Abstract
In the modern world, new technologies such as artificial intelligence, machine learning, and big data are essential to support healthcare surveillance systems, especially for monitoring confirmed cases of monkeypox. The statistics of infected and uninfected people worldwide contribute to the growing number of publicly available datasets that can be used to predict early-stage confirmed cases of monkeypox through machine-learning models. Thus, this paper proposes a novel filtering and combination technique for accurate short-term forecasts of infected monkeypox cases. To this end, we first filter the original time series of the cumulative confirmed cases into two new subseries: the long-term trend series and residual series, using the two proposed and one benchmark filter. Then, we predict the filtered subseries using five standard machine learning models and all their possible combination models. Hence, we combine individual forecasting models directly to obtain a final forecast for newly infected cases one day ahead. Four mean errors and a statistical test are performed to verify the proposed methodology’s performance. The experimental results show the efficiency and accuracy of the proposed forecasting methodology. To prove the superiority of the proposed approach, four different time series and five different machine learning models were included as benchmarks. The results of this comparison confirmed the dominance of the proposed method. Finally, based on the best combination model, we achieved a forecast of fourteen days (two weeks). This can help to understand the spread and lead to an understanding of the risk, which can be utilized to prevent further spread and enable timely and effective treatment.
1. Introduction
In today’s world, humans have made incredible advances in the fields of science, technology, and artificial intelligence (AI) by inventing remote-controlled drones, automated responsive robots, and self-driving cars. However, they continue to face numerous natural disasters challenges, such as floods, earthquakes, and droughts, as well as novel viral diseases, including the coronavirus infectious disease 2019 (COVID-19) and the monkeypox virus (MV). The COVID-19 pandemic was one of the worst disasters in human history and caused 6.8 million deaths around the world as of 17 February 2023 [1]. Moreover, it is on the decline and is in the endemic phase, while the world is about to face another crisis in the form of a new viral disease outbreak of MV. MV is transmitted from one human to another through physical contact with the one who is infected, with contaminated matter, or with infected animals. The symptoms of MV include a rash on the skin, a mucosal lesion, muscle aches, headaches, back pain, fever, low energy, swollen lymph nodes, and a fever that can last for around 2 to 4 weeks. It can be difficult to identify and distinguish MV due to its similarity to other infectious diseases. It is important to differentiate MV from chickenpox, bacterial skin infections, capsules, herpes, scabies, other sexually transmitted infections, and medicine-related allergies. Therefore, diagnostic tests are necessary to distinguish it from other similar diseases, to obtain treatment as soon as possible, and to stop the spread. The most preferred laboratory diagnostic test for MV is the detection of viral DNA by polymerase chain reaction. MV is an infectious disease caused by the MV, a species of the Orthopoxvirus genus and a causative agent of smallpox. There are two different clades of MV: Clade I and Clade II. MV was first detected in Copenhagen, Denmark, in 1958 [2,3].
Meanwhile, the first formally documented case was observed in a nine-year-old child in the Democratic Republic of the Congo (DRC) in 1970 [4,5]. Initially, the MV outbreak was limited to the continent of Africa but gradually spread to North America and Europe. Furthermore, confirmed MV cases were recorded in African countries, including one case in Cote d’Ivoire, one in Cameroon, three cases in Nigeria, four in Liberia, and thirty-eight in Congo, between 1970 and 1979. In the year 1986, the total confirmed cases reached 400, with a 10% mortality rate. Moreover, between 1991 and 1999, some small outbreaks were also observed in West Africa and the equatorial central region, and Congo alone observed 500 cases. After that, the continent of Africa witnessed a decline and an endemic stage of the MV outbreak [6,7]. Since 2005, thousands of suspected MV infectious cases have been recorded every year in the DRC. In 2017, MV re-emerged and spread among the people of Nigeria through travelers across the country. However, in May 2022, the sudden increase and rapid spread of the MV outbreak were seen across Europe, America, and all six regions of the WHO, with the reporting of around 87 thousand confirmed cases and 112 deaths in 110 countries. This variant of MV was due to Clade I of MV, and it was detected in a refugee camp in the Republic of Sudan. Later, many countries on different continents, including Asia, Australia, Africa, South America, North America, and Europe, witnessed the same outbreak of MV.
The MV outbreak was declared a “public health emergency of international concern” (PHEIC) by the World Health Organization (WHO) after reporting 82,000 confirmed cases on 23 July 2022 [8]. Recently, the multi-country MV outbreak has attracted global attention, as a cumulative total of 86,017 confirmed cases and 97 deaths have been reported as of 17 February 2023, worldwide in over 111 countries [9,10]. On 11 May 2023, the WHO declared that the emergence of the MV outbreak of international concern in multi-countries is over [11]. The WHO also published a response plan and guidance documents on strategic preparedness to curb the spread of MV. The proper diagnostics, surveillance, risk management, and engagement of the community are most important to stop the spread and eliminate the human-to-human spread of MV. MV poses a major threat to global health and the economy due to the non-availability of a dedicated vaccine, cure, and on-time detection; therefore, it needs community awareness, the education of health workers, and timely forecasting to prevent its spread [12]. For this purpose, time series and machine learning models are needed for modeling and forecasting the daily cumulative deaths and confirmed cases of MV to assist governments and stakeholders in controlling the spread.
