

Predictive Modeling and Experimental Validation for Assessing the Mechanical Properties of Cementitious Composites Made with Silica Fume and Ground Granulated Blast Furnace Slag




Abstract
1. Introduction
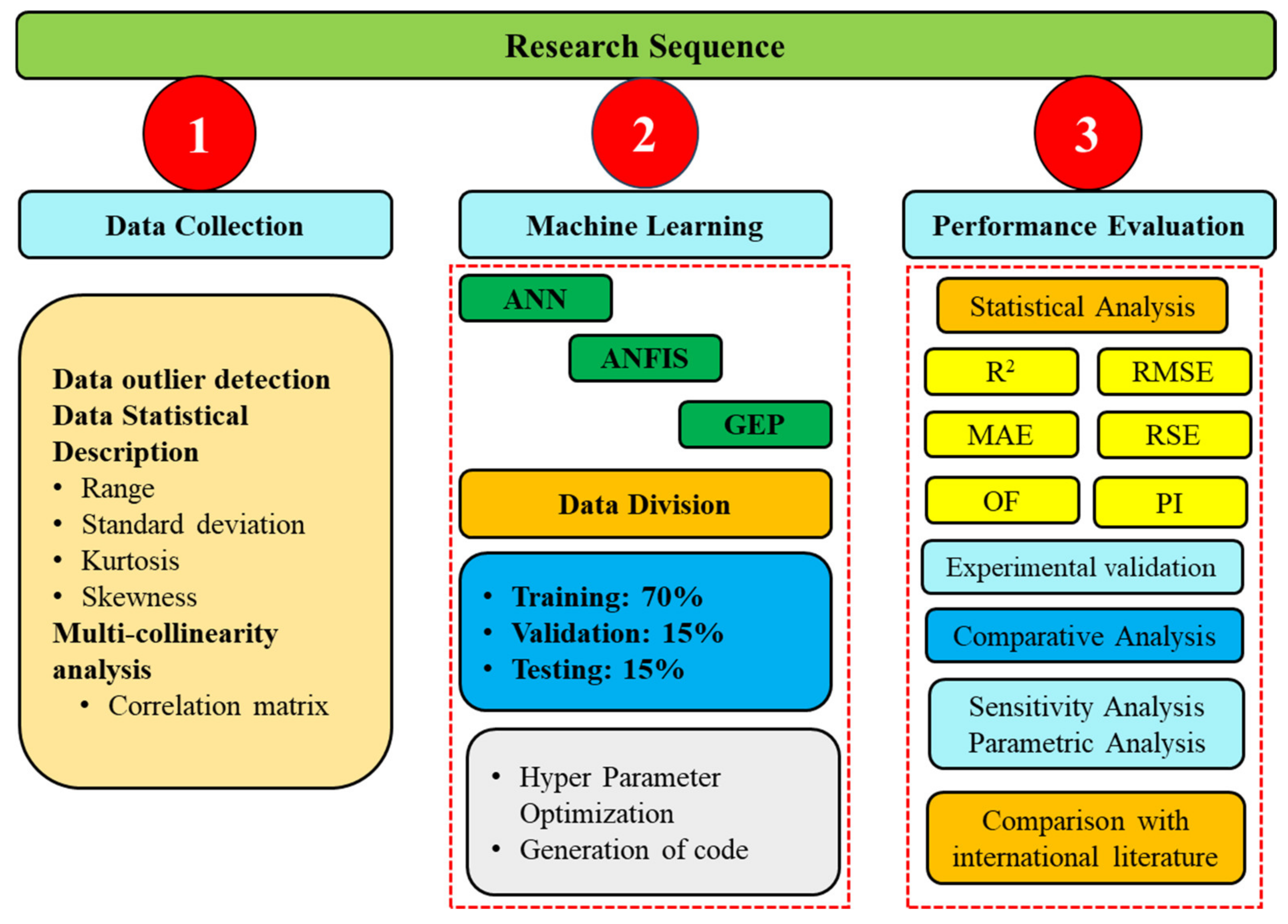
2. Research Methodology
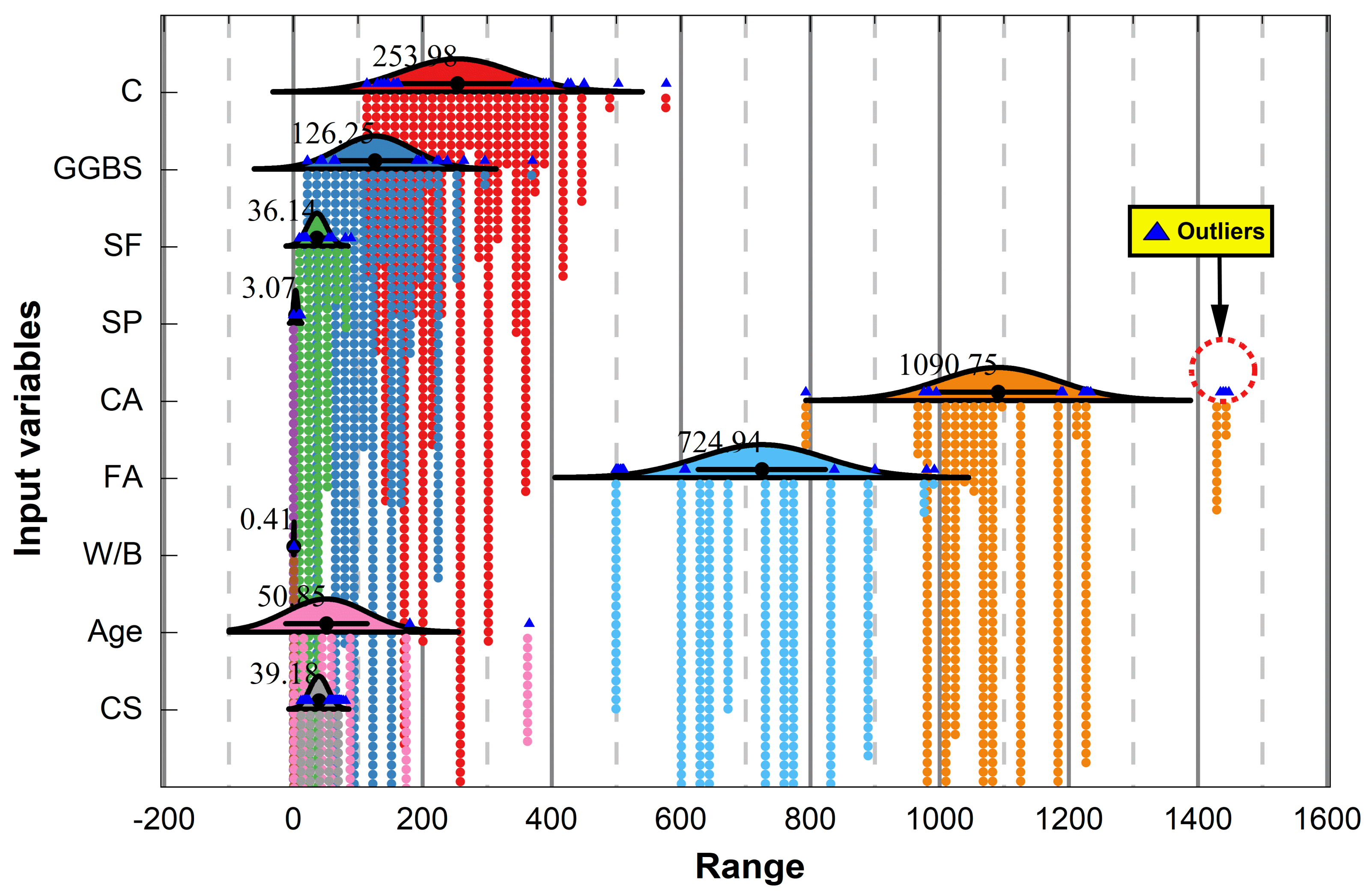
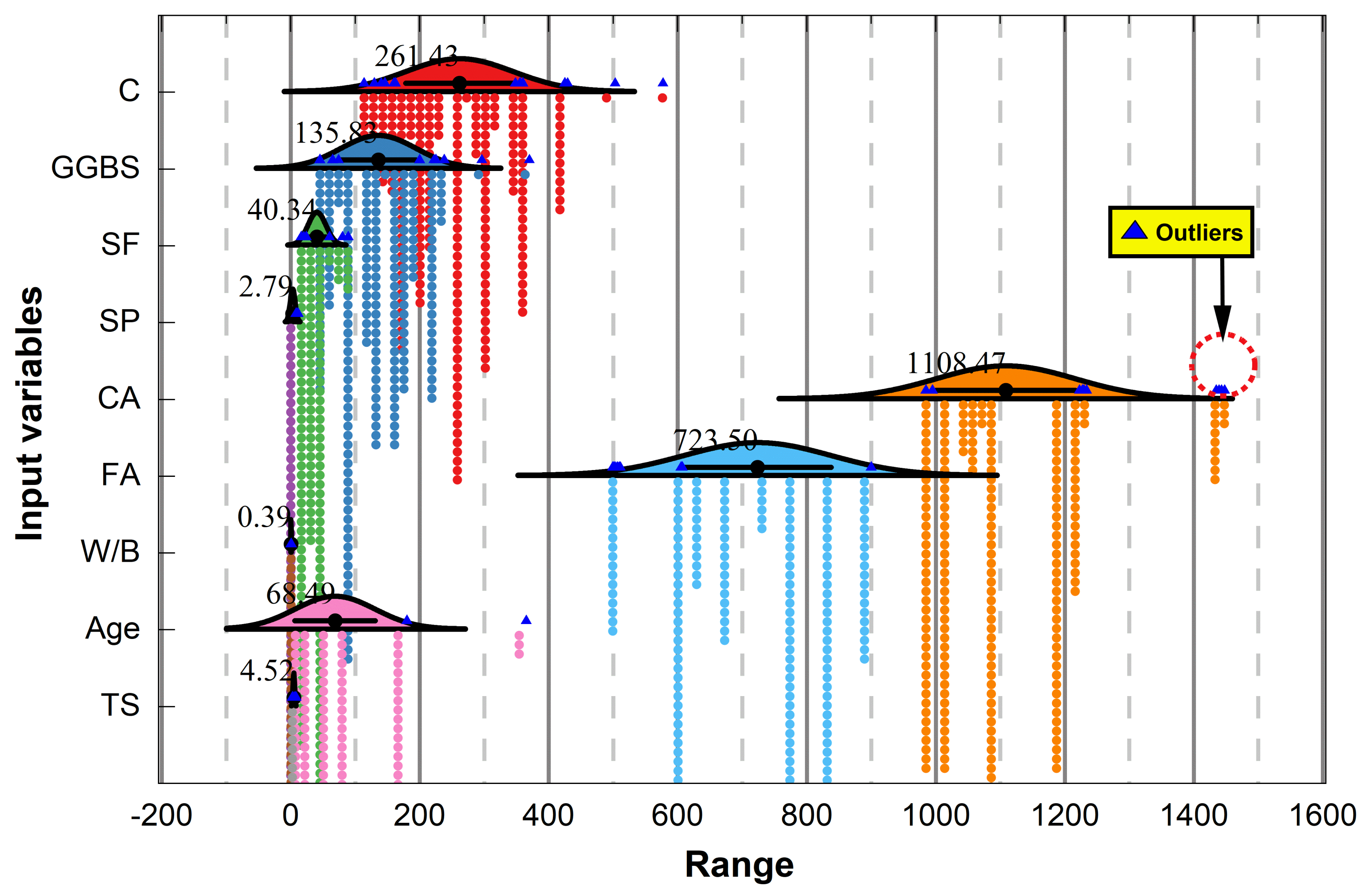
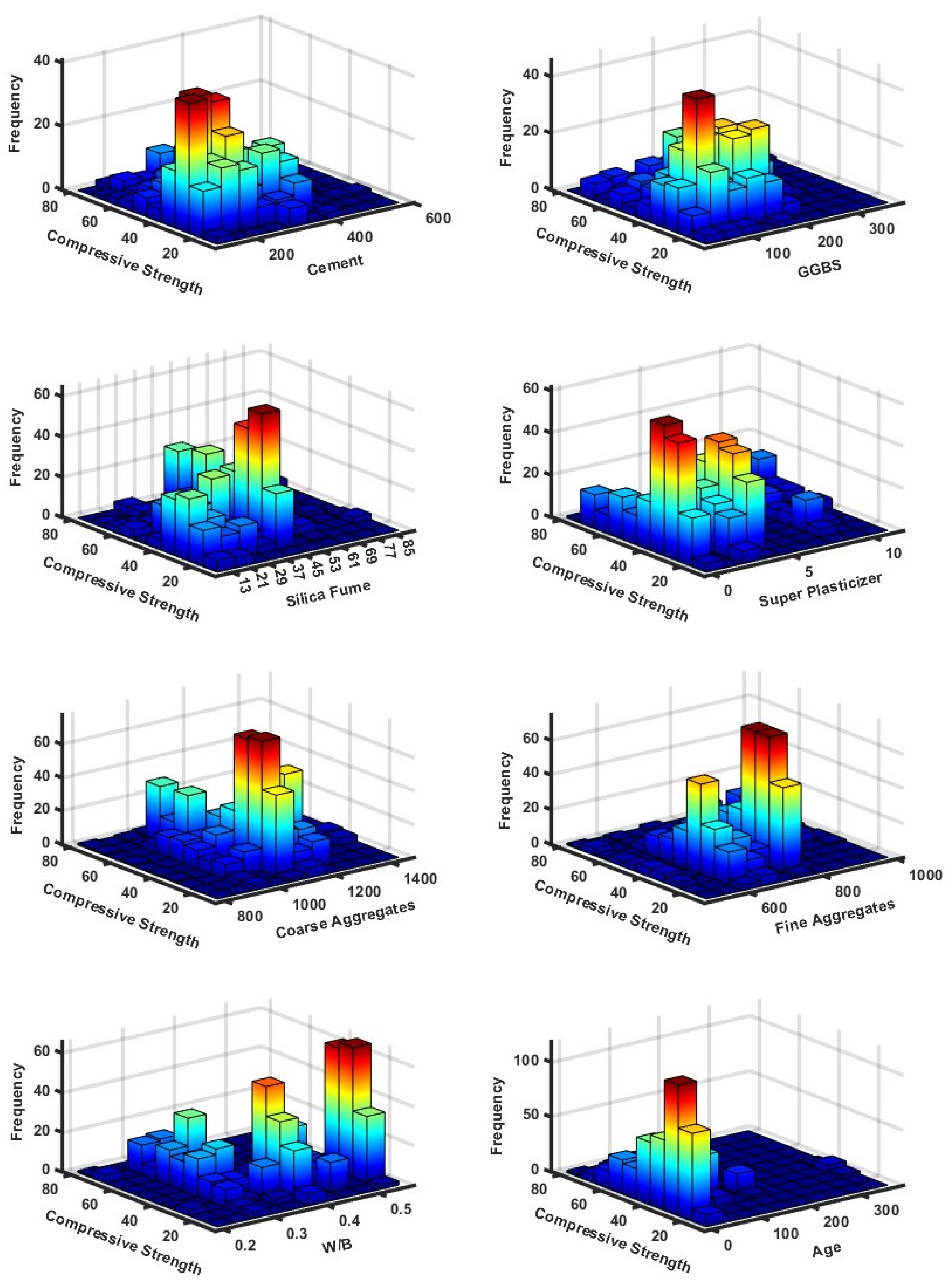
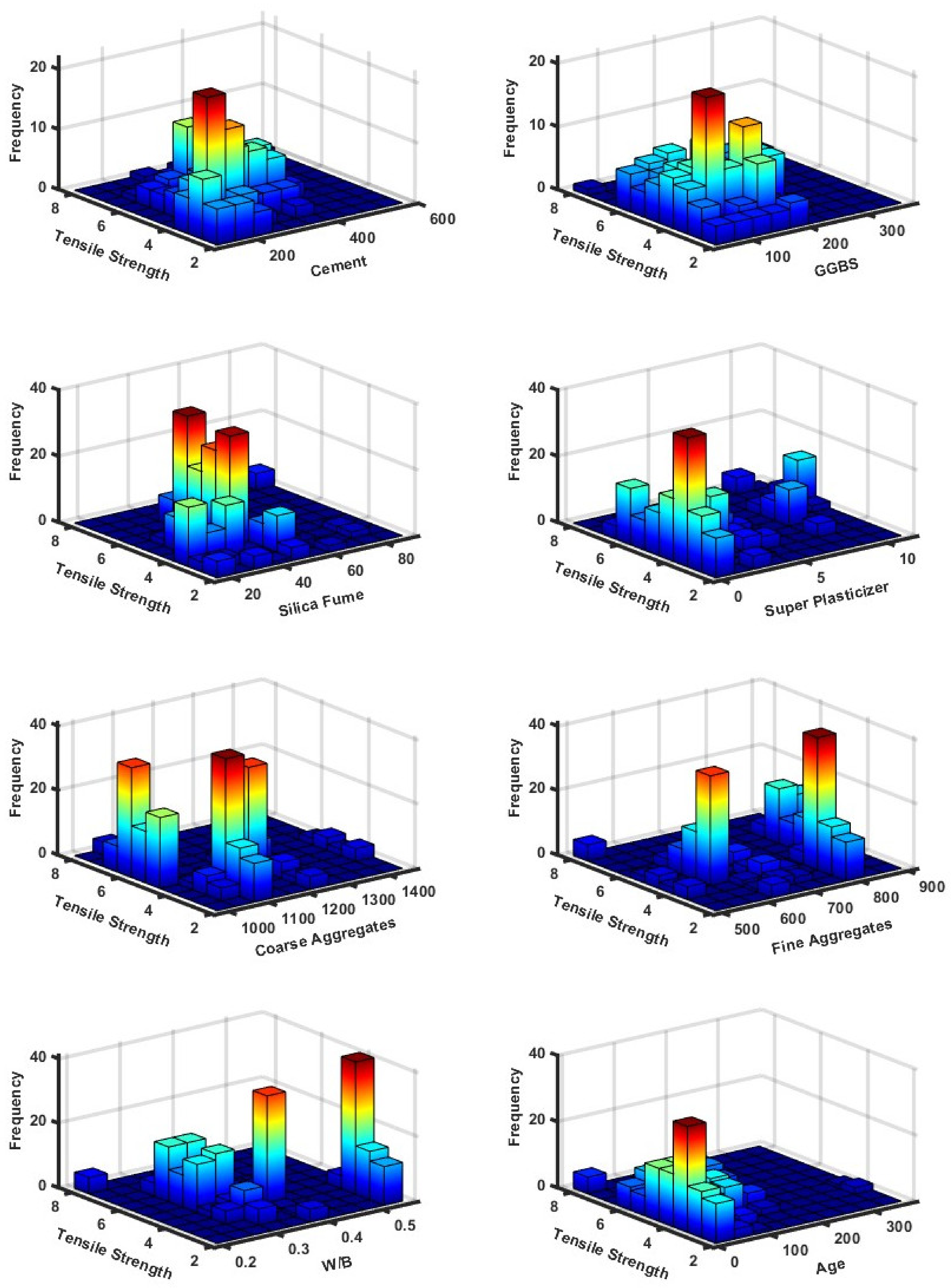
2.1. Data Collection
2.2. Overview of Soft Computing Techniques
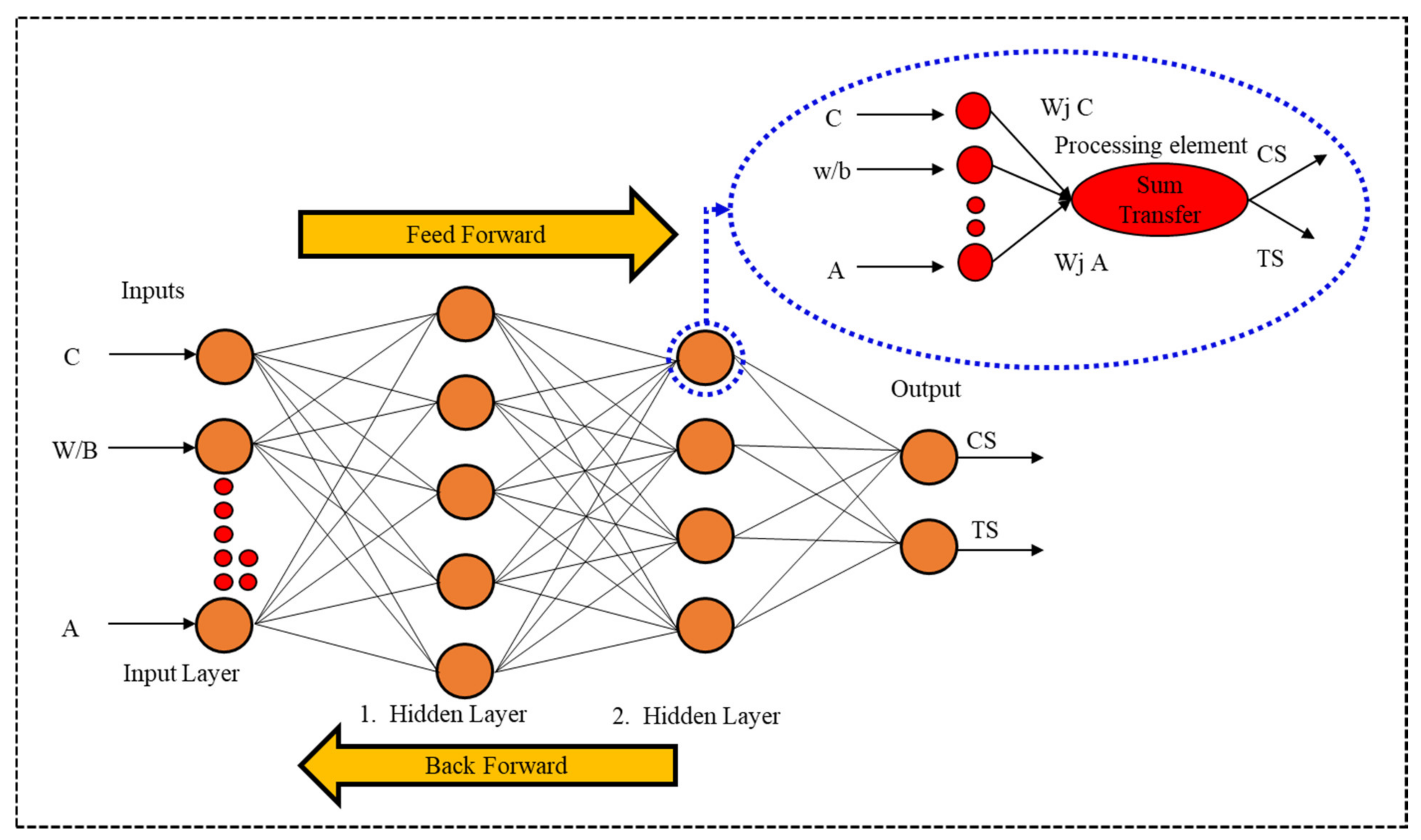
2.2.1. Artificial Neural Networks
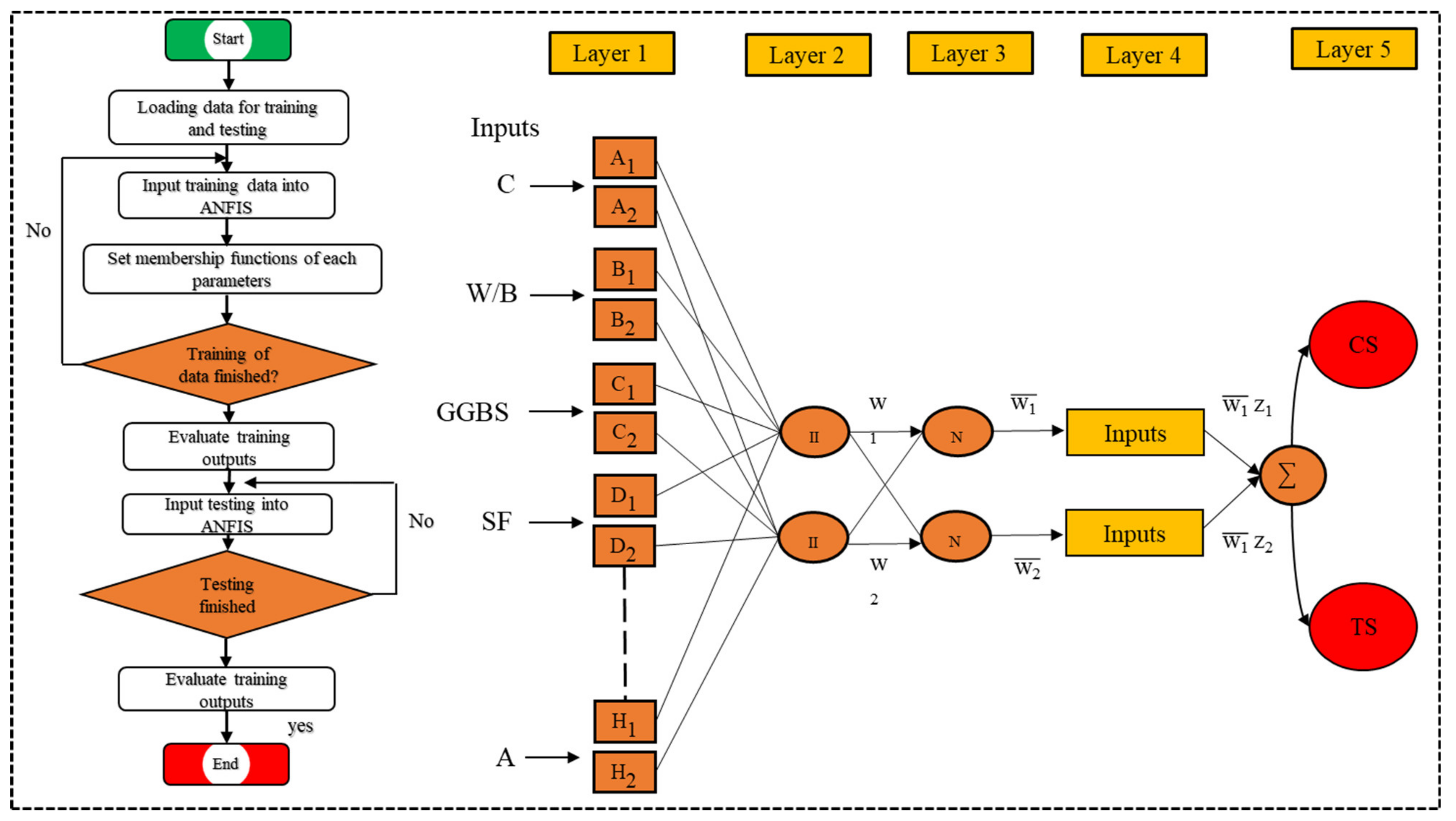
2.2.2. Adaptive Neuro-Fuzzy Inference System (ANFIS)
- An and Bn = fuzzy logic sets;
- Pn, qn, and rn = shape factors (estimated in the training phase);
