
A Modified LeNet CNN for Breast Cancer Diagnosis in Ultrasound Images

 ,
, 
Abstract
:1. Introduction
- To accurately distinguish between malignant (cancerous) and benign (non-cancerous) breast lesions.
- To improve treatment outcomes and survival rates, using the LeNet model to assist in identifying subtle abnormalities in breast images that may indicate the presence of cancer at an early stage.
- To reduce false positives and false negatives, the LeNet model can be trained to strike a balance between sensitivity (detecting true positive cases) and specificity (avoiding false positives) and enhance the accuracy of breast cancer classification.
- To provide prognostic information, predict the likelihood of disease progression and patient survival, and to help assess the risk of recurrence and guide decisions regarding post-treatment surveillance and follow-up care.
- To recommend tailoring treatment approaches to individual patients. By classifying tumors based on specific molecular markers or genetic profiles, personalized treatment plans can be developed and therapeutic outcomes can be optimized.
- It is important to note that the modified LeNet can serve as a foundation for breast cancer classification. The architecture offers increased model depth, enabling the learning of more complex features, and potentially achieving higher classification accuracy.
2. Literature Review
- CAD models may produce false-positive results, leading to unnecessary follow-up tests or interventions. False positives can cause patient anxiety, additional healthcare costs, and potential harm from invasive procedures. Striking a balance between sensitivity and specificity is crucial to reduce false-positive rates in CAD models.
- CAD models are often developed and trained on specific datasets, which may not adequately represent the population or exhibit heterogeneity in terms of demographics, imaging protocols, or lesion types. This limited generalizability can affect the performance of CAD models when applied to different populations or images.
- CAD models are often considered “black boxes” since medical professionals do not readily interpret their decision-making process. This lack of transparency and interpretability can create challenges in understanding the features or patterns driving the model’s predictions, hindering trust and acceptance from clinicians.
- Integrating CAD models into clinical practice can be challenging. Incorporating CAD systems requires workflow adjustments, radiologist training, and potential integration with existing healthcare information systems. Adoption barriers, resistance to change, and logistical constraints may hinder the effective integration of CAD models into routine clinical workflows.
- The proposed modified LeNet, like many other deep learning models, is designed for performance and aims to classify images accurately.
- Modified LeNet demonstrates promising performance on breast cancer ultrasound datasets; their generalizability and applicability to real-world clinical settings, evaluating their impact on clinical decision-making and patient outcome, are better than any other CAD models.
3. Proposed System
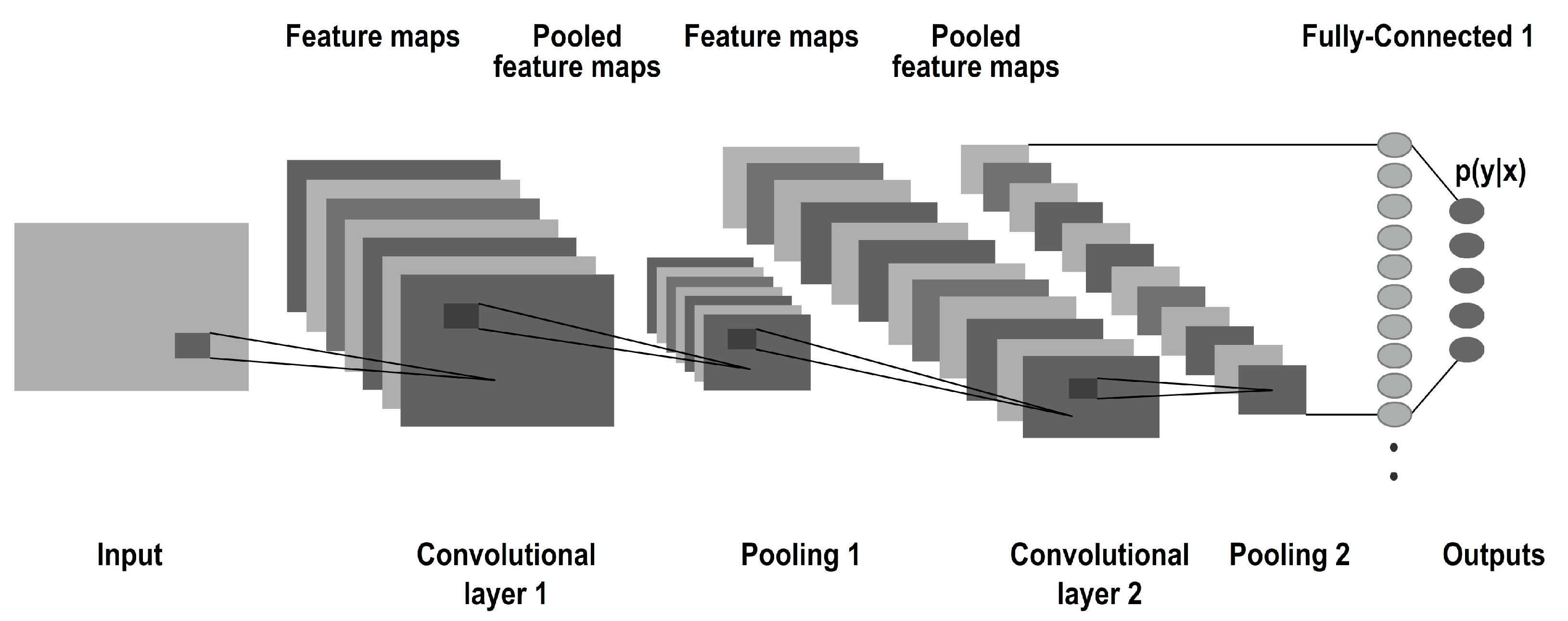
3.1. CNN Model
3.2. Fully Connected Layer
4. LeNet Architecture
- Learning rate is 0.01 which determines the step size at each iteration during training and achieves the best performance.
