
Component Identification and Depth Estimation for Structural Images Based on Multi-Scale Task Interaction Network

Abstract
:1. Introduction
2. Methods
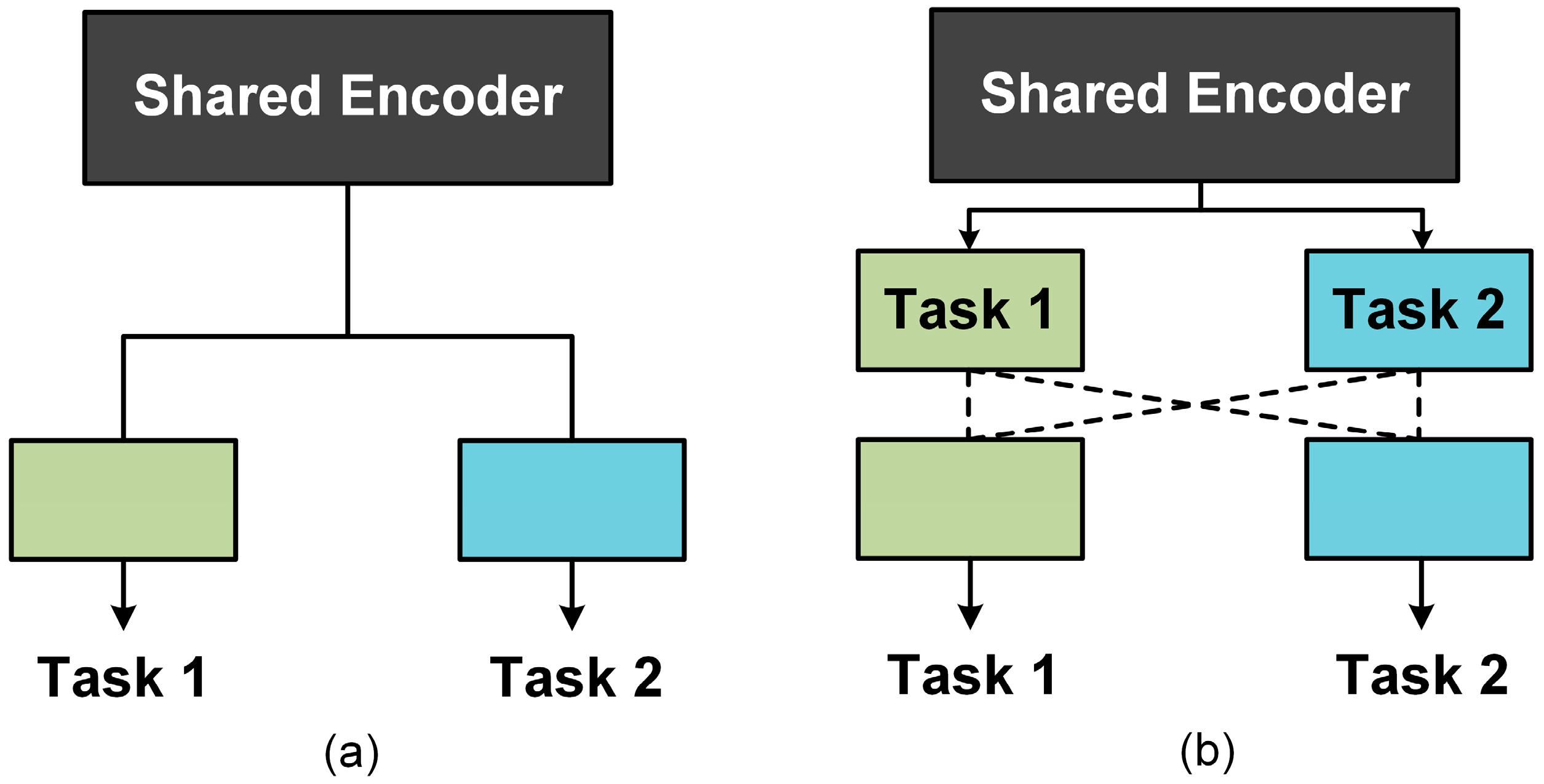
2.1. Multi-Task Deep Learning in Computer Vision
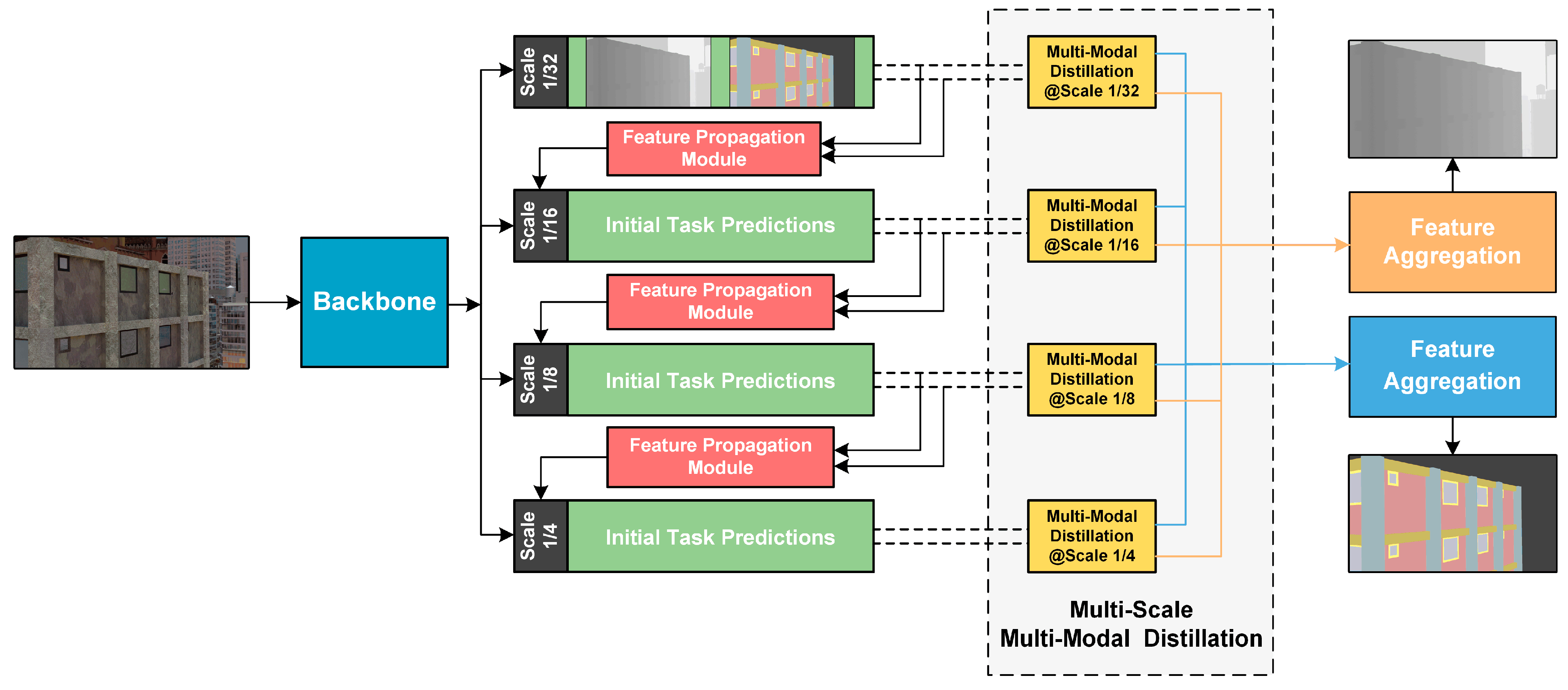
2.2. Multi-Scale Task Interaction Strategy
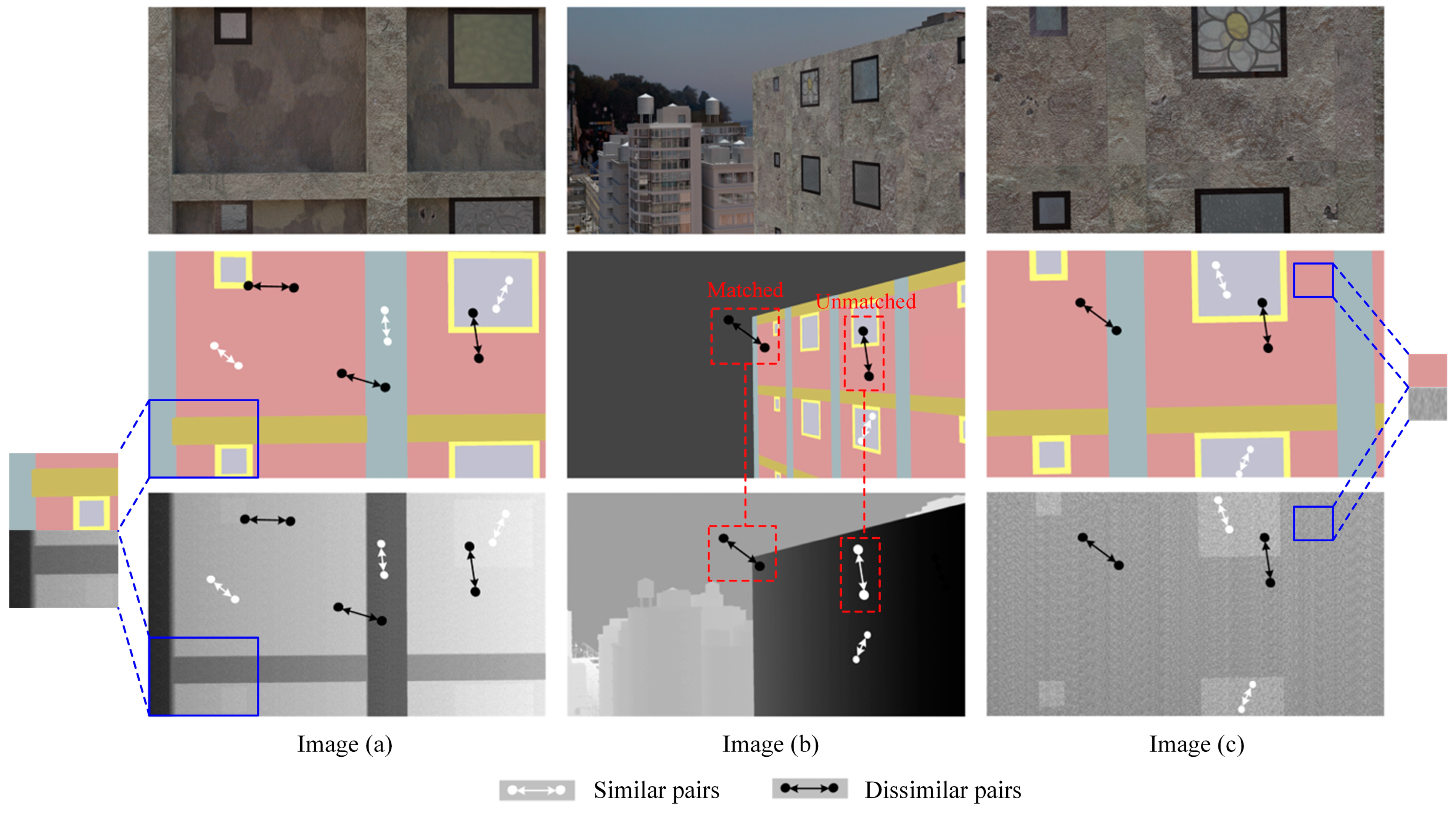
2.3. Pixel Affinity
2.4. Evaluation Metrics
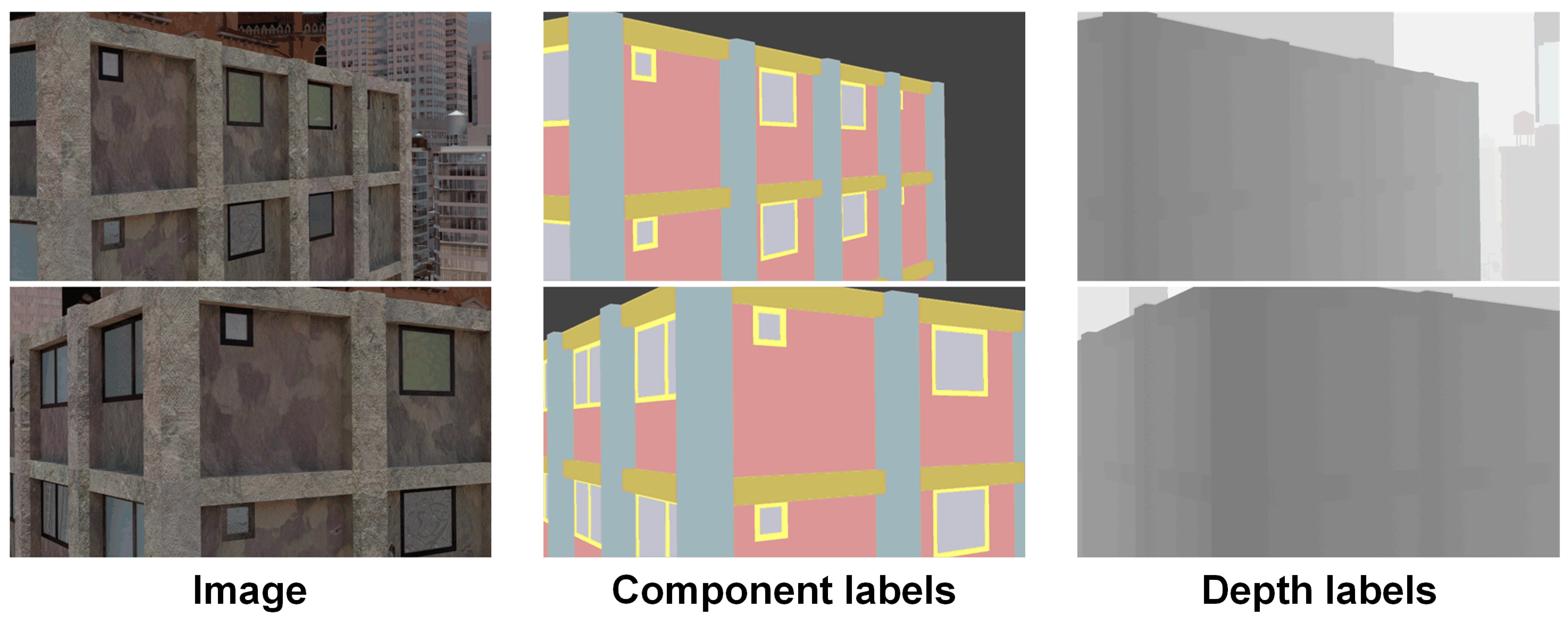
3. Dataset
4. Experiments and Results
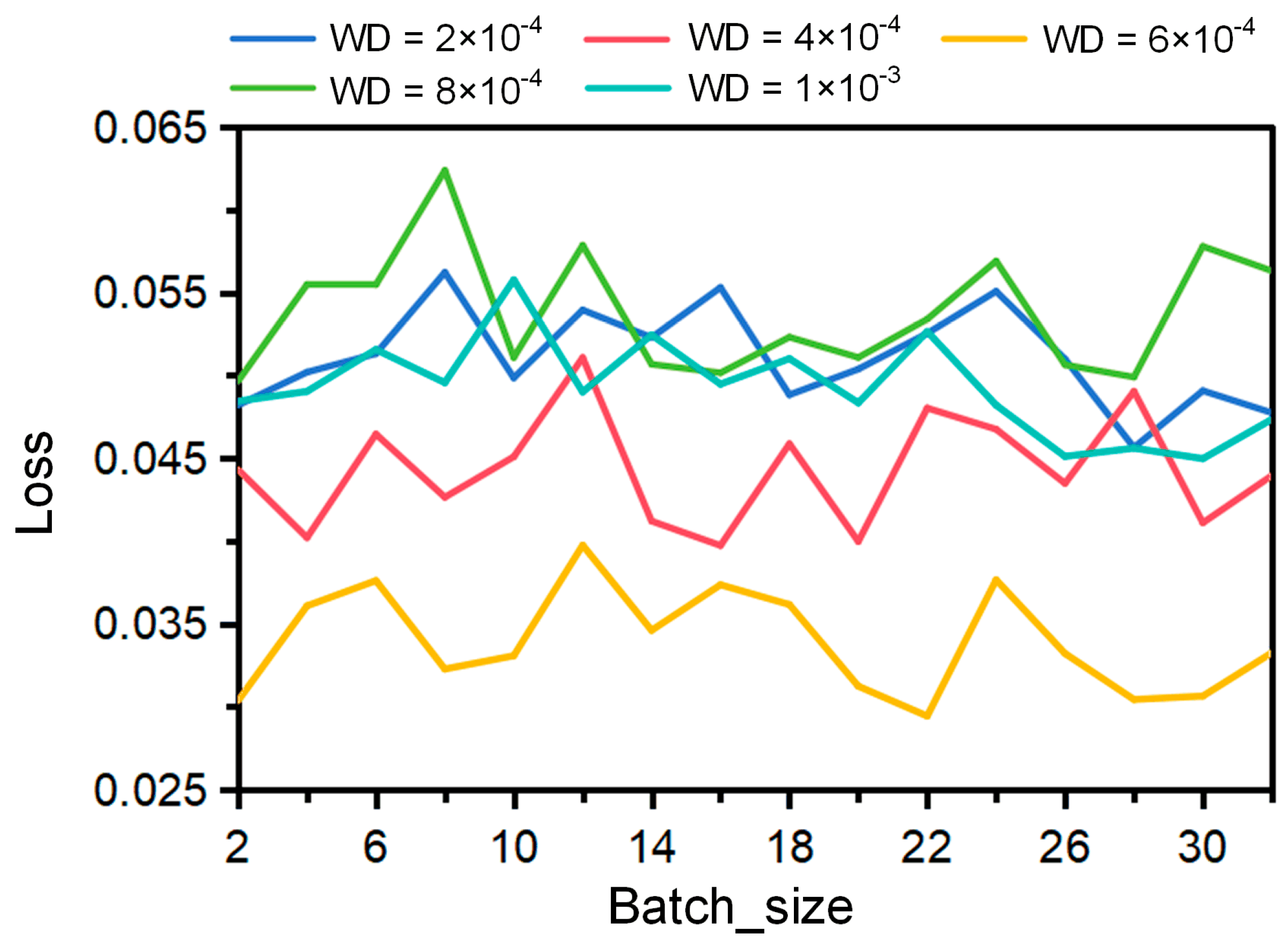
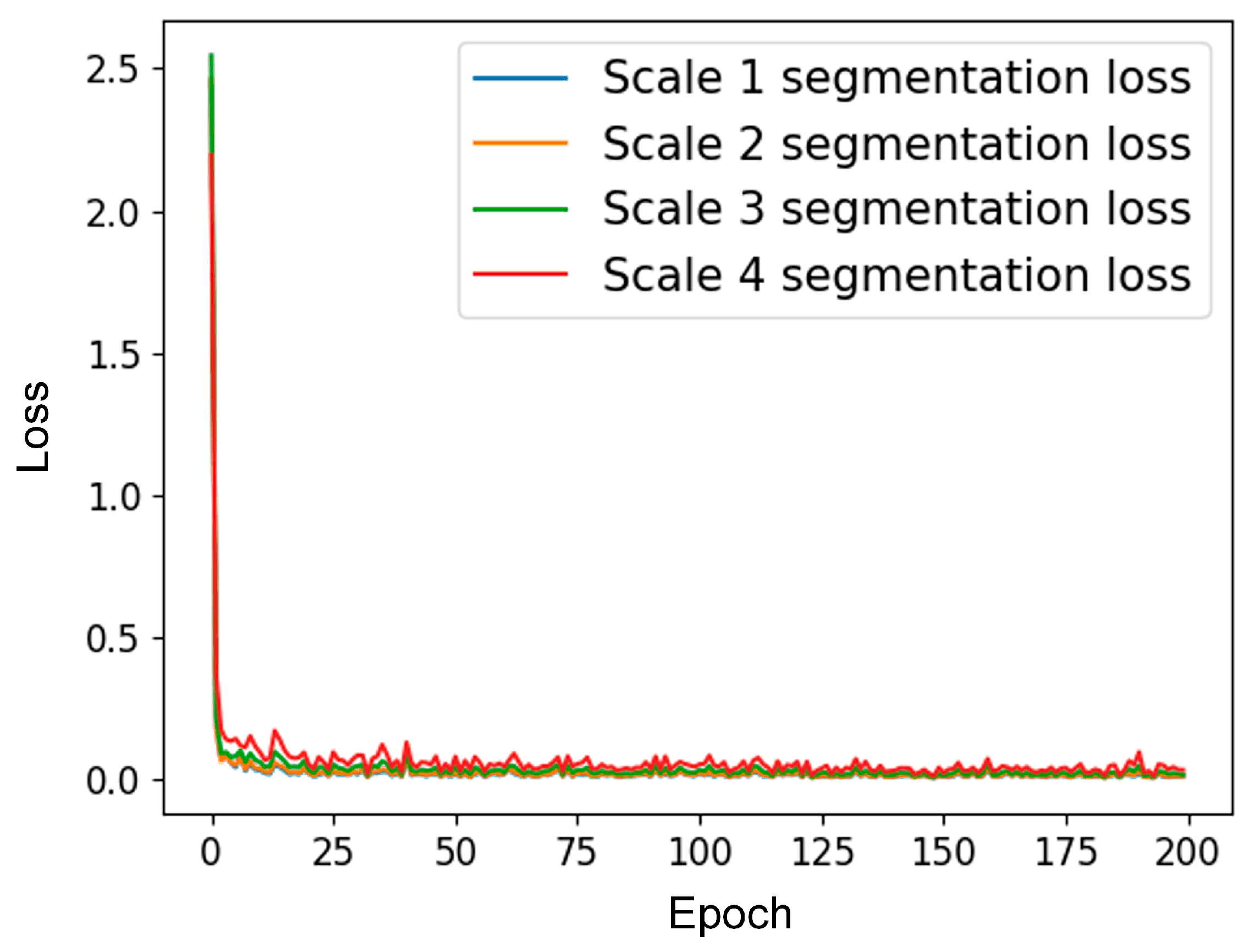
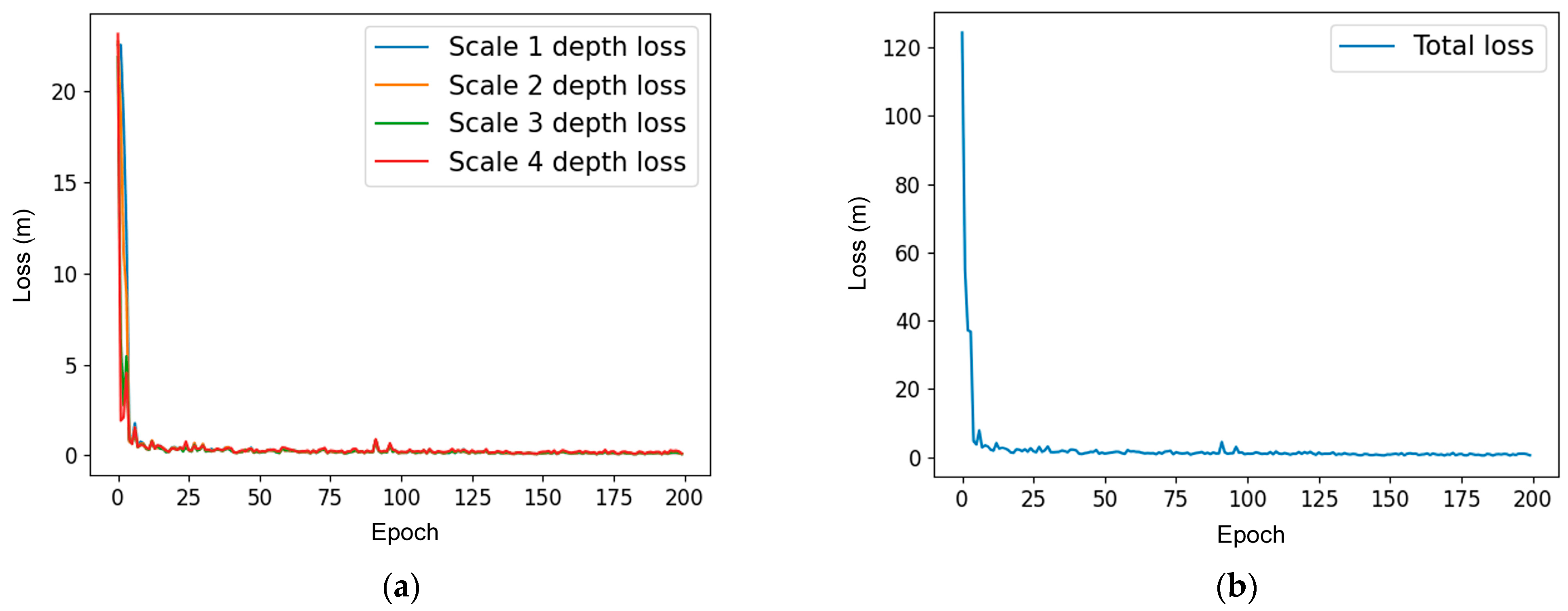
4.1. Experimental Setup
4.2. Computational Efficiency Results
4.3. Component Segmentation Results
4.4. Depth Estimation Results
5. Conclusions
- (1)
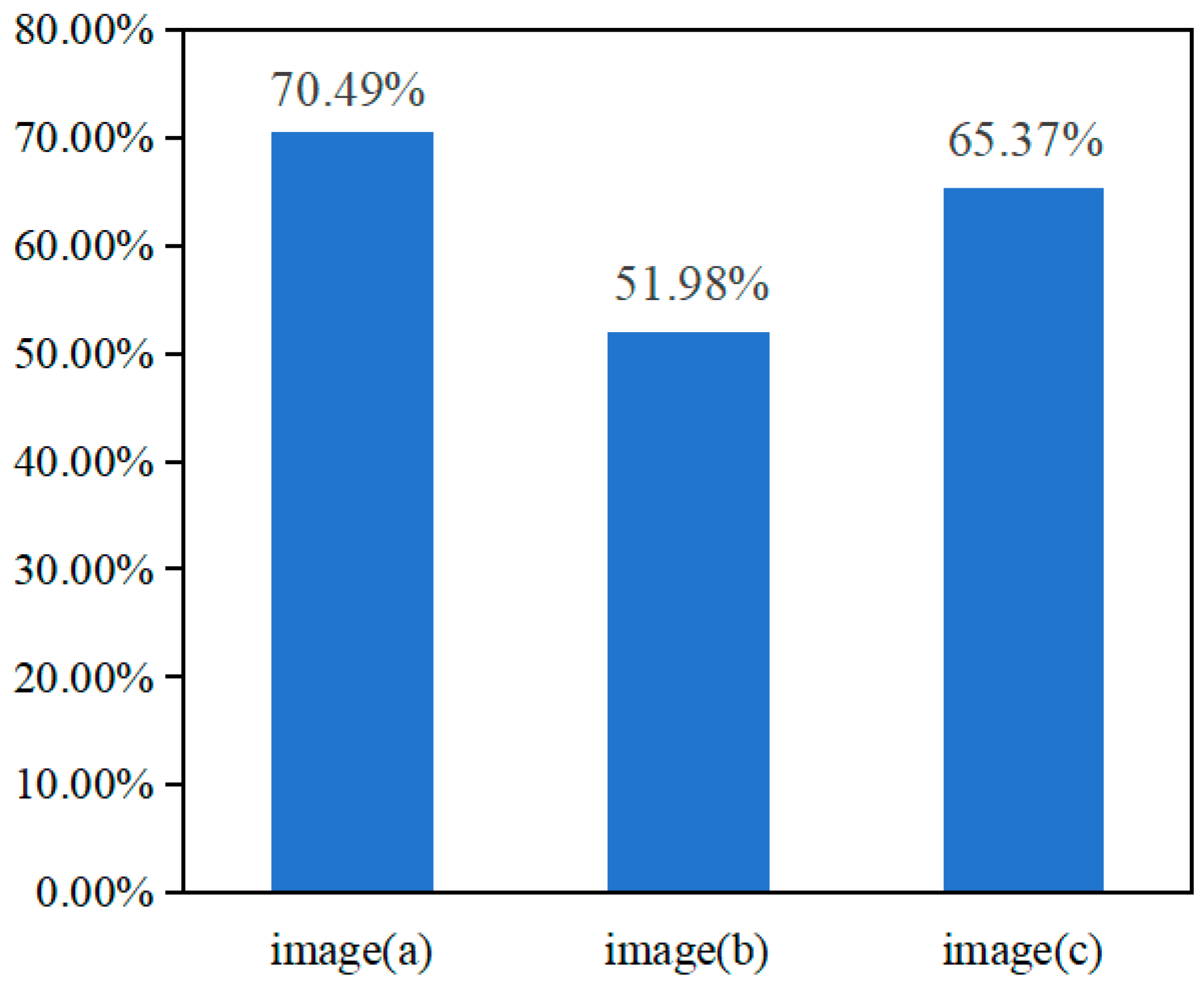
- Component segmentation and depth estimation are highly related tasks and have the potential to enhance each other’s performance. It is observed that the matched ratios of matching pixels between component segmentation and depth estimation account for a rather high value, reaching around 50–70% in the dataset, indicating that the dual tasks are very suitable for the multi-task learning strategy.
- (2)
- The proposed multi-task framework is superior to single-task networks concerning computational efficiency. Quantitative results indicate that MTI-Net has faster training and inference speed and lower memory footprint. As the multi-task framework distills features in shared layers for different tasks, it avoids repeatedly modeling and cuts down the computational cost.
- (3)
