
GETNet: Group Normalization Shuffle and Enhanced Channel Self-Attention Network Based on VT-UNet for Brain Tumor Segmentation



Abstract
:1. Introduction
- We proposed a new GETNet for brain tumor segmentation which combined 3D convolution with VT-UNet to comprehensively capture delicate local information and global semantic information and improve brain tumor segmentation performance.
- We developed a GNS block between the VT Encoder Block and the downsampling module to enable the Transformer architecture to obtain local information effectively.
- We designed an ECSA block in the bottleneck layer to enhance the model for detailed feature extraction.
2. Related Work
2.1. Deep-Learning-Based Methods for Medical Image Segmentation
2.2. Attention-Based Module for Medical Image Segmentation
2.3. The Transformer-Based Module for Medical Image Segmentation
3. Materials and Methods
3.1. Datasets and Preprocessing
3.2. Implementation Details
3.3. Evaluation Metrics
3.4. Methodology
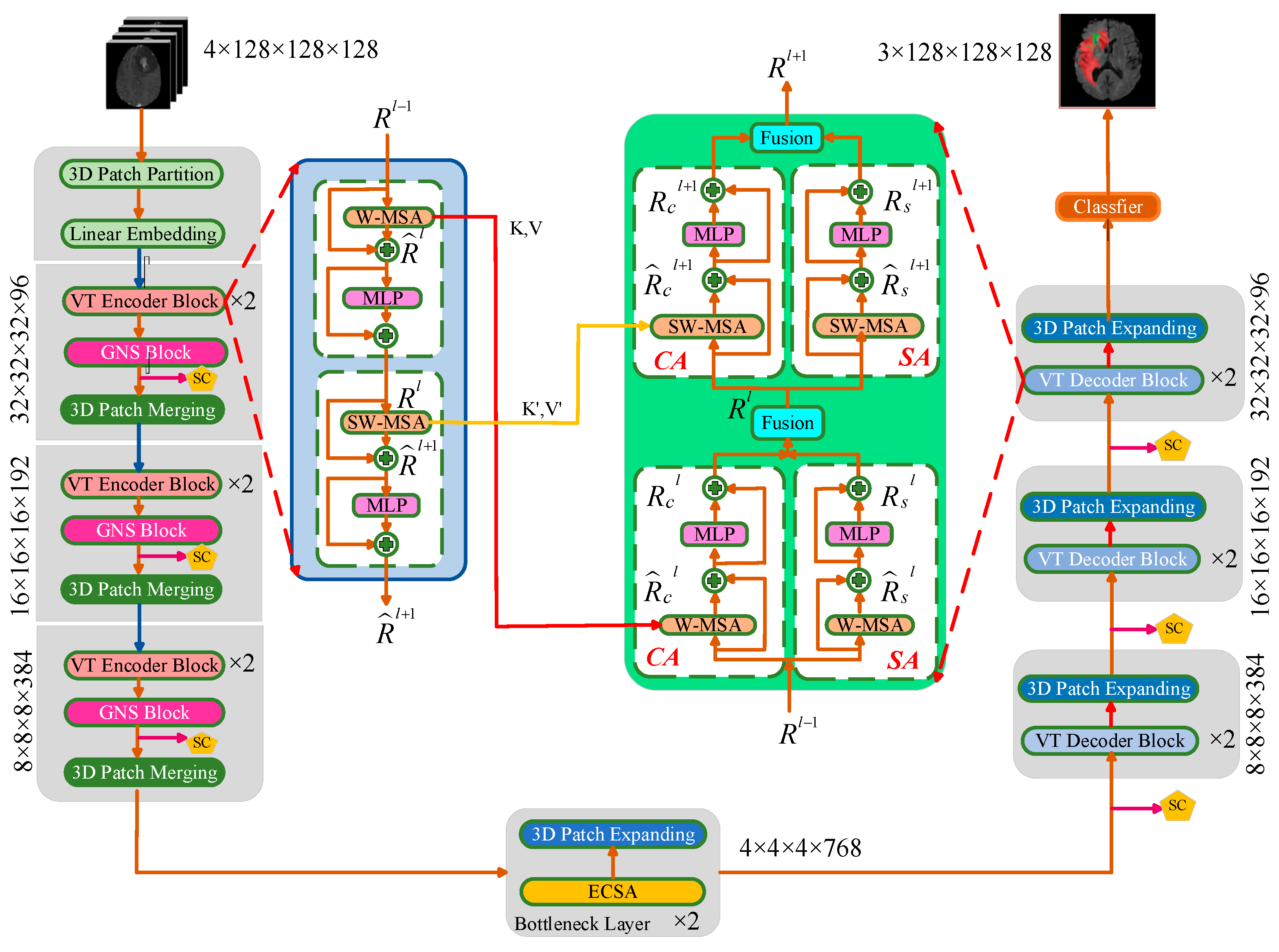
3.4.1. Network Architecture
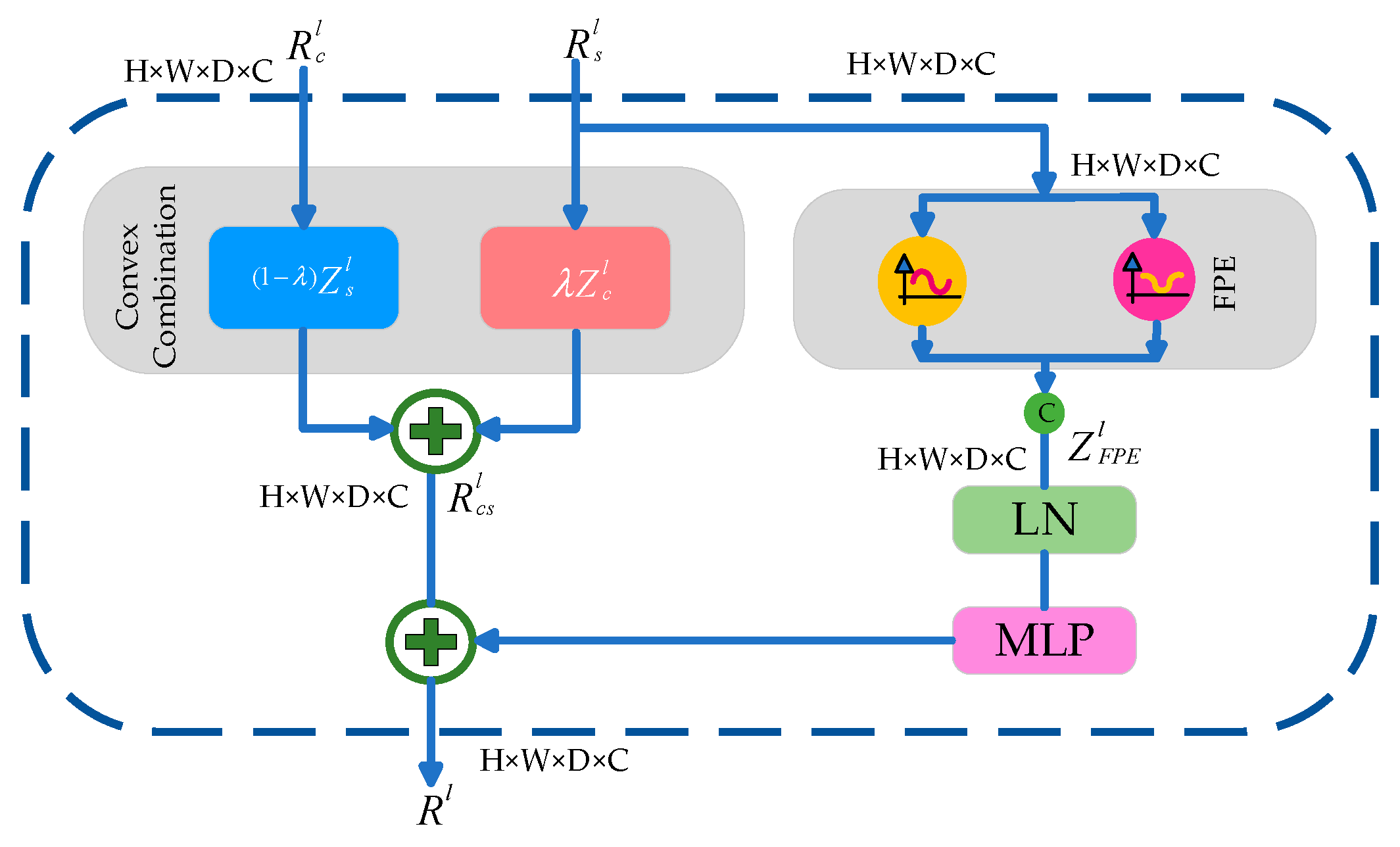
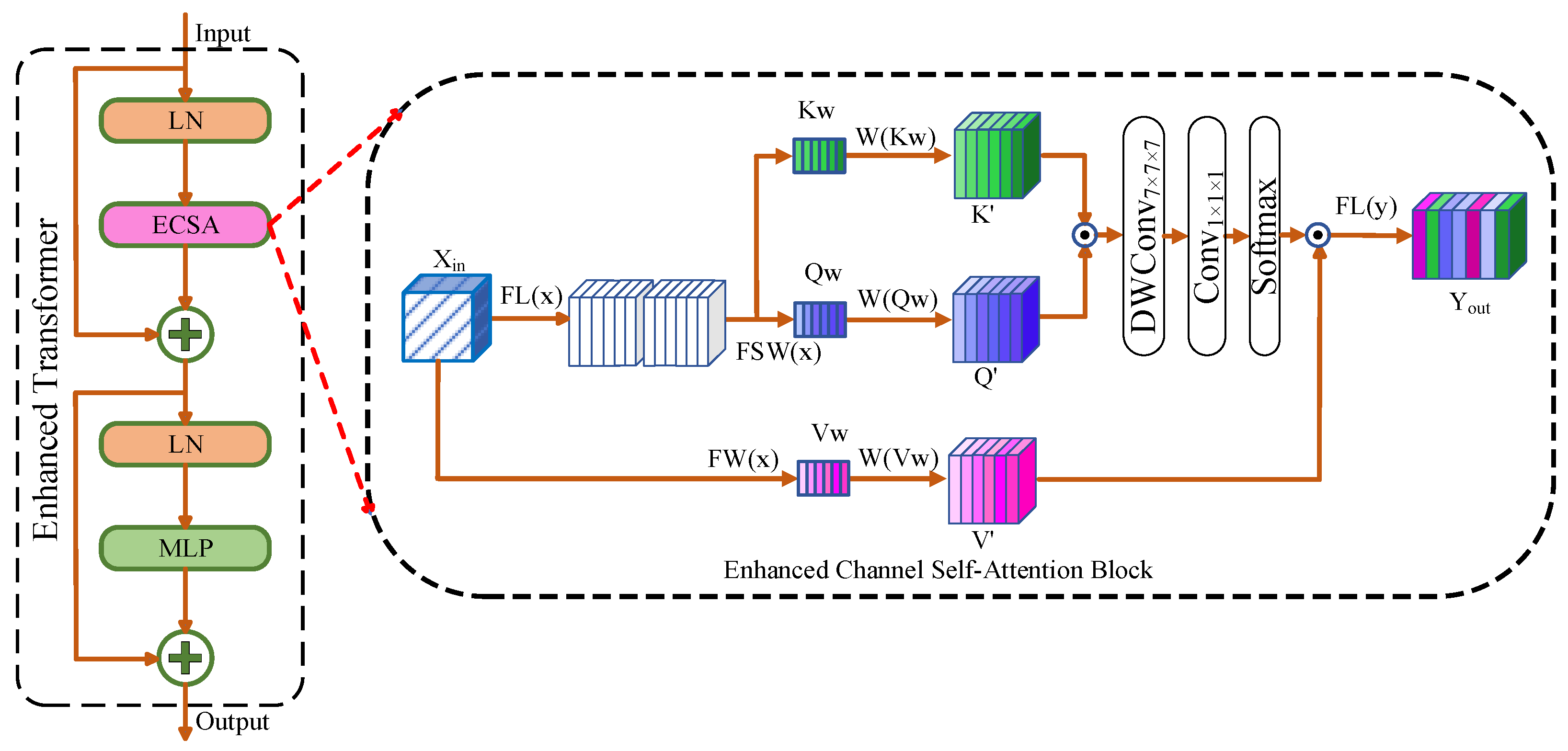
3.4.2. Enhanced Channel Self-Attention Block (ECSA)
3.4.3. Group Normalization Shuffle (GNS) Block
4. Results and Discussion
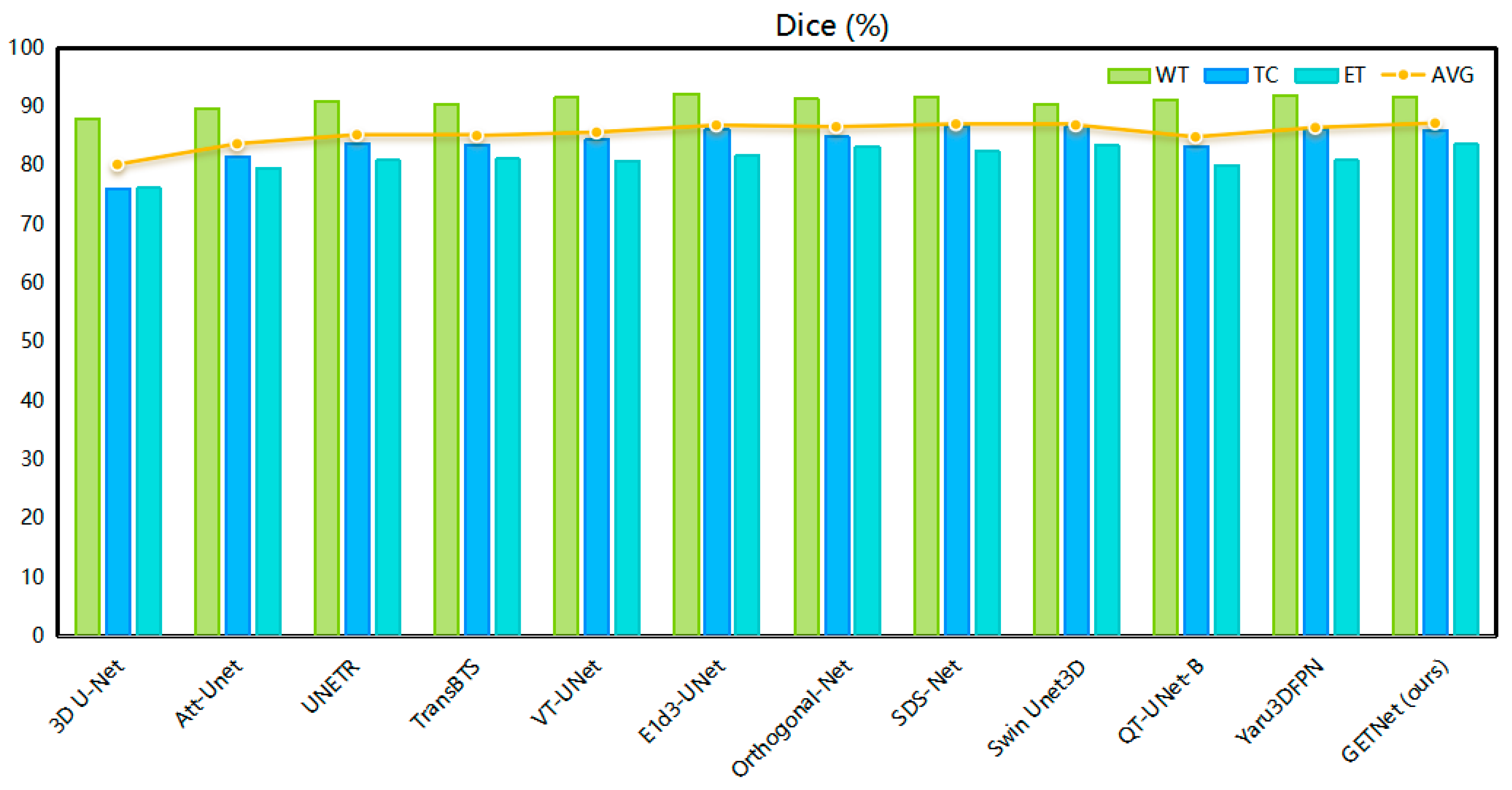
4.1. Comparison with Other Methods
4.2. Ablation Experiments
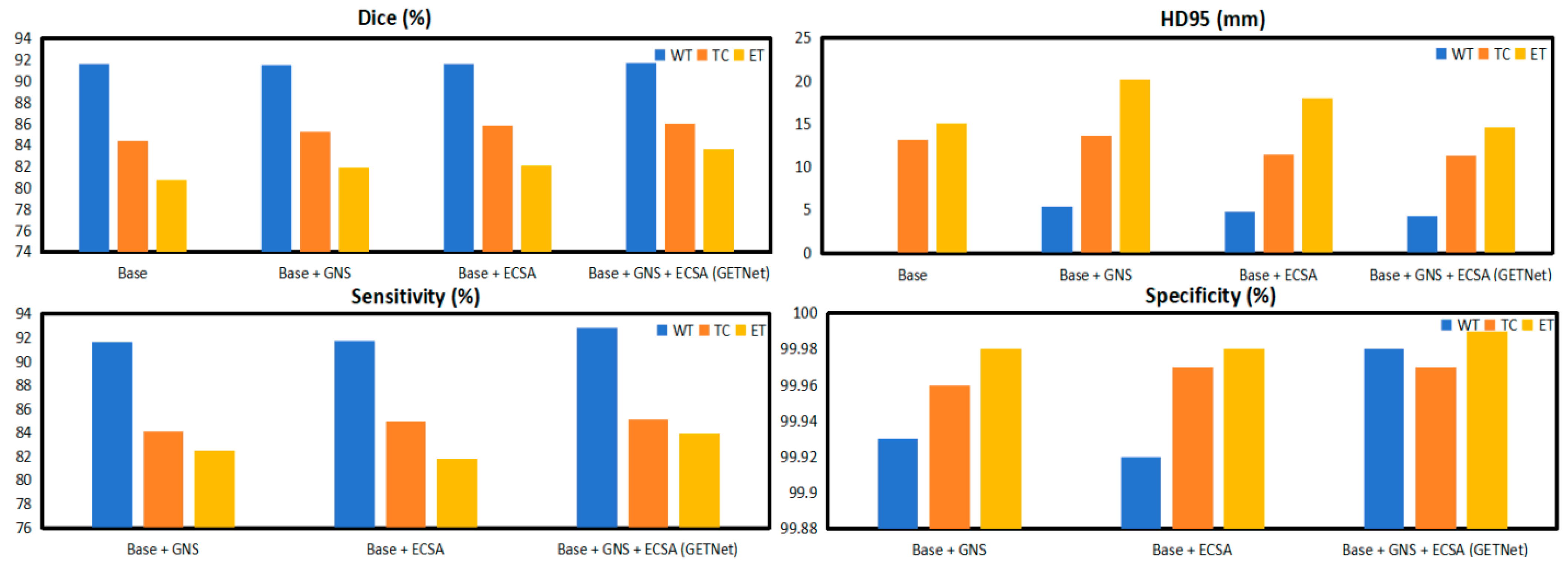
4.2.1. Ablation Study of Each Module in GETNet
4.2.2. Ablation Study of GN and GeLU in the GNS Module
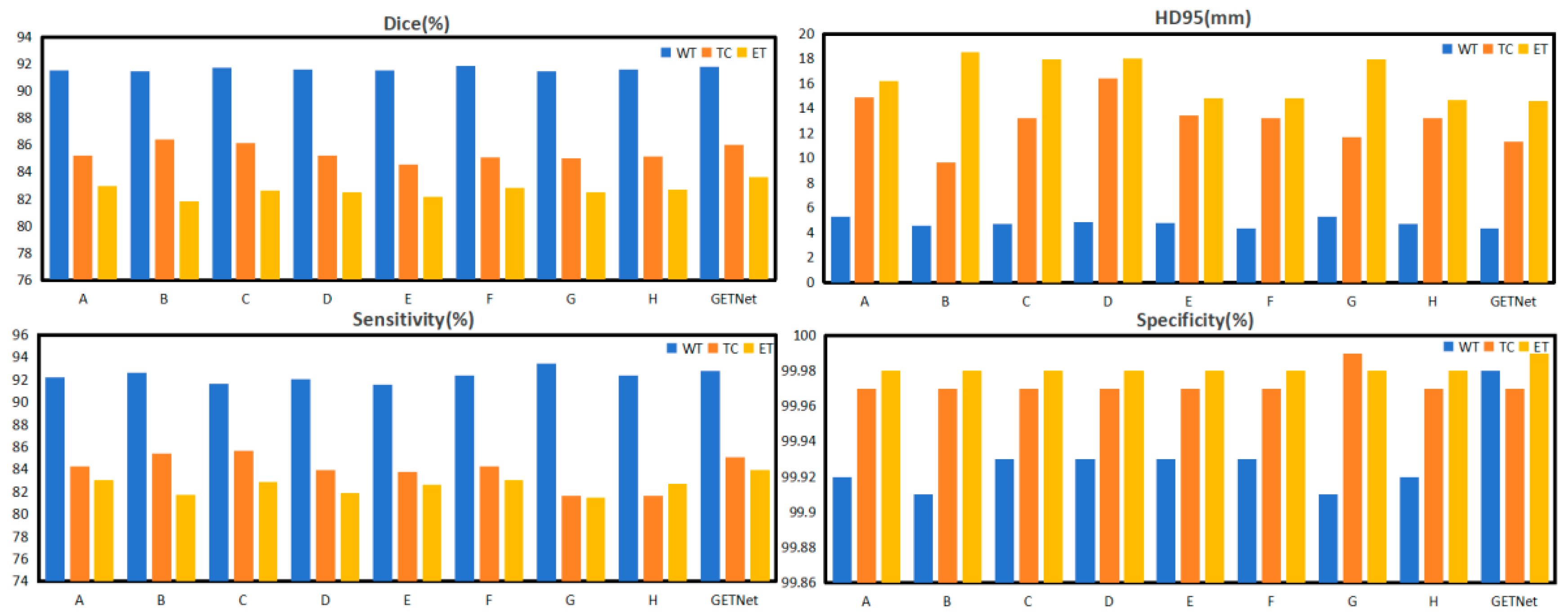
4.2.3. Ablation Study of the Convex Combination in the ECSA Module
4.2.4. Ablation Study of the Frequency Coefficient of FEP in the ECSA Module
4.2.5. Comparative Experiment on the Depth-Wise Size of the 3D Patch-Merging Operation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nelson, S.; Taylor, L.P. Headaches in brain tumor patients: Primary or secondary? Headache J. Head Face Pain 2014, 54, 776–785. [Google Scholar] [CrossRef]
- Hoesin, F.R.; Adikusuma, W. Visual Disturbances as an Early Important Sign of Brain Tumor: A Case Report. J. Oftalmol. 2022, 4, 1–5. [Google Scholar] [CrossRef]
- Sorribes, I.C.; Moore, M.N.; Byrne, H.M.; Jain, H.V. A biomechanical model of tumor-induced intracranial pressure and edema in brain tissue. Biophys. J. 2019, 116, 1560–1574. [Google Scholar] [CrossRef]
- Siddiq, M. Ml-based medical image analysis for anomaly detection in CT scans, X-rays, and MRIs. Devot. J. Res. Community Serv. 2020, 2, 53–64. [Google Scholar] [CrossRef]
- Kwong, R.Y.; Yucel, E.K. Computed tomography scan and magnetic resonance imaging. Circulation 2003, 108, e104–e106. [Google Scholar] [CrossRef] [PubMed]