- z1 and z2 = outputs (CS and TS).
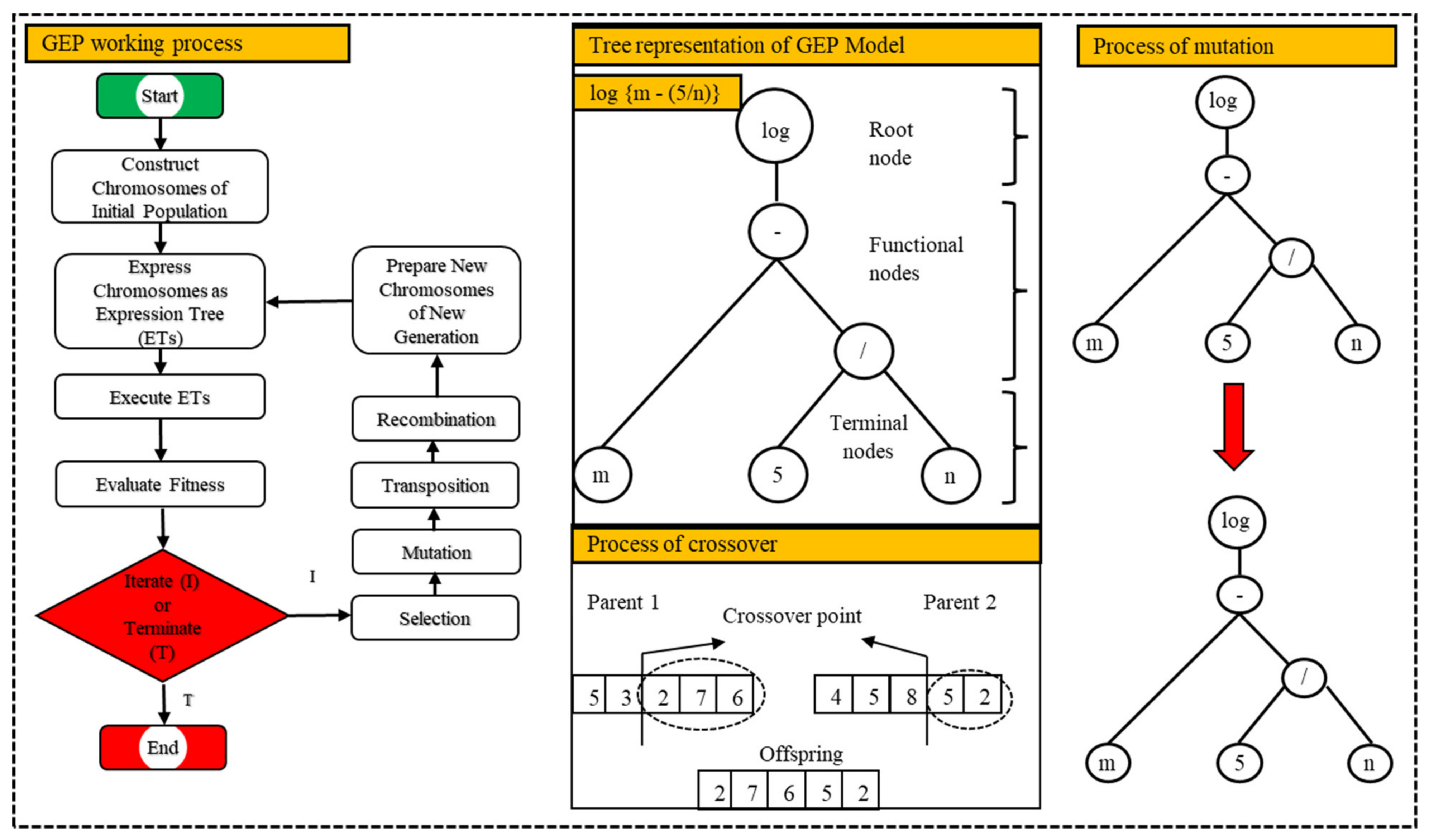
2.2.3. Gene Expression Programming (GEP)
2.3. Model Structures
2.4. Model Validation
2.4.1. Statistical Validation
2.4.2. Experimental Validation
Materials
Mix Design and Specimen Preparation
3. Results and Discussion
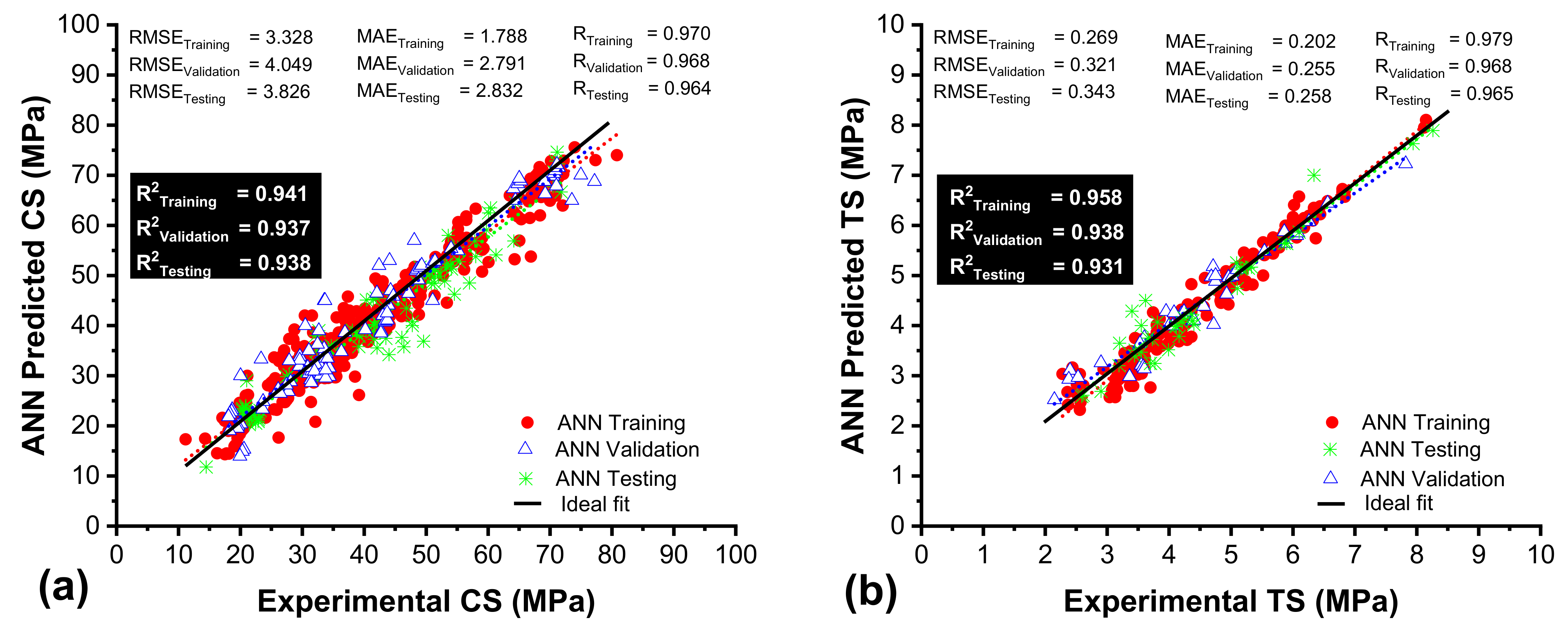
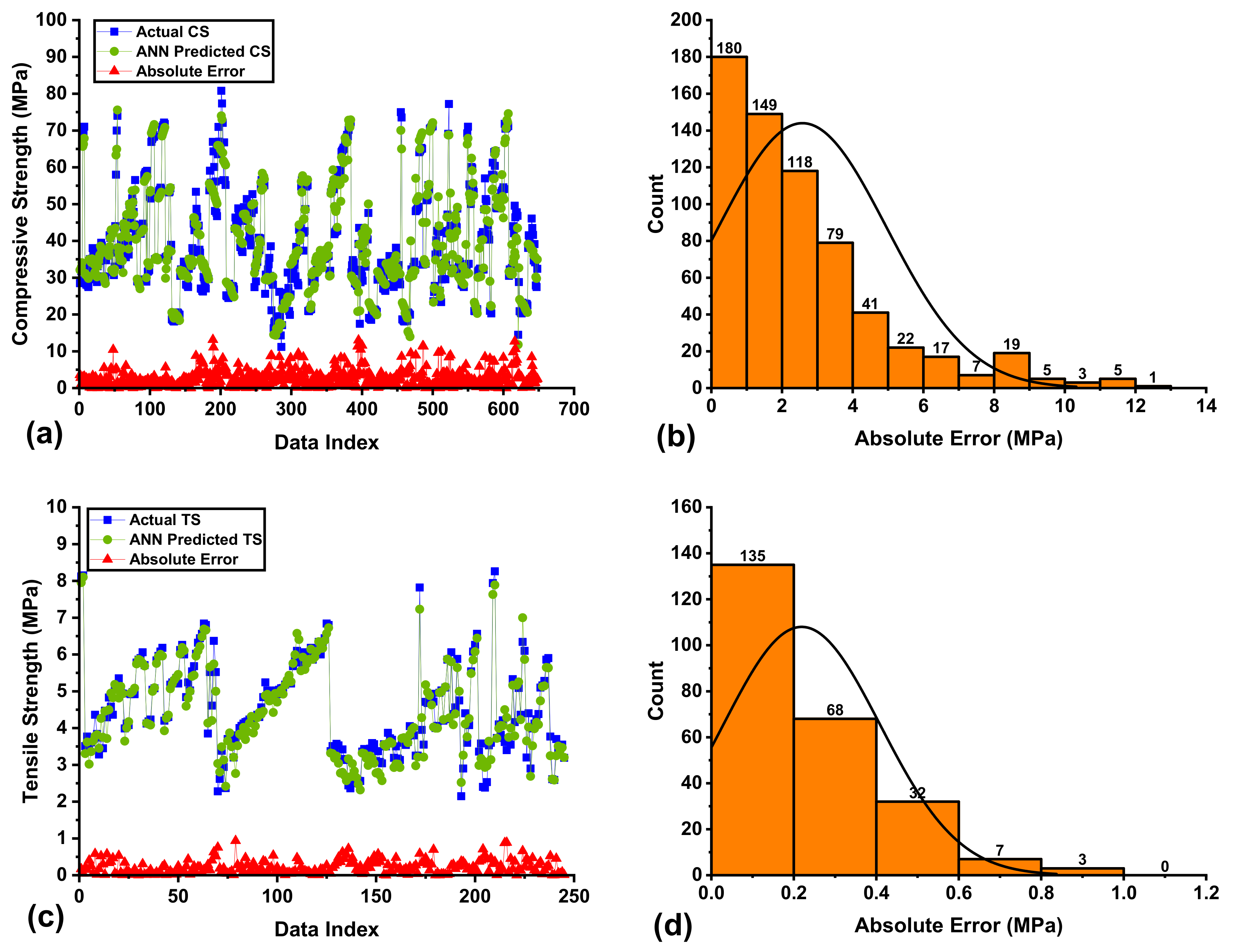
3.1. Performance Assessment of ANN Models
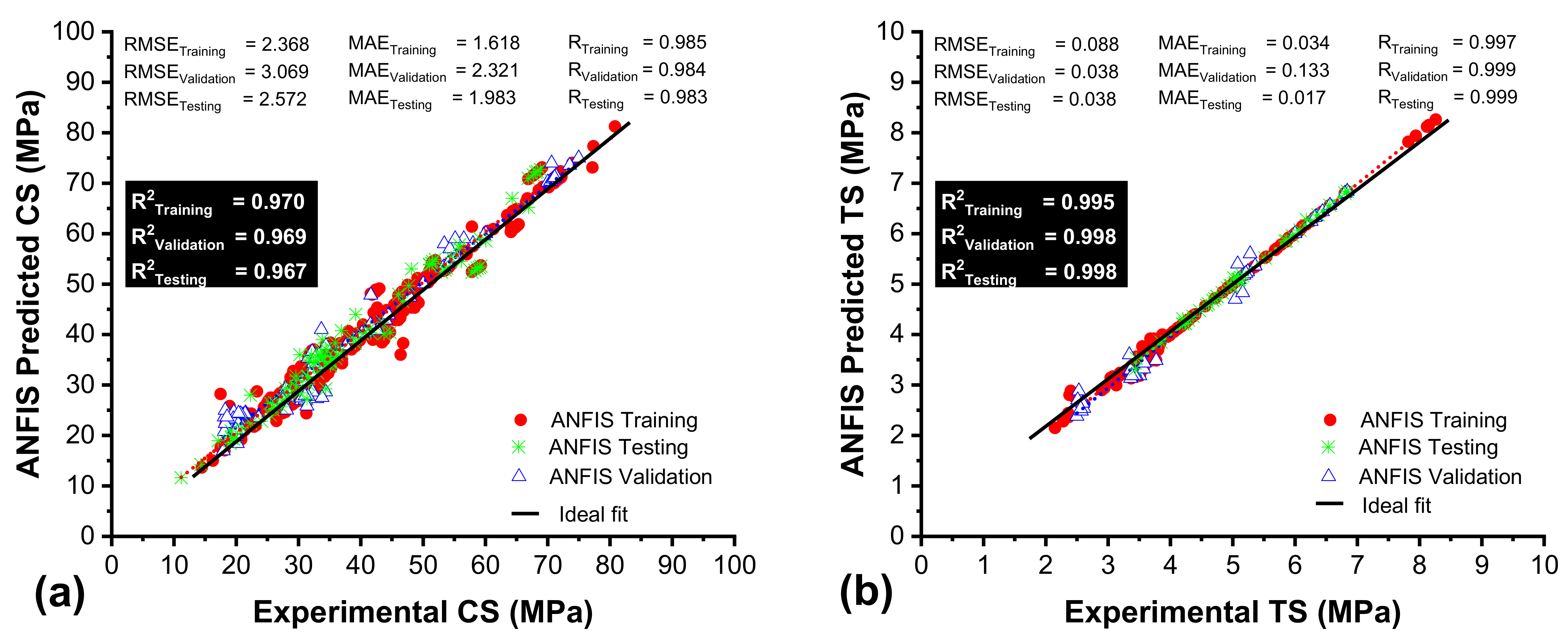
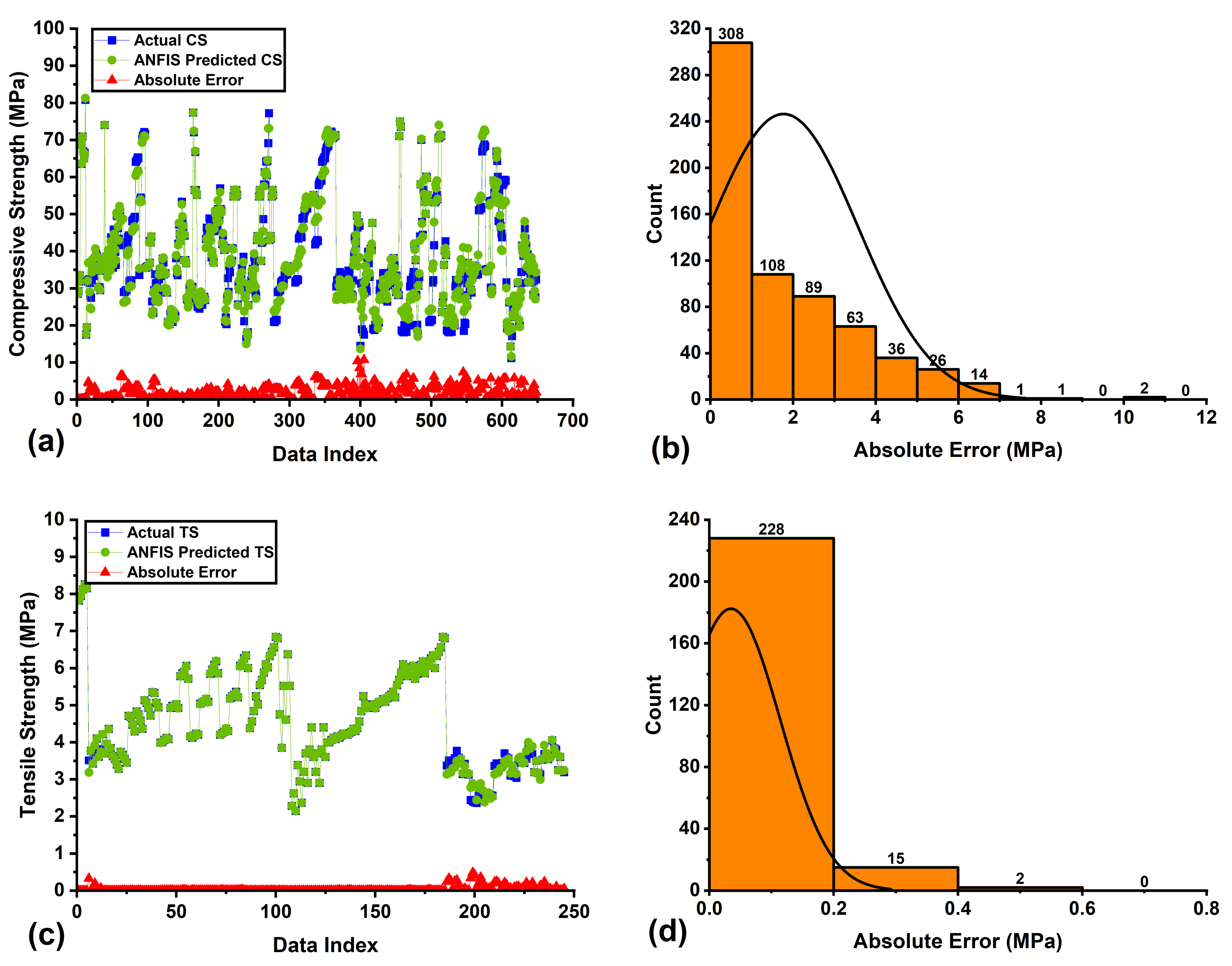
3.2. Performance Assessment of ANFIS Models
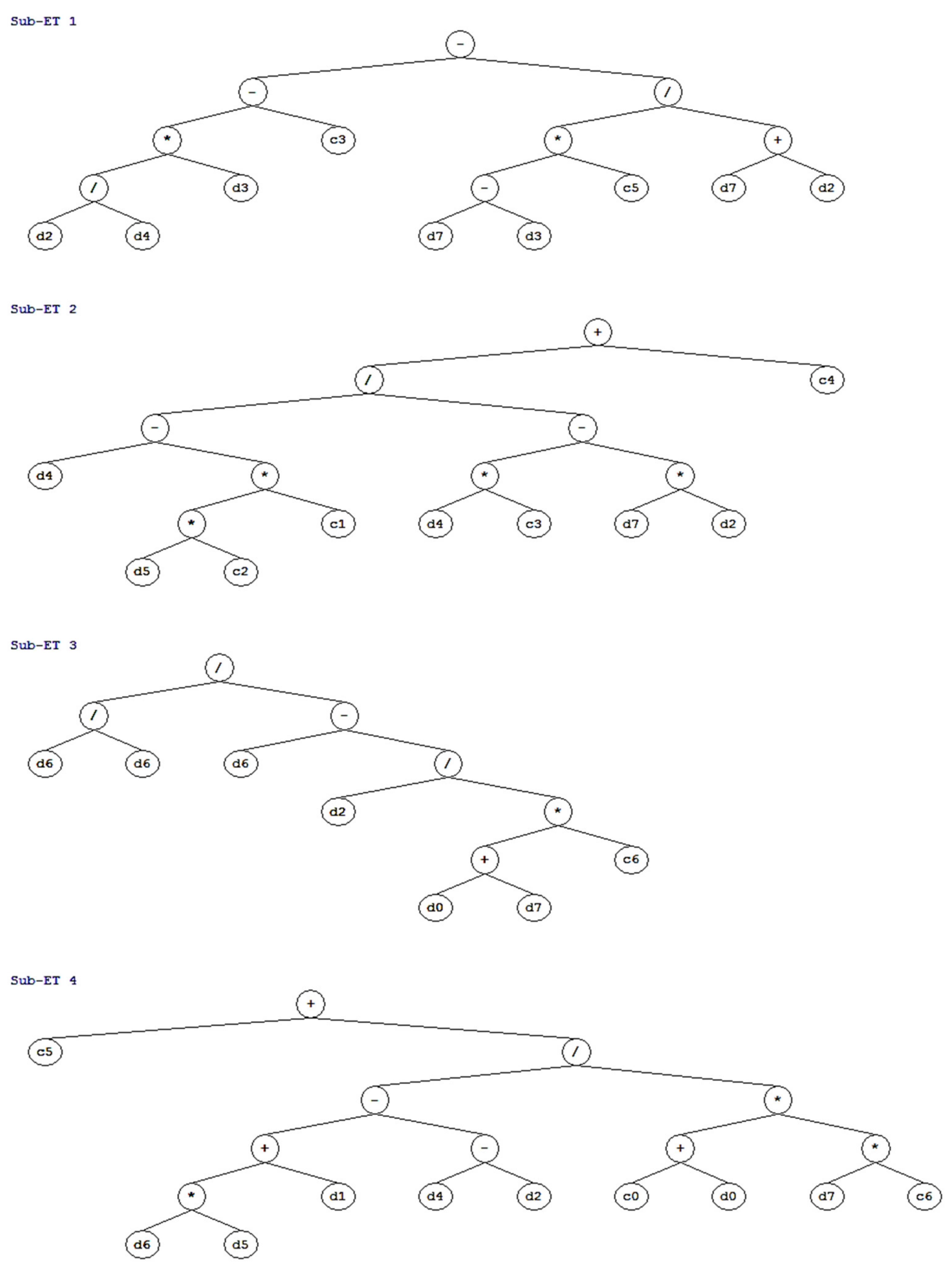
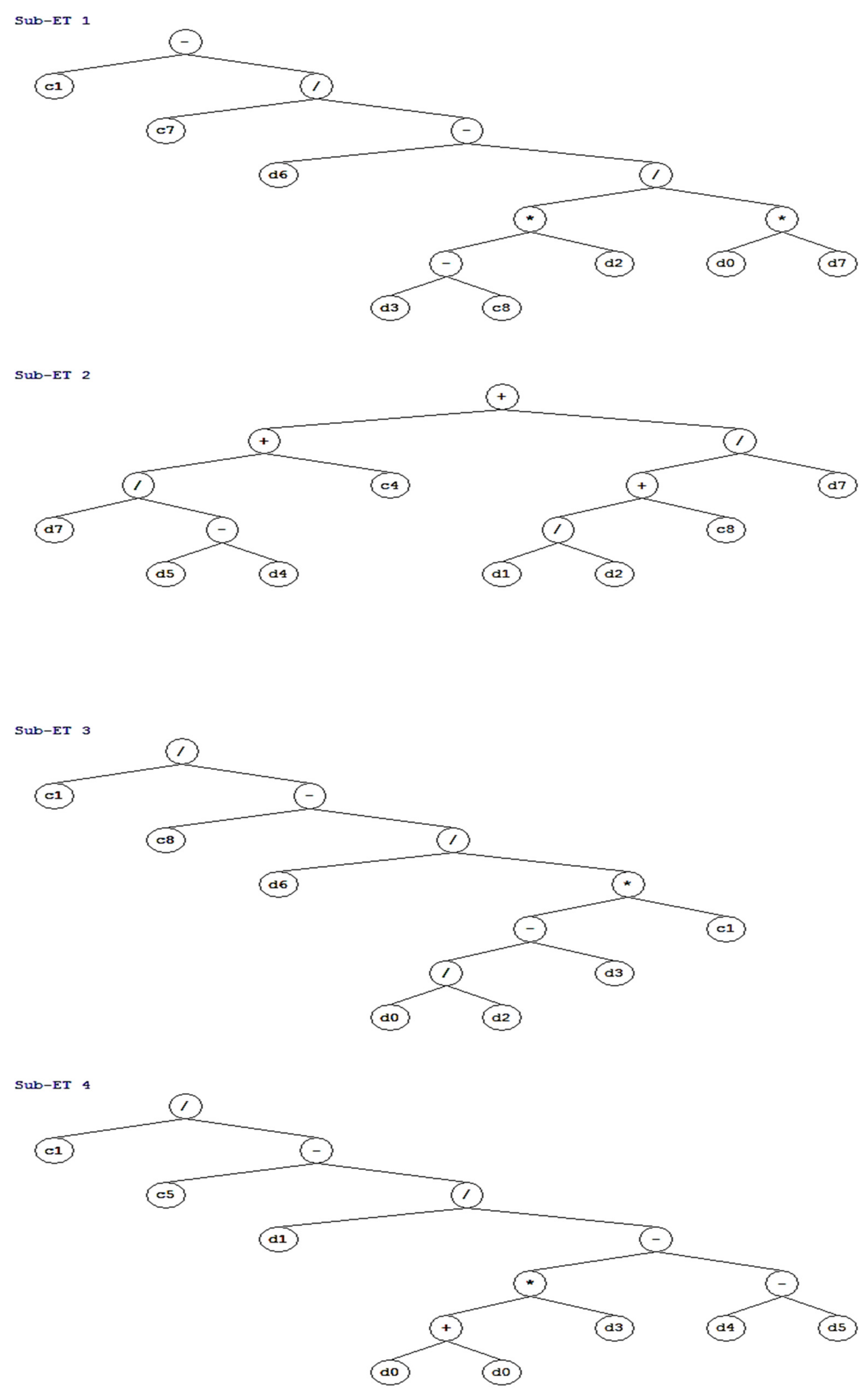
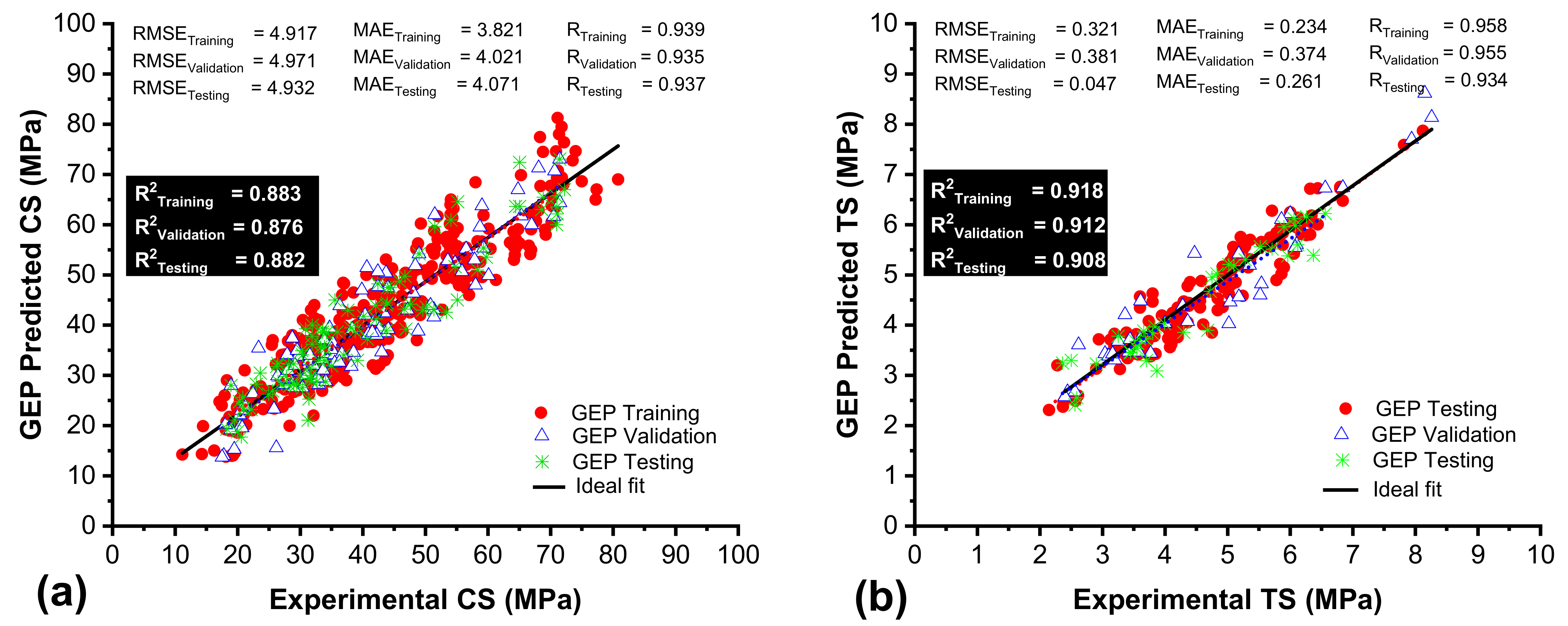
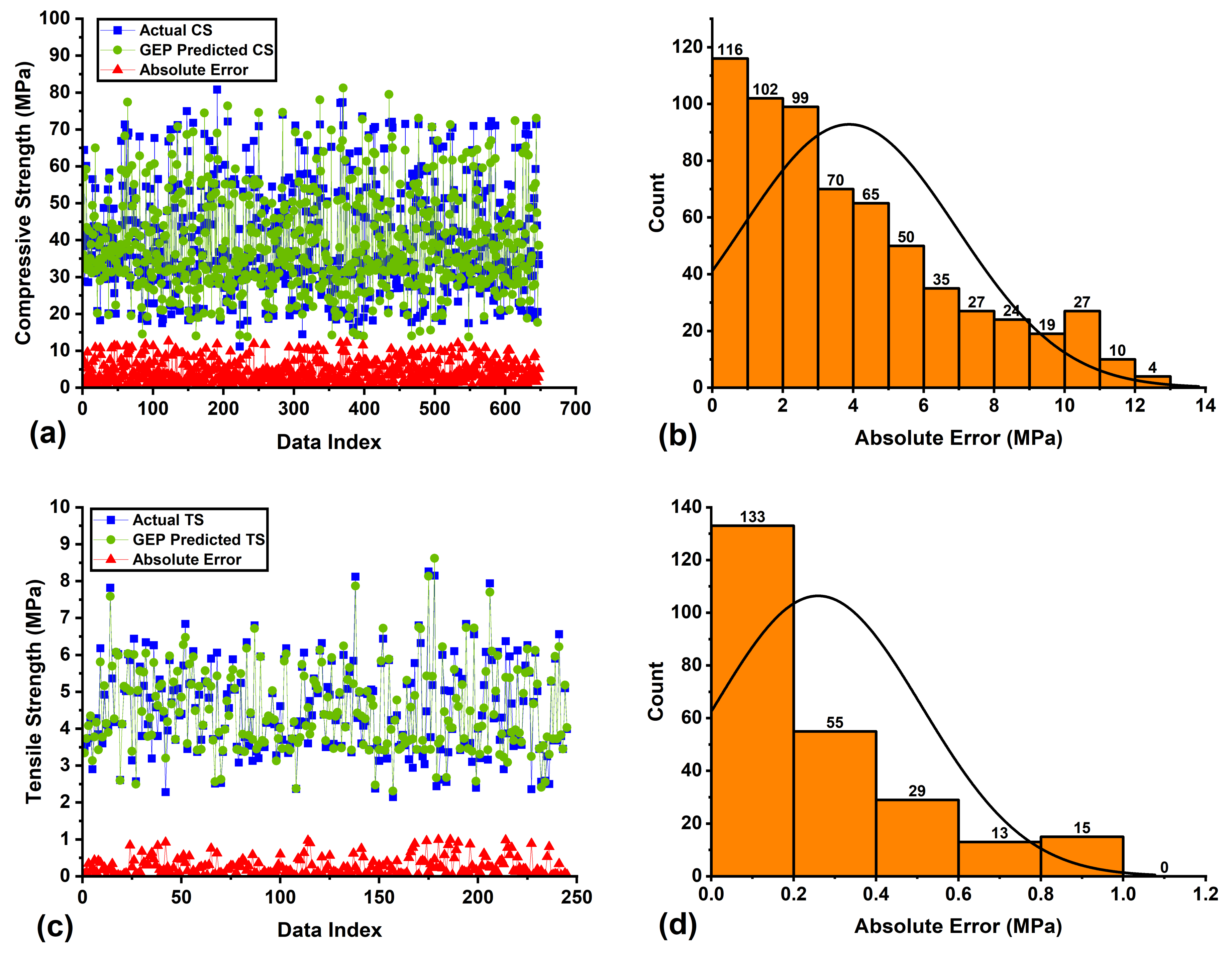
3.3. GEP Model Development and Performance Assessment
