
Reinforcement-Learning-Based Localization of Hippocampus for Alzheimer’s Disease Detection

Abstract
:1. Introduction
- Introduction of a novel reinforcement-learning-based algorithm for localizing the hippocampal region in structural MRIs.
- Application of an integrated loss function combining cross-entropy and contrastive loss to effectively train the classifier model.
- Utilization of a deep Q-network (DQN) and convolutional neural network (CNN) framework for classification, which involves the use of a single optimal slice extracted from each subject’s 3D sMRI, thereby reducing the complexity while still providing comparable results.
- Comparison of the model’s performance with that of other 2D CNN-based supervised models trained on ground truth hippocampal masks.
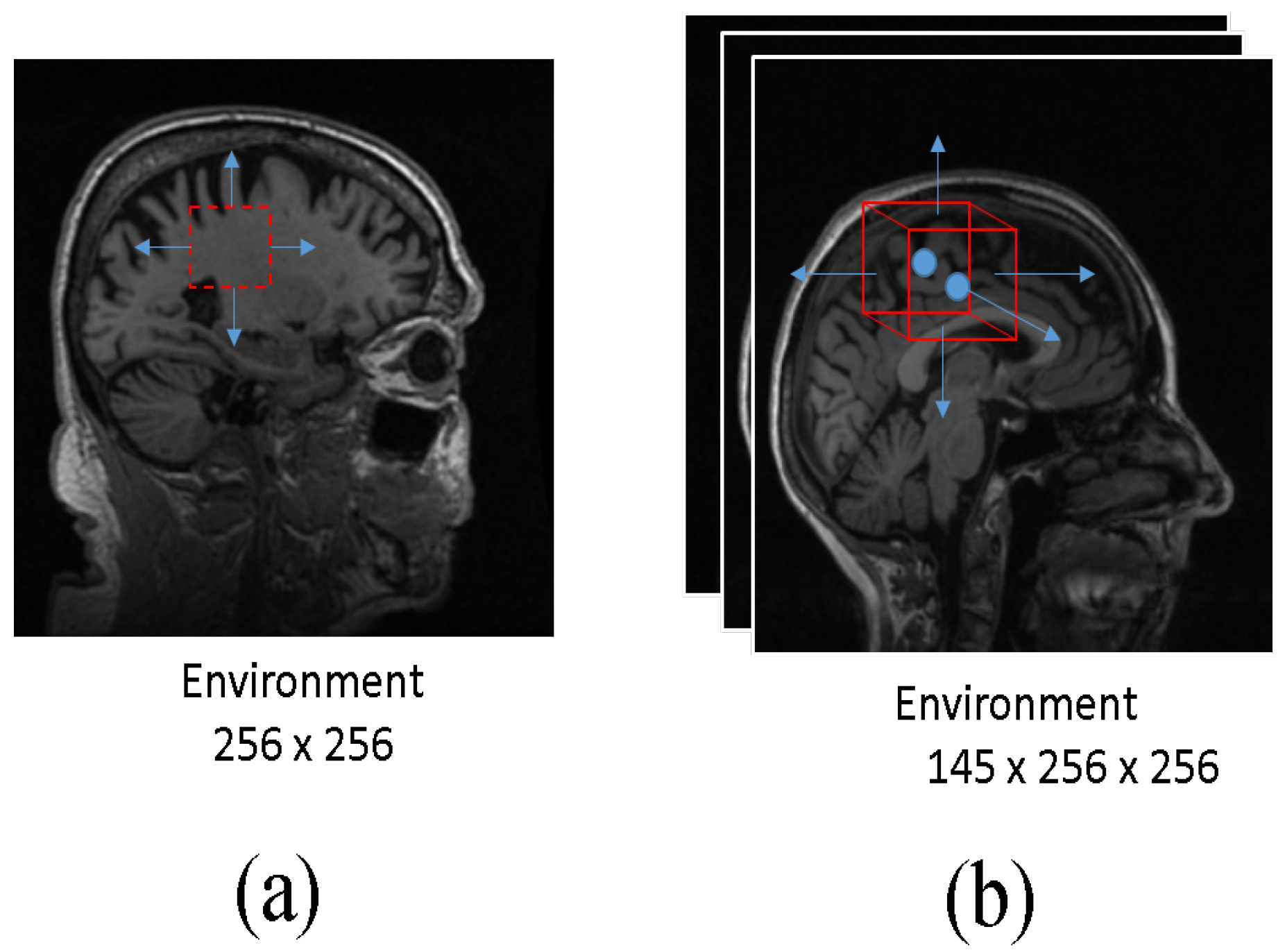
2. Methodology
2.1. Dataset and Preprocessing
2.2. Proposed Method
3. Experimental Setup
3.1. Designed Actions
3.2. Reward Computation
3.3. Deep Q-Network Setup
3.4. Model Training Protocol
3.5. Evaluation Metric
4. Results
5. Discussion
5.1. Comparative Analysis of Existing Hippocampus Localization Methods
5.2. Ablation Study: Episode Termination
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| RL | Reinforcement Learning |
| DL | Deep Learning |
| SVM | Support Vector Machine |
| KNN | K-Nearest Neighbor |
| ROI | Region of Interest |
| AD | Alzheimer’s Disease |
| MCI | Mild Cognition Impairment |
| CN | Cognitively Normal |
| HV | Hippocampus Volume |
| BA | Balanced Accuracy |
References
- Mirzaei, G.; Adeli, A.; Adeli, H. Imaging and machine learning techniques for diagnosis of Alzheimer’s disease. Rev. Neurosci. 2016, 27, 857–870. [Google Scholar] [CrossRef] [PubMed]
- Mirzaei, G.; Adeli, H. Machine learning techniques for diagnosis of alzheimer disease, mild cognitive disorder, and other types of dementia. Biomed. Signal Process. Control 2022, 72, 103293. [Google Scholar] [CrossRef]
- Gosche, K.; Mortimer, J.; Smith, C.; Markesbery, W.; Snowdon, D. Hippocampal volume as an index of Alzheimer neuropathology: Findings from the Nun Study. Neurology 2002, 58, 1476–1482. [Google Scholar] [CrossRef]
- Kim, D.; Han, D.; Park, J.; Choi, H.; Park, J.; Cha, M.; Woo, J.; Byun, M.S.; Lee, D.Y.; Kim, Y.; et al. Deep proteome profiling of the hippocampus in the 5XFAD mouse model reveals biological process alterations and a novel biomarker of Alzheimer’s disease. Exp. Mol. 2019, 51, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Sørensen, L.; Igel, C.; Liv Hansen, N.; Osler, M.; Lauritzen, M.; Rostrup, E.; Nielsen, M.; for the Alzheimer’s Disease Neuroimaging Initiative and the Australian Imaging Biomarkers; Lifestyle Flagship Study of Ageing. Early detection of Alzheimer’s disease using M RI hippocampal texture. Hum. Brain Mapp. 2016, 37, 1148–1161. [Google Scholar] [CrossRef] [PubMed]
