
Improved Re-Parameterized Convolution for Wildlife Detection in Neighboring Regions of Southwest China


Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
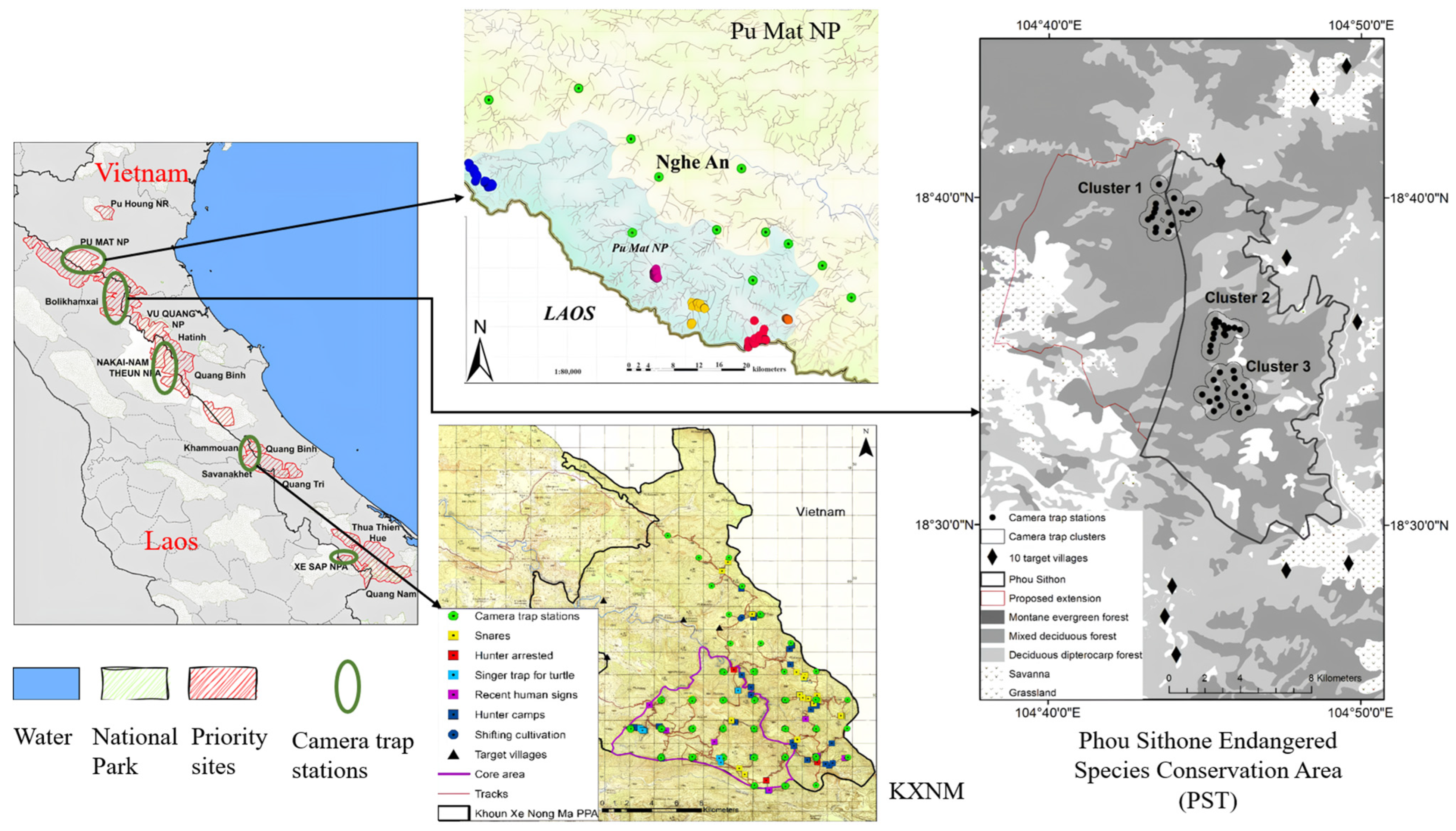
2.1. Data Acquisition and Pre-Processing
2.1.1. SWG Dataset
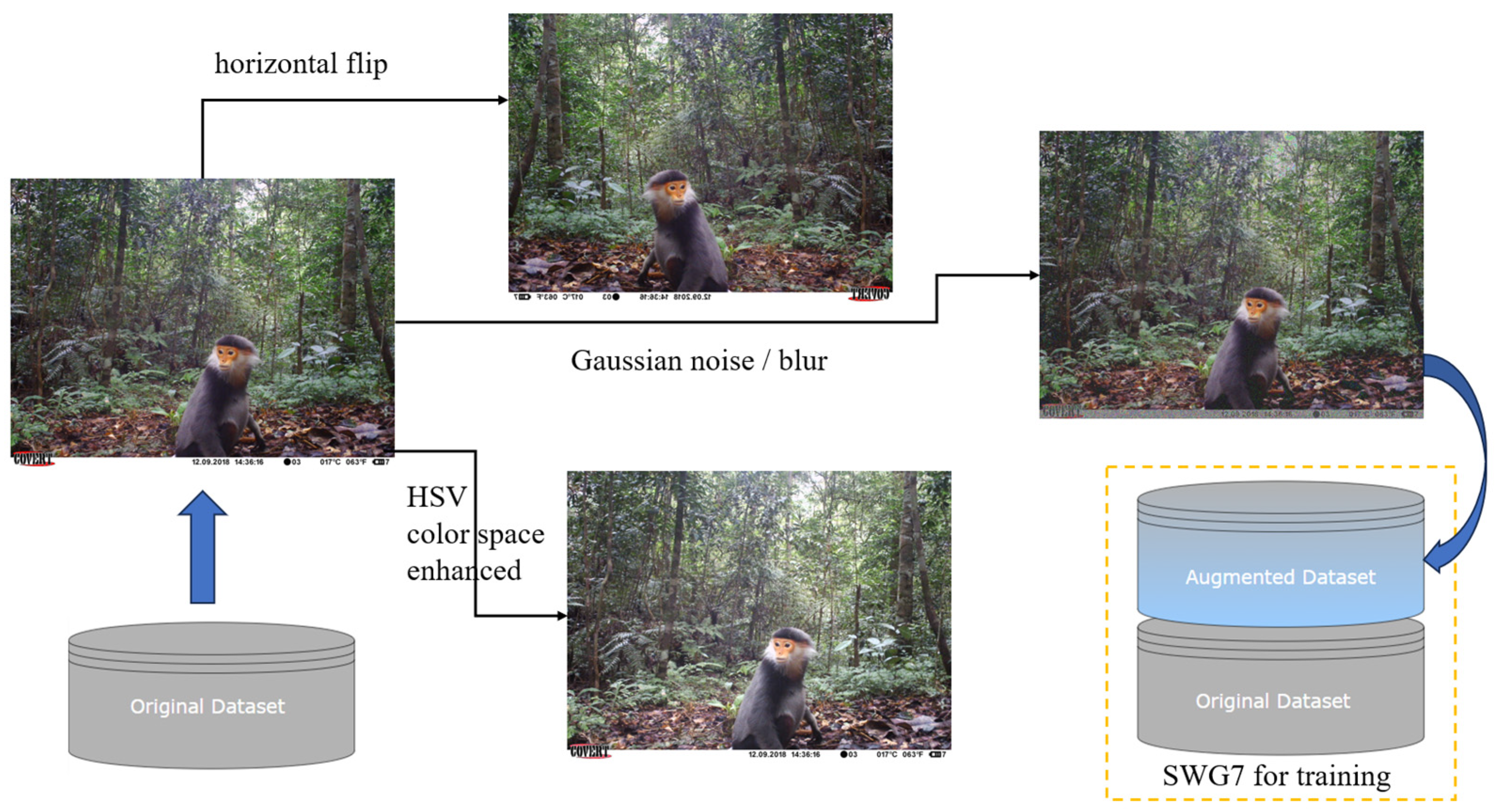
2.1.2. Dataset Annotation and Augmentation
2.2. Experimental Environment and Parameter Settings
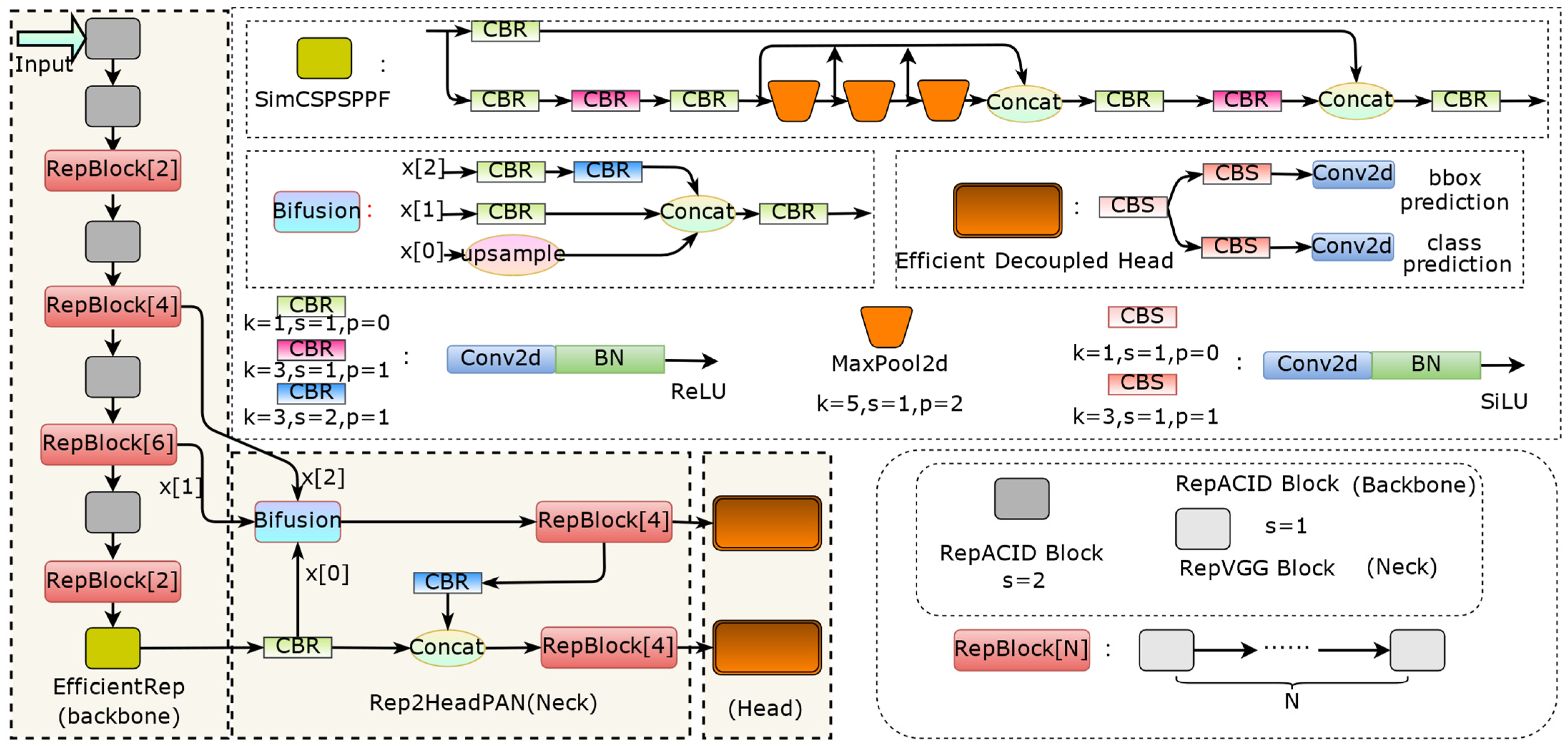
2.3. WildLife Detection Network
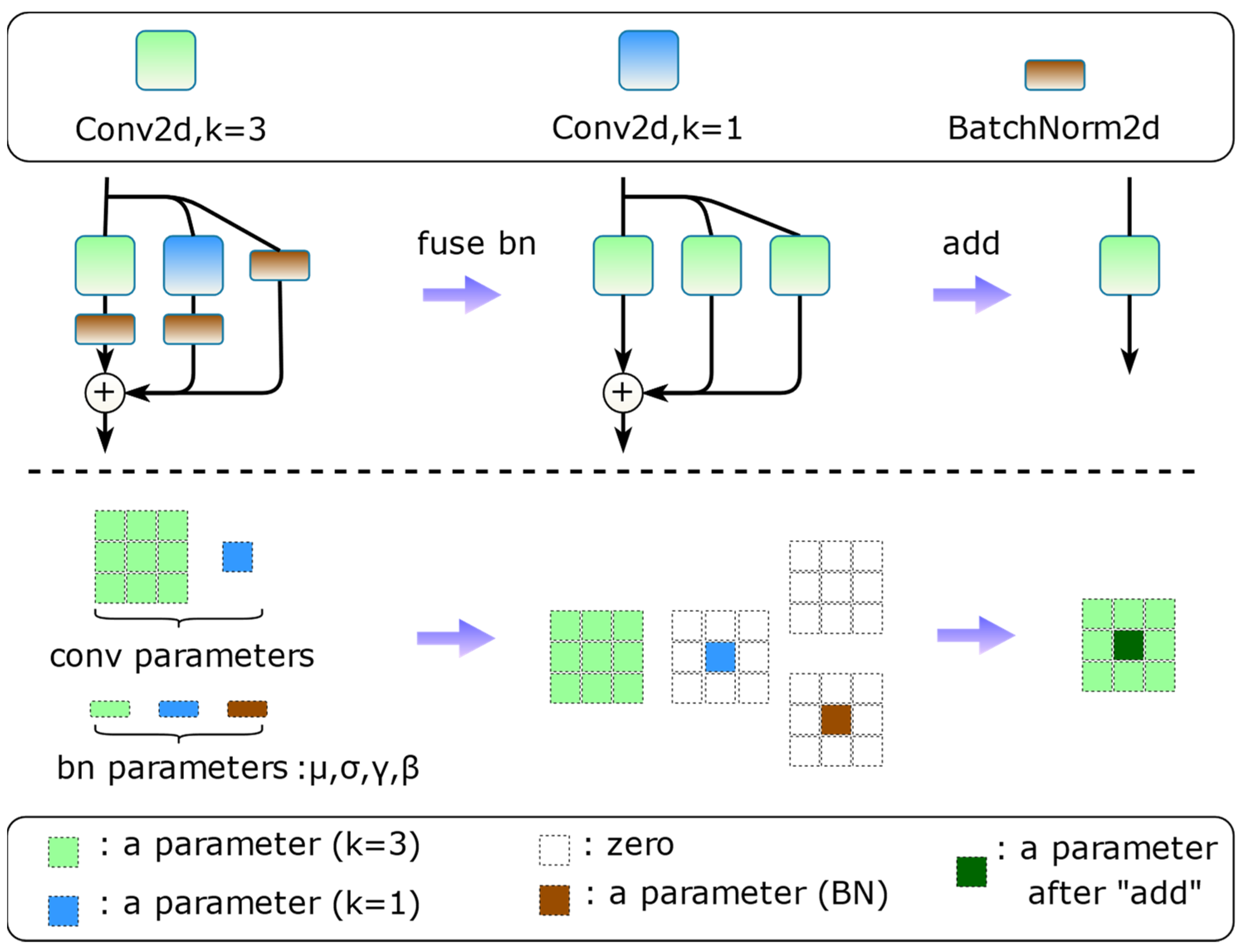
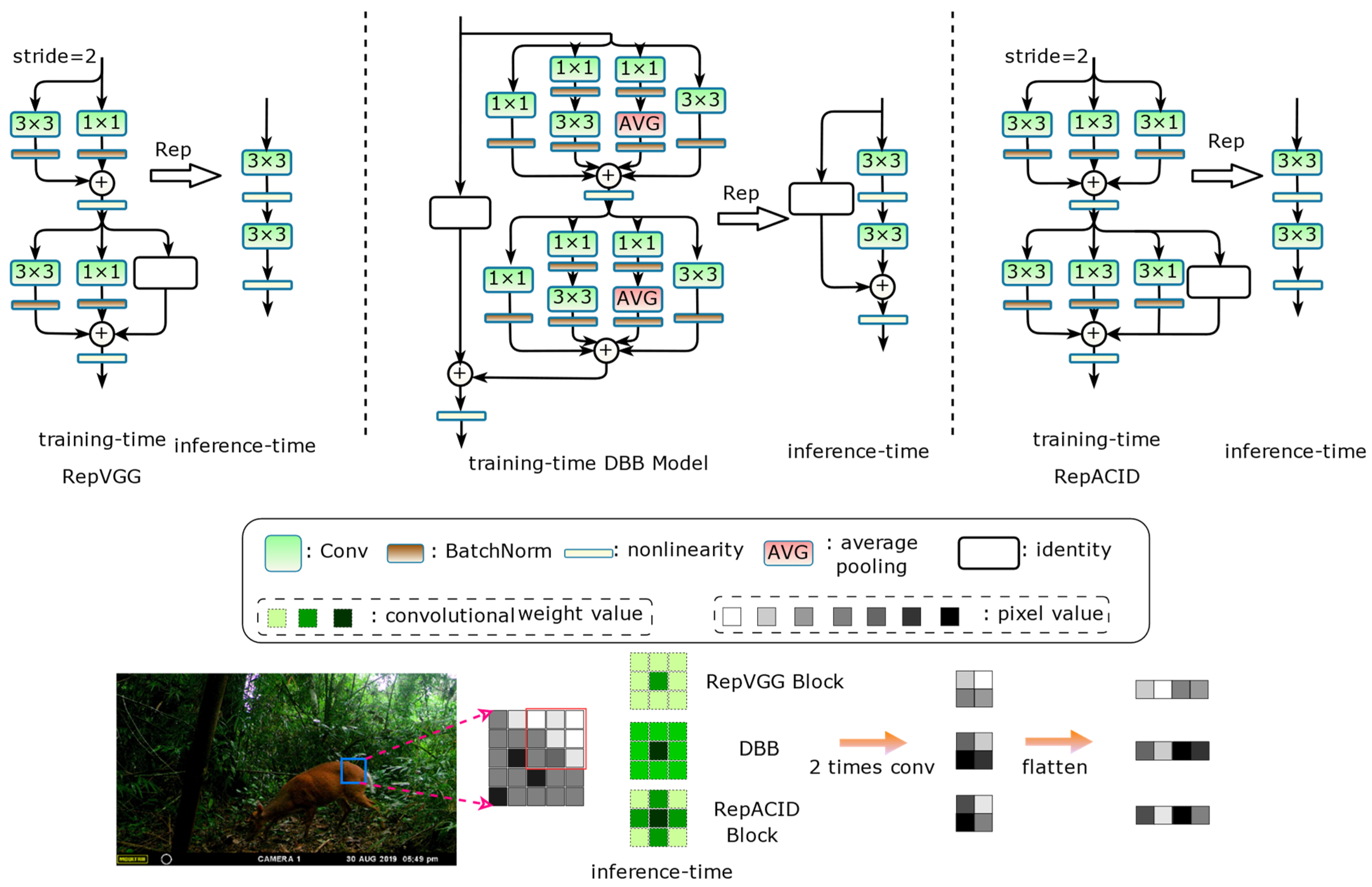
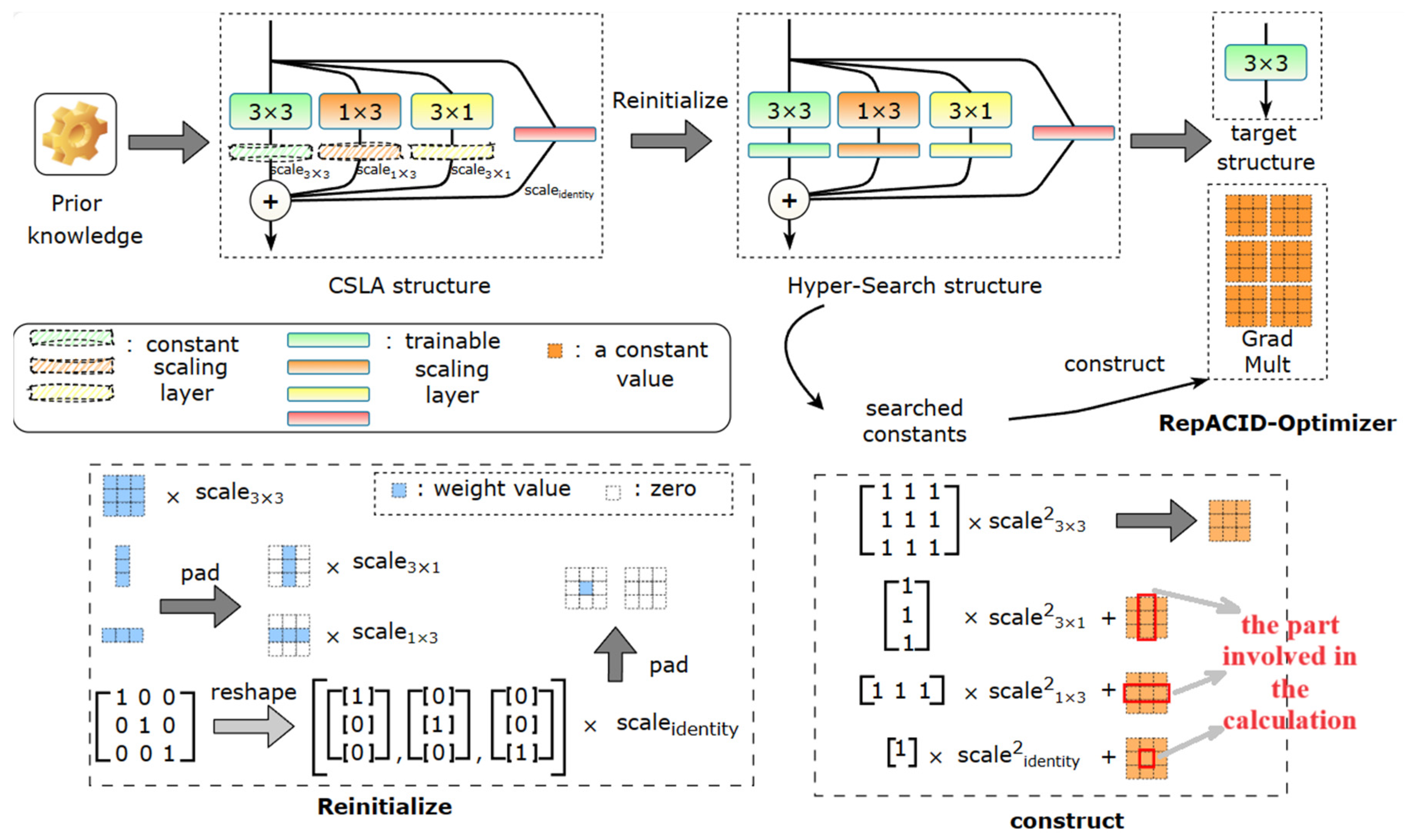
2.3.1. Re-Parameterized Convolution
2.3.2. YOLOv6
2.3.3. Inferring Faster Neck and Head
2.3.4. Box Regression Loss Function Improvement
2.3.5. Quantization of Re-Parameterized Structures
3. Results
3.1. Evaluation Criteria
3.2. Results of Improved Algorithm Experiments
3.2.1. Comparison on Public Dataset
3.2.2. SWG7 Dataset Ablation Study
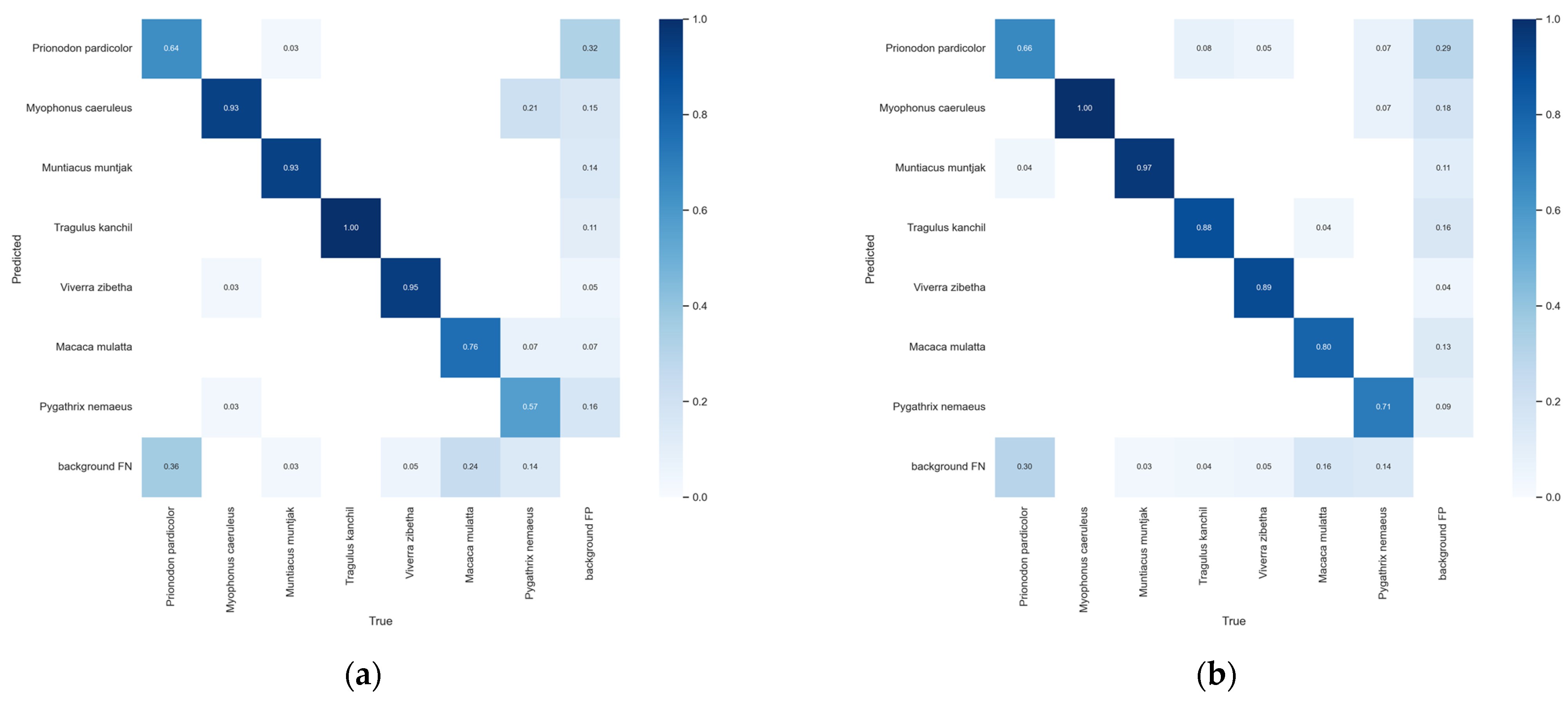
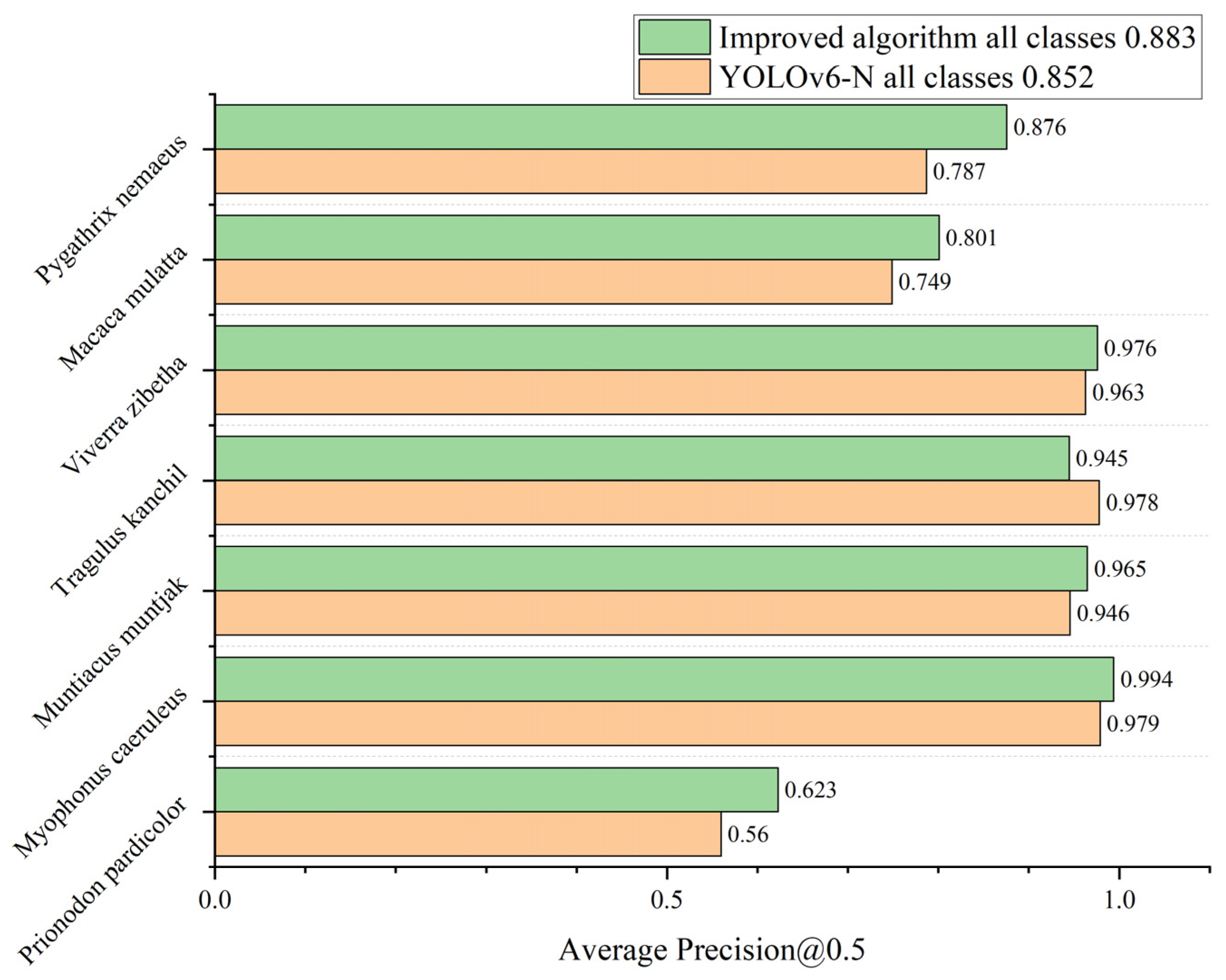