3.4. Experimental Validation
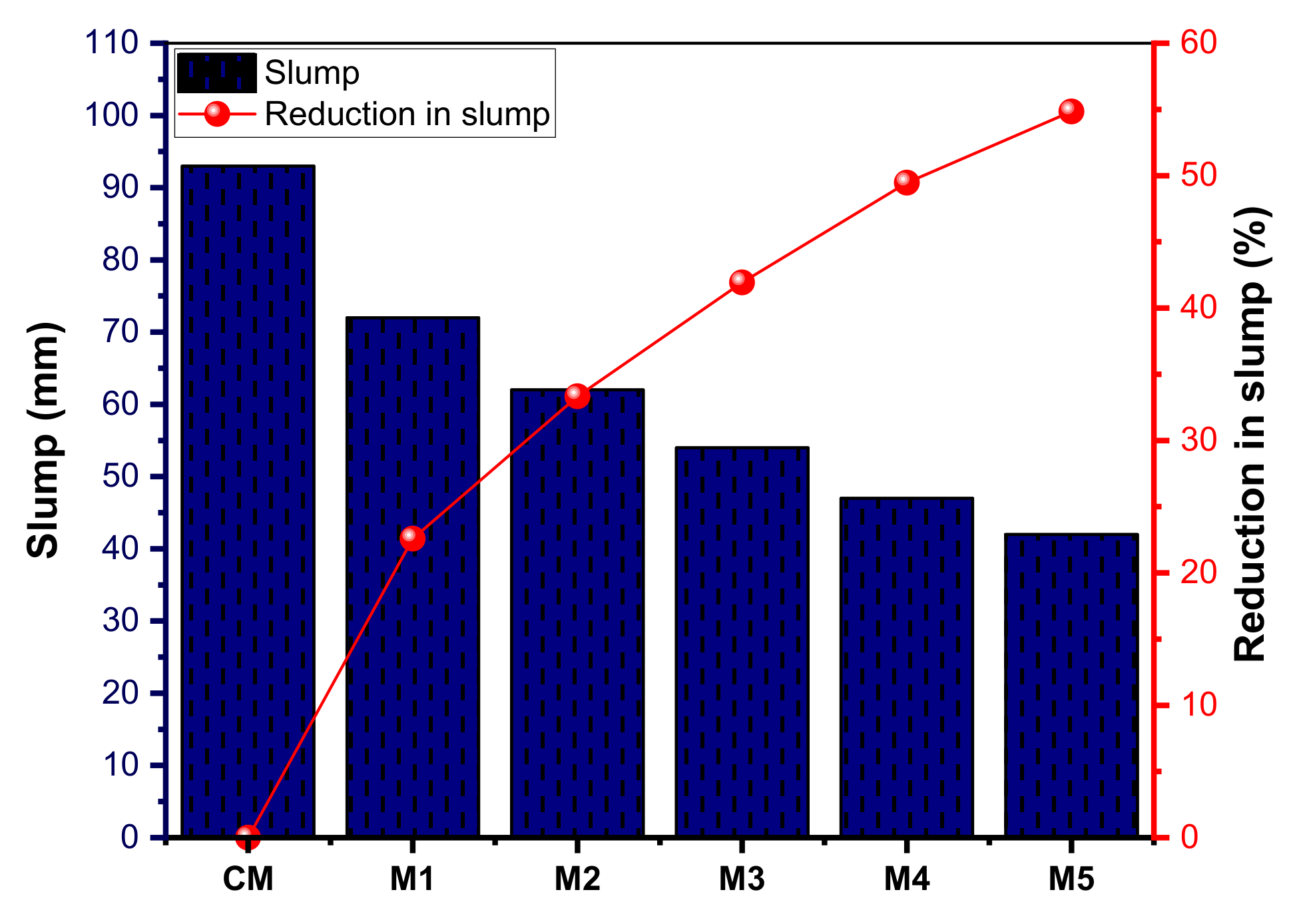
3.4.1. Workability
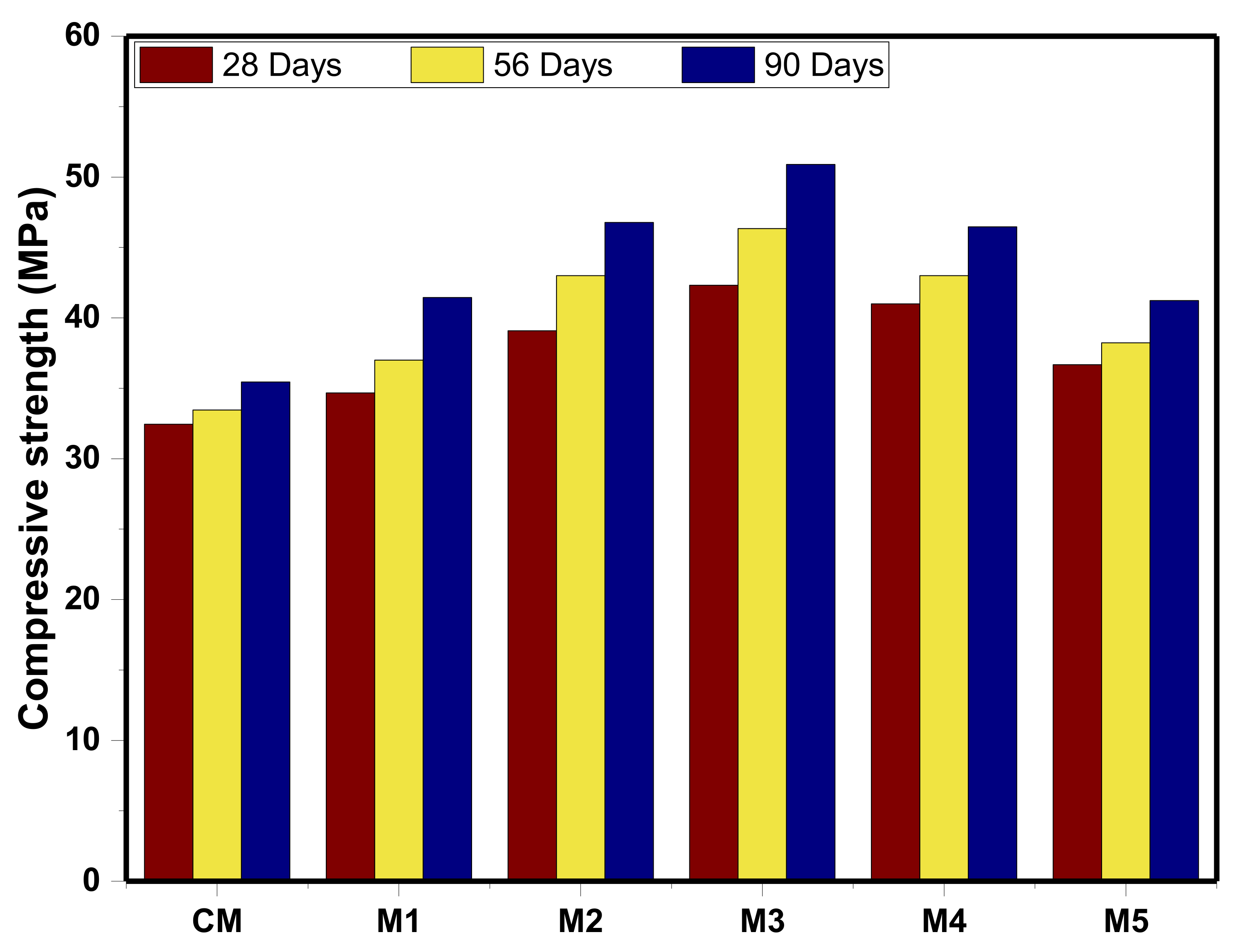
3.4.2. Compressive Strength
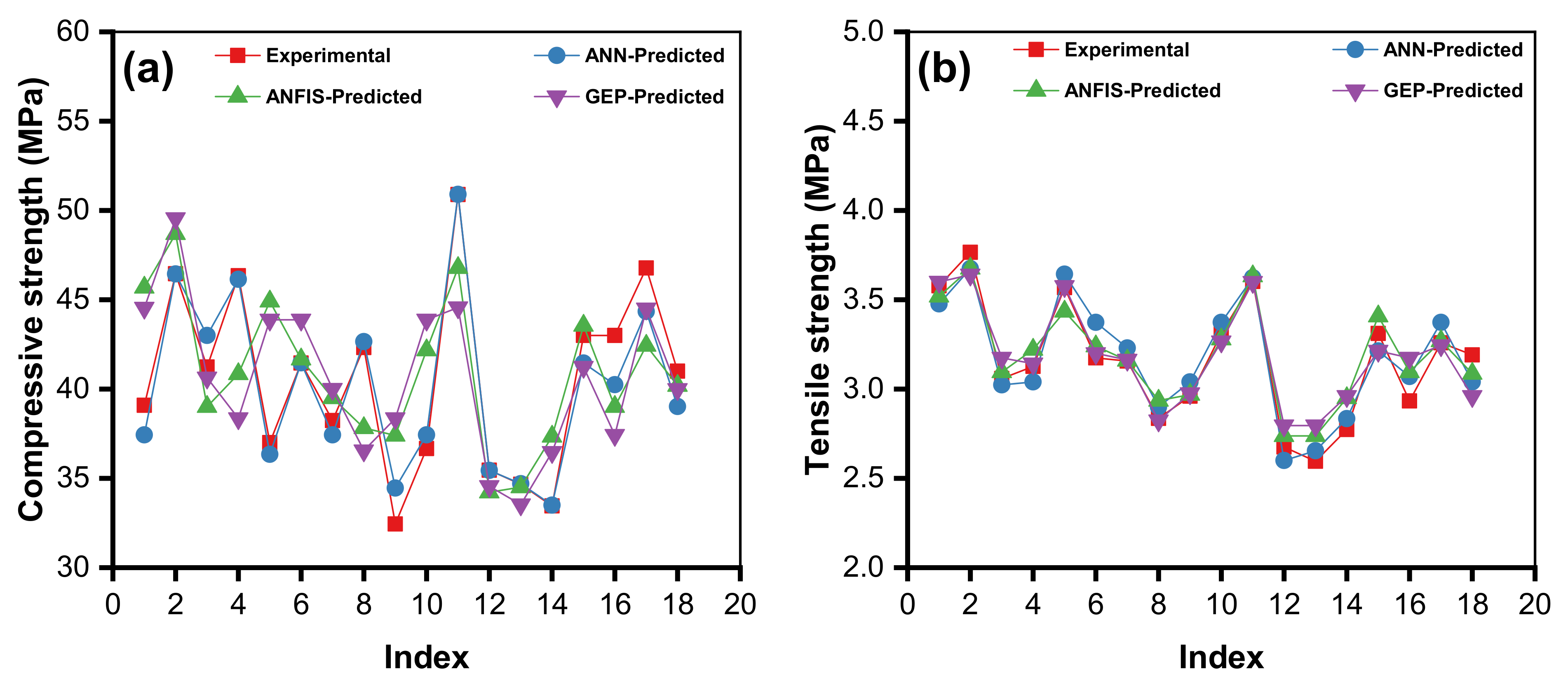
3.4.3. Comparison of Experimental Results with Proposed Models
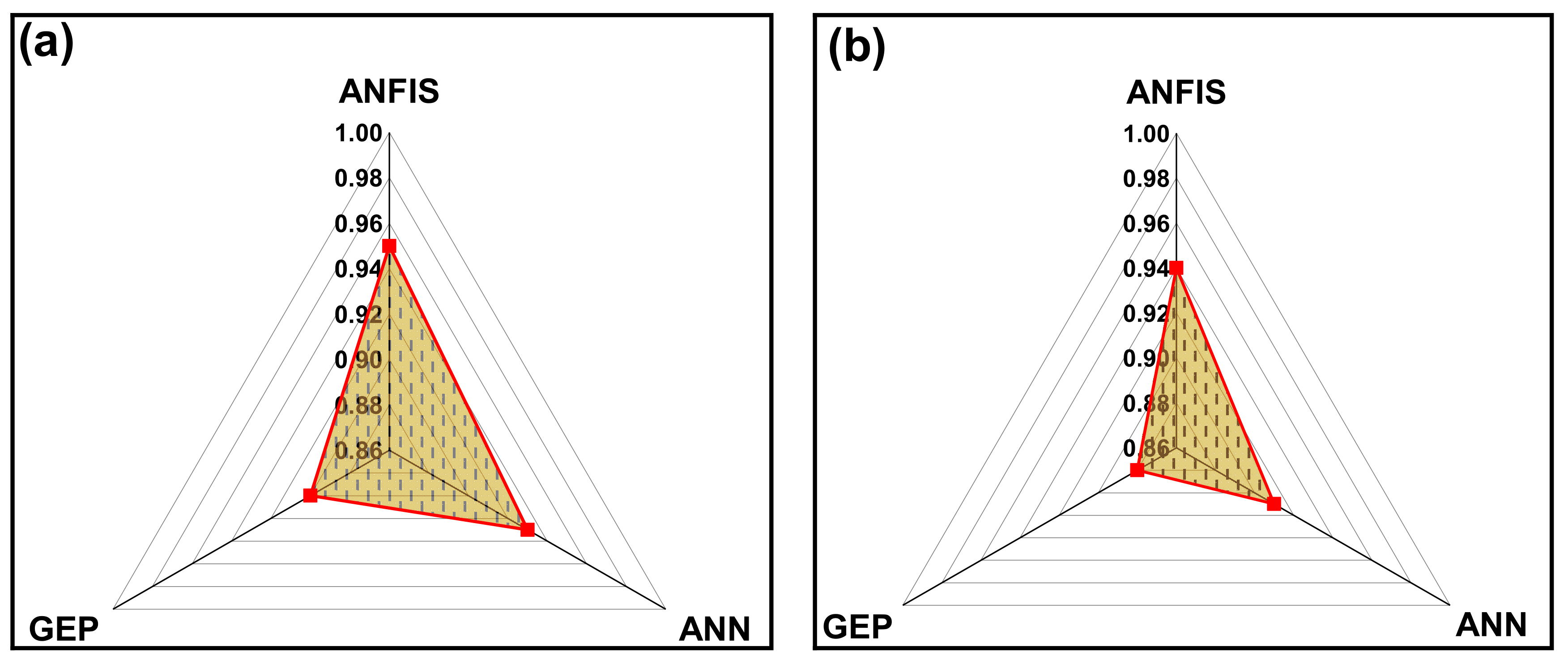
3.5. Statistical Evaluation and Comparative Analysis of Models
3.6. Validation of GEP-Based Equations
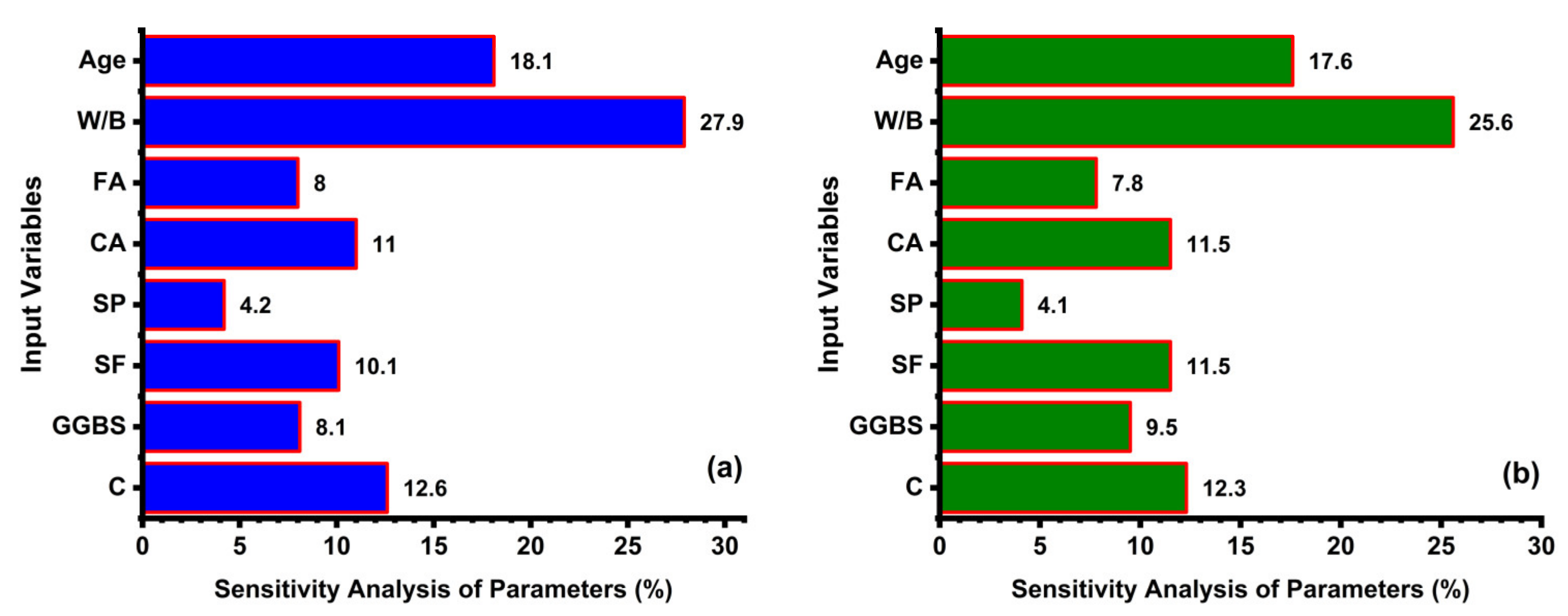
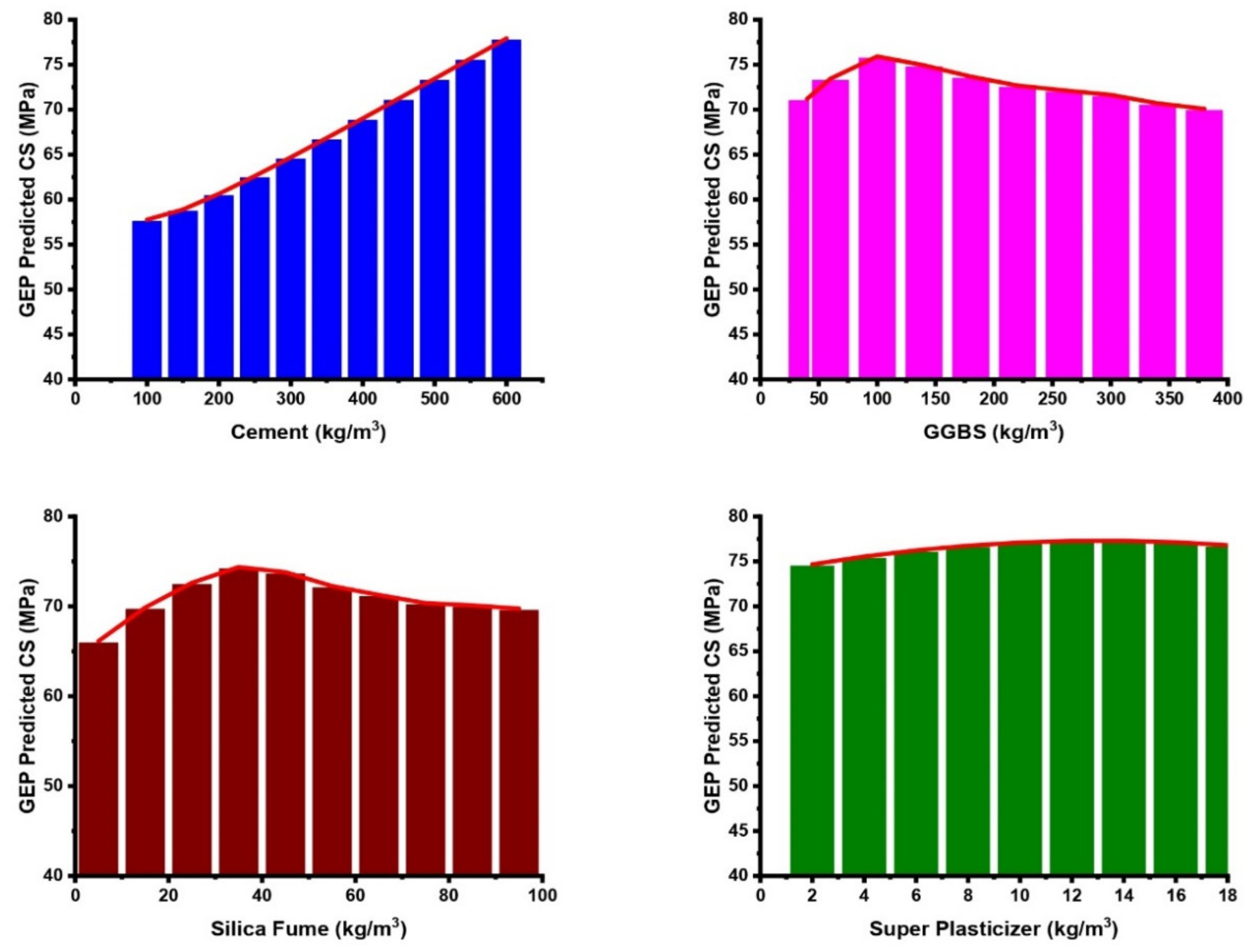
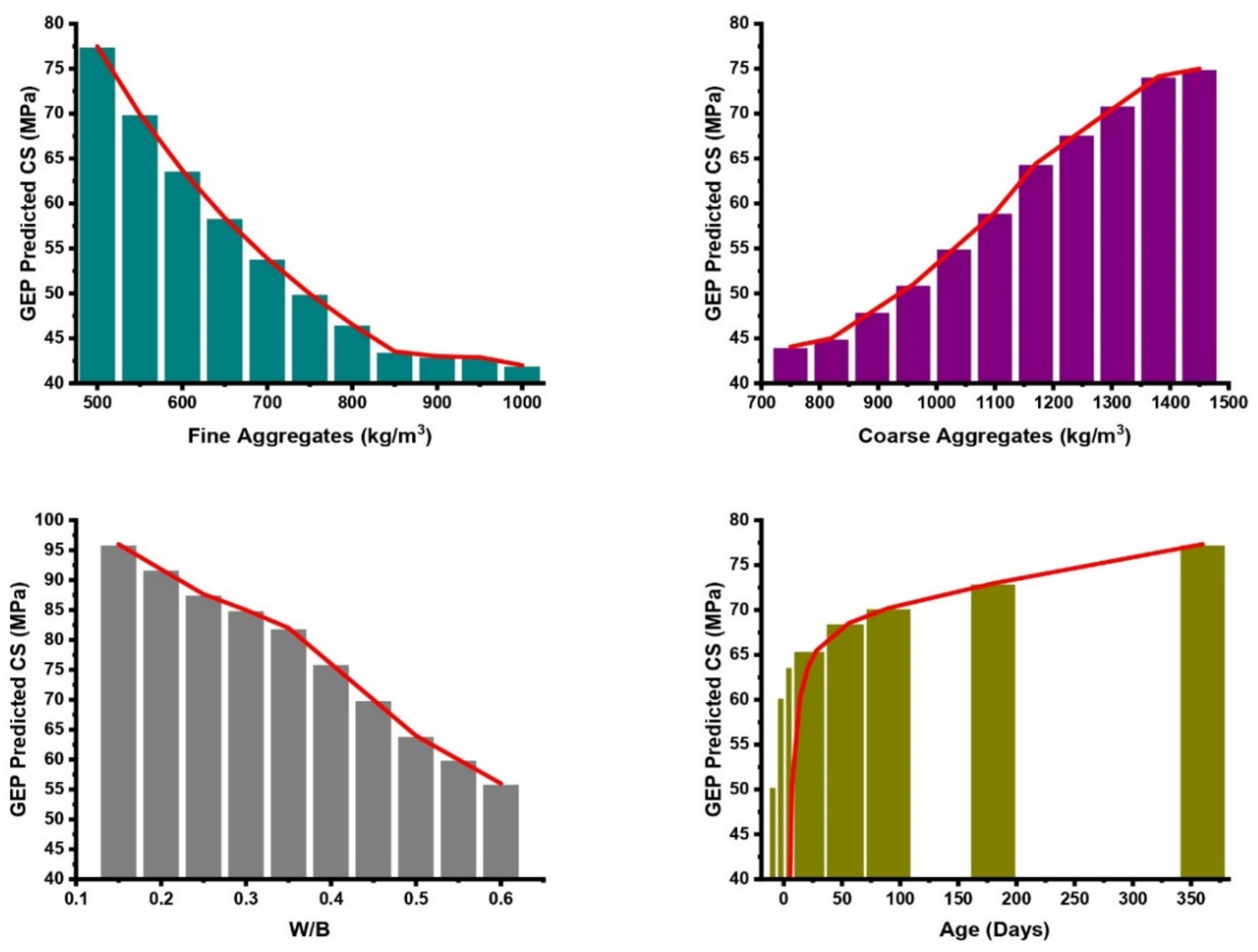
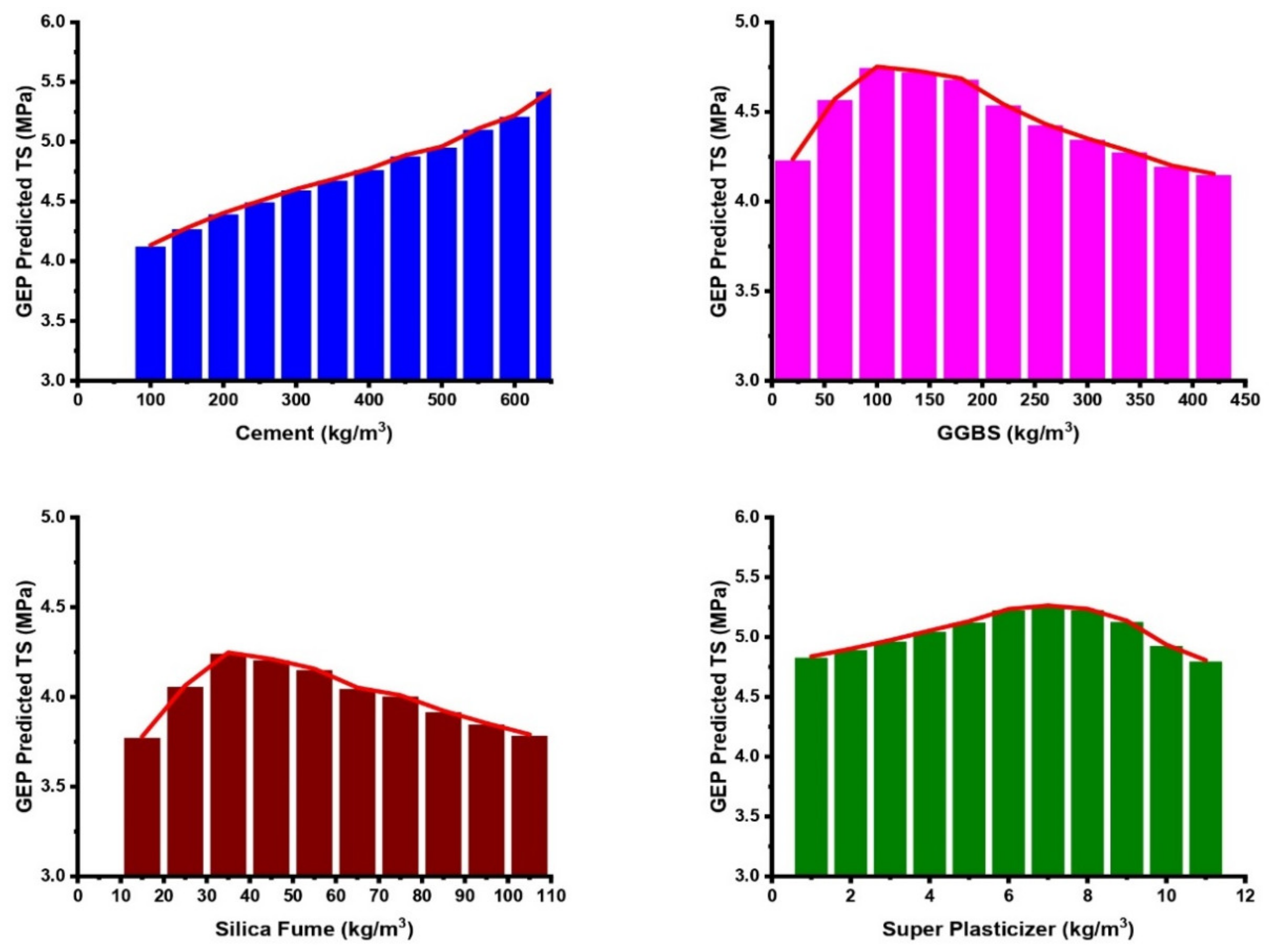
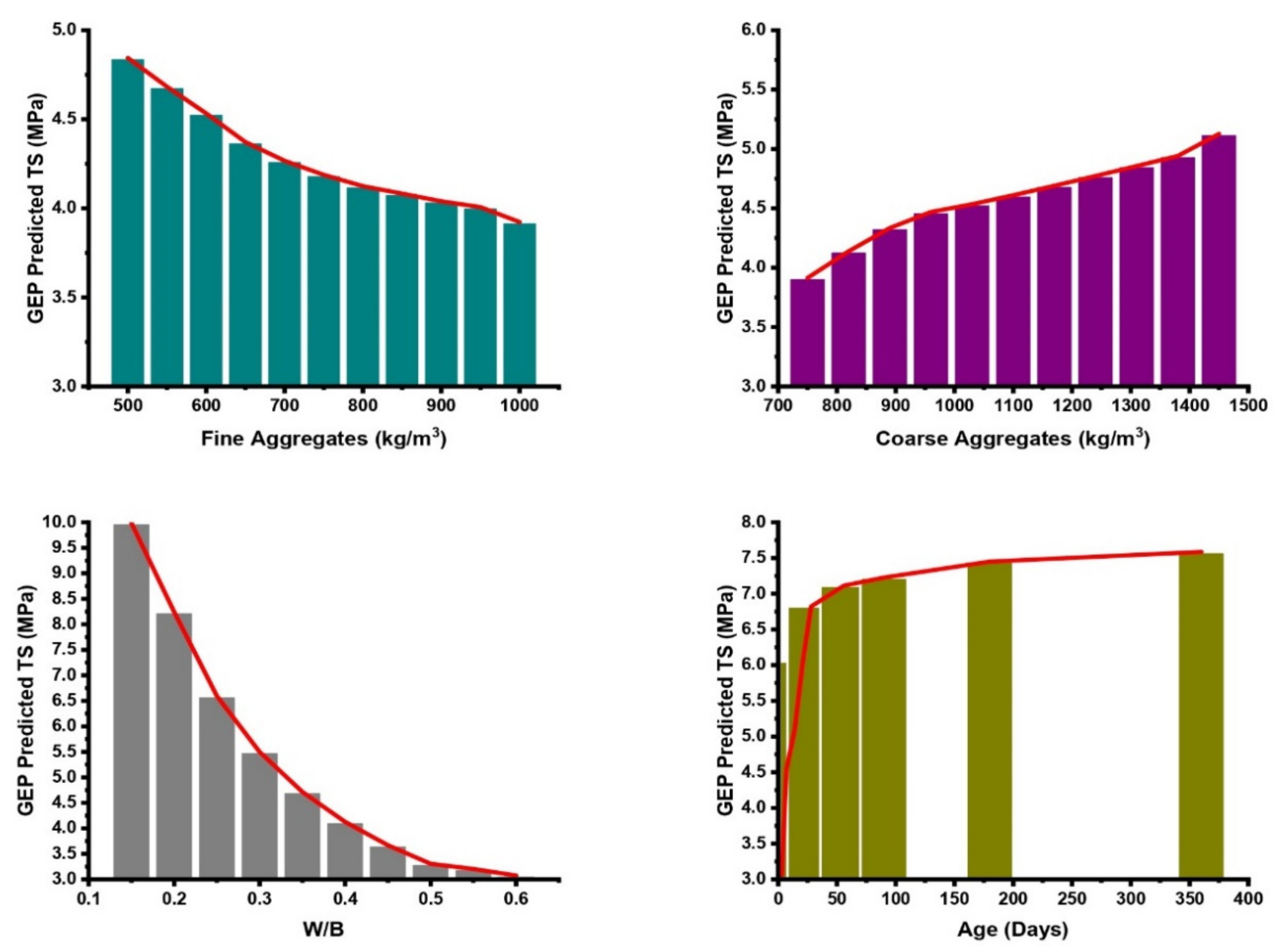
3.7. Sensitivity and Parametric Analyses
4. Conclusions
- (a)