- Feng, X.; Yang, J.; Laine, A.F.; Angelini, E.D. Alzheimer’s disease diagnosis based on anatomically stratified texture analysis of the hippocampus in structural MRI. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1546–1549. [Google Scholar]
- Sarwinda, D.; Bustamam, A. Detection of Alzheimer’s disease using advanced local binary pattern from hippocampus and whole brain of MR images. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 5051–5056. [Google Scholar]
- Maqsood, M.; Nazir, F.; Khan, U.; Aadil, F.; Jamal, H.; Mehmood, I.; Song, O.Y. Transfer learning assisted classification and detection of Alzheimer’s disease stages using 3D MRI scans. Sensors 2019, 19, 2645. [Google Scholar] [CrossRef]
- Xia, Z.; Yue, G.; Xu, Y.; Feng, C.; Yang, M.; Wang, T.; Lei, B. A novel end-to-end hybrid network for Alzheimer’s disease detection using 3D CNN and 3D CLSTM. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–4. [Google Scholar]
- Folego, G.; Weiler, M.; Casseb, R.F.; Pires, R.; Rocha, A. Alzheimer’s disease detection through whole-brain 3D-CNN MRI. Front. Bioeng. Biotechnol. 2020, 8, 534592. [Google Scholar] [CrossRef]
- Ebrahimi, A.; Luo, S.; Chiong, R.; Alzheimer’s Disease Neuroimaging Initiative. Deep sequence modelling for Alzheimer’s disease detection using MRI. Comput. Biol. Med. 2021, 134, 104537. [Google Scholar] [CrossRef]
- Gheisari, M.; Ebrahimzadeh, F.; Rahimi, M.; Moazzamigodarzi, M.; Liu, Y.; Dutta Pramanik, P.K.; Heravi, M.A.; Mehbodniya, A.; Ghaderzadeh, M.; Feylizadeh, M.R.; et al. Deep learning: Applications, architectures, models, tools, and frameworks: A comprehensive survey. CAAI Trans. Intell. Technol. 2023, 8, 581–606. [Google Scholar] [CrossRef]
- Garavand, A.; Behmanesh, A.; Aslani, N.; Sadeghsalehi, H.; Ghaderzadeh, M. Towards diagnostic aided systems in coronary artery disease detection: A comprehensive multiview survey of the state of the art. Int. J. Intell. Syst. 2023, 2023, 6442756. [Google Scholar] [CrossRef]
- Raj, A.; Mirzaei, G. End to End Trained Long Term Recurrent Convolutional Network for Subject-level Alzheimer Detection. In Proceedings of the 2022 56th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 31 October–2 November 2022; pp. 1059–1070. [Google Scholar] [CrossRef]
- Mirzaei, G. Ensembles of Convolutional Neural Network Pipelines for Diagnosis of Alzheimer’s Disease. In Proceedings of the 2021 55th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 31 October–2 November 2021; pp. 583–589. [Google Scholar] [CrossRef]
- Battineni, G.; Hossain, M.; Chintalapudi, N.; Traini, E.; Dhulipalla, V.R.; Ramasamy, M.; Amenta, F. Improved Alzheimer’s Disease Detection by MRI Using Multimodal Machine Learning Algorithms. Diagnostics 2021, 11, 2103. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Habes, M.; Wolk, D.A.; Fan, Y. A deep learning model for early prediction of Alzheimer’s disease dementia based on hippocampal magnetic resonance imaging data. Alzheimer’s Dement. 2019, 15, 1059–1070. [Google Scholar] [CrossRef]