- Component segmentation and depth estimation are incorporated to carry out the multi-task learning strategy. Compared with the conventional single-task network, mean IoU in terms of component segmentation rose from 96.84% to 99.14%. The additional incorporation of depth information can provide spatial information of building images and can greatly improve the performance of component identification.
- (4)
- The RMSE of depth estimation decreases from 0.63 m for the single-task network to 0.27 m for the multi-task network. The proposed multi-task multi-scale deep learning network performs well in both tasks, and the component identification and depth map can provide each other with auxiliary information to achieve more accurate structural inspection.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kilic, G.; Caner, A. Augmented Reality for Bridge Condition Assessment Using Advanced Non-Destructive Techniques. Struct. Infrastruct. Eng. 2021, 17, 977–989. [Google Scholar] [CrossRef]
- Mishra, M.; Lourenço, P.B.; Ramana, G.V. Structural Health Monitoring of Civil Engineering Structures by Using the Internet of Things: A Review. J. Build. Eng. 2022, 48, 103954. [Google Scholar] [CrossRef]
- Sofi, A.; Jane Regita, J.; Rane, B.; Lau, H.H. Structural Health Monitoring Using Wireless Smart Sensor Network—An Overview. Mech. Syst. Signal Process. 2022, 163, 108113. [Google Scholar] [CrossRef]
- Gordan, M.; Sabbagh-Yazdi, S.-R.; Ismail, Z.; Ghaedi, K.; Carroll, P.; McCrum, D.; Samali, B. State-of-the-Art Review on Advancements of Data Mining in Structural Health Monitoring. Measurement 2022, 193, 110939. [Google Scholar] [CrossRef]
