
A Bibliometric Analysis of the Rise of ChatGPT in Medical Research

 , ,
, , 
Abstract
:1. Introduction
2. Materials and Methods
3. Results
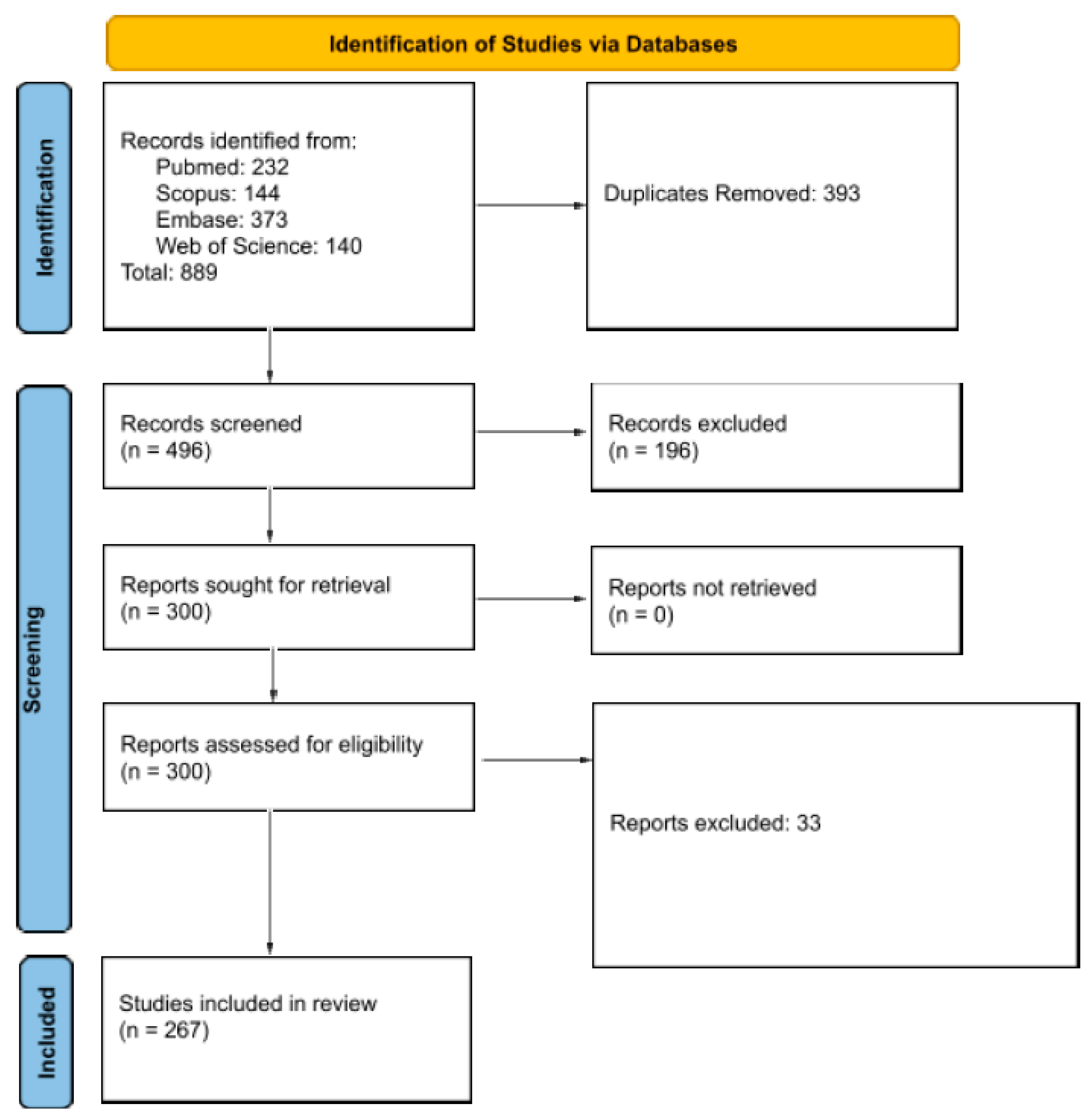
3.1. Search Results
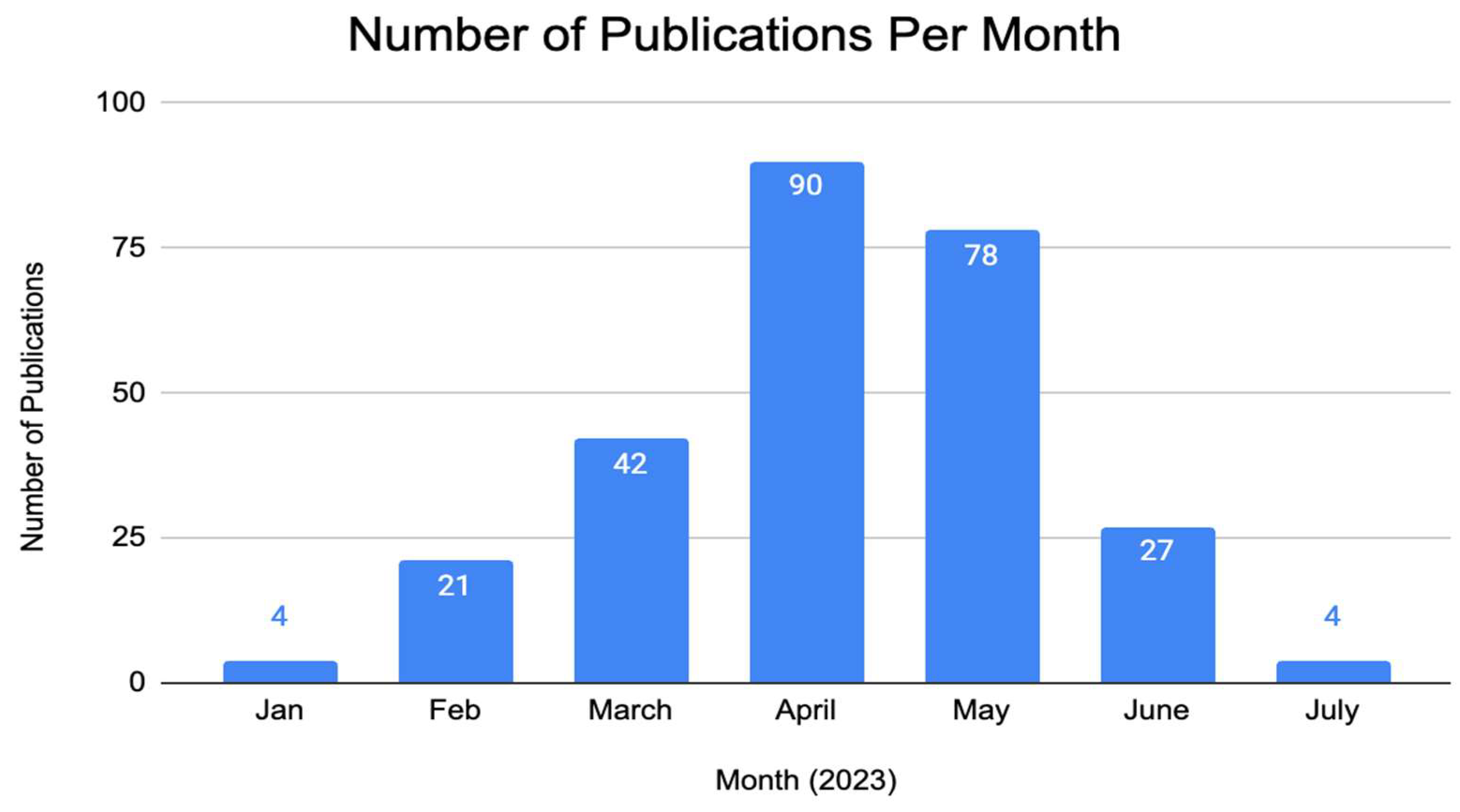
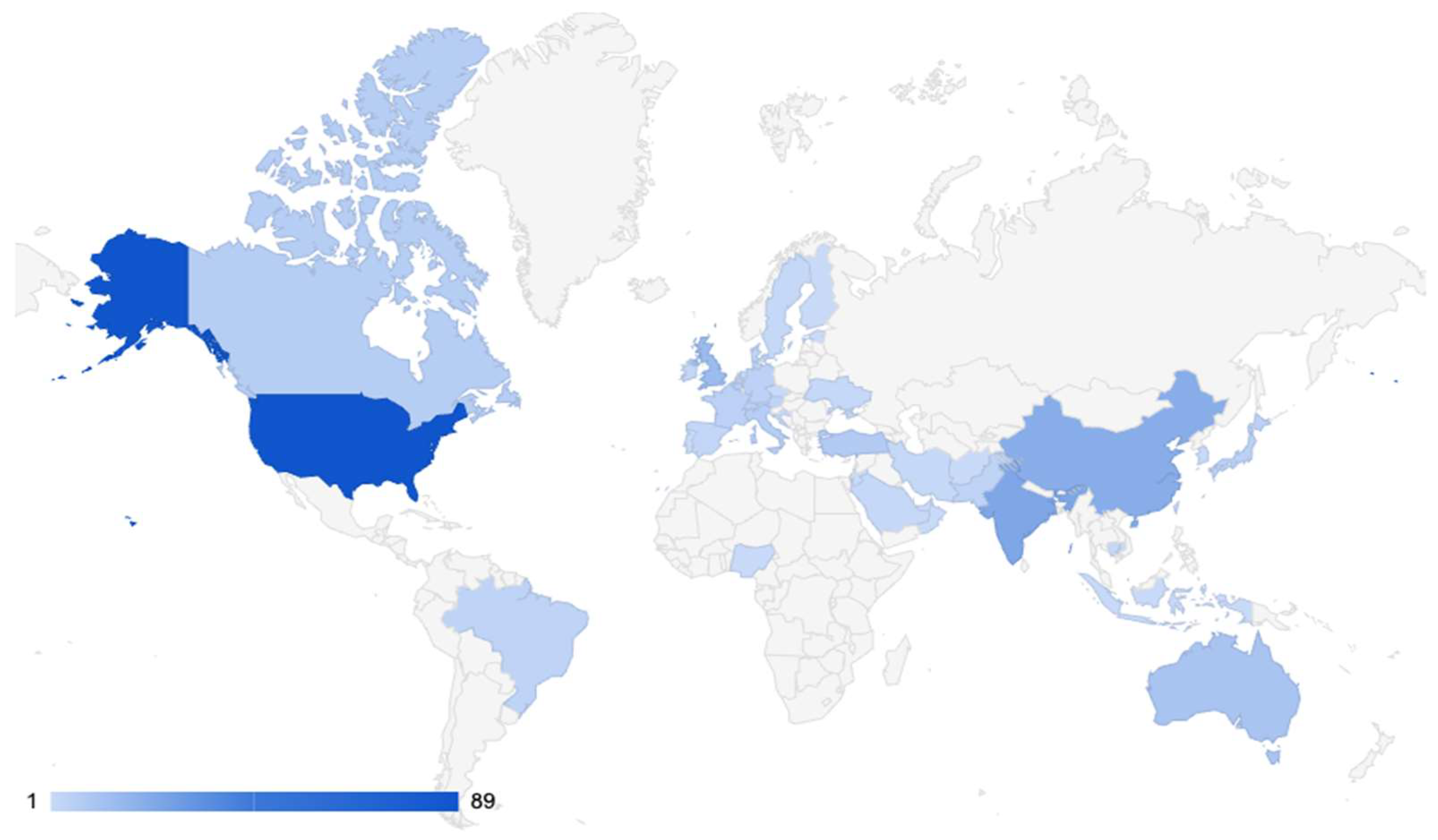
3.2. General Characteristics, Temporal and Geographic Trends
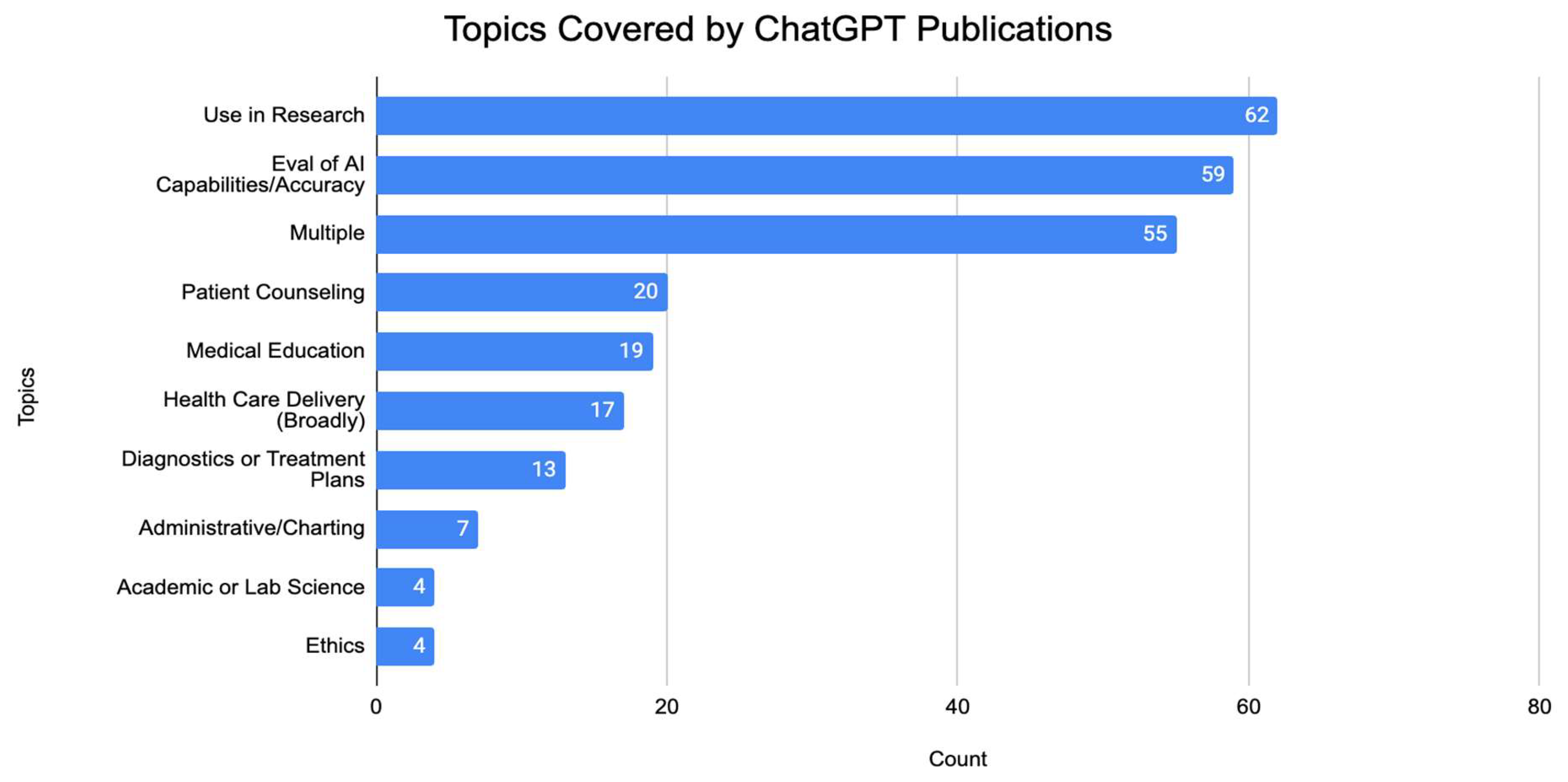
3.3. Topics and Medical Specialties
3.4. Citation Metrics and Characteristics of Top 20 Cited Studies
3.5. Top Journals and Keywords
4. Discussion
Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sejnowski, T.J. Large Language Models and the Reverse Turing Test. Neural Comput. 2023, 35, 309–342. [Google Scholar] [CrossRef]
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepaño, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J.; et al. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLoS Digit. Health 2023, 2, e0000198. [Google Scholar] [CrossRef] [PubMed]
- Jeblick, K.; Schachtner, B.; Dexl, J.; Mittermeier, A.; Stüber, A.T.; Topalis, J.; Weber, T.; Wesp, P.; Sabel, B.; Ricke, J.; et al. ChatGPT Makes Medicine Easy to Swallow: An Exploratory Case Study on Simplified Radiology Reports. arXiv 2022, arXiv:2212.14882. Available online: http://arxiv.org/abs/2212.14882 (accessed on 1 August 2023).
- Introducing ChatGPT. Available online: https://openai.com/blog/chatgpt (accessed on 4 September 2023).
- Li, H.; Moon, J.T.; Purkayastha, S.; Celi, L.A.; Trivedi, H.; Gichoya, J.W. Ethics of large language models in medicine and medical research. Lancet Digit. Health 2023, 5, e333–e335. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. Available online: https://arxiv.org/abs/1706.03762 (accessed on 1 August 2023).
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2016, arXiv:1409.04732014. Available online: https://arxiv.org/abs/1409.0473 (accessed on 1 August 2023).
- Transformer Architecture: The Engine Behind ChatGPT. Available online: https://www.thoughtspot.com/data-trends/ai/what-is-transformer-architecture-chatgpt (accessed on 28 August 2023).
- Carman, J.; Cui, J. Inside ChatGPT: How AI chatbots work. NBC News, 17 May 2023. Available online: https://www.nbcnews.com/data-graphics/chat-gpt-artificial-intelligence-how-chatbot-work-rcna83266 (accessed on 1 August 2023).