- Dropout rate is 40% (0.4) which controls the amount of regularization applied to the model and prevents overfitting.
- Batch size is 32 which determines the number of samples processed before the model’s weights are updated. This will lead to faster convergence and will result in better generalization which impacts the model’s performance.
- Number of Hidden Units is three which can significantly impact the model’s capacity and performance and finding the optimal balance between model complexity and overfitting.
- Number of training epochs is 10 which determines how many times the model will iterate over the entire training dataset which leads to balance between underfitting and overfitting.
- Activation functions: The activation function used in the convolutional layers (ReLU) and the dense layer (SoftMax) can also be experimented with to determine if other activation functions yield better results for your specific problem.
- Number of filters in the convolutional layers are 32, 64, and 128 which can be tuned to determine the complexity and capacity of the model.
- Kernel size in the convolutional layers is 3, 5, and 4 which can be tuned to capture different spatial patterns in the input data.
- Optimizer: The choice of optimizer can also influence the model’s performance. An optimizer is a function that modifies the attributes of the neural network, such as weights and learning rate. Common optimizers include Adam, RMSprop, and SGD with momentum. Each optimizer has different hyperparameters of its own, such as momentum or decay rates. Thus, it helps in reducing the overall loss and improving accuracy. Here, the Adam optimizer is used which is best suited for breast cancer datasets.
- Weight sharing: LeNet utilizes weight sharing in its convolutional layers. The same set of weights is applied to different spatial locations across the input. This sharing of parameters enables the network to extract and recognize similar features throughout the image. It helps reduce the total number of parameters and allows LeNet to efficiently capture local patterns.
- Activation function: LeNet employs the sigmoid activation function in its fully connected layers. The sigmoid function squashes the output of each neuron into a range between 0 and 1. This non-linearity introduces non-linear transformations and allows the network to model complex relationships between features.
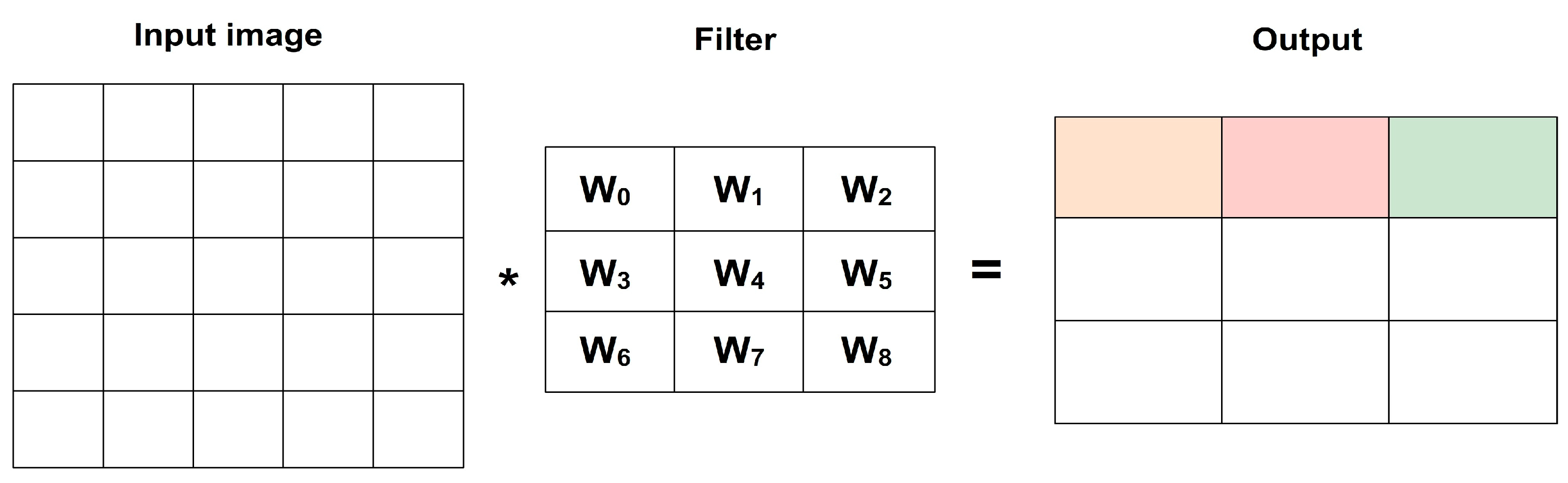
- Convolution and pooling operations: LeNet incorporates convolutional layers for spatial feature extraction. Convolutional layers apply filters to the input, capturing local patterns and creating feature maps. Pooling operations, specifically max pooling in LeNet, downsample the feature maps via selecting the maximum value in each pooling region which reduces the spatial dimensions of the features.
