
Empirical Study on Real Estate Mass Appraisal Based on Dynamic Neural Networks

Abstract
:1. Introduction
2. Dataset Construction
2.1. Real Estate Feature Indicators Selection
2.2. Extraction of Locational Characteristics
2.3. Acquisition of Socio-Economic Characteristic Indicators
3. Data Preprocessing
3.1. Sample Case Selection
3.2. Quantification of Characteristic Indicators
3.3. Handling Missing and Outlier Values
3.4. Data Normalization Procedures
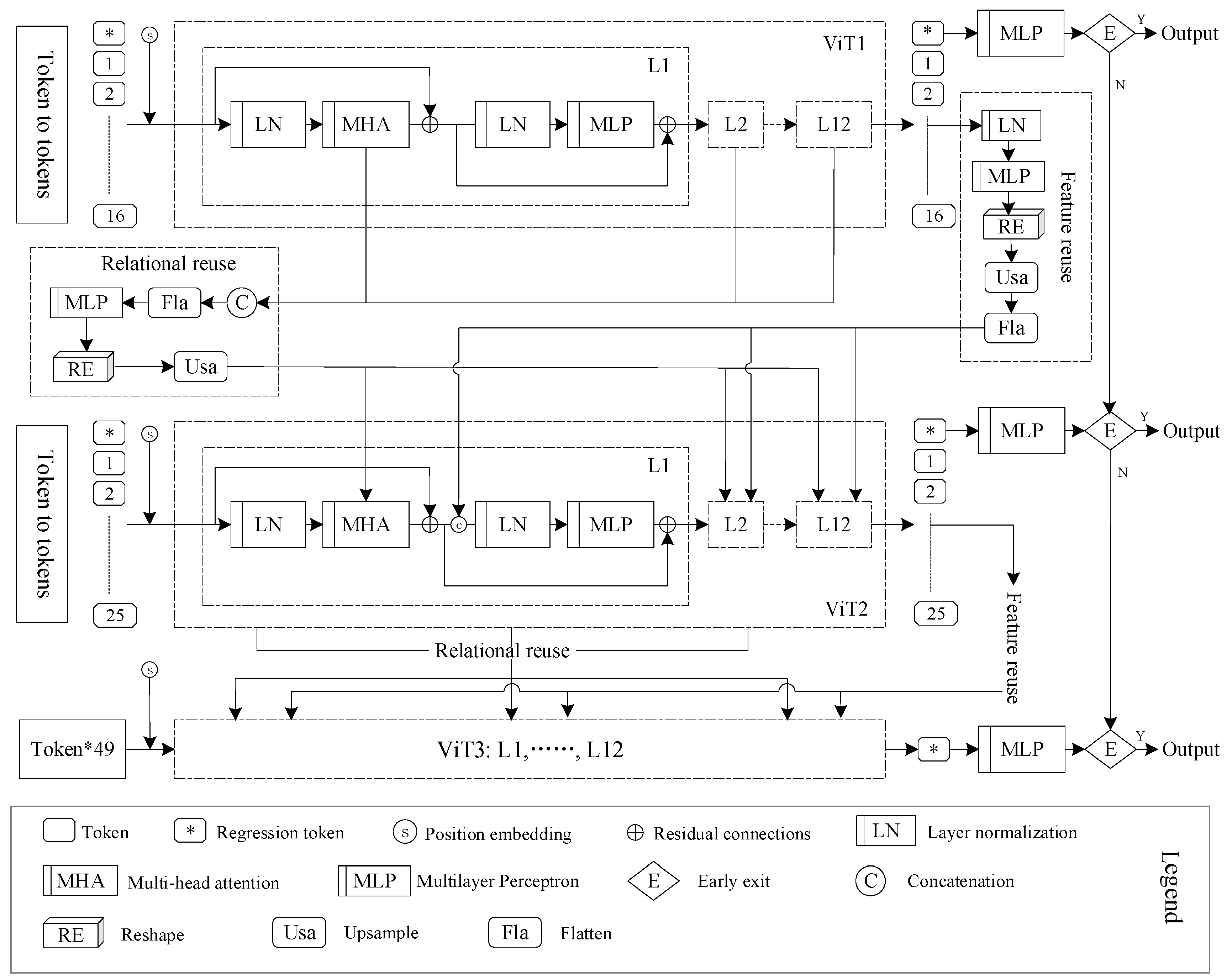
4. Model Construction
5. Mass Appraisal Results
5.1. Evaluation Dataset Split and Performance Metrics
5.2. Dynamic Neural Network Model Parameter Settings
5.3. Analysis of the Predictive Performance
5.4. Verification of the Effectiveness of Relationship and Feature Reuse
5.5. Real Mass Appraisal Evaluation Results
6. Model Comparative Analysis
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yousfi, S.; Dubé, J.; Legros, D.; Thanos, S. Mass appraisal without statistical estimation: A simplified comparable sales approach based on a spatiotemporal matrix. Ann. Reg. Sci. 2020, 64, 349–365. [Google Scholar] [CrossRef]
- Wang, D.; Li, V.J. Mass appraisal models of real estate in the 21st Century: A systematic literature review. Sustainability 2019, 11, 7006. [Google Scholar] [CrossRef]
- Dimopoulos, T.; Bakas, N.P. Sensitivity analysis of machine learning models for the mass appraisal of real estate. Case study of residential units in Nicosia, Cyprus. Remote Sens. 2019, 11, 3047. [Google Scholar] [CrossRef]
- Arribas, I.; García, F.; Guijarro, F.; Oliver, J.; Tamošiūnienė, R. Mass appraisal of residential real estate using multilevel modelling. Int. J. Strateg. Prop. Manag. 2016, 20, 77–87. [Google Scholar] [CrossRef]
- McCluskey, W.; McCord, M.; Davis, P.; Haran, M.; McIlhatton, D. Prediction accuracy in mass appraisal: A comparison of modern approaches. J. Prop. Res. 2013, 30, 239–265. [Google Scholar] [CrossRef]
- Zhang, R.; Du, Q.; Geng, J.; Liu, B.; Huang, Y. An improved spatial error model for the mass appraisal of commercial real estate based on spatial analysis: Shenzhen as a case study. Habitat Int. 2015, 46, 196–205. [Google Scholar] [CrossRef]
- Uberti, M.S.; Antunes, M.A.H.; Debiasi, P.; Tassinari, W. Mass appraisal of farmland using classical econometrics and spatial modeling. Land Use Policy 2018, 72, 161–170. [Google Scholar] [CrossRef]