- Hu, K. ChatGPT sets record for fastest-growing user base—Analyst note. Reuters, 2 February 2023. Available online: https://www.reuters.com/technology/chatgpt-sets-record-fastest-growing-user-base-analyst-note-2023-02-01/ (accessed on 1 August 2023).
- Tamayo-Sarver, J. I’m an ER doctor, here’s how I’m using ChatGP to help treat patients. Fast Company, 15 May 2023. Available online: https://www.fastcompany.com/90895618/how-a-doctor-uses-chat-gpt-to-treat-patients (accessed on 1 August 2023).
- Subbaraman, N. ChatGPT Will See You Now: Doctors Using AI to Answer Patient Questions. WSJ, 28 April 2023. Available online: https://www.wsj.com/articles/dr-chatgpt-physicians-are-sending-patients-advice-using-ai-945cf60b (accessed on 1 August 2023).
- Barnett, S. ChatGPT Is Making Universities Rethink Plagiarism. WIRED, 30 January 2023. Available online: https://www.wired.com/story/chatgpt-college-university-plagiarism/ (accessed on 1 August 2023).
- Dave, T.; Athaluri, S.A.; Singh, S. ChatGPT in medicine: An overview of its applications, advantages, limitations, future prospects, and ethical considerations. Front. Artif. Intell. 2023, 6, 1169595. [Google Scholar] [CrossRef]
- Wen, J.; Wang, W. The future of ChatGPT in academic research and publishing: A commentary for clinical and translational medicine. Clin. Transl. Med. 2023, 13, e1207. [Google Scholar] [CrossRef]
- Sebastian, G. Exploring Ethical Implications of ChatGPT and Other AI Chatbots and Regulation of Disinformation Propagation. SSRN Electron. J. 2023, 1–16. [Google Scholar] [CrossRef]
- Varanasi, L. AI models like ChatGPT and GPT-4 are acing everything from the bar exam to AP Biology. Here’s a list of difficult exams both AI versions have passed. Business Insider, 25 June 2023. Available online: https://www.businessinsider.com/list-here-are-the-exams-chatgpt-has-passed-so-far-2023-1 (accessed on 1 August 2023).
- Oztermeli, A.D.; Oztermeli, A. ChatGPT performance in the medical specialty exam: An observational study. Medicine 2023, 102, e34673. [Google Scholar] [CrossRef] [PubMed]
- Gilson, A.; Safranek, C.W.; Huang, T.; Socrates, V.; Chi, L.; Taylor, R.A.; Chartash, D. How Does ChatGPT Perform on the United States Medical Licensing Examination? The Implications of Large Language Models for Medical Education and Knowledge Assessment. JMIR Med. Educ. 2023, 9, e45312. [Google Scholar] [CrossRef]
- Stokel-Walker, C. ChatGPT listed as author on research papers. Nature 2023, 613, 620–621. [Google Scholar] [CrossRef]
- Gupta, N.K.; Doyle, D.M.; D’amico, R.S. Response to “Large language model artificial intelligence: The current state and future of ChatGPT in neuro-oncology publishing”. J. Neuro Oncol. 2023, 163, 731–733. [Google Scholar] [CrossRef] [PubMed]
- Will ChatGPT Transform Healthcare? Nat. Med. 2023, 29, 505–506. [CrossRef] [PubMed]
- Qureshi, R.; Shaughnessy, D.; Gill, K.A.R.; Robinson, K.A.; Li, T.; Agai, E. Are ChatGPT and large language models “the answer” to bringing us closer to systematic review automation? Syst. Rev. 2023, 12, 72. [Google Scholar] [CrossRef] [PubMed]
- Mahuli, S.A.; Rai, A.; Mahuli, A.V.; Kumar, A. Application ChatGPT in conducting systematic reviews and meta-analyses. Br. Dent. J. 2023, 235, 90–92. [Google Scholar] [CrossRef] [PubMed]
- Feng, S.; Shen, Y. ChatGPT and the Future of Medical Education. Acad. Med. 2023, 98, 867. [Google Scholar] [CrossRef]
- Mohammad, B.; Supti, T.; Alzubaidi, M.; Shah, H.; Alam, T.; Shah, Z.; Househ, M. The Pros and Cons of Using ChatGPT in Medical Education: A Scoping Review; Mantas, J., Gallos, P., Zoulias, E., Hasman, A., Househ, M.S., Charalampidou, M., Magdalinou, A., Eds.; Studies in Health Technology and Informatics; IOS Press: Amsterdam, The Netherlands, 2023. [Google Scholar] [CrossRef]
- Mondal, H.; Mondal, S.; Podder, I. Using ChatGPT for writing articles for patients’ education for dermatological diseases: A pilot study. Indian Dermatol. Online J. 2023, 14, 482. [Google Scholar] [CrossRef]
- Zhao, J.; Shao, C.; Li, H.; Liu, X.-L.; Li, C.; Yang, L.-Q.; Zhang, Y.-J.; Luo, J. Appropriateness and Comprehensiveness of Using ChatGPT for Perioperative Patient Education in Thoracic Surgery in Different Language Contexts: Survey Study. Interact. J. Med Res. 2023, 12, e46900. [Google Scholar] [CrossRef]
- GPT-4 vs. ChatGPT-3.5: What’s the Difference? PCMag, 16 March 2023. Available online: https://www.pcmag.com/news/the-new-chatgpt-what-you-get-with-gpt-4-vs-gpt-35 (accessed on 28 August 2023).
