Abstract
Background: Hepatocellular carcinoma (HCC) accounts for 75% of primary liver tumors. Controlling risk factors associated with its development and implementing screenings in risk populations does not seem sufficient to improve the prognosis of these patients at diagnosis. The development of a predictive prognostic model for mortality at the diagnosis of HCC is proposed. Methods: In this retrospective multicenter study, the analysis of data from 191 HCC patients was conducted using machine learning (ML) techniques to analyze the prognostic factors of mortality that are significant at the time of diagnosis. Clinical and analytical data of interest in patients with HCC were gathered. Results: Meeting Milan criteria, Barcelona Clinic Liver Cancer (BCLC) classification and albumin levels were the variables with the greatest impact on the prognosis of HCC patients. The ML algorithm that achieved the best results was random forest (RF). Conclusions: The development of a predictive prognostic model at the diagnosis is a valuable tool for patients with HCC and for application in clinical practice. RF is useful and reliable in the analysis of prognostic factors in the diagnosis of HCC. The search for new prognostic factors is still necessary in patients with HCC.
Keywords:
hepatocellular carcinoma; machine learning; prognosis; mortality; Milan criteria; BCLC; albumin 1. Introduction
Primary liver tumors are the seventh most common cause of cancer worldwide and the second leading cause of cancer-related deaths. Hepatocellular carcinoma (HCC) is the most common primary liver neoplasm, accounting for 75% of cases of primary liver malignancies [1]. HCC is an adenocarcinoma-type neoplasm that originates in hepatocytes due to sustained cellular damage and stress. This damage induces chronic inflammatory changes, necrosis, and fibrosis in hepatocytes, promoting the development of advanced liver disease (ACLD) [2]. The development of advanced chronic liver disease (ACLD) of any etiology is a key factor for HCC development. Up to 80% of HCC cases occur in livers with ACLD. Viral infections with hepatitis C virus (HCV) and hepatitis B virus (HBV), metabolic dysfunction-associated steatotic liver disease (MASLD), and alcohol consumption are the major determinants in the development of ACLD and HCC [3,4]. The prognosis for patients diagnosed with HCC remains poor, with a global mortality rate of 8.3 per 100,000 individuals in 2020 [5]. These data underscore the need for further research in this field.
HCC is diagnosed through imaging tests such as computed tomography (CT), hepatic magnetic resonance imaging (MRI), or contrast-enhanced ultrasound (CEUS) in patients with ACLD or chronic infection with HBV. Currently, confirmatory liver biopsy is not always necessary [6,7], reserved for cases of uncertain diagnosis and for conducting a more detailed histological analysis that allows for molecular and immunological studies to guide treatment, especially in the context of immunotherapy [8,9,10]. Factors such as tumor burden, liver dysfunction, and the patient’s functional status play a crucial role in prognosis and therapeutic approach. Staging systems such as the Barcelona Clinic Liver Cancer (BCLC) evaluate these aspects, along with objective scores like the Model for End-stage Liver Disease (MELD), the albumin–bilirubin (ALBI) score, and biomarkers such as alpha-fetoprotein (AFP) [11,12]. Early detection of HCC is associated with increased survival [13], and screening programs based on ultrasound monitoring and AFP measurements every 6 months are implemented in patients with ACLD or chronic HBV infection [3,14,15,16]. However, the precise identification of risk populations remains a challenge, and scores like PAGE-B and GALAD assist in risk stratification [17,18]. Despite advances, accurate risk prediction, early detection, prognosis at diagnosis, and personalized treatments are areas that require further research and development [19]. Improving studies on prognostic factors for mortality in HCC is essential to determine their impact on clinical decision making.
Considering the limited published scientific literature, the following study assessing clinical and analytical data for HCC diagnosis was proposed. The main goal is to develop a predictive model for prognostic factors at the diagnosis of this type of tumor. For this purpose, ML algorithms are used. ML employs statistical and mathematical algorithms to extract patterns from variable data, assisting in making complex decisions in medical applications [20,21,22]. These models are designed to make accurate predictions using data from a multitude of variables. In this study, the random forest (RF) algorithm was used. The selection of this ML method is based on its high accuracy, versatility, applicability in large datasets, ability to estimate variable importance, and the lesser need for tuning compared to other ML methods [23,24]. In this way, a predictive model that enables the evaluation of different variables with the most influence on the mortality and prognosis of our HCC patients has been developed.
2. Materials and Methods
2.1. Study Design and Population
A multicenter retrospective study was conducted involving patients diagnosed with HCC in two different hospitals in Castilla-La Mancha, Spain. The participating hospitals were the University Hospital of Guadalajara and the Virgen de la Luz Hospital in Cuenca. Data collection spanned from January 2008 to December 2022. The study approval was granted by the research ethics committee of the University Hospital of Guadalajara.
Inclusion criteria were as follows: Diagnosis of HCC through validated imaging techniques or histological examination in cases of uncertain diagnosis in patients aged 18 years and older. Diagnosis through imaging techniques was performed using triphasic CT or MRI, where the characteristic uptake of HCC was observed. Patients whose HCC diagnosis was made at another center where clinical and analytical data for the diagnosis were not collected were excluded. Additionally, patients diagnosed at these centers without available study target variables were also excluded.
2.2. Data Collection
Patient general information was collected, including gender; active smoking habits at the time of diagnosis; age at HCC diagnosis; censoring date, or date of death if it occurred; and the etiology attributed to HCC (alcohol, HCV, HBV, MASLD, hemochromatosis, autoimmune hepatitis, etc.).
Important clinical characteristics in patients with HCC were noted: the presence of cirrhosis, ACLD, encephalopathy, or clinically significant portal hypertension (CSPH). CSPH was defined as the presence of a hepatic venous portal pressure gradient (HVPG) > 10 mmHg, ascites, or the presence of varices during gastroscopy [25]. Other critical data in tumor assessment, such as the presence of lymphadenopathy, metastasis, portal thrombosis, number and size of hepatic lesions, were also recorded.
Important hepatic analytical data, including albumin (g/dL), international normalized ratio (INR), alanine aminotransferase (ALT) (U/L), aspartate aminotransferase (AST) (U/L), AFP (ng/mL), total bilirubin (mg/dL); other relevant general biochemical data like creatinine (mg/dL), sodium (Na) (mmol/L), C-reactive protein (CRP) (mg/L); and hematologic information involving lymphocyte count (cell/mmc), neutrophil count (cell/mmc), and platelet count (cell/mmc) were also collected.
Using the collected information, staging indices, liver function, and patient baseline status were calculated, including BCLC, Milan Criteria, Child–Pugh, MELD, ECOG (Eastern Cooperative Oncology Group), and TNM. These variables have been validated as useful tools in the management and assessment of patients with liver disease and cancer [11,26,27,28].
2.3. Model Development
To conduct the data analysis, the use of ML techniques was proposed. Specifically, the RF algorithm was chosen to develop the predictive model.
The RF algorithm was compared with other ML methods to verify its accuracy. The algorithms used for comparison were support vector machine (SVM), Bayesian linear discriminant analysis (BLDA), decision tree (DT), Gaussian naïve Bayes (GNB), and K-nearest neighbors (KNN).
SVM is a supervised learning algorithm designed for classification. They seek an optimal hyperplane in a higher-dimensional space, maximizing the margin between classes. SVM handles non-linear data using the kernel trick, transforming it into a more manageable space [24,29].
BLDA extends linear discriminant analysis (LDA) with additional probabilistic assumptions. It assumes multivariate normal distribution within each class and employs Bayesian approaches. BLDA is particularly useful when classes exhibit different distributions or varying variances [24,30].
DT is a predictive model structured as trees featuring decision rules and outcomes. Nodes include the root, internal nodes, and leaf nodes. Depth impacts model generalization, and pruning is applied to prevent overfitting. Construction involves recursively selecting features to split data, maximizing homogeneity [24,31].
GNB is a variant assuming Gaussian distribution for input features. Widely used in classification, it requires a training dataset with class-labeled examples. Parameters for Gaussian distribution are calculated for each class, and Bayes’ rule is used for classification, providing a probabilistic estimation [24,32].
KNN is a supervised learning algorithm for classification based on the majority of labels from k-nearest neighbors. It relies on a training dataset with labeled examples, utilizing a chosen distance metric and a specified k value. Classification involves voting among the k neighbors to determine the label for a new point [33].
Among the various ML techniques, the decision to use this algorithm was made due to its interesting features in this study. On one hand, the RF algorithm is an ensemble learning model. It combines multiple models to obtain a more robust and accurate model compared to a single model. The foundation of RF lies in decision trees. Several decision trees are built during the training process. “Randomness” is key in Random Forest. Variations are introduced during the construction of each tree, either through the random selection of features or through the random selection of samples from the dataset. A process called “bagging” (Bootstrap Aggregating) is used to build the trees in the RF model. This involves training each tree with a random sample from the dataset, allowing the trees to be different from each other. RF is known for being robust against overfitting and for handling large datasets with many features [23,24,34]. This technique is widely used in practice due to its good performance and versatility [35].
Primarily, RF employs an ensemble of decision trees. Each tree is trained independently, and their results are then combined. For RF, the trees are constructed in parallel and independently of each other [24,36].