- Shen, K.k.; Fripp, J.; Mériaudeau, F.; Chételat, G.; Salvado, O.; Bourgeat, P.; The Alzheimer’s Disease Neuroimaging Initiative. Detecting global and local hippocampal shape changes in Alzheimer’s disease using statistical shape models. Neuroimage 2012, 59, 2155–2166. [Google Scholar] [CrossRef] [PubMed]
- Yao, W.; Wang, S.; Fu, H. Hippocampus segmentation in MRI using side U-net model. In Proceedings of the International Conference on Neural Information Processing, Sydney, NSW, Australia, 12–15 December 2019; Springer: Berlin, Germany, 2019; pp. 143–150. [Google Scholar]
- Liu, M.; Li, F.; Yan, H.; Wang, K.; Ma, Y.; Shen, L.; Xu, M.; Alzheimer’s Disease Neuroimaging Initiative. A multi-model deep convolutional neural network for automatic hippocampus segmentation and classification in Alzheimer’s disease. Neuroimage 2020, 208, 116459. [Google Scholar] [CrossRef] [PubMed]
- Caicedo, J.C.; Lazebnik, S. Active object localization with deep reinforcement learning. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2488–2496. [Google Scholar]
- Pirinen, A.; Sminchisescu, C. Deep reinforcement learning of region proposal networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6945–6954. [Google Scholar]
- Carmichael, O.; Xie, J.; Evan, F.; Singh, B.; DeCarli, C.; Alzheimer’s Disease Neuroimaging Initiative. Localized hippocampus measures are associated with alzheimer pathology and cognition independent of total hippocampal volume. Neurobiol. Aging 2012, 33, 1124.e31. [Google Scholar] [CrossRef]
- Lian, C.; Liu, M.; Zhang, J.; Shen, D. Hierarchical fully convolutional network for joint atrophy localization and alzheimer’s disease diagnosis using structural mri. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 880–893. [Google Scholar] [CrossRef]
- Bäckström, K.; Nazari, M.; Gu, I.Y.H.; Jakola, A.S. An efficient 3D deep convolutional network for Alzheimer’s disease diagnosis using MR images. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 149–153. [Google Scholar]
- Xu, X.; Lin, L.; Sun, S.; Wu, S. A review of the application of three-dimensional convolutional neural networks for the diagnosis of Alzheimer’s disease using neuroimaging. Rev. Neurosci. 2023, 34, 649–670. [Google Scholar] [CrossRef]
- Minh, V.; Kavulcuoglu, K.; Silver, D.; Rusu, A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Katabathula, S.; Wang, Q.; Xu, R. Predict alzheimer’s disease using hippocampus mri data: A lightweight 3d deep convolutional network model with visual and global shape representations. Alzheimer’s Res. Ther. 2021, 13, 104. [Google Scholar] [CrossRef]
