


DSMRI: Domain Shift Analyzer for Multi-Center MRI Datasets


Abstract
:1. Introduction
2. Related Works
2.1. Domain Shift in Multi-Center MRI Datasets
2.2. Quality Assessment Methods for MRI Data
2.3. Existing Domain Shift Analysis Tools
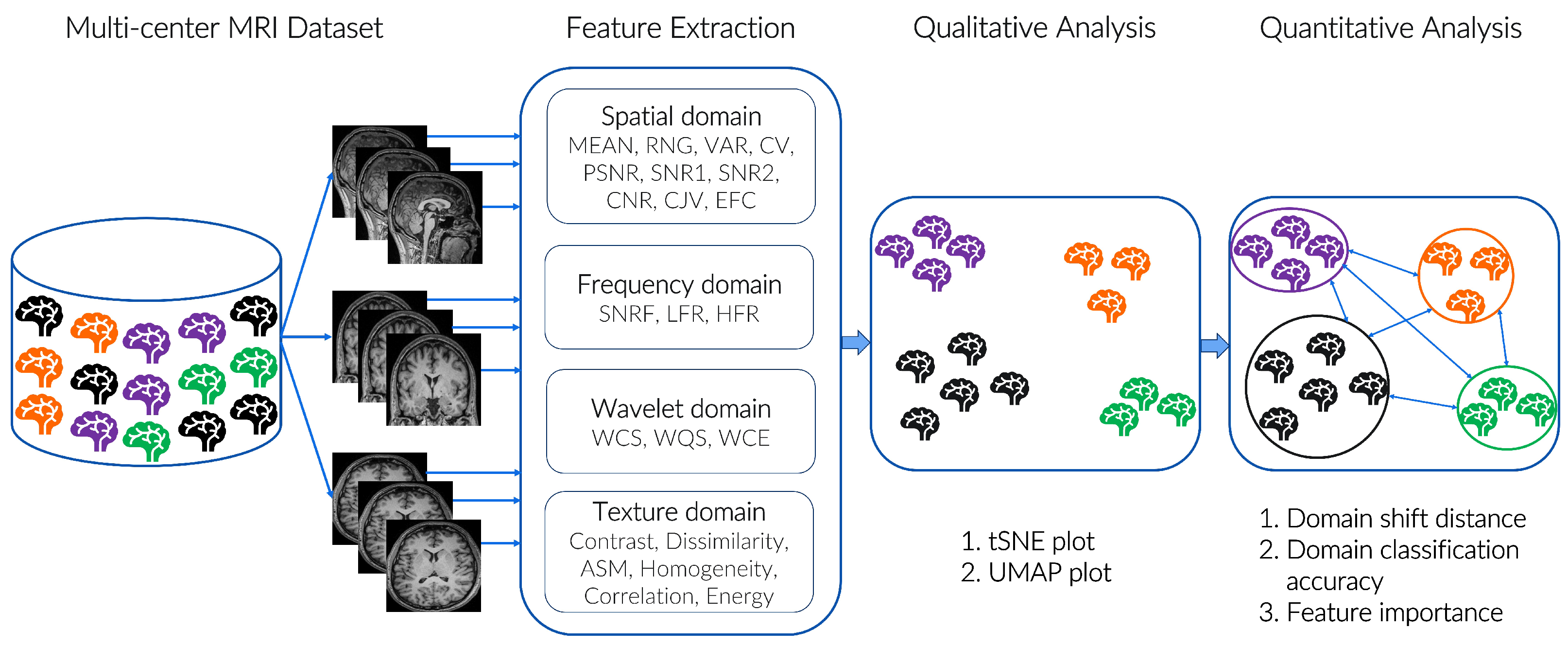
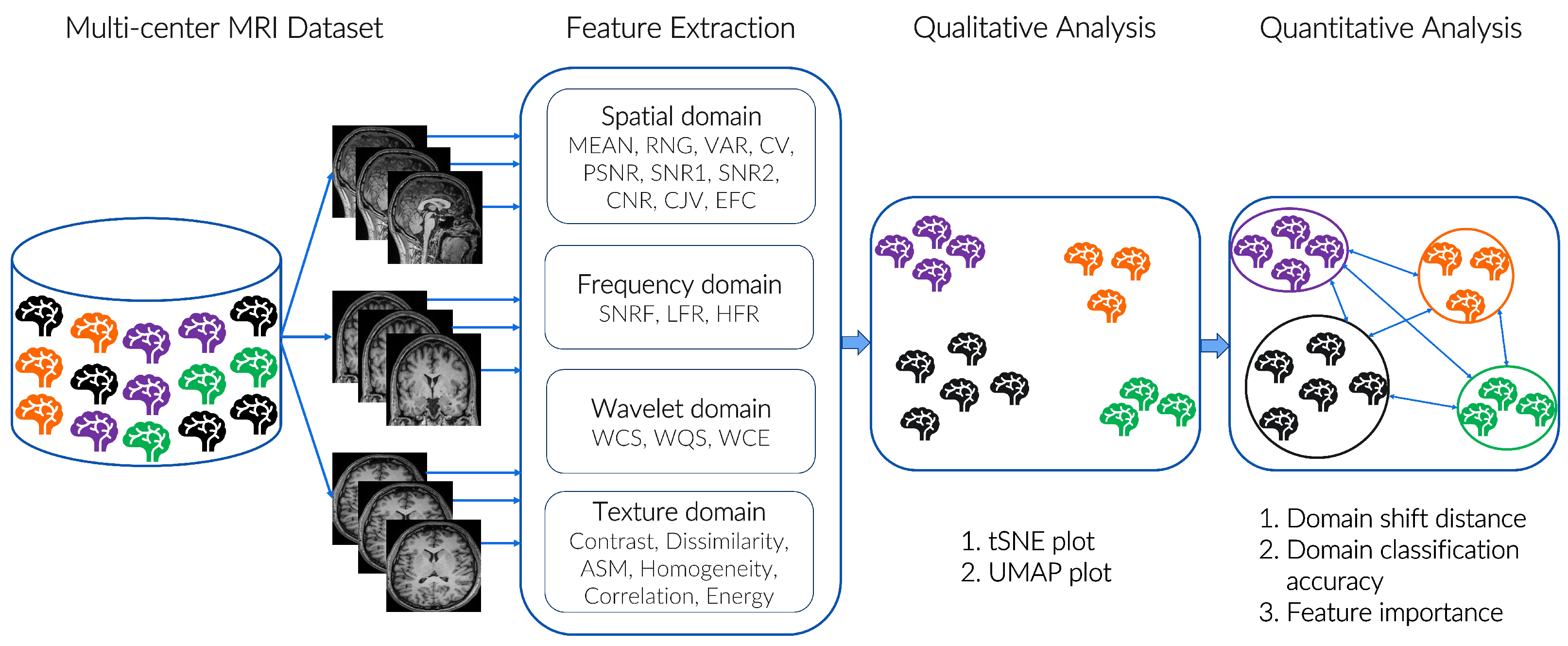
3. Materials and Methods
3.1. Datasets
3.2. Proposed Features
3.2.1. Spatial Domain Features
3.2.2. Frequency Domain Features
3.2.3. Wavelet Domain Features
3.2.4. Texture Domain Features
4. Experimental Analysis
4.1. Evaluation Metrics
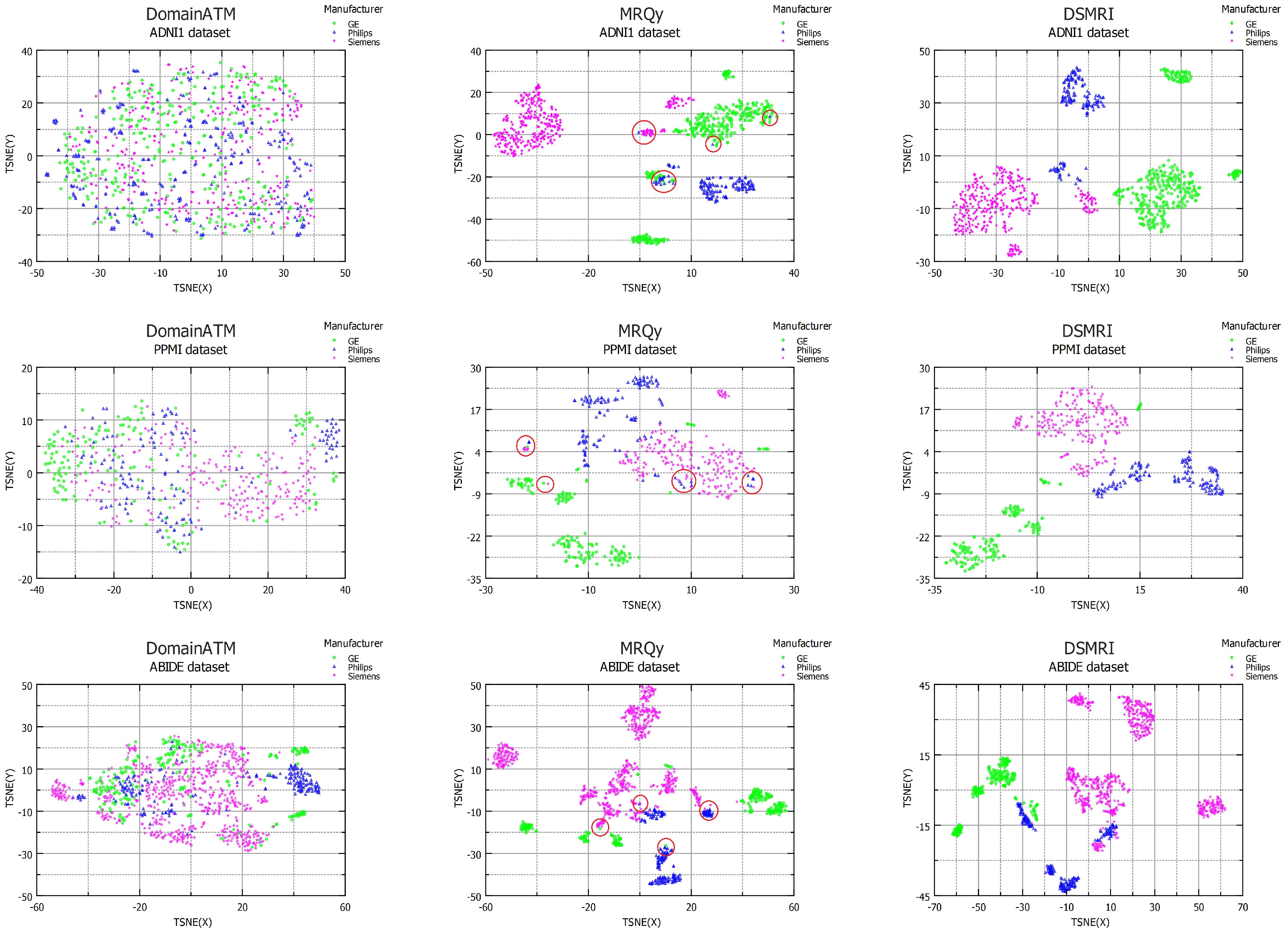
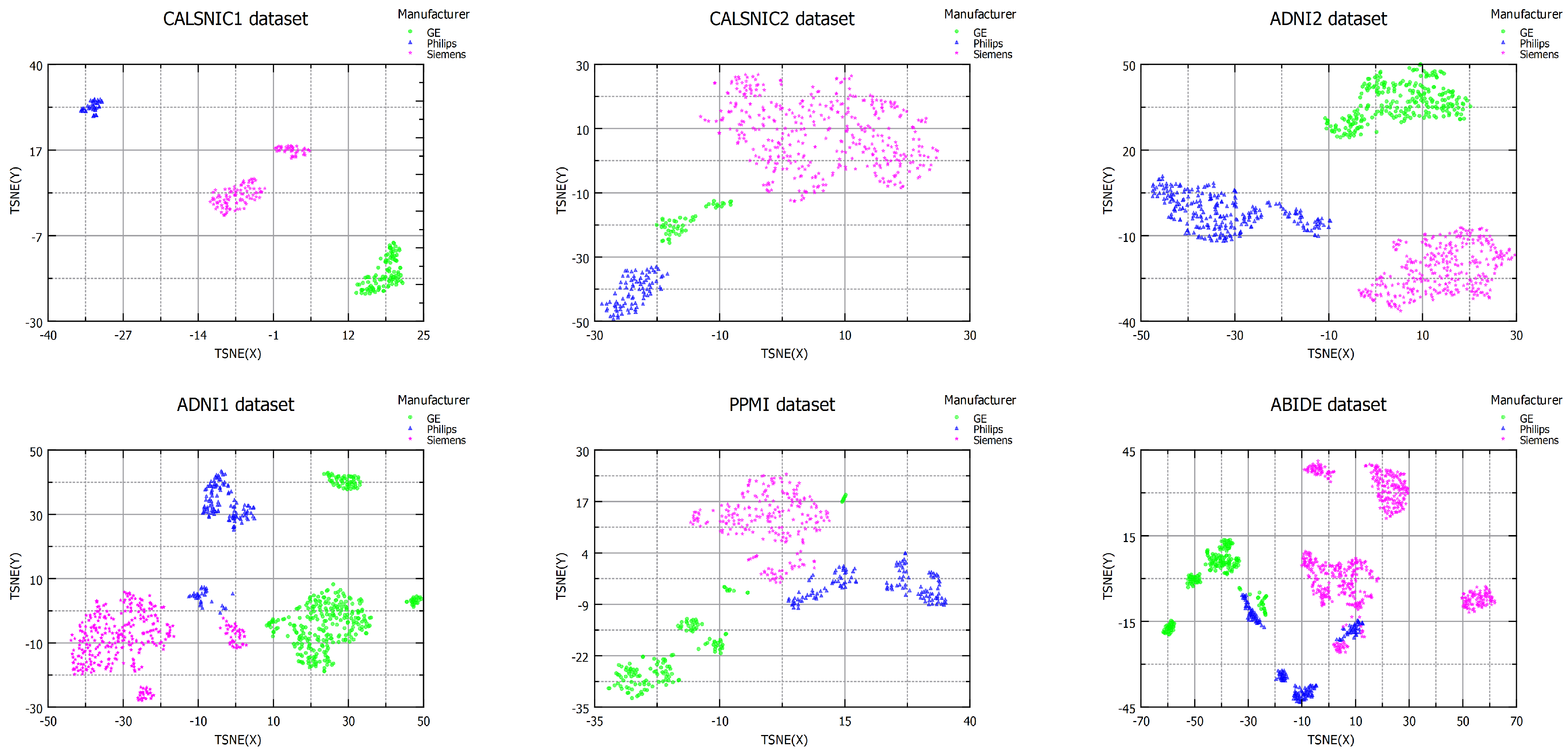
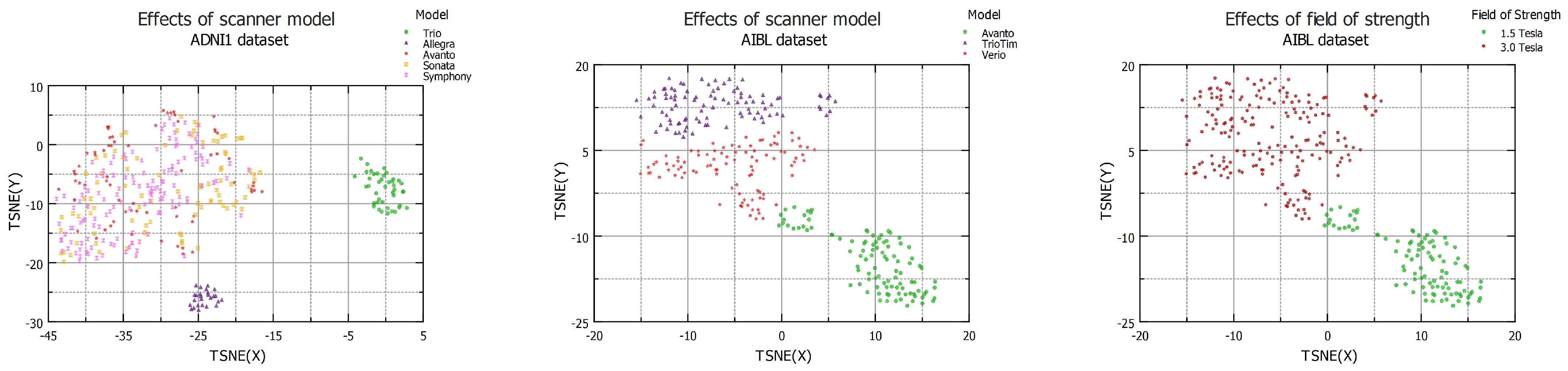
4.1.1. Qualitative Analysis
4.1.2. Quantitative Analysis
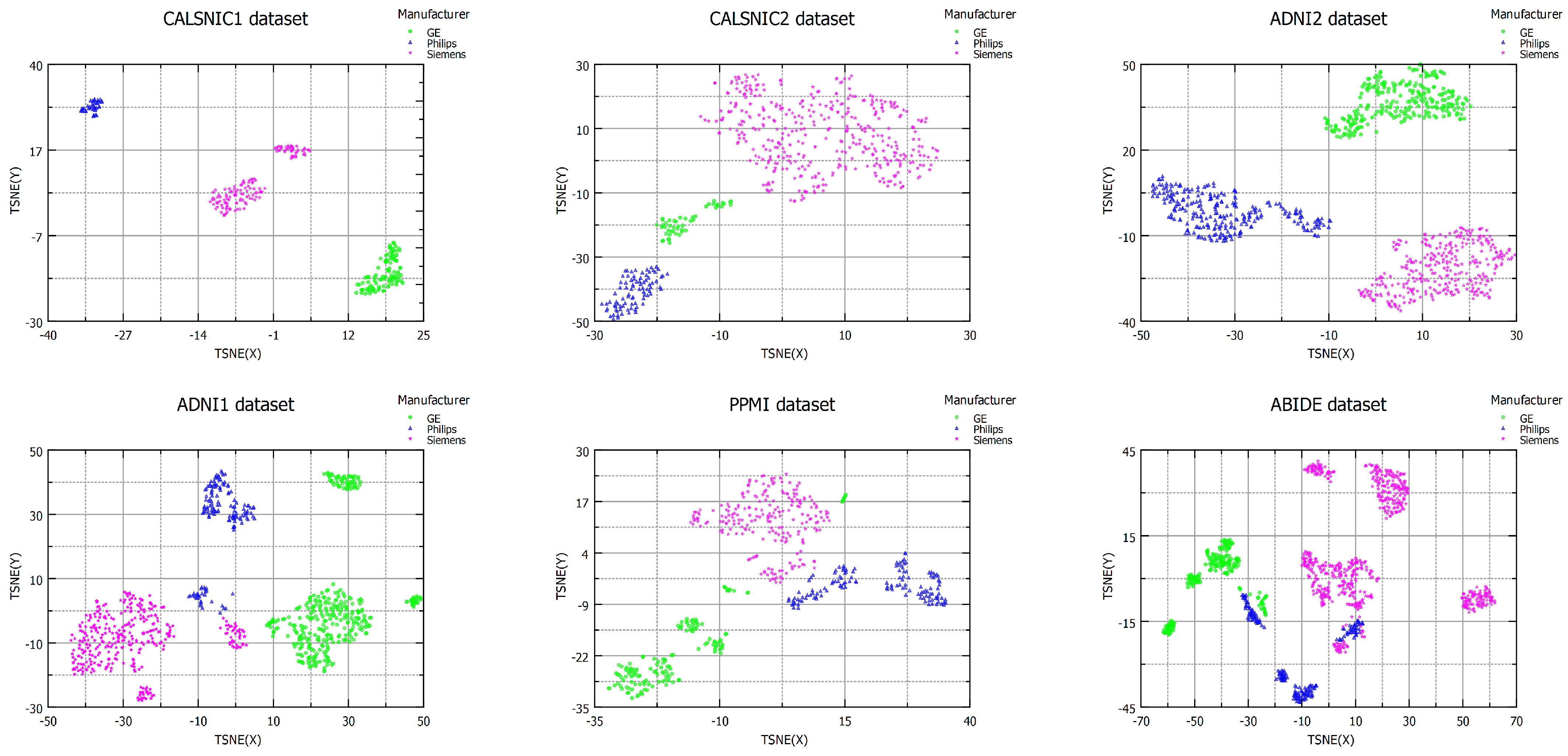
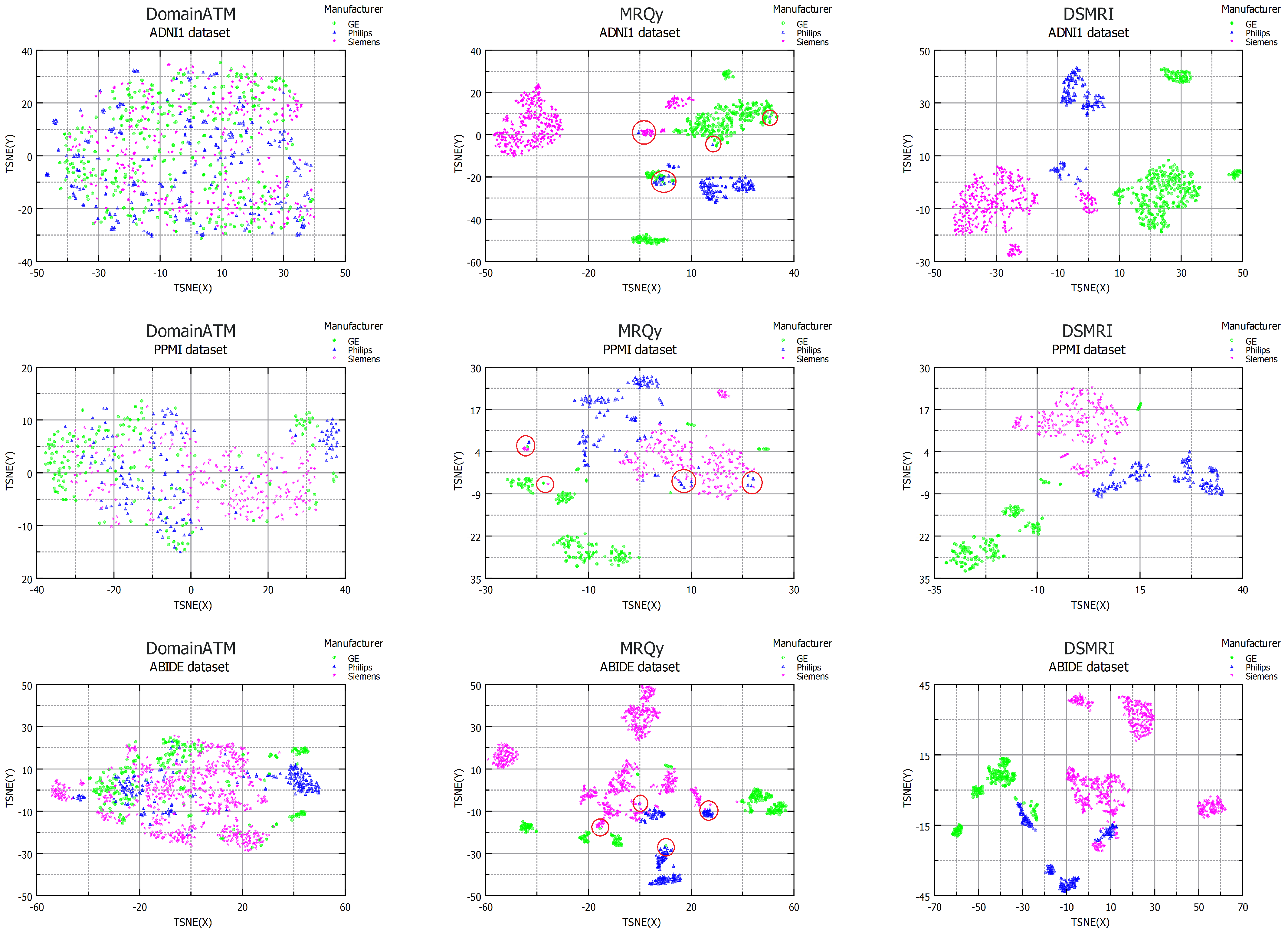
4.2. Domain Shift in Multi-Center Datasets
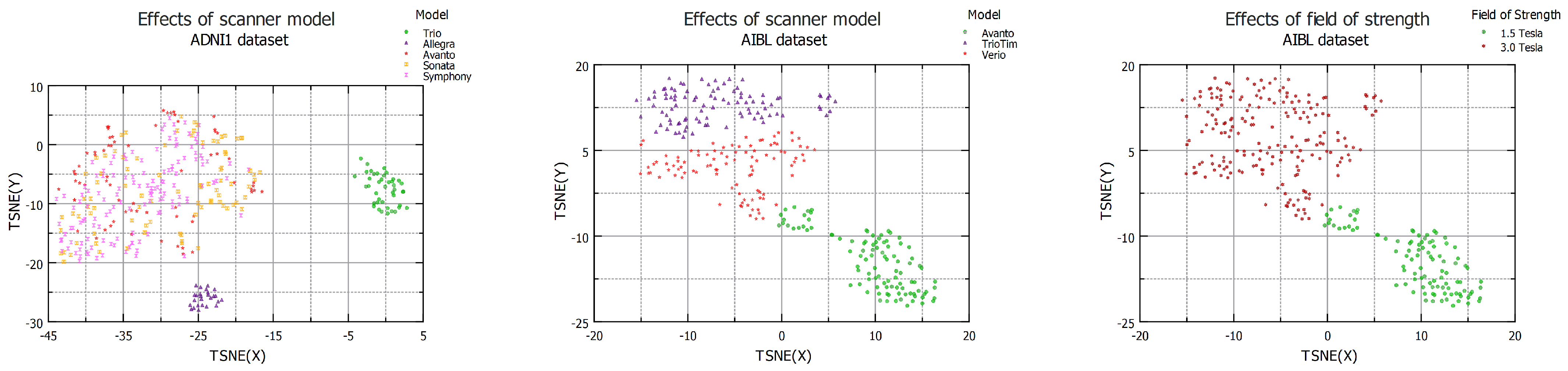
4.3. Effects of Scanner Model
4.4. Effects of Resolution
4.5. Effects of T2-Weighted and FLAIR Images
4.6. Effects of Processed Data
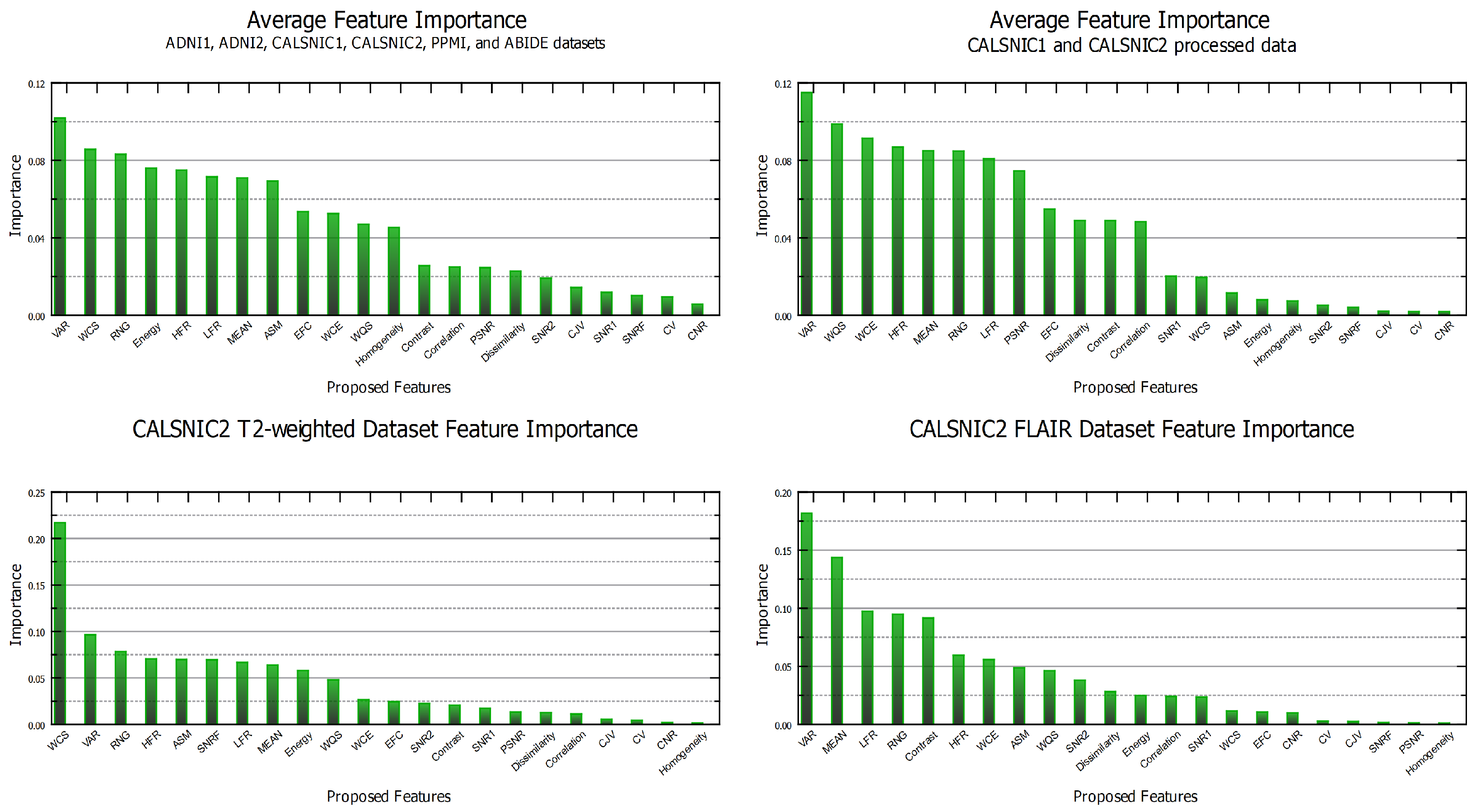
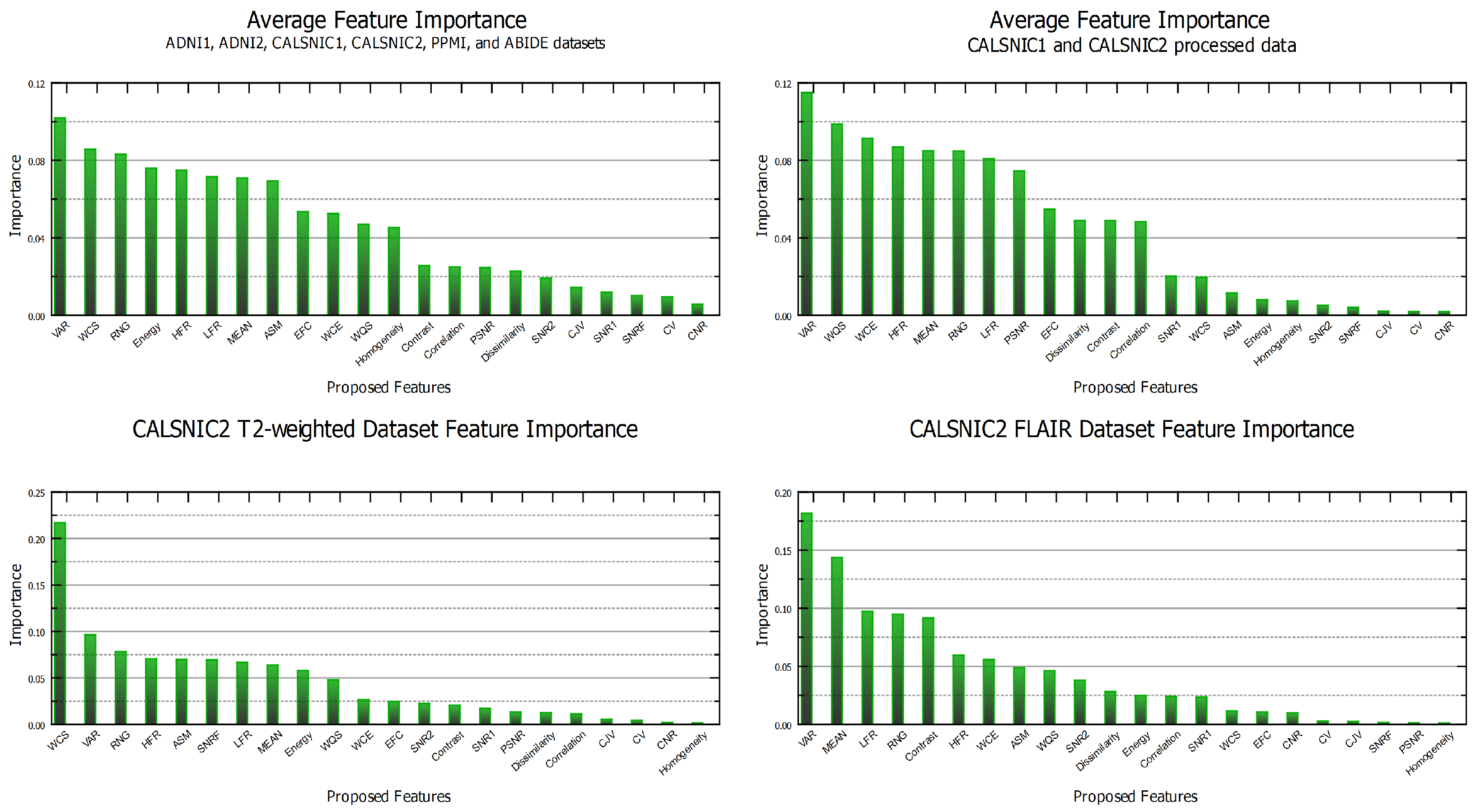
4.7. Feature Importance
4.8. Comparison
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kushol, R.; Masoumzadeh, A.; Huo, D.; Kalra, S.; Yang, Y.H. Addformer: Alzheimer’s disease detection from structural Mri using fusion transformer. In Proceedings of the IEEE 19th International Symposium on Biomedical Imaging, Kolkata, India, 28–31 March 2022; pp. 1–5. [Google Scholar]
- El-Latif, A.A.A.; Chelloug, S.A.; Alabdulhafith, M.; Hammad, M. Accurate Detection of Alzheimer’s Disease Using Lightweight Deep Learning Model on MRI Data. Diagnostics 2023, 13, 1216. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Lee, E.K.; Song, C.J.; Sohn, E. Iron Rim Lesions as a Specific and Prognostic Biomarker of Multiple Sclerosis: 3T-Based Susceptibility-Weighted Imaging. Diagnostics 2023, 13, 1866. [Google Scholar] [CrossRef] [PubMed]
- Kushol, R.; Luk, C.C.; Dey, A.; Benatar, M.; Briemberg, H.; Dionne, A.; Dupré, N.; Frayne, R.; Genge, A.; Gibson, S.; et al. SF2Former: Amyotrophic lateral sclerosis identification from multi-center MRI data using spatial and frequency fusion transformer. Comput. Med Imaging Graph. 2023, 108, 102279. [Google Scholar] [CrossRef] [PubMed]