- The statistical analysis indicated that in all developed models (ANN, ANFIS, and GEP), the projected values are very near to actual values for both the CS and TS models.
- (b)
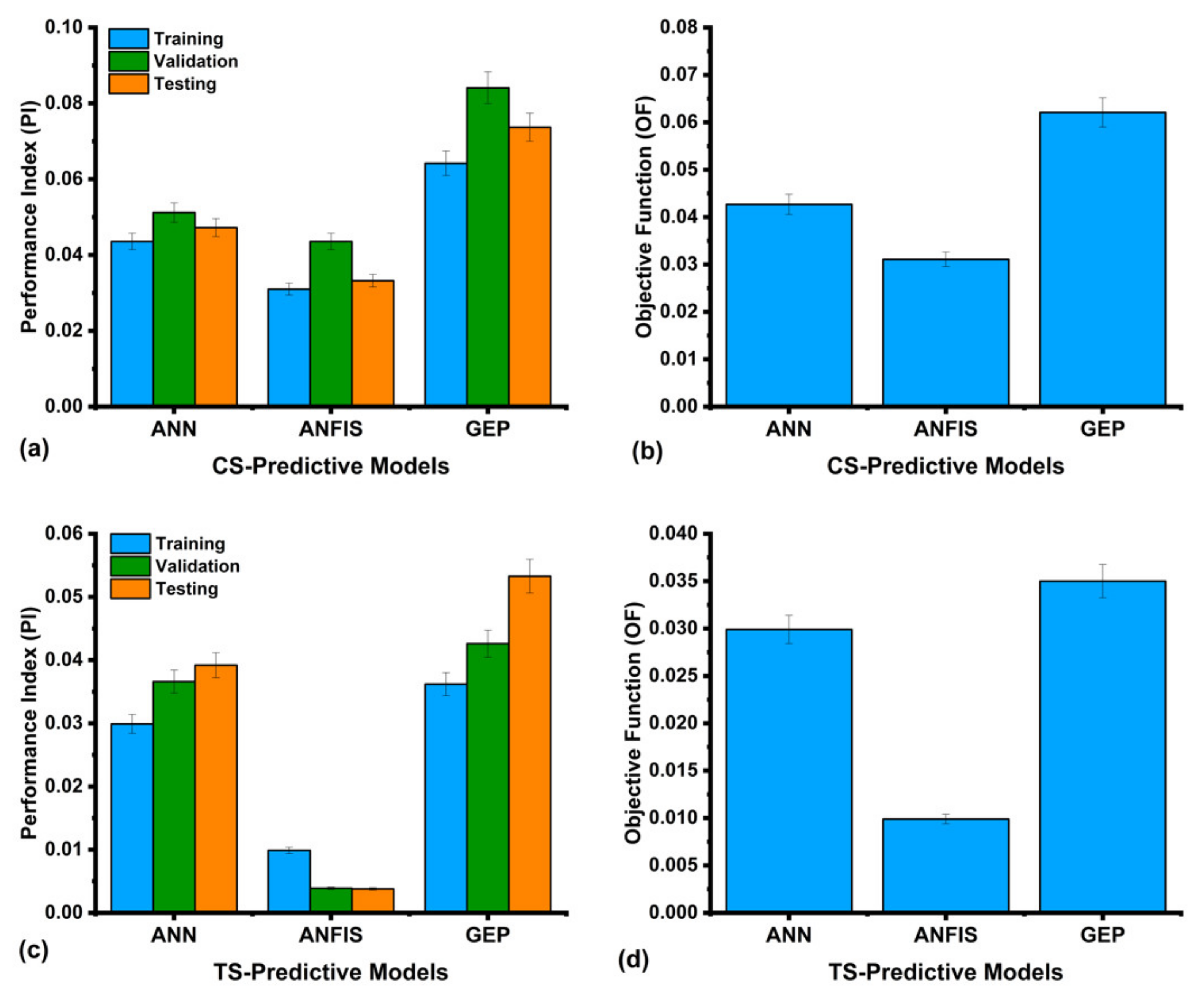
- The performance index of the ANN, ANFIS, and GEP models created for CS and TS is less than 0.15, indicating that these models are classified as excellent. Furthermore, it can be noted that the OF values obtained from the ANN, ANFIS, and GEP models for CS are 0.042, 0.031, and 0.062, respectively, and for the TS models, these values are 0.029, 0.009, and 0.035, respectively. The OF values for all cases are close to zero, demonstrating the validity of the proposed models while controlling the overfitting.
- (c)
- The comparative analysis showed that ANFIS models exhibit higher predictive performance compared to ANN and GEP models. The mean R2 values of all three testing conditions (training, testing, and validation) for the CS models are 0.988 (ANFIS), 0.944 (ANN), and 0.887 (GEP), whereas these are 0.998 (ANFIS), 0.954 (ANN), and 0.903 (GEP) for the TS models.
- (d)
- Based on the MAE values, the ANFIS models showed enhanced performance by 29% and 48%, as compared to the CS models of ANN and GEP, respectively, whereas the ANFIS models for TS showed better predictive performance by 35% and 49% compared to the ANN and GEP models. However, the GEP models showed superior performance compared to the ANFIS and ANNs with respect to the closeness of the statistical measure values between the training, validation, and testing sets for both the CS and TS models.