- Architectural simplicity: LeNet architecture consists of alternating convolutional and pooling layers followed by fully connected layers. Overall, LeNet’s unique features of weight sharing, sigmoid activation, and the combination of convolutional and pooling operations made it a pioneering architecture for image classification tasks and achieving higher performance.
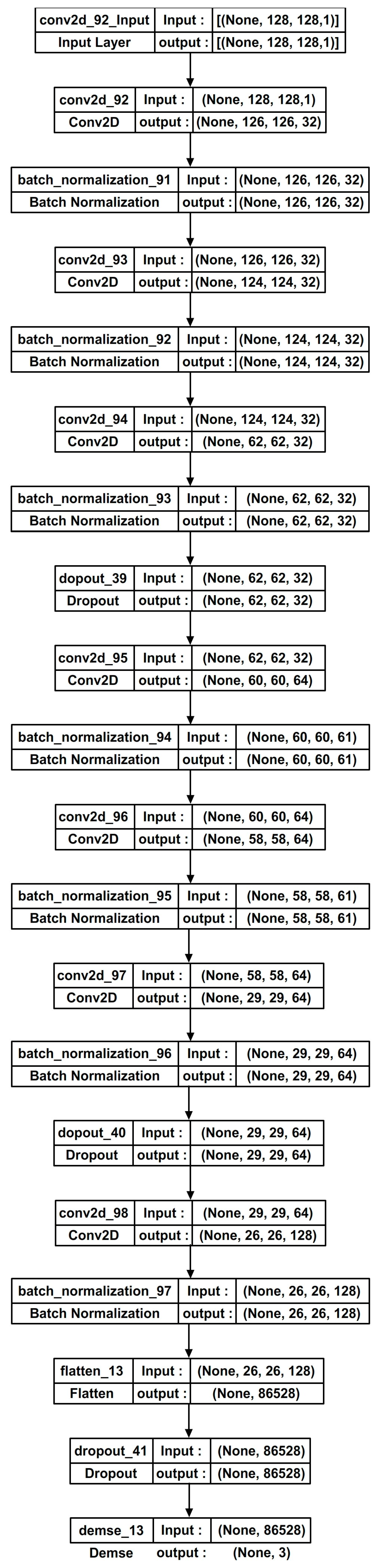
5. Modified LeNet Architecture
5.1. Batch Normalization
5.2. Replacing the Pooling Layers
5.3. ReLU Activation
5.4. Dropout
6. Materials and Methods
6.1. Dataset Description
6.2. Software Details
7. Performance Metrics
7.1. Classification Accuracy
7.2. Validation Loss
7.3. Precision
7.4. Recall
7.5. F1 Score
8. Results and Discussion
- The first step is to preprocess the BUS dataset to ensure it is in the appropriate format for training and testing models. This will include resizing the image, normalizing the pixel values, and dividing the data into training, testing sets, and validation sets.
- Train multiple LeNet models with different initialization or hyperparameter settings on the training set. This can be achieved using the TensorFlow deep learning framework.
- Combine the predictions of the individual LeNet models using soft voting.
- Hyperparameter tuning optimizes the model’s performance via finding optimal values for different hyperparameters. The number of filters in convolutional layers affects model complexity. Kernel size captures spatial patterns. Adjusting dropout rate prevents overfitting. Learning rate in Adam optimizer controls gradient descent step size. Random search samples hyperparameters randomly within a predefined range and provides computational efficiency for exploring the hyperparameter space.
- Evaluate the performance of the LeNet CNN cluster via calculating parameters such as accuracy, precision, recall, and F1 score. Compare the overall performance of a LeNet model and other high-end models.