- Castiglioni, I.; Rundo, L.; Codari, M.; Di Leo, G.; Salvatore, C.; Interlenghi, M.; Gallivanone, F.; Cozzi, A.; D‘Amico, N.C.; Sardanelli, F. AI applications to medical images: From machine learning to deep learning. Phys. Medica 2021, 83, 9–24. [Google Scholar] [CrossRef]
- Yang, J.; An, P.; Shen, L.; Wang, Y. No-reference stereo image quality assessment by learning dictionaries and color visual characteristics. IEEE Access 2019, 7, 173657–173669. [Google Scholar] [CrossRef]
- Xin, W.; Liu, R.; Liu, Y.; Chen, Y.; Yu, W.; Miao, Q. Transformer for skeleton-based action recognition: A review of recent advances. Neurocomputing 2023, 537, 164–186. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2016: 19th International Conference, Athens, Greece, 17–21 October 2016; pp. 424–432. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chen, C.; Liu, X.; Ding, M.; Zheng, J.; Li, J. 3D dilated multi-fiber network for real-time brain tumor segmentation in MRI. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2019: 22nd International Conference, Shenzhen, China, 13–17 October 2019; pp. 184–192. [Google Scholar]
- Xu, Y.; Gong, M.; Fu, H.; Tao, D.; Zhang, K.; Batmanghelich, K. Multi-scale masked 3-D U-net for brain tumor segmentation. In Proceedings of the Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries: 4th International Workshop, BrainLes 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 16 September 2019; pp. 222–233. [Google Scholar]
- Jiang, Y.; Ye, M.; Huang, D.; Lu, X. AIU-Net: An efficient deep convolutional neural network for brain tumor segmentation. Math. Probl. Eng. 2021, 2021, 7915706. [Google Scholar] [CrossRef]
- Ahmad, P.; Jin, H.; Qamar, S.; Zheng, R.; Saeed, A. RD 2 A: Densely connected residual networks using ASPP for brain tumor segmentation. Multimed. Tools Appl. 2021, 80, 27069–27094. [Google Scholar] [CrossRef]
- Wang, L.; Liu, M.; Wang, Y.; Bai, X.; Zhu, M.; Zhang, F. A multi-scale method based on U-Net for brain tumor segmentation. In Proceedings of the 2022 7th International Conference on Communication, Image and Signal Processing (CCISP), Chengdu, China, 18–20 November 2022; pp. 271–275. [Google Scholar]
- Bukhari, S.T.; Mohy-ud-Din, H. E1D3 U-Net for brain tumor segmentation: Submission to the RSNA-ASNR-MICCAI BraTS 2021 challenge. In Proceedings of the International MICCAI Brainlesion Workshop, Virtual Event, 27 September 2021; pp. 276–288. [Google Scholar]
- Ahmad, P.; Qamar, S.; Shen, L.; Rizvi, S.Q.A.; Ali, A.; Chetty, G. Ms unet: Multi-scale 3d unet for brain tumor segmentation. In Proceedings of the International MICCAI Brainlesion Workshop, Virtual Event, 27 September 2021; pp. 30–41. [Google Scholar]
