
A Cost-Effective System for Indoor Three-Dimensional Occupant Positioning and Trajectory Reconstruction
Abstract
:1. Introduction
- (1)
- We propose an inverse proportional model to estimate the distance between human heads and the camera in the direction of the camera optical axis according to pixel-heights of human heads. With the help of this model, the 3D position coordinates of human heads can be calculated based on a single RGB camera. Compared with previous 3D positioning methods, our proposed method is significantly more cost-effective.
- (2)
- We propose a 3D occupant trajectory reconstruction method that associates the 3D position coordinates of human heads with human tracking results according to the degree of overlap between binary masks of human heads and human bodies. This proposed method takes advantage of both the low cost of our 3D positioning method and the stability of human body tracking.
- (3)
- We perform experiments on both 3D occupant positioning and 3D occupant trajectory reconstruction datasets. Experimental results show that our proposed system successfully calculates accurate 3D position coordinates and 3D trajectories of indoor occupants with only one RGB camera, demonstrating the effectiveness of the proposed system.
2. Methods
2.1. Overview
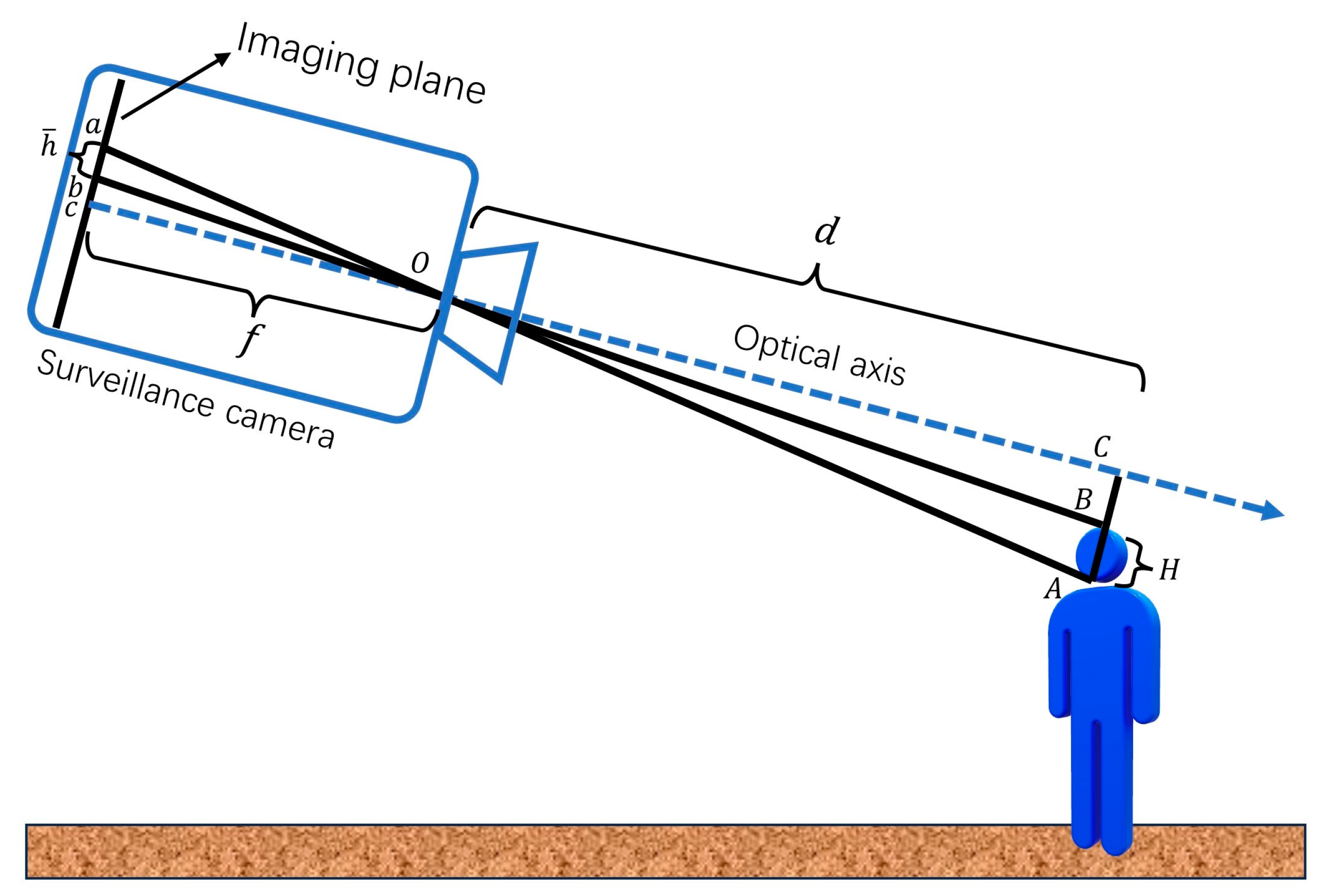
2.2. Three-Dimensional Occupant Positioning
- (1)
- Calculate the distance between the head and the camera in the direction of camera optical axis
- (2)
- Calculate the 3D coordinates of human heads in the camera coordinate system
- (3)
- Calculate the 3D coordinates of human heads in the world coordinate system
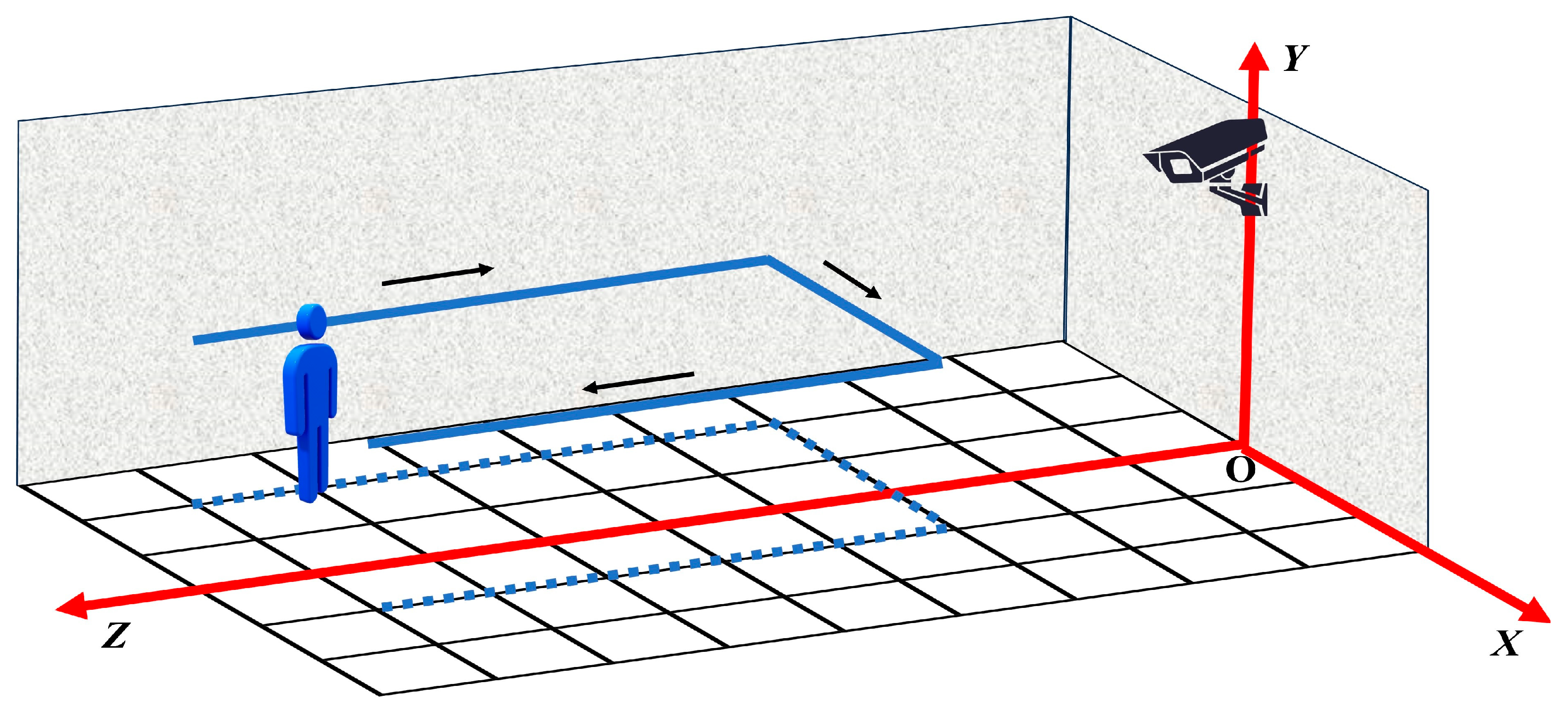
2.3. Three-Dimensional Occupant Trajectory Generation
3. Experiments
3.1. Datasets
3.1.1. Dataset for 3D Occupant Positioning
3.1.2. Dataset for 3D Occupant Trajectory Reconstruction
3.2. Three-Dimensional occupant Positioning
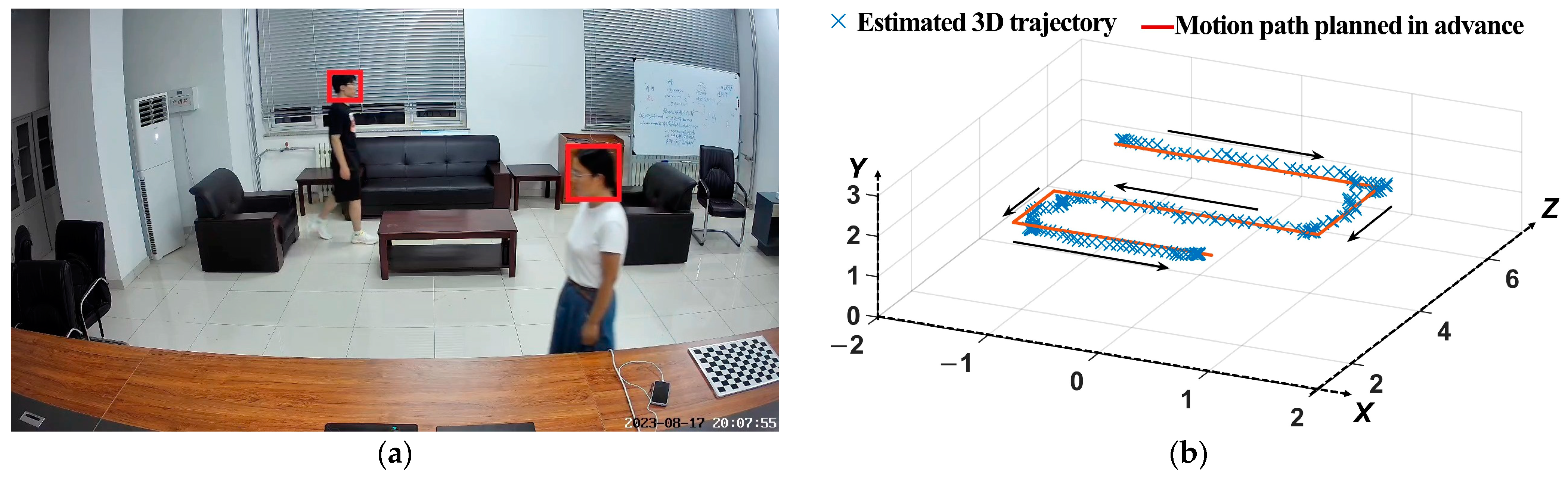
3.3. Three-Dimensional Occupant Trajectory Reconstruction