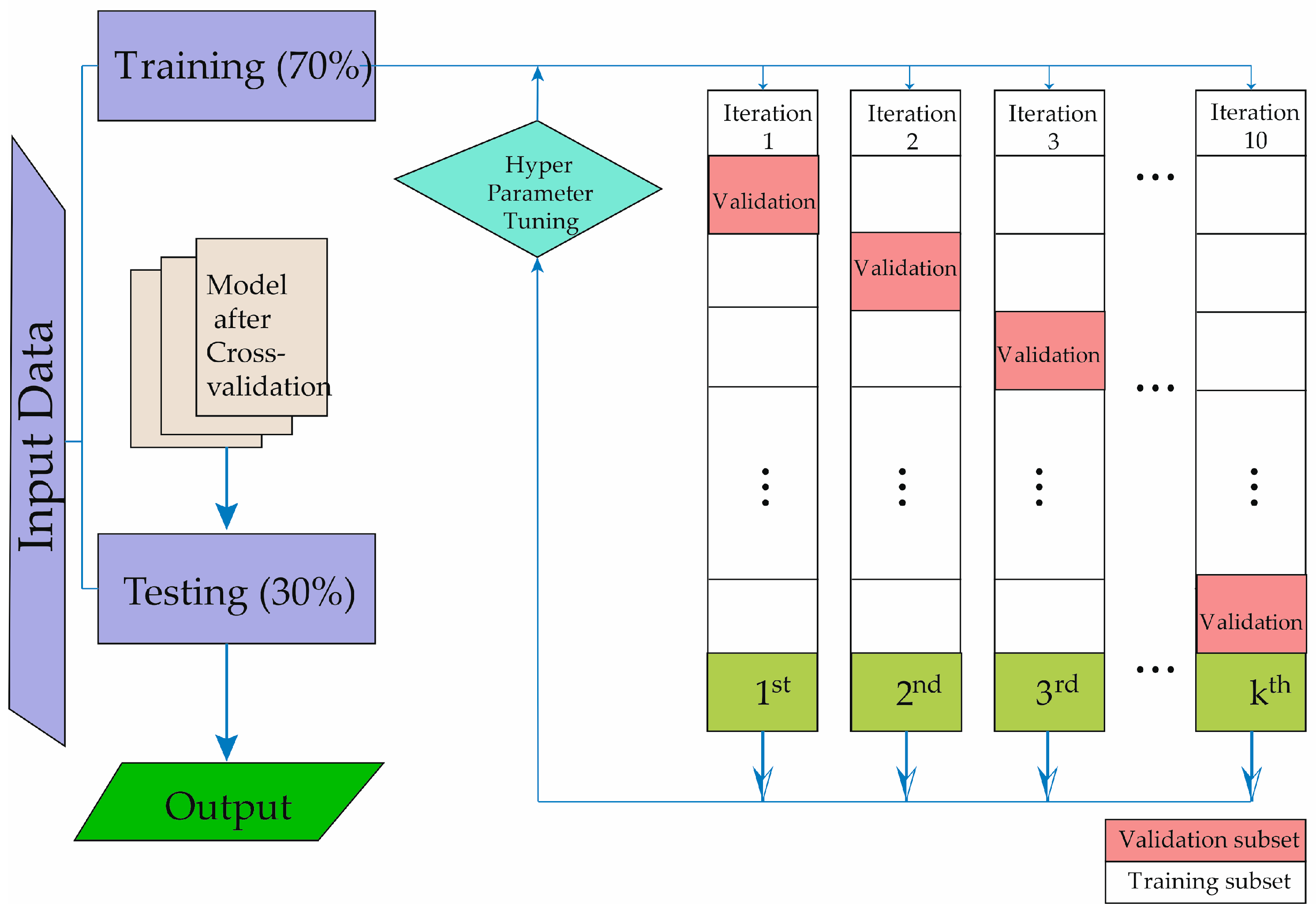
In Figure 1, the technique of cross-validation is described for obtaining our predictive model, allowing the development of machine learning. The study data are divided into two groups. The evaluation cohort of patients underwent 10-fold cross-validation to assess the algorithm’s performance. In each validation fold, 70% of the patients were utilized for training, while the remaining 30% were allocated for testing and validation. The testing process was iterated a hundred times, each time with non-overlapping patient subsets. To prevent the algorithm from being tested on data from the same patients used for training, patient data were not shared between the training and testing subsets. Figure 1 illustrates the step-by-step process undertaken for the entire study. As depicted, the initial phase involved the selection of subjects to be studied. Following the creation of the database, the machine learning methods were then trained and validated.
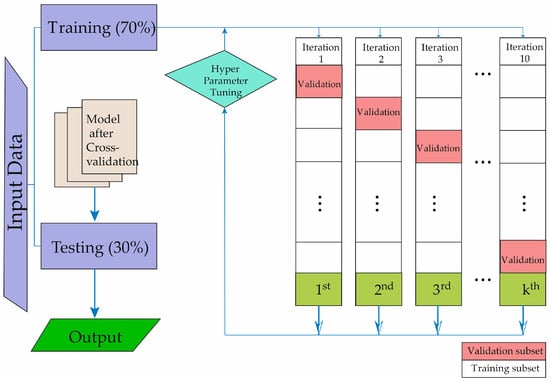
Figure 1.
Description of the machine learning methodology development process.
ML techniques typically incorporate one or more hyperparameters that facilitate the adjustment of the algorithm throughout the training process. Varied values for these hyperparameters, such as the number of splits, learners, neighbors, distance metric, distant weight, kernel, box constraint level, and the multiclass method, among others, contribute to distinct prediction performances. The objective is to achieve optimal performance by optimizing these hyperparameters for each machine learning technique utilized in this study. Bayesian optimization was employed for hyperparameter tuning, aiming to identify configurations that maximize algorithm performance based on previous attempts. This approach assumes a relationship between different hyperparameters and algorithm performance. Performance measures, specifically the area under the curve (AUC) and balanced accuracy were employed for maximization.
The most prominent hyperparameters of the implemented systems are as follows. For the SVM method, a Gaussian kernel function is chosen with the following parameters: C = 1, sigma = 0.5, numerical tolerance = 0.001, and iteration limit = 100. For the DT system, the base parameter estimator is adjusted: tree, maximum number of splits = 20, learning rate = 0.1, and number of learners = 40. GNB algorithm: usekernel: False, fL = 0, and Adjust = 0. As for the BLDA algorithm, the Bayesian kernel was selected. Finally, for the KNN method, the distance metric was Euclidean, and it used 20 neighbors.
2.4. Performance Evaluation
In this work, the different methods were compared with the following metrics: specificity, precision (also known as positive predictive value), recall (also known as sensitivity), balanced accuracy, degenerate Youden index (DYI), F1 score Matthew’s correlation coefficient (MCC), Cohen’s Kappa index (CKI), receiver operating characteristic (ROC), and area under the curve (AUC) [24].
The F1 score is described as:
MCC and DYI were also used to test the performance of the ML methods, defined as:
where TP shows the number of true positives, FP represents the number of false positives, TN is the number of true negatives, and FN corresponds to the number of false negatives. CKI was used to estimate the overall performance of the system [24].
3. Results
In accordance with the mentioned inclusion and exclusion criteria, analyzed data from 191 patients were included.
Baseline data are presented in Table 1 and Table 2, where 86.91% of the patients were males, and 87.96% of the total had ACLD. The mean age at HCC diagnosis was 67.13 years old. Regarding the etiology attributed to HCC, 32.46% were associated with alcohol, 29.32% with HCV, and 13.61% with both. At the time of diagnosis, according to the BCLC classification, 37.17% were in stage A, 30.37% in stage C, 15.18% in stage B, 12.04% in stage D, and 5.24% in stage 0. At diagnosis, 37.17% of the patients met the Milan Criteria. It is noteworthy that only 47.12% of the patients were diagnosed through screening. The median, Q1 (first quartile), Q3 (third quartile), and interquartile range of the age at diagnosis and the most relevant analytical data are documented in Table 2.

Table 1.
Baseline data collected from the study patients. ACLD: advanced chronic liver disease, HCV: Hepatitis C Virus, HBV: Hepatitis B Virus, BCLC: Barcelona Clinic Liver Cancer.
Table 2.
Age at diagnosis and the most relevant analytical data collected from the study patients. Q1: first quartile, Q3: third quartile, IQR: interquartile range, AFP: alpha-fetoprotein, AST: aspartate aminotransferase, ALT: alanine aminotransferase.
Below, the results obtained with the methods in the training phase are presented. As shown in Table 3 and Table 4, the ML models achieve good accuracy in the training phase. The crucial aspect of the training phase is to ensure that the system has the ability to generalize and does not exhibit overfitting. To achieve this, we use the cross-validation technique depicted in Figure 1. This helps prevent the model from memorizing the data and being unable to make accurate predictions on new data. Generalization capacity in machine learning refers to the model’s ability to make accurate predictions on new data, i.e., situations not included in the training set. Successful generalization is essential for a model to be effective in real-world scenarios and to avoid overfitting to specific patterns in the training set [24].
Table 3.
The table shows the results of the mean values of accuracy, recall, specificity, precision, and F1 score obtained from the different ML models and RF method in the training phase. SVM: support vector machine, BLDA: Bayesian linear discriminant analysis, DT: decision tree, GNB: Gaussian naïve Bayes, KNN: K-nearest neighbors, RF: random forest.
Table 4.
The table presents the results of the mean values and standard deviation of MCC, AUC, DYI and Kappa score achieved from the different ML models and the RF method in the training phase. SVM: support vector machine, BLDA: Bayesian linear discriminant analysis, DT: decision tree, GNB: Gaussian naïve Bayes, KNN: K-nearest neighbors, RF: random forest.