- Ouzzani, M.; Hammady, H.; Fedorowicz, Z.; Elmagarmid, A. Rayyan—A web and mobile app for systematic reviews. Syst. Rev. 2016, 5, 210. [Google Scholar] [CrossRef]
- First Time Journal Citation Reports Inclusion List 2023. Clarivate. Available online: https://clarivate.com/first-time-journal-citation-reports-inclusion-list-2023/ (accessed on 1 August 2023).
- Shah, N.H.; Entwistle, D.; Pfeffer, M.A. Creation and Adoption of Large Language Models in Medicine. JAMA 2023, 330, 866–869. [Google Scholar] [CrossRef]
- Savage, N. The race to the top among the world’s leaders in artificial intelligence. Nature 2020, 588, S102–S104. [Google Scholar] [CrossRef]
- Country/Territory Tables | Nature Index. Available online: https://www.nature.com/nature-index/country-outputs/generate/all/global (accessed on 4 September 2023).
- Fontelo, P.; Liu, F. A review of recent publication trends from top publishing countries. Syst. Rev. 2018, 7, 147. [Google Scholar] [CrossRef]
- Grewal, H.; Dhillon, G.; Monga, V.; Sharma, P.; Buddhavarapu, V.S.; Sidhu, G.; Kashyap, R. Radiology Gets Chatty: The ChatGPT Saga Unfolds. Cureus 2023, 15, e40135. [Google Scholar] [CrossRef]
- Bosbach, W.A.; Senge, J.F.; Nemeth, B.; Omar, S.H.; Mitrakovic, M.; Beisbart, C.; Horváth, A.; Heverhagen, J.; Daneshvar, K. Ability of ChatGPT to generate competent radiology reports for distal radius fracture by use of RSNA template items and integrated AO classifier. Curr. Probl. Diagn. Radiol. 2023, in press. [Google Scholar] [CrossRef]
- Harris, J.E. An AI-Enhanced Electronic Health Record Could Boost Primary Care Productivity. JAMA 2023, 330, 801. [Google Scholar] [CrossRef]
- Harris, E. Large Language Models Answer Medical Questions Accurately, but Can’t Match Clinicians’ Knowledge. JAMA 2023, 330, 792. [Google Scholar] [CrossRef]
- Walker, H.L.; Ghani, S.; Kuemmerli, C.; Nebiker, C.A.; Müller, B.P.; Raptis, D.A.; Staubli, S.M. Reliability of Medical Information Provided by ChatGPT: Assessment Against Clinical Guidelines and Patient Information Quality Instrument. J. Med. Internet Res. 2023, 25, e47479. [Google Scholar] [CrossRef]
- NRMP. Residency Data & Reports. Available online: https://www.nrmp.org/match-data-analytics/residency-data-reports/ (accessed on 1 August 2023).
