
Evaluating Radiance Field-Inspired Methods for 3D Indoor Reconstruction: A Comparative Analysis




Abstract
1. Introduction
2. Related Work
2.1. LiDAR-Based Methods
2.2. RGB-D-Based Methods
2.3. Photogrammetry-Based Methods
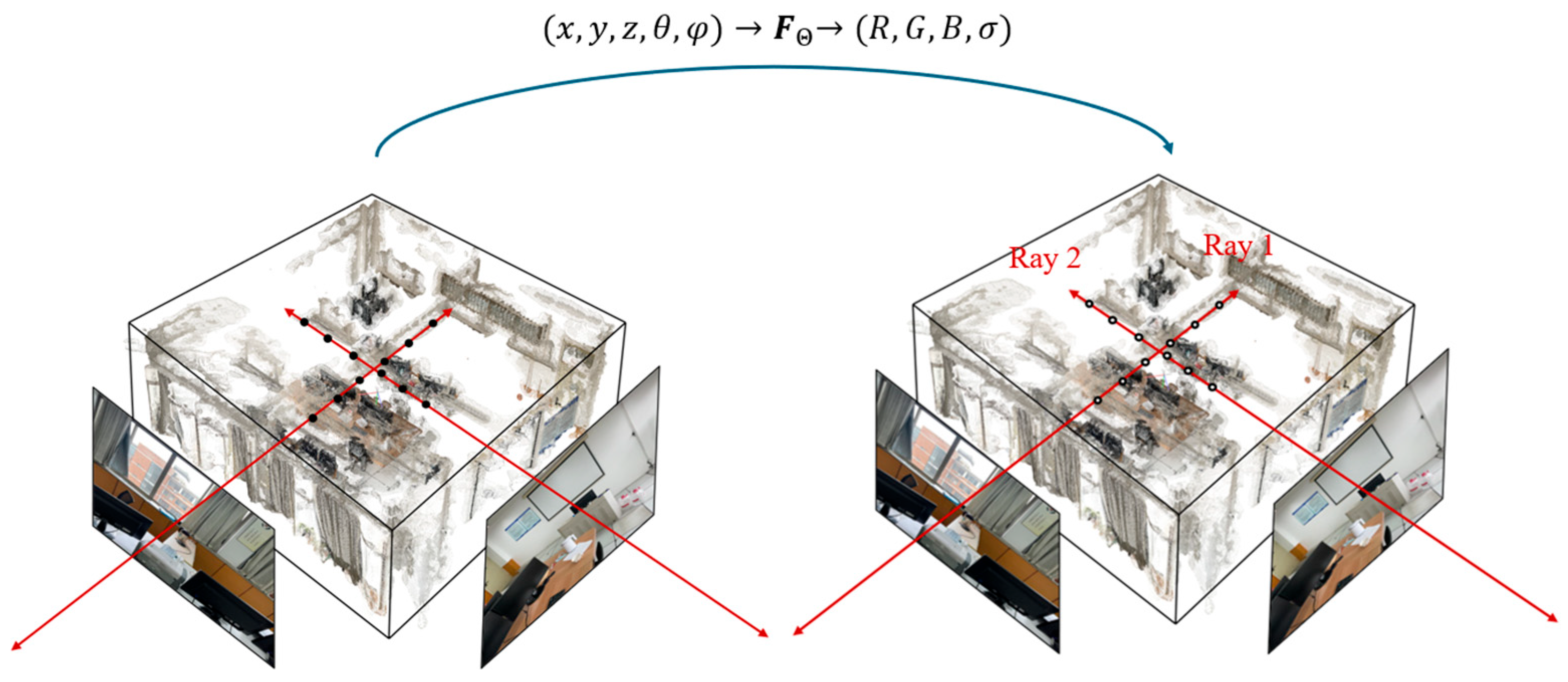
3. Radiance Field (RF)-Inspired Methods
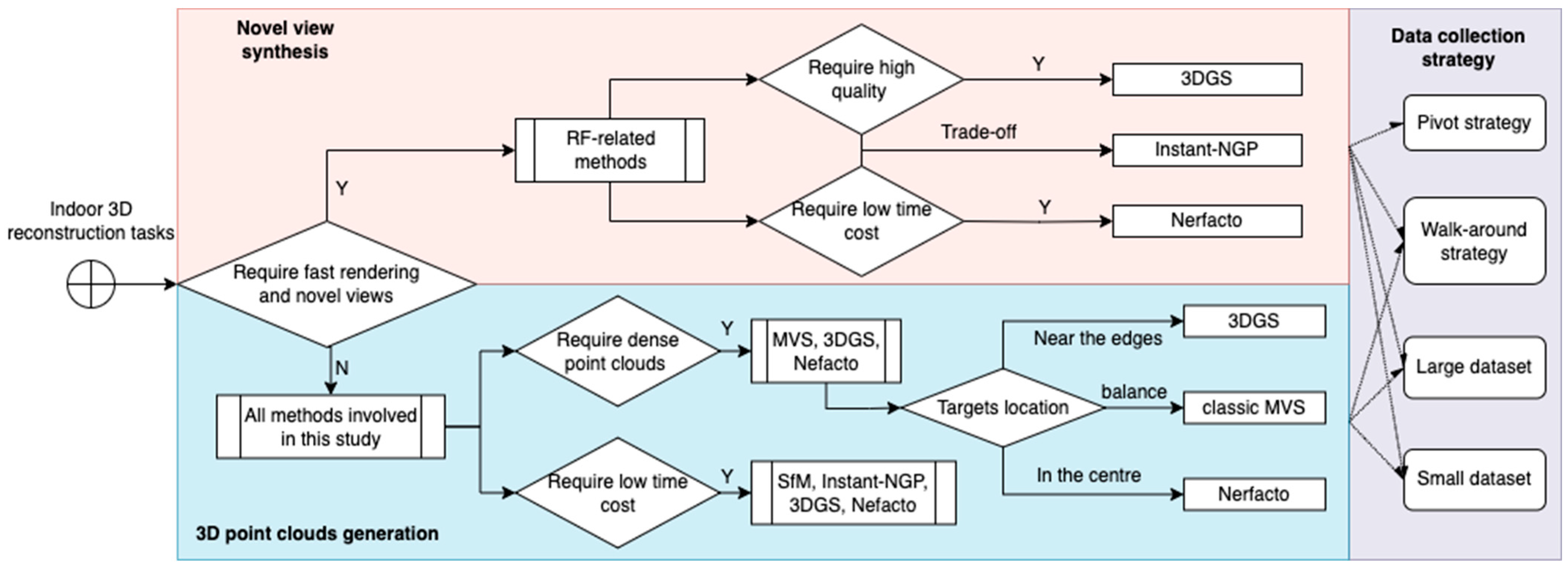
4. Research Method
4.1. Methods for Performance Comparison
- They are recognized as classic algorithms in their respective fields;
- They have publicly available open-source GitHub repositories;
- We exclude the latest specialized algorithmic variants designed for unique conditions (e.g., poor lighting or large-scale environments).
4.2. Performance Evaluation Metrics
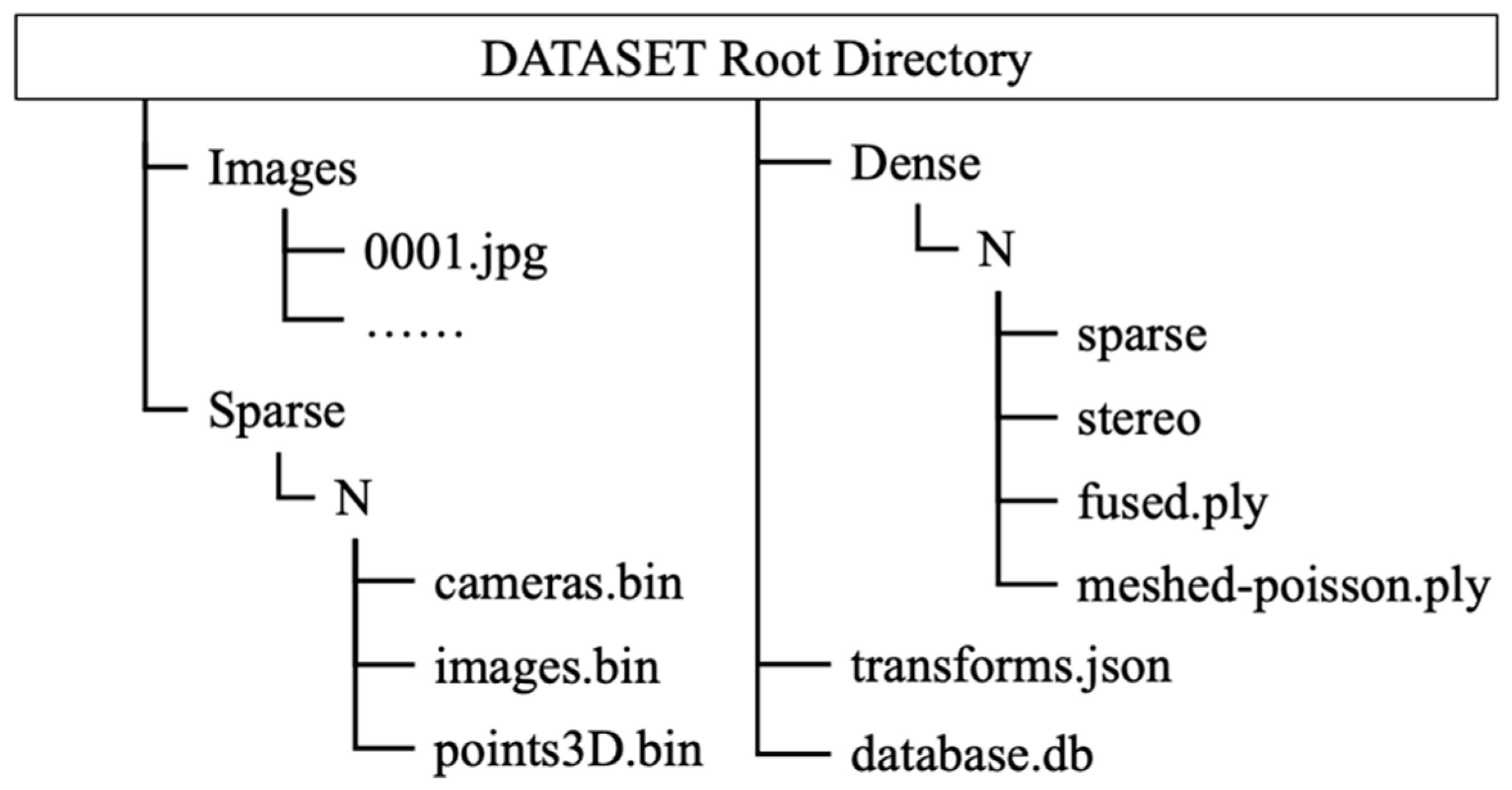
4.3. Data Collection
5. Results and Performance Comparison
5.1. View Synthesis
- PSNR: Higher PSNR values indicate better image quality. 3DGS achieves 28.2287 dB, followed by Instant-NGP and Nerfacto (~20 dB), demonstrating near-realistic indoor scene rendering.
- SSIM: SSIM measures structural similarity and ranges from 0 to 1. Instant-NGP achieved the highest SSIM (0.7923), closely followed by 3DGS (0.7559). Mip-NeRF performed least satisfactorily in terms of structure retention.
- LPIPS: LPIPS evaluates perceptual similarity. Vanilla-NeRF excelled here (0.8332), generating images closely matching human perception. By contrast, 3DGS lagged behind in LPIPS at 0.4405.
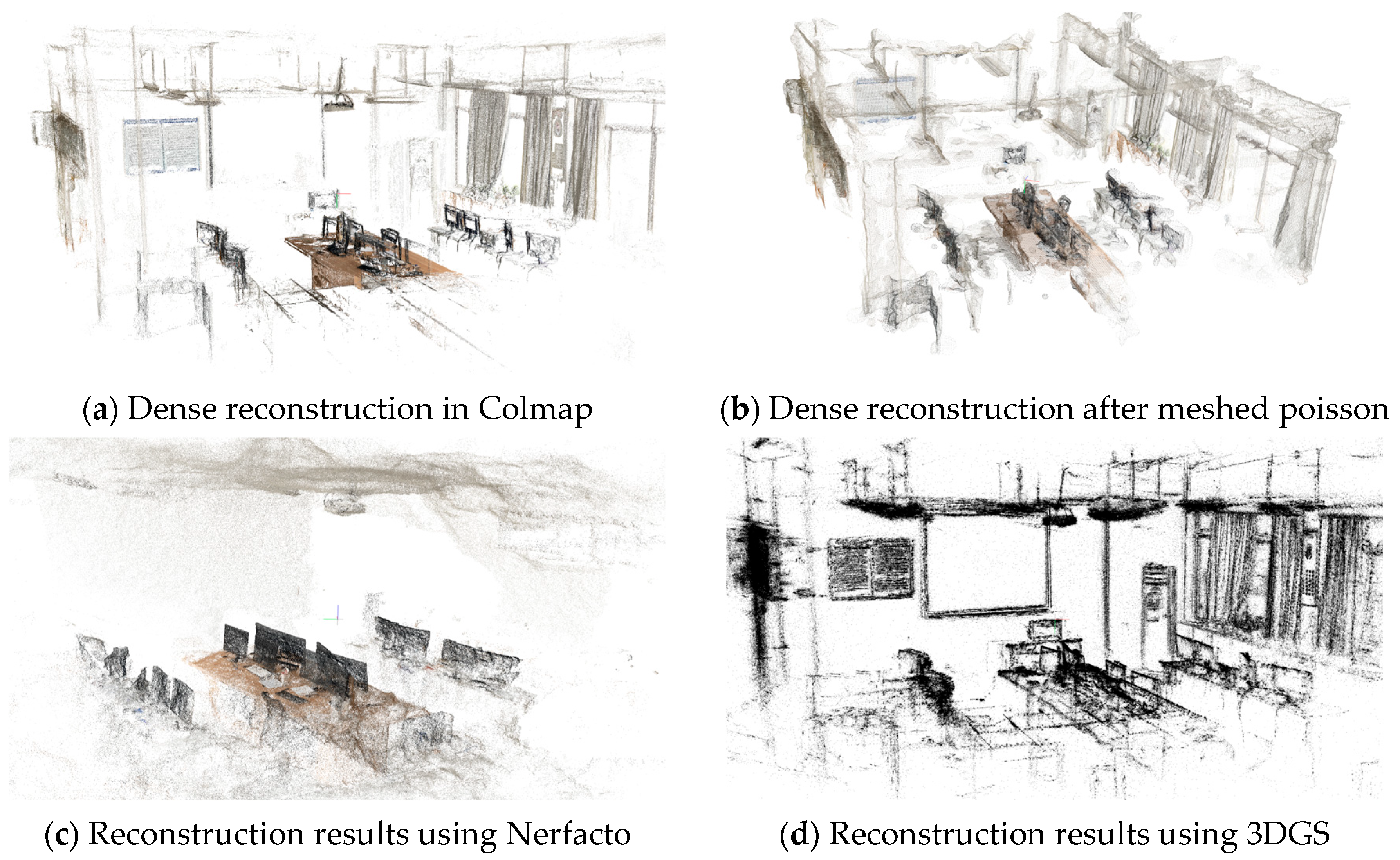
5.2. 3D Point Cloud Generation
5.3. Reconstruction Efficiency
5.4. Downstream Tasks
6. Discussion
6.1. Sensitivity Analysis on Data Collection Strategies
6.2. Sensitivity Analysis of Dataset Size
6.3. Applicability of RF-Inspired Methods in Indoor Scenarios
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kim, M.; Kim, H. Optimal Pre-processing of Laser Scanning Data for Indoor Scene Analysis and 3D Reconstruction of Building Models. Ksce J. Civ. Eng. 2024, 28, 1–14. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. Kinectfusion: Real-time dense surface mapping and tracking. In Proceedings of the 2011 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 26–29 October 2011. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Dai, A.; Nießner, M.; Zollhöfer, M.; Izadi, S.; Theobalt, C. Bundlefusion: Real-time globally consistent 3d reconstruction using on-the-fly surface reintegration. ACM Trans. Graph. (ToG) 2017, 36, 1. [Google Scholar] [CrossRef]
