
A Pig Mass Estimation Model Based on Deep Learning without Constraint

Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection Scenarios
2.2. Improving Data Quality
2.2.1. Image Blur Detection
2.2.2. Structural Similarity Index Measure
2.3. Construction of Dataset
2.4. Construction of Pig Mass Estimation Model Based on Deep Learning without Constraint
2.4.1. The Pig Instance Segmentation Algorithm Based on Mask R-CNN Network
- (1)
- Multi-branch Convolution Module. To address the shortcomings of ResNet in terms of its poor ability to represent fine-grained features, our model borrows the idea of multi-branch convolution from Res2Net [33] and uses one group of smaller filter sets to replace the 3 × 3 filters, as shown in Figure 8. The new 3 × 3 filter sets are connected in a hierarchical residual-like style to increase the perceptual field of the network and improve its multi-scale representation capability. This is accomplished as follows. After 1 × 1 convolution, the input feature maps are divided into multiple groups; one group of filters first extracts information from one set of input feature maps, then the output feature maps of the previous group are sent to the next group of filters along with another set of input feature maps. This process is repeated several times until all input feature maps are processed. Finally, the feature maps of all groups are connected and sent to the 1 × 1 filter to completely fuse the information. Along any possible path from the input feature map to the output feature map, the equivalent perceptual field is increased when passing through the 3 × 3 filter, resulting in more equivalent feature-scale information due to the combination effect.
- (2)
- Depthwise Convolution. Although there is no significant increase in the number of parameters required by the residual structure of Res2Net, its multi-branch structure destroys the parallelism of the network and reduces the speed of network computation. In order to avoid slowdown of the model, the bottleneck layer in the stage4 part of the convolution module of the ResNet network is replaced with the multi-branch convolution form from Res2Net. For the other stages, the optimization ideas verified in ConvNeXt [34] are borrowed for further improvement, and the depthwise convolution proposed in ResNeXt [35] is used to achieve a better balance between computational effort and accuracy. The structure of Res2Net combined with depthwise convolution is shown in Figure 9.
- (3)
- Inverse Bottleneck. In this paper, we use the inverse bottleneck layer structure proposed in MobileNetV2 [36], which adopts the form of “small dimension–large dimension–small-dimension” to ensure that the information of the feature map can avoid the information loss caused by compression of dimensionality when transforming between different dimensional feature spaces. This prevents the loss of detailed features on the body of the pig during the downsampling process.
- (4)
- Improved Normalization and Activation Layers. In this paper, we reduce the oscillation of gradients during training by reducing the number of normalization and activation layers, using layer normalization instead of batch normalization, and using GELU instead of ReLU.
- (5)
- Using 7 × 7 Convolution instead of 3 × 3 Convolution. In this study, we borrow the concept of the Swin Transformer [37] to increase the perceptual field and use 7 × 7 convolution kernels instead of 3 × 3 convolution kernels in ResNet, which results in a model with a larger perceptual field.
