
Seismic Vulnerability Assessment at an Urban Scale by Means of Machine Learning Techniques


 ,
,  ,
,  and
and
Abstract
:1. Introduction
2. Buildings Dataset and “a priori” Seismic Vulnerability Estimation
3. Machine Learning Models and Dataset Pre-Processing
3.1. ANN and Random Forest Algorithms
- Random Forest Classifier (RFC): This model is an ensemble learning technique, well-regarded for its robustness and accuracy in various applications. The main key strength of random forest algorithms lies in their ability to prevent overfitting, a common challenge in machine learning models. This is achieved through its ensemble nature (see Figure 2), where multiple trees, each trained on subsets of the data with randomized feature selection, contribute to the final classification, thus ensuring a very reliable performance.
- Artificial Neural Network (ANN): This model is inspired by a brain’s neural networks, comprising layers of interconnected nodes or neurons. Each node processes the input data, which then travel through multiple layers, each altering the input uniquely. ANNs excel in learning intricate patterns in data by modifying the weights of the connections between neurons through backpropagation. Figure 3 shows the architecture of the ANN used in our work: after normalization, the data are passed onto the ‘Feature Augmentation’ module, which applies mathematical transformations to the numeric values (building coordinates and distance to the five main epicenters) in order to improve both the model’s ability to assign the correct vulnerability to each location and the overall performance.
3.2. Data Pre-Processing and Features Selection
- Since the original dataset employs highly detailed damage categorization, some simplification is necessary. First of all, we only refer to damage that occurred in vertical structures. The level of damage was originally classified according to what was proposed in the European Macroseismic Scale EMS-98, namely: D1 (light damage), D2 (moderate damage), D3 (extensive damage), D4 (total damage), and D5 (collapse). The zero damage class D0 was also added to the previous ones for completeness. Since, in the database, damages are reported for different portions of each building, the different combinations result in a complex matrix of 26 distinct damage classes with a non-homogeneous number of elements. To circumvent this issue, we condensed these classes, assuming the highest level of damage sustained by any of its portions for each building. Finally, merging the three highest damage classes (D3, D4, and D5) into a macro class representing general ‘high damage’ reduces the classification to four ordinal damage categories, ranging from D0 to D3. Alternative strategies, like assigning a numerical score to each of the 26 categories for regression analysis or experimenting with different class counts, were explored but did not enhance the model’s performance. This optimized approach is both efficient and practical, ensuring a more balanced and manageable dataset for analysis.
- Then, specific columns (Figure 4) from the original dataset were selected for analysis, including geographic, structural, and damage-related information. The considered characteristics of the buildings concern the following:
- Horizontal and vertical structure typologies;
- Chains, beams, or isolated columns;
- Year of construction or restructuring;
- Latitude and longitude of buildings;
- Number of floors, basement floors, floor height, and area;
- Slope morphology and position in the complex.
4. “A posteriori” Seismic Vulnerability Estimation and Numerical Results
- Creation of dummy buildings: these are not real buildings but virtual ones created only for analysis. Each dummy building mirrors the actual buildings in all respects except for one chosen feature, which is held constant across the entire set. For instance, we might simulate a group of buildings with exactly two floors, regardless of their original design.
- Model predictions: we then input these dummy buildings into our pre-trained machine learning models: the neural network and random forest. The models assess each building and output a damage prediction, treating the fixed feature as a variable of interest.
- “A posteriori” vulnerability score derivation: by analyzing the predicted damage across all dummy buildings with the fixed feature, we can calculate an average predicted damage value. This average becomes a numerical representation, a score, of the vulnerability contributed by that specific feature (e.g., having two floors).
- Comprehensive feature analysis: this procedure is methodically applied to each categorical feature within our dataset. As a result, we establish a continuous “a posteriori” vulnerability score for every characteristic examined.
- Score averaging for robustness: to ensure our findings are not skewed by the idiosyncrasies of a single model, we further average the results of the “a posteriori” vulnerability scores obtained with both the neural network and the random forest models. This step enhances the reliability of our results, yielding a more balanced and comprehensive “a posteriori” vulnerability score for each building feature.