- Schonberger, J.L.; Frahm, J.-M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Chen, J.; Kira, Z.; Cho, Y.K. Deep learning approach to point cloud scene understanding for automated scan to 3D reconstruction. J. Comput. Civ. Eng. 2019, 33, 04019027. [Google Scholar] [CrossRef]
- Tosi, F.; Zhang, Y.; Gong, Z.; Sandström, E.; Mattoccia, S.; Oswald, M.R.; Poggi, M. How NeRFs and 3D Gaussian Splatting are Reshaping SLAM: A Survey. arXiv 2024, arXiv:2402.13255. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Garbin, S.J.; Kowalski, M.; Johnson, M.; Shotton, J.; Valentin, J. Fastnerf: High-fidelity neural rendering at 200fps. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph. (TOG) 2022, 41, 1–15. [Google Scholar] [CrossRef]
- Hu, X.; Xiong, G.; Zang, Z.; Jia, P.; Han, Y.; Ma, J. PC-NeRF: Parent-Child Neural Radiance Fields Using Sparse LiDAR Frames in Autonomous Driving Environments. arXiv 2024, arXiv:2402.09325. [Google Scholar] [CrossRef]
- Park, M.; Do, M.; Shin, Y.; Yoo, J.; Hong, J.; Kim, J.; Lee, C. H2O-SDF: Two-phase Learning for 3D Indoor Reconstruction using Object Surface Fields. arXiv 2024, arXiv:2402.08138. [Google Scholar]
- Kerbl, B.; Kopanas, G.; Leimkuehler, T.; Drettakis, G. 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph. 2023, 42, 1–14. [Google Scholar] [CrossRef]
- Yu, Z.; Chen, A.; Huang, B.; Sattler, T.; Geiger, A. Mip-splatting: Alias-free 3d gaussian splatting. arXiv 2023, arXiv:2311.16493. [Google Scholar]
- Yan, Z.; Low, W.F.; Chen, Y.; Lee, G.H. Multi-scale 3d gaussian splatting for anti-aliased rendering. arXiv 2023, arXiv:2311.17089. [Google Scholar]
- Jiang, Y.; Tu, J.; Liu, Y.; Gao, X.; Long, X.; Wang, W.; Ma, Y. GaussianShader: 3D Gaussian Splatting with Shading Functions for Reflective Surfaces. arXiv 2023, arXiv:2311.17977. [Google Scholar]
- Liang, Z.; Zhang, Q.; Feng, Y.; Shan, Y.; Jia, K. Gs-ir: 3d gaussian splatting for inverse rendering. arXiv 2023, arXiv:2311.16473. [Google Scholar]