3.4. Running Time Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Long, C.M.; Suh, H.H.; Catalano, P.J.; Koutrakis, P. Using time-and size-resolved particulate data to quantify indoor penetration and deposition behavior. Environ. Sci. Technol. 2001, 35, 2089–2099. [Google Scholar] [CrossRef] [PubMed]
- D’Oca, S.; Hong, T.; Langevin, J. The human dimensions of energy use in buildings: A review. Renew. Sust. Energy Rev. 2018, 81, 731–742. [Google Scholar] [CrossRef]
- Kang, X.; Yan, D.; An, J.; Jin, Y.; Sun, H. Typical weekly occupancy profiles in non-residential buildings based on mobile positioning data. Energy Build. 2021, 250, 111264. [Google Scholar] [CrossRef]
- Zhang, R.; Kong, M.; Dong, B.; O’Neill, Z.; Cheng, H.; Hu, F.; Zhang, J. Development of a testing and evaluation protocol for occupancy sensing technologies in building HVAC controls: A case study of representative people counting sensors. Build. Environ. 2022, 208, 108610. [Google Scholar] [CrossRef]
- Sayed, A.N.; Himeur, Y.; Bensaali, F. Deep and transfer learning for building occupancy detection: A review and comparative analysis. Eng. Appl. Artif. Intel. 2022, 115, 105254. [Google Scholar] [CrossRef]
- Pang, Z.; Chen, Y.; Zhang, J.; O’Neill, Z.; Cheng, H.; Dong, B. Nationwide HVAC energy-saving potential quantification for office buildings with occupant-centric controls in various climates. Appl. Energy 2020, 279, 115727. [Google Scholar] [CrossRef]
- Zou, H.; Zhou, Y.; Jiang, H.; Chien, S.-C.; Xie, L.; Spanos, C.J. WinLight: A WiFi-based occupancy-driven lighting control system for smart building. Energy Build. 2018, 158, 924–938. [Google Scholar] [CrossRef]
- Tekler, Z.D.; Low, R.; Yuen, C.; Blessing, L. Plug-Mate: An IoT-based occupancy-driven plug load management system in smart buildings. Build. Environ. 2022, 223, 109472. [Google Scholar] [CrossRef]