- Quinonero-Candela, J.; Sugiyama, M.; Schwaighofer, A.; Lawrence, N.D. Dataset Shift in Machine Learning; MIT Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Botvinik-Nezer, R.; Wager, T.D. Reproducibility in neuroimaging analysis: Challenges and solutions. Biol. Psychiatry: Cogn. Neurosci. Neuroimaging 2023, 8, 780–788. [Google Scholar] [CrossRef] [PubMed]
- Guan, H.; Liu, M. Domain adaptation for medical image analysis: A survey. IEEE Trans. Biomed. Eng. 2021, 69, 1173–1185. [Google Scholar] [CrossRef] [PubMed]
- Kushol, R.; Frayne, R.; Graham, S.J.; Wilman, A.H.; Kalra, S.; Yang, Y.H. Domain adaptation of MRI scanners as an alternative to MRI harmonization. In Proceedings of the 5th MICCAI Workshop on Domain Adaptation and Representation Transfer, Vancouver, BC, Canada, 12 October 2023. [Google Scholar]
- Gebre, R.K.; Senjem, M.L.; Raghavan, S.; Schwarz, C.G.; Gunter, J.L.; Hofrenning, E.I.; Reid, R.I.; Kantarci, K.; Graff-Radford, J.; Knopman, D.S.; et al. Cross–scanner harmonization methods for structural MRI may need further work: A comparison study. NeuroImage 2023, 269, 119912. [Google Scholar] [CrossRef] [PubMed]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar]
- Dadar, M.; Duchesne, S.; CCNA Group and the CIMA-Q Group. Reliability assessment of tissue classification algorithms for multi-center and multi-scanner data. NeuroImage 2020, 217, 116928. [Google Scholar] [CrossRef]
- Tian, D.; Zeng, Z.; Sun, X.; Tong, Q.; Li, H.; He, H.; Gao, J.H.; He, Y.; Xia, M. A deep learning-based multisite neuroimage harmonization framework established with a traveling-subject dataset. NeuroImage 2022, 257, 119297. [Google Scholar] [CrossRef]
- Lee, H.; Nakamura, K.; Narayanan, S.; Brown, R.A.; Arnold, D.L.; Alzheimer’s Disease Neuroimaging Initiative. Estimating and accounting for the effect of MRI scanner changes on longitudinal whole-brain volume change measurements. Neuroimage 2019, 184, 555–565. [Google Scholar] [CrossRef] [PubMed]