- Yao, Y.; Zhang, J.; Liu, J.; Qu, Y.; Fang, T.; McKinnon, D.; Tsin, Y.; Quan, L. Neilf: Neural incident light field for physically-based material estimation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Ma, L.; Agrawal, V.; Turki, H.; Kim, C.; Gao, C.; Sander, P.; Zollhöfer, M.; Richardt, C. SpecNeRF: Gaussian Directional Encoding for Specular Reflections. arXiv 2023, arXiv:2312.13102. [Google Scholar]
- Lu, T.; Yu, M.; Xu, L.; Xiangli, Y.; Wang, L.; Lin, D.; Dai, B. Scaffold-gs: Structured 3d gaussians for view-adaptive rendering. arXiv 2023, arXiv:2312.00109. [Google Scholar]
- Navaneet, K.; Meibodi, K.P.; Koohpayegani, S.A.; Pirsiavash, H. Compact3d: Compressing gaussian splat radiance field models with vector quantization. arXiv 2023, arXiv:2311.18159. [Google Scholar]
- Girish, S.; Gupta, K.; Shrivastava, A. Eagles: Efficient accelerated 3d gaussians with lightweight encodings. arXiv 2023, arXiv:2312.04564. [Google Scholar]
- Fan, Z.; Fan, Z.; Wang, K.; Wen, K.; Zhu, Z.; Xu, D.; Wang, Z. Lightgaussian: Unbounded 3d gaussian compression with 15x reduction and 200+ fps. arXiv 2023, arXiv:2311.17245. [Google Scholar]
- Jo, J.; Kim, H.; Park, J. Identifying Unnecessary 3D Gaussians using Clustering for Fast Rendering of 3D Gaussian Splatting. arXiv 2024, arXiv:2402.13827. [Google Scholar]
- Chung, J.; Oh, J.; Lee, K.M. Depth-regularized optimization for 3d gaussian splatting in few-shot images. arXiv 2023, arXiv:2311.13398. [Google Scholar]
- Zhu, Z.; Fan, Z.; Jiang, Y.; Wang, Z. FSGS: Real-Time Few-shot View Synthesis using Gaussian Splatting. arXiv 2023, arXiv:2312.00451. [Google Scholar]
- Charatan, D.; Li, S.L.; Tagliasacchi, A.; Sitzmann, V. pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. arXiv 2023, arXiv:2312.12337. [Google Scholar]
- Xiong, H. Sparsegs: Real-time 360° sparse view synthesis using gaussian splatting. arXiv 2023, arXiv:2312.00206. [Google Scholar]
- Zou, Z.-X.; Yu, Z.; Guo, Y.; Li, Y.; Liang, D.; Cao, Y.; Zhang, S. Triplane meets gaussian splatting: Fast and generalizable single-view 3d reconstruction with transformers. arXiv 2023, arXiv:2312.09147. [Google Scholar]
- Das, D.; Wewer, C.; Yunus, R.; Ilg, E.; Lenssen, J.E. Neural parametric gaussians for monocular non-rigid object reconstruction. arXiv 2023, arXiv:2312.01196. [Google Scholar]
