


Hybrid Fusion of High-Resolution and Ultra-Widefield OCTA Acquisitions for the Automatic Diagnosis of Diabetic Retinopathy
 , , , , ,
, , , , ,
Abstract
:1. Introduction
1.1. Context
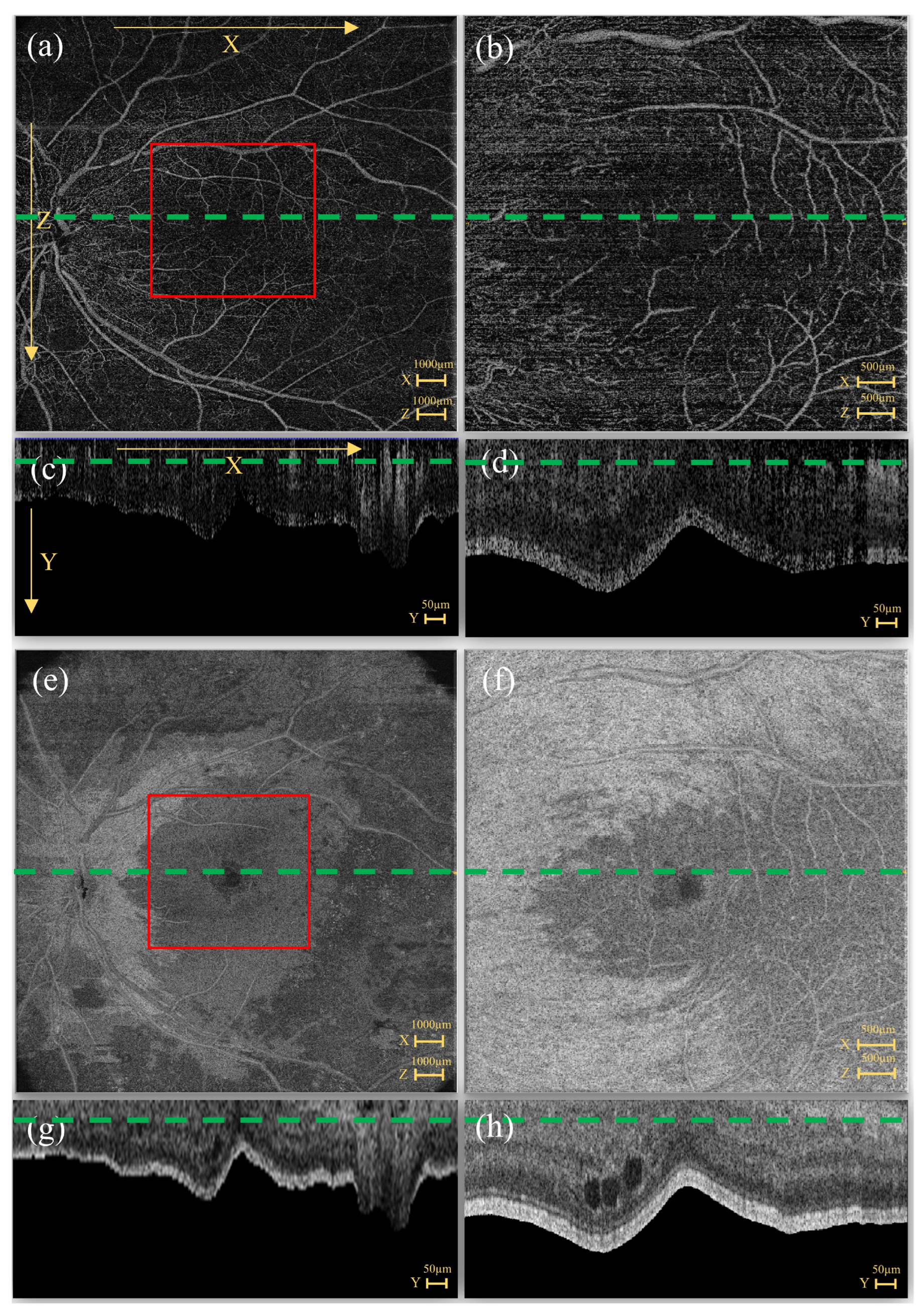
1.2. OCTA Acquisitions
1.3. Highlights
2. Materials and Methods
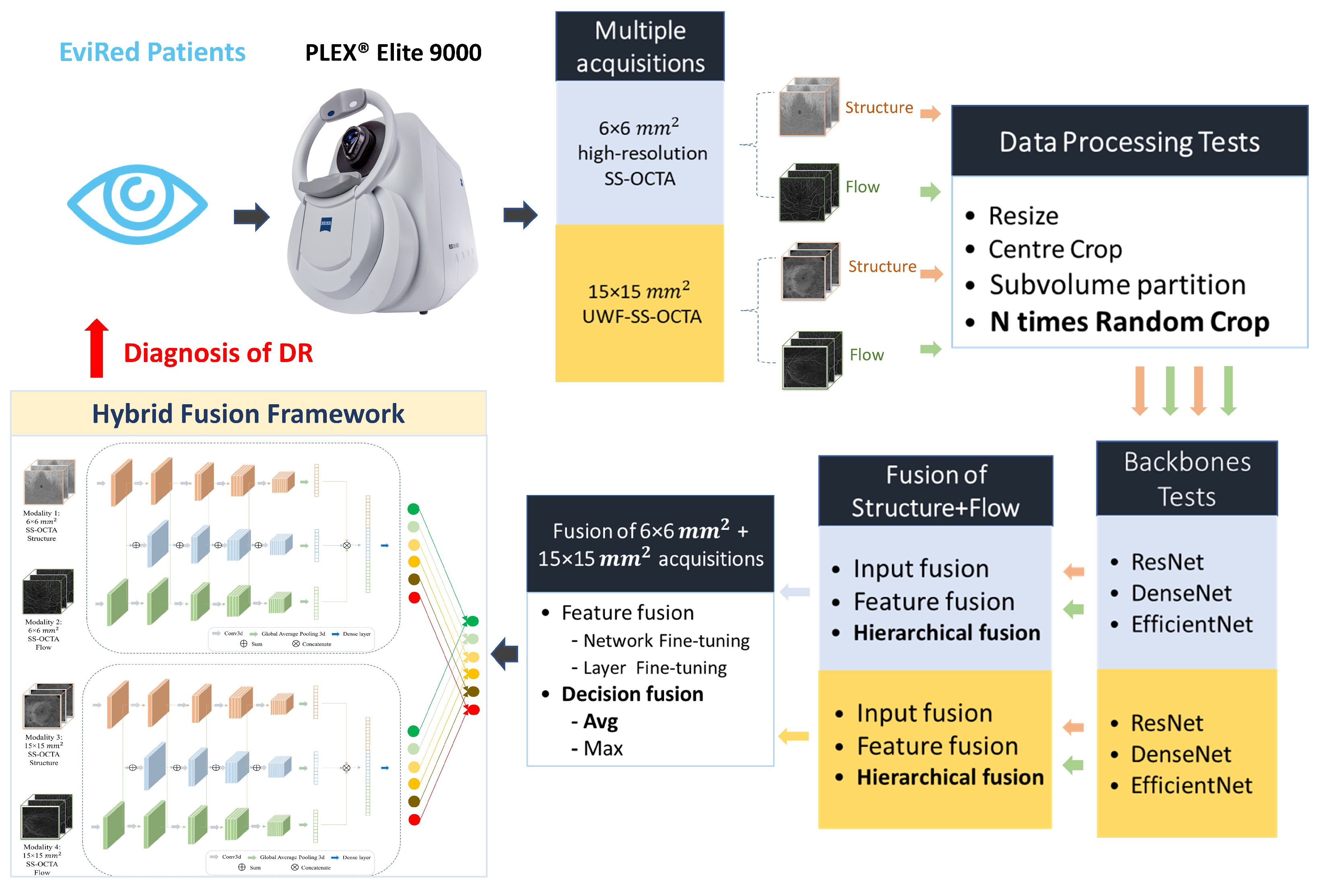
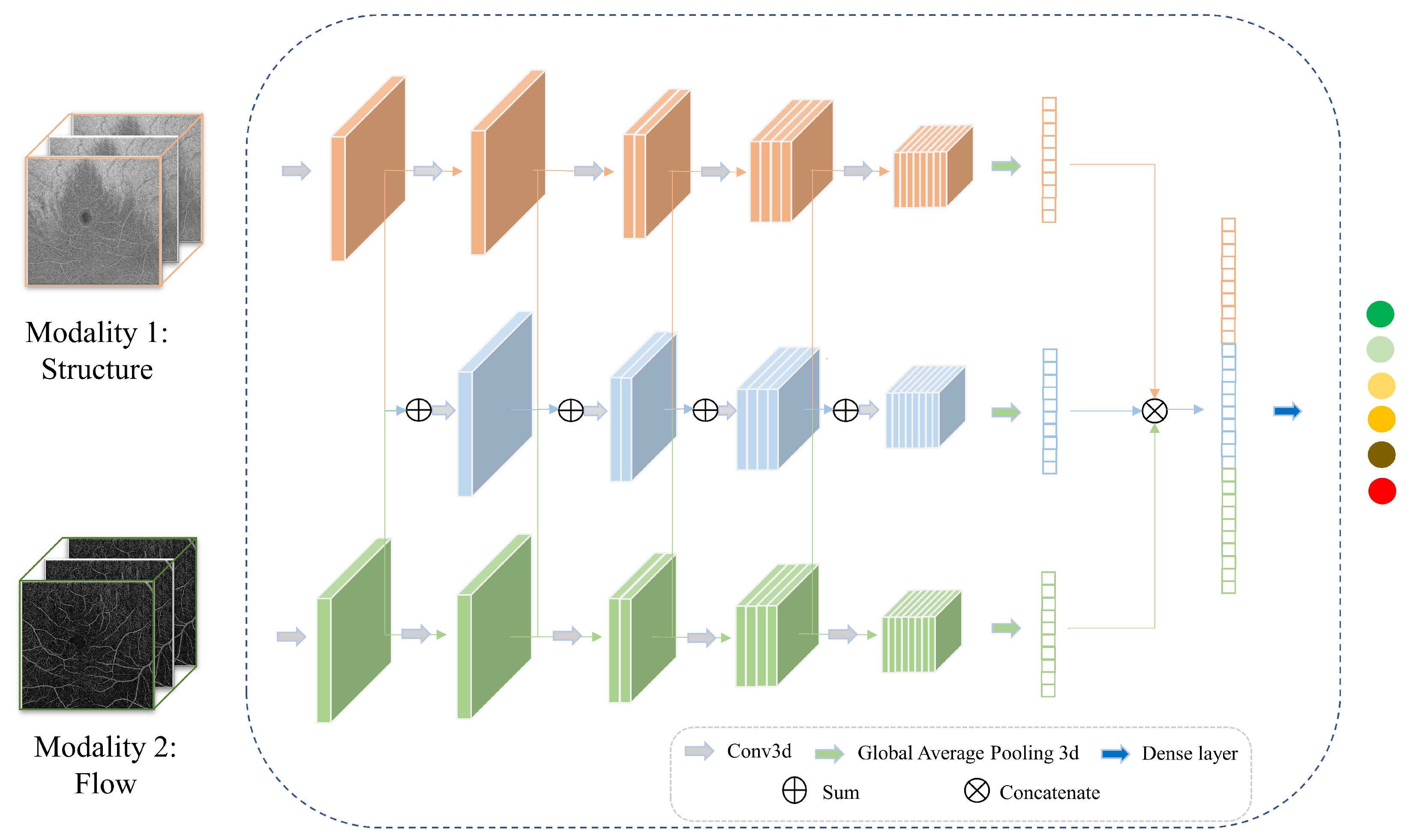
2.1. Hybrid Fusion Workflow
- (1)
- Data processing. The first step involved exploring a variety of approaches to process the raw data from different acquisitions and adapt it to the input specifications of the CNN network.
- (2)
- Backbones. Subsequently, we investigated the most effective backbone for the Structure and Flow separately for both acquisitions of OCTA data.
- (3)
- Fusion of Structure and Flow. After selecting the most effective backbone from three deep learning architectures for each modality, we evaluated four different fusion strategies—input fusion, feature fusion, decision fusion (leveraging averaging strategies), and hierarchical fusion using Structure and Flow.
- (4)
- Fusion of mm and mm acquisitions. Based on the best optimal fusion structure for each acquisition, we assessed two strategies, namely feature fusion and decision fusion, on information derived from both mm and mm SS-OCTA acquisitions:
- For the feature fusion strategy, we utilized the model parameters obtained in the previous fusion step and conducted two types of fine-tuning—(a) fine-tuning the entire network (network fine-tuning), and (b) freezing all convolutional layers and fine-tuning the classification layer (layer fine-tuning).
- For the decision fusion strategy, we implemented and tested both averaging (Avg) and maximization (Max) strategies.
