
Performance of Large Language Models ChatGPT and Gemini on Workplace Management Questions in Radiology

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Design and Categories of Questions
2.2. Evaluation and Scoring of Responses
- Overall quality score (OQS): This dimension evaluated the answer’s completeness, accuracy, and relevance.
- ○
- Insufficient (1): The answer is incomplete, incorrect, or fails to address the question adequately.
- ○
- Moderate (2): The answer partially addresses the question but lacks key points or includes inaccuracies.
- ○
- Good (3): The answer is accurate and covers most critical aspects, with only minor omissions.
- ○
- Very good (4): The answer is thorough, accurate, and addresses all key points effectively.
- Understandability score (US): This dimension assessed the response’s clarity, organization, and ease of understanding.
- ○
- Insufficient (1): The answer is confusing, poorly organized, or difficult to comprehend.
- ○
- Moderate (2): The answer is somewhat clear but lacks proper organization or contains language issues that affect readability.
- ○
- Good (3): The answer is clear, well-structured, and easy to understand, with only minor issues.
- ○
- Very good (4): The answer is exceptionally clear, well-organized, and easy to read.
- Implementability score (IS): This dimension measured the practicality and feasibility of the recommendations provided.
- ○
- Insufficient (1): Recommendations are impractical, unrealistic, or too vague to implement.
- ○
- Moderate (2): Some recommendations are practical, but others are vague, unrealistic, or require significant refinement.
- ○
- Good (3): Recommendations are practical and largely feasible, requiring only minor adjustments.
- ○
- Very good (4): Recommendations are highly practical, feasible, and readily implementable.
2.3. Statistical Analysis Methods
3. Results
3.1. Inter-Rater Reliability
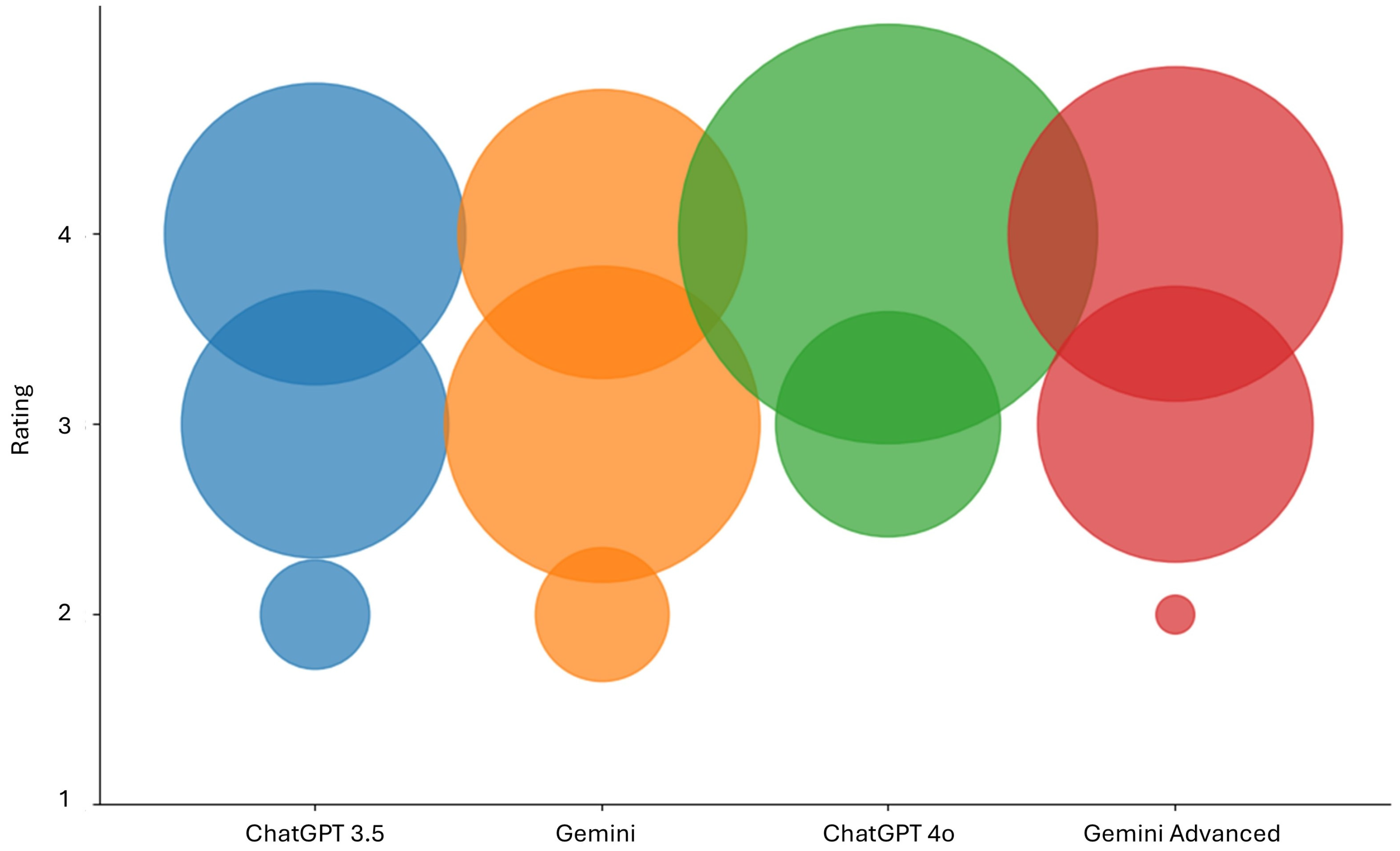
3.2. OQS, US, IS, and MQS
3.3. Significances
3.4. Superiority Analysis
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pavli, A.; Theodoridou, M.; Maltezou, H.C. Post-COVID Syndrome: Incidence, Clinical Spectrum, and Challenges for Primary Healthcare Professionals. Arch. Med. Res. 2021, 52, 575–581. [Google Scholar] [CrossRef] [PubMed]
- Shaheen, M.Y. Applications of Artificial Intelligence (AI) in healthcare: A review. Sci. Prepr. 2021. [Google Scholar] [CrossRef]
- Thomson, N.B.; Rawson, J.V.; Slade, C.P.; Bledsoe, M. Transformation and Transformational Leadership: A Review of the Current and Relevant Literature for Academic Radiologists. Acad. Radiol. 2016, 23, 592–599. [Google Scholar] [CrossRef] [PubMed]
