
Compositional Data and Microbiota Analysis: Imagination and Reality

 , , , , and
, , , , and
Abstract
1. Introduction
2. Compositional Data and Microbiota Analysis
3. Discussion
3.1. Artificial Data and Statistics
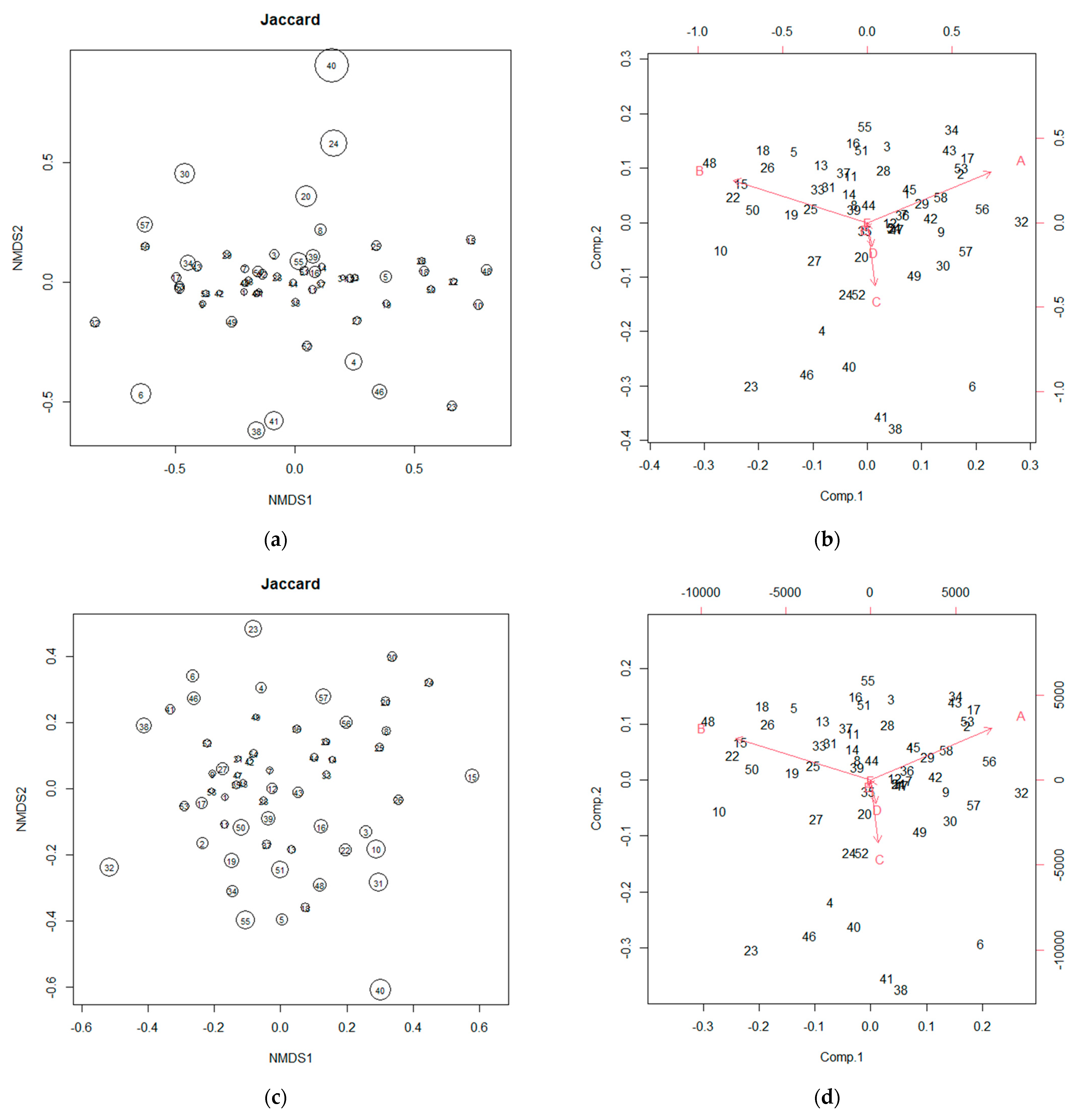
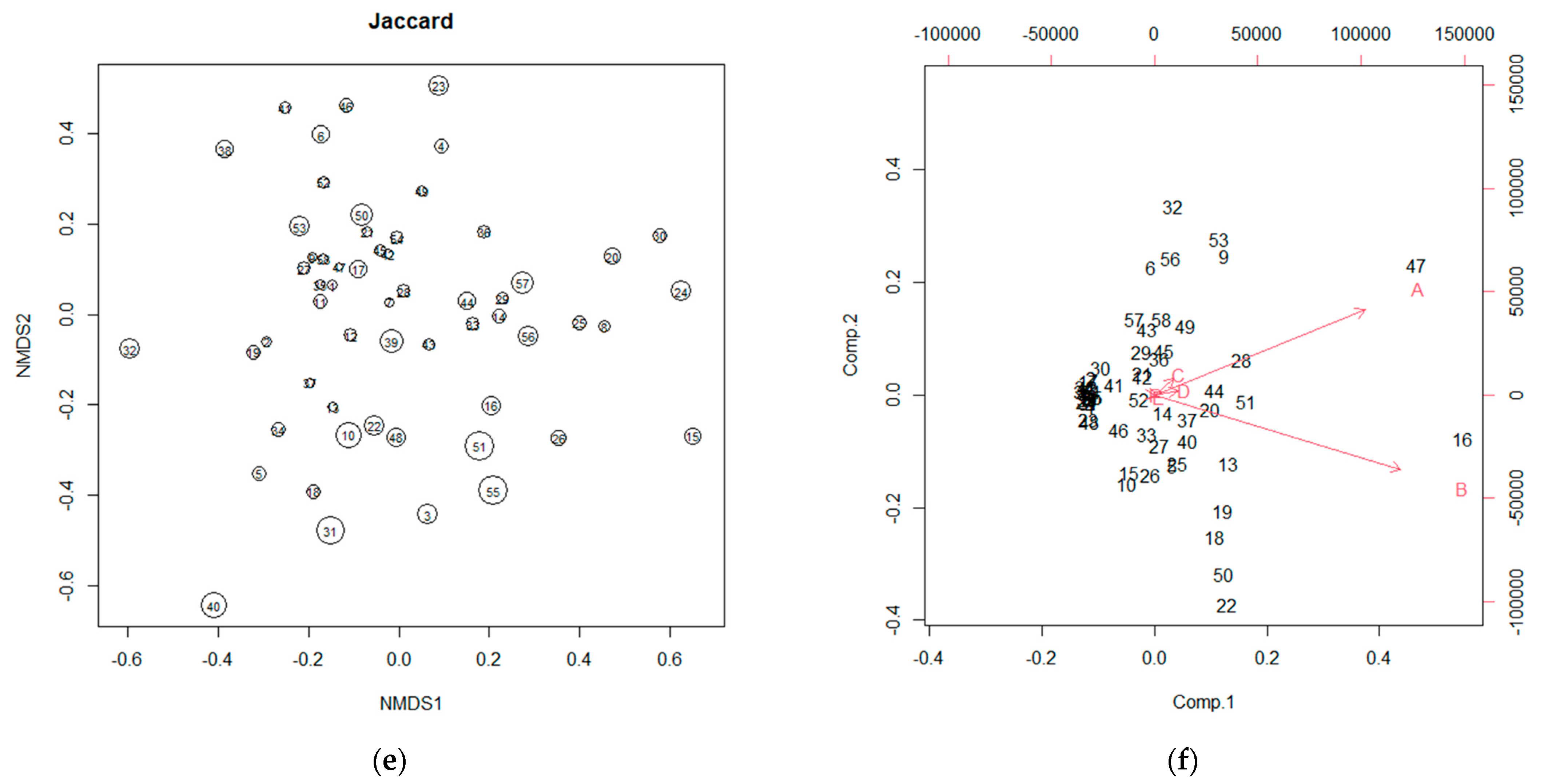
3.2. NMDS and PCA
3.3. LEfSe
3.4. Ratio Analysis and Method of Ohta et al.
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Itagaki, T.; Sakata, K.-I.; Hasebe, A.; Kitagawa, Y. Diversity of the Japanese Gut Microbiome Analysis: Relative Approach Using Principal Component Analysis. Preprints 2024, 2024020275. [Google Scholar] [CrossRef]
- Walker, A.W.; Hoyles, L. Human microbiome myths and misconceptions. Nat. Microbiol. 2023, 8, 1392–1396. [Google Scholar] [CrossRef] [PubMed]
- Pearson, K. Mathematical contributions to the theory of evolution: On a form of spurious correlation which may arise when indices are used in the measurement of organs. Proc. R. Soc. Lond. 1897, 60, 489–498. [Google Scholar] [CrossRef]
- Aitchison, J. The statistical analysis of compositional data. J. R. Stat. Soc. Ser. B. (Stat. Methodol.) 1982, 44, 139–160. [Google Scholar] [CrossRef]
- Aitchison, J. The statistical analysis of geochemical compositions. J. Int. Assoc. Math. Geol. 1984, 16, 531–564. [Google Scholar] [CrossRef]
- Aitchison, J. Compositional data analysis: Where are we and where should we be heading? J. Int. Assoc. Math. Geol. 2005, 37, 829–850. [Google Scholar] [CrossRef]