- Yang, B.; Liu, Y.; Liu, P.; Wang, F.; Cheng, X.; Lv, Z. A novel occupant-centric stratum ventilation system using computer vision: Occupant detection, thermal comfort, air quality, and energy savings. Build. Environ. 2023, 237, 110332. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, T.; Zhou, X.; Wang, J.; Zhang, X.; Qin, C.; Luo, M. Room zonal location and activity intensity recognition model for residential occupant using passive-infrared sensors and machine learning. Build. Simul. 2022, 15, 1133–1144. [Google Scholar] [CrossRef]
- Franco, A.; Leccese, F. Measurement of CO2 concentration for occupancy estimation in educational buildings with energy efficiency purposes. J. Build. Eng. 2020, 32, 101714. [Google Scholar] [CrossRef]
- Kampezidou, S.I.; Ray, A.T.; Duncan, S.; Balchanos, M.G.; Mavris, D.N. Real-time occupancy detection with physics-informed pattern-recognition machines based on limited CO2 and temperature sensors. Energy Build. 2021, 242, 110863. [Google Scholar] [CrossRef]
- Khan, A.; Nicholson, J.; Mellor, S.; Jackson, D.; Ladha, K.; Ladha, C.; Hand, J.; Clarke, J.; Olivier, P.; Plötz, T. Occupancy monitoring using environmental & context sensors and a hierarchical analysis framework. In Proceedings of the 1st ACM Conference on Embedded Systems for Energy-Efficient Buildings, Memphis, TN, USA, 3–6 November 2014. [Google Scholar] [CrossRef]
- Uziel, S.; Elste, T.; Kattanek, W.; Hollosi, D.; Gerlach, S.; Goetze, S. Networked embedded acoustic processing system for smart building applications. In Proceedings of the 2013 Conference on Design and Architectures for Signal and Image Processing, Cagliari, Italy, 8–10 October 2013. [Google Scholar]
- Islam, S.M.M.; Droitcour, A.; Yavari, E.; Lubecke, V.M.; Boric-Lubecke, O. Building occupancy estimation using microwave Doppler radar and wavelet transform. Build. Environ. 2023, 236, 110233. [Google Scholar] [CrossRef]
- Tang, C.; Li, W.; Vishwakarma, S.; Chetty, K.; Julier, S.; Woodbridge, K. Occupancy detection and people counting using wifi passive radar. In Proceedings of the 2020 IEEE Radar Conference (RadarConf20), Florence, Italy, 21–25 September 2020. [Google Scholar] [CrossRef]
- Zaidi, A.; Ahuja, R.; Shahabi, C. Differentially Private Occupancy Monitoring from WiFi Access Points. In Proceedings of the 2022 23rd IEEE International Conference on Mobile Data Management, Paphos, Cyprus, 6–9 June 2022. [Google Scholar] [CrossRef]