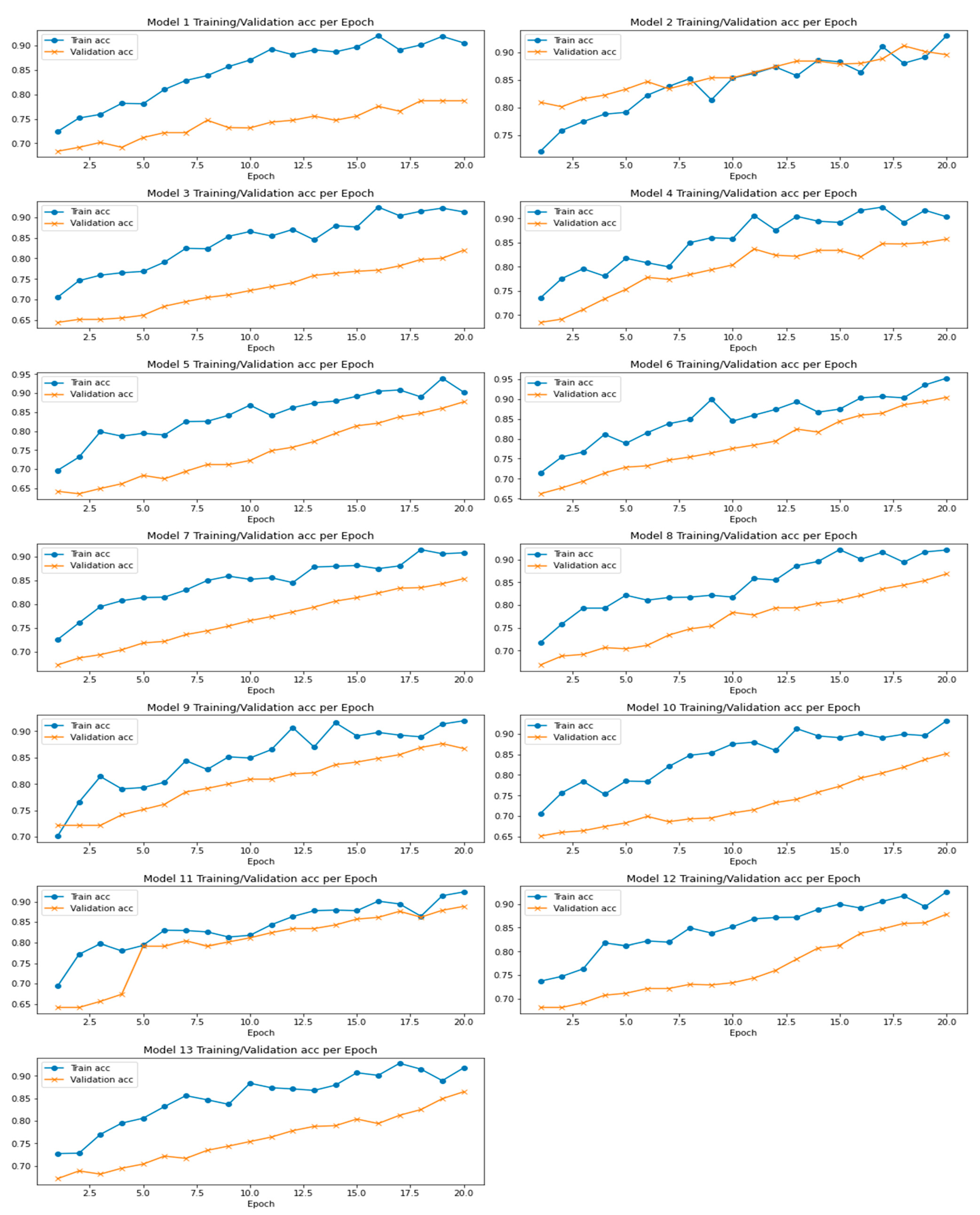
8.1. Modified LeNet’s Performance Scores
8.2. Experimental Evaluation
8.2.1. Modified LeNet Model’s Predictions Using BUS Dataset
8.2.2. Modified LeNet Model’s Performance Analysis
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- American Cancer Society. Breast Cancer Facts & Figures; American Cancer Society, Inc.: Atlanta, GA, USA, 2015. [Google Scholar]
- Madani, M.; Behzadi, M.M.; Nabavi, S. The Role of Deep Learning in Advancing Breast Cancer Detection Using Different Imaging Modalities: A Systematic Review. Cancers 2022, 14, 5334. [Google Scholar] [CrossRef] [PubMed]
- Xie, W.; Li, Y.; Ma, Y. Breast mass classification in digital mammography based on extreme learning machine. Neurocomputing 2016, 173, 930–941. [Google Scholar] [CrossRef]
- Hubbard, R.A.; Kerlikowske, K.; Flowers, C.I.; Yankaskas, B.C.; Zhu, W.; Miglioretti, D.L. Cumulative probability of false-positive recall or biopsy recommendation after 10 years of screening mammography: A cohort study. Ann. Intern. Med. 2011, 155, 481–492. [Google Scholar] [CrossRef] [PubMed]
- Heath, M.; Bowyer, K.; Kopans, D.; Kegelmeyer, P., Jr.; Moore, R.; Chang, K.; Munishkumaran, S. Current status of the digital database for screening mammography. In Digital Mammography; Springer: Berlin/Heidelberg, Germany, 1998; pp. 457–460. [Google Scholar]
- Cho, N.; Han, W.; Han, B.K.; Bae, M.S.; Ko, E.S.; Nam, S.J.; Chae, E.Y.; Lee, J.W.; Kim, S.H.; Kang, B.J.; et al. Breast cancer screening with mammography plus ultrasonography or magnetic resonance imaging in women 50 years or younger at diagnosis and treated with breast conservation therapy. JAMA Oncol. 2017, 3, 1495–1502. [Google Scholar] [CrossRef]
- Tsochatzidis, L.; Zagoris, K.; Arikidis, N.; Karahaliou, A.; Costaridou, L.; Pratikakis, I. Computer-aided diagnosis of mammographic masses based on a supervised content-based image retrieval approach. Pattern Recognit. 2017, 71, 106–117. [Google Scholar] [CrossRef]
- Hamidinekoo, A.; Denton, E.; Rampun, A.; Honnor, K.; Zwiggelaar, R. Deep learning in mammography and breast histology, an overview and future trends. Med. Image Anal. 2018, 47, 45–67. [Google Scholar] [CrossRef]
- Arevalo, J.; González, F.A.; Ramos-Pollán, R.; Oliveira, J.L.; Lopez, M.A.G. Representation learning for mammography mass lesion classification with convolutional neural networks. Comput. Methods Programs Biomed. 2016, 127, 248–257. [Google Scholar] [CrossRef]
- Rampun, A.; Scotney, B.W.; Morrow, P.J.; Wang, H. Breast Mass Classification in Mammograms using Ensemble Convolutional Neural Networks. In Proceedings of the 20th International Conference on e-Health Networking, Applications and Services (Healthcom), Ostrava, Czech Republic, 17–20 September 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Arikidis, N.; Vassiou, K.; Kazantzi, A.; Skiadopoulos, S.; Karahaliou, A.; Costaridoua, L. A two-stage method for microcalcification cluster segmentation in mammography by deformable models. Med. Phys. 2015, 42, 5848–5861. [Google Scholar] [CrossRef]
- Lee, R.S.; Gimenez, F.; Hoogi, A.; Miyake, K.K.; Gorovoy, M.; Rubin, D. A curated mammography data set for use in computer-aided detection and diagnosis research. Sci. Data 2017, 4, 170–177. [Google Scholar] [CrossRef]