In the past, several statistical and machine learning (ML) models have been widely used by researchers for the prediction of various diseases and pandemics [13,14,15,16,17,18,19]. There has been tremendous progress in the use of AI tools to detect, diagnose, and classify diseases [20,21]. Hence, it is possible to implement AI models for the disease classification, monitoring, and forecasting of MV outbreaks [22,23]. The researchers in [24] comparatively evaluated the performance of machine-learning-based multilayer perception models (MLP) and (autoregressive integrated moving average) ARIMA models for the forecasting of the cumulative confirmed cases of MV and found that MLP with a sigmoid function outperformed the traditional ARIMA model in forecasting the actual cases of MV. Further, the human historical monkeypox cases were used for the prediction of the MV transmission rate by the application of stack ensemble learning (SEL) and ML techniques including random forest, adaptive boosting regression (Adaboost), and gradient boosting (Gboost). The experimental results revealed that the SEL outperformed the other used algorithms [25]. For seven-day forecasting of MV cases in the USA, the five ML and time series models, including ARIMA, long short-term memory (LSTM), prophet, neural prophet, and a stacking model, were used, and 95% accuracy was achieved in the neural prophet output [26]. The researchers in [27] proposed an optimized hybrid deep learning approach based on the Al-Biruni earth-radius-based (BER) optimization technique and an optimized LSTM for forecasting confirmed cases of MV outbreaks with high accuracy and low error. Furthermore, researchers have analyzed the spread of MV across multiple countries by using various ML models, including linear regression (LR), random forest (RF), elastic net regression (EN), convolutional neural network (CNN), and artificial neural network (ANN), and found the CNN outperformed the other methods used in forecasting MV outbreaks. They have also used time series models, ARIMA, and seasonal autoregressive integrated moving averages (SARIMA) to measure the events’ occurrence over time [28]. In further studies, the ARIMA and feedforward neural network (FFNN) were used for the daily confirmed and death cases of MV outbreaks for the next two months; their forecasted estimates were around 87,276 confirmed and 94 deaths up to 31 January 2023, with a 95% confidence interval [29]. The authors in [30] performed the sentiment analysis of tweets related to the illness of MV by analyzing the three possible responses of positive, negative, and neutral with 94% accuracy via the proposed hybrid deep learning approach based on CNN-LSTM. The researchers in [31] conducted a study for a short-term forecast for 10 weeks of calibration by applying n-sub-epidemic models and found an accurate prediction of the declining trend in MPV cases globally and country-specific cases in the last subsequent period of ten days. Their findings also revealed that the population with behavioral modifications and increased immunity were at higher risk of being affected by viruses. Further, the authors in [32] implemented a lag-correlation analysis, a gradient causality test, and a vector autoregression model to forecast the monkeypox epidemic in 20 countries and found a robust association between 13 days of priority and daily confirmed cases globally.
In this paper, we propose a novel filtering and combination technique for the accurate and efficient short-term forecasting of cumulative confirmed cases of MV. The proposed methodology is based on various filters and machine learning models. The steps of the proposed methodology are as follows: First, we decompose the original time series of the cumulative confirmed cases into new subseries, that is, the long-term trend series and residual series, using the two proposed and one benchmark filter, including the regression spline filter (RSF), smoothing spline filter (SSF), and the Hodrick–Prescott filter (HPF). Then, to predict the decomposed subseries, we consider five well-known machine learning models, including artificial neural network (ANN), support vector machine with two kernels (linear (SVM1) and spline (SVM2)), random forest (RF), decision tree learning (DT), and all their possible combination models. Hence, we combine the individual predictive models directly to obtain the final predictions one day ahead of the cumulatively infected cases of MV. The contributions of this work can be summarized as follows: A novel filtering and combination approach is proposed based on different filters and various combinations of ML models to improve the accuracy of the MV-confirmed-case day-ahead forecasts. First, we verify the performance of the proposed filters compared to the standard benchmark filter method using accuracy measures and a statistical test. Second, within the proposed methodology, we compare the performance of the different combinations of the considered machine learning models using two proposed filters and a benchmark filter. Third, the proposed final combination model is compared with the standard time series and the ML models, and the comparative results are noted. The noted results showed that the proposed final model is highly accurate and efficient for forecasting the daily confirmed cases of MV as compared to the benchmark models. Finally, the proposed methodology can be generalized and tested for other datasets.
The rest of the paper is organized as follows: Section 2 describes the general procedure of the proposed filtering and combination forecasting methodology. Section 3 provides an empirical application of the proposed modeling framework using the daily cumulative time series of the MV. Section 4 comprises a discussion of the proposed best combination model versus some of the best time series and machine learning models. Finally, Section 5 addresses the concluding remarks and future research directions.
2. The Proposed Filtering and Combination Technique
This section explains the proposed filtering and combination forecasting technique for the short-term cumulative confirmed cases forecast. To achieve this, the time series of the cumulative confirmed cases () is decomposed into two subseries: the long-term nonlinear trend () and a residual subseries () using two new proposed filters and a considered benchmark filter, including the regression spline filter, the smoothing spline filter, and the Hodrick–Prescott Filter. The mathematical representation of the decomposed subsequence is formulated as
Therefore, for the modeling and forecasting purposes, the long-run nonlinear trend is a function of time t and the residual subseries, which describes the short-run dependence of the cumulative series and is obtained by . Therefore, the new proposed filters and the benchmark filter are described in the following subsection.
- Regression Spline Filter
A regression spline is a general nonparametric approximation of by a piecewise mth degree polynomial, estimating a subinterval bounded by a series of m points (called knots). Any spline function of order q can be defined as a linear combination of functions called basis functions, whose formula is given by increase.
The unknown parameter is , estimated by the ordinary least squares method. The most important choices are the number of nodes and their positions that define the smoothness of the approximation. In this work, we used cross validation to estimate these quantities.
- Smoothing Splines Filter
To meet the requirements for resolving the knot regions, spline features can be predicted using a least-squares penalty environment to limit the sum of squares. Hence, the equation can be written as
where is the second derivative of . The first term describes the goodness of fit, and the second term penalizes the coarseness of the function by the smoothing parameter . Moreover, the selection of smoothing parameters is a difficult task and is performed by cross-validation methods in this work.
- Hodrick–Prescott Filter
To assess the performance of the two proposed filters, they are compared to a standard benchmark filter, the Hodrick–Prescott Filter (HPF). The HPF is used to obtain a smoothed-curve representation of a time series that is more complex for long-term than short-term fluctuations. The adjustment of the sensitivity of the trend to short-term fluctuations is achieved by modifying a multiplier . Let (t = 1,2,...., N) be denoted the time series data. The series is made up of a trend component denoted by , and an error component, denoted by ; therefore, the equation is
Here, we insert this into in a long-term trend component that can be estimated by minimizing the following expression,
In the above equation, the first term is the loss function, and the second term is a plenty term multiplied by the sum of the square of the trend component second difference, which penalizes the variation in the growth rate of the trend component.