- Sedaghat, S. The Future Role of Radiologists in the Artificial Intelligence-Driven Hospital. Ann. Biomed. Eng. 2024, 52, 2316–2318. [Google Scholar] [CrossRef] [PubMed]
- Sedaghat, S. Success Through Simplicity: What Other Artificial Intelligence Applications in Medicine Should Learn from History and ChatGPT. Ann. Biomed. Eng. 2023, 51, 2657–2658. [Google Scholar] [CrossRef]
- Clusmann, J.; Kolbinger, F.R.; Muti, H.S.; Carrero, Z.I.; Eckardt, J.-N.; Laleh, N.G.; Löffler, C.M.L.; Schwarzkopf, S.-C.; Unger, M.; Veldhuizen, G.P.; et al. The future landscape of large language models in medicine. Commun. Med. 2023, 3, 141. [Google Scholar] [CrossRef]
- Sedaghat, S. Early applications of ChatGPT in medical practice, education and research. Clin. Med. 2023, 23, 278–279. [Google Scholar] [CrossRef]
- Lau, L. Leadership and management in quality radiology. Biomed. Imaging Interv. J. 2007, 3, e21. [Google Scholar] [CrossRef]
- Sedaghat, S. Large Language Model-Based Chatbots Like ChatGPT for Accessing Basic Leadership Education in Radiology. Acad. Radiol. 2024, 31, 4296–4297. [Google Scholar] [CrossRef]
- Buijs, E.; Maggioni, E.; Mazziotta, F.; Lega, F.; Carrafiello, G. Clinical impact of AI in radiology department management: A systematic review. Radiol. Medica 2024, 129, 1656–1666. [Google Scholar] [CrossRef]
- Slanetz, P.J.; Omary, R.A.; Mainiero, M.B.; Deitte, L.A. Educating the Next Generation of Leaders in Radiology. J. Am. Coll. Radiol. 2020, 17, 1046–1048. [Google Scholar] [CrossRef] [PubMed]
- Leutz-Schmidt, P.; Grözinger, M.; Kauczor, H.-U.; Jang, H.; Sedaghat, S. Performance of ChatGPT on basic healthcare leadership and management questions. Health Technol. 2024, 14, 1161–1166. [Google Scholar] [CrossRef]
- Shipton, H.; Armstrong, C.; West, M.; Dawson, J. The impact of leadership and quality climate on hospital performance. Int. J. Qual. Health Care 2008, 20, 439–445. [Google Scholar] [CrossRef] [PubMed]
- Abdi, Z.; Lega, F.; Ebeid, N.; Ravaghi, H. Role of hospital leadership in combating the COVID-19 pandemic. Health Serv. Manag. Res. 2022, 35, 2–6. [Google Scholar] [CrossRef]
- van Wart, M. A comprehensive model of organizational leadership: The leadership action cycle. Int. J. Organ. Theory Behav. 2003, 7, 173–208. [Google Scholar] [CrossRef]
- Daly, J.; Jackson, D.; Mannix, J.; Davidson, P.; Hutchinson, M. The importance of clinical leadership in the hospital setting. J. Healthc. Leadersh. 2014, 6, 75–83. [Google Scholar] [CrossRef]
