 0.930 | 0.965 |
| AUC | 0.558 | 0.542 | 0.621 | 0.774 | 0.937 | 0.953 | 0.981 |
| PRE | 0.565 | 0.672 | 0.600 | 0.767 | 0.774 | 0.837 | 0.974 |
| REC | 0.473 | 0.696 | 0.033 | 0.256 | 0.722 | 0.800 | 0.878 |
| F1 | 0.515 | 0.684 | 0.063 | 0.383 | 0.747 | 0.818 | 0.905 |
| Year | Author | Dataset | Non-Me: Me (IR) | Method | Validation | Test Result |
|---|---|---|---|---|---|---|
| 2016 | Nasr et al. [26] | MED-NODE | 100:70 (1.429) | DL | Holdout (8:2) full: 7650 | ACC: 0.810 SE: 0.810 SP: 0.800 |
| 2018 | Adjed et al. [8] | PH2 | 160:40 (4) | Multiresolution technique + ML | Repeat 1000 times Holdout (7:3) full: 200 | ACC: 0.861 SE: 0.790 SP: 0.933 |
| 2018 | Li et al. [15] | ISIC 2018 | 8902:1113 (7.998) | DL + ML | Holdout (7:1:2) full: 10015 | ACC: 0.853 PRE: 0.860 REC: 0.850 F1: 0.860 |
| 2019 | Devansh et al. [41] | Combine of ISIC 2017, Edinburgh data, ISIC 2018, PH2 | 3063:919 (3.333) | DL | Holdout (85:15) full: 3982 | AUC: 0.880 |
| 2019 | Warsi et al. [10] | PH2 | 160:40 (4) | 3D color-texture feature (CTF) + DL | Holdout (70:15:15) full: 200 | ACC: 0.970 SE: 0.981 SP: 0.925 |
| 2019 | Abbes et al. [24] | Combine of DermQuest and DermIS | 87:119 (0.731) | FCM + DL | Holdout (NA) full: 206 | ACC: 0.875 SE: 0.901 SP: 0.844 |
| 2019 | Abbas et al. [25] | Subset of combining Skin-EDRA, ISIC 2018, DermNet, PH2 | 1420:1380 (1.029) | DL + ML | Holdout (1:1) full: 2800 | ACC: 0.950 AUC: 0.960 SE: 0.930 SP: 0.950 |
| 2020 | Almaraz-Damian et al. [19] | ISIC 2018 | 8902:1113 (7.998) | DL + ML | Holdout (75:25) full: 10015 | ACC: 0.897 |
| 2020 | Daghrir et al. [42] | Subset of ISIC archive | NA | DL+ML | Holdout (8:2) full: 640 | ACC: 0.884 |
| 2022 | Iftiaz A. Alf et al. [23] | Subset of ISIC 2018 | 1800:1497 (1.202) | DL and ML | Holdout (8:2) full: 3297 | DL ACC: 0.910 PRE: 0.910 REC: 0.920 AUC: 0.970 F1: 0.910 ML ACC: 0.880 PRE: 0.840 REC: 0.920 F1: 0.880 |
| 2022 | Our approach (Holdout 8:2) | Subset of combining ISIC 2018 and ISIC 2019 | 1849:450 (4.109) | DL + ML | Holdout (8:2) full: 2299 | ACC: 0.965 PRE: 0.974 REC: 0.878 AUC: 0.981 F1: 0.905 |
| 2022 | Our approach (Stratified 10-fold Cross Validation) | Subset of combining ISIC 2018 and ISIC 2019 | 1849:450 (4.109) | DL + ML | Stratified 10-fold Cross-Validation full: 2299 | ACC: 0.941 PRE: 0.870 REC: 0.822 AUC: 0.968 F1: 0.844 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, C.-C.; Li, Y.-Z.; Wu, H.-C.; Tseng, M.-H. Melanoma Detection Using XGB Classifier Combined with Feature Extraction and K-Means SMOTE Techniques. Diagnostics 2022, 12, 1747. https://doi.org/10.3390/diagnostics12071747
Chang C-C, Li Y-Z, Wu H-C, Tseng M-H. Melanoma Detection Using XGB Classifier Combined with Feature Extraction and K-Means SMOTE Techniques. Diagnostics. 2022; 12(7):1747. https://doi.org/10.3390/diagnostics12071747
Chicago/Turabian StyleChang, Chih-Chi, Yu-Zhen Li, Hui-Ching Wu, and Ming-Hseng Tseng. 2022. "Melanoma Detection Using XGB Classifier Combined with Feature Extraction and K-Means SMOTE Techniques" Diagnostics 12, no. 7: 1747. https://doi.org/10.3390/diagnostics12071747
APA StyleChang, C. -C., Li, Y. -Z., Wu, H. -C., & Tseng, M. -H. (2022). Melanoma Detection Using XGB Classifier Combined with Feature Extraction and K-Means SMOTE Techniques. Diagnostics, 12(7), 1747. https://doi.org/10.3390/diagnostics12071747