To graphically demonstrate the performance of the proposed filters and the considered benchmark filter (HPF) presented above, the new subseries are shown in Figure 1. In each subfigure, at the first position is a nonlinear increasing trend () subseries, and in the second position is a residual () subseries. From the figure, we observe that the proposed and the benchmark filters decomposed () and captured the long-term nonlinear trend well.
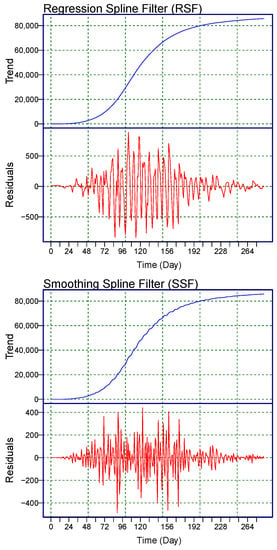
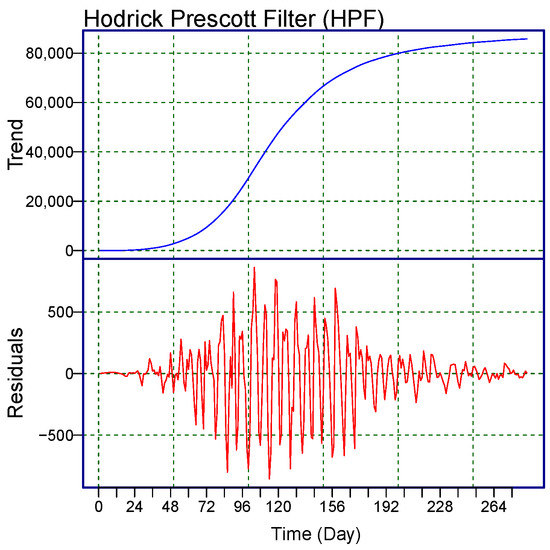
Figure 1.
World Monkeypox Virus Data: the daily confirmed cases of the monkeypox virus are filtered by the two proposed filters: (top) RSF, (middle) SSF, and the benchmark filter HPF (bottom). Within each subfigure, the top panel shows the long-term trend (blue curve-), and the bottom panel shows the residual part (red curve-).
2.1. Modeling to Filtered Series
Once the filtered subseries are extracted from the time series of the daily cumulative confirmed cases using the two new proposed filters and a benchmark filter, we estimate the extracted subseries using five standard machine learning models, including artificial neural network, support vector machine with two kernels (linear and spline), random forest, and decision tree learning. Therefore, all the considered models are explained as follows:
- Nonlinear autoregressive neural network
A nonlinear autoregressive neural network (ANN) is a type of machine learning model that is useful for forecasting the future values of an input variable. The ANN network predicts the future values of a time series based on its history using a re-feeding mechanism, in which an expected value can be used as an input for new predictions at later points in time [33]. The network is built and trained in an open loop, using actual target values as feedback to ensure greater training accuracy. The network is converted into a closed loop after training, and the predicted values are used to supply new feedback inputs to the network.
Mathematically, the model predicts the future values of a time series based on its historical values , where d is the time delay parameter. The backpropagation algorithm is used to train the network, and the steepest descent method is used to minimize the square error between the actual and predicted values.
- Support Vector Machine
The statistical learning theory and the concept of structural risk reduction, which were first introduced by Cortes and Vapnik in 1995, serve as the foundation for the machine learning algorithm known as support vector machine (SVM). One of the most widely used methods for supervised learning, the SVM is used to solve classification and regression issues [34]. The SVM is quick, easy to operate, consistent, and generates accurate results. On the other hand, SVM models employ a variety of fundamental kernel operations. The functions can be categorized as a polynomial, linear, sigmoid, and exponential radial basis function and a radial basis function. Complex nonlinear decision boundaries can be modeled by the SVM technique. In addition, the SVM model is effective in time series forecasting because it can resolve issues with nonlinear regression estimates. The formula listed below determines the SVM model for a given dataset.
Consider an n set of data (x1, y1), …, (xn, yn), where xi is the ith input vector, and yi is the corresponding desired output. Because i = 1, 2, …, n, where n is the size of the sample, the estimating function assumes the following form:
where is the weight vector, is the bias, is the high-dimensional feature space nonlinearly mapped from the input space, and (·) represents the inner product. This work considers two kernels, the linear (SVM1) and spline (SVM2) kernels.
- Random Forest Model
A well-known machine learning algorithm that belongs to the supervised learning class is called the random forest (RF). Random forest often referred to as random decision forest, is an ensemble learning technique for classification and regression that operates by putting several decision trees through training. The RF algorithm determines the outcome based on the decision trees’ predictions [35]. The output of different trees is averaged to produce forecasts. As the number of trees increases, the accuracy of the result increases. The more trees in the forest, the more accurate it is, and the issue of overfitting is avoided. To train tree learners, the random forest training algorithm employs the widely used method of bootstrap aggregation or bagging [36]. Bagging repeatedly (M times) takes a random sample with replacement of the training set and fits trees to these samples given a training set with responses .
For
1. m training instances from Y, X are sampled with replacement; they are referred to as .
2. On , we train a classification or regression tree . After training, summing the predictions from all the various regression trees on can be used to make predictions for the unseen samples :
This bootstrap technique enhances the model performance by reducing the model variance without increasing the bias. The majority vote is used in classification tree cases.
- Decision Tree Learning
Data mining frequently uses the decision tree learning technique [37]. The goal is to develop a model that predicts the value of a target parameter given a set of input parameters. A tree can be trained to learn by subdividing the source dataset depending on an attribute value test [38]. With the use of a recursive partitioning process, a decision tree algorithm divides a training dataset, } → }, to create a model. Note that each observation → could include features, . If the data at node m are Q with observations, then for each candidate partition consisting of a feature f and threshold , the data Q are split into and subsets, such that
and
The impurity at node n after each partition is defined as:
G is the impurity function in this situation.