2.2. Data Processing
2.2.1. EviRed Dataset
2.2.2. OCTA Cropping
- (1)
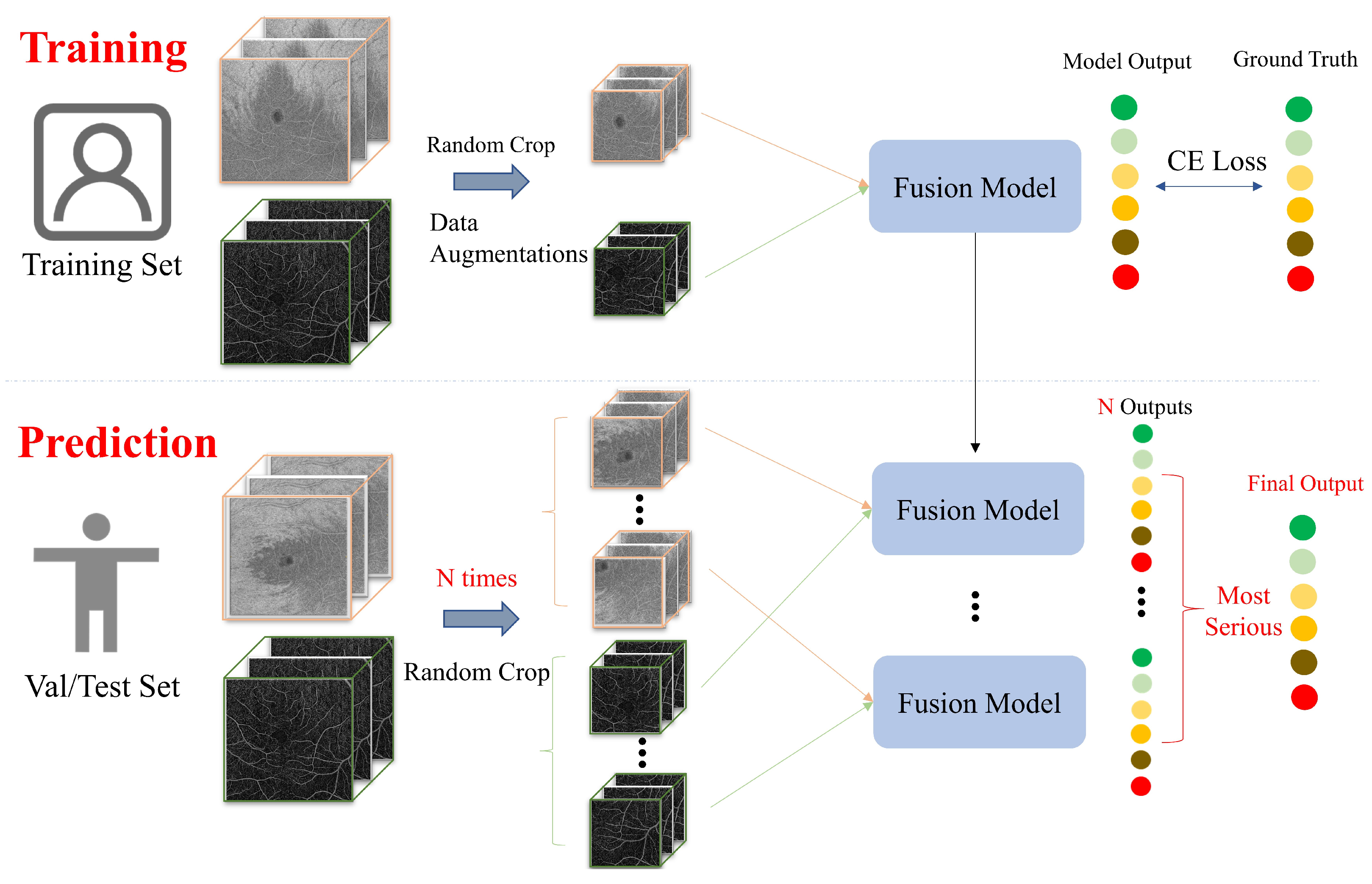
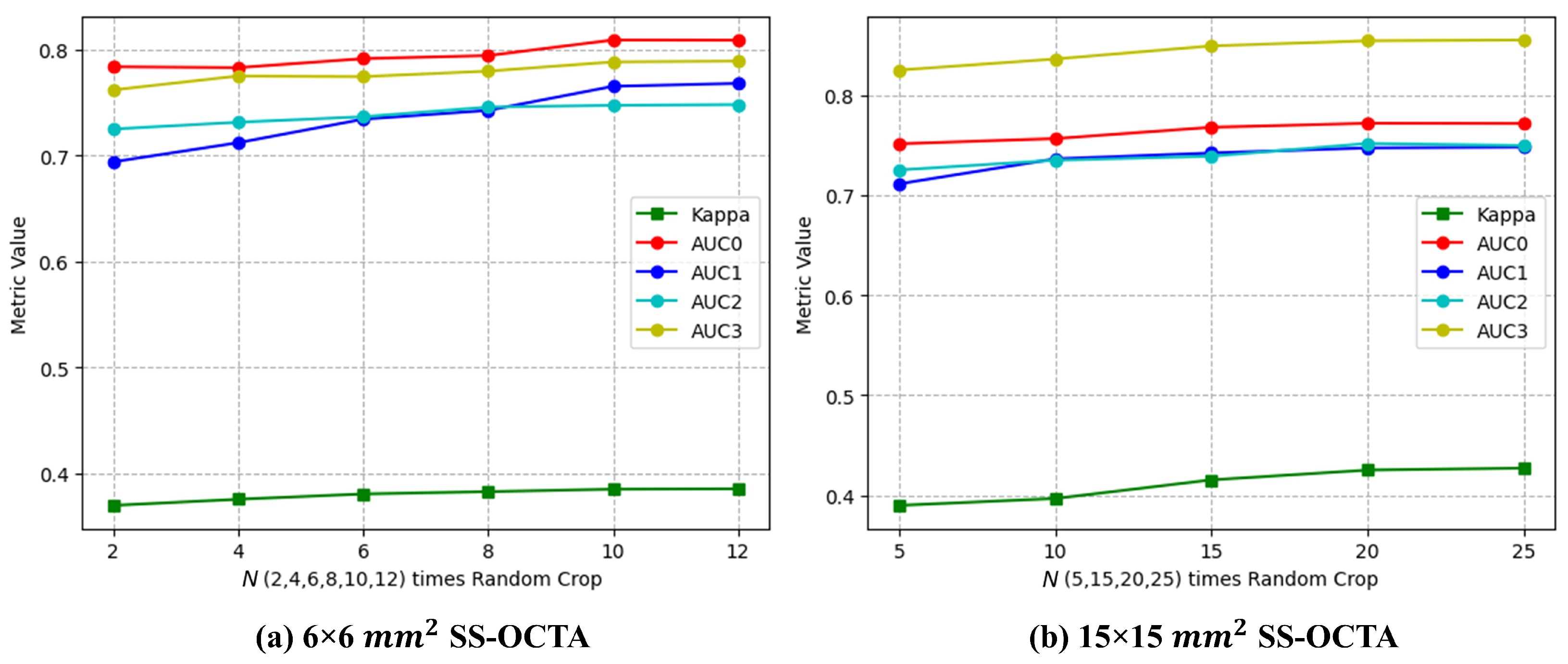
- N times Random Crop (proposed). During the training of the deep learning network, Random Crop processing was employed, while in the prediction process, we utilized multiple volumes extracted from the OCTA image (N times Random Crop) simultaneously to make predictions. Considering that the patch size was voxels, it would take at least 9 batches () to traverse the voxel mm SS-OCTA images, while 16 batches () would be required to traverse the voxel mm SS-OCTA images. By comparing the performance of the ResNet input fusion model on the validation set with different N times Random Crop methods, we determined the N values for the two SS-OCTA acquisitions. The final prediction for an OCTA image was based on the severest prediction among these N predictions.
- (2)
- Resize. This method compressed the original volume of voxels into voxels for both training and prediction.
- (3)
- Center Crop. This approach selected a random patch of voxels from the original voxel OCTA for training. For prediction, a central patch was selected.