- Wu, Q.; Pei, Y.; Cheng, Z.; Hu, X.; Wang, C. SDS-Net: A lightweight 3D convolutional neural network with multi-branch attention for multimodal brain tumor accurate segmentation. Math. Biosci. Eng. 2023, 20, 17384–17406. [Google Scholar] [CrossRef]
- Chen, R.; Lin, Y.; Ren, Y.; Deng, H.; Cui, W.; Liu, W. An efficient brain tumor segmentation model based on group normalization and 3D U-Net. Int. J. Imaging Syst. Technol. 2024, 34, e23072. [Google Scholar] [CrossRef]
- Kharaji, M.; Abbasi, H.; Orouskhani, Y.; Shomalzadeh, M.; Kazemi, F.; Orouskhani, M. Brain Tumor Segmentation with Advanced nnU-Net: Pediatrics and Adults Tumors. Neurosci. Inform. 2024, 4, 100156. [Google Scholar] [CrossRef]
- Liu, T.; Luo, R.; Xu, L.; Feng, D.; Cao, L.; Liu, S.; Guo, J. Spatial channel attention for deep convolutional neural networks. Mathematics 2022, 10, 1750. [Google Scholar] [CrossRef]
- Zhou, C.; Chen, S.; Ding, C.; Tao, D. Learning contextual and attentive information for brain tumor segmentation. In Proceedings of the Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries: 4th International Workshop, BrainLes 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 16 September 2019; pp. 497–507. [Google Scholar]
- Zhang, X.; Zhang, X.; Ouyang, L.; Qin, C.; Xiao, L.; Xiong, D. SMTF: Sparse transformer with multiscale contextual fusion for medical image segmentation. Biomed. Signal Process. Control 2024, 87, 105458. [Google Scholar] [CrossRef]
- Zhao, J.; Sun, L.; Sun, Z.; Zhou, X.; Si, H.; Zhang, D. MSEF-Net: Multi-scale edge fusion network for lumbosacral plexus segmentation with MR image. Artif. Intell. Med. 2024, 148, 102771. [Google Scholar] [CrossRef]
- Liu, C.; Liu, H.; Zhang, X.; Guo, J.; Lv, P. Multi-scale and multi-view network for lung tumor segmentation. Comput. Biol. Med. 2024, 172, 108250. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Zou, Y.; Chen, H.; Liu, P.X.; Chen, J. Multi-scale features and attention guided for brain tumor segmentation. J. Vis. Commun. Image Represent. 2024, 100, 104141. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Peiris, H.; Hayat, M.; Chen, Z.; Egan, G.; Harandi, M. A robust volumetric transformer for accurate 3D tumor segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; pp. 162–172. [Google Scholar]
- Hatamizadeh, A.; Tang, Y.; Nath, V.; Yang, D.; Myronenko, A.; Landman, B.; Roth, H.R.; Xu, D. Unetr: Transformers for 3d medical image segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 574–584. [Google Scholar]
- Jia, Q.; Shu, H. Bitr-unet: A cnn-transformer combined network for mri brain tumor segmentation. In Proceedings of the International MICCAI Brainlesion Workshop, Virtual Event, 27 September 2021; pp. 3–14. [Google Scholar]
