AI-based model is the most widely used technique for solving several engineering problems, such as classification, prediction, pattern recognition, and regression problems. With the aid of a predetermined architecture, an AI-based model was used to develop predictions based on the input data and learning type. This study compared the efficacies of the two classical models (MLR and SVM) and the hybrid IEPANN model for predicting the final prestressed strand slips of precast prestressed HCU specimens under flexural loading conditions.
6.1. Optimal Input Parameters Selection
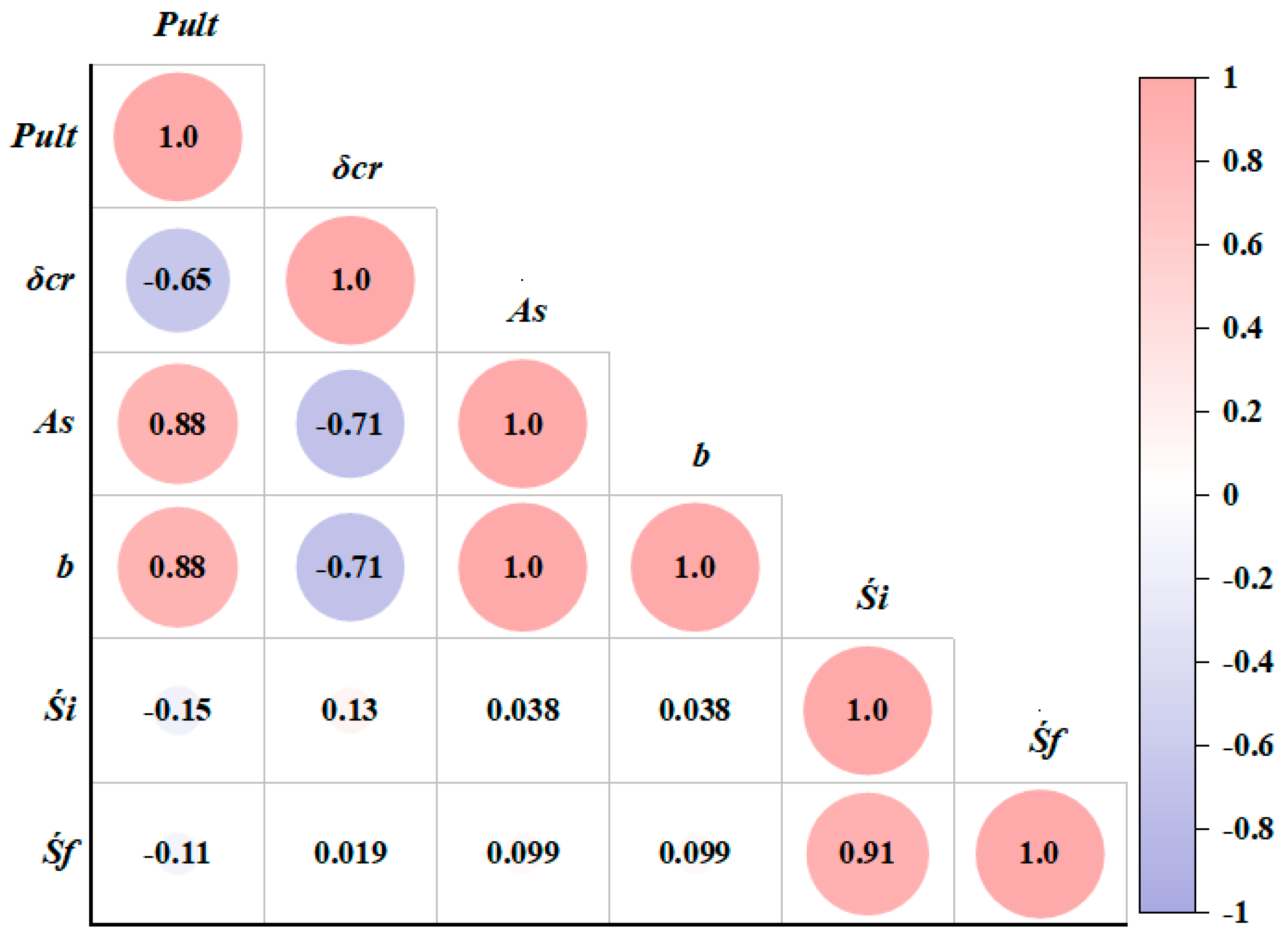
The choice of the input parameters in developing any model is critical for achieving accurate prediction skills. Therefore, including