- Bencure, J.C.; Tripathi, N.K.; Miyazaki, H.; Ninsawat, S.; Kim, S.M. Development of an innovative land valuation model (iLVM) for mass appraisal application in sub-urban areas Using AHP: An Integration of theoretical and practical approaches. Sustainability 2019, 11, 3731. [Google Scholar] [CrossRef]
- Zhao, Y.; Shen, X.; Ma, J.; Yu, M. Path selection of spatial econometric model for mass appraisal of real estate: Evidence from yinchuan. Int. J. Strateg. Prop. Manag. 2023, 27, 304–316. [Google Scholar] [CrossRef]
- Kilpatrick, J. Expert systems and mass appraisal. J. Prop. Invest. Financ. 2011, 29, 529–550. [Google Scholar] [CrossRef]
- Doszyń, M. Might expert knowledge improve econometric real estate mass appraisal? J. Real Estate Financ. Econ. 2022, 1–22. [Google Scholar] [CrossRef]
- Zurada, J.; Levitan, A.S.; Guan, J. A Comparison of regression and artificial Intelligence methods in a mass appraisal context. J. Real Estate Res. 2011, 33, 349–387. [Google Scholar] [CrossRef]
- Hong, J.; Choi, H.; Kim, W.S. A house price valuation based on the random forest approach: The mass appraisal of residential property in South Korea. Int. J. Strateg. Prop. Manag. 2020, 24, 140–152. [Google Scholar] [CrossRef]
- Morano, P.; Tajani, F.; Locurcio, M. Multicriteria analysis and genetic algorithms for mass appraisals in the Italian property market. Int. J. Hous. Mark. Anal. 2018, 11, 229–262. [Google Scholar] [CrossRef]
- Morano, P.; Rosato, P.; Tajani, F.; Manganelli, B.; Di Liddo, F. Contextualized property market models vs. Generalized mass appraisals: An innovative approach. Sustainability 2019, 11, 4896. [Google Scholar] [CrossRef]
- Reyes-Bueno, F.; García-Samaniego, J.M.; Sánchez-Rodríguez, A. Large-scale simultaneous market segment definition and mass appraisal using decision tree learning for fiscal purposes. Land Use Policy 2018, 79, 116–122. [Google Scholar] [CrossRef]
- Antipov, E.A.; Pokryshevskaya, E.B. Mass appraisal of residential apartments: An application of random forest for valuation and a CART-based approach for model diagnostics. Expert Syst. Appl. 2012, 39, 1772–1778. [Google Scholar] [CrossRef]