By reducing the impurity , the decision tree model’s parameters are chosen.
Recursively, the identical partitioning operation is carried out for the subsets and up until the maximum permitted depth is reached, or there is only one observation left ( = 1). The model may then be used to forecast the value of a target variable () based on the independent variables () after the decision tree has been trained with the training dataset, Y and X.
In the current study, we denote each combined model with each filter method by RSF, where the at the top right is associated with a nonlinear trend subseries, and the at bottom right is associated to the residual subseries. In the forecasting models, we assign a code to each model: “0” for the ANN, “1” for the SVM1, “2” for the SVM2, “3” for the RF, and “4” for the DT. For example, RSF represents the estimate of the long-term trend () with the ANN, and the residual series () estimated using the SVM1. The individual forecast models are summed to obtain the final one-day-ahead cumulative confirmed cases to forecast.
2.2. Accuracy Measures
In the literature, many researchers have used various accuracy measures and statistical tests to check the performance of predictive models [39]. However, in this work, we initially use four accuracy mean errors for the proposed evaluation of all sixteen combination models, such as the root mean square percentage error (RMSPE), the root mean square error (RMSE), the mean absolute error (MAE), and the mean absolute error percentage (MAPE). The mathematical equations for these mean errors are the following:
where N is the number of observations in the dataset, () and () are the T estimated and observed data points, respectively.
The layout of the proposed filtering and combination technique is shown in Figure 2.
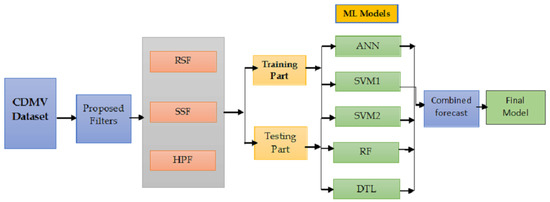
Figure 2.
A flowchart of the proposed filtering and combination technique.
3. Data Description and Case Study Results
The main aim of this work is to provide a short-term forecast of the cumulatively infected cases of MV using a dataset from the entire world. The dataset (daily cumulative confirmed cases) of MV was taken from the official website of “Our World in Data” from 7 May 2022 to 10 February 2023. The graphical presentation and the descriptive statistics of daily and cumulative confirmed cases can be seen in Figure 3 and Table 1. Figure 3 (left) shows the daily cumulative infected cases of MV, and Figure 3 (right) shows the daily new infected cases of MV. Further, Figure 3 (left) shows an increasing nonlinear curve, while Figure 3 (right) shows low infected cases at the start and end of the considered series and high cases in the middle of the considered series. It was confirmed that at the start, MV had a low number of infections, and with time, it gradually increased, but after that, it again showed a gradual decline in the infected cases. On the other hand, the descriptive statistics are tabulated in Table 1. This table shows that the minimum number of confirmed cases of MV was zero, and the maximum number was 1814. Moreover, the average number of infected cases was 300 throughout the world, while the variation among the infected cases was observed by the standard deviation with a value of 406. Therefore, the complete dataset of the daily cumulative confirmed cases covering 286 days was split; 7 May to 11 November 2022 (214 days) was used for model training, and 12 November 2022 to 10 February 2023 (72 days) was used for the one-day-ahead cumulative confirmed cases post-sample (testing) forecasts.
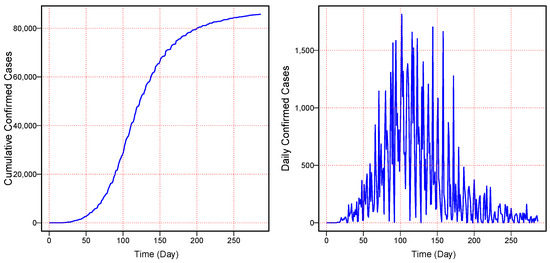
Figure 3.
World Monkeypox Virus Data: the cumulative confirmed cases of monkeypox virus (left) and the daily confirmed cases of monkeypox virus (right) from 7 May 2022 to 10 February 2023.

Table 1.
Descriptive statistics for the daily confirmed cases of the monkeypox virus dataset.
To obtain the forecast for the daily confirmed MV cases a day ahead, using the filtering and combination forecasting technique described in Section 2, the following steps were followed: first, the new two proposed filters and a benchmark filter were used to obtain a long-term nonlinear trend (), and residual () time subseries. Second, the previously described five well-known machine learning models were applied to each subseries. Thereby, the models were estimated, and a day-ahead forecast for 72 days was obtained using the rolling window method. The final daily confirmed MV cases day-ahead forecasts were obtained using Equation (8). The accuracy measures RMSPE, RMSE, MPAE, and MAE were then used to evaluate and compare the performance of the models.
The actual time series of the daily cumulative confirmed MV cases () was divided into a long-term nonlinear trend () and a residual subseries (), and two proposed filters and a benchmark filter were used in this work. Forecasts for these subseries were obtained using five machine learning models. To this end, combining the model and subseries forecasts, there were ( = 25) different combinations for each proposed filter. Thus, there were two proposed filters (RSF and SSF) and one benchmark filter (HPF), for a total of 75 () models. For these 75 models, the out-of-sample forecast accuracy measures for one day ahead (RMSPE, RMSE, MPAE, and MAE) are tabulated in Table 2, Table 3 and Table 4. The results of the performance measures showed that the RSF model produced a better prediction than all the other models using the RS filter. The best forecasting model was RSF, which produced 0.1452, 1.2083, 1010.7360, and 1207.9950 for the RMSPE, MAPE, MAE, and RMSE, respectively. However, the RSF and RSF models produced the second and third-best results. On the other hand, using the SS filter, the lowest forecast errors were found by the SSF model with the values of 0.1415, 1.2162, 1020.2140, and 1182.9890 for the RMSPE, MAPE, MAE, and RMSE, respectively. Notwithstanding, the second- and third-best results were achieved by the SSF, and SSF models, respectively. In contrast, the benchmark filter (HPF) was outperformed by the proposed filters. Therefore, it was confirmed from Table 2, Table 3 and Table 4, within the proposed filtered and benchmark filters, the RS filter produced the lowest mean errors. Moreover, within all the possible combination models ( = 25 = 75), the RSF was declared the best model.