- (e)
- GEP is an evolutionary technique that also gives a simple empirical formula for forecasting the CS and TS. This approach significantly diminishes the overall time needed to estimate CS and TS compared with conventional testing procedures, i.e., the evaluation process can be completed at a significantly faster rate. Therefore, the application of the presented equations gives a viable and quick method for the estimation of the CS and TS of concrete containing SF and GGBS.
- (f)
- External validation based on experimental investigations showed strong evidence for the applicability of the proposed models, with an R2 of 0.88 and error percentages of less than 10%.
- (g)
- The sensitivity analysis revealed the significance of the input variables to be in the following increasing trend: W/B (27.9%) > age (18.1%) > C (12.6%) > CA (11%) > SF (10.1%) > GGBS (8.1%) > FA (8%) > SP (4.2%) for the CS models, whereas this was W/B (25.6%) > age (17.6%) > C (12.3%) > CA (11.5%) > SF (11.5%) > GGBS (9.5%) > FA (7.8%) > SP (4.1%) in the case of the TS models. These findings are highly comparable with the actual database. The parametric study showed that all of the input variables consistently follow the trend mentioned in the experimental database.
- (h)
- The developed models successfully fulfilled various criteria that were considered for their external validation.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CS | Compressive strength |
| TS | Tensile strength |
| SCMs | Secondary cementitious raw materials |
| GGBS | Ground granulated blast furnace slag |
| ML | Machine learning |
| SF | Silica fume |
| OF | Objective function |
| MAE | Mean absolute error |
| RF | Random forest |
| SVM | Support vector machine |
| MEP | Multi-expression programming |
| RMSE | Root mean square error |
| ANN | Artificial neural network |
| DT | Decision tree |
| GEP | Gene expression programming |
| MLPNN | Multilayer perception neural network |
| OF | Objective function |
| MEP | Multi-expression programming |
| ANFIS | Adaptive neuro-fuzzy logic inference system |
| DL | Deep learning |
| PI | Performance index |
| SA | Sensitivity analysis |
| R2 | Coefficient of determination |
| MSE | Mean square error |
References
- Arrigoni, A.; Panesar, D.K.; Duhamel, M.; Opher, T.; Saxe, S.; Posen, I.D.; MacLean, H.L. Life cycle greenhouse gas emissions of concrete containing supplementary cementitious materials: Cut-off vs. substitution. J. Clean. Prod. 2020, 263, 121465. [Google Scholar] [CrossRef]
- Iftikhar, B.; Alih, S.C.; Vafaei, M.; Ali, M.; Javed, M.F.; Asif, U.; Ismail, M.; Umer, M.; Gamil, Y.; Amran, M. Experimental study on the eco-friendly plastic-sand paver blocks by utilising plastic waste and basalt fibers. Heliyon 2023, 9, e17107. [Google Scholar] [CrossRef] [PubMed]
- IEA: Cement Technology Roadmap 2009–Carbon Emissions Reductions up to 2050. Available online: https://scholar.google.com/scholar_lookup?title=Cement%20Technology%20Roadmap%202009%3A%20Carbon%20Emissions%20Reductions%20up%20to%202050&publication_year=2009&author=IEA (accessed on 17 December 2023).
- U.S. National Minerals Information Center. Mineral commodity summaries 2020. In Mineral Commodity Summaries; U.S. National Minerals Information Center: Reston, VA, USA, 2020. [Google Scholar] [CrossRef]
- Global Cement CO2 Emissions 1960–2022 | Statista. Available online: https://www.statista.com/statistics/1299532/carbon-dioxide-emissions-worldwide-cement-manufacturing/ (accessed on 21 March 2024).
- Cement Production Global 2023 | Statista. Available online: https://www.statista.com/statistics/1087115/global-cement-production-volume/ (accessed on 21 March 2024).
- Cheng, D.; Reiner, D.M.; Yang, F.; Cui, C.; Meng, J.; Shan, Y.; Liu, Y.; Tao, S.; Guan, D. Projecting future carbon emissions from cement production in developing countries. Nat. Commun. 2023, 14, 8213. [Google Scholar] [CrossRef] [PubMed]
- Hanifa, M.; Agarwal, R.; Sharma, U.; Thapliyal, P.; Singh, L. A review on CO2 capture and sequestration in the construction industry: Emerging approaches and commercialised technologies. J. CO2 Util. 2023, 67, 102292. [Google Scholar] [CrossRef]
- Sivakrishna, A.; Adesina, A.; Awoyera, P.O.; Kumar, K.R. “Green concrete: A review of recent developments. Mater. Today Proc. 2019, 27, 54–58. [Google Scholar] [CrossRef]
- Chen, C.; Xu, R.; Tong, D.; Qin, X.; Cheng, J.; Liu, J.; Zheng, B.; Yan, L.; Zhang, Q. A striking growth of CO2 emissions from the global cement industry driven by new facilities in emerging countries A striking growth of CO2 emissions from the global cement industry driven by new facilities in emerging countries. Environ. Res. Lett. 2022, 17, 044007. [Google Scholar] [CrossRef]
- Kaish, A.B.M.A.; Odimegwu, T.C.; Zakaria, I.; Abood, M.M. Effects of different industrial waste materials as partial replacement of fine aggregate on strength and microstructure properties of concrete. J. Build. Eng. 2020, 35, 102092. [Google Scholar] [CrossRef]
- Bheel, N.; Ibrahim, M.H.W.; Adesina, A.; Kennedy, C.; Shar, I.A. Mechanical performance of concrete incorporating wheat straw ash as partial replacement of cement. J. Build. Pathol. Rehabil. 2020, 6, 4. [Google Scholar] [CrossRef]
- A Elahi, M.; Shearer, C.R.; Reza, A.N.R.; Saha, A.K.; Khan, N.N.; Hossain, M.; Sarker, P.K. Improving the sulfate attack resistance of concrete by using supplementary cementitious materials (SCMs): A review. Constr. Build. Mater. 2021, 281, 122628. [Google Scholar] [CrossRef]
- Jhatial, A.A.; Nováková, I.; Gjerløw, E. A Review on Emerging Cementitious Materials, Reactivity Evaluation and Treatment Methods. Buildings 2023, 13, 526. [Google Scholar] [CrossRef]
- Snellings, R.; Suraneni, P.; Skibsted, J. Future and emerging supplementary cementitious materials. Cem. Concr. Res. 2023, 171, 107199. [Google Scholar] [CrossRef]
- Ahmad, W.; Ahmad, A.; Ostrowski, K.A.; Aslam, F.; Joyklad, P.; Zajdel, P. Sustainable approach of using sugarcane bagasse ash in cement-based composites: A systematic review. Case Stud. Constr. Mater. 2021, 15, e00698. [Google Scholar] [CrossRef]
- Paris, J.M.; Roessler, J.G.; Ferraro, C.C.; Deford, H.D.; Townsend, T.G. A review of waste products utilized as supplements to Portland cement in concrete. J. Clean. Prod. 2016, 121, 1–18. [Google Scholar] [CrossRef]
- Piatak, N.M.; Parsons, M.B.; Seal, R.R. Characteristics and environmental aspects of slag: A review. Appl. Geochem. 2015, 57, 236–266. [Google Scholar] [CrossRef]
- Gupta, S.; Chaudhary, S. State of the art review on supplementary cementitious materials in India—II: Characteristics of SCMs, effect on concrete and environmental impact. J. Clean. Prod. 2022, 357, 131945. [Google Scholar] [CrossRef]
- Akhtar, M.N.; Jameel, M.; Ibrahim, Z.; Bunnori, N.M. Incorporation of recycled aggregates and silica fume in concrete: An environmental savior-a systematic review. J. Mater. Res. Technol. 2022, 20, 4525–4544. [Google Scholar] [CrossRef]
- Özbay, E.; Erdemir, M.; Durmuş, H.I. Utilization and efficiency of ground granulated blast furnace slag on concrete properties—A review. Constr. Build. Mater. 2016, 105, 423–434. [Google Scholar] [CrossRef]
- Gholampour, A.; Gandomi, A.H.; Ozbakkaloglu, T. New formulations for mechanical properties of recycled aggregate concrete using gene expression programming. Constr. Build. Mater. 2017, 130, 122–145. [Google Scholar] [CrossRef]
- Nafees, A.; Javed, M.F.; Khan, S.; Nazir, K.; Farooq, F.; Aslam, F.; Musarat, M.A.; Vatin, N.I. Predictive Modeling of Mechanical Properties of Silica Fume-Based Green Concrete Using Artificial Intelligence Approaches: MLPNN, ANFIS, and GEP. Materials 2021, 14, 7531. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, J.; Gu, Y.; Huang, Y.; Sun, Y.; Ma, G. Prediction of permeability and unconfined compressive strength of pervious concrete using evolved support vector regression. Constr. Build. Mater. 2019, 207, 440–449. [Google Scholar] [CrossRef]
- Farooq, F.; Czarnecki, S.; Niewiadomski, P.; Aslam, F.; Alabduljabbar, H.; Ostrowski, K.A.; Śliwa-Wieczorek, K.; Nowobilski, T.; Malazdrewicz, S. A Comparative Study for the Prediction of the Compressive Strength of Self-Compacting Concrete Modified with Fly Ash. Materials 2021, 14, 4934. [Google Scholar] [CrossRef] [PubMed]
- Moein, M.M.; Saradar, A.; Rahmati, K.; Mousavinejad, S.H.G.; Bristow, J.; Aramali, V.; Karakouzian, M. Predictive models for concrete properties using machine learning and deep learning approaches: A review. J. Build. Eng. 2023, 63, 105444. [Google Scholar] [CrossRef]
- Iqbal, M.F.; Javed, M.F.; Rauf, M.; Azim, I.; Ashraf, M.; Yang, J.; Liu, Q.-F. Sustainable utilization of foundry waste: Forecasting mechanical properties of foundry sand based concrete using multi-expression programming. Sci. Total Environ. 2021, 780, 146524. [Google Scholar] [CrossRef]
- Shahmansouri, A.A.; Yazdani, M.; Ghanbari, S.; Bengar, H.A.; Jafari, A.; Ghatte, H.F. Artificial neural network model to predict the compressive strength of eco-friendly geopolymer concrete incorporating silica fume and natural zeolite. J. Clean. Prod. 2021, 279, 123697. [Google Scholar] [CrossRef]
- Amlashi, A.T.; Abdollahi, S.M.; Goodarzi, S.; Ghanizadeh, A.R. Soft computing based formulations for slump, compressive strength, and elastic modulus of bentonite plastic concrete. J. Clean. Prod. 2019, 230, 1197–1216. [Google Scholar] [CrossRef]
- Mahesh, R.R.; Sathyan, D. Modelling the hardened properties of steel fiber reinforced concrete using ANN. Mater. Today Proc. 2022, 49, 2081–2089. [Google Scholar] [CrossRef]
- Topçu, I.B.; Saridemir, M. Prediction of mechanical properties of recycled aggregate concretes containing silica fume using artificial neural networks and fuzzy logic. Comput. Mater. Sci. 2008, 42, 74–82. [Google Scholar] [CrossRef]
- Van Dao, D.; Ly, H.B.; Trinh, S.H.; Le, T.T.; Pham, B.T. Artificial Intelligence Approaches for Prediction of Compressive Strength of Geopolymer Concrete. Materials 2019, 12, 983. [Google Scholar] [CrossRef] [PubMed]
- Sadowski, Ł.; Piechówka-Mielnik, M.; Widziszowski, T.; Gardynik, A.; Mackiewicz, S. Hybrid ultrasonic-neural prediction of the compressive strength of environmentally friendly concrete screeds with high volume of waste quartz mineral dust. J. Clean. Prod. 2019, 212, 727–740. [Google Scholar] [CrossRef]
- Sebaaly, H.; Varma, S.; Maina, J.W. Optimizing asphalt mix design process using artificial neural network and genetic algorithm. Constr. Build. Mater. 2018, 168, 660–670. [Google Scholar] [CrossRef]
- Mohammadzadeh: Prediction of Compression Index of Fine-Grained Soils Using a Gene Expression Programming Model. Available online: https://scholar.google.com/scholar_lookup?title=Prediction%20of%20compression%20index%20of%20fine-grained%20soils%20using%20a%20gene%20expression%20programming%20model&author=S.%20Mohammadzadeh&publication_year=2019 (accessed on 12 June 2023).
- Gandomi, A.H.; Alavi, A.H. Multi-stage genetic programming: A new strategy to nonlinear system modeling. Inf. Sci. 2011, 181, 5227–5239. [Google Scholar] [CrossRef]
- Awoyera, P.O.; Kirgiz, M.S.; Viloria, A.; Ovallos-Gazabon, D. Estimating strength properties of geopolymer self-compacting concrete using machine learning techniques. J. Mater. Res. Technol. 2020, 9, 9016–9028. [Google Scholar] [CrossRef]
- Shahmansouri, A.A.; Bengar, H.A.; Ghanbari, S. Compressive strength prediction of eco-efficient GGBS-based geopolymer concrete using GEP method. J. Build. Eng. 2020, 31, 101326. [Google Scholar] [CrossRef]
- Park, S.; Wu, S.; Liu, Z.; Pyo, S. The role of supplementary cementitious materials (Scms) in ultra high performance concrete (uhpc): A review. Materials 2021, 14, 1472. [Google Scholar] [CrossRef] [PubMed]
- Balakrishna, Y.; Lavanya, V.; Naresh, A.; Reddy, S.B. Triple Blending of Cement Concrete with Micro Silica and Ground Granulated Blast Furnace Slag. 2016. Available online: www.irjet.net (accessed on 18 February 2024).
- Akram, M.R.; Raza, S. Effect of Micro Silica and GGBS on Compressive Strength and Permeability of Impervious Concrete as a Cement Replacement. Eur. Acad. Res. 2015, 3, 7456–7468. [Google Scholar]
- Rajagopalan, G.; Komarasamy, C. Influence of Silica Fume on Strength Characteristics of High Strength Concrete Influence of Silica Fume on Strength Characteristics of High Strength Concrete. Int. J. Earth Sci. Eng. 2018, 6, 2. [Google Scholar]
- Reddy, K.A.; Kode, V.R.; Malasani, P.; Satish, S.; Darapu, K. Influence of Addition of Micro Silica on Strength Properties of Basalt Fiber Reinforced Multi Blended Concrete. Int. J. Eng. Adv. Technol. (IJEAT) 2019, 9, 4463–4467. [Google Scholar] [CrossRef]
- Vivek, S.S.; Dhinakaran, G. Engineering Science and Technology, an International Journal Fresh and hardened properties of binary blend high strength self compacting concrete. Eng. Sci. Technol. Int. J. 2017, 20, 1173–1179. [Google Scholar] [CrossRef]
- Rajeshwari, R.; Mandal, S. Prediction of compressive strength of high-volume fly ash concrete using artificial neural network. Lect. Notes Civ. Eng. 2019, 25, 471–483. [Google Scholar] [CrossRef]
- Suda, V.B.R.; Paul, S.P. Relationship between compressive, split tensile and flexural strengths of ternary blended concrete. Mater. Today Proc. 2022, 65, 1112–1119. [Google Scholar] [CrossRef]
- Reddy, S.V.B.; Mounika, P.R. Strength and Durability Studies of Ternary Concrete. J. Appl. Eng. 2018, 13, 12161–12177. Available online: https://www.ripublication.com/ijaer18/ijaerv13n15_65.pdf (accessed on 18 February 2024).
- Siddique, R.; Kaur, D. Properties of concrete containing ground granulated blast furnace slag (GGBFS) at elevated temperatures. J. Adv. Res. 2012, 3, 45–51. [Google Scholar] [CrossRef]
- Babu, A. Study on the Strength and Durability Properties of Ternary Blended Concrete. Int. J. Eng. Res. Technol. (IJERT) 2016, 3, 155–160. [Google Scholar]
- Marani, A.; Jamali, A.; Nehdi, M.L. Predicting Ultra-High-Performance Concrete Compressive Strength Using Tabular Generative Adversarial Networks. Materials 2020, 13, 4757. [Google Scholar] [CrossRef] [PubMed]
- Haroon, W.; Ahmad, N.; Akram, R.R. Developing of Impervious Concrete Using Silica Fume and GGBS as CEMENT Replacement Materials Department of Civil Engineering. Ph.D. Thesis, University of Engineering and Technology, Taxila, Pakistan, 2012. [Google Scholar]
- Zhang, W.; Ba, H. Effect of ground granulated blast-furnace slag (GGBFS) and silica fume (SF) on chloride migration through concrete subjected to repeated loading. Sci. China Technol. Sci. 2012, 55, 3102–3108. [Google Scholar] [CrossRef]
- Juenger, M. Supplementary cementitious materials for concrete: Characterization needs. Mater. Res. Soc. Symp. Proc. 2012, 1488, 106–120. [Google Scholar] [CrossRef]
- Prakash, S.; Kumar, S.; Biswas, R.; Rai, B. Influence of silica fume and ground granulated blast furnace slag on the engineering properties of ultra-high-performance concrete. Innov. Infrastruct. Solut. 2022, 7, 1–18. [Google Scholar] [CrossRef]
- Suda, V.B.R.; Rao, P.S. Experimental investigation on optimum usage of Micro silica and GGBS for the strength characteristics of concrete. Mater. Today Proc. 2020, 27, 805–811. [Google Scholar] [CrossRef]
- Reddy, S.V.B.; Rao, P.S. ScienceDirect Experimental studies on compressive strength of ternary blended concretes at different levels of micro silica and ggbs. Mater. Today Proc. 2016, 3, 3752–3760. [Google Scholar] [CrossRef]
- Suda, V.B.R.; Rao, P. Influence of Mineral admixtures on Compressive strength of Ternary concrete with different Water binder ratios. IOSR J. Mech. Civ. Eng. 2016, 16, 48–56. [Google Scholar] [CrossRef]
- Biswal, U.S.; Dinakar, P. A mix design procedure for fly ash and ground granulated blast furnace slag based treated recycled aggregate concrete. Clean Eng. Technol. 2021, 5, 100314. [Google Scholar] [CrossRef]
- Chandini, S.; Mohammed, P.; Nusari, S. Green Concrete—A Low Cost and Sustainable Solution for a Better Environment. Indian J. Econ. Bus. 2020, 19, 261–269. [Google Scholar]
- Kumar, S.; Joon, P. A Ternary Blended Concrete Mix with Partial Replacement of OPC with GGBS & Micro Silica and Their Effects on Strength-An Experimental Study Post Graduate Student (Structural Design). 2016. Available online: www.iaster.com (accessed on 18 February 2024).