unfitting parameters in the modelling and resulting to the reduced performance accuracies will cause the high computational tasks [
36,
53]. Nevertheless, insufficient input parameters can lead to the reduced estimation accuracy. Thus, Pearson correlation was utilized in our work to decide on the most important input parameters for estimating the final strand slips of the HCU slabs subjected to flexural loading.
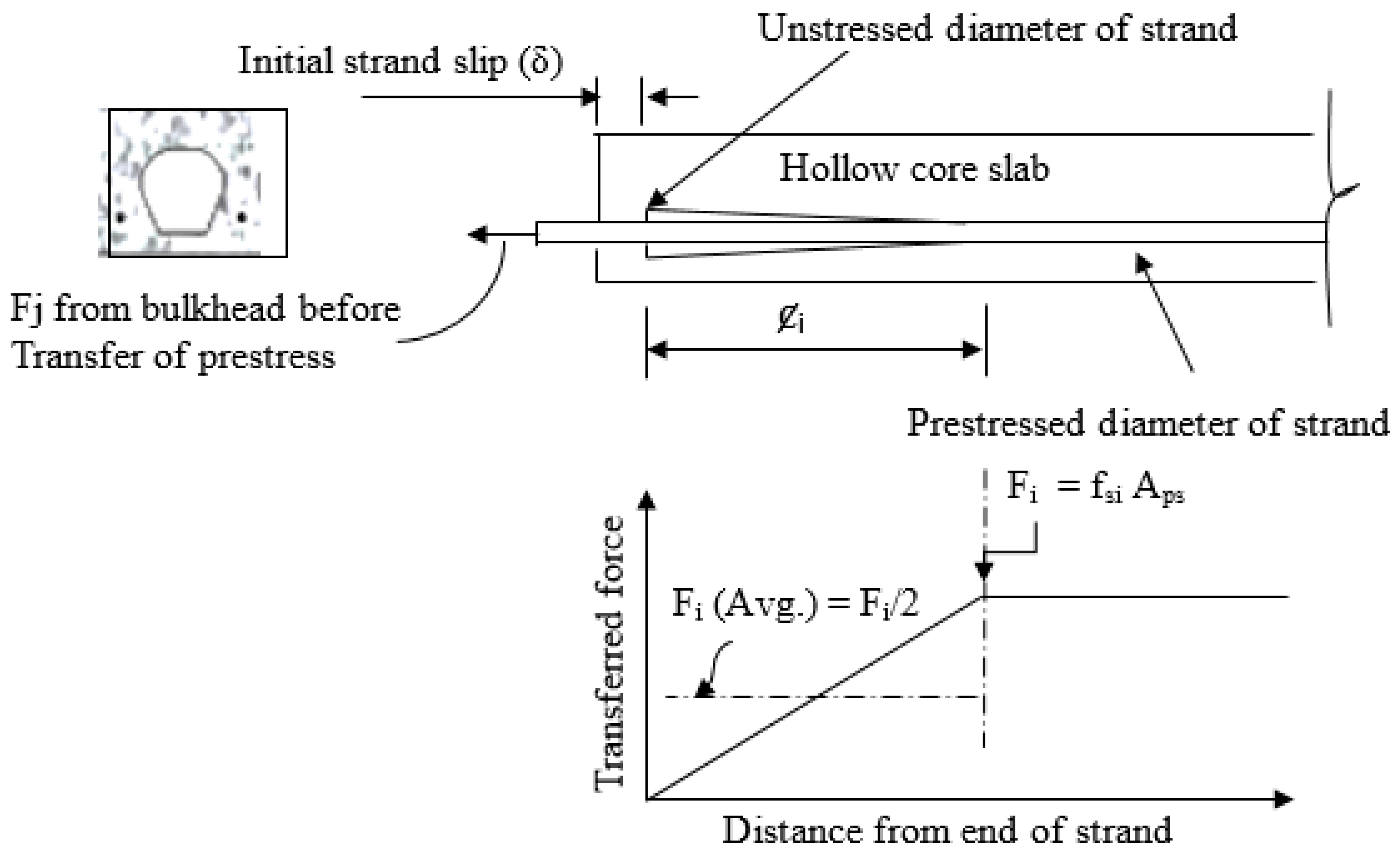
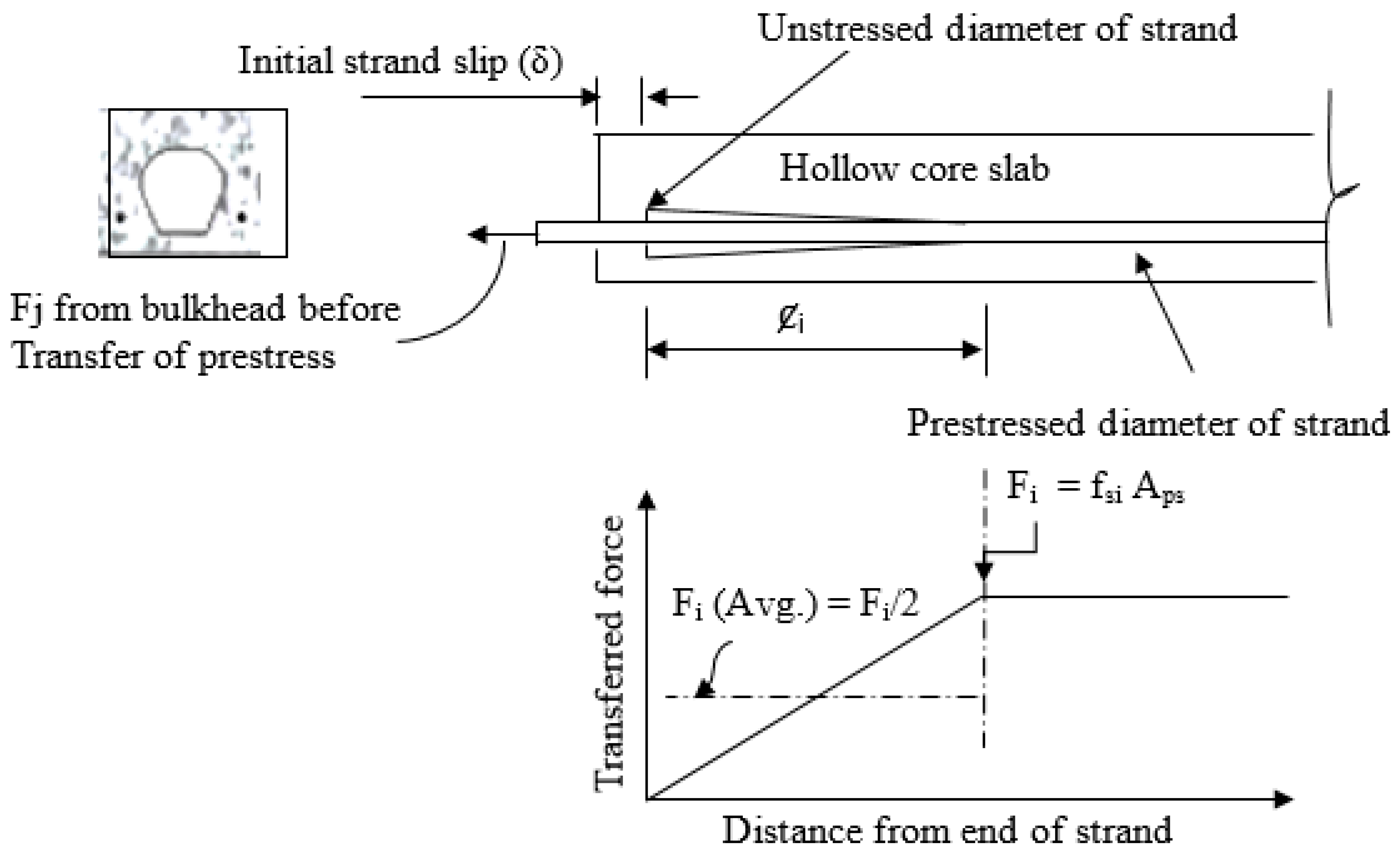
Figure 9 shows the results of sensitivity analysis involving the potential input and output parameters. The analysis showed that the initial strand slip is the most sensitive parameter for predicting the final strand slip (