- Rouhi, R.; Jafari, M.; Kasaei, S.; Keshavarzian, P. Benign and malignant breast tumor classification based on region growing and CNN segmentation. Expert Syst. Appl. 2015, 42, 990–1002. [Google Scholar] [CrossRef]
- Huynh, B.Q.; Li, H.; Giger, M.L. Digital mammographic tumor classification using transfer learning from deep convolutional neural networks. J. Med. Imaging 2016, 3, 034501. [Google Scholar] [CrossRef]
- Guleria, H.V.; Luqmani, A.M.; Kothari, H.D.; Phukan, P.; Patil, S.; Pareek, P.; Kotecha, K.; Abraham, A.; Gabralla, L.A. Enhancing the Breast Histopathology Image Analysis for Cancer Detection Using Variational Autoencoder. Int. J. Environ. Res. Public Health 2023, 20, 4244. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Jiao, Z.; Gao, X.; Wang, Y.; Li, J. A deep feature based framework for breast masses classification. Neurocomputing 2016, 197, 221–231. [Google Scholar] [CrossRef]
- Vidhushavarshini, S.; Sathiyabhama, B. Comparison of Classification Techniques on Thyroid Detection Using J48 and Naive Bayes Classification Techniques. In Proceedings of the International Conference on Intelligent Computing Systems (ICICS 2017) Organized by Sona College of Technology, Salem, Tamilnadu, India, 15–16 December 2017. [Google Scholar]
- Zahoor, S.; Shoaib, U.; Lali, I.U. Breast Cancer Mammograms Classification Using Deep Neural Network and Entropy-Controlled Whale Optimization Algorithm. Diagnostics 2022, 12, 557. [Google Scholar] [CrossRef]
- Sadad, T.; Hussain, A.; Munir, A.; Habib, M.; Ali Khan, S.; Hussain, S.; Yang, S.; Alawairdhi, M. Identification of breast malignancy by marker-controlled watershed transformation and hybrid feature set for healthcare. Appl. Sci. 2020, 10, 1900. [Google Scholar] [CrossRef]
- Badawi, S.M.; Mohamed, A.E.-N.A.; Hefnawy, A.A.; Zidan, H.E.; GadAllah, M.T.; El-Banby, G.M. Automatic semantic segmentation of breast tumors in ultrasound images based on combining fuzzy logic and deep learning—A feasibility study. PLoS ONE 2021, 16, e0251899. [Google Scholar] [CrossRef] [PubMed]
- Zahoor, S.; Lali, I.U.; Khan, M.A.; Javed, K.; Mehmood, W. Breast cancer detection and classification using traditional computer vision techniques: A comprehensive review. Curr. Med. Imaging 2020, 16, 1187–1200. [Google Scholar] [CrossRef] [PubMed]
- Lévy, D.; Jain, A. Breast mass classification from mammograms using deep convolutional neural networks. arXiv 2016, arXiv:1612.00542. [Google Scholar]
- Ting, F.F.; Tan, Y.J.; Sim, K.S. Convolutional neural network improvement for breast cancer classification. Expert Syst. Appl. 2019, 120, 103–115. [Google Scholar] [CrossRef]
- Vidhushavarshini, S.; Balasubramaniam, S.; Ravi, V.; Arunachalam, A. A hybrid optimization algorithm-based feature selection for thyroid disease classifier with rough type-2 fuzzy support vector machine. Expert Syst. 2022, 39, e12811. [Google Scholar]
- Huang, S.; Houssami, N.; Brennan, M.; Nickel, B. The impact of mandatory mammographic breast density notification on supplemental screening practice in the United States: A systematic review. Breast Cancer Res. Treat. 2021, 187, 11–30. [Google Scholar] [CrossRef] [PubMed]