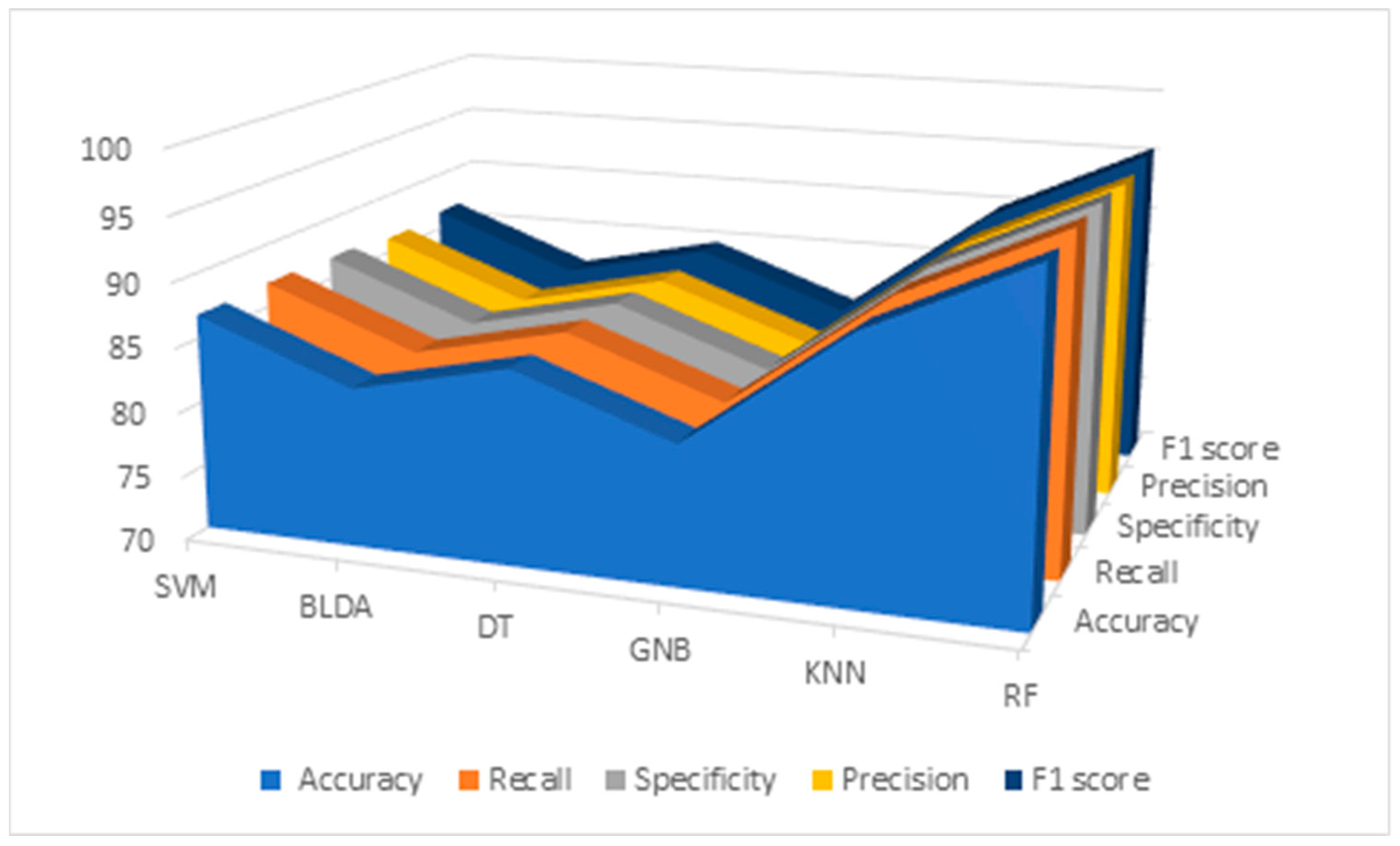
Results of the data analysis conducted by RF and different ML algorithms mentioned before —SVM, BLDA, DT, GNB, and KNN—are presented in Table 5 and Figure 2. As observed, the GNB and BLDA algorithms exhibit the lowest degree of accuracy, just surpassing 80%. KNN demonstrates the highest accuracy, around 90%, but this is still inferior to the one achieved by RF, which reaches 95%. These findings are consistent when analyzing recall, precision, and the F1 score were analyzed.
Table 5.
Results of the mean values and standard deviation of accuracy, recall, specificity, precision, and F1 score obtained from the different ML models and RF method in the study. SVM: support vector machine, BLDA: Bayesian linear discriminant analysis, DT: decision tree, GNB: Gaussian naïve Bayes, KNN: K-nearest neighbors, RF: random forest.
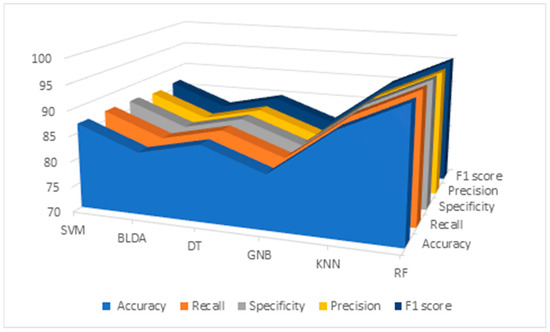
Figure 2.
Descriptive figure of performance metrics (accuracy, recall, specificity, precision, and F1 score) for all methods (SVM, BLDA, DT, GNB, KNN, and RF). SVM: support vector machine. BLDA: Bayesian linear discriminant analysis. DT: decision tree. GNB: Gaussian naïve Bayes. KNN: K-nearest neighbors. RF: random forest.
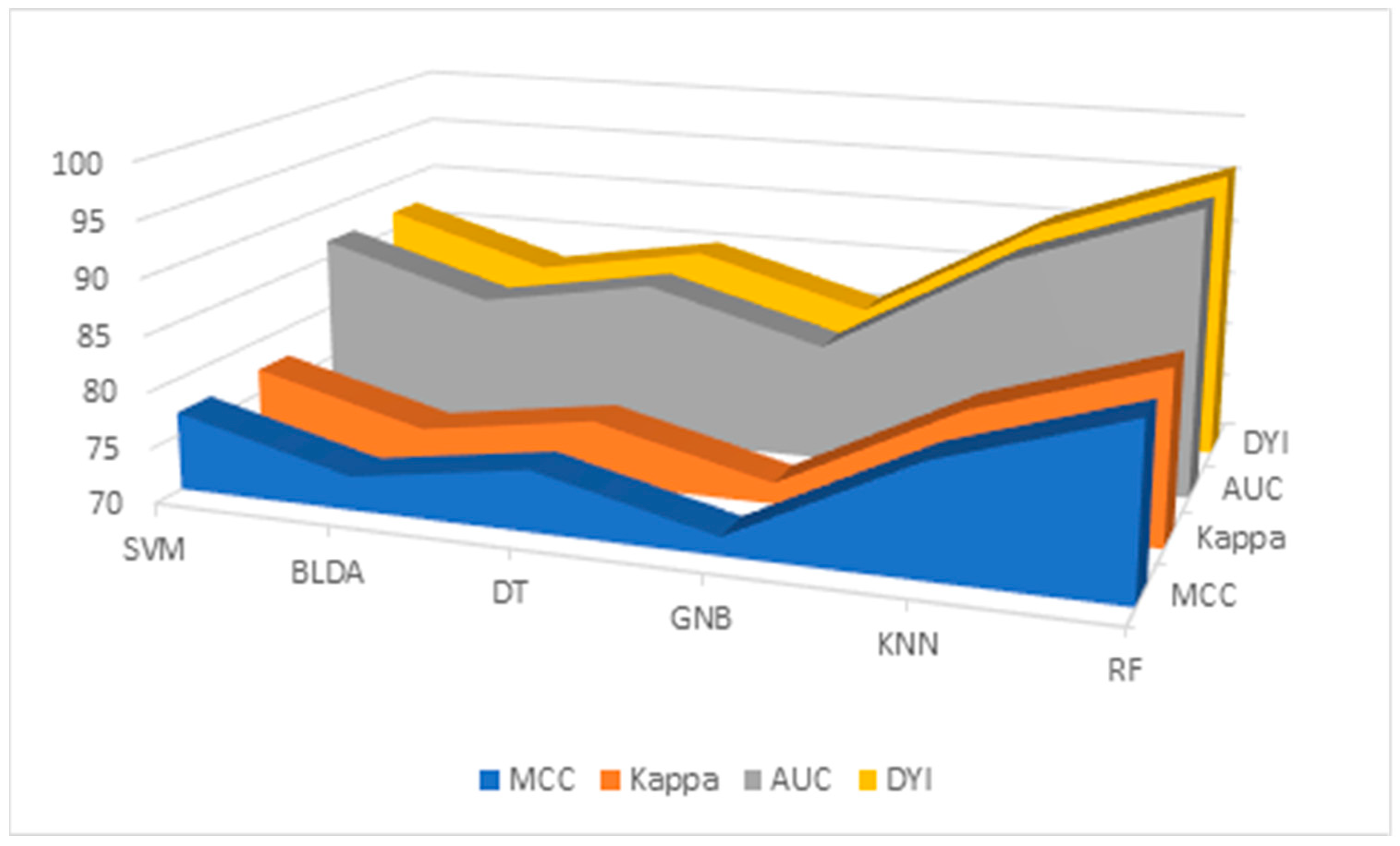
Additionally, the results for the MMC, AUC, DYI, and Kappa index are given in Table 6 and Figure 3, for all the proposed methods. GNB shows the lowest results, with an MCC of 71.64, DYI of 80.73, and Kappa of 71.88. Our proposed RF system exhibits an MCC of 85.13, DYI of 95.94, and Kappa of 85.41, clearly outperforming the other algorithms, such as KNN, SVM, DT, and BLDA, which have lower values. These results, along with those presented in Table 3, indicate that the RF algorithm, among those proposed in ML, was the most suitable algorithm for data analysis and the development of the proposed predictive model.
Table 6.
Results of the mean values and standard deviation of MMC, AUC, DYI, and Kappa obtained from the different ML models and RF method in the study. SVM: support vector machine, BLDA: Bayesian linear discriminant analysis, DT: decision tree, GNB: Gaussian naïve Bayes, KNN: K-nearest neighbors, RF: random forest, MCC: Matthews’ correlation coefficient, AUC: area under the curve, DYI: degenerated Youden index.