- Glocker, B.; Robinson, R.; Castro, D.C.; Dou, Q.; Konukoglu, E. Machine learning with multi-site imaging data: An empirical study on the impact of scanner effects. arXiv 2019, arXiv:1910.04597. [Google Scholar]
- Panman, J.L.; To, Y.Y.; van der Ende, E.L.; Poos, J.M.; Jiskoot, L.C.; Meeter, L.H.; Dopper, E.G.; Bouts, M.J.; van Osch, M.J.; Rombouts, S.A.; et al. Bias introduced by multiple head coils in MRI research: An 8 channel and 32 channel coil comparison. Front. Neurosci. 2019, 13, 729. [Google Scholar] [CrossRef] [PubMed]
- Esteban, O.; Birman, D.; Schaer, M.; Koyejo, O.O.; Poldrack, R.A.; Gorgolewski, K.J. MRIQC: Advancing the automatic prediction of image quality in MRI from unseen sites. PLoS ONE 2017, 12, e0184661. [Google Scholar] [CrossRef] [PubMed]
- Keshavan, A.; Datta, E.; McDonough, I.M.; Madan, C.R.; Jordan, K.; Henry, R.G. Mindcontrol: A web application for brain segmentation quality control. NeuroImage 2018, 170, 365–372. [Google Scholar] [CrossRef] [PubMed]
- Osadebey, M.E.; Pedersen, M.; Arnold, D.L.; Wendel-Mitoraj, K.E.; Alzheimer’s Disease Neuroimaging Initiative, f.t. Standardized quality metric system for structural brain magnetic resonance images in multi-center neuroimaging study. BMC Med. Imaging 2018, 18, 31. [Google Scholar] [CrossRef] [PubMed]
- Jang, J.; Bang, K.; Jang, H.; Hwang, D.; Initiative, A.D.N. Quality evaluation of no-reference MR images using multidirectional filters and image statistics. Magn. Reson. Med. 2018, 80, 914–924. [Google Scholar] [CrossRef] [PubMed]
- Esteban, O.; Blair, R.W.; Nielson, D.M.; Varada, J.C.; Marrett, S.; Thomas, A.G.; Poldrack, R.A.; Gorgolewski, K.J. Crowdsourced MRI quality metrics and expert quality annotations for training of humans and machines. Sci. Data 2019, 6, 30. [Google Scholar] [CrossRef]
- Oszust, M.; Piórkowski, A.; Obuchowicz, R. No-reference image quality assessment of magnetic resonance images with high-boost filtering and local features. Magn. Reson. Med. 2020, 84, 1648–1660. [Google Scholar] [CrossRef]
- Bottani, S.; Burgos, N.; Maire, A.; Wild, A.; Ströer, S.; Dormont, D.; Colliot, O.; APPRIMAGE Study Group. Automatic quality control of brain T1-weighted magnetic resonance images for a clinical data warehouse. Med. Image Anal. 2022, 75, 102219. [Google Scholar] [CrossRef]