- Yilmazer, S.; Kocaman, S. A mass appraisal assessment study using machine learning based on multiple regression and random forest. Land Use Policy 2020, 99, 104889. [Google Scholar] [CrossRef]
- Chun Lin, C.; Mohan, S.B. Effectiveness comparison of the residential property mass appraisal methodologies in the USA. Int. J. Hous. Mark. Anal. 2011, 4, 224–243. [Google Scholar] [CrossRef]
- McCluskey, W.; Davis, P.; Haran, M.; McCord, M.; McIlhatton, D. The potential of artificial neural networks in mass appraisal: The case revisited. J. Financ. Manag. Prop. Constr. 2012, 17, 274–292. [Google Scholar] [CrossRef]
- Yacim, J.A.; Boshoff, D.G.B.; Khan, A. Hybridizing Cuckoo Search with Levenberg-Marquardt algorithms in optimization and training of ANNs for mass appraisal of properties. J. Real Estate Lit. 2016, 24, 473–492. [Google Scholar] [CrossRef]
- Yacim, J.A.; Boshoff, D.G.B. Combining BP with PSO algorithms in weights optimisation and ANNs training for mass appraisal of properties. Int. J. Hous. Mark. Anal. 2018, 11, 290–314. [Google Scholar] [CrossRef]
- Torres-Pruñonosa, J.; García-Estévez, P.; Prado-Román, C. Artificial neural network, quantile and Semi-Log regression modelling of mass appraisal in Housing. Mathematics 2021, 9, 783. [Google Scholar] [CrossRef]
- Iban, M.C. An explainable model for the mass appraisal of residences: The application of tree-based machine learning algorithms and interpretation of value determinants. Habitat Int. 2022, 128, 102660. [Google Scholar] [CrossRef]
- Carranza, J.P.; Piumetto, M.A.; Lucca, C.M.; Da Silva, E. Mass appraisal as affordable public policy: Open data and machine learning for mapping urban land values. Land Use Policy 2022, 119, 106211. [Google Scholar] [CrossRef]
- McCord, M.; Lo, D.; Davis, P.; McCord, J.; Hermans, L.; Bidanset, P. Applying the geostatistical eigenvector spatial filter approach into regularized regression for Improving prediction accuracy for mass appraisal. Appl. Sci. 2022, 12, 10660. [Google Scholar] [CrossRef]
- Bilgilioglu, S.S.; Yilmaz, H.M. Comparison of different machine learning models for mass appraisal of real estate. Surv. Rev. 2023, 55, 32–43. [Google Scholar] [CrossRef]
- Dearmon, J.; Smith, T.E. A Local gaussian process regression approach to mass appraisal of residential properties. J. Real Estate Financ. Econ. 2024, 1–19. [Google Scholar] [CrossRef]