Table 2.
World Monkeypox Virus Data: out-of-sample one-day-ahead mean forecast error for all combination models using the RS filter.
Table 3.
World Monkeypox Virus Data: out-of-sample one-day-ahead mean forecast error for all combination models using the SS filter.
Table 4.
World Monkeypox Virus Data: out-of-sample one-day-ahead mean forecast error for all combination models using the HP filter.
On the other hand, from the proposed filters (RSF and SSF) and the benchmark filter (HPF), one best combination model from each filter was selected and compared. The mean of the accuracy measures numerically are listed in Table 5 and graphically presented in Figure 4. From both presentations, it was confirmed that the RSF produced the lowest values (RMSPE = 0.1452, MAPE = 1.2083, MAE = 1010.7360, and RMSE = 1207.9950) among the best combination models. Finally, it was concluded that the proposed filter (RSF) resulted in more accurate forecasts than the other proposed filter and a benchmark filter. On the other hand, the RSF was confirmed as the best model.
Table 5.
World Monkeypox Virus Data: the best final combination models results of the out-of-sample cumulative confirmed day-ahead mean forecast error.
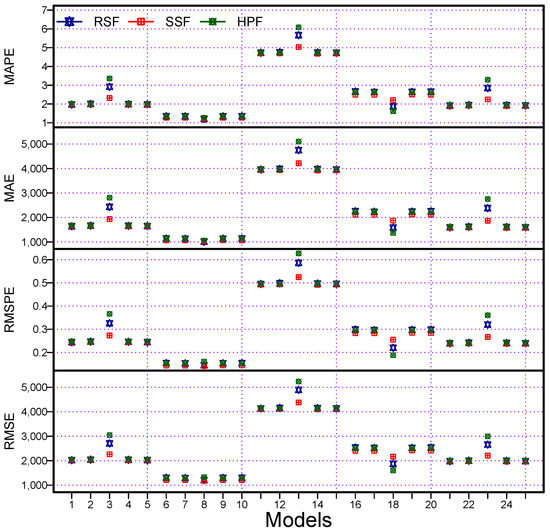
Figure 4.
World Monkeypox Virus Data: accuracy measurement plots: MAPE (1st), MAE (2nd), RMAPE (3rd), and RMSE (4th), for all combination models using two proposed filters and a benchmark filter.
Once the accuracy measures were calculated, the next step was to evaluate the dominance of these results. For this purpose, many researchers in the literature have performed the Diebold and Mariano test (DM) [40,41,42,43]. In this work, to verify the superiority of the proposed filtering and combination forecasting system results (accuracy measurements) presented in Table 2, Table 3 and Table 4, we performed tests by Diebold and Mariano (DM) on each pair of models [44]. The DM test results (p-values) are shown in Table 6. In contrast to the alternative that each entry in the table is p and that the column/row predictor accuracies are more accurate than the column/row predictor values of the hypothesis system, the null hypothesis was that there was no predictor. This table shows that among all the combination models, in Table 3, Table 4 and Table 5, the RSF, SSF, and SSF models were statistically superior to the others at the 5% significance level. In the same way, from the proposed filters (RSF and SSF) and the benchmark filter (HPF), one best model from each combination of filters was selected, and their accuracy error is listed in Table 5. Moreover, to verify the superiority of the best-selected models, the DM test results (p-values) are shown in Table 6; it was confirmed that the RSF was statistically superior to the others at the 5% significance level.
Table 6.
World Monkeypox Virus Data: results (p-value) of the DM test for the null hypothesis that the two models on the rows and columns are equally accurate and the alternative hypothesis that the model on the columns is more accurate than the model on the rows (using the loss square function).
Finally, the graphical representations of the performance measures for all 75 models are also shown in Figure 4, for the MAPE (1st), MAE (2nd), RMSPE (3rd), and RMSE (4th). In these plots, we can see that the proposed filters produced the highest accuracy (MAPE, MAE, RMSPE, and RMSE) when compared with the considered benchmark filter (HPF). However, within the proposed filters, the RSF obtained the highest accuracy. Moreover, within all the possible combination models (75), the RSF was declared as the best model. Therefore, from the descriptive statistics, statistical tests, and graphical results, we can conclude that the proposed forecasting methodology is highly accurate and efficient for the daily cumulative confirmed cases of MV forecasting. Additionally, the proposed filters had high accuracy and resulted in efficient forecasts when compared with the considered benchmark filter. Within the set of proposed filters, the RS filter produced a more precise forecast when compared with the alternatives. Moreover, it was confirmed from these visualizations that the RSF was statistically superior to the others (Figure 5).
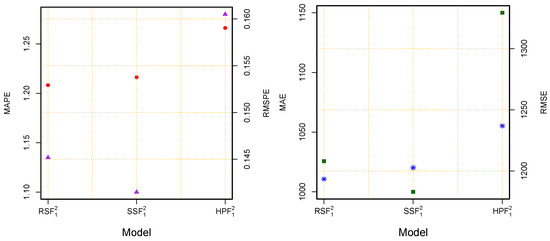
Figure 5.
World Monkeypox Virus Data: accuracy measurement plots for the best three models, (left) (MAPE-red circle and RMSPE-purple triangle) and (right) (MAE-blue star and RMSE-green square) for the best three final models using the two proposed filtering methods and a benchmark filter.