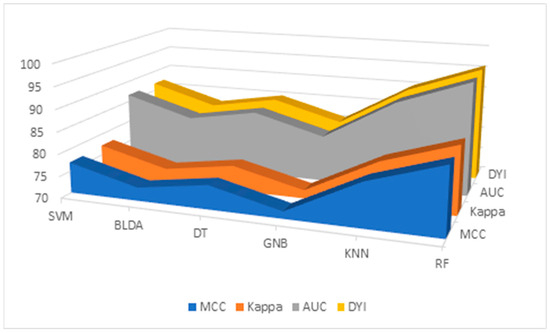
Figure 3.
Descriptive figure of performance metrics (MMC, Kappa, AUC, and DYI) for all methods (SVM, BLDA, DT, GNB, KNN, and RF). SVM: support vector machine. BLDA: Bayesian linear discriminant analysis. DT: decision tree. GNB: Gaussian naïve Bayes. KNN: K-nearest neighbors. RF: random forest. MMC: Matthews’ correlation coefficient, AUC: area under the curve, DYI: degenerated Youden index.
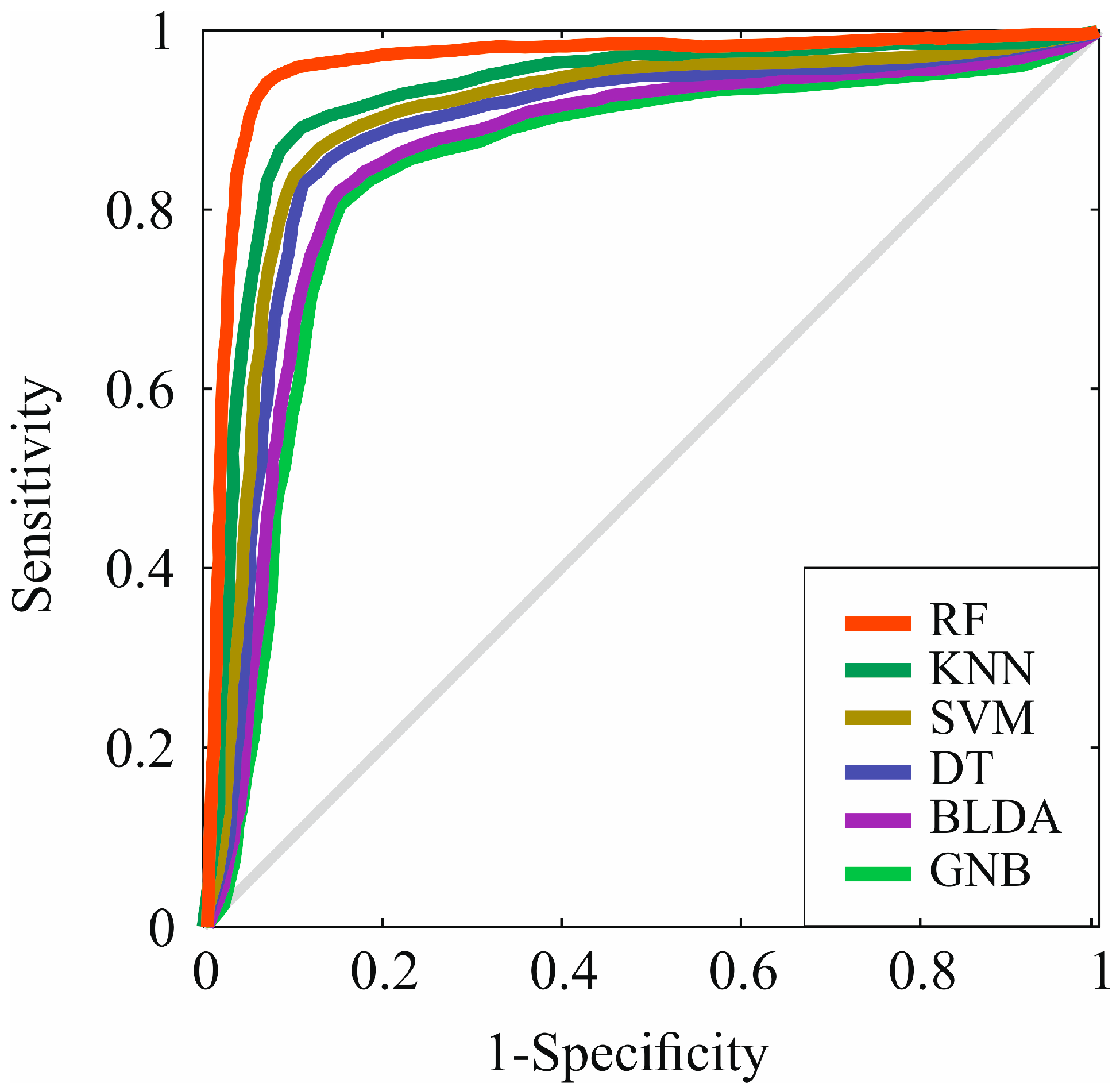
However, in Figure 4, the receiver operating characteristic (ROC) curve of the different ML algorithms can be observed, comparing them among themselves and with the proposed method, RF. As can be observed, in all of them, the AUC is greater than 0.8, but RF presents the highest AUC value compared to the other evaluated methods, standing at 0.96, as shown in Table 6. These results suggest that the RF method has the highest accuracy for predicting prognostic factors at the diagnosis of HCC.
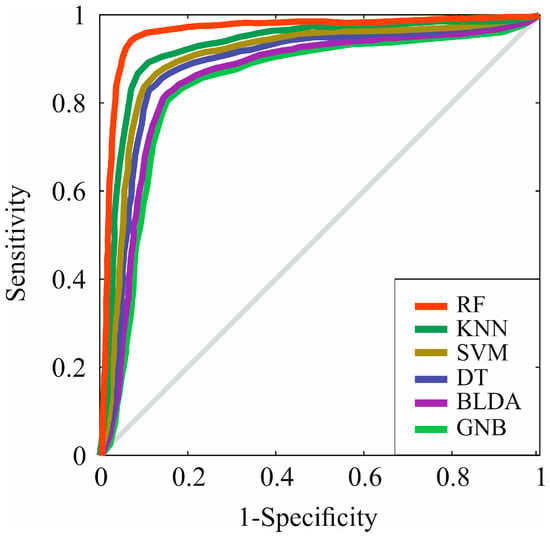
Figure 4.
Representation of ROC curves of the analyzed algorithms. RF: random forest. KNN: K-nearest neighbors. SVM: support vector machine. DT: decision tree. BLDA: bayesian linear discriminant analysis. GNB: Gaussian naïve Bayes.
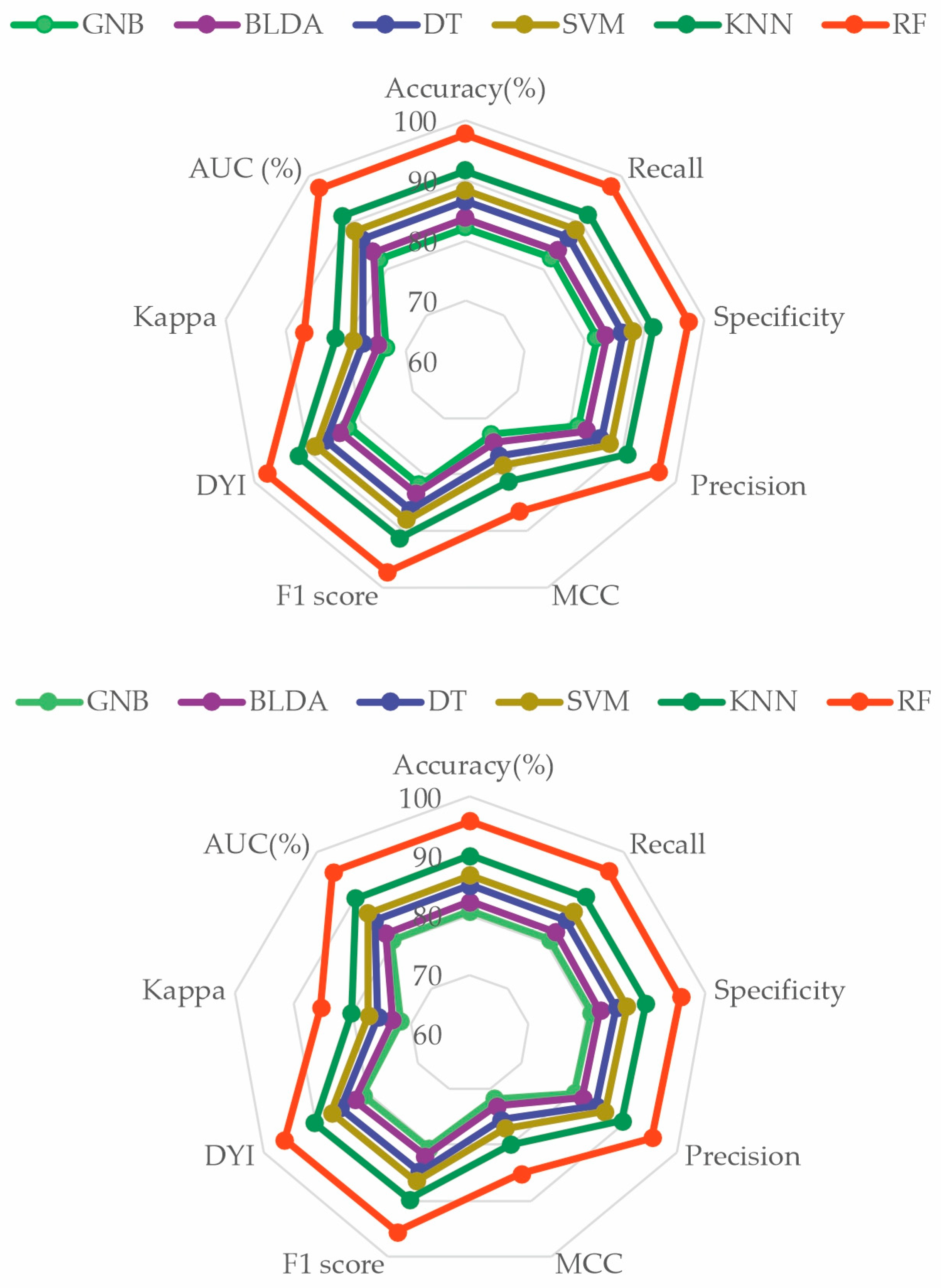
To perform a comprehensive evaluation of all the proposed ML methods, a radar plot was chosen, as depicted in Figure 4. It captures the different metrics and their values for each algorithm. Thus, the larger the area of the circle forming the radar plot, the better the chosen predictive model will be. It is evident that the RF method achieved the widest area. The consistency of the image obtained in both phases—the training phase and the validation phase—demonstrates that RF is accurate, does not overestimate, and therefore, is generalizable. This translates to obtaining appropriate and reliable information with new input data. These results indicate that the RF method is a valid, reproducible, and applicable approach in the development of clinical practice (Figure 5).