- Szymanowicz, S.; Rupprecht, C.; Vedaldi, A. Splatter image: Ultra-fast single-view 3d reconstruction. arXiv 2023, arXiv:2312.13150. [Google Scholar]
- Chen, Y.; Gu, C.; Jiang, J.; Zhu, X.; Zhang, L. Periodic vibration gaussian: Dynamic urban scene reconstruction and real-time rendering. arXiv 2023, arXiv:2311.18561. [Google Scholar]
- Lin, J.; Li, Z.; Tang, X.; Liu, J.; Liu, S.; Liu, J.; Lu, Y.; Wu, X.; Xu, S.; Yan, Y.; et al. VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction. arXiv 2024, arXiv:2402.17427. [Google Scholar]
- Kratimenos, A.; Lei, J.; Daniilidis, K. Dynmf: Neural motion factorization for real-time dynamic view synthesis with 3d gaussian splatting. arXiv 2023, arXiv:2312.00112. [Google Scholar]
- Lin, Y.; Dai, Z.; Zhu, S.; Yao, Y. Gaussian-flow: 4d reconstruction with dynamic 3d gaussian particle. arXiv 2023, arXiv:2312.03431. [Google Scholar]
- Yang, Z.; Yang, H.; Pan, Z.; Zhang, L. Real-time photorealistic dynamic scene representation and rendering with 4d gaussian splatting. arXiv 2023, arXiv:2310.10642. [Google Scholar]
- Duisterhof, B.P.; Mandi, Z.; Yao, Y.; Liu, J.W.; Shou, M.Z.; Song, S.; Ichnowski, J. Md-splatting: Learning metric deformation from 4d gaussians in highly deformable scenes. arXiv 2023, arXiv:2312.00583. [Google Scholar]
- Tancik, M.; Weber, E.; Ng, E.; Li, R.; Yi, B.; Wang, T.; Kristoffersen, A.; Austin, J.; Salahi, K.; Ahuja, A.; et al. Nerfstudio: A modular framework for neural radiance field development. In Proceedings of the ACM SIGGRAPH 2023 Conference Proceedings, Los Angeles, CA, USA, 6–10 August 2023. [Google Scholar]
- Barron, J.T.; Mildenhall, B.; Tancik, M.; Hedman, P.; Martin-Brualla, R.; Srinivasan, P.P. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Zhang, X.; Srinivasan, P.P.; Deng, B.; Debevec, P.; Freeman, W.T.; Barron, J.T. Nerfactor: Neural factorization of shape and reflectance under an unknown illumination. ACM Trans. Graph. (ToG) 2021, 40, 1–18. [Google Scholar] [CrossRef]
- Mekuria, R.; Li, Z.; Tulvan, C.; Chou, P. Evaluation criteria for pcc (point cloud compression). ISO/IEC JTC 2016, 1, N16332. Available online: https://mpeg.chiariglione.org/standards/mpeg-i/point-cloud-compression/evaluation-criteria-pcc.html (accessed on 2 February 2025).