- Gupta, Y.; Lee, K.H.; Choi, K.Y.; Lee, J.J.; Kim, B.C.; Kwon, G.R.; National Research Center for Dementia; Alzheimer’s Disease Neuroimaging Initiative. Early diagnosis of Alzheimer’s disease using combined features from voxel-based morphometry and cortical, subcortical, and hippocampus regions of MRI T1 brain images. PLoS ONE 2019, 14, e0222446. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, S.; Choi, K.Y.; Lee, J.J.; Kim, B.C.; Kwon, G.R.; Lee, K.H.; Jung, H.Y. Ensembles of patch-based classifiers for diagnosis of Alzheimer diseases. IEEE Access 2019, 7, 73373–73383. [Google Scholar] [CrossRef]
- Sarasua, I.; Pölsterl, S.; Wachinger, C. Hippocampal representations for deep learning on Alzheimer’s disease. Sci. Rep. 2022, 12, 8619. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 3D ROI Net (Same as 3D Target Net) | |
|---|---|
| Conv 3D + LeakyReLU | (Input dim, 32), filter size = 5, stride = 2 |
| Maxpool 3D | (2, 2, 2) |
| Conv 3D + LeakyReLU | (32, 64), filter size = 5, stride = 1 |
| Maxpool 3D | (1, 2, 2) |
| Conv 3D + LeakyReLU | (64, 64), filter size = 3, stride = 2 |
| Maxpool 3D | (2, 2, 2) |
| Flatten Features | |
| Dense + ReLU | (Input dim, 256) |
| Dense + Sigmoid | (256, Output dim) |
| Tech. | Accuracy | F1-Score | Recall | Precision | HR |
|---|---|---|---|---|---|
| 2D CNN | 71.6% | 70.3% | 64.8% | 77.6% | Ground Truth |
| AlexNet | 76.6% | 72.9% | 61.2% | 91.4% | Ground Truth |
| Proposed ROI Net | 70% | 69.2% | 65% | 74% | DQN |
| Proposed Fusion Net | 76.67% | 75% | 70% | 83% | DQN |
| Tech. | Data | Accuracy | F1-Score | Balanced Accuracy * | |
|---|---|---|---|---|---|
| KNN | HV | 85.52% | 76.59% | 82.07% | |
| [30] | RF | HV | 86.84% | 79.16% | 83.5% |
| SVM | HV | 88.15% | 79.06% | 85.47% | |
| [29] | DL | Shape | 70.89% | 63.14% | 64.86% |
| Shape + Vis | 92.52% | 91.45% | 91.32% | ||
| [31] | DL | L. HV ROI | 80.40% | 85.16% | 80.46% |
| R. HV ROI | 79.5% | 79.1% | 79.39% | ||
| [32] | DL | HV Mask | - | - | 76.6% |
| HV Texture | - | - | 78.8% | ||
| RL | 2D H ROI | 70% | 69.2% | 69.5% | |
| Ours | +DL | 2D H ROI + | 76.67% | 75% | 76.5% |
| Whole slice |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raj, A.; Mirzaei, G. Reinforcement-Learning-Based Localization of Hippocampus for Alzheimer’s Disease Detection. Diagnostics 2023, 13, 3292. https://doi.org/10.3390/diagnostics13213292
Raj A, Mirzaei G. Reinforcement-Learning-Based Localization of Hippocampus for Alzheimer’s Disease Detection. Diagnostics. 2023; 13(21):3292. https://doi.org/10.3390/diagnostics13213292
Chicago/Turabian StyleRaj, Aditya, and Golrokh Mirzaei. 2023. "Reinforcement-Learning-Based Localization of Hippocampus for Alzheimer’s Disease Detection" Diagnostics 13, no. 21: 3292. https://doi.org/10.3390/diagnostics13213292
APA StyleRaj, A., & Mirzaei, G. (2023). Reinforcement-Learning-Based Localization of Hippocampus for Alzheimer’s Disease Detection. Diagnostics, 13(21), 3292. https://doi.org/10.3390/diagnostics13213292