4.1. Demonstrating Spatial Independence in Seismic Vulnerability Prediction
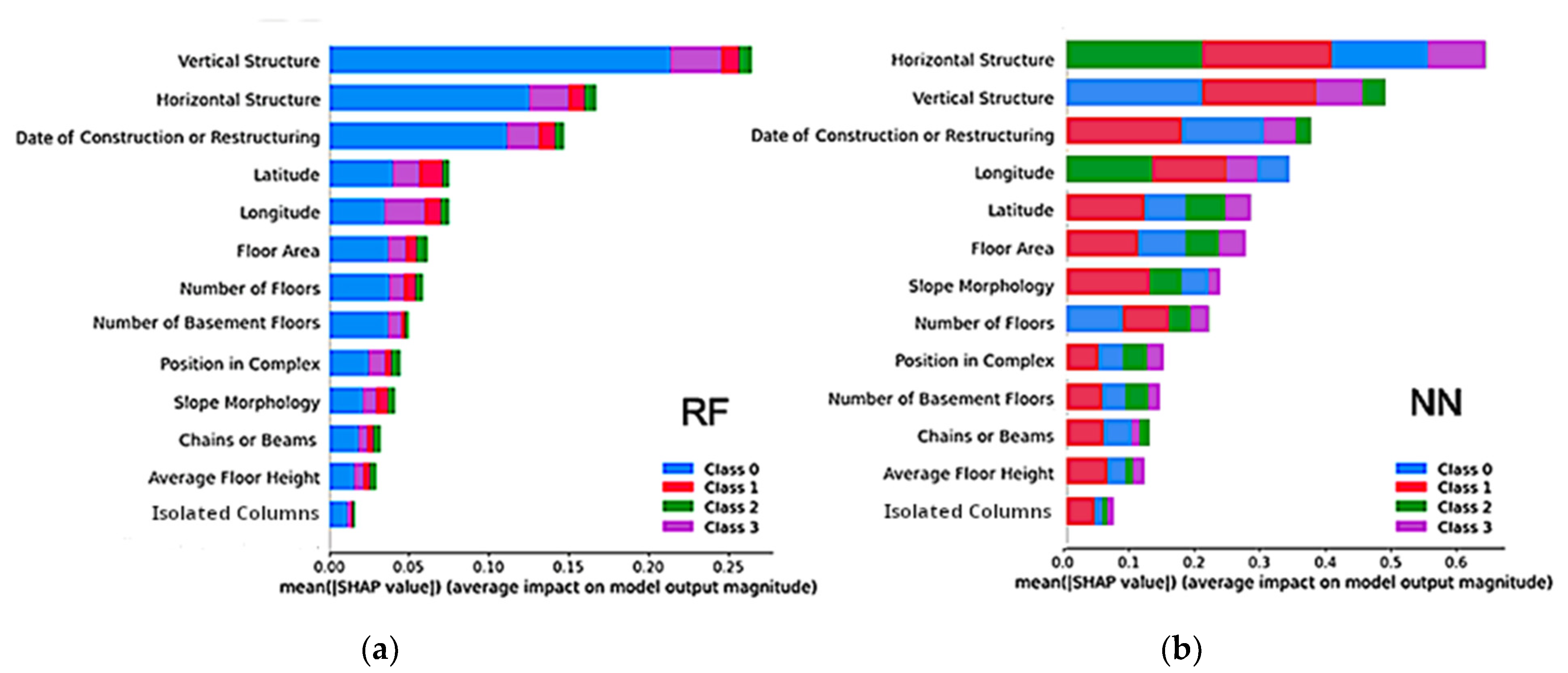
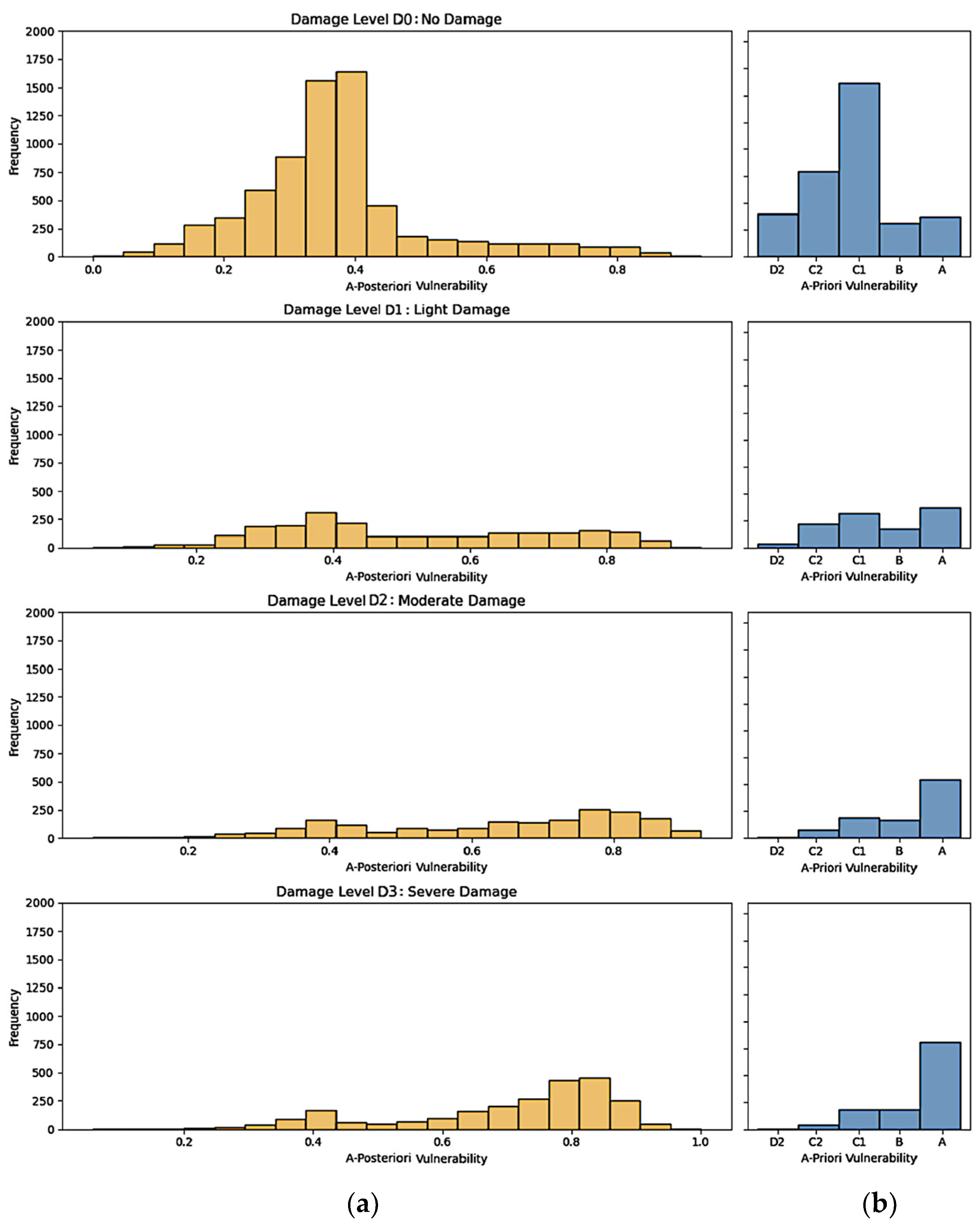
4.2. Feature Analysis and A-Posteriori Vulnerability Score
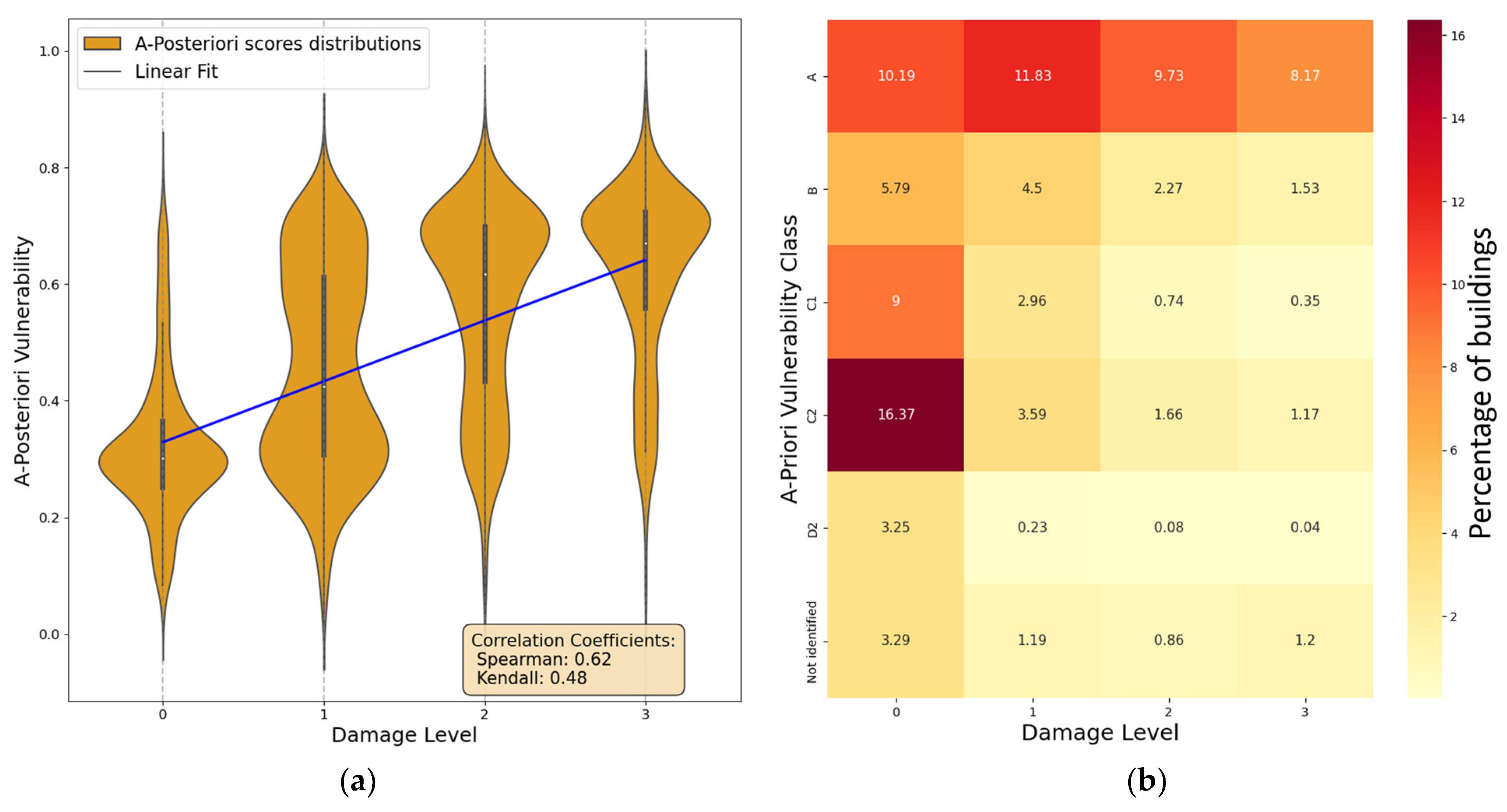
4.3. Correlation Analysis at Fixed Distance
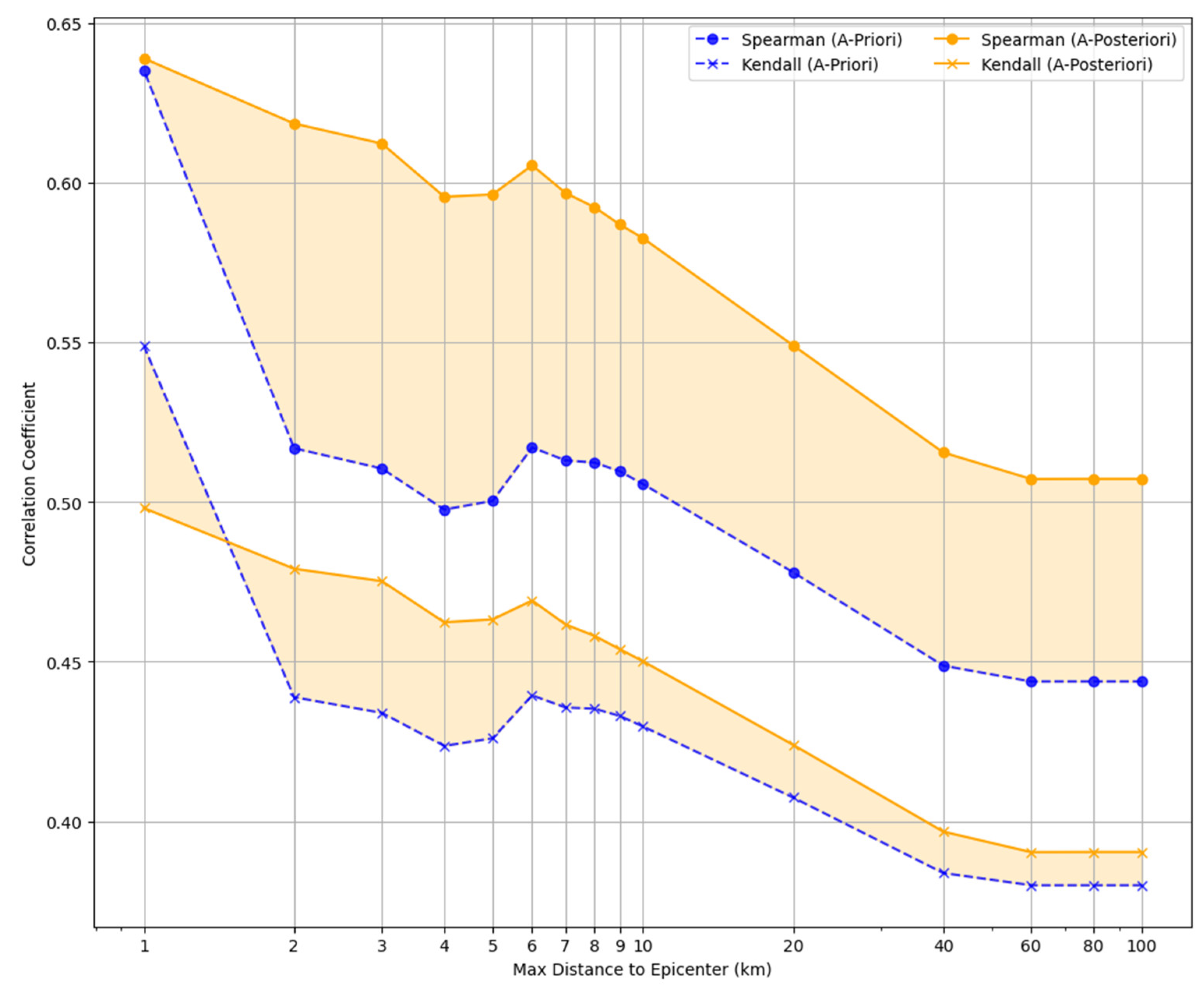
4.4. Correlation Analysis over Distance
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ramhormozian, S.; Clifton, G.C.; Latour, M.; MacRae, G.A. Proposed Simplified Approach for the Seismic Analysis of Multi-Storey Moment Resisting Framed Buildings Incorporating Friction Sliders. Buildings 2019, 9, 130. [Google Scholar] [CrossRef]
- Greco, A.; Fiore, I.; Occhipinti, G.; Caddemi, S.; Spina, D.; Caliò, I. An Equivalent Non-Uniform Beam-like Model for Dynamic Analysis of Multi-Storey Irregular Buildings. Appl. Sci. 2020, 10, 3212. [Google Scholar] [CrossRef]
- Blasone, V.; Basaglia, A.; De Risi, R.; De Luca, F.; Spacone, E. A simplified model for seismic safety assessment of reinforced concrete buildings: Framework and application to a 3-storey plan-irregular moment resisting frame. Eng. Struct. 2022, 250, 113348. [Google Scholar] [CrossRef]
- Greco, A.; Caddemi, S.; Caliò, I.; Fiore, I. A Review of Simplified Numerical Beam-like Models of Multi-Storey Framed Buildings. Buildings 2022, 12, 1397. [Google Scholar] [CrossRef]