- Tian, Y.; Chen, C.; Sagoe-Crentsil, K.; Zhang, J.; Duan, W. Intelligent Robotic Systems for Structural Health Monitoring: Applications and Future Trends. Autom. Constr. 2022, 139, 104273. [Google Scholar] [CrossRef]
- Akbar, M.A.; Qidwai, U.; Jahanshahi, M.R. An Evaluation of Image-Based Structural Health Monitoring Using Integrated Unmanned Aerial Vehicle Platform. Struct. Control Health Monit. 2019, 26, e2276. [Google Scholar] [CrossRef]
- Insa-Iglesias, M.; Jenkins, M.D.; Morison, G. 3D Visual Inspection System Framework for Structural Condition Monitoring and Analysis. Autom. Constr. 2021, 128, 103755. [Google Scholar] [CrossRef]
- Dong, C.-Z.; Catbas, F.N. A Review of Computer Vision–Based Structural Health Monitoring at Local and Global Levels. Struct. Health Monit. 2021, 20, 692–743. [Google Scholar] [CrossRef]
- Deng, J.; Singh, A.; Zhou, Y.; Lu, Y.; Lee, V.C.-S. Review on Computer Vision-Based Crack Detection and Quantification Methodologies for Civil Structures. Constr. Build. Mater. 2022, 356, 129238. [Google Scholar] [CrossRef]
- Spencer, B.F.; Hoskere, V.; Narazaki, Y. Advances in Computer Vision-Based Civil Infrastructure Inspection and Monitoring. Engineering 2019, 5, 199–222. [Google Scholar] [CrossRef]
- Lenjani, A.; Yeum, C.M.; Dyke, S.; Bilionis, I. Automated Building Image Extraction from 360° Panoramas for Postdisaster Evaluation. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 241–257. [Google Scholar] [CrossRef]
- Wogen, B.E.; Choi, J.; Zhang, X.; Liu, X.; Iturburu, L.; Dyke, S.J. Automated Bridge Inspection Image Retrieval Based on Deep Similarity Learning and GPS. J. Struct. Eng. 2024, 150, 04023238. [Google Scholar] [CrossRef]