- (4)
- Subvolume Crop. This technique traversed the OCTA using a window, predicting all subvolumes of voxels and determining the maximum value.
2.3. Multimodal Information Fusion
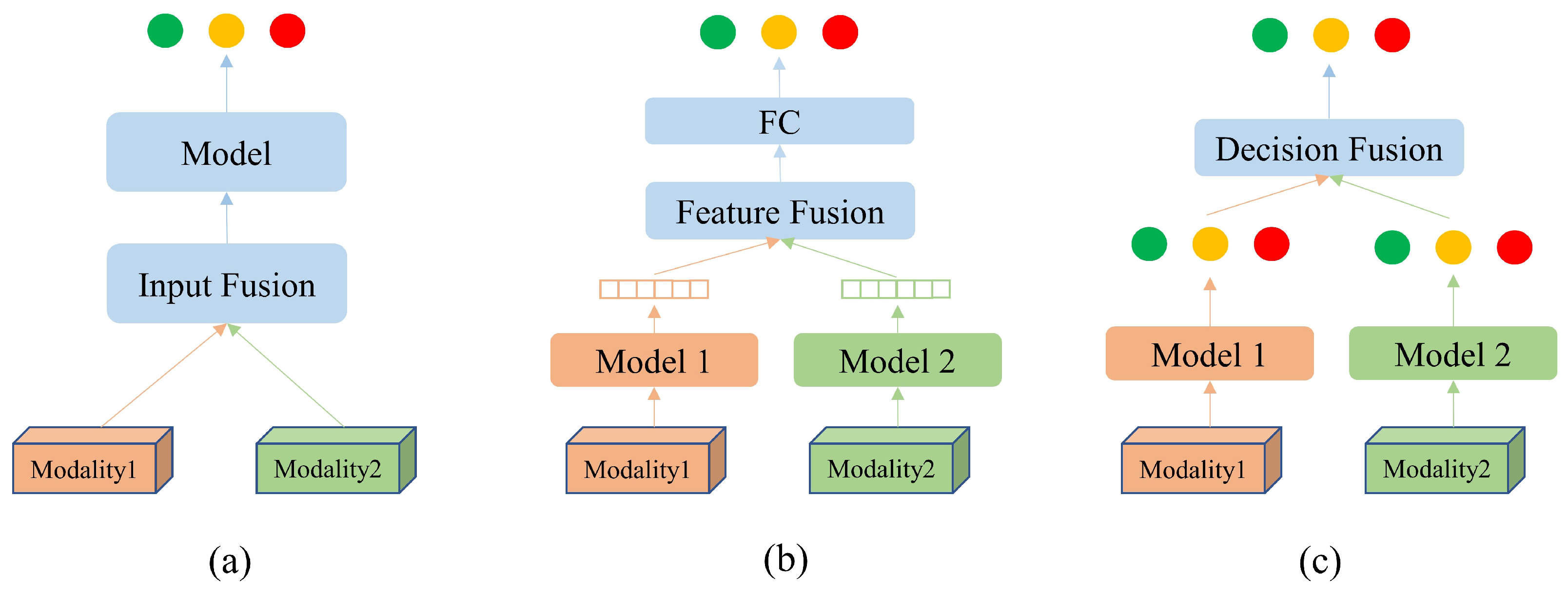
2.3.1. Input Fusion
2.3.2. Feature Fusion
2.3.3. Decision Fusion
2.3.4. Hierarchical Fusion
2.4. Classification Tasks
2.5. Dataset Splitting
2.6. Implementation Details
3. Results
3.1. Data Cropping
3.2. Backbones
3.3. Fusion of Structure and Flow
3.4. Fusion of mm SS-OCTA and mm SS-OCTA
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AUC | Area under the ROC curve |
| CNN | Convolutional neural networks |
| DR | Diabetic retinopathy |
| FC | Fully connected |
| GPU | Graphics processing unit |
| LSO | Line-scanning ophthalmoscope |
| ICDR | International Clinical Diabetic Retinopathy Disease Severity Scale |
| ILM | Internal limiting membrane |
| IRMA | Intraretinal microvascular abnormality |
| NPDR | Non-proliferative DR |
| OCT | Optical coherence tomography |
| OCTA | Optical coherence tomography angiography |
| PDR | Proliferative diabetic retinopathy |
| PRP | Panretinal photocoagulation |
| ROC | Receiver operating characteristic |
| RPE | Retinal pigment epithelium |
| SS-OCTA | Swept-source OCTA |
| UWF | Ultra-widefield |
References
- Sivaprasad, S.; Gupta, B.; Crosby-Nwaobi, R.; Evans, J. Prevalence of diabetic retinopathy in various ethnic groups: A worldwide perspective. Surv. Ophthalmol. 2012, 57, 347–370. [Google Scholar] [CrossRef]
- Teo, Z.L.; Tham, Y.C.; Yu, M.; Chee, M.L.; Rim, T.H.; Cheung, N.; Bikbov, M.M.; Wang, Y.X.; Tang, Y.; Lu, Y.; et al. Global prevalence of diabetic retinopathy and projection of burden through 2045: Systematic review and meta-analysis. Ophthalmology 2021, 128, 1580–1591. [Google Scholar] [CrossRef]
- Selvachandran, G.; Quek, S.G.; Paramesran, R.; Ding, W.; Son, L.H. Developments in the detection of diabetic retinopathy: A state-of-the-art review of computer-aided diagnosis and machine learning methods. Artif. Intell. Rev. 2023, 56, 915–964. [Google Scholar] [CrossRef]
- Saeedi, P.; Petersohn, I.; Salpea, P.; Malanda, B.; Karuranga, S.; Unwin, N.; Colagiuri, S.; Guariguata, L.; Motala, A.A.; Ogurtsova, K.; et al. Global and regional diabetes prevalence estimates for 2019 and projections for 2030 and 2045: Results from the International Diabetes Federation Diabetes Atlas, 9th edition. Diabetes Res. Clin. Pract. 2019, 157, 107843. [Google Scholar] [CrossRef] [PubMed]
- Huang, D.; Swanson, E.A.; Lin, C.P.; Schuman, J.S.; Stinson, W.G.; Chang, W.; Hee, M.R.; Flotte, T.; Gregory, K.; Puliafito, C.A.; et al. Optical coherence tomography. Science 1991, 254, 1178–1181. [Google Scholar] [CrossRef] [PubMed]
- Lains, I.; Wang, J.C.; Cui, Y.; Katz, R.; Vingopoulos, F.; Staurenghi, G.; Vavvas, D.G.; Miller, J.W.; Miller, J.B. Retinal applications of swept source optical coherence tomography (OCT) and optical coherence tomography angiography (OCTA). Prog. Retin. Eye Res. 2021, 84, 100951. [Google Scholar] [CrossRef]
- Cui, Y.; Zhu, Y.; Wang, J.C.; Lu, Y.; Zeng, R.; Katz, R.; Vingopoulos, F.; Le, R.; Laíns, I.; Wu, D.M.; et al. Comparison of widefield swept-source optical coherence tomography angiography with ultra-widefield colour fundus photography and fluorescein angiography for detection of lesions in diabetic retinopathy. Br. J. Ophthalmol. 2021, 105, 577–581. [Google Scholar] [CrossRef]
- Russell, J.F.; Shi, Y.; Hinkle, J.W.; Scott, N.L.; Fan, K.C.; Lyu, C.; Gregori, G.; Rosenfeld, P.J. Longitudinal wide-field swept-source OCT angiography of neovascularization in proliferative diabetic retinopathy after panretinal photocoagulation. Ophthalmol. Retin. 2019, 3, 350–361. [Google Scholar] [CrossRef] [PubMed]
- Pichi, F.; Smith, S.D.; Abboud, E.B.; Neri, P.; Woodstock, E.; Hay, S.; Levine, E.; Baumal, C.R. Wide-field optical coherence tomography angiography for the detection of proliferative diabetic retinopathy. Graefe’s Arch. Clin. Exp. Ophthalmol. 2020, 258, 1901–1909. [Google Scholar] [CrossRef]
- Khalid, H.; Schwartz, R.; Nicholson, L.; Huemer, J.; El-Bradey, M.H.; Sim, D.A.; Patel, P.J.; Balaskas, K.; Hamilton, R.D.; Keane, P.A.; et al. Widefield optical coherence tomography angiography for early detection and objective evaluation of proliferative diabetic retinopathy. Br. J. Ophthalmol. 2021, 105, 118–123. [Google Scholar] [CrossRef]
- Sawada, O.; Ichiyama, Y.; Obata, S.; Ito, Y.; Kakinoki, M.; Sawada, T.; Saishin, Y.; Ohji, M. Comparison between wide-angle OCT angiography and ultra-wide field fluorescein angiography for detecting non-perfusion areas and retinal neovascularization in eyes with diabetic retinopathy. Graefe’s Arch. Clin. Exp. Ophthalmol. 2018, 256, 1275–1280. [Google Scholar] [CrossRef]