Śf). All others input parameters demonstrate lower correlation coefficient values with the output parameters.
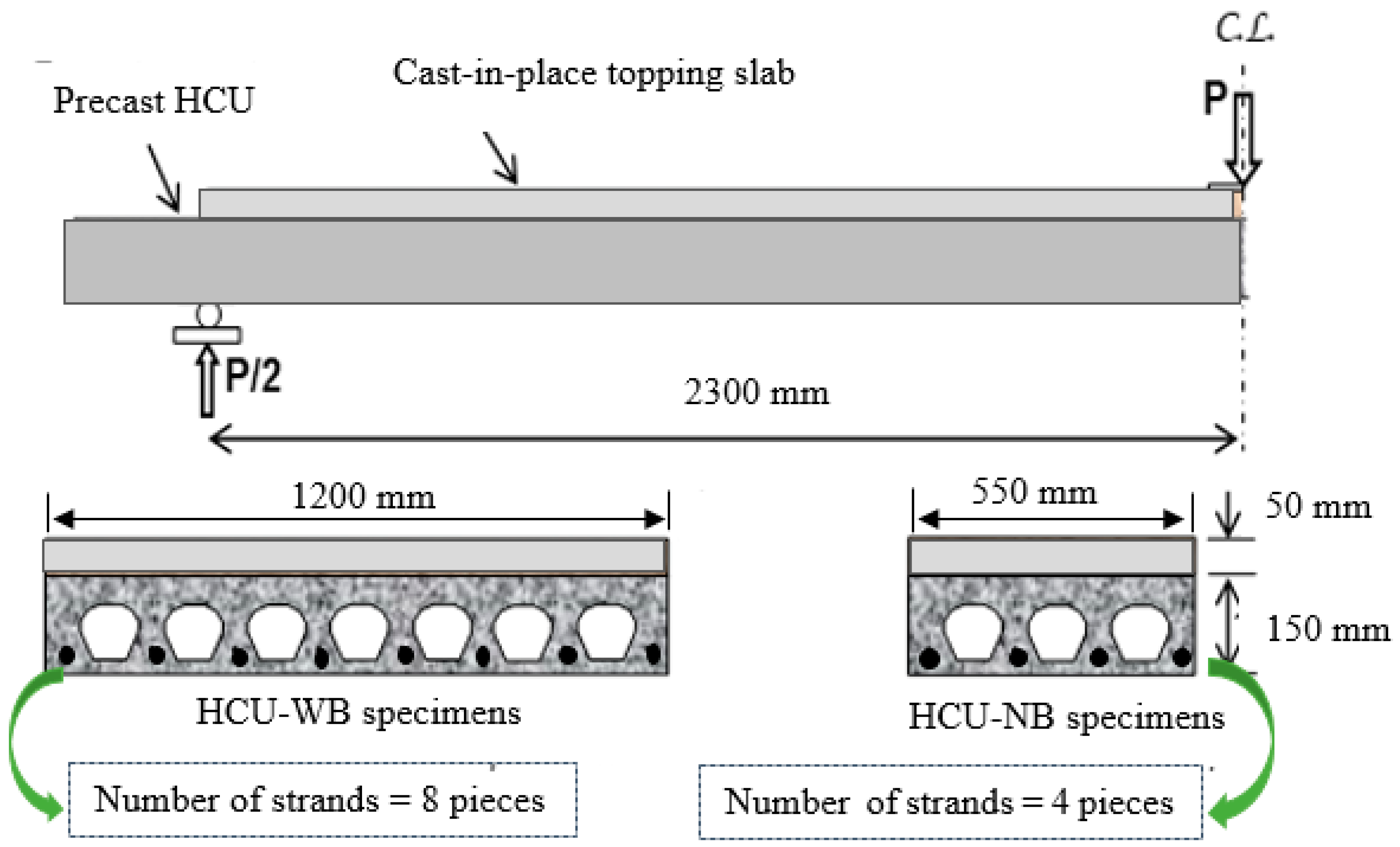
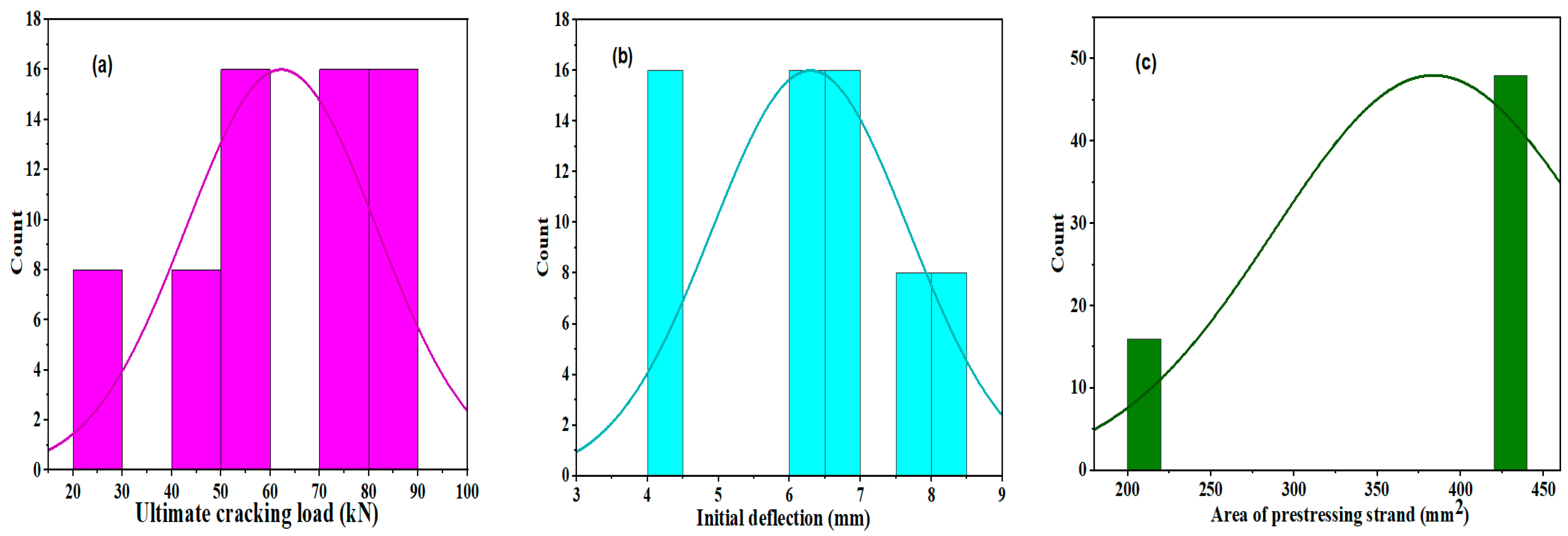
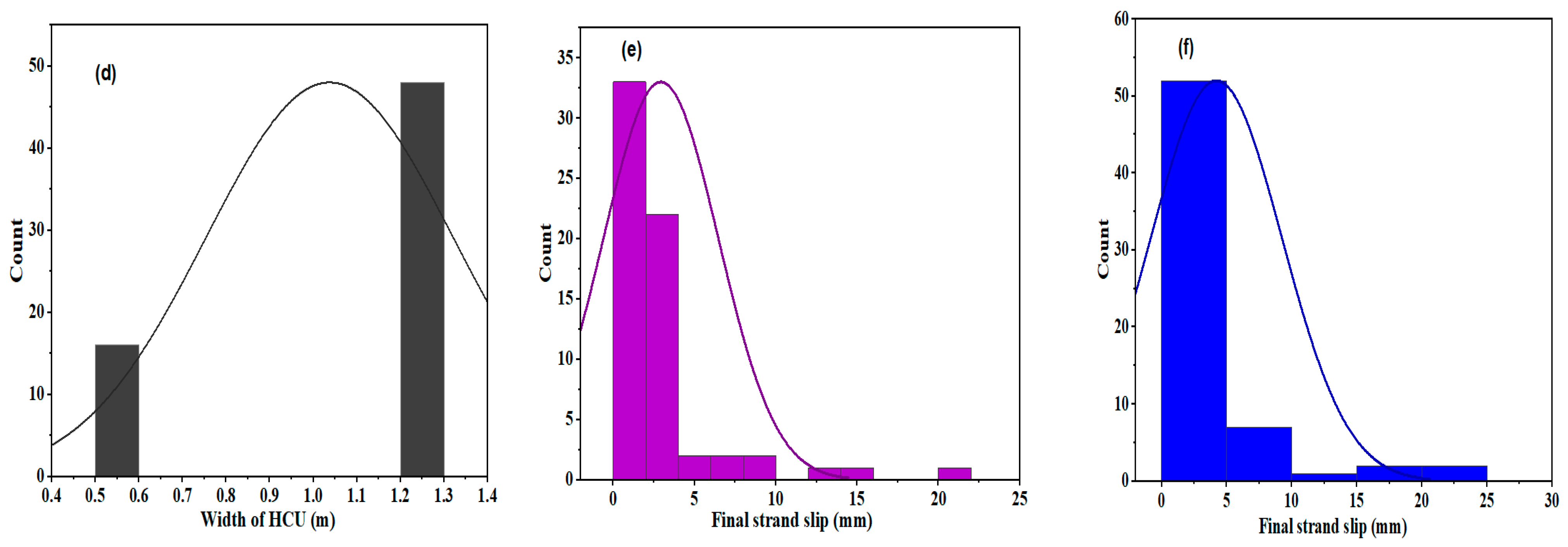
The frequency distributions of the dataset utilized to estimate the final strand slips of the HCU slabs under flexural loading are shown in
Figure 10. The figures showed that potential datasets did not follow the normal distributions. The frequently used values of the ultimate cracking load ranged from 70 kN to 90 kN. Most of the initial crack deflections were between 6 and 7 mm, and the strand area and width of the HCU-WBs were used. The most frequently used initial and final strand slip values were between 0.1 and 5 mm.