- Yasnitsky, L.N.; Yasnitsky, V.L.; Alekseev, A.O. The complex neural network model for mass appraisal and scenario forecasting of the urban real estate market value that adapts Itself to space and time. Complexity 2021, 2021, 5392170. [Google Scholar] [CrossRef]
- Han, Y.; Huang, G.; Song, S.; Yang, L.; Wang, H.; Wang, Y. Dynamic neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7436–7456. [Google Scholar] [CrossRef]
- Chau, K.W.; Chin, T.L. A critical review of literature on the hedonic price model. Int. J. Hous. Sci. Its Appl. 2003, 27, 145–165. [Google Scholar]
- Walacik, M.; Chmielewska, A. Real Estate Industry Sustainable Solution (Environmental, Social, and Governance) Significance Assessment-AI-Powered Algorithm Implementation. Sustainability 2024, 16, 1079. [Google Scholar] [CrossRef]
- Zhan, W.; Hu, Y.; Zeng, W.; Fang, X.; Kang, X.; Li, D. Total Least Squares Estimation in Hedonic House Price Models. ISPRS Int. J. Geo-Inf. 2024, 13, 159. [Google Scholar] [CrossRef]
- Rey-Blanco, D.; Zofío, J.L.; González-Arias, J. Improving hedonic housing price models by integrating optimal accessibility indices into regression and random forest analyses. Expert Syst. Appl. 2024, 235, 121059. [Google Scholar] [CrossRef]
- Cardone, B.; Di Martino, F.; Senatore, S. Real estate price estimation through a fuzzy partition-driven genetic algorithm. Inf. Sci. 2024, 667, 120442. [Google Scholar] [CrossRef]
- Unel, F.B.; Yalpir, S. Sustainable tax system design for use of mass real estate appraisal in land management. Land Use Policy 2023, 131, 106734. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, J.P. Application of geographic Information system on urban residential real estate mass appraisal. Appl. Mech. Mater. 2015, 744, 1665–1668. [Google Scholar] [CrossRef]
- Chen, S.Q.; Wang, H.W. Machine Learning-Based Mass Appraisal Model for Real Estate, Statistics and Decision Making; Tongfang CNKI (Beijing) Technology Co., Ltd.: Beijing, China, 2020; Volume 36, pp. 181–185. [Google Scholar] [CrossRef]
- Huang, G.; Chen, D.; Li, T.; Wu, F.; Van Der Maaten, L.; Weinberger, K.Q. Multi-scale dense networks for resource efficient image classification [EB/OL]. arXiv 2017. https://arxiv.org/abs/1703.09844.