- Mahoney, M.C. Radiology Leadership in a Time of Crisis: A Chair’s Perspective. Acad. Radiol. 2020, 27, 1214–1216. [Google Scholar] [CrossRef]
- Clements, W. Understanding Leadership and its Vital Role in the Growth of Interventional Radiology. Cardiovasc. Interv. Radiol. 2023, 46, 541–542. [Google Scholar] [CrossRef]
- Chung, E.M.; Zhang, S.C.; Nguyen, A.T.; Atkins, K.M.; Sandler, H.M.; Kamrava, M. Feasibility and acceptability of ChatGPT generated radiology report summaries for cancer patients. Digit. Health 2023, 9, 20552076231221620. [Google Scholar] [CrossRef]
- Jiang, H.; Xia, S.; Yang, Y.; Xu, J.; Hua, Q.; Mei, Z.; Hou, Y.; Wei, M.; Lai, L.; Li, N.; et al. Transforming free-text radiology reports into structured reports using ChatGPT: A study on thyroid ultrasonography. Eur. J. Radiol. 2024, 175, 111458. [Google Scholar] [CrossRef]
- Schmidt, S.; Zimmerer, A.; Cucos, T.; Feucht, M.; Navas, L. Simplifying radiologic reports with natural language processing: A novel approach using ChatGPT in enhancing patient understanding of MRI results. Arch. Orthop. Trauma Surg. 2024, 144, 611–618. [Google Scholar] [CrossRef] [PubMed]
- Gordon, E.B.; Towbin, A.J.; Wingrove, P.; Shafique, U.; Haas, B.; Kitts, A.B.; Feldman, J.; Furlan, A. Enhancing Patient Communication with Chat-GPT in Radiology: Evaluating the Efficacy and Readability of Answers to Common Imaging-Related Questions. J. Am. Coll. Radiol. 2024, 21, 353–359. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Hu, Z.; Liu, W.; Gao, A.; Wen, S.; Liu, S.; Lin, Z. Exploring the potential of ChatGPT as an adjunct for generating diagnosis based on chief complaint and cone beam CT radiologic findings. BMC Med. Inform. Decis. Mak. 2024, 24, 55. [Google Scholar] [CrossRef] [PubMed]
- Sedaghat, S. Future potential challenges of using large language models like ChatGPT in daily medical practice. J. Am. Coll. Radiol. 2023, 21, 344–345. [Google Scholar] [CrossRef]
- Temperley, H.C.; O’Sullivan, N.J.; Mac Curtain, B.M.; Corr, A.; Meaney, J.F.; Kelly, M.E.; Brennan, I. Current applications and future potential of ChatGPT in radiology: A systematic review. J. Med. Imaging Radiat. Oncol. 2024, 68, 257–264. [Google Scholar] [CrossRef]
- Sedaghat, S. Plagiarism and Wrong Content as Potential Challenges of Using Chatbots Like ChatGPT in Medical Research. J. Acad. Ethics 2024, 1–4. [Google Scholar] [CrossRef]
- Ullah, E.; Parwani, A.; Baig, M.M.; Singh, R. Challenges and barriers of using large language models (LLM) such as ChatGPT for diagnostic medicine with a focus on digital pathology—A recent scoping review. Diagn. Pathol. 2024, 19, 43. [Google Scholar] [CrossRef]