4. Discussion
According to the results (the descriptive statistics, statistical test, and graphical analysis), the conclusion is that the final best combination model was the RSF, which was highly accurate and efficient for the daily cumulative confirmed cases of MV. Hence, it is important to note that reported mean accuracy errors (RMSPE, MAPE, MAE, and RMSE) in this work were, for the best combination model (RSF), relatively lower than the considered times series and machine learning benchmark models. The considered benchmark models were the following: three standard time series models: the autoregressive (AR), nonparametric autoregressive (NPAR), and autoregressive moving integrated average (ARIMA) models, and four popular machine learning models: ANN, SVM, DT, and RF. An empirical comparison of the proposed work’s best model with the other considered benchmarks (AR, ARIMA, NPAR, ANN, SVM, DT, and RF) models are presented numerically in Table 7. As we can see from Table 7 , the proposed best combination model (RSF) in this work obtained significantly lower accuracy mean errors as compared to the time series and machine learning models. Additionally, to confirm the superiority of the proposed best combination model mentioned in Table 8, we performed a statistical test using the DM on each pair of models. The results (p-values) of the DM test are reported in Table 8, showing that the proposed models among all the considered time series and machine learning models were outperformed by our best model at the 5% significance level. To conclude, based on all of these results, the accuracy of the proposed forecasting methodology is comparatively high and efficient when compared with all the considered competitors.
Table 7.
World Monkeypox Virus Data: comparison of the proposed best model versus the considered time series and machine learning benchmark models: out-of-sample cumulative confirmed day-ahead mean forecast error.
Table 8.
World Monkeypox Virus Data: the best final model and the considered time series and machine learning benchmark models: results (p-value) of the DM test for the null hypothesis that the two models on the rows and columns are equally accurate and the alternative hypothesis that the model on the columns is more accurate than the model on the rows (using the loss square function).
Once the best models were assessed through descriptive statistics, statistical tests, and graphical analysis, we proceeded to future forecasting with the superior model. We used the RSF for the confirmed cases of MV, and forecast from 15 February to 26 February 2023 (two weeks) for the cumulative confirmed cases of MV. The forecasted values of the cumulative and daily confirmed cases from the MV are tabulated in Table 9. This table reveals that the daily confirmed cases increased in the first two days but decreased in the following three consecutive days, while on the rest of the days, there was an average increase of 45 per day. Furthermore, we predicted that during the next fourteen days (15 February to 26 February 2023), a total of 642 new cases of MV would be added globally. However, these forecasts continued to support an overall declining trend in the number of newly infected cases of MV around the world. Finally, to justify the superiority of the proposed final best model forecasting performance, we compared the cumulative infected cases of MV with the forecasted case by the proposed best model. To achieve this, we computed the percentage forecast error (PFE); the PEF is defined as PEF = (|forecasted value − actual value|/|actual value|) × 100. The values of the PFE are listed in the last column of Table 9. From this column, one can see that the forecasted values were relatively close to the actual values in terms of a low PFE. Therefore, our results offer valuable information to policymakers to guide the continued allocation of resources and inform mitigation efforts. Moreover, the forecasting exercise will help to understand the spread and lead to an understanding of the risk, which may be used to prevent further spread and enable timely and effective treatment.
Table 9.
World Monkeypox Virus Data: the forecasted cumulative and daily confirmed cases of the monkeypox virus using the best-proposed model over two weeks.
On the other hand, actual-time forecasting in epidemic emergencies provides actionable information that governments can use to anticipate medical needs and strategize the intensity and composition of public health interventions. This study provides and evaluates accurate real-time short-term forecasts of monkeypox cases worldwide, with much higher case numbers reported in most epidemics. Our model continues to predict a slowdown in MV incidence globally. Overall, our model has proven useful in making short-term forecasts and capturing slowdowns and peaks in growth with reasonable accuracy.
5. Conclusions
The main aim of this work was to forecast the short-term transmission rate of the monkeypox virus. For this purpose, we proposed a novel filtering and combination forecasting approach to accurately forecast the daily cumulative confirmed monkeypox virus cases using the publicly updated monkeypox virus dataset. To this end, we first filtered the original time series of the cumulative confirmed cases into new subseries, that is, the long-term trend series and residual series, using two proposed and one benchmark filter. Then, to predict the decomposed subseries, we considered five well-known machine learning models and all their possible combinations. Hence, we combined the individual predictive models directly to obtain the final predictions for newly confirmed cases one day ahead. To verify the performance of the proposed filtering and combination methodology, four mean errors—two absolute errors, two relative errors, and a statistical test—were considered. The experimental results showed the efficiency and accuracy of the proposed filtering and combination forecasting system. Overall, this work was compared within the proposed forecasting technique with three filters: two proposed and a benchmark filter. Among these three filtering methods, the regression smoothing spline filter outperformed the rest. On the other hand, within all the possible combination models, the (RSF), (SSF), and (HPF) were the first-, second-, and third-best models. In addition, the proposed final combination model (RSF) had superior results (accuracy mean errors, graphical analysis, and statistical test) when all the time series and machine learning models were considered. Finally, based on the best-selected model (RSF), we provided a forecast of the next fourteen days (15 February to 26 February 2023), which will help to understand the spread and lead to understanding the risk, which may be used to prevent further spread and enable timely and effective treatment.
As this study used only cumulatively confirmed monkeypox data, it could be extended to other variables (such as daily new infected cases and daily and cumulative death counts) to evaluate the performance of the proposed forecasting technique. Further, it could be used for the short-term forecasting of daily and cumulative COVID-19 confirmed cases, death counts, and recovered cases. On the other hand, the proposed forecasting techniques used only machine learning models; in the future, they will be extended by time series models, such as parametric autoregressive, nonparametric autoregressive, autoregressive integrated moving average models, etc.
Author Contributions
Conceptualization, methodology, and software, H.I.; validation, H.I., M.K. (Murad Khan) and M.K. (Mehak Khan); formal analysis, H.I.; investigation, H.I., M.K. (Murad Khan) and M.S.K.; resources, M.S.K. and M.K. (Mehak Khan); data curation, H.I. and M.K. (Murad Khan); writing—original draft preparation, H.I., M.K. (Murad Khan) and M.K. (Mehak Khan); writing—review and editing, H.I. and M.K. (Murad Khan); visualization, H.I., M.K. (Murad Khan) and M.K. (Mehak Khan); supervision, H.I. and M.K. (Mehak Khan); project administration, H.I., M.S.K. and M.K. (Mehak Khan); funding acquisition, M.K. (Mehak Khan) and M.S.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data will be provided upon the request of the first author.