- Wang, W.; Chen, C.; Ding, M.; Yu, H.; Zha, S.; Li, J. TransBTS: Multimodal brain tumor segmentation using transformer. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Virtual Event, 27 September–1 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 109–119. [Google Scholar]
- Cai, Y.; Long, Y.; Han, Z.; Liu, M.; Zheng, Y.; Yang, W.; Chen, L. Swin Unet3D: A three-dimensionsal medical image segmentation network combining vision transformer and convolution. BMC Med. Inform. Decis. Mak. 2023, 23, 33. [Google Scholar] [CrossRef] [PubMed]
- Fu, B.; Peng, Y.; He, J.; Tian, C.; Sun, X.; Wang, R. HmsU-Net: A hybrid multi-scale U-net based on a CNN and transformer for medical image segmentation. Comput. Biol. Med. 2024, 170, 108013. [Google Scholar] [CrossRef] [PubMed]
- Ao, Y.; Shi, W.; Ji, B.; Miao, Y.; He, W.; Jiang, Z. MS-TCNet: An effective Transformer–CNN combined network using multi-scale feature learning for 3D medical image segmentation. Comput. Biol. Med. 2024, 170, 108057. [Google Scholar] [CrossRef] [PubMed]
- Aboussaleh, I.; Riffi, J.; el Fazazy, K.; Mahraz, A.M.; Tairi, H. 3DUV-NetR+: A 3D hybrid Semantic Architecture using Transformers for Brain Tumor Segmentation with MultiModal MR Images. Results Eng. 2024, 21, 101892. [Google Scholar] [CrossRef]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R. The multimodal brain tumor image segmentation benchmark (BRATS). IEEE Trans. Med. Imaging 2014, 34, 1993–2024. [Google Scholar] [CrossRef] [PubMed]
- Bakas, S.; Akbari, H.; Sotiras, A.; Bilello, M.; Rozycki, M.; Kirby, J.S.; Freymann, J.B.; Farahani, K.; Davatzikos, C. Advancing the cancer genome atlas glioma MRI collections with expert segmentation labels and radiomic features. Sci. Data 2017, 4, 170117. [Google Scholar] [CrossRef]
- Baid, U.; Ghodasara, S.; Mohan, S.; Bilello, M.; Calabrese, E.; Colak, E.; Farahani, K.; Kalpathy-Cramer, J.; Kitamura, F.C.; Pati, S. The rsna-asnr-miccai brats 2021 benchmark on brain tumor segmentation and radiogenomic classification. arXiv 2021, arXiv:2107.02314. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Dice, L.R. Measures of the amount of ecologic association between species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Kim, I.S.; McLean, W. Computing the Hausdorff distance between two sets of parametric curves. Commun. Korean Math. Soc. 2013, 28, 833–850. [Google Scholar] [CrossRef]
- Aydin, O.U.; Taha, A.A.; Hilbert, A.; Khalil, A.A.; Galinovic, I.; Fiebach, J.B.; Frey, D.; Madai, V.I. On the usage of average Hausdorff distance for segmentation performance assessment: Hidden error when used for ranking. Eur. Radiol. Exp. 2021, 5, 4. [Google Scholar] [CrossRef] [PubMed]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J. Mlp-mixer: An all-mlp architecture for vision. Adv. Neural Inf. Process. Syst. 2021, 34, 24261–24272. [Google Scholar]