The MATLAB (2021a) toolbox (Machine learning) was used to develop the classical and hybrid models. The validation of the classical model was carried out using a 10-fold cross-validation technique [
22,
24]. The models used were the trained and tested dataset. The performances of the models were determined using the evaluation metrices and are summarized in
Table 7. As shown in
Table 7, all the developed models estimated the strand slips with high accuracies in the two modelling stages with the
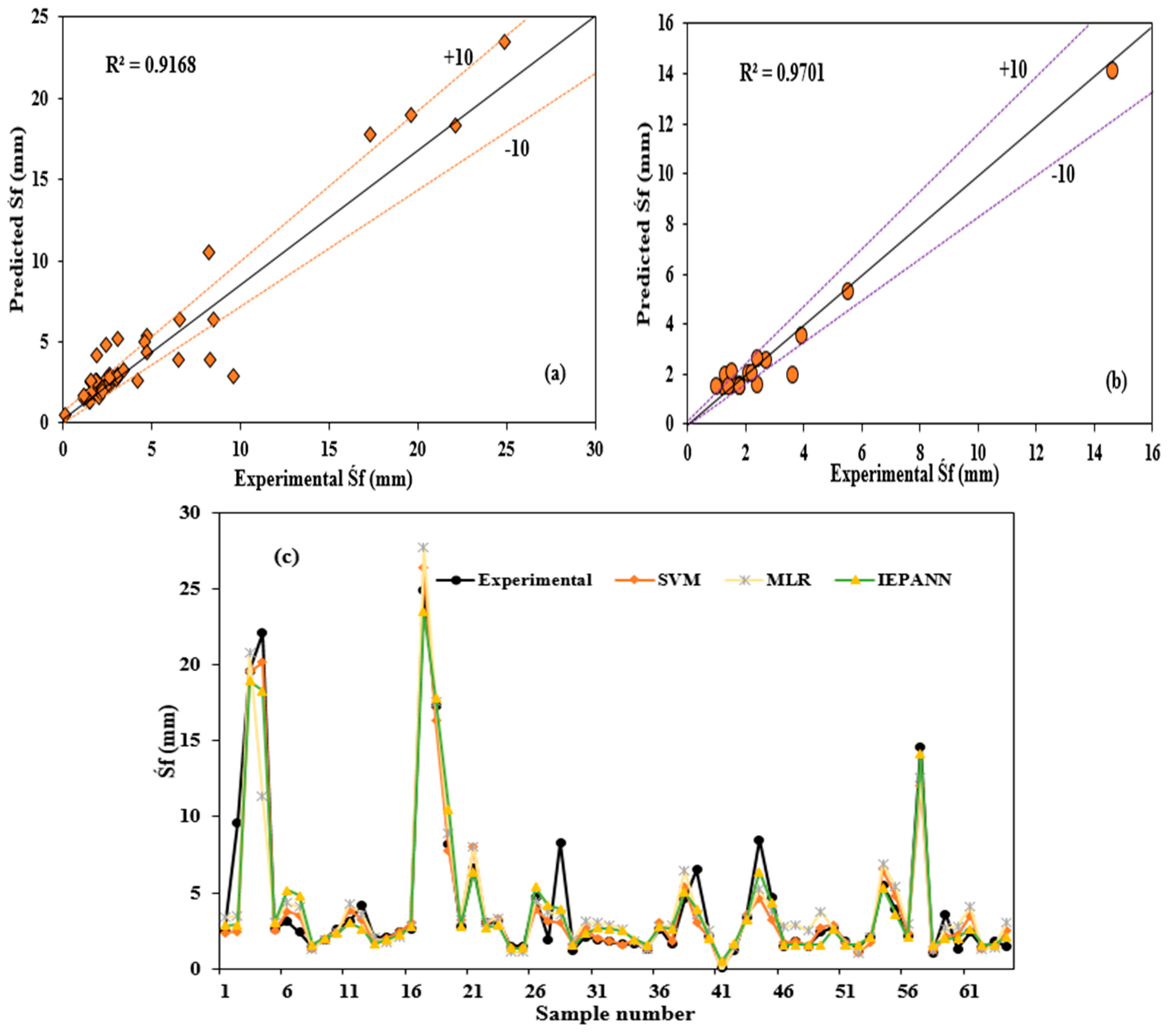
R2 values > 0.8. Moreover, the IEPANN outperformed the other classical model in forecasting Śf in the precast HCUs with the
R2 values of 0.9168 in the training phase and 0.9701 in the attesting phase. The normalized RI values were used to assess the performances of both the classical and hybrid models because the other evaluation indicators might not effectively reflect the combined errors of the developed models. As can be observed, the hybrid IEPANN model performed best in the training and testing phases with the RI values of 1.31 and 0.4651.
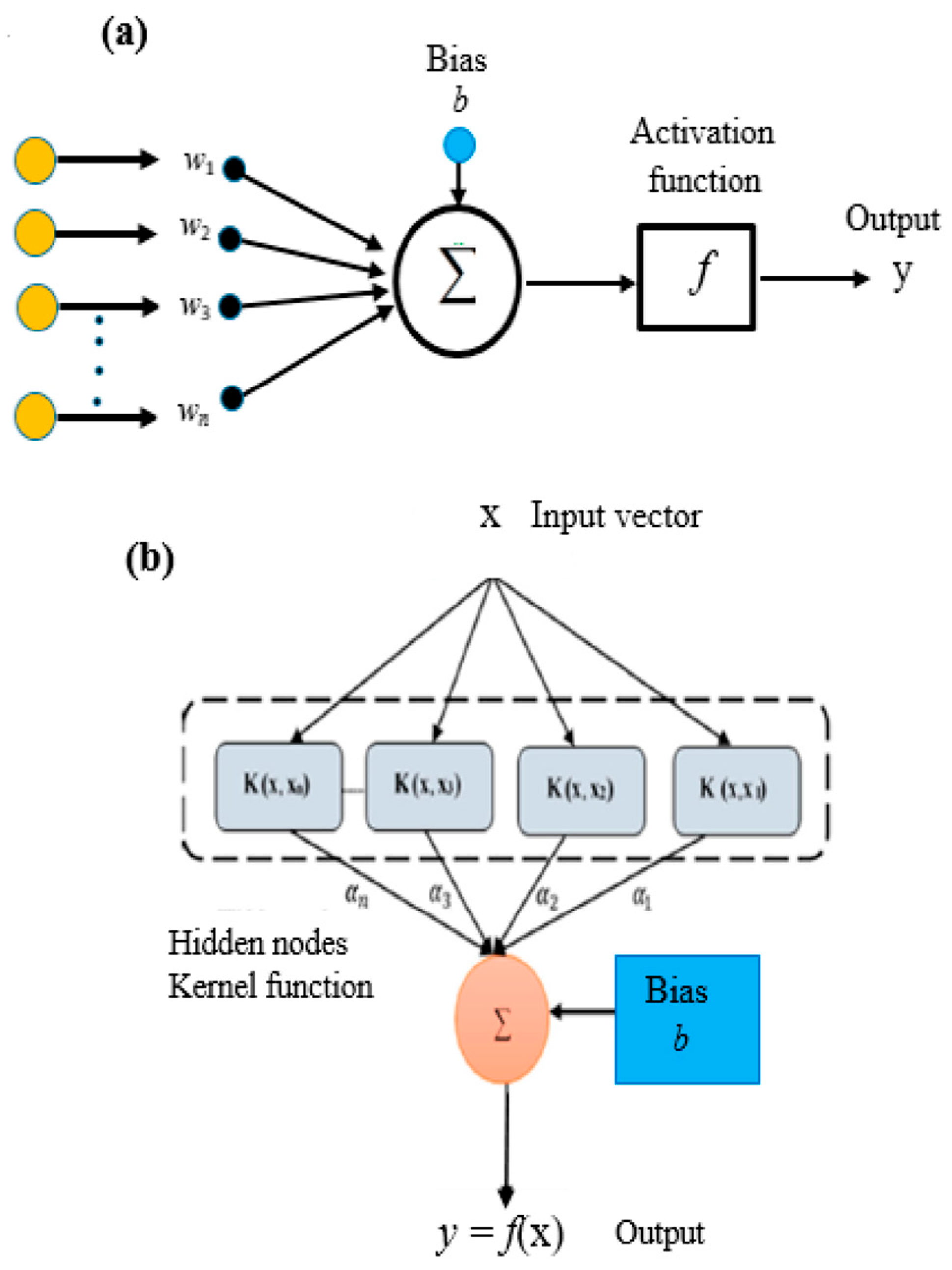
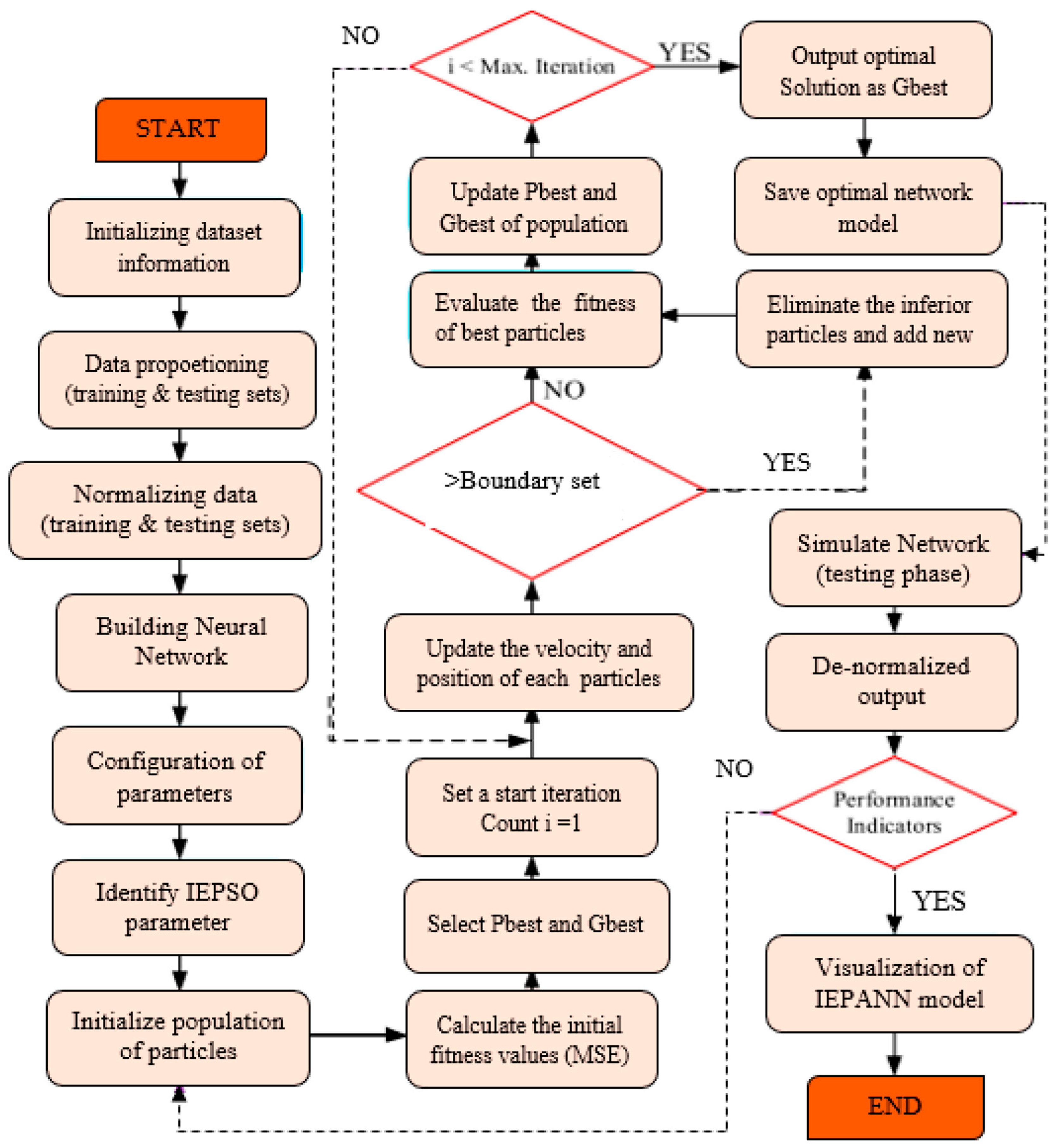
6.3. IEPANN
To develop the IEPANN model, this study implemented one hidden layer of the ANN, as recommended in some previous studies [
47,