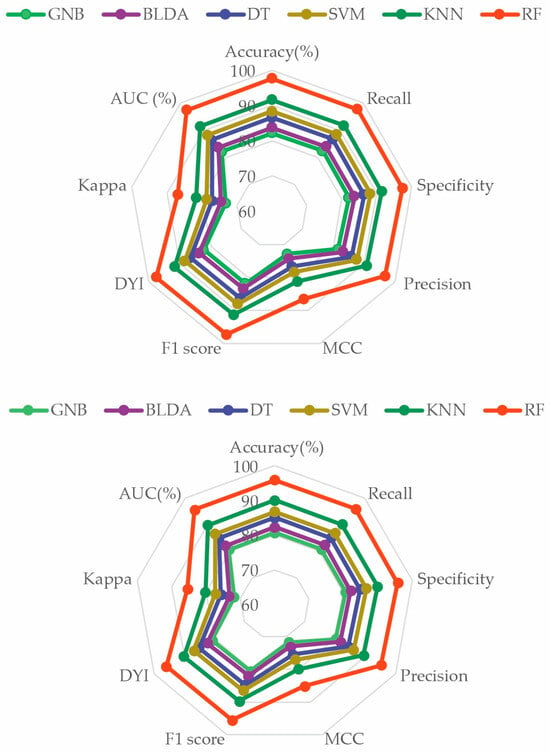
Figure 5.
Radar plot comparing all the analyzed methods. The image above is the training phase, and the image below is the test phase. GNB: Gaussian naïve Bayes. BLDA: Bayesian linear discriminant analysis. DT: decision tree. SVM: support vector machine. KNN: K-nearest neighbors. RF: random forest. MCC: Matthews correlation coefficient. DYI: degenerated Youden index. AUC: area under the curve.
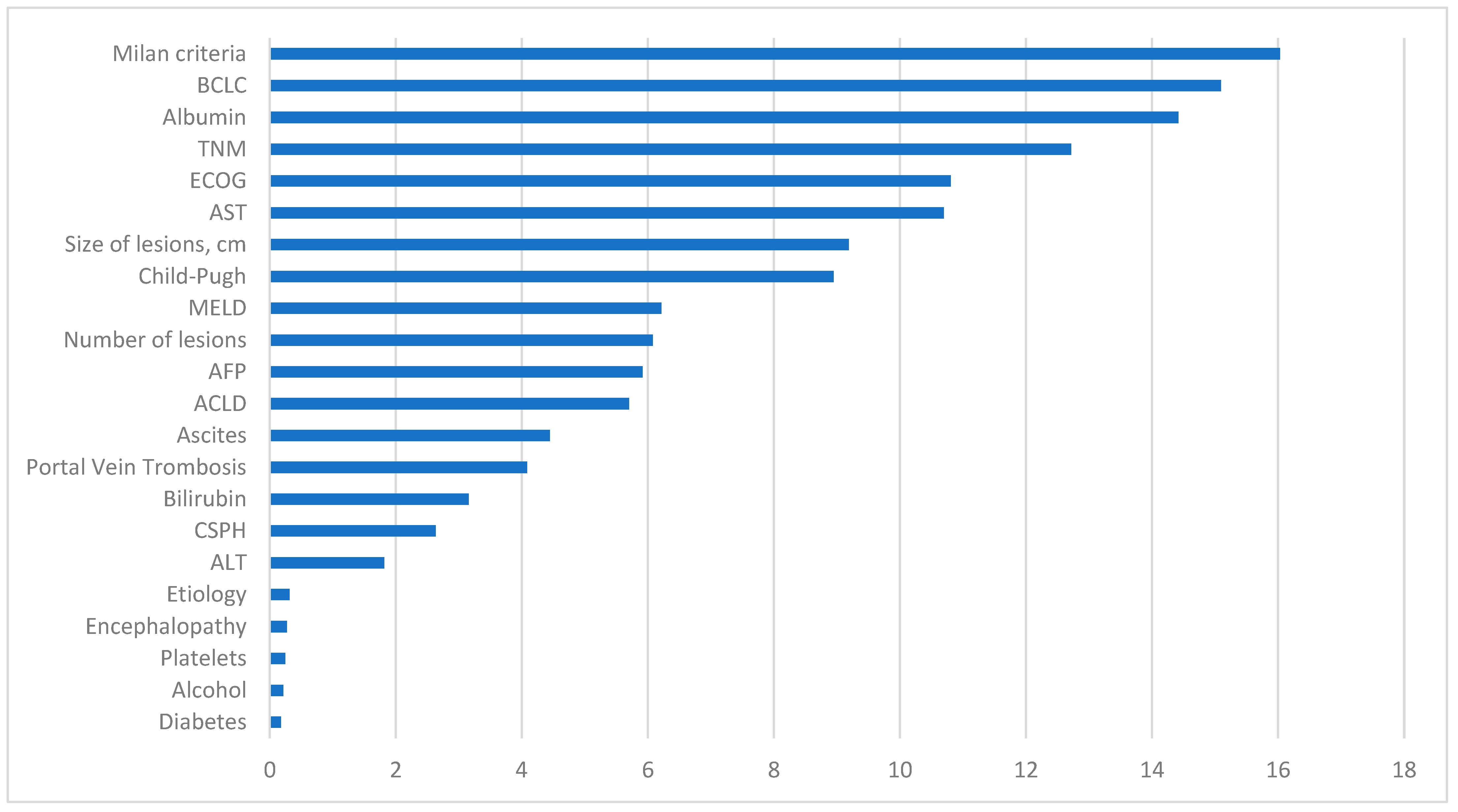
In Figure 6, the variables with the most significant impact on the development of the predictive model are observed. The fulfillment of Milan Criteria was the most crucial variable, followed by one of the calculated scores, the BCLC classification. Additionally, analytical values such as albumin levels were positioned as the third most important factor in terms of significance. The receipt or non-receipt of a liver transplant, ECOG classification, TNM, hepatic lesions size, Child–Pugh classification, and AST levels also play a substantial role in our predictive model.
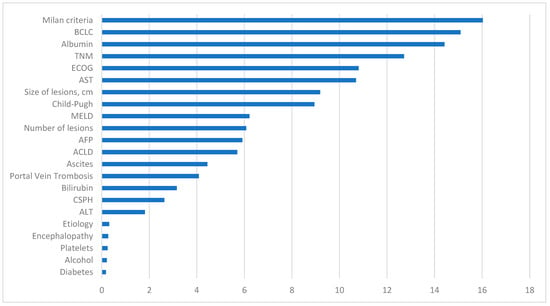
Figure 6.
Representation of the importance of each variable in the machine learning predictive model. BCLC: Barcelona Clinic Liver Cancer, TNM: tumor node metastases, ECOG: Eastern Cooperative Oncology Group, AST: aspartate aminotransferase, MELD: model for end-stage liver disease, AFP: alpha-fetoprotein, ACLD: advanced chronic liver disease, CSPH: clinically significant portal hypertension, ALT: alanine aminotransferase.
Conversely, variables with diminished influence include diabetes status and alcohol consumption. Other analytical data that appear less relevant are platelet count and ALT levels. The etiology attributed to HCC does not exhibit a significant impact in this model, similar to the diagnostic method.
Other initially intriguing markers that did not appear to have a significant influence in our model include CSPH, bilirubin levels, the presence of portal thrombosis, ascites, ACLD, encephalopathy, or AFP levels.
4. Discussion
As previously mentioned, liver tumors stand out as neoplasms with a dismal prognosis, currently ranking as the second leading cause of cancer-related deaths [1]. Urgent research in this field is essential to achieve more substantial goals and develop tools that enhance the prognosis of our patients. A targeted approach to address this issue involves intervening in the primary risk factors for the development of HCC and ACLD. Both HCV and HBV emerge as the primary risk factors for ACLD globally. Vaccination campaigns against HBV and effective treatments against HCV have contributed to a reduction in infections caused by these viruses [3]. However, factors such as MASLD and alcohol consumption continue to be determining factors in the development of ACLD and HCC, with an increasing incidence in recent years, particularly in Western countries [3,37]. Indeed, it seems that managing risk factors is advantageous but not entirely sufficient.
Another tool used to attempt to improve the prognosis of patients with HCC is the implementation of screenings in the selected high-risk population [13,38]. The goal is to achieve early diagnosis in patients predisposed to HCC for better management. It has been demonstrated that ultrasound monitoring, along with AFP measurements, appears to be a cost-effective tool in surveilling HCC development [39].
The management of patients with HCC should be coordinated. Multidisciplinary committees led by gastroenterologists, hepatobiliary surgeons, radiologists, oncologists, and radiotherapists work collaboratively. In these committees, the best therapeutic decisions are reached by consensus, aiming to enhance the prognosis of patients with HCC [40,41,42].