- Ghassemzadeh, F.; Shekarchi, M.; Sajedi, S.; Khanzadeh, M.; Sadati, S. Effect of silica fume and GGBS on shrinkage in the high performance concrete. In Concrete under Severe Conditions: Environment and Loading; Taylor & Francis: Abingdon, UK, 2010; Volume 2, pp. 1007–1012. [Google Scholar]
- Duval, R.; Kadri, E.H. Influence of Silica Fume on the Workability and the Compressive Strength of High-Performance Concretes. Cem. Concr. Res. 1998, 28, 533–547. [Google Scholar] [CrossRef]
- Mardani-Aghabaglou, A.; Bayqra, S.H.; Nobakhtjoo, A. Specimen size and shape effects on strength of concrete in the absence and presence of steel fibers. Rev. Constr. 2021, 20, 128–144. [Google Scholar] [CrossRef]
- Elwell, D.J.; Fu, G. Compression testing of concrete: Cylinders vs. cube. Spec. Rep. 1995, 119, 21. [Google Scholar]
- Gandomi, A.H.; Roke, D.A. Assessment of artificial neural network and genetic programming as predictive tools. Adv. Eng. Softw. 2015, 88, 63–72. [Google Scholar] [CrossRef]
- Atkinson, A.C.; Riani, M.; Cerioli, A. The forward search: Theory and data analysis. J. Korean Stat. Soc. 2010, 39, 117–134. [Google Scholar] [CrossRef]
- Khan, S.I.; Hoque, A.S.M.L. SICE: An improved missing data imputation technique. J. Big Data 2020, 7, 1–21. [Google Scholar] [CrossRef]
- Sharma, C.; Ojha, C.S.P. Statistical Parameters of Hydrometeorological Variables: Standard Deviation, SNR, Skewness and Kurtosis. Lect. Notes Civ. Eng. 2020, 39, 59–70. [Google Scholar] [CrossRef]
- Brown, S.C.; Greene, J.A. The wisdom development scale: Translating the conceptual to the concrete. J. Coll. Stud. Dev. 2006, 47, 1–19. [Google Scholar] [CrossRef]
- GN Smith—Probability & Statistics in Civil Engineering PDF | PDF | Matrix (Mathematics) | Normal Distribution. Available online: https://www.scribd.com/document/338933868/GN-Smith-Probability-Statistics-in-Civil-Engineering-pdf# (accessed on 31 May 2023).
- Pitts, W.; McCulloch, W.S. How we know universals the perception of auditory and visual forms. Bull. Math. Biol. 1947, 9, 127–147. [Google Scholar] [CrossRef]
- Kourgialas, N.N.; Dokou, Z.; Karatzas, G.P. Statistical analysis and ANN modeling for predicting hydrological extremes under climate change scenarios: The example of a small Mediterranean agro-watershed. J. Environ. Manag. 2015, 154, 86–101. [Google Scholar] [CrossRef] [PubMed]
- Koçak, Y.; Şiray, G.Ü. New activation functions for single layer feedforward neural network. Expert. Syst. Appl. 2020, 164, 113977. [Google Scholar] [CrossRef]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for activation functions. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018—Workshop Track Proceedings, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Babu, K.V.N.; Edla, D.R. New Algebraic Activation Function for Multi-Layered Feed Forward Neural Networks. IETE J. Res. 2016, 63, 71–79. [Google Scholar] [CrossRef]
- Das, S.K. Artificial Neural Networks in Geotechnical Engineering: Modeling and Application Issues. Metaheuristics Water Geotech. Transp. Eng. 2013, 45, 231–270. [Google Scholar] [CrossRef]
- Tahani, M.; Vakili, M.; Khosrojerdi, S. Experimental evaluation and ANN modeling of thermal conductivity of graphene oxide nanoplatelets/deionized water nanofluid. Int. Commun. Heat. Mass. Transf. 2016, 76, 358–365. [Google Scholar] [CrossRef]
- Khan, S.; Khan, M.A.; Zafar, A.; Javed, M.F.; Aslam, F.; Musarat, M.A.; Vatin, N.I. Predicting the Ultimate Axial Capacity of Uniaxially Loaded CFST Columns Using Multiphysics Artificial Intelligence. Materials 2021, 15, 39. [Google Scholar] [CrossRef] [PubMed]
- Moayedi, H.; Mosavi, A. A water cycle-based error minimization technique in predicting the bearing capacity of shallow foundation. Eng. Comput. 2021, 38, 3993–4006. [Google Scholar] [CrossRef]
- Golafshani, E.M.; Behnood, A.; Arashpour, M. Predicting the compressive strength of normal and High-Performance Concretes using ANN and ANFIS hybridized with Grey Wolf Optimizer. Constr. Build. Mater. 2019, 232, 117266. [Google Scholar] [CrossRef]
- Islam, M.R.; Jaafar, W.Z.W.; Hin, L.S.; Osman, N.; Hossain, A.; Mohd, N.S. Development of an intelligent system based on ANFIS model for predicting soil erosion. Environ. Earth Sci. 2018, 77, 186. [Google Scholar] [CrossRef]
- Gene Expression Programming: Mathematical Modeling by an Artificial Intelligence—Candida Ferreira—Google Books. Available online: https://books.google.kz/books?hl=en&lr=&id=NkG7BQAAQBAJ&oi=fnd&pg=PR7&ots=Y_orvEYgF2&sig=nbBd7c2pns60WPMczu9EAjAjPQA&redir_esc=y#v=onepage&q&f=false (accessed on 9 October 2022).
- Saridemir, M. Genetic programming approach for prediction of compressive strength of concretes containing rice husk ash. Constr. Build. Mater. 2010, 24, 1911–1919. [Google Scholar] [CrossRef]
- A GENE EXPRESSION PROGRAMMING SYSTEM FOR TIME SERIES MODELING. Available online: https://www.researchgate.net/publication/253404813_A_GENE_EXPRESSION_PROGRAMMING_SYSTEM_FOR_TIME_SERIES_MODELING (accessed on 9 October 2022).
- Jalal, F.E.; Xu, Y.; Iqbal, M.; Javed, M.F.; Jamhiri, B. Predictive modeling of swell-strength of expansive soils using artificial intelligence approaches: ANN, ANFIS and GEP. J. Environ. Manag. 2021, 289, 112420. [Google Scholar] [CrossRef] [PubMed]
- Venkatesh, K.; Bind, Y.K. ANN and Neuro-Fuzzy Modeling for Shear Strength Characterization of Soils. Proc. Natl. Acad. Sci. India Sect. A—Phys. Sci. 2022, 92, 243–249. [Google Scholar] [CrossRef]
- Iqbal, M.F.; Liu, Q.-F.; Azim, I.; Zhu, X.; Yang, J.; Javed, M.F.; Rauf, M. Prediction of mechanical properties of green concrete incorporating waste foundry sand based on gene expression programming. J. Hazard. Mater. 2020, 384, 121322. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Zhang, R.; Wu, C.; Goh, A.T.C.; Lacasse, S.; Liu, Z.; Liu, H. State-of-the-art review of soft computing applications in underground excavations. Geosci. Front. 2020, 11, 1095–1106. [Google Scholar] [CrossRef]
- Alade, I.O.; Rahman, M.A.A.; Saleh, T.A. Modeling and prediction of the specific heat capacity of Al2 O3/water nanofluids using hybrid genetic algorithm/support vector regression model. Nano-Struct. Nano-Objects 2019, 17, 103–111. [Google Scholar] [CrossRef]
- Shahin, M.A. Use of evolutionary computing for modelling some complex problems in geotechnical engineering. Geomech. Geoengin. 2014, 10, 109–125. [Google Scholar] [CrossRef]
- Kareken, G.; Shon, C.-S.; Tukaziban, A.; Kozhageldi, N.; Mardenov, M.; Zhang, D.; Kim, J.R. Geopolymer as a key material to utilize basic oxygen furnace slag (BOFS) as an aggregate. Mater. Today Proc. 2023. [Google Scholar] [CrossRef]
- Bakhbergen, U.; Shon, C.S.; Zhang, D.; Kim, J.R.; Liu, J. Optimization of mixture parameter for physical and mechanical properties of reactive powder concrete under external sulfate attack using Taguchi method. Constr. Build. Mater. 2022, 352, 129023. [Google Scholar] [CrossRef]
- Güllü, H.; Fedakar, H.İ. On the prediction of unconfined compressive strength of silty soil stabilized with bottom ash, jute and steel fibers via artificial intelligence. Geomech. Eng. 2017, 12, 441–464. [Google Scholar] [CrossRef]
- Hakeem, I.Y.; Althoey, F.; Hosen, A. Mechanical and durability performance of ultra-high-performance concrete incorporating SCMs. Constr. Build. Mater. 2022, 359, 129430. [Google Scholar] [CrossRef]
- ACI Committee 363. ACI PRC-363-10 Report on High-Strength Concrete; American Concrete Institute: Farmington Hills, MI, USA, 2010. [Google Scholar]
- Golbraikh, A.; Tropsha, A. Beware of q2! J. Mol. Graph. Model. 2002, 20, 269–276. [Google Scholar] [CrossRef] [PubMed]
- Alavi, A.H.; Ameri, M.; Gandomi, A.H.; Mirzahosseini, M.R. Formulation of flow number of asphalt mixes using a hybrid computational method. Constr. Build. Mater. 2011, 25, 1338–1355. [Google Scholar] [CrossRef]
- Cyr, M. Influence of supplementary cementitious materials (SCMs) on concrete durability. In Eco-Efficient Concrete; Woodhead Publishing Series in Civil and Structural Engineering: Toulouse, France, 2013; pp. 153–197. [Google Scholar] [CrossRef]
- Chu, S.H. Effect of paste volume on fresh and hardened properties of concrete. Constr. Build. Mater. 2019, 218, 284–294. [Google Scholar] [CrossRef]
- Meddah, M.S.; Zitouni, S.; Belâabes, S. Effect of content and particle size distribution of coarse aggregate on the compressive strength of concrete. Constr. Build. Mater. 2010, 24, 505–512. [Google Scholar] [CrossRef]
- Samad, S.; Shah, A. Role of binary cement including Supplementary Cementitious Material (SCM), in production of environmentally sustainable concrete: A critical review. Int. J. Sustain. Built Environ. 2017, 6, 663–674. [Google Scholar] [CrossRef]




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Minimum | Mean | Range | Median | Kurtosis | Mode | SD | Skewness | Maximum | |
|---|---|---|---|---|---|---|---|---|---|---|
| Inputs | Units | |||||||||
| C | kg/m3 | 113.4 | 254.0 | 463.6 | 243.0 | −0.3 | 270.0 | 87.9 | 0.5 | 577.0 |
| GGBS | kg/m3 | 21.5 | 126.2 | 348.5 | 129.6 | −0.1 | 64.8 | 57.6 | 0.5 | 370.0 |
| SF | kg/m3 | 9.0 | 36.1 | 80.0 | 38.7 | 0.9 | 45.0 | 15.0 | 0.5 | 89.0 |
| SP | kg/m3 | 0.0 | 3.1 | 11.3 | 3.8 | 0.6 | 0.0 | 3.1 | 1.0 | 11.3 |
| CA | kg/m3 | 793.0 | 1090.8 | 655.0 | 1093.0 | 4.0 | 1093.0 | 91.7 | 1.2 | 1448.0 |
| FA | kg/m3 | 499.0 | 724.9 | 493.0 | 768.0 | −0.5 | 785.0 | 98.5 | −0.2 | 992.0 |
| W/B | 0.2 | 0.4 | 0.4 | 0.4 | −1.2 | 0.6 | 0.1 | 0.2 | 0.6 | |
| Age | Days | 1.0 | 50.8 | 364.0 | 28.0 | 9.8 | 28.0 | 63.0 | 2.8 | 365.0 |
| Output | ||||||||||
| CS | MPa | 11.2 | 39.2 | 69.6 | 35.2 | −0.2 | 34.4 | 14.3 | 0.7 | 80.8 |
| Parameters | Minimum | Mean | Range | Median | Kurtosis | Mode | SD | Skewness | Maximum | |
|---|---|---|---|---|---|---|---|---|---|---|
| Inputs | Units | |||||||||
| C | kg/m3 | 113.4 | 261.4 | 463.6 | 270.0 | 0.0 | 270.0 | 83.6 | 0.4 | 577.0 |
| GGBS | kg/m3 | 45.0 | 135.8 | 325.0 | 135.0 | 0.0 | 45.0 | 58.4 | 0.4 | 370.0 |
| SF | kg/m3 | 16.2 | 40.3 | 72.8 | 45.0 | 2.4 | 45.0 | 13.9 | 0.6 | 89.0 |
| SP | kg/m3 | 0.0 | 2.8 | 11.3 | 0.0 | −0.1 | 0.0 | 3.8 | 1.1 | 11.3 |
| CA | kg/m3 | 985.0 | 1108.5 | 463.0 | 1093.0 | 2.0 | 1093.0 | 108.1 | 1.3 | 1448.0 |
| FA | kg/m3 | 499.0 | 723.5 | 401.0 | 785.0 | −1.1 | 785.0 | 114.3 | −0.3 | 900.0 |
| W/B | 0.2 | 0.4 | 0.4 | 0.4 | −1.3 | 0.6 | 0.1 | 0.5 | 0.6 | |
| Age | Days | 7.0 | 68.5 | 358.0 | 56.0 | 5.1 | 28.0 | 62.2 | 1.9 | 365.0 |
| Output | ||||||||||
| TS | MPa | 2.1 | 4.5 | 6.1 | 4.3 | −0.1 | 3.7 | 1.2 | 0.5 | 8.3 |
| C | GGBS | SF | SP | CA | FA | W/B | Age | CS | |
|---|---|---|---|---|---|---|---|---|---|
| C | 1 | ||||||||
| GGBS | −0.2172 | 1 | |||||||
| SF | 0.0304 | 0.1853 | 1 | ||||||
| SP | −0.0681 | 0.0145 | 0.2537 | 1 | |||||
| CA | −0.0004 | −0.0160 | −0.1282 | −0.0553 | 1 | ||||
| FA | −0.4142 | −0.1128 | 0.0059 | 0.3206 | −0.5484 | 1 | |||
| W/B | −0.5972 | −0.2312 | −0.2535 | −0.2416 | 0.1206 | 0.3244 | 1 | ||
| Age | −0.1608 | −0.0225 | 0.0425 | 0.0707 | −0.0420 | 0.1705 | 0.1828 | 1 | |
| CS | 0.2388 | 0.2360 | 0.2262 | 0.2561 | −0.3149 | 0.2068 | −0.5637 | 0.2442 | 1 |
| C | GGBS | SF | SP | CA | FA | W/B | Age | TS | |
|---|---|---|---|---|---|---|---|---|---|
| C | 1 | ||||||||
| GGBS | −0.2450 | 1 | |||||||
| SF | 0.3150 | 0.1287 | 1 | ||||||
| SP | 0.1128 | 0.1204 | 0.2327 | 1 | |||||
| CA | −0.0548 | 0.1256 | −0.3269 | −0.0927 | 1 | ||||
| FA | −0.3015 | −0.2016 | −0.0832 | 0.2561 | −0.6536 | 1 | |||
| W/B | −0.6520 | −0.2686 | −0.3952 | −0.4985 | 0.0654 | 0.2200 | 1 | ||
| Age | 0.0304 | −0.0619 | 0.0519 | 0.1025 | −0.1778 | 0.1123 | −0.0198 | 1 | |
| TS | 0.5449 | 0.1457 | 0.4139 | 0.5142 | −0.3211 | 0.0702 | −0.7511 | 0.3124 | 1 |
| Parameter Type | Value/Type | |
|---|---|---|
| Data Distribution | CS | TS |
| Total dataset | 682 | 245 |
| Calibration (training) (70%) | 454 | 171 |
| Testing (15%) | 97 | 37 |
| Validation (15%) | 97 | 37 |
| General settings | ||
| Hidden neurons | 10 | |
| Network type | Feed-forward back-propagation | |
| Output layer transfer function | PURELIN | |
| Training method | Levenberg–Marquardt | |
| Computational layer transfer function | TANSIG | |
| Epochs | 41 | |
| Data division | Random | |
| Rate of learning | 0.01 | |
| Non-linear parameters | 18 | |
| Parameter Type | Value/Type | |
|---|---|---|
| Data Distribution | CS | TS |
| Total dataset | 648 | 245 |
| Calibration (training) (70%) | 454 | 171 |
| Testing (15%) | 97 | 37 |
| Validation (15%) | 97 | 37 |
| General settings | ||
| Number of nodes | 10 | 10 |
| Number of fuzzy rules | 7 | 8 |
| Number of non-linear parameters | 50 | 77 |
| Epochs | 40 | 40 |
| Number of linear parameters | 66 | 120 |
| Number of MFs | 18 | 89 |
| Error goal in training | 0 | 0 |
| Fuzzy structure | Sugeno | |
| Output function | Linear | |
| Optimization technique | Hybrid method | |
| MF type | trimf | |
| FIS type | Sub-clustering | |
| Genetic Operators | |
|---|---|
| RIS transposition rate | 0.00541 |
| Permutation | 0.00546 |
| Two-point recombination rate | 0.00273 |
| Leaf mutation | 0.00546 |
| Gene recombination rate | 0.00274 |
| Conservative mutation | 0.00364 |
| Rate of gene transposition | 0.00272 |
| Mutation | 0.00138 |
| Rate of mutation | 0.00134 |
| Fixed-root mutation | 0.00182 |
| Rate of inversion | 0.00535 |
| IS transposition rate | 0.00531 |