- Yang, L.; Han, Y.; Chen, X.; Song, S.; Dai, J.; Huang, G. Resolution adaptive networks for efficient inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2366–2375. [Google Scholar]
- De Salvo, M.; Signorello, G.; Cucuzza, G.; Begalli, D.; Agnoli, L. Estimating preferences for controlling beach erosion in Sicily. Aestimum 2018, 72, 27–38. [Google Scholar]
- d’Amato, M.; Cucuzza, G. Cyclical capitalization: Basic models. Aestimum 2022, 80, 45–54. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Type | Indicators |
|---|---|
| Individual characteristics | Area, internal area, layout, layout structure, orientation, decoration, year of construction, elevator, elevator-to-unit ratio, total floors, floor level, building structure, building type, total number of units, total number of buildings, parking space ratio, property management fee, greening rate, plot ratio, property usage, ownership, years of property ownership. |
| Locational characteristics | CBD, administrative district, commercial district, longitude, latitude, subway station, bus station, high school, primary school, kindergarten, general hospital, health center, bank, shopping mall, supermarket, convenience store, market, restaurant, cinema, sports facility, scenic spot, park square. |
| Socio-Economic characteristics | Economic environment, inflation, household income, financial policies, real estate policies, supply and demand of housing, consumer preferences, market participants’ expectations. |
| Indicator | Data Type | Indicator | Data Type | Indicator | Data Type |
|---|---|---|---|---|---|
| Area | Numerical value | Building structure | Classification | Administrative district | Classification |
| Internal area | Numerical value | Building type | Classification | Commercial district | Classification |
| layout | Classification | Total households | Numerical value | Longitude (BD09) | Numerical value |
| Unit layout structure | Classification | Total buildings | Numerical value | Latitude (BD09) | Numerical value |
| Orientation | Classification | Ratio of parking space | Numerical value | Community link | URL |
| Decoration | Classification | Property management fee | Numerical value | Property link | URL |
| Year of construction | Time | Greenery ratio | Numerical value | Transaction link | Time |
| Elevator | Classification | Plot ratio | Numerical value | Transaction timing | Numerical value |
| Ratio of elevator to households | Numerical value | Housing use | Classification | Transaction price | Numerical value |
| Total number of floors | Numerical value | Ownership of transaction | Classification | Water usage type | Classification |
| Floors level | Classification | Housing age limit | Classification | Electricity usage type | Classification |
| POI Data Category | District Characteristics | POI Data Category | District Characteristics |
|---|---|---|---|
| Address information | CBD | Shopping services | Shopping mall, supermarket, convenience store, market |
| Transportation services | Subway station, bus station | Catering services | Restaurant, fast food restaurant, beverage shop |
| Education services | High school, primary school and kindergarten | Sports and leisure services | Cinema, theater |
| Medical services | General hospital, health center | Scenic spots | Parks, squares |
| Financial services | bank | - | - |
| Characteristic | Quantitative Methodology | Theoretical Expectation Symbols |
|---|---|---|