- Lin, J.; Chuang, M. Simplified nonlinear modeling for estimating the seismic response of buildings. Eng. Struct. 2023, 279, 115590. [Google Scholar] [CrossRef]
- Perrone, D.; Aiello, M.A.; Pecce, M.; Rossi, F. Rapid visual screening for seismic evaluation of RC hospital buildings. Structures 2015, 3, 57–70. [Google Scholar] [CrossRef]
- Lagomarsino, S.; Giovinazzi, S. Macroseismic and mechanical models for the vulnerability and damage assessment of current buildings. Bullet. Earthq. Eng. 2006, 4, 415–443. [Google Scholar] [CrossRef]
- Benedetti, D.; Benzoni, G.; Parisi, M.A. Seismic vulnerability and risk evaluation for old urban nuclei. Earthq. Eng. Struct. Dyn. 1988, 16, 183–201. [Google Scholar] [CrossRef]
- Mourous, P.; Le Brun, B. Risk-UE Project: An Advanced Approach to Earthquake Risk Scenarios with Application to Different European Towns. In Assessing and Managing Earthquake Risk. Geotechnical, Geological and Earthquake Engineering; Oliveira, C.S., Roca, A., Goula, X., Eds.; Springer: Dordrecht, The Netherlands, 2008; Volume 2. [Google Scholar]
- Bernardini, A.; Giovinazzi, S.; Lagomarsino, S.; Parodi, S. Vulnerabilità e Previsione di Danno a Scala Territoriale Secondo una Metodologia Macrosismica Soerente con la Scala EMS-98. In Proceedings of the 12th Italian Conference on Earthquake Engineering, Pisa, Italy, 10–14 June 2007. [Google Scholar]