| Numerical Constants | |
| Data type | Floating number |
| Method | Random selection |
| Lower bound | −10 |
| Fine-tuning | 0.0026 |
| Constant per gene | 10 |
| Upper bound | 10 |
| Models | No. of Chromosomes | Variable Used | Head Size | Constant per Genes | Number of Genes | Linking Function | Ftn Set | Duration (Minutes) |
|---|---|---|---|---|---|---|---|---|
| CS1 | 30 | 7 | 8 | 10 | 3 | Addition | (÷, ×, +, −) | 20 |
| CS2 | 50 | 7 | 10 | 10 | 4 | 23 | ||
| CS3 | 80 | 9 | 12 | 10 | 5 | 25 | ||
| CS4 | 100 | 7 | 14 | 10 | 6 | 30 | ||
| CS5 | 150 | 7 | 16 | 10 | 7 | 40 | ||
| CS6 | 30 | 7 | 8 | 10 | 3 | Division | (÷, ×, +, −) | 23 |
| CS7 | 50 | 9 | 10 | 10 | 4 | 26 | ||
| CS8 | 80 | 9 | 12 | 10 | 5 | 29 | ||
| CS9 | 100 | 8 | 14 | 10 | 6 | 35 | ||
| CS10 | 150 | 7 | 16 | 10 | 7 | 45 | ||
| CS11 | 30 | 9 | 8 | 10 | 3 | Multiplication | (÷, ×, +, −) | 18 |
| CS12 | 50 | 8 | 10 | 10 | 4 | 22 | ||
| CS13 | 80 | 9 | 12 | 10 | 5 | 24 | ||
| CS14 | 100 | 8 | 14 | 10 | 6 | 27 | ||
| CS15 | 150 | 8 | 16 | 10 | 7 | 35 | ||
| CS16 | 30 | 7 | 8 | 10 | 3 | Multiplication | (÷, ×, +, −, Pow, √) | 30 |
| CS17 | 50 | 9 | 10 | 10 | 4 | 34 | ||
| CS18 | 80 | 8 | 12 | 10 | 5 | 38 | ||
| CS19 | 100 | 9 | 14 | 10 | 6 | 42 | ||
| CS20 | 150 | 8 | 16 | 10 | 7 | 50 |
| Models | No. of Chromosome | Variable Used | Head Size | Constant per Genes | Number of Genes | Linking Function | Function Set | Duration (Minutes) |
|---|---|---|---|---|---|---|---|---|
| TS1 | 30 | 7 | 8 | 10 | 3 | Addition | (÷, ×, +, −) | 22 |
| TS2 | 50 | 8 | 10 | 10 | 4 | 24 | ||
| TS3 | 80 | 9 | 12 | 10 | 5 | 26 | ||
| TS4 | 100 | 9 | 14 | 10 | 6 | 32 | ||
| TS5 | 150 | 9 | 16 | 10 | 7 | 40 | ||
| TS6 | 30 | 8 | 8 | 10 | 3 | Division | (÷, ×, +, −) | 24 |
| TS7 | 50 | 8 | 10 | 10 | 4 | 26 | ||
| TS8 | 80 | 7 | 12 | 10 | 5 | 28 | ||
| TS9 | 100 | 8 | 14 | 10 | 6 | 33 | ||
| TS10 | 150 | 7 | 16 | 10 | 7 | 45 | ||
| TS11 | 30 | 9 | 8 | 10 | 3 | Multiplication | (÷, ×, +, −) | 20 |
| TS12 | 50 | 9 | 10 | 10 | 4 | 22 | ||
| TS13 | 80 | 9 | 12 | 10 | 5 | 26 | ||
| TS14 | 100 | 8 | 14 | 10 | 6 | 27 | ||
| TS15 | 150 | 8 | 16 | 10 | 7 | 37 | ||
| TS16 | 30 | 7 | 8 | 10 | 3 | Multiplication | (÷, ×, +, −, Pow, √) | 31 |
| TS17 | 50 | 7 | 10 | 10 | 4 | 37 | ||
| TS18 | 80 | 8 | 12 | 10 | 5 | 38 | ||
| TS19 | 100 | 9 | 14 | 10 | 6 | 44 | ||
| TS20 | 150 | 9 | 16 | 10 | 7 | 54 |
| Component | OPC | GGBS | SF |
|---|---|---|---|
| Chemical Composition (% Mass) | |||
| K2O | – | 0.69 | 0.56 |
| CaO | 62.73 | 33.06 | 0.22 |
| Fe2O3 | 3.95 | 0.34 | 0.5 |
| SO3 | 3.14 | 2.67 | 0.12 |
| SiO2 | 20.78 | 35.84 | 97.5 |
| Na2O | 0.78 | 1.08 | 0.25 |
| Al2O3 | 4.82 | 12.43 | 0.2 |
| MgO | 1.57 | 12.08 | 0.56 |
| Physical Properties | |||
| Specific gravity | 3.15 | 3.05 | 2.22 |
| Specific surface area (m2/kg) | 421 | 550 | 2300 |
| Loss on ignition | 2.08 | 2.08 | 2.08 |
| Code | SCMs | Cement | SP | SF | Water | GGBS | CA | FA |
|---|---|---|---|---|---|---|---|---|
| (kg/m3) | (kg/m3) | (kg/m3) | (kg/m3) | (kg/m3) | (kg/m3) | (kg/m3) | ||
| CM | CM | 415 | 10 | 0 | 156 | 0 | 1050 | 730 |
| M1 | SF5+GGBS10 | 353 | 10 | 20 | 156 | 41 | 1050 | 730 |
| M2 | SF10+GGBS20 | 291 | 10 | 41 | 156 | 83 | 1050 | 730 |
| M3 | SF10+GGBS30 | 249 | 10 | 41 | 156 | 125 | 1050 | 730 |
| M4 | SF15+GGBS30 | 228 | 10 | 62 | 156 | 125 | 1050 | 730 |
| M5 | SF20+GGBS40 | 166 | 10 | 83 | 156 | 166 | 1050 | 730 |
| Models | Training Dataset | Testing (Validation) Dataset | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | RRSE | R | ρ | R2 | RMSE | MAE | RRSE | R | ρ | |
| CS1 | 0.861 | 5.047 | 4.070 | 0.374 | 0.928 | 0.107 | 0.839 | 5.277 | 4.071 | 0.402 | 0.916 | 0.110 |
| CS2 | 0.860 | 5.079 | 4.069 | 0.375 | 0.927 | 0.108 | 0.852 | 5.031 | 4.098 | 0.387 | 0.923 | 0.111 |
| CS3 | 0.863 | 4.960 | 4.069 | 0.370 | 0.929 | 0.107 | 0.857 | 4.997 | 4.065 | 0.379 | 0.926 | 0.110 |
| CS4 | 0.871 | 4.934 | 4.063 | 0.357 | 0.933 | 0.102 | 0.861 | 4.957 | 4.060 | 0.366 | 0.928 | 0.106 |
| CS5 | 0.870 | 4.959 | 4.061 | 0.362 | 0.933 | 0.104 | 0.881 | 4.967 | 4.087 | 0.345 | 0.939 | 0.108 |
| CS6 | 0.767 | 7.691 | 5.085 | 0.483 | 0.876 | 0.166 | 0.784 | 6.738 | 5.030 | 0.465 | 0.885 | 0.169 |
| CS7 | 0.798 | 6.871 | 5.075 | 0.463 | 0.893 | 0.177 | 0.805 | 6.401 | 5.074 | 0.457 | 0.897 | 0.180 |
| CS8 | 0.798 | 6.871 | 5.075 | 0.463 | 0.893 | 0.123 | 0.805 | 6.401 | 5.064 | 0.468 | 0.897 | 0.127 |
| CS9 | 0.857 | 5.046 | 4.066 | 0.346 | 0.926 | 0.095 | 0.857 | 5.035 | 4.071 | 0.385 | 0.925 | 0.099 |
| CS10 | 0.866 | 5.002 | 4.068 | 0.366 | 0.930 | 0.094 | 0.869 | 4.988 | 4.063 | 0.366 | 0.932 | 0.098 |
| CS11 | 0.876 | 4.998 | 3.98 | 0.376 | 0.936 | 0.085 | 0.875 | 4.935 | 4.062 | 0.366 | 0.936 | 0.088 |
| CS12 | 0.883 | 4.917 | 3.821 | 0.341 | 0.940 | 0.064 | 0.876 | 4.972 | 4.021 | 0.356 | 0.936 | 0.067 |
| CS13 | 0.882 | 4.922 | 3.881 | 0.344 | 0.939 | 0.069 | 0.872 | 4.985 | 4.065 | 0.359 | 0.934 | 0.072 |
| CS14 | 0.881 | 4.949 | 3.897 | 0.345 | 0.939 | 0.069 | 0.881 | 4.997 | 4.058 | 0.346 | 0.938 | 0.072 |
| CS15 | 0.860 | 5.759 | 4.071 | 0.462 | 0.927 | 0.099 | 0.861 | 4.967 | 4.071 | 0.400 | 0.928 | 0.102 |
| CS16 | 0.778 | 6.691 | 5.082 | 0.483 | 0.882 | 0.156 | 0.787 | 6.634 | 5.083 | 0.467 | 0.887 | 0.159 |
| CS17 | 0.808 | 5.875 | 4.945 | 0.463 | 0.899 | 0.167 | 0.805 | 6.401 | 4.865 | 0.447 | 0.897 | 0.170 |
| CS18 | 0.818 | 5.781 | 4.936 | 0.433 | 0.905 | 0.125 | 0.805 | 6.401 | 4.826 | 0.436 | 0.897 | 0.128 |
| CS19 | 0.860 | 5.079 | 4.069 | 0.375 | 0.927 | 0.103 | 0.852 | 4.931 | 4.869 | 0.387 | 0.923 | 0.107 |
| CS20 | 0.861 | 5.035 | 4.068 | 0.373 | 0.928 | 0.102 | 0.846 | 5.073 | 4.888 | 0.393 | 0.920 | 0.106 |
| Models | Training Dataset | Testing (Validation) Dataset | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | RRSE | R | ρ | R2 | RMSE | MAE | RRSE | R | ρ | |
| TS1 | 0.896 | 0.365 | 0.265 | 0.312 | 0.947 | 0.058 | 0.871 | 9.277 | 0.385 | 0.353 | 0.933 | 0.059 |
| TS2 | 0.895 | 0.379 | 0.275 | 0.313 | 0.946 | 0.058 | 0.884 | 8.931 | 0.395 | 0.340 | 0.940 | 0.060 |
| TS3 | 0.899 | 0.396 | 0.245 | 0.309 | 0.948 | 0.058 | 0.889 | 8.747 | 0.395 | 0.333 | 0.943 | 0.059 |
| TS4 | 0.907 | 0.353 | 0.242 | 0.298 | 0.952 | 0.055 | 0.892 | 7.597 | 0.392 | 0.322 | 0.945 | 0.057 |
| TS5 | 0.906 | 0.376 | 0.242 | 0.302 | 0.952 | 0.056 | 0.913 | 7.967 | 0.382 | 0.303 | 0.956 | 0.058 |
| TS6 | 0.803 | 0.469 | 0.367 | 0.403 | 0.896 | 0.089 | 0.816 | 10.738 | 0.387 | 0.409 | 0.903 | 0.091 |
| TS7 | 0.834 | 0.427 | 0.341 | 0.387 | 0.913 | 0.095 | 0.836 | 10.401 | 0.381 | 0.401 | 0.914 | 0.097 |
| TS8 | 0.834 | 0.411 | 0.342 | 0.387 | 0.913 | 0.067 | 0.836 | 10.401 | 0.384 | 0.411 | 0.914 | 0.068 |
| TS9 | 0.892 | 0.388 | 0.276 | 0.289 | 0.945 | 0.052 | 0.888 | 8.346 | 0.387 | 0.339 | 0.942 | 0.053 |
| TS10 | 0.902 | 0.367 | 0.245 | 0.306 | 0.949 | 0.051 | 0.901 | 8.430 | 0.382 | 0.321 | 0.949 | 0.053 |
| TS11 | 0.912 | 0.345 | 0.239 | 0.315 | 0.955 | 0.046 | 0.907 | 8.257 | 0.379 | 0.284 | 0.952 | 0.047 |
| TS12 | 0.919 | 0.321 | 0.234 | 0.285 | 0.959 | 0.035 | 0.908 | 7.972 | 0.374 | 0.312 | 0.953 | 0.036 |
| TS13 | 0.918 | 0.322 | 0.238 | 0.287 | 0.958 | 0.037 | 0.904 | 8.283 | 0.378 | 0.315 | 0.951 | 0.039 |
| TS14 | 0.917 | 0.349 | 0.237 | 0.288 | 0.958 | 0.037 | 0.912 | 7.997 | 0.377 | 0.304 | 0.955 | 0.039 |
| TS15 | 0.896 | 0.359 | 0.255 | 0.386 | 0.946 | 0.054 | 0.893 | 8.967 | 0.385 | 0.351 | 0.945 | 0.055 |
| TS16 | 0.814 | 0.491 | 0.366 | 0.403 | 0.902 | 0.084 | 0.818 | 10.634 | 0.386 | 0.410 | 0.905 | 0.086 |
| TS17 | 0.844 | 0.487 | 0.356 | 0.387 | 0.919 | 0.090 | 0.836 | 10.401 | 0.396 | 0.392 | 0.914 | 0.092 |
| TS18 | 0.854 | 0.478 | 0.345 | 0.362 | 0.924 | 0.067 | 0.836 | 10.401 | 0.391 | 0.383 | 0.914 | 0.069 |
| TS19 | 0.895 | 0.379 | 0.245 | 0.313 | 0.946 | 0.056 | 0.884 | 8.931 | 0.385 | 0.340 | 0.940 | 0.058 |
| TS20 | 0.897 | 0.387 | 0.247 | 0.312 | 0.947 | 0.055 | 0.878 | 9.073 | 0.387 | 0.345 | 0.937 | 0.057 |
| Parameter | Unit | Indicator in the Expression Tree | Description |
|---|---|---|---|
| C | kg/m3 | d0 | Cement content |
| GGBS | kg/m3 | d1 | Amount of GGBS |
| SF | kg/m3 | d2 | Amount of silica fume |
| SP | kg/m3 | d3 | Superplasticizer |
| CA | kg/m3 | d4 | Coarse aggregates (granite) |
| FA | kg/m3 | d5 | Fine aggregates |
| W/B | - | d6 | Water-to-cement ratio |
| Age | Days | d7 | Age of specimens at the time of testing |
| Parameters | Cement | Water | SF | GGBS | CA | FA | Age | CS | TS |
|---|---|---|---|---|---|---|---|---|---|
| (kg/m3) | (kg/m3) | (kg/m3) | (kg/m3) | (kg/m3) | (kg/m3) | (Days) | (MPa) | (MPa) | |
| Mean | 283.67 | 156 | 41.17 | 90 | 1050 | 730 | 59.56 | 40.53 | 3.16 |
| Median | 270 | 156 | 104 | 1050 | 730 | 56 | 41.12 | 3.17 | |
| SD | 84.28 | 0 | 57.56 | 0 | 0 | 25 | 5.1 | 0.33 | |
| Range | 249 | 0 | 166 | 0 | 0 | 62 | 18.45 | 1.17 | |
| Minimum | 166 | 156 | 0 | 1050 | 730 | 28 | 32.44 | 2.6 | |
| Maximum | 415 | 156 | 166 | 1050 | 730 | 90 | 50.89 | 3.77 |
| CS Experimental Values | Error % in ML Models | TS Experimental Values | Error % in ML Models | ||||
|---|---|---|---|---|---|---|---|
| ANN | ANFIS | GEP | ANN | ANFIS | GEP | ||
| 39.09 | 4.24 | 1.67 | 4.12 | 3.58 | 2.82 | 1.64 | 0.63 |
| 46.46 | 0.03 | 4.33 | 2.61 | 3.77 | 2.41 | 2.40 | 3.34 |
| 41.23 | 4.29 | 2.03 | 6.30 | 3.06 | 1.16 | 1.21 | 3.80 |
| 46.34 | 0.42 | 4.50 | 1.88 | 3.13 | 2.78 | 3.02 | 0.48 |
| 37.00 | 1.78 | 3.08 | 5.31 | 3.57 | 2.10 | 3.75 | 0.22 |
| 41.45 | 0.04 | 1.06 | 6.42 | 3.17 | 6.25 | 2.06 | 0.79 |
| 38.23 | 2.09 | 3.66 | 2.44 | 3.16 | 2.31 | 0.10 | 0.20 |
| 42.32 | 0.78 | 6.70 | 3.13 | 2.84 | 2.26 | 3.50 | 0.44 |
| 32.44 | 6.20 | 1.08 | 3.66 | 2.96 | 2.71 | 0.29 | 0.54 |
| 36.67 | 2.07 | 1.91 | 2.04 | 3.31 | 1.88 | 0.96 | 1.39 |
| 50.89 | 0.03 | 0.03 | 4.73 | 3.60 | 0.60 | 0.83 | 0.09 |
| 35.45 | 0.02 | 2.32 | 3.32 | 2.68 | 2.84 | 2.32 | 4.48 |
| 34.67 | 0.11 | 6.38 | 3.38 | 2.60 | 2.27 | 5.51 | 7.74 |
| 33.45 | 0.15 | 7.71 | 5.19 | 2.77 | 2.19 | 6.37 | 6.73 |
| 43.00 | 3.60 | 1.28 | 4.11 | 3.31 | 2.96 | 2.93 | 2.95 |
| 43.00 | 6.42 | 6.37 | 2.05 | 2.93 | 4.65 | 5.51 | 8.22 |
| 46.78 | 5.20 | 0.26 | 5.15 | 3.26 | 3.52 | 0.30 | 0.42 |
| 41.00 | 4.82 | 3.04 | 3.53 | 3.19 | 4.74 | 3.30 | 7.26 |
| Proposed Models | Subset Type | R2 | RMSE | MAE | RRMSE | RSE | R | ρ | OF | |
|---|---|---|---|---|---|---|---|---|---|---|
| CS | ANN | Trn-set | 0.9419 | 3.3284 | 1.788 | 0.0851 | 0.0583 | 0.9705 | 0.0436 | 0.0427 |
| Vald-set | 0.9377 | 4.0493 | 2.791 | 0.1008 | 0.0647 | 0.9683 | 0.0512 | |||
| Test-set | 0.938 | 3.8269 | 2.832 | 0.0925 | 0.0657 | 0.9685 | 0.0472 | |||
| ANFIS | Trn-set | 0.9702 | 2.3688 | 1.681 | 0.0731 | 0.0298 | 0.985 | 0.031 | 0.0311 | |
| Vald-set | 0.9698 | 3.0691 | 2.321 | 0.0859 | 0.0583 | 0.9848 | 0.0436 | |||
| Test-set | 0.9678 | 2.5721 | 1.983 | 0.0659 | 0.0339 | 0.9838 | 0.03325 | |||
| GEP | Trn-set | 0.8831 | 4.9174 | 3.821 | 0.1251 | 0.1161 | 0.9392 | 0.0642 | 0.0621 | |
| Vald-set | 0.8763 | 4.9716 | 4.021 | 0.1263 | 0.1243 | 0.9353 | 0.0841 | |||
| Test-set | 0.8821 | 4.9321 | 4.071 | 0.1255 | 0.1191 | 0.9371 | 0.0737 | |||
| TS | ANN | Trn-set | 0.9585 | 0.2699 | 0.202 | 0.0592 | 0.2675 | 0.979 | 0.0299 | 0.0299 |
| Vald-set | 0.9384 | 0.3211 | 0.255 | 0.0723 | 0.0671 | 0.9681 | 0.0366 | |||
| Test-set | 0.9311 | 0.3433 | 0.258 | 0.0761 | 0.0692 | 0.9654 | 0.0392 | |||
| ANFIS | Trn-set | 0.9951 | 0.0886 | 0.034 | 0.0198 | 0.0167 | 0.9975 | 0.0099 | 0.0099 | |
| Vald-set | 0.9981 | 0.0381 | 0.133 | 0.0077 | 0.0021 | 0.9991 | 0.0039 | |||
| Test-set | 0.998 | 0.0383 | 0.017 | 0.0076 | 0.002 | 0.9992 | 0.0038 | |||
| GEP | Trn-set | 0.9188 | 0.3213 | 0.234 | 0.0712 | 0.0812 | 0.9585 | 0.0362 | 0.035 | |
| Vald-set | 0.9123 | 0.3812 | 0.374 | 0.0782 | 0.0891 | 0.9551 | 0.0426 | |||
| Test-set | 0.9081 | 0.4043 | 0.261 | 0.0861 | 0.0972 | 0.9342 | 0.0533 | |||
| S. No. | Equation | Condition | Model | |
|---|---|---|---|---|
| CS | TS | |||
| 1 | 0.991 | 0.993 | ||
| 2 | 0.971 | 0.973 | ||
| 3 | 1.002 | 1.001 | ||
| 4 | , | 0.969 | 0.970 | |
| 5 | , | 0.990 | 0.991 | |
| 6 | 0.0541 | 0.055 | ||
| 7 | 0.005 | 0.005 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asif, U.; Memon, S.A.; Javed, M.F.; Kim, J. Predictive Modeling and Experimental Validation for Assessing the Mechanical Properties of Cementitious Composites Made with Silica Fume and Ground Granulated Blast Furnace Slag. Buildings 2024, 14, 1091. https://doi.org/10.3390/buildings14041091
Asif U, Memon SA, Javed MF, Kim J. Predictive Modeling and Experimental Validation for Assessing the Mechanical Properties of Cementitious Composites Made with Silica Fume and Ground Granulated Blast Furnace Slag. Buildings. 2024; 14(4):1091. https://doi.org/10.3390/buildings14041091
Chicago/Turabian StyleAsif, Usama, Shazim Ali Memon, Muhammad Faisal Javed, and Jong Kim. 2024. "Predictive Modeling and Experimental Validation for Assessing the Mechanical Properties of Cementitious Composites Made with Silica Fume and Ground Granulated Blast Furnace Slag" Buildings 14, no. 4: 1091. https://doi.org/10.3390/buildings14041091
APA StyleAsif, U., Memon, S. A., Javed, M. F., & Kim, J. (2024). Predictive Modeling and Experimental Validation for Assessing the Mechanical Properties of Cementitious Composites Made with Silica Fume and Ground Granulated Blast Furnace Slag. Buildings, 14(4), 1091. https://doi.org/10.3390/buildings14041091