- Abolhassani, S.S.; Zandifar, A.; Ghourchian, N.; Amayri, M.; Bouguila, N.; Eicker, U. Improving residential building energy simulations through occupancy data derived from commercial off-the-shelf Wi-Fi sensing technology. Energy Build. 2022, 272, 112354. [Google Scholar] [CrossRef]
- Tekler, Z.D.; Low, R.; Gunay, B.; Andersen, R.K.; Blessing, L. A scalable Bluetooth Low Energy approach to identify occupancy patterns and profiles in office spaces. Build. Environ. 2020, 171, 106681. [Google Scholar] [CrossRef]
- Apolónia, F.; Ferreira, P.M.; Cecílio, J. Buildings Occupancy Estimation: Preliminary Results Using Bluetooth Signals and Artificial Neural Networks. In Communications in Computer and Information Science; Springer: Cham, Switzerland, 2022; Volume 1525, pp. 567–579. [Google Scholar] [CrossRef]
- Brown, R.; Ghavami, N.; Adjrad, M.; Ghavami, M.; Dudley, S. Occupancy based household energy disaggregation using ultra wideband radar and electrical signature profiles. Energy Build. 2017, 141, 134–141. [Google Scholar] [CrossRef]
- Xu, Y.; Shmaliy, Y.S.; Li, Y.; Chen, X. UWB-based indoor human localization with time-delayed data using EFIR filtering. IEEE Access 2017, 5, 16676–16683. [Google Scholar] [CrossRef]
- Sun, K.; Liu, P.; Xing, T.; Zhao, Q.; Wang, X. A fusion framework for vision-based indoor occupancy estimation. Build. Environ. 2022, 225, 109631. [Google Scholar] [CrossRef]
- Tekler, Z.D.; Chong, A. Occupancy prediction using deep learning approaches across multiple space types: A minimum sensing strategy. Build. Environ. 2022, 226, 109689. [Google Scholar] [CrossRef]
- Tan, S.Y.; Jacoby, M.; Saha, H.; Florita, A.; Henze, G.; Sarkar, S. Multimodal sensor fusion framework for residential building occupancy detection. Energy Build. 2022, 258, 111828. [Google Scholar] [CrossRef]
- Qaisar, I.; Sun, K.; Zhao, Q.; Xing, T.; Yan, H. Multi-sensor Based Occupancy Prediction in a Multi-zone Office Building with Transformer. Buildings 2023, 13, 2002. [Google Scholar] [CrossRef]