Despite applying these tools, the prognosis for these patients remains very limited, necessitating ongoing research and the development of tools to achieve more ambitious goals with these patients.
This study demonstrates that the variables with the most significant impact on the prognosis of patients with HCC are the indices calculated based on clinical and analytical data, such as the Milan criteria. The Milan criteria are used to assess HCC patients eligible for liver transplantation. Patients with a single lesion between 1 and 5 cm or two or three lesions between 1 and 3 cm are considered suitable for transplantation [43]. Consequently, meeting transplant criteria will have a substantial impact on the prognosis of patients with HCC.
This makes sense, as the survival of patients who undergo transplantation is higher than those who are not candidates. Therefore, there has been a proposal to expand the Milan criteria for years. Criteria such as the University of California, San Francisco (UCSF) criteria, up to seven criteria, extended Toronto criteria, and Kyoto criteria evaluate liver transplantation in patients with a higher tumor burden than the limit established by the Milan criteria. It has been demonstrated that the benefit of liver transplantation remains superior in these patients compared to other therapeutic options [44,45]. Another tool used to optimize initially non-transplantable patients is downstaging. It involves administering neoadjuvant local therapy to these patients so that they meet the necessary criteria for liver transplantation [46,47].
The BCLC, as a stratification tool based on tumor burden, the patient’s baseline state, and liver function, also holds substantial significance as a determinant in the prognosis diagnosis of patients in this study. This aligns with the importance demonstrated by other variables that determine tumor burden, such as TNM, or variables that assess the patient’s baseline state, like the ECOG scale [26,28]. This suggests that the combination of both variables, as assessed by BCLC, along with the analytical analysis of other factors, appears to be a suitable option in assessing the prognosis of patients with HCC. Clinical and analytical scores that assess liver function in patients with ACLD, such as the Child–Pugh score, also show significant relevance in the predictive model [27].
Albumin levels were the analytical value of utmost importance in the predictive model. It can be affirmed that albumin levels are determinant as a prognostic factor in patients with HCC. Low levels of serum albumin are associated with poor nutritional status and a worse prognosis at the diagnosis of HCC [48,49]. Furthermore, various studies describe the importance of albumin as a negative regulator in the progression of HCC, particularly in local invasion and metastasis of HCC [50]. It has been demonstrated that albumin levels allow for an adequate assessment of hepatic functional reserve in patients with HCC. They have been combined in different indices such as ALBI or PALBI (platelet–albumin–bilirubin ratio), which discriminate the survival of patients with HCC [51]. In contrast, in this study, the significance of bilirubin levels and platelet count is not as pronounced as that observed with albumin. Further research is needed to evaluate these indices as prognostic factors in HCC.
Nevertheless, ACLD itself and its typical characteristics, such as the presence of ascites, encephalopathy, and CSPH, lack a decisive impact in the predictive model. As mentioned, around 80% of HCC cases occur in the liver with ACLD, and moreover, the population in this study has a similar prevalence, reaching 87.96%. These data suggest that the isolated presence of ascites, encephalopathy, or CSPH does not influence the prognosis of HCC. In contrast, the combination of these factors translates into hepatic dysfunction that does affect the predictive model. It can be concluded that the degree of tumor burden and the patient’s functional status carry more weight than the level of hepatic dysfunction in the prognostic assessment of the study’s patients, highlighting the need for further research.
According to the study findings, not meeting Milan criteria, being in stages B, C, and D of the BCLC, and having low levels of albumin are associated with an unfavorable prognosis in patients with HCC. These data enable us to identify which patients will have a more favorable prognosis and which ones could benefit from different therapeutic options, leading to an increasingly personalized management approach for patients. In this regard, a tool using the proposed method could be generated, and an executable interface could also be installed on medical equipment. This hardware/software tool must comply with European regulations on medical devices and must also have minimum technical characteristics (it is worthwhile to mention that currently, all computers can easily meet these requirements).
An active search was conducted of the current literature on determining prognostic factors for mortality at the diagnosis of HCC using ML techniques. Only one article, authored by Hiraoka et al. [52], was found in which artificial intelligence is utilized to develop a predictive prognostic model related to short- and medium-term survival outcomes. This model is designed to inform decision making regarding the optimal therapeutic approach for both initial and recurrent cases of HCC. Studies that employed ML techniques were identified to classify patients benefiting from immunotherapy in HCC [53] or outlined the application of ML techniques in analyzing radiological and histological images to obtain diagnostic and prognostic information for HCC patients [54]. Within this context, multiple articles describe the analysis of potential prognostic biomarkers for HCC [55,56,57,58,59], which are covered in Piñero et al.’s review [59]. Stefano et al. perform a review of the most relevant biomarkers in the prognosis of HCC [57]. Lima et al. detail, in their review, the potential new minimally invasive biomarkers in the diagnosis and prognosis of HCC [58]. The data analysis in these studies is conducted through conventional statistics, and the review concludes that more tools are needed to determine the prognosis of patients with HCC [59].
The use of ML techniques for the analysis of clinical and analytical data in HCC patients to develop a predictive mortality model and identify prognostic factors at the diagnosis has not been explored. Thus, the aim of this study is to employ various widely used machine learning methods in the scientific and medical community to develop a useful tool for assessing the prognosis of patients with HCC. The selection of the proposed RF method over alternative machine learning algorithms is grounded in the notable advantages that position it as a superior choice in terms of accuracy, robustness, and versatility. Compared to SVM, RF exhibits a unique ability to handle complex and high-dimensional datasets without compromising computational efficiency. The inherent diversity in its ensemble approach minimizes the risk of overfitting, providing more general and predictive models, particularly in scenarios with elevated problem complexity. Against GNB, RF stands out for its effective handling of irrelevant or noisy features. The inclusion of multiple independent decision trees allows the model to ignore less informative variables, significantly enhancing robustness and prediction efficacy. Unlike KNN, which may be sensitive to noisy data, RF demonstrates inherent resilience to dataset noise and variability. By constructing models based on multiple trees, the impact of outliers or errors is mitigated, ensuring greater reliability in decision making. In summary, the preference for RF is justified by its ability to deliver robust and accurate predictive models, especially in complex environments and large datasets. Its resistance to overfitting, capacity to handle irrelevant features, and versatility relative to other algorithms make it a preferred choice, ensuring more reliable results and enhancing the model’s generalization capabilities.
As observed in the results, the proposed RF algorithm achieved the best outcomes in all analyzed parameters, with most metrics surpassing 90%. These results outperformed all other machine learning algorithms evaluated. This allows for the creation of an effective tool for classifying HCC patients. Moreover, the main determinants influencing the prognosis of HCC patients were identified. This tool aids in clinical practice for decision making by healthcare professionals, enhancing the quality of life for patients.
5. Conclusions
Meeting Milan criteria and BCLC classification are the variables with the greatest impact on the prognosis of patients with HCC in the developed predictive model. Both are valuable in clinical practice. Albumin levels emerge as an analytical variable that holds significant importance in the prognosis of HCC patients, and their combination with other analytical values may be interesting for the development of new prognostic biomarkers in HCC.
The proposed RF method achieves the best results in identifying the main prognostic factors of HCC at diagnosis and in the development of the predictive model. RF achieved superior results in all analyzed parameters, securing an AUC of 0.96 and standing out from the other proposed models. These results demonstrate that RF is useful and reliable for the analysis of prognostic factors in HCC diagnosis.
The development of a predictive prognostic model at the diagnosis of HCC aims to identify the factors that most influence patient mortality. This tool allows us to determine the prognosis of patients and, in the future, could help us personalize and optimize the management of patients at the time of HCC diagnosis. Therefore, it is essential to conduct the search for new prognostic factors and develop additional tools.
Author Contributions
Conceptualization: P.M.-B., M.S., S.G.-R., A.M.T., M.T. and J.M.; methodology, P.M.-B., S.G.-R., M.S., A.M.T., M.T. and J.M.; software, A.M.T. and J.M.; validation, A.M.T. and J.M.; formal analysis, A.M.T. and J.M.; investigation, P.M.-B., M.S., S.G.-R., N.M.-G. and M.T.; resources, P.M.-B., M.S., S.G.-R., A.M.T., M.T. and J.M.; data curation, P.M.-B., M.S., S.G.-R., A.M.T., N.M.-G., M.T. and J.M.; writing—original draft preparation, P.M.-B., M.S. and J.M.; writing—review and editing, P.M.-B., M.S., S.G.-R., A.M.T., N.M.-G., P.B., M.T. and J.M.; visualization, P.M.-B., M.S., S.G.-R., A.M.T., N.M.-G., P.B., M.T. and J.M.; supervision, M.T. and J.M.; project administration, P.M.-B., M.S. and J.M.; funding acquisition, P.B. and J.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Fundación Investigación Hospital General Universitario de Valencia and the Institute of Technology of University of Castilla-La Mancha (Spain).
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki and approved by the Ethics Committee of the University Hospital of Guadalajara.
Informed Consent Statement
Patient consent was waived due to the number of patients, study design (retrospective), absence of medical prescription, and the number of deceased patients.
Data Availability Statement
The datasets used and/or analyzed during the present study are available from the corresponding author upon reasonable request.