2.4.2. The Pig Keypoint Detection Algorithm Based on Keypoint R-CNN Network
2.4.3. Pig Mass Estimation Algorithm Based on Improved ResNet
3. Results
3.1. Experiments and Results for Pig Instance Segmentation Algorithm
3.2. Experiments and Results for Pig Keypoint Detection Algorithm
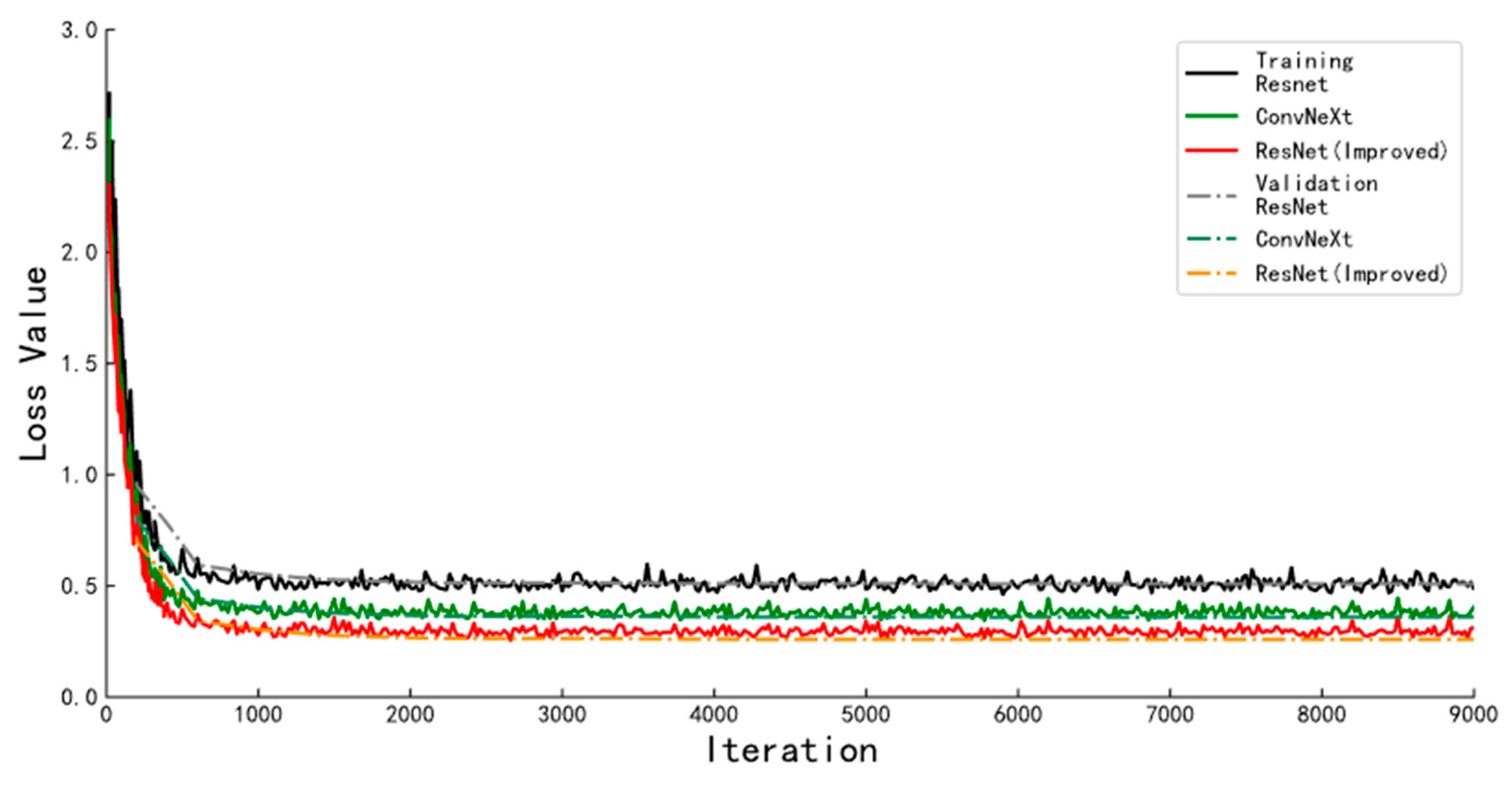
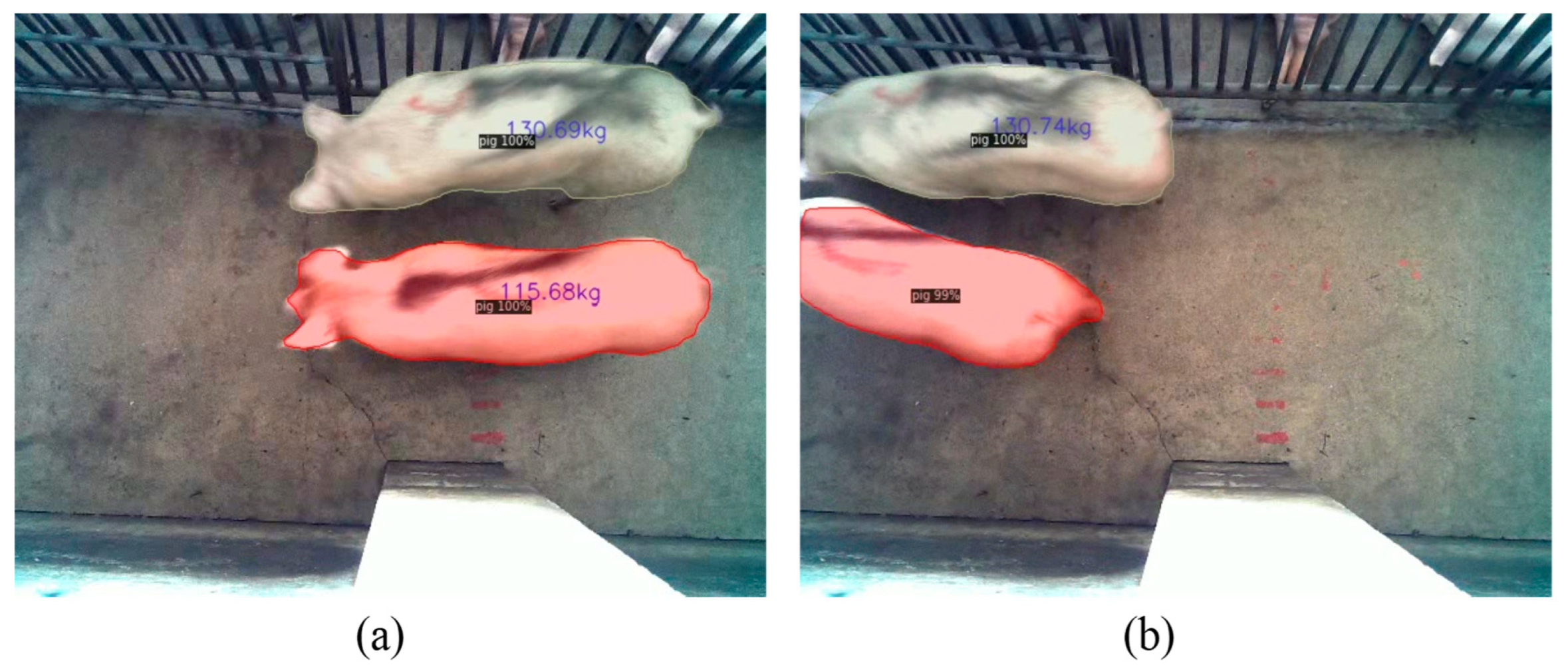
3.3. Experiments and Results for Pig Body Mass Estimation Algorithm
4. Discussion
5. Conclusions
- (1)
- In this paper, an unconstrained pig body mass estimation model is designed. The model uses blurry detection and similarity metric algorithms to ensure that the image quality used for body mass estimation is stable, then an instance segmentation algorithm is used to extract individual pigs in the image. A keypoint detection algorithm is used to eliminate the obscured pigs, and finally the image is fed into the body mass estimation algorithm to obtain the body mass.
- (2)
- In this paper, the proposed PMEM-DLWC model is improved by combining the latest developments in deep learning in recent years. The ResNet backbone network was improved by introducing multi-branch convolution, depthwise convolution, and an inverse bottleneck to construct a network that achieves a good balance between the number of model parameters and the accuracy rate. The RMSE of the model on the test set was 3.52 kg, and the average estimation speed was 0.339 s per image. These result show that the proposed mass estimation model can automatically extract the important features required for mass estimation. The reported speed and accuracy are effectively able to meet actual production needs.