- Shiraki, A.; Sakimoto, S.; Tsuboi, K.; Wakabayashi, T.; Hara, C.; Fukushima, Y.; Sayanagi, K.; Nishida, K.; Sakaguchi, H.; Nishida, K. Evaluation of retinal nonperfusion in branch retinal vein occlusion using wide-field optical coherence tomography angiography. Acta Ophthalmol. 2019, 97, e913–e918. [Google Scholar] [CrossRef]
- Li, M.; Mao, M.; Wei, D.; Liu, M.; Liu, X.; Leng, H.; Wang, Y.; Chen, S.; Zhang, R.; Wang, M.; et al. Different scan areas affect the detection rates of diabetic retinopathy lesions by high-speed ultra-widefield swept-source optical coherence tomography angiography. Front. Endocrinol. 2023, 14, 350. [Google Scholar] [CrossRef] [PubMed]
- Hirano, T.; Kakihara, S.; Toriyama, Y.; Nittala, M.G.; Murata, T.; Sadda, S. Wide-field en face swept-source optical coherence tomography angiography using extended field imaging in diabetic retinopathy. Br. J. Ophthalmol. 2018, 102, 1199–1203. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Wei, D.; Mao, M.; Li, M.; Liu, S.; Li, F.; Chen, L.; Liu, M.; Leng, H.; Wang, Y.; et al. Ultra-widefield color fundus photography combined with high-speed ultra-widefield swept-source optical coherence tomography angiography for non-invasive detection of lesions in diabetic retinopathy. Front. Public Health 2022, 10, 1047608. [Google Scholar] [CrossRef]
- Xuan, Y.; Chang, Q.; Zhang, Y.; Ye, X.; Liu, W.; Li, L.; Wang, K.; Zhou, J.; Wang, M. Clinical observation of choroidal osteoma using swept-source optical coherence tomography and optical coherence tomography angiography. Appl. Sci. 2022, 12, 4472. [Google Scholar] [CrossRef]
- Zhang, W.; Li, C.; Gong, Y.; Liu, N.; Cao, Y.; Li, Z.; Zhang, Y. Advanced ultrawide-field optical coherence tomography angiography identifies previously undetectable changes in biomechanics-related parameters in nonpathological myopic fundus. Front. Bioeng. Biotechnol. 2022, 10, 920197. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Garg, I.; Miller, J.B. Wide field swept source optical coherence tomography angiography for the evaluation of proliferative diabetic retinopathy and associated lesions: A review. Semin. Ophthalmol. 2021, 36, 162–167. [Google Scholar] [CrossRef] [PubMed]
- Grzybowski, A.; Singhanetr, P.; Nanegrungsunk, O.; Ruamviboonsuk, P. Artificial intelligence for diabetic retinopathy screening using color retinal photographs: From development to deployment. Ophthalmol. Ther. 2023, 12, 1419–1437. [Google Scholar] [CrossRef] [PubMed]
- Ryu, G.; Lee, K.; Park, D.; Park, S.H.; Sagong, M. A deep learning model for identifying diabetic retinopathy using optical coherence tomography angiography. Sci. Rep. 2021, 11, 23024. [Google Scholar] [CrossRef]
- Le, D.; Alam, M.; Yao, C.K.; Lim, J.I.; Hsieh, Y.T.; Chan, R.V.; Toslak, D.; Yao, X. Transfer learning for automated OCTA detection of diabetic retinopathy. Transl. Vis. Sci. Technol. 2020, 9, 35. [Google Scholar] [CrossRef]
- Li, Y.; El Habib Daho, M.; Conze, P.H.; Al Hajj, H.; Bonnin, S.; Ren, H.; Manivannan, N.; Magazzeni, S.; Tadayoni, R.; Cochener, B.; et al. Multimodal information fusion for glaucoma and diabetic retinopathy classification. In Proceedings of the Ophthalmic Medical Image Analysis: 9th International Workshop, OMIA 2022, Held in Conjunction with MICCAI 2022, Singapore, 22 September 2022; Springer: Cham, Switzerland, 2022; pp. 53–62. [Google Scholar]
- Heisler, M.; Karst, S.; Lo, J.; Mammo, Z.; Yu, T.; Warner, S.; Maberley, D.; Beg, M.F.; Navajas, E.V.; Sarunic, M.V. Ensemble deep learning for diabetic retinopathy detection using optical coherence tomography angiography. Transl. Vis. Sci. Technol. 2020, 9, 20. [Google Scholar] [CrossRef]
- Zang, P.; Hormel, T.T.; Wang, X.; Tsuboi, K.; Huang, D.; Hwang, T.S.; Jia, Y. A Diabetic Retinopathy Classification Framework Based on Deep-Learning Analysis of OCT Angiography. Transl. Vis. Sci. Technol. 2022, 11, 10. [Google Scholar] [CrossRef]
- Salz, D.A.; de Carlo, T.E.; Adhi, M.; Moult, E.; Choi, W.; Baumal, C.R.; Witkin, A.J.; Duker, J.S.; Fujimoto, J.G.; Waheed, N.K. Select Features of Diabetic Retinopathy on Swept-Source Optical Coherence Tomographic Angiography Compared With Fluorescein Angiography and Normal Eyes. JAMA Ophthalmol. 2016, 134, 644. [Google Scholar] [CrossRef]
- Agemy, S.A.; Scripsema, N.K.; Shah, C.M.; Chui, T.; Garcia, P.M.; Lee, J.G.; Gentile, R.C.; Hsiao, Y.S.; Zhou, Q.; Ko, T.; et al. Retinal vascular perfusion density mapping using optical coherence tomography angiography in normals and diabetic retinopathy patients. Retina 2015, 35, 2353–2363. [Google Scholar] [CrossRef]
- Al-Sheikh, M.; Akil, H.; Pfau, M.; Sadda, S.R. Swept-Source OCT Angiography Imaging of the Foveal Avascular Zone and Macular Capillary Network Density in Diabetic Retinopathy. Investig. Opthalmol. Vis. Sci. 2016, 57, 3907. [Google Scholar] [CrossRef]