- Ohta, T.; Arai, H.; Noda, A. Identification of the unchanging reference component of compositional data from the properties of the coefficient of variation. Math. Geosci. 2011, 43, 421–434. [Google Scholar] [CrossRef]
- Stojanov, S.; Berlec, A.; Štrukelj, B. The Influence of Probiotics on the Firmicutes/Bacteroidetes Ratio in the Treatment of Obesity and Inflammatory Bowel disease. Microorganisms 2020, 8, 1715. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
| Composition | A | B | C | D | E | F |
| Average | 0.394288 | 0.456073 | 0.071928 | 0.051586 | 0.025462 | 0.000663 |
| Coefficient of variation | 0.333277 | 0.302911 | 1.02974 | 1.149273 | 2.025749 | 1.371844 |
| Skewness | −0.14103 | 0.282245 | 1.983293 | 4.330247 | 3.094253 | 3.004872 |
| Kurtosis | −0.51101 | −0.3021 | 3.81018 | 24.34699 | 10.19621 | 10.68641 |
| Correlation with A | 1 | −0.74465 | −0.16093 | −0.1366 | −0.16563 | 0.029699 |
| Assumption 1 | A | B | C | D | E | F |
| Average | 3918.19 | 4541.655 | 713.4828 | 513.5 | 254.2759 | 6.568966 |
| Coefficient of variation | 0.329642 | 0.306276 | 1.029157 | 1.153159 | 2.028733 | 1.358041 |
| Skewness | −0.2025 | 0.290015 | 2.00465 | 4.354737 | 3.095241 | 2.975476 |
| Kurtosis | −0.58333 | −0.30179 | 3.923947 | 24.55164 | 10.19947 | 10.65289 |
| Correlation with A | 1 | −0.73827 | −0.17343 | −0.13419 | −0.16025 | −0.00122 |
| Assumption 2 | A | B | C | D | E | F |