- Wadhwa, H.; Shah, S.S.; Shan, J.; Cheng, J.; Beniwal, A.S.; Chen, J.-S.; Gill, S.A.; Mummaneni, N.; McDermott, M.W.; Berger, M.S.; et al. The neurosurgery applicant’s “arms race”: Analysis of medical student publication in the Neurosurgery Residency Match. J. Neurosurg. 2020, 133, 1913–1921. [Google Scholar] [CrossRef] [PubMed]
- Noy, S.; Zhang, W. Experimental evidence on the productivity effects of generative artificial intelligence. Science 2023, 381, 187–192. [Google Scholar] [CrossRef] [PubMed]
- Cascella, M.; Montomoli, J.; Bellini, V.; Bignami, E. Evaluating the Feasibility of ChatGPT in Healthcare: An Analysis of Multiple Clinical and Research Scenarios. J. Med. Syst. 2023, 47, 33. [Google Scholar] [CrossRef]
- Cifarelli, C.P.; Sheehan, J.P. Large language model artificial intelligence: The current state and future of ChatGPT in neuro-oncology publishing. J. Neuro Oncol. 2023, 163, 473–474. [Google Scholar] [CrossRef] [PubMed]
- Goto, A.; Katanoda, K. Should We Acknowledge ChatGPT as an Author? J. Epidemiol. 2023, 33, 333–334. [Google Scholar] [CrossRef]
- Howard, J. Concern Grows around US Health-Care Workforce Shortage: ‘We don’t Have Enough Doctors’. CNN, 16 May 2023. Available online: https://www.cnn.com/2023/05/16/health/health-care-worker-shortage/index.html (accessed on 1 August 2023).
- Reddy, V.P.; Singh, R.; McLelland, M.D.; Barpujari, A.; Catapano, J.S.; Srinivasan, V.M.; Lawton, M.T. Bibliometric Analysis of the Extracranial-Intracranial Bypass Literature. World Neurosurg. 2022, 161, 198–205.e5. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Li, Z.; Zhang, K.; Dan, R.; Jiang, S.; Zhang, Y. ChatDoctor: A Medical Chat Model Fine-Tuned on a Large Language Model Meta-AI (LLaMA) Using Medical Domain Knowledge. Cureus 2023, 15, e40895. [Google Scholar] [CrossRef] [PubMed]
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.S.; Wei, J.; Chung, H.W.; Scales, N.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; et al. Large language models encode clinical knowledge. Nature 2023, 620, 172–180. [Google Scholar] [CrossRef] [PubMed]
- BioMedLM: A Domain-Specific Large Language Model for Biomedical Text. Available online: https://www.mosaicml.com/blog/introducing-pubmed-gpt (accessed on 28 August 2023).
- Yan, A.; McAuley, J.; Lu, X.; Du, J.; Chang, E.Y.; Gentili, A.; Hsu, C.-N. RadBERT: Adapting Transformer-based Language Models to Radiology. Radiol. Artif. Intell. 2022, 4, e210258. [Google Scholar] [CrossRef]
- Engaging a Scientific ‘Conversational Manuscript’ With Artificial Intelligence: A Test and Reader Invitation. Available online: https://www.newswise.com/articles/engaging-a-scientific-conversational-manuscript-with-artificial-intelligence-a-test-and-reader-invitation (accessed on 1 August 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Medical Specialty | Number of Publications |
|---|---|
| Non-Surgical | N (%) |
| Radiology | 21 (25.3%) |
| Internal Medicine/Primary Care | 10 (12.0%) |
| Oncology | 6 (7.2%) |
| Gastroenterology | 5 (6.02%) |
| Rheumatology | 5 (6.02%) |
| Dermatology | 4 (4.8%) |
| Emergency Medicine | 4 (4.8%) |
| Endocrine | 4 (4.8%) |
| Pediatrics | 4 (4.8%) |
| Psychiatry | 4 (4.8%) |
| Neurology | 3 (3.6%) |
| Anesthesia | 2 (2.4%) |
| Infectious Disease | 2 (2.4%) |
| Pathology | 2 (2.4%) |
| Pulmonology/Critical Care | 2 (2.4%) |
| Cardio | 1 (1.2%) |
| Fam Med | 1 (1.2%) |
| Hepatology | 1 (1.2%) |
| Sports Med | 1 (1.2%) |
| Toxicology | 1 (1.2%) |
| Surgical Specialties | N (%) |
| Plastic Surgery | 18 (26.9%) |
| General Surgery | 15 (22.4%) |
| Orthopedic Surgery | 7 (10.4%) |
| Ophthalmology | 6 (9.0%) |
| Obstetrics and Gynecology | 5 (7.5%) |
| Neurosurgery | 4 (6.0%) |
| Otolaryngology | 4 (6.0%) |
| Oral and Maxillofacial Surgery | 2 (3.0%) |
| Surgical Oncology | 2 (3.0%) |
| Urology | 2 (3.0%) |
| Bariatric Surgery | 1 (1.5%) |
| Colorectal Surgery | 1 |
| Rank | Article Name | Number of Citations | Journal of Article |
|---|---|---|---|