48]. Therefore, a trial run with two to nine neurons achieved the optimal neuron number. The model was trained using Levenberg–Marquardt back-propagation techniques, with Purelin in the output layer and Tansig in the hidden layer. The general operating theory of the ANN model for estimating the Śf is expressed as
where
bx and
wj are the bias in the output and the weight joining the
jth neuron in the hidden and output,
wij is the weight of the connection between the
ith input parameter and the neuron in the hidden layer,
bhj is the bias in the
jth neuron of the hidden neuron, and
Ii is the input parameter
i.
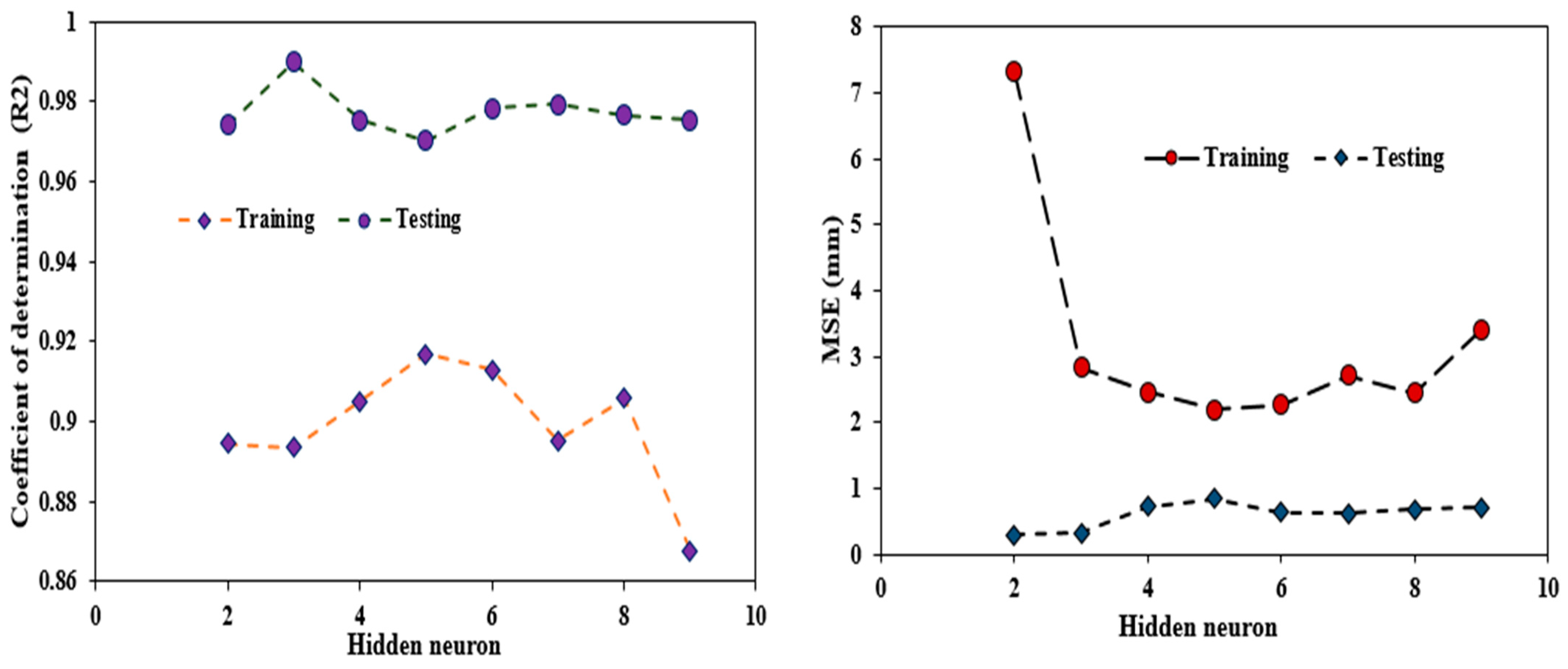
Figure 13 shows the performances of the IEPANN model. It can be observed that the IEPANN technique exhibiting five neurons in the hidden layer (5
5 × 1) outperformed the other single models with the
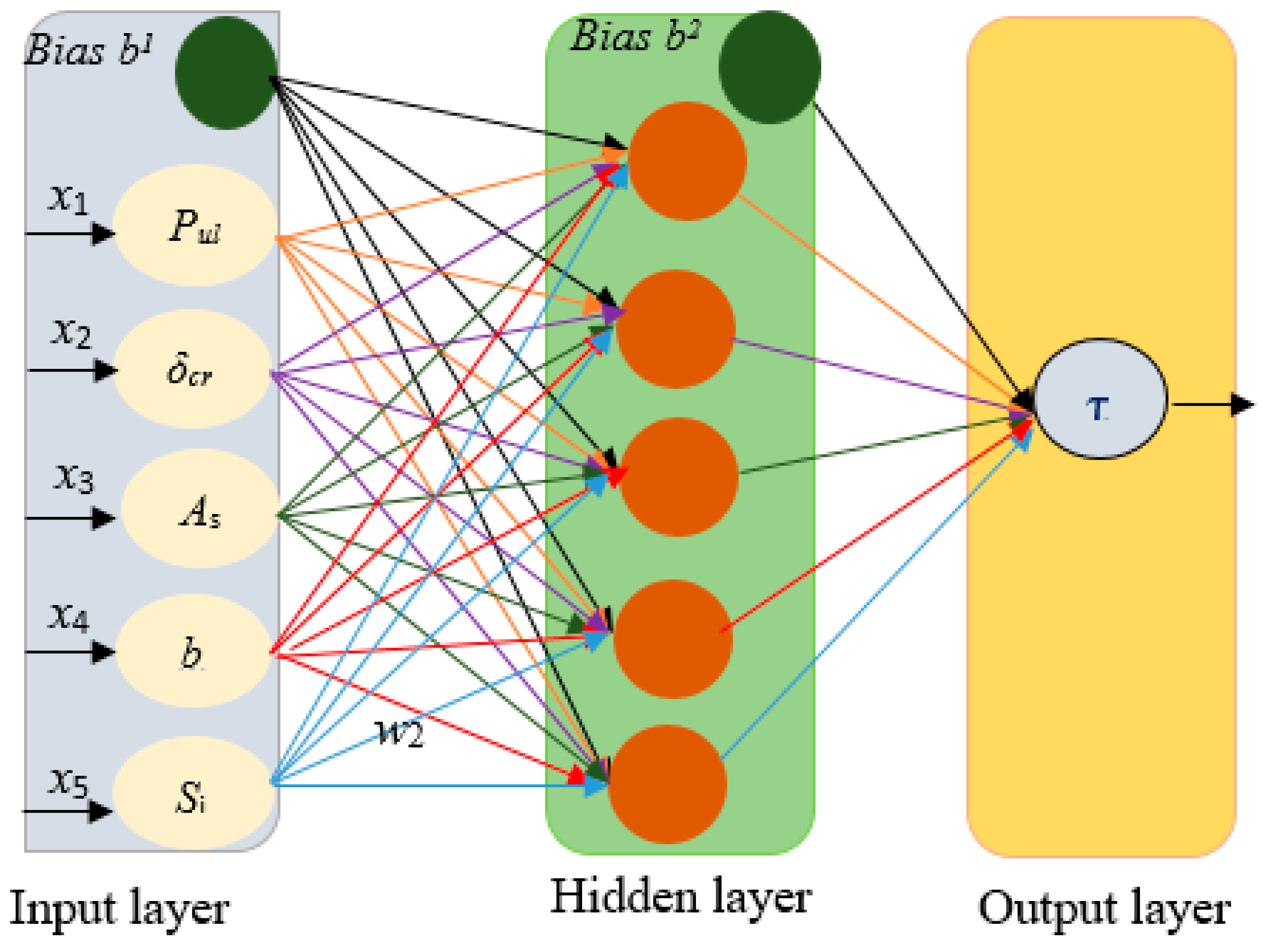
R2 values of 0.9168 in the training phase and 0.9701 in the testing phase, with the lowest MSE values of 0.0836 and 0.0299, respectively. The structure of the optimal IEPANN is shown in
Figure 14.
Subsequently, the learning approach was to optimize the ANN weight and bias with the IEPSO. In this process, parameters such as population size, velocity coefficient, inertia weight, the local–global information sharing parameter, and stopping criteria were optimized in the ANN model. The coefficients of the velocities
V1 and
V2 are described according to [
54], as given in Equation (14) below.