3.2.3. SWG7 Dataset Test Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chardonnet, P.; Des Clers, B.; Fisher, J.R.; Gerhold, R.; Jori, F.; Lamarque, F. The Value of Wildlife. Rev. Sci. Tech. OIE 2002, 21, 15–51. [Google Scholar] [CrossRef]
- Zhang, L.; Hua, N.; Sun, S. Wildlife Trade, Consumption and Conservation Awareness in Southwest China. Biodivers. Conserv. 2008, 17, 1493–1516. [Google Scholar] [CrossRef]
- Maydanov, M.; Andreychev, A.; Boyarova, E.; Kuznetsov, V.; Ilykaeva, E. Small mammals as reservoirs of tularemia and hfrs in the forest zone of saransk. For. Ideas 2021, 27, 128–135. [Google Scholar]
- Mackenzie, J.S.; Jeggo, M. The One Health Approach—Why Is It So Important? Trop. Med. Infect. Dis. 2019, 4, 88. [Google Scholar] [CrossRef]
- Schneider, T.C.; Kowalczyk, R.; Köhler, M. Resting Site Selection by Large Herbivores—The Case of European Bison (Bison Bonasus) in Białowieża Primeval Forest. Mamm. Biol. 2013, 78, 438–445. [Google Scholar] [CrossRef]
- Silaeva, T.; Andreychev, A.; Kiyaykina, O.; Balčiauskas, L. Taxonomic and Ecological Composition of Forest Stands Inhabited by Forest Dormouse Dryomys Nitedula (Rodentia: Gliridae) in the Middle Volga. Biologia 2020, 76, 1475–1482. [Google Scholar] [CrossRef]