| 1 | How Does ChatGPT Perform on the United States Medical Licensing Examination? The Implications of Large Language Models for Medical Education and Knowledge Assessment. | 147 | JMIR Medical Education |
| 2 | A Conversation on Artificial Intelligence, Chatbots, and Plagiarism in Higher Education | 119 | Cellular and Molecular Bioengineering |
| 3 | Artificial Hallucinations in ChatGPT: Implications in Scientific Writing | 118 | Cureus Journal of Medical Science |
| 4 | ChatGPT: the future of discharge summaries? | 94 | The Lancet Digital Health |
| 5 | Can artificial intelligence help for scientific writing? | 87 | Critical Care |
| 6 | Evaluating the Feasibility of ChatGPT in Healthcare: An Analysis of Multiple Clinical and Research Scenarios. | 68 | Journal of Medical Systems |
| 7 | Role of Chat GPT in Public Health | 61 | Annals of Biomedical Engineering |
| 8 | ChatGPT: evolution or revolution? | 57 | Medicine, Health Care, and Philosophy |
| 9 | Generating scholarly content with ChatGPT: ethical challenges for medical publishing | 56 | The Lancet Digital Health |
| 10 | ChatGPT—Reshaping medical education and clinical management. | 51 | Pakistan Journal of Medical Sciences |
| 11 | The future of medical education and research: Is ChatGPT a blessing or blight in disguise? | 48 | Medical Education Online |
| 12 | Can ChatGPT draft a research article? An example of population-level vaccine effectiveness analysis. | 45 | Journal of Global Health |
| 13 | Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum. | 41 | JAMA Internal Medicine |
| 14 | ChatGPT and other artificial intelligence applications speed up scientific writing. | 37 | Journal of the Chinese Medical Association |
| 15 | Revolutionizing radiology with GPT-based models: Current applications, future possibilities and limitations of ChatGPT. | 32 | Diagnostic and Interventional Imaging |
| 16 | Using ChatGPT to write patient clinic letters. | 32 | The Lancet Digital Health |
| 17 | Artificial intelligence bot ChatGPT in medical research: the potential game changer as a double-edged sword. | 29 | Knee Surgery, Sports Traumatology, Arthroscopy |
| 18 | ChatGPT and antimicrobial advice: the end of the consulting infection doctor? | 28 | The Lancet Infectious Diseases |
| 19 | To ChatGPT or not to ChatGPT? The Impact of Artificial Intelligence on Academic Publishing | 26 | The Pediatric Infectious Disease Journal |
| 20 | Assessing the performance of ChatGPT in answering questions regarding cirrhosis and hepatocellular carcinoma. | 25 | Clinical and Molecular Hepatology |
| Journal Name | Number of Related Publications | h-Index | Impact Factor |
|---|---|---|---|
| Annals of Biomedical Engineering | 14 | 141 | 3.8 |
| Aesthetic Surgery Journal | 13 | 71 | 2.9 |
| Cureus | 10 | NA | 1.15 |
| Radiology | 8 | 320 | 19.7 |
| International Journal of Surgery | 5 | 71 | 15.3 |
| Average +/− SD | 10 +/− 3.7 | 150.8 +/− 117.6 | 8.6 +/− 8.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barrington, N.M.; Gupta, N.; Musmar, B.; Doyle, D.; Panico, N.; Godbole, N.; Reardon, T.; D’Amico, R.S. A Bibliometric Analysis of the Rise of ChatGPT in Medical Research. Med. Sci. 2023, 11, 61. https://doi.org/10.3390/medsci11030061
Barrington NM, Gupta N, Musmar B, Doyle D, Panico N, Godbole N, Reardon T, D’Amico RS. A Bibliometric Analysis of the Rise of ChatGPT in Medical Research. Medical Sciences. 2023; 11(3):61. https://doi.org/10.3390/medsci11030061
Chicago/Turabian StyleBarrington, Nikki M., Nithin Gupta, Basel Musmar, David Doyle, Nicholas Panico, Nikhil Godbole, Taylor Reardon, and Randy S. D’Amico. 2023. "A Bibliometric Analysis of the Rise of ChatGPT in Medical Research" Medical Sciences 11, no. 3: 61. https://doi.org/10.3390/medsci11030061
APA StyleBarrington, N. M., Gupta, N., Musmar, B., Doyle, D., Panico, N., Godbole, N., Reardon, T., & D’Amico, R. S. (2023). A Bibliometric Analysis of the Rise of ChatGPT in Medical Research. Medical Sciences, 11(3), 61. https://doi.org/10.3390/medsci11030061