- Arevalo, J.; Gonzalez, F.A.; Ramos-Pollan, R.; Oliveira, J.L.; Lopez, M.A.G. Convolutional neural networks for mammography mass lesion classification. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 797–800. [Google Scholar]
- Duraisamy, S.; Emperumal, S. Computer-aided mammogram diagnosis system using deep learning convolutional fully complex-valued relaxation neural network classifier. IET Comput. Vis. 2017, 11, 656–662. [Google Scholar] [CrossRef]
- Chai, J.; Zeng, H.; Li, A.; Ngai, E.W. Deep learning in computer vision: A critical review of emerging techniques and application scenarios. Mach. Learn. Appl. 2021, 6, 100134. [Google Scholar] [CrossRef]
- Borah, N.; Varma, P.S.P.; Datta, A.; Kumar, A.; Baruah, U.; Ghosal, P. Performance Analysis of Breast Cancer Classification from Mammogram Images Using Vision Transformer. In Proceedings of the 2022 IEEE Calcutta Conference (CALCON), Kolkata, India, 10–11 December 2022; pp. 238–243. [Google Scholar] [CrossRef]
- Reenadevi, R.; Sathiyabhama, B.; Vinayakumar, R.; Sankar, S. Hybrid Optimization Algorithm based feature selection for mammogram images and detecting the breast mass using Multilayer Perceptron classifier. J. Comput. Intell. 2022, 38, 1559–1593. [Google Scholar] [CrossRef]
- Manikandan, P.; Durga, U.; Ponnuraja, C. An integrative machine learning framework for classifying SEER breast cancer. Sci. Rep. 2023, 13, 5362. [Google Scholar] [CrossRef]
- Sun, W.; Tseng, T.L.; Zhang, J.; Qian, W. Enhancing Deep Convolutional Neural Network Scheme for Breast Cancer Diagnosis with Unlabeled Data. Comput. Med. Imaging Graph. 2017, 57, 4–9. [Google Scholar] [CrossRef]
- Khan, S.; Khan, M.A.; Alhaisoni, M.; Tariq, U.; Yong, H.-S.; Armghan, A.; Allenzi, F. Human Action Recognition: Paradigm of Best Deep Learning Features Selection and Serial Based Extended Fusion. Sensors 2021, 21, 7941. [Google Scholar] [CrossRef]
- Khan, M.A.; Alhaisoni, M.; Tariq, U.; Hussain, N.; Majid, A.; Damaševičius, R.; Maskeliunas, R. COVID-19 Case Recognition from Chest CT Images by Deep Learning, Entropy-Controlled Firefly Optimization, and Parallel Feature Fusion. Sensors 2021, 21, 7286. [Google Scholar] [CrossRef]
- Shervan, F.-E.; Alsaffar, M.F. Developing a Tuned Three-Layer Perceptron Fed with Trained Deep Convolutional Neural Networks for Cervical Cancer Diagnosis. Diagnostics 2023, 13, 686. [Google Scholar]
- Tan, Y.N.; Tinh, V.P.; Lam, P.D.; Nam, N.H.; Khoa, T.A. A Transfer Learning Approach to Breast Cancer Classification in a Federated Learning Framework. IEEE Access 2023, 11, 27462–27476. [Google Scholar] [CrossRef]
- Patil, N.S.; Desai, S.D.; Kulkarni, S. Magnification independent fine-tuned transfer learning adaptation for multi-classification of breast cancer in histopathology images. In Proceedings of the 2022 4th International Conference on Advances in Computing, Communication Control and Networking (ICAC3N), Greater Noida, India, 16–17 December 2022; pp. 1185–1191. [Google Scholar] [CrossRef]