- Yeum, C.M.; Choi, J.; Dyke, S.J. Automated Region-of-Interest Localization and Classification for Vision-Based Visual Assessment of Civil Infrastructure. Struct. Health Monit. 2019, 18, 675–689. [Google Scholar] [CrossRef]
- Yeum, C.M.; Dyke, S.J.; Benes, B.; Hacker, T.; Ramirez, J.; Lund, A.; Pujol, S. Postevent Reconnaissance Image Documentation Using Automated Classification. J. Perform. Constr. Facil. 2019, 33, 04018103. [Google Scholar] [CrossRef]
- Aloisio, A.; Rosso, M.M.; De Leo, A.M.; Fragiacomo, M.; Basi, M. Damage Classification after the 2009 L’Aquila Earthquake Using Multinomial Logistic Regression and Neural Networks. Int. J. Disaster Risk Reduct. 2023, 96, 103959. [Google Scholar] [CrossRef]
- Yilmaz, M.; Dogan, G.; Arslan, M.H.; Ilki, A. Categorization of Post-Earthquake Damages in RC Structural Elements with Deep Learning Approach. J. Earthq. Eng. 2024, 1–32. [Google Scholar] [CrossRef]
- Khankeshizadeh, E.; Mohammadzadeh, A.; Arefi, H.; Mohsenifar, A.; Pirasteh, S.; Fan, E.; Li, H.; Li, J. A Novel Weighted Ensemble Transferred U-Net Based Model (WETUM) for Postearthquake Building Damage Assessment From UAV Data: A Comparison of Deep Learning- and Machine Learning-Based Approaches. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4701317. [Google Scholar] [CrossRef]
- Marano, G.C.; Quaranta, G. A New Possibilistic Reliability Index Definition. Acta Mech. 2010, 210, 291–303. [Google Scholar] [CrossRef]