- Wang, H.; Wang, G.; Li, X. An RGB-D camera-based indoor occupancy positioning system for complex and densely populated scenarios. Indoor Built Environ. 2023, 32, 1198–1212. [Google Scholar] [CrossRef]
- Sun, K.; Zhao, Q.; Zou, J. A review of building occupancy measurement systems. Energy Build. 2020, 216, 109965. [Google Scholar] [CrossRef]
- Labeodan, T.; Zeiler, W.; Boxem, G.; Zhao, Y. Occupancy measurement in commercial office buildings for demand-driven control applications–A survey and detection system evaluation. Energy Build. 2015, 93, 303–314. [Google Scholar] [CrossRef]
- Dai, Y.; Wen, C.; Wu, H.; Guo, Y.; Chen, L.; Wang, C. Indoor 3D human trajectory reconstruction using surveillance camera videos and point clouds. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 2482–2495. [Google Scholar] [CrossRef]
- Sun, K.; Ma, X.; Liu, P.; Zhao, Q. MPSN: Motion-aware Pseudo-Siamese Network for indoor video head detection in buildings. Build. Environ. 2022, 222, 109354. [Google Scholar] [CrossRef]
- Hu, S.; Wang, P.; Hoare, C.; O’Donnell, J. Building Occupancy Detection and Localization Using CCTV Camera and Deep Learning. IEEE Internet Things 2023, 10, 597–608. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, Y.; Zhou, Y.; Sun, S.; Zhang, H.; Wang, Y. Automatic detection of indoor occupancy based on improved YOLOv5 model. Neural Comput. Appl. 2023, 35, 2575–2599. [Google Scholar] [CrossRef]
- Wang, H.; Wang, G.; Li, X. Image-based occupancy positioning system using pose-estimation model for demand-oriented ventilation. J. Build. Eng. 2021, 39, 102220. [Google Scholar] [CrossRef]
- Zhou, X.; Sun, K.; Wang, J.; Zhao, J.; Feng, C.; Yang, Y.; Zhou, W. Computer vision enabled building digital twin using building information model. IEEE Trans. Ind. Inform. 2023, 19, 2684–2692. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]
- Glenn, J. Yolo by Ultralytics (Version 8.0.0). Available online: https://github.com/ultralytics/ultralytics (accessed on 8 November 2023).