- Pavez, E.; Chou, P.A.; de Queiroz, R.L.; Ortega, A. Dynamic polygon clouds: Representation and compression for VR/AR. APSIPA Trans. Signal Inf. Process. 2018, 7, e15. [Google Scholar] [CrossRef]
- Tian, D.; Ochimizu, H.; Feng, C.; Cohen, R.; Vetro, A. Geometric distortion metrics for point cloud compression. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Alexiou, E.; Ebrahimi, T. Towards a point cloud structural similarity metric. In Proceedings of the 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), London, UK, 6–10 July 2020. [Google Scholar]
- Yang, Q.; Zhang, Y.; Chen, S.; Xu, Y.; Sun, J.; Ma, Z. MPED: Quantifying point cloud distortion based on multiscale potential energy discrepancy. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 6037–6054. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Ma, Z.; Xu, Y.; Li, Z.; Sun, J. Inferring point cloud quality via graph similarity. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 3015–3029. [Google Scholar] [CrossRef]
- Meynet, G.; Nehmé, Y.; Digne, J.; Lavoué, G. PCQM: A full-reference quality metric for colored 3D point clouds. In Proceedings of the 2020 Twelfth International Conference on Quality of Multimedia Experience (QoMEX), Athlone, Ireland, 26–28 May 2020. [Google Scholar]
- Viola, I.; Cesar, P. A reduced reference metric for visual quality evaluation of point cloud contents. IEEE Signal Process. Lett. 2020, 27, 1660–1664. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, Q.; Xu, Y.; Yang, L. Point cloud quality assessment: Dataset construction and learning-based no-reference metric. ACM Trans. Multimed.Comput. Commun. Appl. 2023, 19, 1–26. [Google Scholar] [CrossRef]
- Jarząbek-Rychard, M.; Maas, H.G. Modeling of 3D geometry uncertainty in Scan-to-BIM automatic indoor reconstruction. Autom. Constr. 2023, 154, 105002. [Google Scholar] [CrossRef]
- Schönberger, J.L.; Zheng, E.; Frahm, J.-M.; Pollefeys, M. Pixelwise view selection for unstructured multi-view stereo. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016. Proceedings, Part III 14. [Google Scholar]