- Noad, M.J.; Cato, D.H.; Stokes, M.D. Acoustic Tracking of Humpback Whales: Measuring Interactions with the Acoustic Environment. In Proceedings of the ACOUSTICS, Gold Coast, Australia, 3–5 November 2004; pp. 353–358. [Google Scholar]
- Swanson, A.; Kosmala, M.; Lintott, C.; Simpson, R.; Smith, A.; Packer, C. Snapshot Serengeti, High-Frequency Annotated Camera Trap Images of 40 Mammalian Species in an African Savanna. Sci. Data 2015, 2, 150026. [Google Scholar] [CrossRef]
- Sunitha, K. Automatically Identifying Wild Animals in Camera-Trap Images with Deep Learning. Int. J. Comput. Sci. Eng. 2021, 8, 12–16. [Google Scholar] [CrossRef]
- Maire, F.; Alvarez, L.M.; Hodgson, A. Automating Marine Mammal Detection in Aerial Images Captured During Wildlife Surveys: A Deep Learning Approach. In AI 2015: Advances in Artificial Intelligence; Pfahringer, B., Renz, J., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; Volume 9457, pp. 379–385. ISBN 978-3-319-26349-6. [Google Scholar]
- Ward, S.; Hensler, J.; Alsalam, B.; Gonzalez, L.F. Autonomous UAVs Wildlife Detection Using Thermal Imaging, Predictive Navigation and Computer Vision. In Proceedings of the 2016 IEEE Aerospace Conference, Big Sky, MT, USA, 5–12 March 2016; IEEE: Big Sky, MT, USA, 2016; pp. 1–8. [Google Scholar]
- Hyun, C.-U.; Park, M.; Lee, W.Y. Remotely Piloted Aircraft System (RPAS)-Based Wildlife Detection: A Review and Case Studies in Maritime Antarctica. Animals 2020, 10, 2387. [Google Scholar] [CrossRef]
- Wang, D.; Shao, Q.; Yue, H. Surveying Wild Animals from Satellites, Manned Aircraft and Unmanned Aerial Systems (UASs): A Review. Remote Sens. 2019, 11, 1308. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A Survey on Object Detection in Optical Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Peng, J.; Wang, D.; Liao, X.; Shao, Q.; Sun, Z.; Yue, H.; Ye, H. Wild Animal Survey Using UAS Imagery and Deep Learning: Modified Faster R-CNN for Kiang Detection in Tibetan Plateau. ISPRS J. Photogramm. Remote Sens. 2020, 169, 364–376. [Google Scholar] [CrossRef]
- Chen, R.; Little, R.; Mihaylova, L.; Delahay, R.; Cox, R. Wildlife Surveillance Using Deep Learning Methods. Ecol. Evol. 2019, 9, 9453–9466. [Google Scholar] [CrossRef] [PubMed]