- Gao, Y.; Mosalam, K.M. Deep Transfer Learning for Image-Based Structural Damage Recognition. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 748–768. [Google Scholar] [CrossRef]
- Liang, X. Image-Based Post-Disaster Inspection of Reinforced Concrete Bridge Systems Using Deep Learning with Bayesian Optimization. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 415–430. [Google Scholar] [CrossRef]
- Saida, T.; Rashid, M.; Nemoto, Y.; Tsukamoto, S.; Asai, T.; Nishio, M. CNN-Based Segmentation Frameworks for Structural Component and Earthquake Damage Determinations Using UAV Images. Earthq. Eng. Eng. Vib. 2023, 22, 359–369. [Google Scholar] [CrossRef]
- Wang, Y.; Jing, X.; Chen, W.; Li, H.; Xu, Y.; Zhang, Q. Geometry-Informed Deep Learning-Based Structural Component Segmentation of Post-Earthquake Buildings. Mech. Syst. Signal Process. 2023, 188, 110028. [Google Scholar] [CrossRef]
- Narazaki, Y.; Hoskere, V.; Hoang, T.A.; Fujino, Y.; Sakurai, A.; Spencer, B.F., Jr. Vision-Based Automated Bridge Component Recognition with High-Level Scene Consistency. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 465–482. [Google Scholar] [CrossRef]
- Narazaki, Y.; Hoskere, V.; Hoang, T.A.; Spencer, B.F., Jr. Automated Bridge Component Recognition Using Video Data. arXiv 2018, arXiv:1806.0682. [Google Scholar]
- Kim, H.; Yoon, J.; Sim, S.-H. Automated Bridge Component Recognition from Point Clouds Using Deep Learning. Struct. Control Health Monit. 2020, 27, e2591. [Google Scholar] [CrossRef]
- Lee, J.S.; Park, J.; Ryu, Y.-M. Semantic Segmentation of Bridge Components Based on Hierarchical Point Cloud Model. Autom. Constr. 2021, 130, 103847. [Google Scholar] [CrossRef]