- Sifre, L.; Mallat, S. Rigid-motion scattering for texture classification. arXiv 2014, arXiv:1403.1687. [Google Scholar]
- Horn, R.A. The hadamard product. In Proceedings of Symposia in Applied Mathematics; American Mathematical Society: Providence, RI, USA, 1990; pp. 87–169. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Rebsamen, M.; Knecht, U.; Reyes, M.; Wiest, R.; Meier, R.; McKinley, R. Divide and conquer: Stratifying training data by tumor grade improves deep learning-based brain tumor segmentation. Front. Neurosci. 2019, 13, 469127. [Google Scholar] [CrossRef]
- Prabhudesai, S.; Wang, N.C.; Ahluwalia, V.; Huan, X.; Bapuraj, J.R.; Banovic, N.; Rao, A. Stratification by tumor grade groups in a holistic evaluation of machine learning for brain tumor segmentation. Front. Neurosci. 2021, 15, 740353. [Google Scholar] [CrossRef] [PubMed]
- Pawar, K.; Zhong, S.; Goonatillake, D.S.; Egan, G.; Chen, Z. Orthogonal-Nets: A Large Ensemble of 2D Neural Networks for 3D Brain Tumor Segmentation. In Proceedings of the International MICCAI Brainlesion Workshop, Virtual Event, 27 September 2021; pp. 54–67. [Google Scholar]
- Håversen, A.H.; Bavirisetti, D.P.; Kiss, G.H.; Lindseth, F. QT-UNet: A self-supervised self-querying all-Transformer U-Net for 3D segmentation. IEEE Access 2024, 12, 62664–62676. [Google Scholar] [CrossRef]
- Akbar, A.S.; Fatichah, C.; Suciati, N.; Za’in, C. Yaru3DFPN: A lightweight modified 3D UNet with feature pyramid network and combine thresholding for brain tumor segmentation. Neural Comput. Appl. 2024, 36, 7529–7544. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Basic Configuration | Value |
|---|---|
| PyTorch Version | 1.11.0 |
| Python | 3.8.10 |
| GPU | NVIDIA RTX A5000 (24 G) |
| Cuda | cu113 |
| Learning Rate | 1.00 × 10−4 |
| Optimizer | Adam |
| Epoch | 350 |
| Batch Size | 1 |
| Input Size | 128 × 128 × 128 |
| Output Size | 128 × 128 × 128 |
| Methods | Dice (%) | SD | Recall (%) | F1-Score (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WT | TC | ET | WT | TC | ET | WT | TC | ET | WT | TC | ET | |
| 3D U-Net [12] | 91.29 | 89.13 | 85.78 | 7.14 | 15.49 | 15.93 | 91.38 | 88.60 | 87.31 | 95.75 | 95.87 | 93.16 |
| Att-Unet [60] | 91.43 | 89.51 | 85.71 | 9.23 | 15.15 | 17.11 | 90.73 | 88.68 | 86.35 | 96.32 | 96.43 | 94.13 |
| UNETR [38] | 91.53 | 88.57 | 85.27 | 8.92 | 15.94 | 18.48 | 92.54 | 88.71 | 85.92 | 95.69 | 95.44 | 94.15 |