- (3)
- The proposed PMEM-DLWC model can be used to estimate the body mass of pigs in an unconstrained environment. Compared with other methods, the pig body mass estimation model constructed in this paper has fewer constraints on pig posture as well as on the data acquisition environment, and the accuracy of the body mass estimation model is further improved by modifying the backbone network while maintaining low-cost equipment. The proposed approach can provide data and technical support for the determination of pig body mass, pig grading management, analysis of pig weight gain patterns, and realization of pig grading management, and can provide new ideas and methods for future research about precision livestock farming.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dohmen, R.; Catal, C.; Liu, Q. Computer vision-based weight estimation of livestock: A systematic literature review. N. Zeal. J. Agric. Res. 2022, 65, 227–247. [Google Scholar] [CrossRef]
- Douglas, S.L.; Szyszka, O.; Stoddart, K.; Edwards, S.A.; Kyriazakis, I. Animal and management factors influencing grower and finisher pig performance and efficiency in European systems: A meta-analysis. Animal 2015, 9, 1210–1220. [Google Scholar] [CrossRef] [PubMed]
- Xiao, D.; Liu, J.; Liu, Y.; Huang, Y.; Tang, Z.; Xiong, B. Intelligent mass measurement model for gestating sows under normality breeding. Trans. Chin. Soc. Agric. Mach. 2022, 38, 161–169. [Google Scholar]
- Parsons, D.J.; Green, D.M.; Schofield, C.P.; Whittemore, C.T. Real-time control of pig growth through an integrated management system. Biosyst. Eng. 2007, 96, 257–266. [Google Scholar] [CrossRef]
- Green, D.M.; Brotherstone, S.; Schofield, C.P.; Whittemore, C.T. Food intake and live growth performance of pigs measured automatically and continuously from 25 to 115 kg live weight. J. Sci. Food Agric. 2003, 83, 1150–1155. [Google Scholar] [CrossRef]
- Matthews, S.G.; Miller, A.L.; Clapp, J.; Plötz, T.; Kyriazakis, I. Early detection of health and welfare compromises through automated detection of behavioural changes in pigs. Vet. J. 2016, 217, 43–51. [Google Scholar] [CrossRef]
- Pezzuolo, A.; Milani, V.; Zhu, D.; Guo, H.; Guercini, S.; Marinello, F. On-Barn Pig Weight Estimation Based on Body Measurements by Structure-from-Motion (SfM). Sensors 2018, 18, 3603. [Google Scholar] [CrossRef]
- Grandin, T.; Shivley, C. How farm animals react and perceive stressful situations such as handling, restraint, and transport. Animals 2015, 5, 1233–1251. [Google Scholar] [CrossRef]
- Zhang, J.; Ji, H.; Teng, G. Weight estimation of fattening pigs based on deep convolutional network. J. China Agric. Univ. 2021, 26, 111–119. [Google Scholar]
- Chu, M.; Liu, G.; Si, Y.; Feng, F. Predicting method of dairy cow weight based on three-dimensional reconstruction. Trans. Chin. Soc. Agric. Mach. 2020, 51 (Suppl. S1), 385–391. [Google Scholar]
- Faucitano, L.; Goumon, S. Transport of Pigs to Slaughter and Associated Handling. In Advances in Pig Welfare; Woodhead Publishing: Sawston, UK, 2018; pp. 261–293. [Google Scholar]
- Al Ard Khanji, M.S.; Llorente, C.; Falceto, M.V.; Bonastre, C.; Mitjana, O.; Tejedor, M.T. Using body measurements to estimate body weight in gilts. Can. J. Anim. Sci. 2018, 98, 362–367. [Google Scholar] [CrossRef]
- Wang, Z.; Shadpour, S.; Chan, E.; Rotondo, V.; Wood, K.M.; Tulpan, D. ASAS-NANP SYMPOSIUM: Applications of machine learning for livestock body weight prediction from digital images. J. Anim. Sci. 2021, 99, skab022. [Google Scholar] [CrossRef]