Acknowledgments
This research work was funded by the Department of Computer Science, AI Lab, Oslo Metropolitan University, P.O. Box 4 St. Olavs plass, Oslo, 0130, Norway.
Conflicts of Interest
The authors declare no conflict of interest.
References
- World Health Organization. COVID-19. Available online: https://covid19.who.int/ (accessed on 17 February 2023).
- Taha, M.J.; Abuawwad, M.T.; Alrubasy, W.A.; Sameer, S.K.; Alsafi, T.; Al-Bustanji, Y.; Abu-Ismail, L.; Nashwan, A.J. Ocular manifestations of recent viral pandemics: A literature review. Front. Med. 2022, 9, 101133. [Google Scholar] [CrossRef] [PubMed]
- Chowdhury, S.R.; Datta, P.K.; Maitra, S. Monkeypox and its pandemic potential: What the anaesthetist should know. Br. J. Anaesth. 2022, 129, e49–e52. [Google Scholar] [CrossRef] [PubMed]
- Cho, C.T.; Wenner, H.A. Monkeypox virus. Bacteriol. Rev. 1973, 37, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Marennikova, S.S.; Šeluhina, E.M.; Mal’Ceva, N.N.; Čimiškjan, K.L.; Macevič, G.R. Isolation and properties of the causal agent of a new variola-like disease (monkeypox) in man. Bull. World Health Organ. 1972, 46, 599. [Google Scholar] [PubMed]
- Bunge, E.M.; Hoet, B.; Chen, L.; Lienert, F.; Weidenthaler, H.; Baer, L.R.; Steffen, R. The changing epidemiology of human monkeypox—A potential threat? A systematic review. PLoS Negl. Trop. Dis. 2022, 16, e0010141. [Google Scholar] [CrossRef]
- Meyer, H.; Perrichot, M.; Stemmler, M.; Emmerich, P.; Schmitz, H.; Varaine, F.; Shungu, R.; Tshioko, F.; Formenty, P. Outbreaks of disease suspected of being due to human monkeypox virus infection in the Democratic Republic of Congo in 2001. J. Clin. Microbiol. 2002, 40, 2919–2921. [Google Scholar] [CrossRef]
- Vivancos, R.; Anderson, C.; Blomquist, P.; Balasegaram, S.; Bell, A.; Bishop, L.; Brown, C.S.; Chow, Y.; Edeghere, O.; Florence, I.; et al. Community transmission of monkeypox in the United Kingdom, April to May 2022. Eurosurveillance 2022, 27, 2200422. [Google Scholar] [CrossRef]
- Mathieu, E.; Spooner, F.; Dattani, S.; Ritchie, H.; Roser, M. “Mpox (monkeypox)”. Published Online at OurWorldInData.org. 2022. Available online: https://ourworldindata.org/monkeypox (accessed on 10 February 2023).
- Mao, L.; Ying, J.; Selekon, B.; Gonofio, E.; Wang, X.; Nakoune, E.; Wong, G.; Berthet, N. Development and Characterization of Recombinase-Based Isothermal Amplification Assays (RPA/RAA) for the Rapid Detection of Monkeypox Virus. Viruses 2022, 14, 2112. [Google Scholar] [CrossRef]
- World Health Organization. Monkeypox. Available online: https://www.who.int/publications/m/item/multi-country-outbreak-of-mpox--external-situation-report--22---11-may-2023/ (accessed on 11 May 2023).
- Yang, Z. Monkeypox: A potential global threat? J. Med. Virol. 2022, 94, 4034–4036. [Google Scholar] [CrossRef]
- Iftikhar, H.; Rind, M. Forecasting daily COVID-19 confirmed, deaths and recovered cases using univariate time series models: A case of Pakistan study. MedRxiv 2020. [Google Scholar] [CrossRef]
- Bantan, R.A.; Ahmad, Z.; Khan, F.; Elgarhy, M.; Almaspoor, Z.; Hamedani, G.G.; El-Morshedy, M.; Gemeay, A.M. Predictive modeling of the COVID-19 data using a new version of the flexible Weibull model and machine leaning techniques. Math. Biosci. Eng. 2023, 20, 2847–2873. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, Z.; Almaspoor, Z.; Khan, F.; El-Morshedy, M. On predictive modeling using a new flexible Weibull distribution and machine learning approach: Analyzing the COVID-19 data. Mathematics 2022, 10, 1792. [Google Scholar] [CrossRef]
- Taimoor, M.; Ali, S.; Shah, I.; Muwanika, F.R. COVID-19 pandemic data modeling in Pakistan using time-series SIR. Comput. Math. Methods Med. 2022, 2022, 6001876. [Google Scholar] [CrossRef] [PubMed]
- Abbasimehr, H.; Paki, R.; Bahrini, A. A novel approach based on combining deep learning models with statistical methods for COVID-19 time series forecasting. Neural Comput. Appl. 2022, 34, 3135–3149. [Google Scholar] [CrossRef]
- Alshanbari, H.M.; Iftikhar, H.; Khan, F.; Rind, M.; Ahmad, Z.; El-Bagoury, A.A.A.H. On the Implementation of the Artificial Neural Network Approach for Forecasting Different Healthcare Events. Diagnostics 2023, 13, 1310. [Google Scholar] [CrossRef]
- Iftikhar, H.; Khan, M.; Khan, Z.; Khan, F.; Alshanbari, H.M.; Ahmad, Z. A Comparative Analysis of Machine Learning Models: A Case Study in Predicting Chronic Kidney Disease. Sustainability 2023, 15, 2754. [Google Scholar] [CrossRef]
- Khan, M.; Wang, H.; Riaz, A.; Elfatyany, A.; Karim, S. Bidirectional LSTM-RNN-based hybrid deep learning frameworks for univariate time series classification. J. Supercomput. 2021, 77, 7021–7045. [Google Scholar] [CrossRef]