Acknowledgments
This study was sponsored by Virgen de la Luz Hospital of Cuenca (Spain), Guadalajara University Hospital, Fundación Investigación Hospital General Universitario de Valencia, and the Institute of Technology of the University of Castilla-La Mancha (Spain).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- McGlynn, K.A.; Petrick, J.L.; El-Serag, H.B. Epidemiology of Hepatocellular Carcinoma. Hepatol. Baltim. Md. 2021, 73 (Suppl. S1), 4–13. [Google Scholar] [CrossRef]
- Forner, A.; Reig, M.; Bruix, J. Hepatocellular carcinoma. Lancet 2018, 391, 1301–1314. [Google Scholar] [CrossRef]
- Singal, A.G.; Llovet, J.M.; Yarchoan, M.; Mehta, N.; Heimbach, J.K.; Dawson, L.A.; Taddei, T.H. AASLD Practice Guidance on prevention, diagnosis, and treatment of hepatocellular carcinoma. Hepatology 2023, 78, 1922–1965. [Google Scholar] [CrossRef]
- Chan, W.K.; Chuah, K.H.; Rajaram, R.B.; Lim, L.L.; Ratnasingam, J.; Vethakkan, S.R. Metabolic Dysfunction-Associated Steatotic Liver Disease (MASLD): A State-of-the-Art Review. J. Obes. Metab. Syndr. 2023, 32, 197–213. [Google Scholar] [CrossRef] [PubMed]
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F.; Bsc, M.F.B.; Me, J.F.; Soerjomataram, M.I.; et al. Global Cancer Statistics 2020: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Moctezuma-Velázquez, C.; Lewis, S.; Lee, K.; Amodeo, S.; Llovet, J.M.; Schwartz, M.; Abraldes, J.G.; Villanueva, A. Non-invasive imaging criteria for the diagnosis of hepatocellular carcinoma in non-cirrhotic patients with chronic hepatitis B. JHEP Rep. 2021, 3, 100364. [Google Scholar] [CrossRef] [PubMed]
- Hanna, R.F.; Miloushev, V.Z.; Tang, A.; Finklestone, L.A.; Brejt, S.Z.; Sandhu, R.S.; Sirlin, C.B. Comparative 13-year meta-analysis of the sensitivity and positive predictive value of ultrasound, CT, and MRI for detecting hepatocellular carcinoma. Abdom. Radiol. 2016, 41, 71–90. [Google Scholar] [CrossRef] [PubMed]
- Llovet, J.M.; Kelley, R.K.; Villanueva, A.; Singal, A.G.; Pikarsky, E.; Roayaie, S.; Lencioni, R.; Koike, K.; Zucman-Rossi, J.; Fin, R.S. Hepatocellular carcinoma. Nat. Rev. Dis. Primer 2021, 7, 1–28. [Google Scholar] [CrossRef] [PubMed]
- Llovet, J.M.; Villanueva, A.; Marrero, J.A.; Schwartz, M.; Meyer, T.; Galle, P.R.; Finn, R.S. Trial Design and Endpoints in Hepatocellular Carcinoma: AASLD Consensus Conference. Hepatology 2021, 73 (Suppl. S1), 158–191. [Google Scholar] [CrossRef] [PubMed]
- Sangro, B.; Melero, I.; Wadhawan, S.; Finn, R.S.; Abou-Alfa, G.K.; Cheng, A.-L.; Yau, T.; Furuse, J.; Park, J.-W.; Boyd, Z.; et al. Association of inflammatory biomarkers with clinical outcomes in nivolumab-treated patients with advanced hepatocellular carcinoma. J. Hepatol. 2020, 73, 1460–1469. [Google Scholar] [CrossRef]
- Llovet, J.M.; Brú, C.; Bruix, J. Prognosis of hepatocellular carcinoma: The BCLC staging classification. Semin. Liver Dis. 1999, 19, 329–338. [Google Scholar] [CrossRef]
- Johnson, P.J.; Berhane, S.; Kagebayashi, C.; Satomura, S.; Teng, M.; Reeves, H.L.; O’Beirne, J.; Fox, R.; Skowronska, A.; Palmer, D.; et al. Assessment of liver function in patients with hepatocellular carcinoma: A new evidence-based approach-the ALBI grade. J. Clin. Oncol. Off. J. Am. Soc. Clin. Oncol. 2015, 33, 550–558. [Google Scholar] [CrossRef] [PubMed]
- Singal, A.G.; Zhang, E.; Narasimman, M.; Rich, N.E.; Waljee, A.K.; Hoshida, Y.; Yang, J.D.; Reig, M.; Cabibbo, G.; Nahon, P.; et al. HCC surveillance improves early detection, curative treatment receipt, and survival in patients with cirrhosis: A meta-analysis. J. Hepatol. 2022, 77, 128–139. [Google Scholar] [CrossRef] [PubMed]
- Moon, A.M.; Singal, A.G.; Tapper, E.B. Contemporary Epidemiology of Chronic Liver Disease and Cirrhosis. Clin. Gastroenterol. Hepatol. Off. Clin. Pract. J. Am. Gastroenterol. Assoc. 2020, 18, 2650–2666. [Google Scholar] [CrossRef]
- El-Serag, H.B.; Kanwal, F.; Feng, Z.; Marrero, J.A.; Khaderi, S.; Singal, A.G. Risk Factors for Cirrhosis in Contemporary Hepatology Practices-Findings From the Texas Hepatocellular Carcinoma Consortium Cohort. Gastroenterology 2020, 159, 376–377. [Google Scholar] [CrossRef] [PubMed]
- Santi, V.; Trevisani, F.; Gramenzi, A.; Grignaschi, A.; Mirici-Cappa, F.; Del Poggio, P.; Di Nolfo, M.A.; Benvegnù, L.; Farinati, F.; Zoli, M.; et al. Semiannual surveillance is superior to annual surveillance for the detection of early hepatocellular carcinoma and patient survival. J. Hepatol. 2010, 53, 291–297. [Google Scholar] [CrossRef] [PubMed]
- Papatheodoridis, G.V.; Dalekos, G.N.; Sypsa, V.; Yurdaydin, C.; Buti, M.; Goulis, J.; Calleja, J.L.; Chi, H.; Manolakopoulos, S.; Mangia, G.; et al. PAGE-B predicts the risk of developing hepatocellular carcinoma in Caucasians with chronic hepatitis B on 5-year antiviral therapy. J. Hepatol. 2016, 64, 800–806. [Google Scholar] [CrossRef]
- Guan, M.-C.; Zhang, S.-Y.; Ding, Q.; Li, N.; Fu, T.-T.; Zhang, G.-X.; He, Q.-Q.; Shen, F.; Yang, T.; Zhu, H. The Performance of GALAD Score for Diagnosing Hepatocellular Carcinoma in Patients with Chronic Liver Diseases: A Systematic Review and Meta-Analysis. J. Clin. Med. 2023, 12, 949. [Google Scholar] [CrossRef] [PubMed]
- Ahn, J.C.; Qureshi, T.A.; Singal, A.G.; Li, D.; Yang, J.D. Deep learning in hepatocellular carcinoma: Current status and future perspectives. World J. Hepatol. 2021, 13, 2039–2051. [Google Scholar] [CrossRef]
- Usategui, I.; Arroyo, Y.; Torres, A.M.; Barbado, J.; Mateo, J. Systemic Lupus Erythematosus: How Machine Learning Can Help Distinguish between Infections and Flares. Bioengineering 2024, 11, 90. [Google Scholar] [CrossRef]
- Casillas, N.; Ramón, A.; Torres, A.M.; Blasco, P.; Mateo, J. Predictive Model for Mortality in Severe COVID-19 Patients across the Six Pandemic Waves. Viruses 2023, 15, 2184. [Google Scholar] [CrossRef]
- Suárez, M.; Martínez, R.; Torres, A.M.; Ramón, A.; Blasco, P.; Mateo, J. A Machine Learning-Based Method for Detecting Liver Fibrosis. Diagnostics 2023, 13, 2952. [Google Scholar] [CrossRef]
- Devyatkin, D.A. Estimation of Vegetation Indices With Random Kernel Forests. IEEE Access 2023, 11, 29500–29509. [Google Scholar] [CrossRef]
- Data Mining: Concepts and Techniques—Jiawei Han, Jian Pei, Hanghang Tong—Google Libros [Internet]. Available online: https://books.google.es/books?hl=es&lr=&id=NR1oEAAAQBAJ&oi=fnd&pg=PP1&dq=Han,+J.%3B+Kamber,+M.%3B+Pei,+J.+Data+Mining:+Concepts+and+Techniques%3B+Morgan+Kauf-mann+Publishers:+Burlington,+MA,+USA,+2022&ots=_N1ILHydr2&sig=7i1Ulr5S5CNkGzIs3URWUzdIgTU#v=onepage&q&f=false (accessed on 22 January 2024).
- Gunarathne, L.S.; Rajapaksha, H.; Shackel, N.; Angus, P.W.; Herath, C.B. Cirrhotic portal hypertension: From pathophysiology to novel therapeutics. World J. Gastroenterol. 2020, 26, 6111–6140. [Google Scholar] [CrossRef] [PubMed]
- Reig, M.; Forner, A.; Rimola, J.; Ferrer-Fàbrega, J.; Burrel, M.; Garcia-Criado, Á.; Kelley, R.K.; Galle, P.R.; Mazzaferro, V.; Salem, R.; et al. BCLC strategy for prognosis prediction and treatment recommendation: The 2022 update. J. Hepatol. 2022, 76, 681–693. [Google Scholar] [CrossRef] [PubMed]
- Ruf, A.; Dirchwolf, M.; Freeman, R.B. From Child-Pugh to MELD score and beyond: Taking a walk down memory lane. Ann. Hepatol. 2022, 27, 100535. [Google Scholar] [CrossRef]
- Sok, M.; Zavrl, M.; Greif, B.; Srpčič, M. Objective assessment of WHO/ECOG performance status. Support Care Cancer Off. J. Multinatl. Assoc. Support Care Cancer 2019, 27, 3793–3798. [Google Scholar] [CrossRef] [PubMed]
- Valkenborg, D.; Rousseau, A.J.; Geubbelmans, M.; Burzykowski, T. Support vector machines. Am. J. Orthod. Dentofacial. Orthop. 2023, 164, 754–757. [Google Scholar] [CrossRef]
- Rajaguru, H.; Kumar Prabhakar, S. Bayesian Linear Discriminant Analysis for Breast Cancer Classification. In Proceedings of the 2017 2nd International Conference on Communication and Electronics Systems (ICCES) [Internet], Coimbatore, India, 19–20 October 2017; pp. 266–269. Available online: https://ieeexplore.ieee.org/abstract/document/8321279 (accessed on 23 January 2024).