- Kim, H.; Kim, C. Deep-Learning-Based Classification of Point Clouds for Bridge Inspection. Remote Sens. 2020, 12, 3757. [Google Scholar] [CrossRef]
- Xia, T.; Yang, J.; Chen, L. Automated Semantic Segmentation of Bridge Point Cloud Based on Local Descriptor and Machine Learning. Autom. Constr. 2022, 133, 103992. [Google Scholar] [CrossRef]
- Hoskere, V.; Narazaki, Y.; Hoang, T.A.; Spencer, B.F., Jr. MaDnet: Multi-Task Semantic Segmentation of Multiple Types of Structural Materials and Damage in Images of Civil Infrastructure. J. Civ. Struct. Health Monit. 2020, 10, 757–773. [Google Scholar] [CrossRef]
- Vandenhende, S.; Georgoulis, S.; Van Gool, L. MTI-Net: Multi-Scale Task Interaction Networks for Multi-Task Learning. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 527–543. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE Xplore: Piscataway, NJ, USA, 2015; pp. 2650–2658. [Google Scholar]
- Misra, I.; Shrivastava, A.; Gupta, A.; Hebert, M. Cross-Stitch Networks for Multi-Task Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE Xplore: Piscataway, NJ, USA, 2016; pp. 3994–4003. [Google Scholar]
- Gao, Y.; Ma, J.; Zhao, M.; Liu, W.; Yuille, A.L. NDDR-CNN: Layerwise Feature Fusing in Multi-Task CNNs by Neural Discriminative Dimensionality Reduction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; IEEE Xplore: Piscataway, NJ, USA, 2019; pp. 3205–3214. [Google Scholar]
- Liu, S.; Johns, E.; Davison, A.J. End-to-End Multi-Task Learning with Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; IEEE Xplore: Piscataway, NJ, USA, 2019; pp. 1871–1880. [Google Scholar]