- Stępień, I.; Oszust, M. A Brief Survey on No-Reference Image Quality Assessment Methods for Magnetic Resonance Images. J. Imaging 2022, 8, 160. [Google Scholar] [CrossRef] [PubMed]
- Sadri, A.R.; Janowczyk, A.; Zhou, R.; Verma, R.; Beig, N.; Antunes, J.; Madabhushi, A.; Tiwari, P.; Viswanath, S.E. MRQy—An open-source tool for quality control of MR imaging data. Med Phys. 2020, 47, 6029–6038. [Google Scholar] [CrossRef] [PubMed]
- Guan, H.; Liu, M. DomainATM: Domain Adaptation Toolbox for Medical Data Analysis. NeuroImage 2023, 268, 119863. [Google Scholar] [CrossRef] [PubMed]
- Jack, C.R., Jr.; Bernstein, M.A.; Fox, N.C.; Thompson, P.; Alexander, G.; Harvey, D.; Borowski, B.; Britson, P.J.; Whitwell, J.L.; Ward, C.; et al. The Alzheimer’s disease neuroimaging initiative (ADNI): MRI methods. J. Magn. Reson. Imaging 2008, 27, 685–691. [Google Scholar] [CrossRef] [PubMed]
- Ellis, K.A.; Bush, A.I.; Darby, D.; De Fazio, D.; Foster, J.; Hudson, P.; Lautenschlager, N.T.; Lenzo, N.; Martins, R.N.; Maruff, P.; et al. The Australian Imaging, Biomarkers and Lifestyle (AIBL) study of aging: Methodology and baseline characteristics of 1112 individuals recruited for a longitudinal study of Alzheimer’s disease. Int. Psychogeriatr. 2009, 21, 672–687. [Google Scholar] [CrossRef] [PubMed]
- Marek, K.; Jennings, D.; Lasch, S.; Siderowf, A.; Tanner, C.; Simuni, T.; Coffey, C.; Kieburtz, K.; Flagg, E.; Chowdhury, S.; et al. The Parkinson progression marker initiative (PPMI). Prog. Neurobiol. 2011, 95, 629–635. [Google Scholar] [CrossRef] [PubMed]
- Di Martino, A.; Yan, C.G.; Li, Q.; Denio, E.; Castellanos, F.X.; Alaerts, K.; Anderson, J.S.; Assaf, M.; Bookheimer, S.Y.; Dapretto, M.; et al. The autism brain imaging data exchange: Towards a large-scale evaluation of the intrinsic brain architecture in autism. Mol. Psychiatry 2014, 19, 659–667. [Google Scholar] [CrossRef]