- Miao, Z.; Gaynor, K.M.; Wang, J.; Liu, Z.; Muellerklein, O.; Norouzzadeh, M.S.; McInturff, A.; Bowie, R.C.K.; Nathan, R.; Yu, S.X.; et al. Insights and Approaches Using Deep Learning to Classify Wildlife. Sci. Rep. 2019, 9, 8137. [Google Scholar] [CrossRef] [PubMed]
- Clapham, M.; Miller, E.; Nguyen, M.; Darimont, C.T. Automated Facial Recognition for Wildlife That Lack Unique Markings: A Deep Learning Approach for Brown Bears. Ecol. Evol. 2020, 10, 12883–12892. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.; Liu, T.; Jiang, P.; Qi, A.; Deng, L.; Liu, Z.; He, Y. A Forest Wildlife Detection Algorithm Based on Improved YOLOv5s. Animals 2023, 13, 3134. [Google Scholar] [CrossRef] [PubMed]
- Roy, A.M.; Bhaduri, J.; Kumar, T.; Raj, K. WilDect-YOLO: An Efficient and Robust Computer Vision-Based Accurate Object Localization Model for Automated Endangered Wildlife Detection. Ecol. Inform. 2023, 75, 101919. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Kim, J.S.; Elli, G.V.; Bedny, M. Knowledge of Animal Appearance among Sighted and Blind Adults. Proc. Natl. Acad. Sci. USA 2019, 116, 11213–11222. [Google Scholar] [CrossRef] [PubMed]