- Vicente, R.; Parodi, S.; Lagomarsino, S.; Varum, H.; Silva, J. Seismic vulnerability and risk assessment: Case study of the historic city centre of Coimbra, Portugal. Bullet. Earthq. Eng. 2011, 9, 1067–1096. [Google Scholar] [CrossRef]
- Greco, A.; Pluchino, A.; Barbarossa, L.; Barreca, G.; Caliò, I.; Martinico, F.; Rapisarda, A. A New Agent-Based Methodology for the Seismic Vulnerability Assessment of Urban Areas. ISPRS Int. J. Geo-Inf. 2019, 8, 274. [Google Scholar] [CrossRef]
- Fischer, E.; Barreca, G.; Greco, A.; Martinico, F.; Pluchino, A.; Rapisarda, A. Seismic risk assessment of a large metropolitan area by means of simulated earthquakes. Nat. Hazards 2023, 118, 117–153. [Google Scholar] [CrossRef]
- Eleftheriadou, A.K.; Karabinis, A.I. Evaluation of damage probability matrices from observational seismic damage data. Earthquakes Struct. 2013, 4, 299–324. [Google Scholar] [CrossRef]
- Surana, M.; Meslem, A.; Singh, Y.; Lang, D.H. Analytical evaluation of damage probability matrices for hill-side RC buildings using different seismic intensity measures. Eng. Struct. 2020, 207, 110254. [Google Scholar] [CrossRef]
- Li, S.-Q.; Chen, Y.-S. Analysis of the probability matrix model for the seismic damage vulnerability of empirical structures. Nat. Hazards 2020, 104, 705–730. [Google Scholar] [CrossRef]