- Khan, M.; Wang, H.; Ngueilbaye, A.; Elfatyany, A. End-to-end multivariate time series classification via hybrid deep learning architectures. Pers. Ubiquitous Comput. 2023, 27, 177–191. [Google Scholar] [CrossRef]
- Khan, M.; Wang, H.; Ngueilbaye, A. Attention-based deep gated fully convolutional end-to-end architectures for time series classification. Neural Process. Lett. 2021, 53, 1995–2028. [Google Scholar] [CrossRef]
- Patel, M.; Surti, M.; Adnan, M. Artificial intelligence (AI) in Monkeypox infection prevention. J. Biomol. Struct. Dyn. 2022, 1–5. [Google Scholar] [CrossRef]
- Qureshi, M.; Khan, S.; Bantan, R.A.; Daniyal, M.; Elgarhy, M.; Marzo, R.R.; Lin, Y. Modeling and Forecasting Monkeypox Cases Using Stochastic Models. J. Clin. Med. 2022, 11, 6555. [Google Scholar] [CrossRef]
- Dada, E.G.; Oyewola, D.O.; Joseph, S.B.; Emebo, O.; Oluwagbemi, O.O. Ensemble Machine Learning for Monkeypox Transmission Time Series Forecasting. Appl. Sci. 2022, 12, 12128. [Google Scholar] [CrossRef]
- Long, B.; Tan, F.; Newman, M. Forecasting the Monkeypox Outbreak Using ARIMA, Prophet, NeuralProphet, and LSTM Models in the United States. Forecasting 2023, 5, 127–137. [Google Scholar] [CrossRef]
- Eid, M.M.; El-Kenawy, E.S.M.; Khodadadi, N.; Mirjalili, S.; Khodadadi, E.; Abotaleb, M.; Alharbi, A.H.; Abdelhamid, A.A.; Ibrahim, A.; Amer, G.M.; et al. Meta-heuristic optimization of LSTM-based deep network for boosting the prediction of monkeypox cases. Mathematics 2022, 10, 3845. [Google Scholar] [CrossRef]
- Priyadarshini, I.; Mohanty, P.; Kumar, R.; Taniar, D. Monkeypox Outbreak Analysis: An Extensive Study Using Machine Learning Models and Time Series Analysis. Computers 2023, 12, 36. [Google Scholar] [CrossRef]
- Khan, M.I.; Qureshi, H.; Bae, S.J.; Awan, U.A.; Saadia, Z.; Khattak, A.A. Predicting Monkeypox incidence: Fear is not over! J. Infect. 2022, 86, 256–308. [Google Scholar] [CrossRef]
- Mohbey, K.K.; Meena, G.; Kumar, S.; Lokesh, K. A CNN-LSTM-based hybrid deep learning approach to detect sentiment polarities on Monkeypox tweets. arXiv 2022, arXiv:2208.12019. [Google Scholar]
- Bleichrodt, A.; Dahal, S.; Maloney, K.; Casanova, L.; Luo, R.; Chowell, G. Real-time forecasting the trajectory of monkeypox outbreaks at the national and global levels, July–October 2022. BMC Med. 2023, 21, 19. [Google Scholar] [CrossRef]
- Yan, W.; Du, M.; Qin, C.; Liu, Q.; Wang, Y.; Liang, W.; Liu, M.; Liu, J. Association between public attention and monkeypox epidemic: A global lag-correlation analysis. J. Med. Virol. 2023, 95, e28382. [Google Scholar] [CrossRef]
- Islam, M.P.; Morimoto, T. Non-linear autoregressive neural network approach for inside air temperature prediction of a pillar cooler. Int. J. Green Energy 2017, 14, 141–149. [Google Scholar] [CrossRef]
- Zendehboudi, A.; Baseer, M.A.; Saidur, R. Application of support vector machine models for forecasting solar and wind energy resources: A review. J. Clean. Prod. 2018, 199, 272–285. [Google Scholar] [CrossRef]
- Breiman, L. Classification and Regression Trees; Routledge: London, UK, 2017. [Google Scholar]
- Bibi, N.; Shah, I.; Alsubie, A.; Ali, S.; Lone, S.A. Electricity spot prices forecasting based on ensemble learning. IEEE Access 2021, 9, 150984–150992. [Google Scholar] [CrossRef]
- Liu, C.; Hu, Z.; Li, Y.; Liu, S. Forecasting copper prices by decision tree learning. Resour. Policy 2017, 52, 427–434. [Google Scholar] [CrossRef]
- Kumar, R. Decision tree for the weather forecasting. Int. J. Comput. Appl. 2013, 76, 31–34. [Google Scholar] [CrossRef]
- Zhang, G.P.; Qi, M. Neural network forecasting for seasonal and trend time series. European J. Oper. Res. 2005, 160, 501–514. [Google Scholar] [CrossRef]
- Shah, I.; Iftikhar, H.; Ali, S.; Wang, D. Short-term electricity demand forecasting using components estimation technique. Energies 2019, 12, 2532. [Google Scholar] [CrossRef]
- Shah, I.; Iftikhar, H.; Ali, S. Modeling and forecasting medium-term electricity consumption using component estimation technique. Forecasting 2020, 2, 163–179. [Google Scholar] [CrossRef]
- Shah, I.; Iftikhar, H.; Ali, S. Modeling and forecasting electricity demand and prices: A comparison of alternative approaches. J. Math. 2022, 2022, 3581037. [Google Scholar] [CrossRef]
- Iftikhar, H.; Bibi, N.; Canas Rodrigues, P.; López-Gonzales, J.L. Multiple Novel Decomposition Techniques for Time Series Forecasting: Application to Monthly Forecasting of Electricity Consumption in Pakistan. Energies 2023, 16, 2579. [Google Scholar] [CrossRef]
- Diebold, F.X.; Mariano, R.S. Comparing predictive accuracy. J. Bus. Econ. Stat. 2002, 20, 134–144. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).