| Area | Actual value (m2) | + |
| Internal area | Actual value (m2) | + |
| Living room | Actual value (m2) | + |
| Bedroom | Actual value (m2) | + |
| Bath | Actual value (m2) | + |
| Layout structure | Split-level, duplex, loft (2), flat (1) | + |
| Orientation | Facing south (4), facing southeast and southwest (3), Facing east and west (2), others (1) | + |
| Decoration | Well-furnished (3), simply furnished (2), rough (1) | + |
| Age of housing | Transaction year-year of completion | − |
| Elevator | Yes (2), No (1) | + |
| Elevator to unit ratio | Actual value | + |
| Total floors | Actual value (floor) | − |
| Floor level | Middle (2), lower and higher (1) | + |
| Building structure | Reinforced concrete (6), brick concrete (5), mixed (4), Framework (3), steel (2), brick and wood (1) | + |
| Building type | Flat (4), flat and tower (3), tower (2), bungalow (1) | + |
| Total number of units | Actual value | − |
| Total number of buildings | Actual value | + |
| Parking space | Actual value | + |
| Property fee | Actual value (yuan/m2/month) | + |
| Greening ratio | Actual value (%) | + |
| Plot ratio | Actual value | − |
| Property usage | Villa (5), Garden villa (4), conventional property (3), model lane (2), traditional lane (1) | + |
| Ownership rights | Commercial (2), relocation resettlement (1) | + |
| Property lease duration | Five year (3), two year (2), less than two year (1) | + |
| Location characteristics | - | - |
| Distance from CBD | Euclidean distance (km) | − |
| Administrative district | Huangpu (16), Jingan (15), Xuhui (14), Changning (13), Yangpu (12), Hongkou (11), Putuo (10), Pudong (9), Minhang (8), Baoshan (7), Qingpu (6), Songjiang (5), Jiaidng (4), Fengxian (3), Chongming (2), Jingshan (1) | + |
| Commercial district | Dummy variable (Random) | Indeterminate |
| Longitude | Actual value (BD09 coordinates) | Indeterminate |
| Latitude | Actual value (BD09 coordinates) | Indeterminate |
| Subway station distance | Nearest distance (km) | − |
| Bus station distance | Nearest distance (km) | − |
| Subway station number | Quantity with 1 km (2), quantity with 2 km (1) | + |
| Bus station number | Quantity with 1 km | + |
| Distance to high school | Nearest distance (km) | − |
| Distance to primary school | Nearest distance (km) | − |
| Distance to kindergarten | Nearest distance (km) | − |
| Distance to general hospital | Nearest distance (km) | + |
| Distance to health center | Nearest distance (km) | + |
| bank | Quantity with 1 km (2), quantity with 2 km (1) | + |
| Shopping mall | Quantity with 1 km (2), quantity with 2 km (1) | + |
| Supermarket | Quantity with 1 km (2), quantity with 2 km (1) | − |
| Convenience stores | Quantity with 1 km | + |
| Distance to market | Nearest distance (km) | − |
| Restaurants | Quantity with 1 km (2), quantity with 2 km (1) | + |
| Fast food outlet | Quantity with 1 km (2), quantity with 2 km (1) | − |
| Beverage shops | Quantity with 1 km (2), quantity with 2 km (1) | + |
| Cinemas | Quantity with 1 km (2), quantity with 2 km (1) | + |
| Sports facilities | Quantity with 1 km (2), quantity with 2 km (1) | + |
| Scenic spots | Quantity with 1 km (2), quantity with 2 km (1) | − |
| Parks and squares | Quantity with 1 km (2), quantity with 2 km (1) | + |
| Socio-economic characteristics | - | - |
| Smoothed adjustment coefficient | Actual value | + |
| Characteristic | Quantity | Processing Rules | Characteristic | Quantity | Processing Rules |