- Sanyal, R.; Kar, D.; Sarkar, R. Carcinoma Type Classification from High-Resolution Breast Microscopy Images Using a Hybrid Ensemble of Deep Convolutional Features and Gradient Boosting Trees Classifiers. IEEE/ACM Trans. Comput. Biol. Bioinform. 2022, 19, 2124–2136. [Google Scholar] [CrossRef]
- Bagchi, A.; Pramanik, P.; Sarkar, R. A Multi-Stage Approach to Breast Cancer Classification Using Histopathology Images. Diagnostics 2023, 13, 126. [Google Scholar] [CrossRef] [PubMed]
- Kumar, D.; Batra, U. Breast Cancer Histopathology Image Classification Using Soft Voting Classifier. In Lecture Notes in Networks and Systems, Proceedings of the 3rd International Conference on Computing Informatics and Networks, Delhi, India, 29–30 July 2020; Abraham, A., Castillo, O., Virmani, D., Eds.; Springer: Singapore, 2021; Volume 167, p. 167. [Google Scholar] [CrossRef]
- Shahidi, F.; Abas, H.; Ahmad, N.A.; Maarop, N. Breast Cancer Classification Using Deep Learning Approaches and Histopathology Image: A Comparison Study. IEEE Access 2020, 8, 187531–187552. [Google Scholar] [CrossRef]
- Kathale, P.; Thorat, S. Breast Cancer Detection and Classification. In Proceedings of the 2020 International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE), Vellore, India, 24–25 February 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Farhadi, A.; Chen, D.; McCoy, R.; Scott, C.; Miller, J.A.; Vachon, C.M.; Ngufor, C. Breast Cancer Classification using Deep Transfer Learning on Structured Healthcare Data. In Proceedings of the 2019 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Washington, DC, USA, 5–8 October 2019; pp. 277–286. [Google Scholar] [CrossRef]
- Rashid, M.; Khan, M.A.; Alhaisoni, M.; Wang, S.H.; Naqvi, S.R.; Rehman, A.; Saba, T.A. Sustainable deep learning framework for object recognition using multi-layers deep features fusion and selection. Sustainability 2020, 12, 5037. [Google Scholar] [CrossRef]
- Sathiyabhama, B.; Gopikrishna, K.; Jayanthi, J.; Sathiya, T.; Ilavarasi, A.K.; Kumar, S.U.; Yuvarajan, V. Automatic Breast Region Extraction and Pectoral Muscle Removal in Mammogram Using Otsu’s Threshold with Connected Component Labelling. In Proceedings of the 3rd World Conference on Applied Science, Engineering and Technology, Singapore, 29–30 June 2017. [Google Scholar]
- Sathiyabhama, B.; Kumar, S.U.; Jayanthi, J.; Sathiya, T.; Ilavarasi, A.K.; Yuvarajan, V.; Gopikrishna, K. Breast Cancer Histopathology Image Analysis using ConvNets and Machine Learning Techniques. In International Conference on Machine Learning, Image Processing, Network Security and Data Sciences; IETE Springer Series; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Hazarika, R.A.; Abraham, A.; Kandar, D.; Maji, A.K. An improved LeNet-deep neural network model for Alzheimer’s disease classification using brain magnetic resonance images. IEEE Access 2021, 9, 161194–161207. [Google Scholar] [CrossRef]
- Sathiyabhama, B.; Kumar, S.U.; Jayanthi, J.; Sathiya, T.; Ilavarasi, A.K.; Yuvarajan, V.; Gopikrishna, K. A Novel Feature Selection Framework Based on Grey Wolf Optimizer for Mammogram Image Analysis. Neural Comput. Appl. 2021, 33, 14583–14602. [Google Scholar] [CrossRef]
- Available online: https://www.kaggle.com/datasets/aryashah2k/breast-ultrasound-images-dataset (accessed on 13 March 2023).