- Kalra, S.; Khan, M.; Barlow, L.; Beaulieu, C.; Benatar, M.; Briemberg, H.; Chenji, S.; Clua, M.G.; Das, S.; Dionne, A.; et al. The Canadian ALS Neuroimaging Consortium (CALSNIC)-a multicentre platform for standardized imaging and clinical studies in ALS. MedRxiv 2020. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Y.; Xuan, W.; Kao, E.; Cao, P.; Tian, B.; Ordovas, K.; Saloner, D.; Liu, J. Fully automatic segmentation of 4D MRI for cardiac functional measurements. Med. Phys. 2019, 46, 180–189. [Google Scholar] [CrossRef]
- Magnotta, V.A.; Friedman, L.; BIRN, F. Measurement of signal-to-noise and contrast-to-noise in the fBIRN multicenter imaging study. J. Digit. Imaging 2006, 19, 140–147. [Google Scholar] [CrossRef]
- Hui, C.; Zhou, Y.X.; Narayana, P. Fast algorithm for calculation of inhomogeneity gradient in magnetic resonance imaging data. J. Magn. Reson. Imaging 2010, 32, 1197–1208. [Google Scholar] [CrossRef] [PubMed]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed]
- Lee, G.; Gommers, R.; Waselewski, F.; Wohlfahrt, K.; O’Leary, A. PyWavelets: A Python package for wavelet analysis. J. Open Source Softw. 2019, 4, 1237. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Gadkari, D. Image quality analysis using GLCM. 2004. Available online: https://stars.library.ucf.edu/etd/187/ (accessed on 5 May 2023).
- Van der Walt, S.; Schönberger, J.L.; Nunez-Iglesias, J.; Boulogne, F.; Warner, J.D.; Yager, N.; Gouillart, E.; Yu, T. scikit-image: Image processing in Python. PeerJ 2014, 2, e453. [Google Scholar] [CrossRef] [PubMed]
- Fischl, B. FreeSurfer. Neuroimage 2012, 62, 774–781. [Google Scholar] [CrossRef]
- Jenkinson, M.; Beckmann, C.F.; Behrens, T.E.; Woolrich, M.W.; Smith, S.M. Fsl. Neuroimage 2012, 62, 782–790. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset (#Total) | Group | MRI Scanner Manufacturer | |||||
|---|---|---|---|---|---|---|---|
| GE | Siemens | Philips | |||||
| Sex | Age | Sex | Age | Sex | Age | ||
| (M/F) | (Mean ± Std) | (M/F) | (Mean ± Std) | (M/F) | (Mean ± Std) | ||
| ADNI1 | AD | 85/85 | 75.5 ± 7.7 | 85/85 | 75.0 ± 7.2 | 43/33 | 75.7 ± 7.0 |
| (900) | HC | 85/85 | 75.1 ± 5.7 | 85/85 | 75.9 ± 5.9 | 90/54 | 75.4 ± 5.2 |
| ADNI2 | AD | 61/40 | 75.0 ± 8.5 | 90/57 | 75.1 ± 7.8 | 45/58 | 74.5 ± 7.3 |