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Aharon, N.; Orfaig, R.; Bobrovsky, B.-Z. BoT-SORT: Robust associations multi-pedestrian tracking. arXiv 2022, arXiv:2206.14651. [Google Scholar] [CrossRef]
- Lian, D.; Chen, X.; Li, J.; Luo, W.; Gao, S. Locating and counting heads in crowds with a depth prior. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 9056–9072. [Google Scholar] [CrossRef] [PubMed]
- Li, T.; Zhao, W.; Liu, R.; Han, J.-Y.; Jia, P.; Cheng, C. Visualized direct shear test of the interface between gravelly sand and concrete pipe. Can. Geotech. J. 2023. [Google Scholar] [CrossRef]
- Tawil, H.; Tan, C.G.; Sulong, N.H.R.; Nazri, F.M.; Sherif, M.M.; El-Shafie, A. Mechanical and thermal properties of composite precast concrete sandwich panels: A Review. Buildings 2022, 12, 1429. [Google Scholar] [CrossRef]
- Han, J.; Wang, J.; Jia, D.; Yan, F.; Zhao, Y.; Bai, X.; Yan, N.; Yang, G.; Liu, D. Construction technologies and mechanical effects of the pipe-jacking crossing anchor-cable group in soft stratum. Fron. Earth Sci. 2023, 10, 1019801. [Google Scholar] [CrossRef]
- Sun, H.; Liu, Y.; Guo, X.; Zeng, K.; Mondal, A.K.; Li, J.; Yao, Y.; Chen, L. Strong, robust cellulose composite film for efficient light management in energy efficient building. Chem. Eng. J. 2021, 425, 131469. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Sets | Number of Images | Image Size (Pixels) | Scene |
|---|---|---|---|
| Image Set A-1 | 21 | 3840 × 2160 | Meeting room |
| Image Set A-2 | 21 | 3840 × 2160 | |
| Image Set A-3 | 11 | 3840 × 2160 | |
| Image Set B-1 | 9 | 3840 × 2160 | Reception room |
| Image Set B-2 | 18 | 3840 × 2160 | |
| Image Set B-3 | 10 | 3840 × 2160 | |
| Image Set C-1 | 20 | 3840 × 2160 | Elevator hall |
| Image Set C-2 | 45 | 3840 × 2160 | |
| Image Set C-3 | 23 | 3840 × 2160 | |
| Image Set D-1 | 9 | 3840 × 2160 | Classroom |
| Image Set D-2 | 13 | 3840 × 2160 | |
| Image Set D-3 | 10 | 3840 × 2160 | |
| Image Set E-1 | 26 | 3840 × 2160 | Hallway |
| Image Set E-2 | 26 | 3840 × 2160 | |
| Image Set E-3 | 23 | 3840 × 2160 |
| Videos | Number of Frames | Image Size (Pixels) | Scene |
|---|---|---|---|
| Video A | 243 | 1280 × 720 | Meeting room |
| Video B | 253 | 3840 × 2160 | Reception room |
| Video C | 432 | 3840 × 2160 | Elevator hall |
| Video D | 528 | 3840 × 2160 | Classroom |
| Video E | 487 | 3840 × 2160 | Hallway |
| Image Sets | X Error (cm) | Y Error (cm) | Z Error (cm) | Spatial Error (cm) |
|---|---|---|---|---|
| Image Set A-1 | 3.28 | 1.89 | 11.54 | 12.75 |
| Image Set A-2 | 3.30 | 2.87 | 14.00 | 15.38 |
| Image Set A-3 | 4.40 | 2.55 | 15.37 | 16.91 |
| Image Set B-1 | 3.16 | 5.59 | 6.73 | 10.23 |
| Image Set B-2 | 3.99 | 4.66 | 14.08 | 16.04 |
| Image Set B-3 | 3.82 | 5.61 | 19.77 | 22.31 |
| Image Set C-1 | 6.94 | 2.72 | 16.77 | 18.65 |