- Chabot, D.; Stapleton, S.; Francis, C.M. Measuring the Spectral Signature of Polar Bears from a Drone to Improve Their Detection from Space. Biol. Conserv. 2019, 237, 125–132. [Google Scholar] [CrossRef]
- Feng, J.; Li, J. An Adaptive Embedding Network with Spatial Constraints for the Use of Few-Shot Learning in Endangered-Animal Detection. ISPRS Int. J. Geo-Inf. 2022, 11, 256. [Google Scholar] [CrossRef]
- Zhao, T.; Yi, X.; Zeng, Z.; Feng, T. MobileNet-Yolo Based Wildlife Detection Model: A Case Study in Yunnan Tongbiguan Nature Reserve, China. J. Intell. Fuzzy Syst. 2021, 41, 2171–2181. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Geng, Y.; Jiang, H.; Cheng, M.; Zhang, B.; Ke, Z.; Xu, X.; Chu, X. YOLOv6 v3.0: A Full-Scale Reloading. arXiv 2023, arXiv:2301.05586. [Google Scholar]
- Ding, X.; Chen, H.; Zhang, X.; Huang, K.; Han, J.; Ding, G. Re-Parameterizing Your Optimizers Rather than Architectures. arXiv 2022, arXiv:2205.15242. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv Preprint 2014, arXiv:1409.1556. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- The Saola Working Group—Save the Saola. Available online: https://www.savethesaola.org/swg/ (accessed on 7 April 2024).
- LILA BC. Lilawp SWG Camera Traps 2018–2020. 2021. Available online: https://lila.science/datasets/swg-camera-traps (accessed on 17 March 2024).
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2015, arXiv:1405.0312. [Google Scholar]
- Foszner, P.; Szczęsna, A.; Ciampi, L.; Messina, N.; Cygan, A.; Bizoń, B.; Cogiel, M.; Golba, D.; Macioszek, E.; Staniszewski, M. CrowdSim2: An Open Synthetic Benchmark for Object Detectors. In Proceedings of the 18th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Lisbon, Portugal, 19–21 February 2023; pp. 676–683. [Google Scholar]
- Niu, L.; Cong, W.; Liu, L.; Hong, Y.; Zhang, B.; Liang, J.; Zhang, L. Making Images Real Again: A Comprehensive Survey on Deep Image Composition. arXiv 2021, arXiv:2106.14490. [Google Scholar]
- TensorRT SDK|NVIDIA Developer. Available online: https://developer.nvidia.com/tensorrt (accessed on 12 March 2024).