- Shen, Y.; Heacock, L.; Elias, J.; Hentel, K.D.; Reig, B.; Shih, G.; Moy, L. ChatGPT and Other Large Language Models Are Double-edged Swords. Radiology 2023, 307, e230163. [Google Scholar] [CrossRef]
- Li, H.; Moon, J.T.; Iyer, D.; Balthazar, P.; Krupinski, E.A.; Bercu, Z.L.; Newsome, J.M.; Banerjee, I.; Gichoya, J.W.; Trivedi, H.M. Decoding radiology reports: Potential application of OpenAI ChatGPT to enhance patient understanding of diagnostic reports. Clin. Imaging 2023, 101, 137–141. [Google Scholar] [CrossRef]
- Shahsavar, Y.; Choudhury, A. User Intentions to Use ChatGPT for Self-Diagnosis and Health-Related Purposes: Cross-sectional Survey Study. JMIR Hum. Factors 2023, 10, e47564. [Google Scholar] [CrossRef]
- D’antonoli, T.A.; Stanzione, A.; Bluethgen, C.; Vernuccio, F.; Ugga, L.; Klontzas, M.E.; Cuocolo, R.; Cannella, R.; Koçak, B. Large language models in radiology: Fundamentals, applications, ethical considerations, risks, and future directions. Diagn. Interv. Radiol. 2024, 30, 80–90. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Question Group | Mean ± SD | |||
|---|---|---|---|---|
| ChatGPT-3.5 | Gemini | ChatGPT-4.0 | Gemini Advanced | |
| Overall Quality Score (OQS) | ||||
| 1 | 2.88 ± 0.76 | 2.88 ± 0.77 | 3.77 ± 0.35 | 3.11 ± 0.46 |
| 2 | 3.07 ± 0.59 | 3.14 ± 0.52 | 3.79 ± 0.41 | 3.57 ± 0.5 |
| 3 | 3.17 ± 0.45 | 3.43 ± 0.5 | 3.79 ± 0.41 | 3.57 ± 0.5 |
| 4 | 3.56 ± 0.5 | 2.88 ± 0.78 | 3.88 ± 0.33 | 3.63 ± 0.48 |
| Understandability Score (US) | ||||
| 1 | 3.22 ± 0.48 | 3.33 ± 0.5 | 3.61 ± 0.48 | 3.44 ± 0.5 |
| 2 | 3.64 ± 0.48 | 3.64 ± 0.48 | 3.86 ± 0.35 | 3.79 ± 0.41 |
| 3 | 3.64 ± 0.48 | 3.57 ± 0.5 | 3.79 ± 0.41 | 3.57 ± 0.5 |
| 4 | 3.56 ± 0.5 | 3.5 ± 0.5 | 3.88 ± 0.33 | 3.75 ± 0.43 |
| Implementability Score (IS) | ||||
| 1 | 2.94 ± 0.7 | 3 ± 0.76 | 3.56 ± 0.5 | 3.16 ± 0.59 |
| 2 | 3.14 ± 0.74 | 3.43 ± 0.5 | 3.71 ± 0.45 | 3.57 ± 0.5 |
| 3 | 3.57 ± 0.5 | 3.5 ± 0.5 | 3.71 ± 0.45 | 3.57 ± 0.5 |
| 4 | 3.56 ± 0.5 | 3.38 ± 0.7 | 3.75 ± 0.43 | 3.63 ± 0.48 |
| Mean Quality Score (MQS) | ||||
| 1 | 3.02 ± 0.68 | 3.07 ± 0.66 | 3.65 ± 0.48 | 3.24 ± 0.54 |
| 2 | 3.29 ± 0.67 | 3.41 ± 0.54 | 3.79 ± 0.41 | 3.64 ± 0.48 |
| 3 | 3.64 ± 0.48 | 3.5 ± 0.5 | 3.76 ± 0.43 | 3.57 ± 0.5 |
| 4 | 3.56 ± 0.5 | 3.25 ± 0.72 | 3.83 ± 0.37 | 3.67 ± 0.47 |
| Analyzed Groups | Chatbot 1 | Chatbot 2 | p Values |
|---|---|---|---|
| Overall | ChatGPT4.0 | ChatGPT3.5 | <0.001 |
| ChatGPT4.0 | Gemini | <0.001 | |
| ChatGPT4.0 | Gemini Advanced | 0.002 | |
| Gemini Advanced | ChatGPT3.5 | 0.056 | |