- Lu, Y.; Kumar, A.; Zhai, S.; Cheng, Y.; Javidi, T.; Feris, R. Fully-Adaptive Feature Sharing in Multi-Task Networks with Applications in Person Attribute Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, Hawaii, 21–26 July 2017; IEEE Xplore: Piscataway, NJ, USA, 2017; pp. 5334–5343. [Google Scholar]
- Xu, D.; Ouyang, W.; Wang, X.; Sebe, N. PAD-Net: Multi-Tasks Guided Prediction-and-Distillation Network for Simultaneous Depth Estimation and Scene Parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; IEEE Xplore: Piscataway, NJ, USA, 2018; pp. 675–684. [Google Scholar]
- Zhang, Z.; Cui, Z.; Xu, C.; Yan, Y.; Sebe, N.; Yang, J. Pattern-Affinitive Propagation Across Depth, Surface Normal and Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; IEEE Xplore: Piscataway, NJ, USA, 2019; pp. 4106–4115. [Google Scholar]
- Zhang, Z.; Cui, Z.; Xu, C.; Jie, Z.; Li, X.; Yang, J. Joint Task-Recursive Learning for Semantic Segmentation and Depth Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; IEEE Xplore: Piscataway, NJ, USA, 2018; pp. 235–251. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; IEEE Xplore: Piscataway, NJ, USA, 2019; pp. 5693–5703. [Google Scholar]
- Hoskere, V.; Narazaki, Y.; Spencer, B.F. Physics-Based Graphics Models in 3D Synthetic Environments as Autonomous Vision-Based Inspection Testbeds. Sensors 2022, 22, 532. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Training Time | Inference latency | Parameter | FLOPS |
|---|---|---|---|---|
| Single model a 1 | −33% | −45% | −29% | −39% |
| Single model b 2 | −67% | −55% | −71% | −61% |