- He, C.; Qiao, Y.; Mao, R.; Li, M.; Wang, M. Enhanced LiteHRNet based sheep weight estimation using RGB-D images. Comput. Electron. Agric. 2023, 206, 107667. [Google Scholar] [CrossRef]
- Bhoj, S.; Tarafdar, A.; Chauhan, A.; Singh, M.; Gaur, G.K. Image processing strategies for pig liveweight measurement: Updates and challenges. Comput. Electron. Agric. 2022, 193, 106693. [Google Scholar] [CrossRef]
- Pezzuolo, A.; Guarino, M.; Sartori, L.; González, L.A.; Marinello, F. On-barn pig weight estimation based on body measurements by a Kinect v1 depth camera. Comput. Electron. Agric. 2018, 148, 29–36. [Google Scholar] [CrossRef]
- Jun, K.; Kim, S.J.; Ji, H.W. Estimating pig weights from images without constraint on posture and illumination. Comput. Electron. Agric. 2018, 153, 169–176. [Google Scholar] [CrossRef]
- Shahinfar, S.; Al-Mamun, H.A.; Park, B.; Kim, S.; Gondro, C. Prediction of marbling score and carcass traits in Korean Hanwoo beef cattle using machine learning methods and synthetic minority oversampling technique. Meat Sci. 2020, 161, 107997. [Google Scholar] [CrossRef]
- Le Cozler, Y.; Allain, C.; Xavier, C.; Depuille, L.; Caillot, A.; Delouard, J.M.; Delattre, L.; Luginbuhl, T.; Faverdin, P. Volume and surface area of Holstein dairy cows calculated from complete 3D shapes acquired using a high-precision scanning system: Interest for body weight estimation. Comput. Electron. Agric. 2019, 165, 104977. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Singh, P.; Bose, S.S. Ambiguous D-means fusion clustering algorithm based on ambiguous set theory: Special application in clustering of CT scan images of COVID-19. Knowl. Based Syst. 2021, 231, 107432. [Google Scholar] [CrossRef]
- Singh, P.; Muchahari, M.K. Solving multi-objective optimization problem of convolutional neural network using fast forward quantum optimization algorithm: Application in digital image classification. Adv. Eng. Softw. 2023, 176, 103370. [Google Scholar] [CrossRef]
- Yang, Q.; Xiao, D.; Cai, J. Pig mounting behaviour recognition based on video spatial–temporal features. Biosyst. Eng. 2021, 206, 55–66. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Dan, B.J.; Dominiak, K.; Pedersen, L.J. Automatic estimation of slaughter pig live weight using convolutional neural networks. In Proceedings of the International Conference on Agro BigData and Decision Support Systems in Agriculture, Lleida, Spain, 12–14 July 2018; Universitat de Lleida: Lleida, Spain, 2018; pp. 1–4. [Google Scholar]
- Cang, Y.; He, H.; Qiao, Y. An intelligent pig weights estimate method based on deep learning in sow stall environments. IEEE Access 2019, 7, 164867–164875. [Google Scholar] [CrossRef]
- Zhang, J.; Zhuang, Y.; Ji, H.; Teng, G. Pig weight and body size estimation using a multiple output regression convolutional neural network: A fast and fully automatic method. Sensors 2021, 21, 3218. [Google Scholar] [CrossRef]
- Meckbach, C.; Tiesmeyer, V.; Traulsen, I. A promising approach towards precise animal weight monitoring using convolutional neural networks. Comput. Electron. Agric. 2021, 183, 106056. [Google Scholar] [CrossRef]
- He, H.; Qiao, Y.; Li, X.; Chen, C.; Zhang, X. Automatic weight measurement of pigs based on 3D images and regression network. Comput. Electron. Agric. 2021, 187, 106299. [Google Scholar] [CrossRef]