- Liu, L.; Gu, J.; Zaw Lin, K.; Chua, T.S. Neural sparse voxel fields. Adv. Neural Inf. Process. Syst. 2020, 33, 15651–15663. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3d semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, S.; Zhang, W.; Gasperini, S.; Wu, S.C.; Navab, N. VoxNeRF: Bridging voxel representation and neural radiance fields for enhanced indoor view synthesis. arXiv 2023, arXiv:2311.05289. [Google Scholar]
- Chen, Y.; Chen, Z.; Zhang, C.; Wang, F.; Yang, X.; Wang, Y.; Cai, Z.; Yang, L.; Liu, H.; Lin, G. Gaussianeditor: Swift and controllable 3d editing with gaussian splatting. arXiv 2023, arXiv:2311.14521. [Google Scholar]
- Jeon, Y.; Kulinan, A.S.; Tran, D.Q.; Park, M.; Park, S. Nerf-con: Neural radiance fields for automated construction progress monitoring. in ISARC. In Proceedings of the International Symposium on Automation and Robotics in Construction, Lille, France, 3–5 June 2024. [Google Scholar]
- Zhu, Z.; Peng, S.; Larsson, V.; Cui, Z.; Oswald, M.R.; Geiger, A.; Pollefeys, M. Nicer-slam: Neural implicit scene encoding for rgb slam. In Proceedings of the 2024 International Conference on 3D Vision (3DV), Davos, Switzerland, 18–21 March 2024. [Google Scholar]
- Zhang, J.; Zhang, F.; Kuang, S.; Zhang, L. Nerf-lidar: Generating realistic lidar point clouds with neural radiance fields. Proc. AAAI Conf. Artif. Intell. 2024, 38, 7178–7186. [Google Scholar] [CrossRef]
- Chang, M.; Sharma, A.; Kaess, M.; Lucey, S. Neural radiance field with lidar maps. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Pros | Cons | Exemplified Methods |
|---|---|---|---|
| LiDAR-based | High accuracy; Suitable for large-scale scenes; Robust to environmental changes. | High cost; Difficult to operate; Large volume of collected data; Require additional processing to generate dense models. | Commercially available applications; [1] |
| RGB-D-based | Cost effective; Easy to operate; | Medium accuracy; Sensitivity to environmental changes; | [2,3,4] |
| Photogrammetry-based | Cost effective; High resolution with color information. | High sensitivity to environmental changes, e.g., lighting; Require complex algorithms to process; | [5,6] |
| Methods | NeRF | 3DGS |
|---|---|---|
| Scene representation type | Implicit | Explicit |
| Scene representation | A deep neural network (MLP) | Centre position μ(x,y,z) Covariance matrix ∑ Color and opacity (R, G, B, α) |
