
Childhood Environmental Instabilities and Their Behavioral Implications: A Machine Learning Approach to Studying Adverse Childhood Experiences

Abstract
:1. Introduction
2. Materials and Methods
2.1. Data and Source
2.2. Outcome: ACEs
2.3. Machine Learning Approach
2.3.1. Overview of Machine Learning Algorithms
2.3.2. Preprocessing
2.3.3. Hyperparameter Optimization
2.3.4. Application to Independent Test Sample
2.4. Model Evaluation Metrics
Feature Importance
3. Results
3.1. Samples
3.2. Selecting ML Model
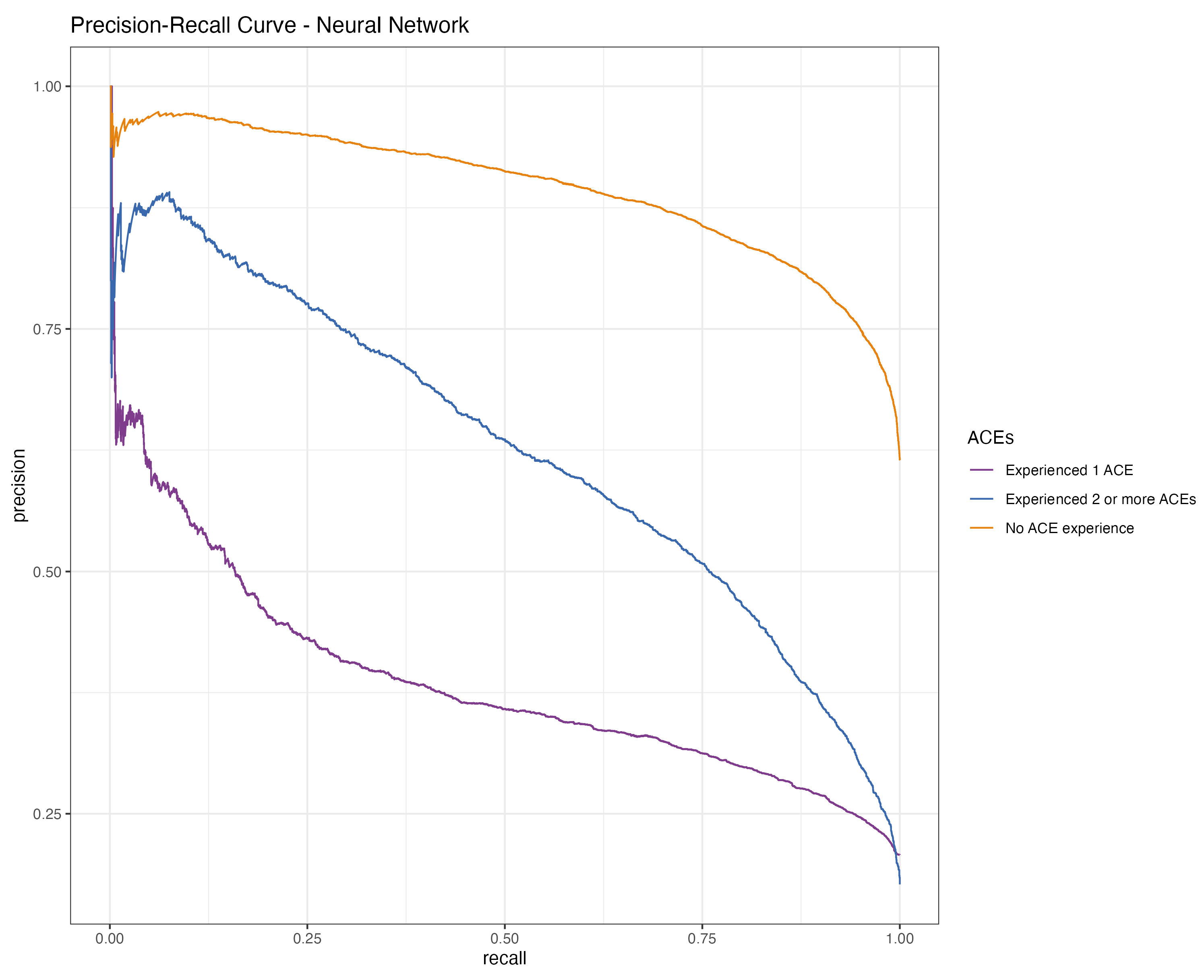
3.3. Prediction of ACEs
4. Discussion
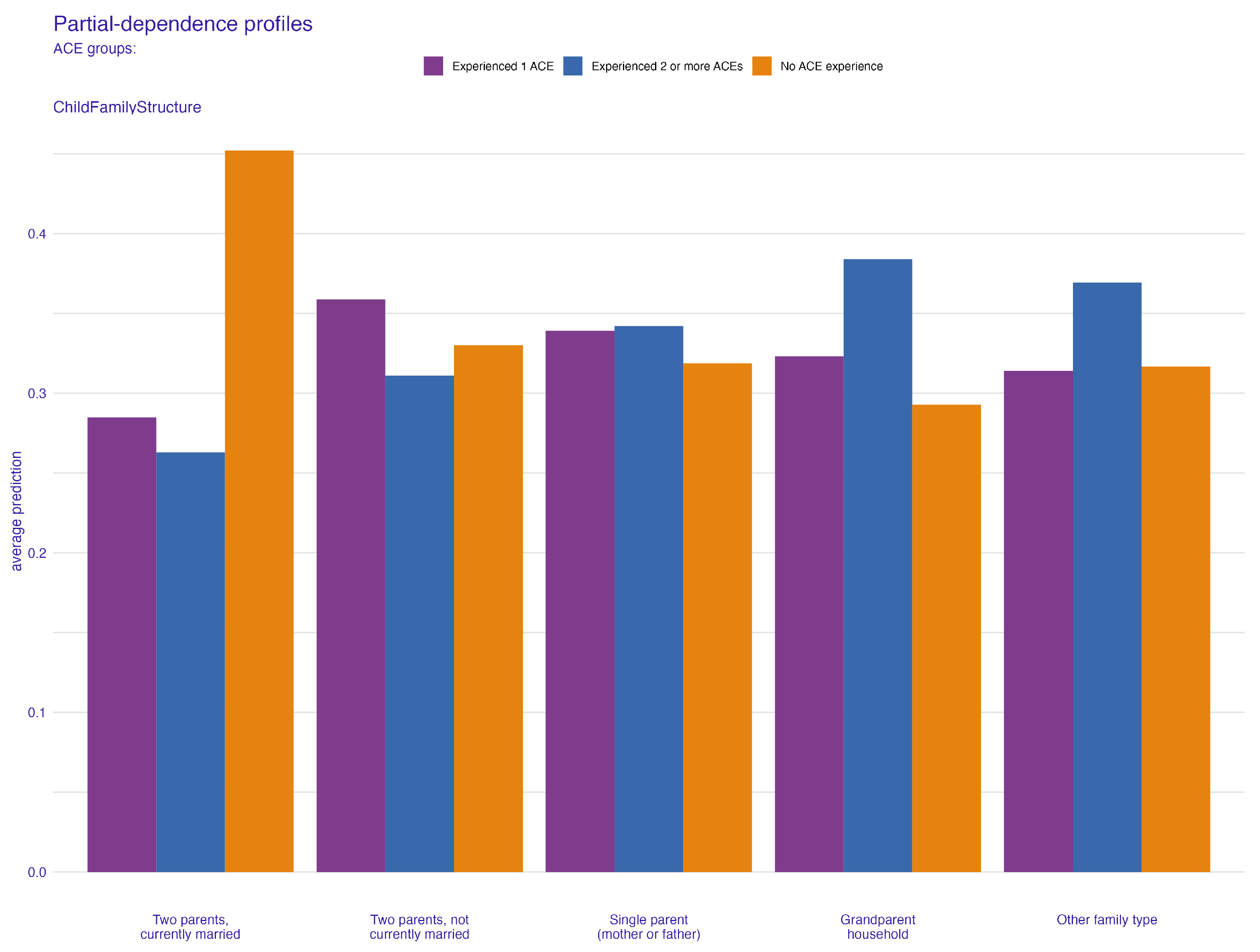