- Ruggieri, S.; Calò, M.; Cardellicchio, A.; Uva, G. Analytical-mechanical based framework for seismic overall fragility analysis of existing RC buildings in town compartments. Bullet. Earthq. Eng. 2022, 20, 8179–8216. [Google Scholar] [CrossRef]
- Ruggieri, S.; Liguori, F.S.; Leggieri, V.; Bilotta, A.; Madeo, A.; Casolo, S.; Uva, G. An archetype-based automated procedure to derive global-local seismic fragility of masonry building aggregates: META-FORMA-XL. Int. J. Disaster Risk Reduct. 2023, 95, 103903. [Google Scholar] [CrossRef]
- Leggieri, V.; Mastrodonato, G.; Uva, G. GIS Multisource Data for the Seismic Vulnerability Assessment of Buildings at the Urban Scale. Buildings 2022, 12, 523. [Google Scholar] [CrossRef]
- Alizadeh, M.; Ngah, I.; Hashim, M.; Pradhan, B.; Pour, A.B. A Hybrid Analytic Network Process and Artificial Neural Network (ANP-ANN) Model for Urban Earthquake Vulnerability Assessment. Remote Sens. 2018, 10, 975. [Google Scholar] [CrossRef]
- Alizadeh, M.; Zabihi, H.; Rezaie, F.; Asadzadeh, A.; Wolf, I.D.; Langat, P.K.; Khosravi, I.; Pour, A.B.; Nataj, M.M.; Pradhan, B. Earthquake Vulnerability Assessment for Urban Areas Using an ANN and Hybrid SWOT-QSPM Model. Remote Sens. 2021, 13, 4519. [Google Scholar] [CrossRef]
- De-Miguel-Rodríguez, J.; Morales-Esteban, A.; Requena-García-Cruz, M.-V.; Zapico-Blanco, B.; Segovia-Verjel, M.-L.; Romero-Sánchez, E.; Carvalho-Estêvão, J.M. Fast Seismic Assessment of Built Urban Areas with the Accuracy of Mechanical Methods Using a Feedforward Neural Network. Sustainability 2022, 14, 5274. [Google Scholar] [CrossRef]