| Rendering method | Volume rendering | Gaussian rasterization |
| Optimization | Differentiable rendering | Gradient descent |
| Tasks | Methods Used for Comparison | Evaluation Metrics |
|---|---|---|
| Novel view synthesis | NeRF, NeRF’s variants, and 3DGS | PSNR, SSIM, LPIPS |
| 3D point clouds generation | SfM, MVS, NeRF, NeRF’s variants, and 3DGS | Number of points, Efficiency |
| 3D point clouds segmentation | MVS, RF-based methods with best view synthesis performance | Accuracy |
| Category | Evaluation Metric | Explanation |
|---|---|---|
| Quality of 3D reconstruction | Accuracy | The average distance between two models |
| View synthesis | Peak Signal-to-Noise Ratio (PSNR) | Ratio of maximum pixel value to the root mean squared error |
| Structural Similarity Index Measure (SSIM) | Measures similarity in luminance, contrast, and structure between two images | |
| Learned Perceptual Image Patch Similarity (LPIPS) | Measures feature similarity between image patches using a pre-trained network |
| Room’s Name | Laboratory | Computer-aided classroom |
| Floor plan shape | Rectangular | Heteromorphism |
| Room area | 20 m2 | 25 m2 |
| Data collection | 107 photos | 41 Photos and 1 Video |
| Image resolution | 3024 × 4032 | 1920 × 1080 |
| Evaluation Metrics | PSNR | SSIM | LPIPS | No. Rays per Second | Training/Rendering Time | |
|---|---|---|---|---|---|---|
| Reconstruction Methods | ||||||
| NeRF-based | Vanilla-NeRF | 12.9516 | 0.6390 | 0.8332 | 50,935 | ~17 h |
| Mip-NeRF | 11.1231 | 0.6330 | 0.7073 | 40,526 | ~14 h | |
| Instant-NGP | 19.0023 | 0.6818 | 0.7090 | 56,520 | ~1 h | |
| Nerfacto | 18.9293 | 0.6955 | 0.6080 | 1,338,020 | ~30 min | |
| 3D Gaussian-based | 3DGS | 28.2287 | 0.7559 | 0.4405 | -- | ~30 min |
| Reconstruction Method | SfM (Sparse) | MVS (Dense) | MipNeRF | Nerfacto | Nerfacto (Meshed Poisson) | 3DGS |
|---|---|---|---|---|---|---|
| Number of Points | 14,422 | 962,847 | 100,0283 | 1,001,213 | 992,125 | 1,574,318 |
| Number of Rays | N/A | N/A | 12,192,768 | N/A | ||
| RF-Inspired Methods | Evaluation Metrics | PSNR | SSIM | LPIPS | No. of Rays per Second | Training/ Rendering Time | |
|---|---|---|---|---|---|---|---|