| (844) | HC | 64/90 | 74.3 ± 5.9 | 92/88 | 74.0 ± 6.4 | 68/91 | 75.6 ± 6.4 |
| AIBL | AD | - | - | 28/45 | 73.6 ± 8.0 | - | - |
| (300) | HC | - | - | 107/120 | 72.9 ± 6.6 | - | - |
| PPMI | PD | 82/37 | 61.6 ± 9.7 | 78/46 | 63.0 ± 9.8 | 68/37 | 61.6 ± 9.9 |
| (520) | HC | 17/17 | 59.6 ± 13.3 | 71/34 | 59.6 ± 10.5 | 20/13 | 59.7 ± 11.2 |
| ABIDE | ASD | 83/15 | 12.8 ± 2.6 | 280/40 | 16.8 ± 8.2 | 79/7 | 18.6 ± 9.7 |
| (1060) | HC | 91/27 | 13.9 ± 3.6 | 275/55 | 17.1 ± 7.8 | 94/14 | 17.6 ± 8.4 |
| CALSNIC1 | ALS | 21/25 | 57.0 ± 11.4 | 43/28 | 59.6 ± 10.8 | 17/1 | 58.1 ± 9.0 |
| (281) | HC | 23/33 | 50.5 ± 11.9 | 38/28 | 57.2 ± 8.1 | 6/18 | 53.1 ± 8.4 |
| CALSNIC2 | ALS | 14/4 | 54.0 ± 11.8 | 124/65 | 60.1 ± 10.2 | 29/19 | 62.4 ± 8.2 |
| (545) | HC | 18/13 | 60.1 ± 8.8 | 120/101 | 54.9 ± 10.5 | 10/28 | 61.7 ± 10.8 |
| Type | Metric | Description |
|---|---|---|
| Spatial domain | MEAN | Mean intensity of the foreground. |
| RNG | Intensity range of the foreground. | |
| VAR | Intensity variance of the foreground. | |
| CV | Coefficient of Variation to detect shadowing and inhomogeneity artifacts [32]. | |
| PSNR | Peak Signal-to-Noise Ratio of the foreground. | |
| SNR1 | Signal to Noise Ratio of foreground SD and background SD [25]. | |
| SNR2 | Signal-to-Noise Ratio of foreground patch mean and background SD [17]. | |
| CNR | Contrast to Noise Ratio to detect shadowing and noise artifacts [33]. Higher values indicate better quality. | |
| CJV | Coefficient of Joint Variation between the foreground and background to detect aliasing and inhomogeneity artifacts [34]. Higher values also indicate heavy head motion. | |
| EFC | Entropy Focus Criterion to detect motion artifacts. An indication of ghosting and blurring induced by head motion [17]. Lower values indicate better quality. | |
| Frequency domain | SNRF | Signal-to-Noise Ratio in the Frequency domain, which can be calculated by taking the ratio of the power in the signal to the power in the noise. |
| LFR | Low Frequency Response, which measures the ability of the MRI scan to capture low- frequency information in the image. | |
| HFR | High Frequency Response, which measures the ability of the MRI scan to capture high- frequency information in the image. | |