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 2014, 13, 8–17. [Google Scholar] [CrossRef]
- Chaplot, N.; Pandey, D.; Kumar, Y.; Sisodia, P.S. A Comprehensive Analysis of Artificial Intelligence Techniques for the Prediction and Prognosis of Genetic Disorders Using Various Gene Disorders. Arch. Comput. Methods Eng. 2023, 30, 3301–3323. [Google Scholar] [CrossRef]
- Uddin, S.; Haque, I.; Lu, H.; Moni, M.A.; Gide, E. Comparative performance analysis of K-nearest neighbour (KNN) algorithm and its different variants for disease prediction. Sci. Rep. 2022, 12, 6256. [Google Scholar] [CrossRef] [PubMed]
- Han, S.; Williamson, B.D.; Fong, Y. Improving random forest predictions in small datasets from two-phase sampling designs. BMC Med. Inform. Decis. Mak. 2021, 21, 322. [Google Scholar] [CrossRef]
- Chen, X.; Yu, S.; Zhang, Y.; Chu, F.; Sun, B. Machine Learning Method for Continuous Noninvasive Blood Pressure Detection Based on Random Forest. IEEE Access 2021, 9, 34112–34118. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques, 3rd ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2011; 696p. [Google Scholar]
- Vitale, A.; Svegliati-Baroni, G.; Ortolani, A.; Cucco, M.; Dalla Riva, G.V.; Giannini, E.G.; Farinati, F. Epidemiological trends and trajectories of MAFLD-associated hepatocellular carcinoma 2002–2033: The ITA.LI. CA database. Gut 2023, 72, 141–152. [Google Scholar] [CrossRef]
- Singal, A.G.; Pillai, A.; Tiro, J. Early detection, curative treatment, and survival rates for hepatocellular carcinoma surveillance in patients with cirrhosis: A meta-analysis. PLoS Med. 2014, 11, e1001624. [Google Scholar] [CrossRef]
- Parikh, N.D.; Singal, A.G.; Hutton, D.W.; Tapper, E.B. Cost-Effectiveness of Hepatocellular Carcinoma Surveillance: An Assessment of Benefits and Harms. Am. J. Gastroenterol. 2020, 115, 1642–1649. [Google Scholar] [CrossRef] [PubMed]
- Serper, M.; Taddei, T.H.; Mehta, R.; D’Addeo, K.; Dai, F.; Aytaman, A.; Baytarian, M.; Fox, R.; Hunt, K.; Goldberg, D.S.; et al. Association of Provider Specialty and Multidisciplinary Care with Hepatocellular Carcinoma Treatment and Mortality. Gastroenterology 2017, 152, 1954–1964. [Google Scholar] [CrossRef]
- El Dahan, K.S.; Reczek, A.; Daher, D.; Rich, N.E.; Yang, J.D.; Hsiehchen, D.; Singal, A.G. Multidisciplinary care for patients with HCC: A systematic review and meta-analysis. Hepatol. Commun. 2023, 7, e0143. [Google Scholar] [CrossRef]
- Asrani, S.K.; Ghabril, M.S.; Kuo, A.; Merriman, R.B.; Morgan, T.; Parikh, N.D.; Ovchinsky, N.; Kanwal, F.; Volk, M.L.; Ho, C.; et al. Quality measures in HCC care by the Practice Metrics Committee of the American Association for the Study of Liver Diseases. Hepatology 2022, 75, 1289–1299. [Google Scholar] [CrossRef]
- Martin, P.; DiMartini, A.; Feng, S.; Brown, R.; Fallon, M. Evaluation for liver transplantation in adults: 2013 practice guideline by the American Association for the Study of Liver Diseases and the American Society of Transplantation. Hepatol. Baltim. Md. 2014, 59, 1144–1165. [Google Scholar] [CrossRef]
- Kaido, T.; Ogawa, K.; Mori, A.; Fujimoto, Y.; Ito, T.; Tomiyama, K.; Takada, Y.; Uemoto, S. Usefulness of the Kyoto criteria as expanded selection criteria for liver transplantation for hepatocellular carcinoma. Surgery 2013, 154, 1053–1060. [Google Scholar] [CrossRef]
- Santopaolo, F.; Lenci, I.; Milana, M.; Manzia, T.M.; Baiocchi, L. Liver transplantation for hepatocellular carcinoma: Where do we stand? World J. Gastroenterol. 2019, 25, 2591–2602. [Google Scholar] [CrossRef]
- Mehta, N.; Dodge, J.L.; Grab, J.D.; Yao, F.Y. National Experience on Down-Staging of Hepatocellular Carcinoma Before Liver Transplant: Influence of Tumor Burden, Alpha-Fetoprotein, and Wait Time. Hepatol. Baltim. Md. 2020, 71, 943–954. [Google Scholar] [CrossRef] [PubMed]
- Mazzaferro, V.; Citterio, D.; Bhoori, S.; Bongini, M.; Miceli, R.; De Carlis, L.; Colledan, M.; Salizzoni, M.; Romagnoli, R.; Antonelli, B.; et al. Liver transplantation in hepatocellular carcinoma after tumour downstaging (XXL): A randomised, controlled, phase 2b/3 trial. Lancet Oncol. 2020, 21, 947–956. [Google Scholar] [CrossRef]
- Man, Z.; Pang, Q.; Zhou, L.; Wang, Y.; Hu, X.; Yang, S.; Jin, H.; Liu, H. Prognostic significance of preoperative prognostic nutritional index in hepatocellular carcinoma: A meta-analysis. HPB 2018, 20, 888–895. [Google Scholar] [CrossRef] [PubMed]
- Liang, X.; Liangliang, X.; Peng, W.; Tao, Y.; Jinfu, Z.; Ming, Z.; Mingqing, X. Combined prognostic nutritional index and albumin-bilirubin grade to predict the postoperative prognosis of HBV-associated hepatocellular carcinoma patients. Sci. Rep. 2021, 11, 14624. [Google Scholar] [CrossRef]
- Fu, X.; Yang, Y.; Zhang, D. Molecular mechanism of albumin in suppressing invasion and metastasis of hepatocellular carcinoma. Liver Int. Off. J. Int. Assoc. Study Liver 2022, 42, 696–709. [Google Scholar] [CrossRef] [PubMed]
- Liu, P.; Hsu, C.; Hsia, C.; Lee, Y.; Chiou, Y.; Huang, Y.; Lee, F.; Lin, H.; Hou, M.; Huo, T. ALBI and PALBI grade predict survival for HCC across treatment modalities and BCLC stages in the MELD Era. J. Gastroenterol. Hepatol. 2017, 32, 879–886. [Google Scholar] [CrossRef]
- Hiraoka, A.; Kumada, T.; Tada, T.; Toyoda, H.; Kariyama, K.; Hatanaka, T.; Kakizaki, S.; Naganuma, A.; Itobayashi, E.; Tsuji, K.; et al. Attempt to Establish Prognostic Predictive System for Hepatocellular Carcinoma Using Artificial Intelligence for Assistance with Selection of Treatment Modality. Liver Cancer 2023, 12, 565–575. [Google Scholar] [CrossRef]
- Chen, D.; Liu, J.; Zang, L.; Xiao, T.; Zhang, X.; Li, Z.; Zhu, H.; Gao, W.; Yu, X. Integrated Machine Learning and Bioinformatic Analyses Constructed a Novel Stemness-Related Classifier to Predict Prognosis and Immunotherapy Responses for Hepatocellular Carcinoma Patients. Int. J. Biol. Sci. 2022, 18, 360–373. [Google Scholar] [CrossRef]
- Nam, D.; Chapiro, J.; Paradis, V.; Seraphin, T.P.; Kather, J.N. Artificial intelligence in liver diseases: Improving diagnostics, prognostics and response prediction. JHEP Rep. Innov. Hepatol. 2022, 4, 100443. [Google Scholar] [CrossRef]
- Galle, P.R.; Foerster, F.; Kudo, M.; Chan, S.L.; Llovet, J.M.; Qin, S.; Schelman, W.R.; Chintharlapalli, S.; Abada, P.B.; Sherman, M.; et al. Biology and significance of alpha-fetoprotein in hepatocellular carcinoma. Liver Int. 2019, 39, 2214–2229. [Google Scholar] [CrossRef]
- Aubé, C.; Oberti, F.; Lonjon, J.; Pageaux, G.; Seror, O.; N’Kontchou, G.; Rode, A.; Radenne, S.; Cassinotto, C.; Vergniol, J.; et al. EASL and AASLD recommendations for the diagnosis of HCC to the test of daily practice. Liver Int. 2017, 37, 1515–1525. [Google Scholar] [CrossRef] [PubMed]
- Stefano, F.D.; Chacon, E.; Turcios, L.; Marti, F.; Gedaly, R. Novel biomarkers in hepatocellular carcinoma. Dig. Liver Dis. 2018, 50, 1115–1123. [Google Scholar] [CrossRef] [PubMed]
- Trevisan França de Lima, L.; Broszczak, D.; Zhang, X.; Bridle, K.; Crawford, D.; Punyadeera, C. The use of minimally invasive biomarkers for the diagnosis and prognosis of hepatocellular carcinoma. Biochim. Biophys. Acta BBA Rev. Cancer 2020, 1874, 188451. [Google Scholar] [CrossRef] [PubMed]
- Piñero, F.; Dirchwolf, M.; Pessôa, M.G. Biomarkers in Hepatocellular Carcinoma: Diagnosis, Prognosis and Treatment Response Assessment. Cells 2020, 9, 1370. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).