- Hansen, M.F.; Smith, M.L.; Smith, L.N.; Salter, M.G.; Baxter, E.M.; Farish, M.; Grieve, B. Towards on-farm pig face recognition using convolutional neural networks. Comput. Ind. 2018, 98, 145–152. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 386–397. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–23 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 11976–11986. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1492–1500. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4510–4520. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual Event, USA, 19–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 10012–10022. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin, Germany, 2014; pp. 740–755. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| learning rate | 0.0001 |
| gamma | 0.1 |
| weight decay | 0.05 |
| batch size | 4 |
| iteration | 9000 |
| BackBone Network | Training Set | Validation Set | Testing Set | Average Speed (s Frame−1) | Model Size | |||
|---|---|---|---|---|---|---|---|---|
| Average Precision of Bounding Box | Average Precision of Mask | Average Precision of Bounding Box | Average Precision of Mask | Average Precision of Bounding Box | Average Precision of Mask | |||
| ResNet | 97.22% | 90.59% | 93.93% | 88.39% | 92.84% | 87.85% | 0.079 | 25.56 M |
| ConvNeXt | 98.85% | 91.60% | 94.10% | 89.88% | 93.03% | 88.98% | 0.085 | 28.59 M |
| Improved ResNet | 99.81% | 92.30% | 96.63% | 91.65% | 93.65% | 91.04% | 0.15 | 28.72 M |
| BackBone Network | Training Set | Validation Set | Testing Set | Average Speed (s Frame−1) | |||
|---|---|---|---|---|---|---|---|
| Average Precision of Bounding | Average Precision of Keypoint | Average Precision of Bounding | Average Precision of Keypoint | Average Precision of Bounding | Average Precision of Keypoint | ||
| ResNet | 94.45% | 87.94% | 93.50% | 85.59% | 89.75% | 85.51% | 0.065 |
| ConvNeXt | 97.86% | 89.59% | 94.52% | 89.62% | 92.53% | 88.54% | 0.087 |
| Improved ResNet | 98.81% | 91.89% | 96.03% | 90.89% | 94.38% | 89.59% | 0.12 |
| Parameters | Values |
|---|---|
| learning rate | 0.0025 |
| gamma | 0.1 |
| weight decay | 0.0005 |
| batch size | 1 |
| epoch | 800 |
| BackBone Network | Training Set | Validation Set | Testing Set | Average Speed (s Frame−1) | |||
|---|---|---|---|---|---|---|---|
| Root Mean Square Error | Mean Absolute Percentage Error | Root Mean Square Error | Mean Absolute Percentage Error | Root Mean Square Error | Mean Absolute Percentage Error | ||
| ResNet | 5.94 kg | 3.38% | 9.36 kg | 6.19% | 10.87 kg | 6.77% | 0.014 |
| ConvNeXt | 3.65 kg | 3.15% | 4.94 kg | 3.93% | 5.15 kg | 4.12% | 0.052 |
| Improved ResNet | 2.81 kg | 2.25% | 3.01 kg | 2.41% | 3.52 kg | 2.82% | 0.069 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Xiao, D.; Liu, Y.; Huang, Y. A Pig Mass Estimation Model Based on Deep Learning without Constraint. Animals 2023, 13, 1376. https://doi.org/10.3390/ani13081376
Liu J, Xiao D, Liu Y, Huang Y. A Pig Mass Estimation Model Based on Deep Learning without Constraint. Animals. 2023; 13(8):1376. https://doi.org/10.3390/ani13081376
Chicago/Turabian StyleLiu, Junbin, Deqin Xiao, Youfu Liu, and Yigui Huang. 2023. "A Pig Mass Estimation Model Based on Deep Learning without Constraint" Animals 13, no. 8: 1376. https://doi.org/10.3390/ani13081376
APA StyleLiu, J., Xiao, D., Liu, Y., & Huang, Y. (2023). A Pig Mass Estimation Model Based on Deep Learning without Constraint. Animals, 13(8), 1376. https://doi.org/10.3390/ani13081376