- Hwang, T.S.; Gao, S.S.; Liu, L.; Lauer, A.K.; Bailey, S.T.; Flaxel, C.J.; Wilson, D.J.; Huang, D.; Jia, Y. Automated Quantification of Capillary Nonperfusion Using Optical Coherence Tomography Angiography in Diabetic Retinopathy. JAMA Ophthalmol. 2016, 134, 367. [Google Scholar] [CrossRef]
- Fayed, A.E.; Abdelbaki, A.M.; El Zawahry, O.M.; Fawzi, A.A. Optical coherence tomography angiography reveals progressive worsening of retinal vascular geometry in diabetic retinopathy and improved geometry after panretinal photocoagulation. PLoS ONE 2019, 14, e0226629. [Google Scholar] [CrossRef]
- Schottenhamml, J.; Moult, E.M.; Ploner, S.; Lee, B.; Novais, E.A.; Cole, E.; Dang, S.; Lu, C.D.; Husvogt, L.; Waheed, N.K.; et al. An automatic, intercapillary area based algorithm for quantifying diabetes related capillary dropout using OCT angiography. Retina 2016, 36, S93–S101. [Google Scholar] [CrossRef]
- Ishibazawa, A.; Nagaoka, T.; Takahashi, A.; Omae, T.; Tani, T.; Sogawa, K.; Yokota, H.; Yoshida, A. Optical Coherence Tomography Angiography in Diabetic Retinopathy: A Prospective Pilot Study. Am. J. Ophthalmol. 2015, 160, 35–44.e1. [Google Scholar] [CrossRef]
- Couturier, A.; Rey, P.A.; Erginay, A.; Lavia, C.; Bonnin, S.; Dupas, B.; Gaudric, A.; Tadayoni, R. Widefield OCT-Angiography and Fluorescein Angiography Assessments of Nonperfusion in Diabetic Retinopathy and Edema Treated with Anti–Vascular Endothelial Growth Factor. Ophthalmology 2019, 126, 1685–1694. [Google Scholar] [CrossRef]
- Alibhai, A.Y.; De Pretto, L.R.; Moult, E.M.; Or, C.; Arya, M.; McGowan, M.; Carrasco-Zevallos, O.; Lee, B.; Chen, S.; Baumal, C.R.; et al. Quantification of retinal capillary nonperfusion in diabetics using wide-field optical coherence tomography angiography. Retina 2020, 40, 412–420. [Google Scholar] [CrossRef]
- Jia, Y.; Bailey, S.T.; Hwang, T.S.; McClintic, S.M.; Gao, S.S.; Pennesi, M.E.; Flaxel, C.J.; Lauer, A.K.; Wilson, D.J.; Hornegger, J.; et al. Quantitative optical coherence tomography angiography of vascular abnormalities in the living human eye. Proc. Natl. Acad. Sci. USA 2015, 112, E2395–E2402. [Google Scholar] [CrossRef]
- Suk, H.I.; Lee, S.W.; Shen, D.; Initiative, A.D.N.; The Alzheimer’s Disease Neuroimaging Initiative. Hierarchical feature representation and multimodal fusion with deep learning for AD/MCI diagnosis. NeuroImage 2014, 101, 569–582. [Google Scholar] [CrossRef]
- Liu, M.; Cheng, D.; Wang, K.; Wang, Y.; Initiative, A.D.N. Multi-modality cascaded convolutional neural networks for Alzheimer’s disease diagnosis. Neuroinformatics 2018, 16, 295–308. [Google Scholar] [CrossRef]
- Shanmugam, D.; Blalock, D.; Balakrishnan, G.; Guttag, J. Better aggregation in test-time augmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 19–25 June 2021; pp. 1214–1223. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ramachandram, D.; Taylor, G.W. Deep multimodal learning: A survey on recent advances and trends. IEEE Signal Process. Mag. 2017, 34, 96–108. [Google Scholar] [CrossRef]
- Liu, S.; Liu, S.; Cai, W.; Che, H.; Pujol, S.; Kikinis, R.; Feng, D.; Fulham, M.J.; ADNI. Multimodal neuroimaging feature learning for multiclass diagnosis of Alzheimer’s disease. IEEE Trans. Biomed. Eng. 2014, 62, 1132–1140. [Google Scholar] [CrossRef]
- Akhavan Aghdam, M.; Sharifi, A.; Pedram, M.M. Combination of rs-fMRI and sMRI data to discriminate autism spectrum disorders in young children using deep belief network. J. Digit. Imaging 2018, 31, 895–903. [Google Scholar] [CrossRef]
- Qian, X.; Zhang, B.; Liu, S.; Wang, Y.; Chen, X.; Liu, J.; Yang, Y.; Chen, X.; Wei, Y.; Xiao, Q.; et al. A combined ultrasonic B-mode and color Doppler system for the classification of breast masses using neural network. Eur. Radiol. 2020, 30, 3023–3033. [Google Scholar] [CrossRef]
- Zong, W.; Lee, J.K.; Liu, C.; Carver, E.N.; Feldman, A.M.; Janic, B.; Elshaikh, M.A.; Pantelic, M.V.; Hearshen, D.; Chetty, I.J.; et al. A deep dive into understanding tumor foci classification using multiparametric MRI based on convolutional neural network. Med. Phys. 2020, 47, 4077–4086. [Google Scholar] [CrossRef]
- Pereira, S.; Pinto, A.; Alves, V.; Silva, C.A. Brain tumor segmentation using convolutional neural networks in MRI images. IEEE Trans. Med. Imaging 2016, 35, 1240–1251. [Google Scholar] [CrossRef]
- Isensee, F.; Kickingereder, P.; Wick, W.; Bendszus, M.; Maier-Hein, K.H. Brain tumor segmentation and radiomics survival prediction: Contribution to the brats 2017 challenge. In Proceedings of the Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries: Third International Workshop, BrainLes 2017, Held in Conjunction with MICCAI 2017, Quebec City, QC, Canada, 14 September 2017; Revised Selected Papers 3. Springer: Cham, Switzerland, 2018; pp. 287–297. [Google Scholar]
- Cui, S.; Mao, L.; Jiang, J.; Liu, C.; Xiong, S. Automatic semantic segmentation of brain gliomas from MRI images using a deep cascaded neural network. J. Healthc. Eng. 2018, 2018, 4940593. [Google Scholar] [CrossRef]