| Wavelet domain | WCS | Wavelet Coefficient Sparsity measures the amount of sparse information in the wavelet coefficients, which can indicate the presence of artifacts or inhomogeneities. |
| WQS | Wavelet-based Quality Score uses the wavelet transform to analyze the spatial frequency content of the image and calculates a quality score based on the magnitude and phase of the wavelet coefficients. | |
| WCE | Wavelet Coefficient Energy measures the amount of energy present in the wavelet coefficients, which can indicate the presence of artifacts or inhomogeneities. | |
| Texture domain | Contrast | Measures the local intensity variations between neighboring pixels. High contrast values indicate large intensity differences, while low indicate more uniform regions. |
| Dissimilarity | Calculates the average absolute difference between the pixel intensities in the GLCM. It quantifies the amount of local variation in the texture. | |
| ASM | Angular Second Moment measures the uniformity of the intensity distribution in the image and is often used to describe the texture of the tissue. | |
| Homogeneity | Measures the closeness of the distribution of elements in the GLCM matrix to the diagonal elements, indicating the level of local homogeneity. | |
| Correlation | Represents the linear dependency between pixel intensities in the image and measures how correlated the pixels are in a given direction. | |
| Energy | Reflects the overall uniformity in the image. It is calculated as the sum of the squared elements in the GLCM. |
| Dataset | Domain Shift Distance | Domain Classification Accuracy | ||
|---|---|---|---|---|
| GE vs. Siemens | GE vs. Philips | Philips vs. Siemens | GE vs. Siemens vs. Philips | |
| ADNI1 | 2.03 | 0.99 | 3.01 | SVM = 0.99 RF = 1.00 |
| ADNI2 | 18.06 | 4.31 | 7.72 | SVM = 0.95 RF = 1.00 |
| CALSNIC1 | 31.60 | 369.34 | 105.59 | SVM = 0.99 RF = 1.00 |
| CALSNIC2 | 3.79 | 2.23 | 9.97 | SVM = 0.99 RF = 0.99 |
| PPMI | 1.35 | 2.02 | 1.19 | SVM = 0.91 RF = 0.98 |
| ABIDE | 2.68 | 1.78 | 2.30 | SVM = 0.93 RF = 0.99 |