|---|---|---|---|---|---|
| Transaction price | 28 | Deleting cases | Structure | 410 | Deleting cases |
| Internal area | 215,131 | Deleting feature | Type | 181 | Deleting cases |
| layout | 3417 | Deleting cases | Parking to unit ratio | 9145 | Deleting cases |
| Layout structure | 144,438 | Mode imputation | Property management fee | 860 | Deleting cases |
| Orientation | 16,896 | Mean imputation | Greening rate | 11,249 | Deleting cases |
| Decoration | 136,858 | Mean imputation | Plot ratio | 4298 | Deleting cases |
| Year of construction | 177 | Deleting cases | Property age limit | 246,938 | Deleting feature |
| Elevator | 2896 | Deleting cases | - | - | - |
| Parameters | Parameter Setting |
|---|---|
| Size | 512 |
| Optimizer | Adamax, 0.0005 |
| Loss function | Absolute loss function |
| Normalization | Normalize both the feature variable using Z-score standardization |
| Maximum number of iterations | 75, 25 |
| MAPE | MAE | RMSE | R2 | |||
|---|---|---|---|---|---|---|
| Fold1 | Training set | Out1 | 6.582502 | 24.983809 | 70.879814 | 0.963392 |
| Out2 | 5.423621 | 20.559443 | 67.747513 | 0.966556 | ||
| Out3 | 5.238632 | 20.309767 | 67.341919 | 0.966955 | ||
| Validation set | Out1 | 8.287363 | 36.023987 | 83.487915 | 0.945973 | |
| Out2 | 7.855760 | 34.425793 | 82.405426 | 0.947365 | ||
| Out3 | 7.688116 | 34.158836 | 83.090019 | 0.946487 | ||
| Fold2 | Training set | Out1 | 6.572026 | 24.770119 | 66.029747 | 0.967751 |
| Out2 | 5.854780 | 23.076227 | 65.405807 | 0.968357 | ||
| Out3 | 5.439150 | 21.075333 | 62.937225 | 0.970701 | ||
| Validation set | Out1 | 8.409850 | 35.866158 | 110.660057 | 0.910733 | |
| Out2 | 7.951491 | 34.931698 | 110.155144 | 0.911545 | ||
| Out3 | 7.858031 | 34.483894 | 109.478119 | 0.912629 | ||
| Fold3 | Training set | Out1 | 7.153530 | 27.895760 | 74.618797 | 0.959092 |
| Out2 | 4.877150 | 18.729902 | 68.677696 | 0.965347 | ||
| Out3 | 4.623269 | 17.947077 | 66.300896 | 0.967704 | ||
| Validation set | Out1 | 8.751267 | 37.590763 | 93.737366 | 0.934191 | |
| Out2 | 7.933979 | 34.954685 | 91.732445 | 0.936976 | ||
| Out3 | 7.611889 | 34.107365 | 90.031654 | 0.939291 | ||
| Fold4 | Training set | Out1 | 7.310944 | 29.143776 | 71.890549 | 0.960641 |
| Out2 | 4.759374 | 19.062849 | 62.082413 | 0.970648 | ||
| Out3 | 4.801227 | 19.073774 | 60.440533 | 0.972180 | ||
| Validation set | Out1 | 8.662125 | 39.258278 | 112.789848 | 0.916685 | |
| Out2 | 7.944169 | 36.775803 | 111.652557 | 0.918357 | ||
| Out3 | 7.893782 | 36.247406 | 108.981903 | 0.922216 | ||
| Fold5 | Training set | Out1 | 6.830754 | 26.634205 | 72.839317 | 0.961583 |
| Out2 | 6.590454 | 26.017817 | 71.017235 | 0.963481 | ||
| Out3 | 5.525959 | 21.393906 | 68.016922 | 0.966502 | ||
| Validation set | Out1 | 8.618005 | 36.875156 | 88.689461 | 0.937333 | |
| Out2 | 8.400989 | 36.270206 | 87.598625 | 0.938865 | ||
| Out3 | 7.958053 | 34.505462 | 86.413239 | 0.940508 |
| MAPE | MAE | RMSE | R2 | |||
|---|---|---|---|---|---|---|
| Fold1 | Training set | Out1 | 6.280432 | 24.876728 | 70.327866 | 0.963960 |
| Out2 | 5.083012 | 19.192019 | 68.024574 | 0.966282 | ||
| Out3 | 5.354226 | 21.244509 | 71.564575 | 0.962681 | ||
| Validation set | Out1 | 8.189092 | 36.558029 | 88.162560 | 0.939754 | |
| Out2 | 7.846367 | 35.320896 | 90.475708 | 0.936551 | ||
| Out3 | 7.960067 | 36.351112 | 96.090004 | 0.928432 | ||
| Fold2 | Training set | Out1 | 5.279011 | 19.738766 | 53.211971 | 0.979056 |
| Out2 | 5.029600 | 18.977011 | 54.899643 | 0.977706 | ||