- Nahid, A.A.; Mehrabi, M.A.; Kong, Y. Histopathological Breast Cancer Image Classification by Deep Neural Network Techniques Guided by Local Clustering. Biomed Res. Int. 2018, 2018, 2362108. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Precision | Recall | F1 Score |
|---|---|---|---|
| Modified LeNet | 0.85 | 0.92 | 0.88 |
| Image ID | Won | Image ID | Won | Image ID | Won | Image ID | Won |
|---|---|---|---|---|---|---|---|
| 1 | 11 | 1 | 21 | 1 | 31 | 1 | |
| 2 | 1 | 12 | 1 | 22 | 1 | 32 | 1 |
| 3 | 1 | 13 | 1 | 23 | 1 | 33 | 1 |
| 4 | 1 | 14 | 1 | 24 | 1 | 34 | 1 |
| 5 | 1 | 15 | 1 | 25 | 1 | 35 | 1 |
| 6 | 1 | 16 | 1 | 26 | 1 | 36 | 2 |
| 7 | 1 | 17 | 1 | 27 | 1 | 37 | 1 |
| 8 | 1 | 18 | 1 | 28 | 2 | 38 | 1 |
| 9 | 0 | 19 | 0 | 29 | 0 | 39 | 0 |
| 10 | 1 | 20 | 1 | 30 | 1 | 40 | 1 |
| Models | Accuracy | Val_Accuracy | Loss | Val_Loss |
|---|---|---|---|---|
| Net1 | 0.8493 | 0.7394 | 1.4750 | 2.1780 |
| Net2 | 0.8427 | 0.85906 | 1.5121 | 2.1867 |
| Net3 | 0.8402 | 0.7258 | 1.4423 | 1.9361 |
| Net4 | 0.8557 | 0.7943 | 1.3765 | 2.1965 |
| Net5 | 0.8427 | 0.7459 | 1.4236 | 1.9475 |
| Net6 | 0.8522 | 0.7856 | 1.2977 | 1.5963 |
| Net7 | 0.8470 | 0.7681 | 1.3175 | 2.2156 |
| Net8 | 0.8469 | 0.7698 | 1.4092 | 2.3700 |
| Net9 | 0.8459 | 0.7322 | 1.3739 | 2.1124 |
| Net10 | 0.8469 | 0.7469 | 0.4733 | 0.4431 |
| Net11 | 0.8396 | 0.7983 | 1.5013 | 1.7907 |
| Net12 | 0.8991 | 0.7652 | 1.3770 | 1.7707 |
| Net13 | 0.8516 | 0.7591 | 1.4053 | 1.8033 |
| Models | Accuracy | Val_Accuracy | Training_Loss | Val_Loss |
|---|---|---|---|---|
| AlexNet | 0.8725 | 0.7325 | 1.6250 | 2.0125 |
| SegNet | 0.8127 | 0.7426 | 1.3232 | 2.3625 |
| U-Net | 0.8619 | 0.7003 | 1.7426 | 1.9981 |
| CE-Net | 0.8352 | 0.6982 | 1.3526 | 2.2635 |
| SCAN | 0.8056 | 0.7169 | 1.3667 | 1.9478 |
| Dense U-Net | 0.8102 | 0.7456 | 1.1125 | 1.4698 |
| LeNet | 0.8506 | 0.7223 | 1.3225 | 2.2215 |
| Modified LeNet | 0.8991 | 0.7652 | 1.3770 | 1.7707 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Balasubramaniam, S.; Velmurugan, Y.; Jaganathan, D.; Dhanasekaran, S. A Modified LeNet CNN for Breast Cancer Diagnosis in Ultrasound Images. Diagnostics 2023, 13, 2746. https://doi.org/10.3390/diagnostics13172746
Balasubramaniam S, Velmurugan Y, Jaganathan D, Dhanasekaran S. A Modified LeNet CNN for Breast Cancer Diagnosis in Ultrasound Images. Diagnostics. 2023; 13(17):2746. https://doi.org/10.3390/diagnostics13172746
Chicago/Turabian StyleBalasubramaniam, Sathiyabhama, Yuvarajan Velmurugan, Dhayanithi Jaganathan, and Seshathiri Dhanasekaran. 2023. "A Modified LeNet CNN for Breast Cancer Diagnosis in Ultrasound Images" Diagnostics 13, no. 17: 2746. https://doi.org/10.3390/diagnostics13172746
APA StyleBalasubramaniam, S., Velmurugan, Y., Jaganathan, D., & Dhanasekaran, S. (2023). A Modified LeNet CNN for Breast Cancer Diagnosis in Ultrasound Images. Diagnostics, 13(17), 2746. https://doi.org/10.3390/diagnostics13172746