- Wang, G.; Li, W.; Ourselin, S.; Vercauteren, T. Automatic brain tumor segmentation using cascaded anisotropic convolutional neural networks. In Proceedings of the Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries: Third International Workshop, BrainLes 2017, Held in Conjunction with MICCAI 2017, Quebec City, QC, Canada, 14 September 2017; Revised Selected Papers 3. Springer: Cham, Switzerland, 2018; pp. 178–190. [Google Scholar]
- Xu, H.; Li, Y.; Zhao, W.; Quellec, G.; Lu, L.; Hatt, M. Joint nnU-Net and radiomics approaches for segmentation and prognosis of head and neck cancers with PET/CT images. In Proceedings of the Head and Neck Tumor Segmentation and Outcome Prediction: Third Challenge, HECKTOR 2022, Held in Conjunction with MICCAI 2022, Singapore, 22 September 2022; Springer: Cham, Switzerland, 2023; pp. 154–165. [Google Scholar]
- Wu, J.; Fang, H.; Li, F.; Fu, H.; Lin, F.; Li, J.; Huang, L.; Yu, Q.; Song, S.; Xu, X.; et al. Gamma challenge: Glaucoma grading from multi-modality images. arXiv 2022, arXiv:2202.06511. [Google Scholar]
- Al-Absi, H.R.; Islam, M.T.; Refaee, M.A.; Chowdhury, M.E.; Alam, T. Cardiovascular disease diagnosis from DXA scan and retinal images using deep learning. Sensors 2022, 22, 4310. [Google Scholar] [CrossRef]
- Xiong, J.; Li, F.; Song, D.; Tang, G.; He, J.; Gao, K.; Zhang, H.; Cheng, W.; Song, Y.; Lin, F.; et al. Multimodal machine learning using visual fields and peripapillary circular OCT scans in detection of glaucomatous optic neuropathy. Ophthalmology 2022, 129, 171–180. [Google Scholar] [CrossRef]
- El-Sappagh, S.; Abuhmed, T.; Islam, S.R.; Kwak, K.S. Multimodal multitask deep learning model for Alzheimer’s disease progression detection based on time series data. Neurocomputing 2020, 412, 197–215. [Google Scholar] [CrossRef]
- Rokach, L. Ensemble-based classifiers. Artif. Intell. Rev. 2010, 33, 1–39. [Google Scholar] [CrossRef]
- Moon, W.K.; Lee, Y.W.; Ke, H.H.; Lee, S.H.; Huang, C.S.; Chang, R.F. Computer-aided diagnosis of breast ultrasound images using ensemble learning from convolutional neural networks. Comput. Methods Programs Biomed. 2020, 190, 105361. [Google Scholar] [CrossRef]
- Guo, S.; Wang, L.; Chen, Q.; Wang, L.; Zhang, J.; Zhu, Y. Multimodal MRI image decision fusion-based network for glioma classification. Front. Oncol. 2022, 12, 819673. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Dai, Y.; Gao, Y.; Liu, F. Transmed: Transformers advance multi-modal medical image classification. Diagnostics 2021, 11, 1384. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Liu, S.; Zhang, L.; To, X.V.; Nasrallah, F.; Chandra, S.S. Cascaded multi-modal mixing transformers for alzheimer’s disease classification with incomplete data. NeuroImage 2023, 277, 120267. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, H.H.; Blaschko, M.B.; Saarakkala, S.; Tiulpin, A. Clinically-Inspired Multi-Agent Transformers for Disease Trajectory Forecasting from Multimodal Data. arXiv 2022, arXiv:2210.13889. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Type | Patients | Eyes |
|---|---|---|
| Total (EviRed dataset) | 444 | 875 |
| Test set (for all fusion tests) | 53 | 97 |
| Dataset 6 × 6 (for fusion of mm OCTA: Structure + Flow) | 386 | 753 |
| Dataset 15 × 15 (for fusion of mm OCTA: Structure + Flow) | 372 | 701 |
| Dataset 6 × 6 + 15 × 15 (for fusion of mm + mm OCTA) | 364 | 676 |
| Severity | Dataset 6 × 6 | Dataset 15 × 15 | Dataset 6 × 6 + 15 × 15 | Test Set |
|---|---|---|---|---|
| Absence of diabetic retinopathy | 151 | 128 | 127 | 17 |
| Mild NPDR | 76 | 69 | 68 | 12 |
| Moderate NPDR | 348 | 334 | 321 | 39 |
| Severe NPDR | 111 | 107 | 97 | 18 |
| PDR | 20 | 20 | 20 | 3 |
| PRP | 47 | 43 | 43 | 8 |
| Data Cropping Method | Kappa | AUC0 | AUC1 | AUC2 | AUC3 |
|---|---|---|---|---|---|
| Resize | 0.2913 | 0.6485 | 0.6557 | 0.6836 | 0.7074 |
| Center Crop | 0.3270 | 0.7257 | 0.7059 | 0.6850 | 0.6903 |
| Subvolume Crop | 0.4048 | 0.7596 | 0.7429 | 0.7449 | 0.8340 |
| N times Random Crop (proposed) | 0.4252 | 0.7721 | 0.7474 | 0.7519 | 0.8546 |
| Modality | Backbone | Kappa | AUC0 | AUC1 | AUC2 | AUC3 |
|---|---|---|---|---|---|---|
| ResNet | 0.4150 | 0.8375 | 0.7659 | 0.7889 | 0.8104 | |
| mm SS-OCTA—Structure | DenseNet | 0.3597 | 0.8285 | 0.7462 | 0.7368 | 0.7040 |
| EfficientNet | 0.4149 | 0.8246 | 0.7521 | 0.7438 | 0.7788 | |
| ResNet | 0.3768 | 0.7931 | 0.7653 | 0.7566 | 0.7863 | |
| mm SS-OCTA—Flow | DenseNet | 0.3399 | 0.7972 | 0.7700 | 0.7525 | 0.7653 |
| EfficientNet | 0.4085 | 0.8306 | 0.7775 | 0.7446 | 0.7150 | |
| ResNet | 0.3900 | 0.8118 | 0.7604 | 0.7462 | 0.8700 | |
| mm SS-OCTA—Structure | DenseNet | 0.3589 | 0.8251 | 0.7527 | 0.7923 | 0.8732 |