| Out3 | 4.318735 | 15.962884 | 58.919735 | 0.974322 | ||
| Validation set | Out1 | 8.084276 | 35.674702 | 110.581459 | 0.910859 | |
| Out2 | 7.874303 | 35.196781 | 112.541832 | 0.907671 | ||
| Out3 | 7.774843 | 35.124073 | 119.312988 | 0.896227 | ||
| Fold3 | Training set | Out1 | 6.450404 | 25.219858 | 68.763458 | 0.965260 |
| Out2 | 6.172630 | 24.344225 | 73.040146 | 0.960805 | ||
| Out3 | 5.171786 | 19.415365 | 70.090607 | 0.963906 | ||
| Validation set | Out1 | 8.178583 | 35.226971 | 85.669205 | 0.945032 | |
| Out2 | 8.333623 | 36.847321 | 96.665001 | 0.930016 | ||
| Out3 | 7.873034 | 35.293766 | 102.016411 | 0.922052 | ||
| Fold4 | Training set | Out1 | 6.542130 | 25.513079 | 65.900955 | 0.966926 |
| Out2 | 5.214116 | 19.814548 | 64.580650 | 0.968238 | ||
| Out3 | 4.968793 | 19.260939 | 65.202042 | 0.967624 | ||
| Validation set | Out1 | 8.226849 | 37.212627 | 112.413467 | 0.917240 | |
| Out2 | 7.973021 | 36.835815 | 117.798599 | 0.909121 | ||
| Out3 | 8.087622 | 37.724483 | 122.078674 | 0.902397 | ||
| Fold5 | Training set | Out1 | 6.671336 | 26.329666 | 76.261787 | 0.957888 |
| Out2 | 5.925183 | 23.713930 | 74.932312 | 0.959344 | ||
| Out3 | 5.715444 | 22.097775 | 75.527740 | 0.958695 | ||
| Validation set | Out1 | 8.394048 | 36.008690 | 90.072845 | 0.935363 | |
| Out2 | 8.168652 | 35.909081 | 93.465927 | 0.930401 | ||
| Out3 | 8.293054 | 36.042675 | 96.629173 | 0.925610 |
| MAPE | MAE | RMSE | R2 | ||
|---|---|---|---|---|---|
| Fold1 | Training set | 5.733302 | 21.887262 | 68.645737 | 0.965663 |
| Validation set | 7.944661 | 34.873470 | 83.153336 | 0.946405 | |
| Fold2 | Training set | 5.937993 | 22.919348 | 65.170738 | 0.968584 |
| Validation set | 8.090828 | 35.148426 | 110.563599 | 0.910888 | |
| Fold3 | Training set | 5.539233 | 21.470678 | 70.377716 | 0.963610 |
| Validation set | 8.148492 | 35.579693 | 91.269135 | 0.937611 | |
| Fold4 | Training set | 5.601123 | 22.318249 | 64.984169 | 0.967840 |
| Validation set | 8.208256 | 37.563663 | 111.897202 | 0.917999 | |
| Fold5 | Training set | 6.265540 | 24.529627 | 71.089607 | 0.963407 |
| Validation set | 8.364384 | 36.068787 | 88.551712 | 0.937527 | |
| Average | Training set | 5.815438 | 22.625033 | 68.053593 | 0.965821 |
| Validation set | 8.151324 | 35.846808 | 97.086996 | 0.930086 |
| MAPE | MAE | RMSE | R2 | ||
|---|---|---|---|---|---|
| Dynamic neural network model | Training set | 5.036730 | 19.160849 | 62.783176 | 0.970929 |
| Validation set | 7.444632 | 33.046982 | 96.708458 | 0.930406 | |
| Multivariate regression model | Training set | 14.571461 | 63.687946 | 137.256558 | 0.861058 |
| Validation set | 14.545142 | 63.470088 | 139.588094 | 0.855009 | |
| BP neural network model | Training set | 16.705354 | 65.148232 | 117.553528 | 0.898085 |
| Validation set | 16.640142 | 65.064880 | 116.835655 | 0.898423 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.; Ma, X.; Zhang, X. Empirical Study on Real Estate Mass Appraisal Based on Dynamic Neural Networks. Buildings 2024, 14, 2199. https://doi.org/10.3390/buildings14072199
Chen C, Ma X, Zhang X. Empirical Study on Real Estate Mass Appraisal Based on Dynamic Neural Networks. Buildings. 2024; 14(7):2199. https://doi.org/10.3390/buildings14072199
Chicago/Turabian StyleChen, Chao, Xinsheng Ma, and Xiaojia Zhang. 2024. "Empirical Study on Real Estate Mass Appraisal Based on Dynamic Neural Networks" Buildings 14, no. 7: 2199. https://doi.org/10.3390/buildings14072199