- Arslan, M.H. An evaluation of effective design parameters on earthquake performance of RC buildings using neural networks. Eng. Struct. 2010, 32, 1888–1898. [Google Scholar] [CrossRef]
- Afsari, R.; Shorabeh, S.N.; Lomer, A.R.B.; Homaee, M.; Arsanjani, J.J. Using Artificial Neural Networks to Assess Earthquake Vulnerability in Urban Blocks of Tehran. Remote Sens. 2023, 15, 1248. [Google Scholar] [CrossRef]
- Jena, R.; Pradhan, B. Integrated ANN-cross-validation and AHP-TOPSIS model to improve earthquake risk assessment. Int. J. Disaster Risk Reduct. 2020, 50, 101723. [Google Scholar] [CrossRef]
- Harirchian, E.; Lahmer, T. Improved Rapid Assessment of Earthquake Hazard Safety of Structures via Artificial Neural Net-works. IOP Conf. Ser. Mater. Sci. Eng. 2020, 897, 012014. [Google Scholar] [CrossRef]
- Kalakonas, P.; Silva, V. Seismic vulnerability modelling of building portfolios using artificial neural networks. Earthq. Eng. Struct. Dyn. 2022, 51, 310–327. [Google Scholar] [CrossRef]
- Izquierdo-Horna, L.; Zevallos, J.; Yepez, Y. An integrated approach to seismic risk assessment using random forest and hierarchical analysis: Pisco, Peru. Heliyon 2022, 8, e10926. [Google Scholar] [CrossRef]