| TransBTS [40] | 90.61 | 88.78 | 84.29 | 10.73 | 16.48 | 19.30 | 91.20 | 87.74 | 85.73 | 95.69 | 96.38 | 93.35 |
| VT-UNet [37] | 92.39 | 90.12 | 86.07 | 8.60 | 14.48 | 16.37 | 92.76 | 90.61 | 87.85 | 96.43 | 96.06 | 93.63 |
| Swin Unet3D (2023) [41] | 92.85 | 90.69 | 86.26 | 5.67 | 14.30 | 17.15 | 92.18 | 90.81 | 87.85 | 96.94 | 96.42 | 93.63 |
| GETNet (ours) | 93.04 | 91.70 | 87.41 | 5.53 | 11.60 | 14.01 | 92.87 | 91.36 | 88.22 | 96.78 | 96.75 | 94.32 |
| Methods | WT | TC | ET | |||
|---|---|---|---|---|---|---|
| %Subjects | p | %Subjects | p | %Subjects | p | |
| GETNet (ours) vs. 3D U-Net | 76.4 | 2.987 × 10−24 | 82.8 | 6.849 × 10−18 | 73.7 | 7.590 × 10−7 |
| GETNet (ours) vs. Att-Unet | 76.1 | 9.093 × 10−16 | 81.2 | 4.548 × 10−14 | 73.7 | 0.008 |
| GETNet (ours) vs. UNETR | 76.1 | 1.286 × 10−6 | 83.6 | 1.612 × 10−15 | 77.2 | 0.092 |
| GETNet (ours) vs. TransBTS | 78.8 | 4.564 × 10−24 | 83.6 | 3.762 × 10−17 | 79.6 | 2.579 × 10−12 |
| GETNet (ours) vs. VT-UNet | 73.3 | 2.724 × 10−6 | 78.8 | 1.421 × 10−10 | 73.7 | 1.576 × 10−9 |
| GETNet (ours) vs. Swin Unet3D | 70.9 | 0.0006 | 76.4 | 0.007 | 72.9 | 0.01 |
| Methods | Dice (%) | SD | Recall (%) | F1-Score (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WT | TC | ET | WT | TC | ET | WT | TC | ET | WT | TC | ET | |
| GETNet in HGG cases | 92.74 | 92.53 | 87.24 | 4.29 | 6.81 | 8.62 | 92.73 | 91.66 | 89.65 | 96.41 | 96.87 | 92.55 |
| GETNet in LGG cases | 92.63 | 82.10 | 77.64 | 3.89 | 15.86 | 29.32 | 91.77 | 81.87 | 81.33 | 96.82 | 92.97 | 92.03 |
| GETNet in all cases | 92.72 | 90.38 | 85.26 | 4.21 | 10.31 | 15.84 | 92.53 | 89.65 | 87.94 | 96.49 | 96.09 | 92.44 |
| Methods | Dice (%) | HD95 (mm) | ||||||
|---|---|---|---|---|---|---|---|---|
| WT | TC | ET | AVG | WT | TC | ET | AVG | |
| 3D U-Net [12] | 88.02 | 76.17 | 76.20 | 80.13 | 9.97 | 21.57 | 25.48 | 19.00 |
| Att-Unet [60] | 89.74 | 81.59 | 79.60 | 83.64 | 8.09 | 14.68 | 19.37 | 14.05 |
| UNETR [38] | 90.89 | 83.73 | 80.93 | 85.18 | 4.71 | 13.38 | 21.39 | 13.16 |
| TransBTS [40] | 90.45 | 83.49 | 81.17 | 85.03 | 6.77 | 10.14 | 18.94 | 11.95 |
| VT-UNet [37] | 91.66 | 84.41 | 80.75 | 85.60 | 4.11 | 13.20 | 15.08 | 10.80 |
| E1d3-UNet (2022) [22] | 92.30 | 86.30 | 81.80 | 86.80 | 4.34 | 9.62 | 18.24 | 10.73 |
| Orthogonal-Net (2022) [63] | 91.40 | 85.00 | 83.20 | 86.53 | 5.43 | 9.81 | 20.97 | 12.07 |
| SDS-Net (2023) [24] | 91.80 | 86.80 | 82.50 | 87.00 | 21.07 | 11.99 | 13.13 | 15.40 |
| Swin Unet3D (2023) [41] | 90.50 | 86.60 | 83.40 | 86.83 | - | - | - | - |
| QT-UNet-B (2024) [64] | 91.24 | 83.20 | 79.99 | 84.81 | 4.44 | 12.95 | 17.19 | 11.53 |
| Yaru3DFPN (2024) [65] | 92.02 | 86.27 | 80.90 | 86.40 | 4.09 | 8.43 | 21.91 | 11.48 |