| Image Set C-2 | 6.53 | 1.76 | 11.46 | 14.51 |
| Image Set C-3 | 4.85 | 2.52 | 15.61 | 17.43 |
| Image Set D-1 | 5.87 | 0.95 | 16.10 | 17.60 |
| Image Set D-2 | 5.88 | 1.18 | 16.13 | 18.13 |
| Image Set D-3 | 5.10 | 0.82 | 18.50 | 19.49 |
| Image Set E-1 | 4.47 | 3.57 | 11.46 | 13.98 |
| Image Set E-2 | 5.99 | 2.97 | 15.82 | 17.85 |
| Image Set E-3 | 6.00 | 3.30 | 11.58 | 14.71 |
| Mean | 4.91 | 2.86 | 14.33 | 16.40 |
| Method | Year | Dependent Devices or Models | Mean Spatial Error (cm) |
|---|---|---|---|
| Depth Estimation [41] + 3D Reconstruction | 2022 | 1 surveillance camera | 103.00 |
| Dai’s Baseline [30] | 2022 | 1 surveillance camera | 54.00 |
| Dai’s Baseline + BKF [30] | 2022 | 1 surveillance camera | 42.00 |
| Dai’s Baseline + BKF + GC [30] | 2022 | 1 surveillance camera + 3D point cloud map | 13.67 |
| EPI+TOF [27] | 2023 | 4 RGBD cameras | 10.05 |
| Zhou et al. [35] | 2023 | 1 surveillance camera + BIM | 16.60 |
| Our 3D Occupant Positioning Method | 2023 | 1 surveillance camera | 16.40 |
| Methods | Year | Dependent Device or Model | Running TIME (ms/frame) |
|---|---|---|---|
| Indoor 3D human trajectory reconstruction [30] | 2022 | Surveillance cameras +3D point cloud map | 140 |
| Our 3D occupant trajectory reconstruction method | 2023 | 1 surveillance camera | 68 |
| Methods | 3D Occupant Positioning | 3D Occupant Trajectory Reconstruction | |
|---|---|---|---|
| Modules | Distortion correction | ✓ | ✓ |
| Instance segmentation | ✓ | ✓ | |
| 3D coordinates calculation | ✓ | ✓ | |
| Tracking | ✗ | ✓ | |
| 3D trajectory generation | ✗ | ✓ | |
| Running Time (ms/Frame) | 33 | 70 | |
| Modules | Running Time (ms/frame) |
|---|---|
| Distortion correction | 15 |
| Instance segmentation | 17 |
| 3D coordinates calculation | 1 |
| Tracking | 33 |
| 3D trajectory generation | 4 |
| Total | 70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, X.; Li, S.; Zhao, Z.; Li, H. A Cost-Effective System for Indoor Three-Dimensional Occupant Positioning and Trajectory Reconstruction. Buildings 2023, 13, 2832. https://doi.org/10.3390/buildings13112832
Zhao X, Li S, Zhao Z, Li H. A Cost-Effective System for Indoor Three-Dimensional Occupant Positioning and Trajectory Reconstruction. Buildings. 2023; 13(11):2832. https://doi.org/10.3390/buildings13112832
Chicago/Turabian StyleZhao, Xiaomei, Shuo Li, Zhan Zhao, and Honggang Li. 2023. "A Cost-Effective System for Indoor Three-Dimensional Occupant Positioning and Trajectory Reconstruction" Buildings 13, no. 11: 2832. https://doi.org/10.3390/buildings13112832
APA StyleZhao, X., Li, S., Zhao, Z., & Li, H. (2023). A Cost-Effective System for Indoor Three-Dimensional Occupant Positioning and Trajectory Reconstruction. Buildings, 13(11), 2832. https://doi.org/10.3390/buildings13112832