The construction coefficient ϕ1 = ϕ2 − 2.05, the dumping ratio = 1, and w = 0.7280, with the upper bound velocity of −5 and the lower bound velocity of 5, respectively. Equation (10) was used to determine c3. Moreover, different swarm sizes were explored in this study to obtain the optimal size. Swarm sizes of 100, 150, 200, …., 300 were adopted. The maximum iteration of the IEPSO approach was regarded as its criterion for stopping. The sensitivity study showed that the MSE value remained constant after 150 iterations, which was thought to be the optimal iteration. The right swarm size was selected based on these iterations, considering the R2 and MSE values. Therefore, the IEPANN model having 120 populations exhibited the highest R2 and lowest MSE values in the two modelling phases, and thus considered the optimal model.
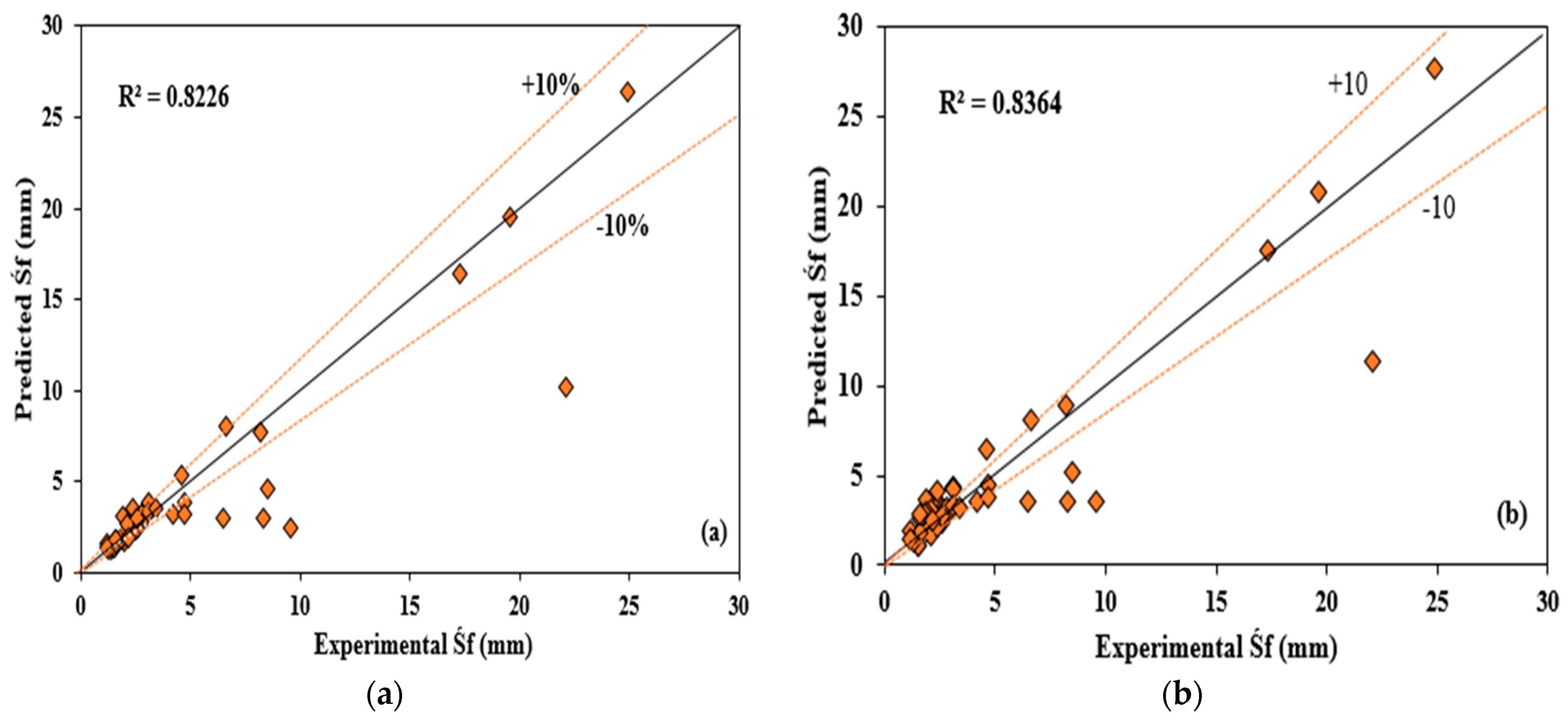
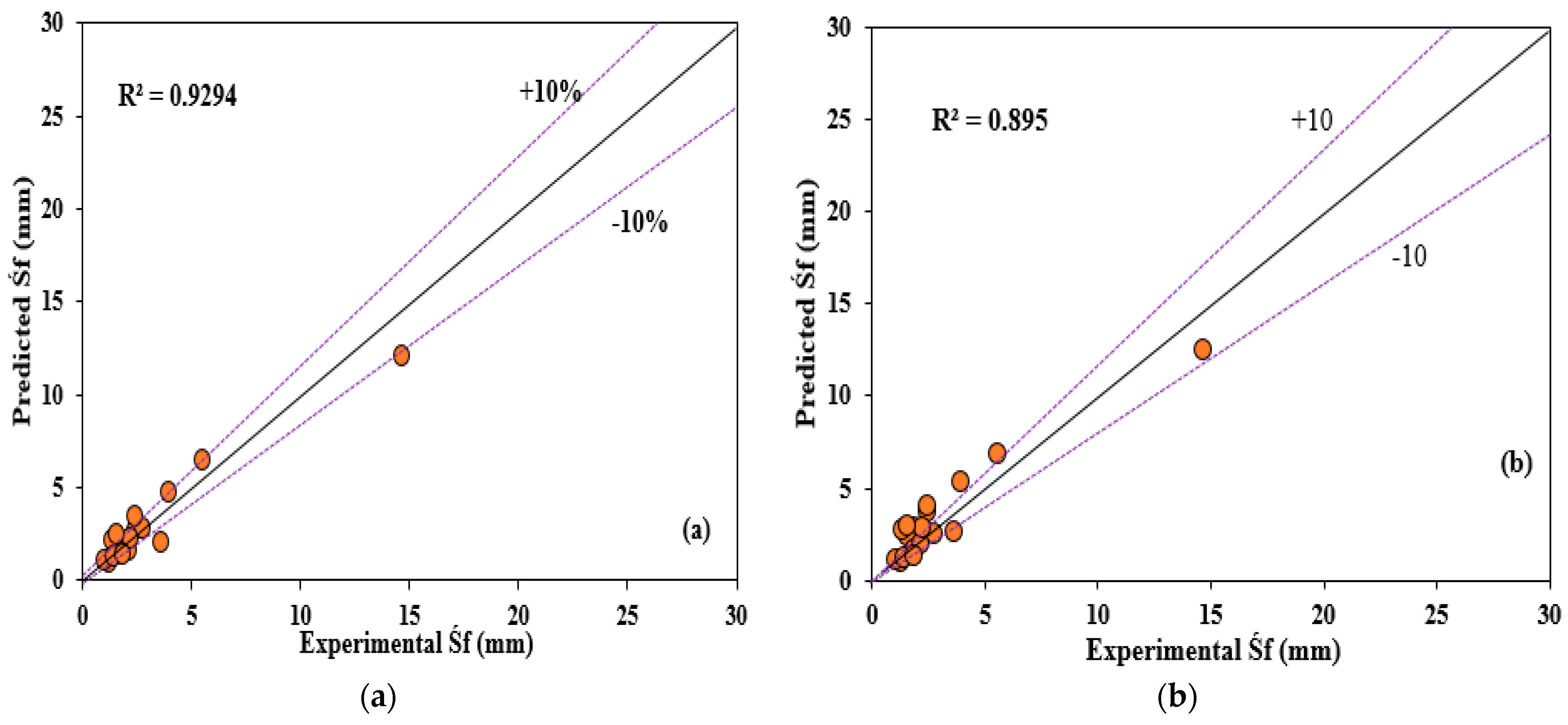
Figure 15 presents the scatters between the experimental and predicted results obtained from the IEPANN model in the modelling phases. As shown in
Figure 15, good agreements between the measured and predicted values were achieved, and data points were close to the fitted lines. The prediction skills of the IEPANN model in the testing phase were higher than those in the training phase. This is similar to the results obtained in the two single models, which is attributed to the dataset involved in the modelling in the testing phase. Moreover, the overall performances of all developed models were provided for comparisons, as depicted in
Figure 15c, which defined the relationships between the observed and predicted values for individual models. The predicted data points were close to the actual data, indicating the effectiveness and accuracy of the developed model, particularly the IEPANN model, for predicting the final prestressing strand slips considering the nonlinearity relations between the input parameters and strand slips. In the related study by Alhassan et al. [
13], which determine the optimal prediction of the transfer length (TL) of prestressing strand based on the ANN model, the results showed the ANN predicted the TL with high prediction skills with all
R2 values greater than 0.9.
To provide an explicit equation for the final strand slip (Śf), Equation (15) is modified by computing and substituting the optimum weight and bias of the trained IEPANN model.
where
y1,
y2, …,
y5 are determined using the input variables as:
In addition, Equation (21) was used to determine the activation function as
From Equations (16)–(20), it is clear that all the input variables were multiplied by the weight, and the bias of the optimum IEPANN model was added to the sum. Following the determination of the nonlinear activation function, Equation (15) was used to analyse the prestressing strand slips.