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ding, X.; Guo, Y.; Ding, G.; Han, J. ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-Style ConvNets Great Again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Diverse Branch Block: Building a Convolution as an Inception-like Unit. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Weng, K.; Chu, X.; Xu, X.; Huang, J.; Wei, X. EfficientRep:An Efficient Rpvgg-Style ConvNets with Hardware-Aware Neural Network Design. arXiv 2023, arXiv:2302.00386. [Google Scholar]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-Neck by GSConv: A Better Design Paradigm of Detector Architectures for Autonomous Vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: A Simple and Strong Anchor-Free Object Detector. Ieee Trans. Pattern Anal. Mach. Intell. 2020, 44, 1922–1933. [Google Scholar] [CrossRef] [PubMed]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. arXiv 2019, arXiv:1911.08287. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss V2: Learning Reliable Localization Quality Estimation for Dense Object Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Nashville, TN, USA, 2021; pp. 11627–11636. [Google Scholar]
- He, J.; Erfani, S.; Ma, X.; Bailey, J.; Chi, Y.; Hua, X.-S. Alpha-IoU: A Family of Power Intersection over Union Losses for Bounding Box Regression. arXiv 2021, arXiv:2110.13675. [Google Scholar]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sünderhauf, N. VarifocalNet: An IoU-Aware Dense Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Chu, X.; Li, L.; Zhang, B. Make RepVGG Greater Again: A Quantization-Aware Approach. arXiv 2022, arXiv:2212.01593. [Google Scholar] [CrossRef]
- Nagel, M.; Fournarakis, M.; Amjad, R.A.; Bondarenko, Y.; van Baalen, M.; Blankevoort, T. A White Paper on Neural Network Quantization. arXiv 2021, arXiv:2106.08295. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Country | Province | Site | Survey Period | Trap Nights | Camera Station |
|---|---|---|---|---|---|
| Laos | Khammouane | KXNM | June 2017–November 2019 | 63,977 | 311 |
| February–April 2020 | - | 270 | |||
| Xe Kong | SAP | July 2018–April 2019 | 26,991 | 181 | |
| - | NNT | 2018 | - | 29 | |
| Bolikhamxay | PST | June–November 2019 | 5151 | 47 | |
| Thongmixay | August–November 2019 | 497 | 7 | ||
| Vietnam | - | Pu Mat | January–December 2018 | - | 165 |
| November 2018–December 2019 | 23,144 | 152 |
| Model | Params (M) | FLOPs (G) | mAP0.5 (%) |
|---|---|---|---|
| YOLOv6-N | 4.63 | 11.35 | 80.5 |
| YOLOv6-T | 10.42 | 25.46 | 84.2 |
| YOLOv7-T | 6.06 | 13.2 | 80.0 |
| YOLOv8-T | 6.42 | 16.8 | 82.3 |
| YOLOv6-N * | 4.64 | 11.43 | 81.9 |
| RepACID | 2 Detection Head | CIoU | α-IoU | Params (M) | FLOPs (G) | mAP0.5 (%) | mAP0.5:0.95 (%) | FPS (bs = 16) |
|---|---|---|---|---|---|---|---|---|
| - | - | - | - | 4.63 | 11.34 | 85.2 | 55.5 | 306.7 |
| - | √ | - | - | 4.39 | 9.82 | 85.8 | 53.4 | 367.3 |
| √ | - | - | - | 4.63 | 11.34 | 86.6 | 56.8 | 305.8 |
| √ | √ | - | - | 4.39 | 9.82 | 87.3 | 58.1 | 365.6 |
| √ | √ | √ | √ | 4.39 | 9.82 | 86.4 | 58.2 | 364.3 |
| √ | √ | √ | - | 4.39 | 9.82 | 88.3 | 58.8 | 366.5 |
| Method | Precision | mAP0.5 (%) | mAP0.5:0.95 (%) | Latency (ms) |
|---|---|---|---|---|
| PTQ | FP16 | 87.2 | 57.1 | 7.24 |
| INT8 | 84.2 | 55.4 | 6.21 | |
| QAT | FP16 | 87.5 | 58.2 | 7.22 |
| INT8 | 85.1 | 57.5 | 6.18 | |
| RepACID-Optimizer | FP16 | 87.6 | 58.2 | 7.19 |
| INT8 | 85.3 | 57.6 | 6.15 |
| Model | Params (M) | FLOPs (G) | mAP0.5 (%) | mAP0.5:0.95 (%) | Model Size (MB) | FPS (bs = 16) | FPS (bs = 1) |
|---|---|---|---|---|---|---|---|
| YOLOv6-N | 4.63 | 11.34 | 85.2 | 55.5 | 10.4 | 306.7 | 112.1 |
| YOLOv7-T | 6.03 | 13.2 | 82.8 | 50.5 | 12.3 | 312.5 | 131.6 |
| YOLOv8-N | 3.01 | 8.2 | 85.5 | 57.8 | 6.2 | 294.1 | 109.9 |
| Ours | 4.39 | 9.82 | 88.3 | 58.8 | 8.9 | 366.5 | 158.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, W.; Li, G.; Li, X. Improved Re-Parameterized Convolution for Wildlife Detection in Neighboring Regions of Southwest China. Animals 2024, 14, 1152. https://doi.org/10.3390/ani14081152
Mao W, Li G, Li X. Improved Re-Parameterized Convolution for Wildlife Detection in Neighboring Regions of Southwest China. Animals. 2024; 14(8):1152. https://doi.org/10.3390/ani14081152
Chicago/Turabian StyleMao, Wenjie, Gang Li, and Xiaowei Li. 2024. "Improved Re-Parameterized Convolution for Wildlife Detection in Neighboring Regions of Southwest China" Animals 14, no. 8: 1152. https://doi.org/10.3390/ani14081152