| EfficientNet | 0.3230 | 0.8046 | 0.7407 | 0.7757 | 0.8671 | |
| ResNet | 0.4189 | 0.7927 | 0.7627 | 0.7911 | 0.8774 | |
| mm SS-OCTA—Flow | DenseNet | 0.3261 | 0.7770 | 0.7517 | 0.7788 | 0.8125 |
| EfficientNet | 0.3259 | 0.7848 | 0.7557 | 0.7545 | 0.8397 |
| Fusion Method | Backbone | Kappa | AUC0 | AUC1 | AUC2 | AUC3 |
|---|---|---|---|---|---|---|
| Structure (unimodal) | ResNet | 0.4150 | 0.8375 | 0.7659 | 0.7889 | 0.8104 |
| Flow (unimodal) | ResNet | 0.3768 | 0.7931 | 0.7653 | 0.7566 | 0.7863 |
| Flow (unimodal) | EfficientNet | 0.4085 | 0.8306 | 0.7775 | 0.7446 | 0.7150 |
| Input Fusion | ResNet | 0.3849 | 0.8093 | 0.7656 | 0.7476 | 0.7886 |
| Input Fusion | EfficientNet | 0.3885 | 0.8192 | 0.7755 | 0.7496 | 0.7321 |
| Feature Fusion | ResNet + ResNet | 0.4329 | 0.8246 | 0.7763 | 0.7577 | 0.7900 |
| Feature Fusion | ResNet + EfficientNet | 0.3959 | 0.8132 | 0.7637 | 0.7023 | 0.7622 |
| Decision Fusion | ResNet + ResNet | 0.3814 | 0.8074 | 0.7757 | 0.7530 | 0.7868 |
| Decision Fusion | ResNet + EfficientNet | 0.4227 | 0.8446 | 0.7770 | 0.7500 | 0.7478 |
| Hierarchical Fusion | ResNet + ResNet | 0.4752 | 0.8462 | 0.7793 | 0.7607 | 0.8013 |
| Hierarchical Fusion | ResNet + EfficientNet | 0.4205 | 0.8206 | 0.7662 | 0.7186 | 0.7743 |
| Fusion Method | Backbone | Kappa | AUC0 | AUC1 | AUC2 | AUC3 |
|---|---|---|---|---|---|---|
| Structure (unimodal) | ResNet | 0.3900 | 0.8118 | 0.7604 | 0.7462 | 0.8700 |
| Structure (unimodal) | DenseNet | 0.3589 | 0.8251 | 0.7527 | 0.7923 | 0.8732 |
| Flow (unimodal) | ResNet | 0.4189 | 0.7927 | 0.7627 | 0.7911 | 0.8774 |
| Input Fusion | ResNet | 0.4252 | 0.7721 | 0.7475 | 0.7519 | 0.8546 |
| Input Fusion | DenseNet | 0.3286 | 0.7108 | 0.7072 | 0.7235 | 0.8175 |
| Feature Fusion | ResNet + ResNet | 0.3982 | 0.8029 | 0.7627 | 0.7876 | 0.8630 |
| Feature Fusion | DenseNet + ResNet | 0.3227 | 0.7437 | 0.7366 | 0.7546 | 0.8429 |
| Decision Fusion | ResNet + ResNet | 0.4124 | 0.7949 | 0.7688 | 0.7688 | 0.8728 |
| Decision Fusion | DenseNet + ResNet | 0.4376 | 0.8205 | 0.7583 | 0.7726 | 0.8754 |
| Hierarchical Fusion | ResNet + ResNet | 0.4430 | 0.8187 | 0.7745 | 0.7967 | 0.8786 |
| Hierarchical Fusion | DenseNet + ResNet | 0.4137 | 0.8088 | 0.7662 | 0.7794 | 0.8719 |
| Modality | Fusion Method | Kappa | AUC0 | AUC1 | AUC2 | AUC3 | Inference Time (seconds/eye) |
|---|---|---|---|---|---|---|---|
| mm SS-OCTA | Structure (unimodal) | 0.4150 | 0.8375 | 0.7659 | 0.7889 | 0.8104 | 0.9729 |
| Hierarchical Fusion | 0.4752 | 0.8462 | 0.7793 | 0.7607 | 0.8013 | 1.8041 | |
| mm SS-OCTA | Structure (unimodal) | 0.3589 | 0.8251 | 0.7527 | 0.7923 | 0.8732 | 1.6394 |
| Hierarchical Fusion | 0.4430 | 0.8187 | 0.7745 | 0.7967 | 0.8786 | 3.84655 | |
| mm SS-OCTA + mm SS-OCTA | Feature Fusion— fine-tuning | 0.4637 | 0.8469 | 0.8004 | 0.7989 | 0.8670 | 4.9233 |
| Feature Fusion— freezing layers | 0.5132 | 0.8741 | 0.7853 | 0.7555 | 0.8207 | 4.8410 | |
| Decision Fusion—max | 0.5218 | 0.8801 | 0.8027 | 0.8083 | 0.8911 | 4.0686 | |
| Decision Fusion—avg (proposed hybrid fusion) | 0.5593 | 0.8868 | 0.8276 | 0.8367 | 0.9070 | 3.9679 |
| Modality | Backbone | Kappa | AUC0 | AUC1 | AUC2 | AUC3 |
|---|---|---|---|---|---|---|
| mm SS-OCTA—Structure | ViT | 0.1122 | 0.6774 | 0.6490 | 0.4900 | 0.5912 |
| mm SS-OCTA—Flow | ViT | 0.0854 | 0.6696 | 0.6474 | 0.5487 | 0.5843 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; El Habib Daho, M.; Conze, P.-H.; Zeghlache, R.; Le Boité, H.; Bonnin, S.; Cosette, D.; Magazzeni, S.; Lay, B.; Le Guilcher, A.; et al. Hybrid Fusion of High-Resolution and Ultra-Widefield OCTA Acquisitions for the Automatic Diagnosis of Diabetic Retinopathy. Diagnostics 2023, 13, 2770. https://doi.org/10.3390/diagnostics13172770
Li Y, El Habib Daho M, Conze P-H, Zeghlache R, Le Boité H, Bonnin S, Cosette D, Magazzeni S, Lay B, Le Guilcher A, et al. Hybrid Fusion of High-Resolution and Ultra-Widefield OCTA Acquisitions for the Automatic Diagnosis of Diabetic Retinopathy. Diagnostics. 2023; 13(17):2770. https://doi.org/10.3390/diagnostics13172770
Chicago/Turabian StyleLi, Yihao, Mostafa El Habib Daho, Pierre-Henri Conze, Rachid Zeghlache, Hugo Le Boité, Sophie Bonnin, Deborah Cosette, Stephanie Magazzeni, Bruno Lay, Alexandre Le Guilcher, and et al. 2023. "Hybrid Fusion of High-Resolution and Ultra-Widefield OCTA Acquisitions for the Automatic Diagnosis of Diabetic Retinopathy" Diagnostics 13, no. 17: 2770. https://doi.org/10.3390/diagnostics13172770
APA StyleLi, Y., El Habib Daho, M., Conze, P.-H., Zeghlache, R., Le Boité, H., Bonnin, S., Cosette, D., Magazzeni, S., Lay, B., Le Guilcher, A., Tadayoni, R., Cochener, B., Lamard, M., & Quellec, G. (2023). Hybrid Fusion of High-Resolution and Ultra-Widefield OCTA Acquisitions for the Automatic Diagnosis of Diabetic Retinopathy. Diagnostics, 13(17), 2770. https://doi.org/10.3390/diagnostics13172770