- Han, J.; Kim, J.; Park, S.; Son, S.; Ryu, M. Seismic Vulnerability Assessment and Mapping of Gyeongju, South Korea Using Frequency Ratio, Decision Tree, and Random Forest. Sustainability 2020, 12, 7787. [Google Scholar] [CrossRef]
- Elyasi, N.; Kim, E.; Yeum, C. A Machine-Learning-Based Seismic Vulnerability Assessment Approach for Low-Rise RC Buildings. J. Earthq. Eng. 2023, 1–17. [Google Scholar] [CrossRef]
- Saadati, D.; Moghadam, A. EZRVS: An AI-Based Web Application to Significantly Enhance Seismic Rapid Visual Screening of Buildings. J. Earthq. Eng. 2023, 1–18. [Google Scholar] [CrossRef]
- Ruggieri, S.; Cardellicchio, A.; Leggieri, V.; Uva, G. Machine-learning based vulnerability analysis of existing buildings. Autom. Constr. 2021, 132, 103936. [Google Scholar] [CrossRef]
- Harirchian, E.; Jadhav, K.; Kumari, V.; Lahmer, T. ML-EHSAPP: A prototype for machine learning-based earthquake hazard safety assessment of structures by using a smartphone app. Eur. J. Environ. Civ. Eng. 2022, 26, 5279–5299. [Google Scholar] [CrossRef]
- Silva, V.; Brzev, S.; Scawthorn, C.; Yepes, C.; Dabbeek, J.; Crowley, H. A Building Classification System for Multi-hazard Risk Assessment. Int. J. Disaster Risk Sci. 2022, 13, 161–177. [Google Scholar] [CrossRef]
- Dataset Developed by Eucentre European Center for Training and Research in Seismic Engineering. Available online: https://egeos.eucentre.it/danno_osservato/web/danno_osservato (accessed on 22 June 2023).