| Gemini Advanced | Gemini | 0.003 | |
| Per Scoring System | |||
| OQS | ChatGPT4.0 | ChatGPT3.5 | <0.001 |
| ChatGPT4.0 | Gemini | <0.001 | |
| ChatGPT4.0 | Gemini Advanced | 0.001 | |
| Gemini Advanced | Gemini | 0.005 | |
| US | ChatGPT4.0 | ChatGPT3.5 | 0.012 |
| ChatGPT4.0 | Gemini | 0.009 | |
| IS | ChatGPT4.0 | ChatGPT3.5 | 0.004 |
| ChatGPT4.0 | Gemini | 0.003 | |
| Per Question Group (1–4) | |||
| MQS | |||
| Question group 1 | ChatGPT4.0 | ChatGPT3.5 | <0.001 |
| ChatGPT4.0 | Gemini | <0.001 | |
| ChatGPT4.0 | Gemini Advanced | <0.001 | |
| Question group 2 | ChatGPT4.0 | ChatGPT3.5 | 0.001 |
| ChatGPT4.0 | Gemini | 0.004 | |
| Gemini Adv | ChatGPT3.5 | 0.027 | |
| Question group 3 | ChatGPT4.0 | Gemini | 0.039 |
| Question group 4 | ChatGPT4.0 | ChatGPT3.5 | 0.023 |
| ChatGPT4.0 | Gemini | <0.001 | |
| Gemini Adv | Gemini | 0.009 | |
| ChatGPT3.5 | Gemini | 0.066 | |
| OQS | |||
| Question group 1 | ChatGPT4.0 | ChatGPT3.5 | 0.001 |
| ChatGPT4.0 | Gemini | 0.001 | |
| ChatGPT4.0 | Gemini Adv | 0.002 | |
| Question group 2 | ChatGPT4.0 | ChatGPT3.5 | 0.007 |
| ChatGPT4.0 | Gemini | 0.009 | |
| Gemini Adv | ChatGPT3.5 | 0.063 | |
| Question group 4 | ChatGPT3.5 | Gemini | 0.023 |
| ChatGPT4.0 | Gemini | 0.001 | |
| Gemini | Gemini Advanced | 0.014 | |
| IS | |||
| Question group 1 | ChatGPT4.0 | ChatGPT3.5 | 0.019 |
| ChatGPT4.0 | Gemini | 0.027 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leutz-Schmidt, P.; Palm, V.; Mathy, R.M.; Grözinger, M.; Kauczor, H.-U.; Jang, H.; Sedaghat, S. Performance of Large Language Models ChatGPT and Gemini on Workplace Management Questions in Radiology. Diagnostics 2025, 15, 497. https://doi.org/10.3390/diagnostics15040497
Leutz-Schmidt P, Palm V, Mathy RM, Grözinger M, Kauczor H-U, Jang H, Sedaghat S. Performance of Large Language Models ChatGPT and Gemini on Workplace Management Questions in Radiology. Diagnostics. 2025; 15(4):497. https://doi.org/10.3390/diagnostics15040497
Chicago/Turabian StyleLeutz-Schmidt, Patricia, Viktoria Palm, René Michael Mathy, Martin Grözinger, Hans-Ulrich Kauczor, Hyungseok Jang, and Sam Sedaghat. 2025. "Performance of Large Language Models ChatGPT and Gemini on Workplace Management Questions in Radiology" Diagnostics 15, no. 4: 497. https://doi.org/10.3390/diagnostics15040497
APA StyleLeutz-Schmidt, P., Palm, V., Mathy, R. M., Grözinger, M., Kauczor, H.-U., Jang, H., & Sedaghat, S. (2025). Performance of Large Language Models ChatGPT and Gemini on Workplace Management Questions in Radiology. Diagnostics, 15(4), 497. https://doi.org/10.3390/diagnostics15040497