| GETNet (ours) | 91.77 | 86.03 | 83.64 | 87.15 | 4.36 | 11.35 | 14.58 | 10.10 |
| Expt | Dice (%) | HD95 (mm) | Sensitivity (%) | Specificity (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WT | TC | ET | WT | TC | ET | WT | TC | ET | WT | TC | ET | |
| Base | 91.66 | 84.41 | 80.75 | 4.11 | 13.20 | 15.08 | - | - | - | - | - | - |
| Base + GNS | 91.50 | 85.30 | 81.92 | 5.36 | 13.68 | 20.24 | 91.67 | 84.08 | 82.51 | 99.93 | 99.96 | 99.98 |
| Base + ECSA | 91.62 | 85.82 | 82.11 | 4.79 | 11.44 | 18.04 | 91.73 | 84.99 | 81.81 | 99.92 | 99.97 | 99.98 |
| Base + GNS + ECSA (GETNet) | 91.77 | 86.03 | 83.64 | 4.36 | 11.35 | 14.58 | 92.83 | 85.12 | 83.91 | 99.98 | 99.97 | 99.99 |
| Expt | Position | GN | BN | GN + GeLU | BN + ReLU | Dice | HD95 | Sen | Spe | |
|---|---|---|---|---|---|---|---|---|---|---|
| A | Unit 1 | √ | WT | 91.32 | 5.72 | 91.64 | 99.98 | |||
| Unit 2 | √ | TC | 84.26 | 17.18 | 83.27 | 99.97 | ||||
| Unit 3 | √ | ET | 83.01 | 15.02 | 83.56 | 99.93 | ||||
| B | Unit 1 | √ | WT | 91.36 | 4.87 | 92.32 | 99.92 | |||
| Unit 2 | √ | TC | 85.89 | 10.07 | 84.80 | 99.97 | ||||
| Unit 3 | √ | ET | 82.19 | 19.91 | 81.90 | 99.98 | ||||
| C | Unit 1 | √ | WT | 91.65 | 4.67 | 92.30 | 99.92 | |||
| Unit 2 | √ | TC | 85.67 | 13.69 | 84.51 | 99.98 | ||||
| Unit 3 | √ | ET | 82.88 | 16.71 | 83.01 | 99.98 | ||||
| D | Unit 1 | √ | WT | 91.42 | 4.56 | 92.87 | 99.91 | |||
| Unit 2 | √ | TC | 85.54 | 13.10 | 84.03 | 99.98 | ||||
| Unit 3 | √ | ET | 82.90 | 17.90 | 82.42 | 99.98 | ||||
| E (GETNet) | Unit 1 | √ | WT | 91.77 | 4.36 | 92.83 | 99.98 | |||
| Unit 2 | √ | TC | 86.03 | 11.35 | 85.12 | 99.97 | ||||
| Unit 3 | √ | ET | 83.64 | 14.58 | 83.91 | 99.99 |
| Expt | λ | 1 − λ | Dice (%) | HD95 (mm) | Sensitivity (%) | Specificity (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WT | TC | ET | WT | TC | ET | WT | TC | ET | WT | TC | ET | |||
| A | 0.1 | 0.9 | 91.56 | 85.22 | 82.94 | 5.28 | 14.91 | 16.22 | 92.22 | 84.26 | 83.08 | 99.92 | 99.97 | 99.98 |
| B | 0.2 | 0.8 | 91.46 | 86.41 | 81.86 | 4.56 | 9.69 | 18.52 | 92.65 | 85.39 | 81.71 | 99.91 | 99.97 | 99.98 |
| C | 0.3 | 0.7 | 91.73 | 86.18 | 82.61 | 4.68 | 13.2 | 17.96 | 91.65 | 85.65 | 82.85 | 99.93 | 99.97 | 99.98 |
| D | 0.4 | 0.6 | 91.63 | 85.23 | 82.47 | 4.86 | 16.44 | 18.01 | 92.07 | 83.97 | 81.91 | 99.93 | 99.97 | 99.98 |
| E | 0.6 | 0.4 | 91.50 | 84.57 | 82.16 | 4.75 | 13.46 | 14.81 | 91.56 | 83.82 | 82.66 | 99.93 | 99.97 | 99.98 |
| F | 0.7 | 0.3 | 91.89 | 85.08 | 82.84 | 4.33 | 13.26 | 14.83 | 92.4 | 84.3 | 83.05 | 99.93 | 99.97 | 99.98 |
| G | 0.8 | 0.2 | 91.48 | 85.02 | 82.51 | 5.28 | 11.71 | 17.97 | 93.43 | 81.65 | 81.48 | 99.91 | 99.99 | 99.98 |