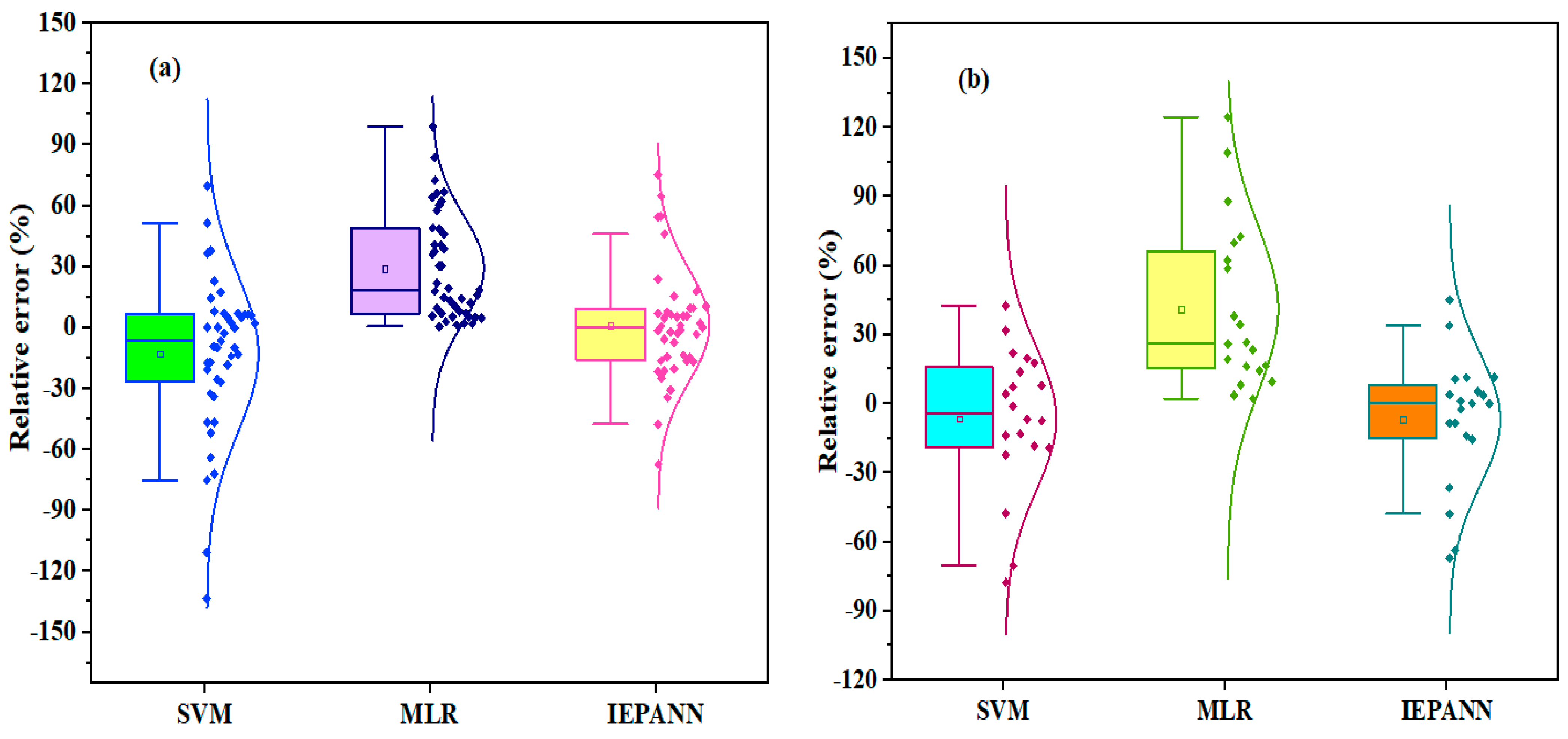
The relative error distributions obtained from individual models were used to evaluate the accuracy of the ML. Boxplot was used to compare the relative error distributions for individual models in the training and testing phases, as shown in
Figure 16. From
Figure 16a, it can be noted that the IEPANN demonstrated the highest accuracy with the lowest maximum and minimum relative error distributions in estimating the final strand slips in the training stage, with the first quartile (Q1) and third quartile (Q3) values of −8.6% and −15%. Secondly, the SVM was the second model with the lowest relative error distributions, with the minimum relative error distribution of 7.5% and the maximum relative error distribution of −22.3%.
Generally, the relative error distributions exhibited by all the MLs were slighly higher in the training phase compared to those in the testing stage, as depicted in
Figure 16a. Similarly, from
Figure 16b, the lowest error distributions were obtained in the IEPANN and SVM models in the testing phase. The minimum and maximum error distributions in Q1 and Q3 were −14.2% and 8%, respectively. Thes results were consistent with the highest performances of the IEPANN model in the scatter curves for the two modeling stages, compared to other models (MLR, SVM).
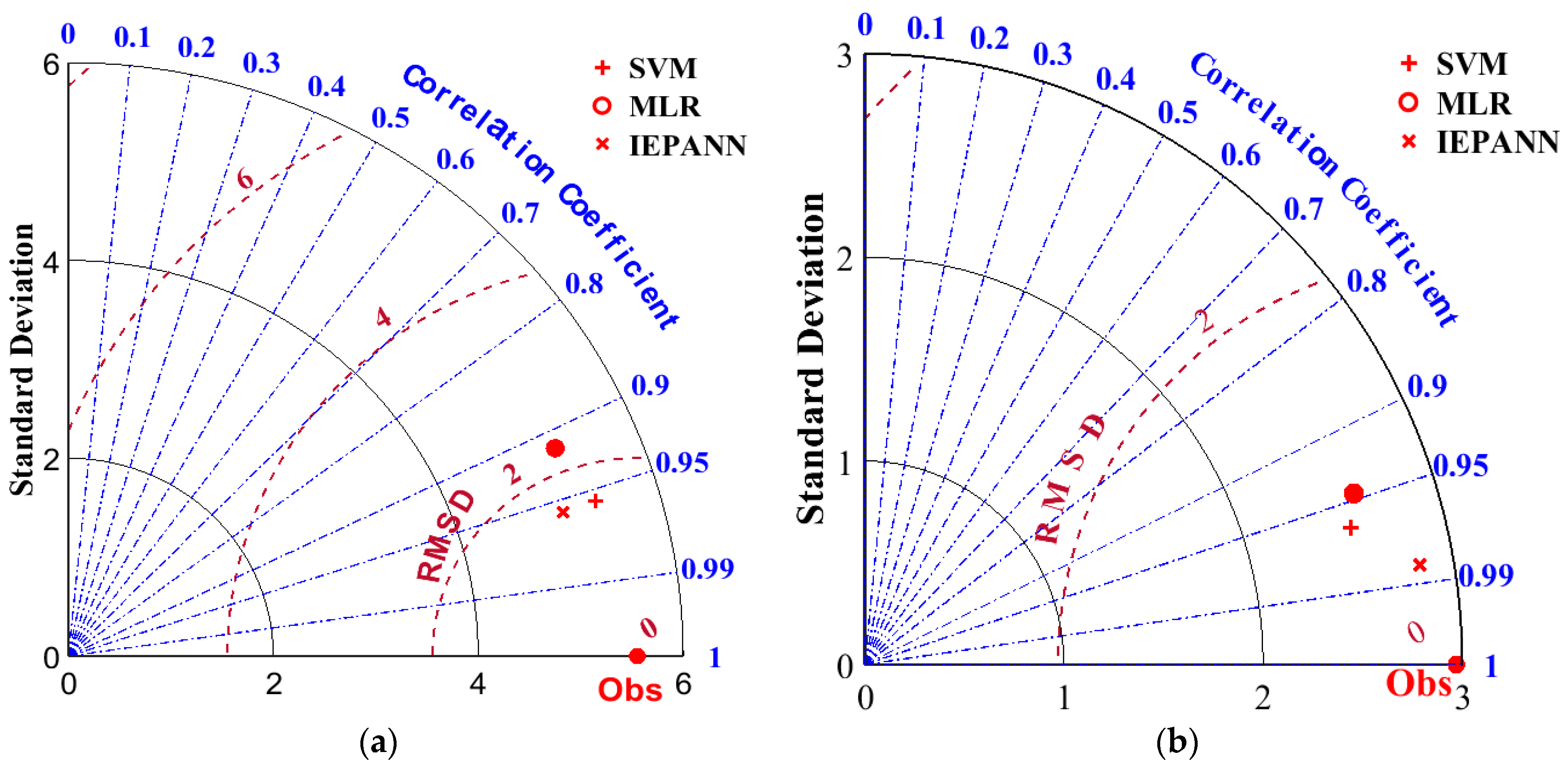
Furthermore, the performances of the ML model in the two modeling phases were also checked using the Taylor diagram, as shown in
Figure 17. The Taylor diagram is a compressive approach for comparing model performances using three statistical parameters: RMSE,
R2 and SD. The correlation between the measured and predicted values was specified by the azimuthal point, i.e., the location where the measured and predicted fields were directly correlated with the RMSE values. The RMSE values decreased with the increases in correlations. As a result, the radial distance measured from the origin increased with an increasing trend of the standard deviation [
55]. The perfect model is achieved by reference point with
R2 = 1 [
56]. However, if the predicted SD is greater than that of the observed data, overestimation may occur, or vice versa. Therefore, it is necessary to use a standard deviation approach to obtain the SD of the observed data.
From
Figure 17a,b, the hybridized IEPANN models demonstrated higher performances in estimating the strand slips in the precast prestressed HCUs with RMSE,
R, and SD closer to the actual data in both training and testing phases. The scatter plots showed that the hybridized IEPANN outperformed all other models in terms of all evaluation matrices. The standard deviations of all the models were lower than those of the actual data, proving that models were not affected by overestimation.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}