| Benchmark a + b | 89,076 s | 285 s | 11.9 M | 30.6 G |
| MTI-Net | −19% | −38% | −20% | −14% |
| Component | Single Task | MTI-Net | |
|---|---|---|---|
| Wall | 98.2195 | 99.6910 | 1.4715 |
| Beam | 97.2283 | 99.3113 | 2.0830 |
| Column | 97.1979 | 99.5937 | 2.3958 |
| Window frame | 89.0310 | 98.3641 | 9.3331 |
| Window pane | 97.5756 | 99.7225 | 2.1469 |
| Balcony | 99.0902 | 99.7582 | 0.6680 |
| Slab | 96.5930 | 96.7125 | 0.1195 |
| Ignore | 99.7461 | 99.9583 | 0.2122 |
| Mean | 96.8352 | 99.1389 | 2.3038 |
| Single Task | MTI-Net | |
|---|---|---|
| 0.6314 | 0.2662 | 0.3652 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, J.; Yu, H.; Liu, G.; Zhou, J.; Shu, J. Component Identification and Depth Estimation for Structural Images Based on Multi-Scale Task Interaction Network. Buildings 2024, 14, 983. https://doi.org/10.3390/buildings14040983
Ye J, Yu H, Liu G, Zhou J, Shu J. Component Identification and Depth Estimation for Structural Images Based on Multi-Scale Task Interaction Network. Buildings. 2024; 14(4):983. https://doi.org/10.3390/buildings14040983
Chicago/Turabian StyleYe, Jianlong, Hongchuan Yu, Gaoyang Liu, Jiong Zhou, and Jiangpeng Shu. 2024. "Component Identification and Depth Estimation for Structural Images Based on Multi-Scale Task Interaction Network" Buildings 14, no. 4: 983. https://doi.org/10.3390/buildings14040983
APA StyleYe, J., Yu, H., Liu, G., Zhou, J., & Shu, J. (2024). Component Identification and Depth Estimation for Structural Images Based on Multi-Scale Task Interaction Network. Buildings, 14(4), 983. https://doi.org/10.3390/buildings14040983