| Dataset | Domain Shift Distance | Domain Classification Accuracy | ||
|---|---|---|---|---|
| Model 1 vs. Model 2 | Model 1 vs. Model 3 | Model 2 vs. Model 3 | Model 1 vs. Model 2 vs. Model 3 | |
| ADNI1 | 4.82 | 1.80 | 6.82 | SVM = 0.99 RF = 1.00 |
| AIBL | 5.02 | 2.62 | 0.92 | SVM = 0.97 RF = 0.98 |
| Dataset | Domain Shift Distance Low Resolution vs. High Resolution | Domain Classification Accuracy Low Resolution vs. High Resolution |
|---|---|---|
| CALSNIC2 Philips | 7.38 | SVM = 1.00 RF = 1.00 |
| CALSNIC2 Siemens | 8.27 | SVM = 1.00 RF = 1.00 |
| Dataset | Domain Shift Distance | Domain Classification Accuracy | ||
|---|---|---|---|---|
| GE vs. Siemens | GE vs. Philips | Philips vs. Siemens | GE vs. Siemens vs. Philips | |
| CALSNIC2 T2-weighted | 143.75 | 203.98 | 130.39 | SVM = 1.00 RF = 1.00 |
| CALSNIC2 FLAIR | 9.57 | 6.08 | 41.73 | SVM = 0.98 RF = 0.99 |
| Dataset | Domain Shift Distance | Domain Classification Accuracy | ||
|---|---|---|---|---|
| GE vs. Siemens | GE vs. Philips | Philips vs. Siemens | GE vs. Siemens vs. Philips | |
| CALSNIC1 Skull-stripped | 37.86 | 13.29 | 150.25 | SVM = 1.00 RF = 1.00 |
| CALSNIC1 MNI-152 | 53.97 | 3.54 | 250.46 | SVM = 1.00 RF = 1.00 |
| CALSNIC2 Skull-stripped | 7.88 | 5.90 | 39.92 | SVM = 0.99 RF = 0.99 |
| CALSNIC2 MNI-152 | 4.16 | 6.21 | 77.24 | SVM = 0.98 RF = 0.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kushol, R.; Wilman, A.H.; Kalra, S.; Yang, Y.-H. DSMRI: Domain Shift Analyzer for Multi-Center MRI Datasets. Diagnostics 2023, 13, 2947. https://doi.org/10.3390/diagnostics13182947
Kushol R, Wilman AH, Kalra S, Yang Y-H. DSMRI: Domain Shift Analyzer for Multi-Center MRI Datasets. Diagnostics. 2023; 13(18):2947. https://doi.org/10.3390/diagnostics13182947
Chicago/Turabian StyleKushol, Rafsanjany, Alan H. Wilman, Sanjay Kalra, and Yee-Hong Yang. 2023. "DSMRI: Domain Shift Analyzer for Multi-Center MRI Datasets" Diagnostics 13, no. 18: 2947. https://doi.org/10.3390/diagnostics13182947
APA StyleKushol, R., Wilman, A. H., Kalra, S., & Yang, Y.-H. (2023). DSMRI: Domain Shift Analyzer for Multi-Center MRI Datasets. Diagnostics, 13(18), 2947. https://doi.org/10.3390/diagnostics13182947