| Data Capturing Methods | |||||||
| Vanilla-NeRF | Walk-around | 12.9516 | 0.6390 | 0.8332 | 50,935 | ~9 h | |
| Pivot | 14.3469 | 0.6650 | 0.7088 | 48,667 | ~16.3 h | ||
| MipNeRF | Walk-around | 11.1231 | 0.6330 | 0.7073 | 40,526 | ~10.5 h | |
| Pivot | 13.9983 | 0.5907 | 0.7571 | 40,753 | ~15 h | ||
| Instant-NGP | Walk-around | 19.0023 | 0.6818 | 0.7090 | 56,520 | ~30 min | |
| Pivot | 14.8730 | 0.7053 | 0.6039 | 44,270 | ~50 min | ||
| Nerfacto | Walk-around | 18.9293 | 0.6955 | 0.6080 | 1,338,020 | ~13 min | |
| Pivot | 17.9385 | 0.7617 | 0.3499 | 1,200,194 | ~32 min | ||
| 3DGS | Walk-around | 28.2287 | 0.7559 | 0.4405 | N/A * | ~10 min | |
| Pivot | 35.9607 | 0.9746 | 0.0955 | N/A | ~20 min | ||
| RF-Inspired Methods | Evaluation Metrics | PSNR | SSIM | LPIPS | Training/ Rendering Time | |
|---|---|---|---|---|---|---|
| Dataset Size | ||||||
| MipNeRF | 41 images | 12.4190 | 0.6852 | 0.6875 | ~16 h | |
| 860 images | 12.3500 | 0.5393 | 0.8302 | ~16 h | ||
| Instant-NGP | 41 images | 15.0179 | 0.6904 | 0.7255 | ~35 min | |
| 860 images | 22.9552 | 0.7615 | 0.5054 | ~40 min | ||
| Nerfacto | 41 images | 17.0927 | 0.7099 | 0.5847 | ~10 min | |
| 860 images | 22.6608 | 0.8090 | 0.2677 | ~12 min | ||
| 3DGS | 41 images | 30.7624 | 0.9246 | 0.2539 | ~10 min | |
| 860 images | 32.1640 | 0.9548 | 0.1268 | ~11 min | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, S.; Wang, J.; Xia, J.; Shou, W. Evaluating Radiance Field-Inspired Methods for 3D Indoor Reconstruction: A Comparative Analysis. Buildings 2025, 15, 848. https://doi.org/10.3390/buildings15060848
Xu S, Wang J, Xia J, Shou W. Evaluating Radiance Field-Inspired Methods for 3D Indoor Reconstruction: A Comparative Analysis. Buildings. 2025; 15(6):848. https://doi.org/10.3390/buildings15060848
Chicago/Turabian StyleXu, Shuyuan, Jun Wang, Jingfeng Xia, and Wenchi Shou. 2025. "Evaluating Radiance Field-Inspired Methods for 3D Indoor Reconstruction: A Comparative Analysis" Buildings 15, no. 6: 848. https://doi.org/10.3390/buildings15060848
APA StyleXu, S., Wang, J., Xia, J., & Shou, W. (2025). Evaluating Radiance Field-Inspired Methods for 3D Indoor Reconstruction: A Comparative Analysis. Buildings, 15(6), 848. https://doi.org/10.3390/buildings15060848