| H | 0.9 | 0.1 | 91.58 | 85.13 | 82.72 | 4.69 | 13.21 | 14.7 | 92.39 | 81.64 | 82.71 | 99.92 | 99.97 | 99.98 |
| GETNet | 0.5 | 0.5 | 91.77 | 86.03 | 83.64 | 4.36 | 11.35 | 14.58 | 92.83 | 85.12 | 83.91 | 99.98 | 99.97 | 99.99 |
| Expt | η | θ | Dice (%) | HD95 (mm) | Sensitivity (%) | Specificity (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WT | TC | ET | WT | TC | ET | WT | TC | ET | WT | TC | ET | |||
| A | ω | ω | 91.56 | 85.54 | 82.83 | 4.67 | 11.70 | 14.78 | 91.82 | 84.91 | 83.10 | 99.93 | 99.97 | 99.98 |
| B | 1 | 1 | 91.50 | 85.76 | 82.47 | 4.49 | 11.39 | 16.44 | 92.28 | 85.72 | 83.08 | 99.92 | 99.97 | 99.98 |
| GETNet | 0.5 | 0.5 | 91.77 | 86.03 | 83.64 | 4.36 | 11.35 | 14.58 | 92.83 | 85.12 | 83.91 | 99.98 | 99.97 | 99.99 |
| Expt | λ | Dice (%) | HD95 (mm) | Sensitivity (%) | Specificity (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WT | TC | ET | WT | TC | ET | WT | TC | ET | WT | TC | ET | ||
| A | 5000 | 91.70 | 85.33 | 82.17 | 4.47 | 13.23 | 19.87 | 92.63 | 83.96 | 82.07 | 99.92 | 99.97 | 99.98 |
| B | 20,000 | 91.64 | 84.96 | 82.21 | 5.38 | 14.97 | 18.57 | 93.79 | 84.95 | 83.18 | 99.90 | 99.97 | 99.98 |
| GETNet | 10,000 | 91.77 | 86.03 | 83.64 | 4.36 | 11.35 | 14.58 | 92.83 | 85.12 | 83.91 | 99.98 | 99.97 | 99.99 |
| Expt | Dice (%) | HD95 (mm) | Sensitivity (%) | Specificity (%) | FLOPs | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WT | TC | ET | WT | TC | ET | WT | TC | ET | WT | TC | ET | ||
| A | 91.50 | 86.83 | 82.88 | 4.45 | 9.65 | 17.88 | 92.09 | 86.58 | 82.54 | 99.92 | 99.96 | 99.97 | 130.94G |
| GETNet | 91.77 | 86.03 | 83.64 | 4.36 | 11.35 | 14.58 | 92.83 | 85.12 | 83.91 | 99.98 | 99.97 | 99.99 | 81.95G |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, B.; Cao, N.; Zhang, R.; Yang, P. GETNet: Group Normalization Shuffle and Enhanced Channel Self-Attention Network Based on VT-UNet for Brain Tumor Segmentation. Diagnostics 2024, 14, 1257. https://doi.org/10.3390/diagnostics14121257
Guo B, Cao N, Zhang R, Yang P. GETNet: Group Normalization Shuffle and Enhanced Channel Self-Attention Network Based on VT-UNet for Brain Tumor Segmentation. Diagnostics. 2024; 14(12):1257. https://doi.org/10.3390/diagnostics14121257
Chicago/Turabian StyleGuo, Bin, Ning Cao, Ruihao Zhang, and Peng Yang. 2024. "GETNet: Group Normalization Shuffle and Enhanced Channel Self-Attention Network Based on VT-UNet for Brain Tumor Segmentation" Diagnostics 14, no. 12: 1257. https://doi.org/10.3390/diagnostics14121257
APA StyleGuo, B., Cao, N., Zhang, R., & Yang, P. (2024). GETNet: Group Normalization Shuffle and Enhanced Channel Self-Attention Network Based on VT-UNet for Brain Tumor Segmentation. Diagnostics, 14(12), 1257. https://doi.org/10.3390/diagnostics14121257