- Mahesh, B. Machine learning algorithms-a review. Int. J. Sci. Res. 2020, 9, 381–386. [Google Scholar]
- Kotsiantis, S.B. Supervised machine learning: A review of classification techniques. Informatica 2007, 31, 249–268. [Google Scholar]
- Shapley, L.S. A Value for N-Person Games. In Contributions to the Theory of Games; Princeton University Press: Princeton, NJ, USA, 1952. [Google Scholar]
- Marcilio, W.E.; Eler, D.M. From Explanations to Feature Selection: Assessing SHAP Values as Feature Selection Mechanism. In Proceedings of the 2020 33rd SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Porto de Galinhas, Brazil, 7–10 November 2020; pp. 340–347. [Google Scholar]
- Ferranti, G. Machine Learning for Earthquake Damage Prediction and Vulnerability Assessment. Available online: https://earthquake-vulnerability-ml.streamlit.app/ (accessed on 9 January 2024).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vulnerability Class | Vertical Structure: Masonry | Horizontal Structure | Chains |
|---|---|---|---|
| A | Bad quality | Vaults without chains, vaults with chains, deformable slab, semi-rigid slab, unidentified | No |
| A | Bad quality | Vaults without unidentified chains | Yes |
| A | Good quality | Chain-free vaults, chain vaults, deformable slab, unidentified | No |
| B | Bad quality | Rigid slab | No |
| B | Bad quality | Chain vaults, deformable slab | Yes |
| B | Good quality | Semi-rigid slab | No |
| B | Good quality | Vaults without chains, vaults with chains, deformable slab, unidentified | Yes |
| C1 | Good quality | Rigid slab | No |
| C1 | Good quality | Semi-rigid slab, rigid slab | Yes |
| Vulnerability Class | Other Vertical Structures | Year of construction | |
| C2 | Reinforced concrete frame, mixed frame-masonry | <2001 | |
| D | Reinforced concrete frame, mixed frame-masonry | ≥2001 | |
| D | Steel frame | Any | |
| Unidentified | Unidentified | Any | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ferranti, G.; Greco, A.; Pluchino, A.; Rapisarda, A.; Scibilia, A. Seismic Vulnerability Assessment at an Urban Scale by Means of Machine Learning Techniques. Buildings 2024, 14, 309. https://doi.org/10.3390/buildings14020309
Ferranti G, Greco A, Pluchino A, Rapisarda A, Scibilia A. Seismic Vulnerability Assessment at an Urban Scale by Means of Machine Learning Techniques. Buildings. 2024; 14(2):309. https://doi.org/10.3390/buildings14020309
Chicago/Turabian StyleFerranti, Guglielmo, Annalisa Greco, Alessandro Pluchino, Andrea Rapisarda, and Adriano Scibilia. 2024. "Seismic Vulnerability Assessment at an Urban Scale by Means of Machine Learning Techniques" Buildings 14, no. 2: 309. https://doi.org/10.3390/buildings14020309
APA StyleFerranti, G., Greco, A., Pluchino, A., Rapisarda, A., & Scibilia, A. (2024). Seismic Vulnerability Assessment at an Urban Scale by Means of Machine Learning Techniques. Buildings, 14(2), 309. https://doi.org/10.3390/buildings14020309