| Average | 18411.97 | 21386.98 | 2926.345 | 2638.897 | 968.5172 | 29.37931 |
| Coefficient of variation | 0.990369 | 0.965048 | 1.15911 | 1.988405 | 2.365539 | 1.565635 |
| Skewness | 2.002331 | 1.818849 | 1.860411 | 5.413138 | 4.758781 | 2.722131 |
| Kurtosis | 5.321145 | 4.519852 | 3.731474 | 33.98872 | 27.75528 | 8.969854 |
| Correlation with A | 1 | 0.778904 | 0.555044 | 0.339023 | 0.111192 | 0.320866 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Itagaki, T.; Kobayashi, H.; Sakata, K.-i.; Miyamoto, I.; Hasebe, A.; Kitagawa, Y. Compositional Data and Microbiota Analysis: Imagination and Reality. Microorganisms 2024, 12, 1484. https://doi.org/10.3390/microorganisms12071484
Itagaki T, Kobayashi H, Sakata K-i, Miyamoto I, Hasebe A, Kitagawa Y. Compositional Data and Microbiota Analysis: Imagination and Reality. Microorganisms. 2024; 12(7):1484. https://doi.org/10.3390/microorganisms12071484
Chicago/Turabian StyleItagaki, Tatsuki, Hirokazu Kobayashi, Ken-ichiro Sakata, Ikuya Miyamoto, Akira Hasebe, and Yoshimasa Kitagawa. 2024. "Compositional Data and Microbiota Analysis: Imagination and Reality" Microorganisms 12, no. 7: 1484. https://doi.org/10.3390/microorganisms12071484
APA StyleItagaki, T., Kobayashi, H., Sakata, K.-i., Miyamoto, I., Hasebe, A., & Kitagawa, Y. (2024). Compositional Data and Microbiota Analysis: Imagination and Reality. Microorganisms, 12(7), 1484. https://doi.org/10.3390/microorganisms12071484