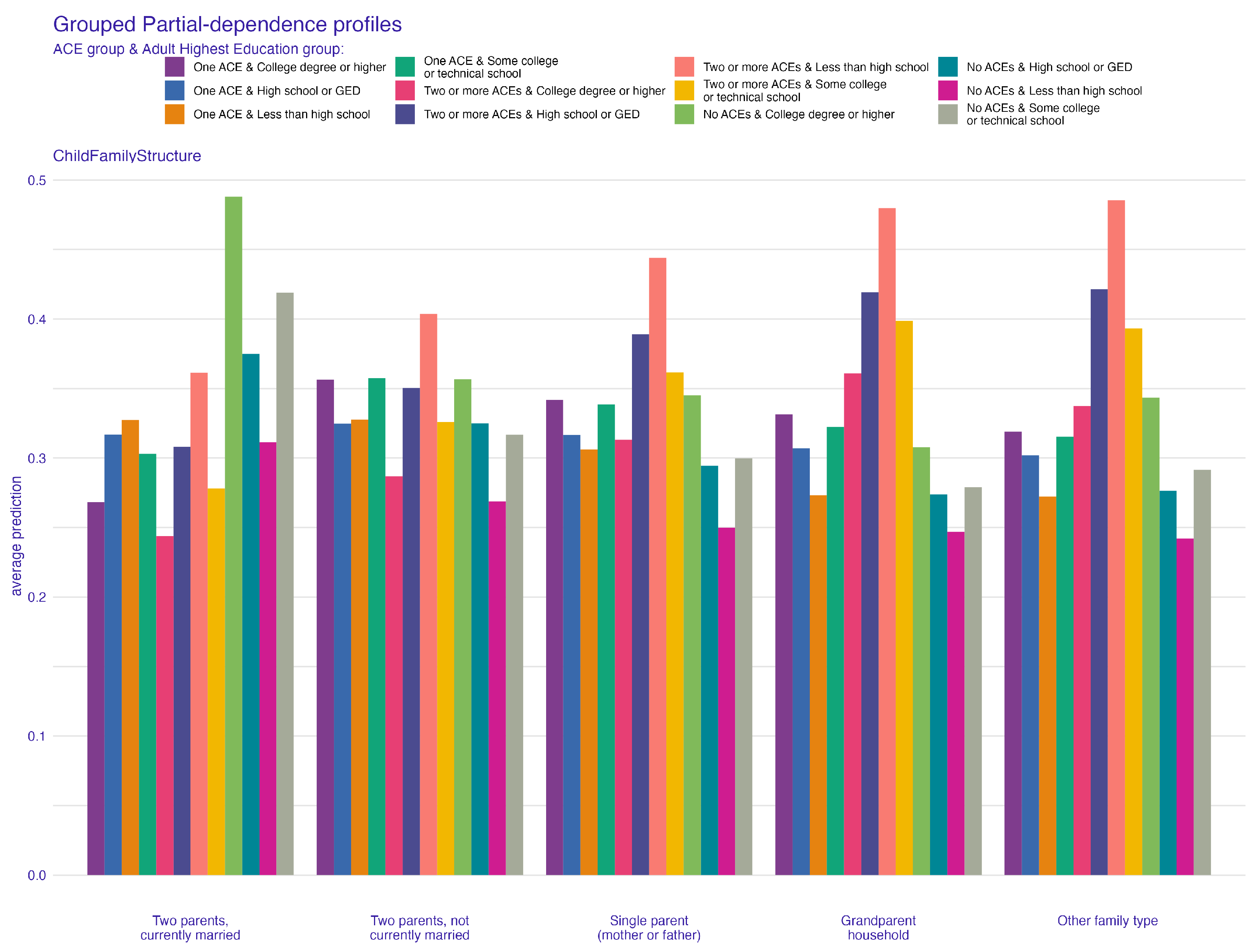
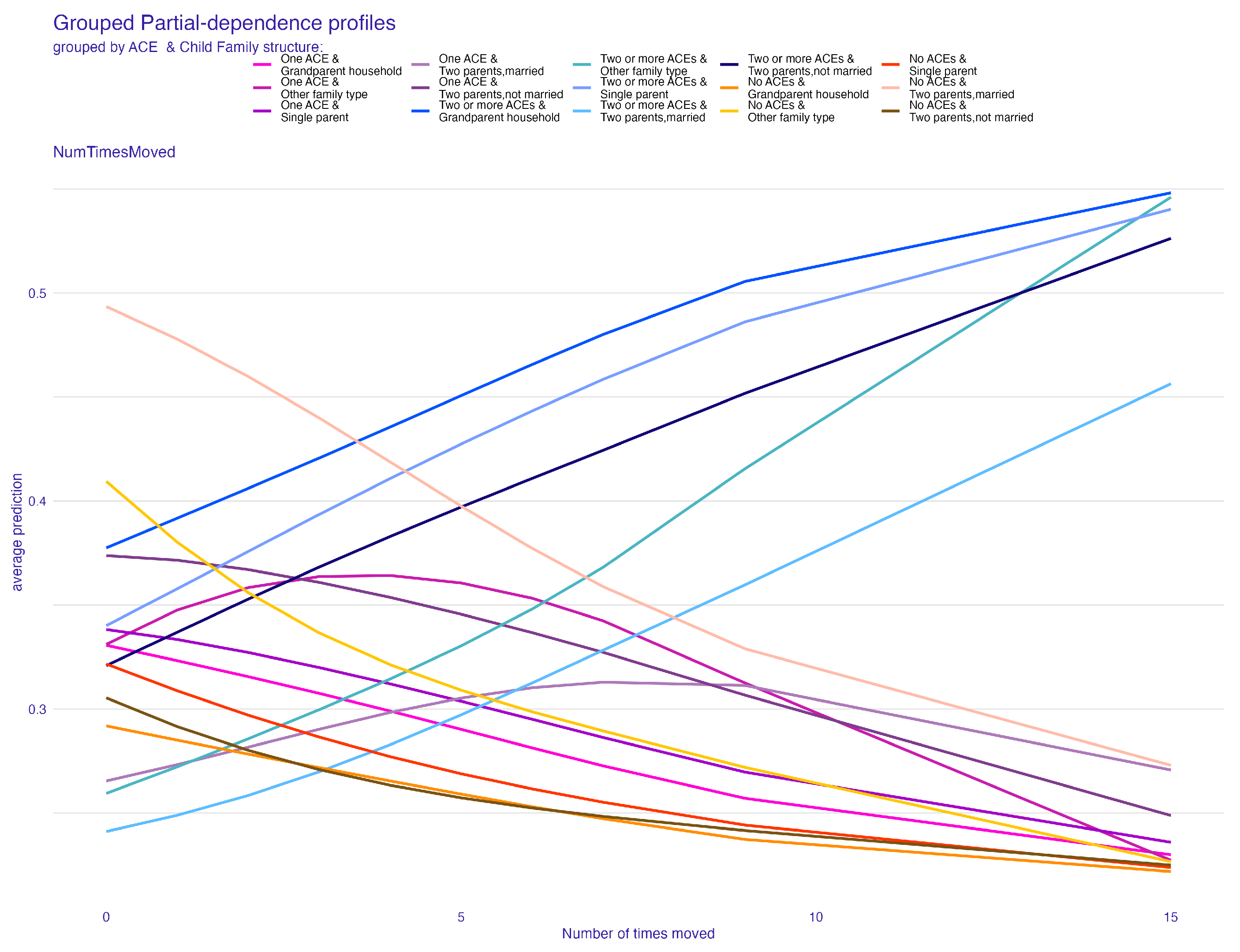
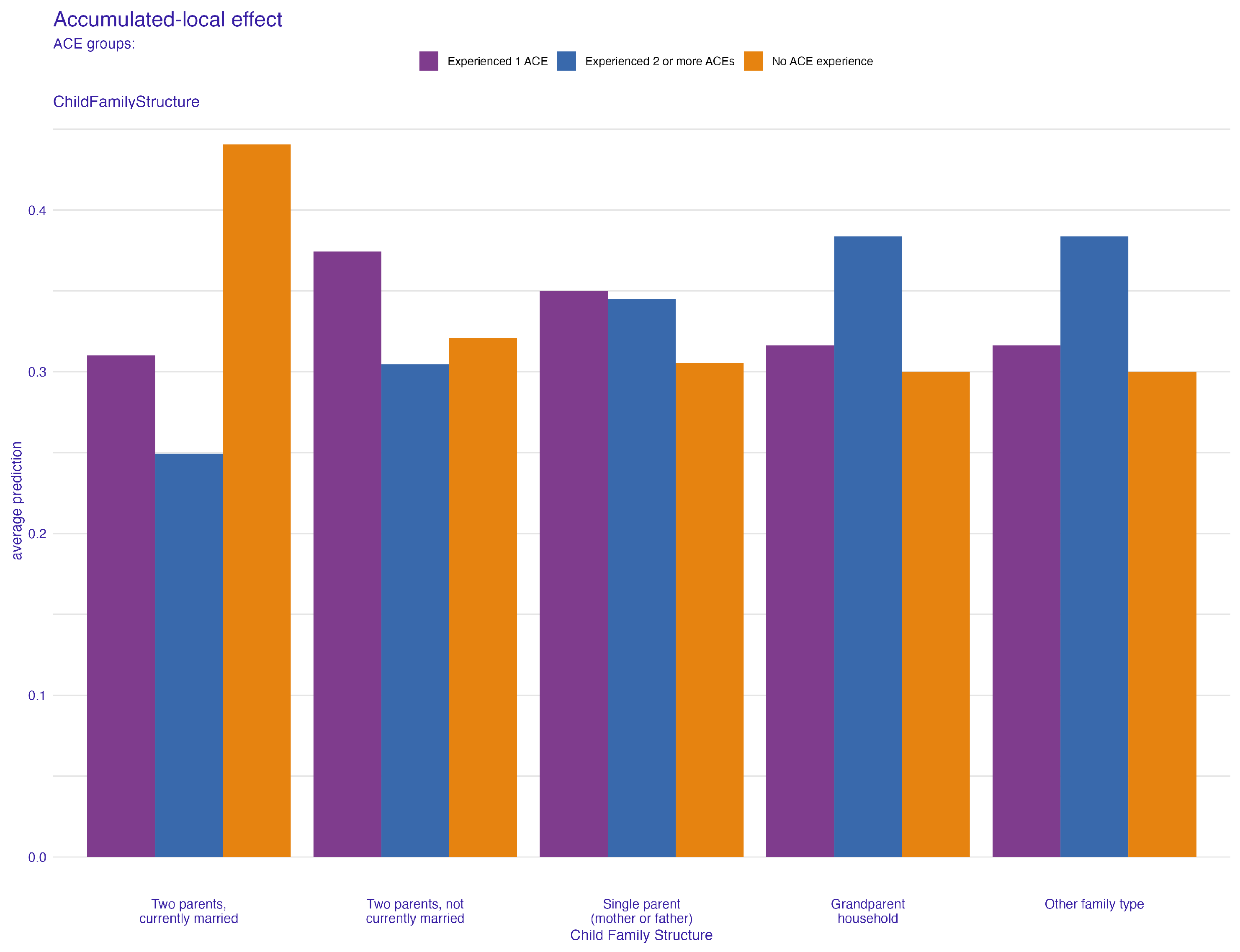
4.1. Family Structure and Its Impact on ACEs
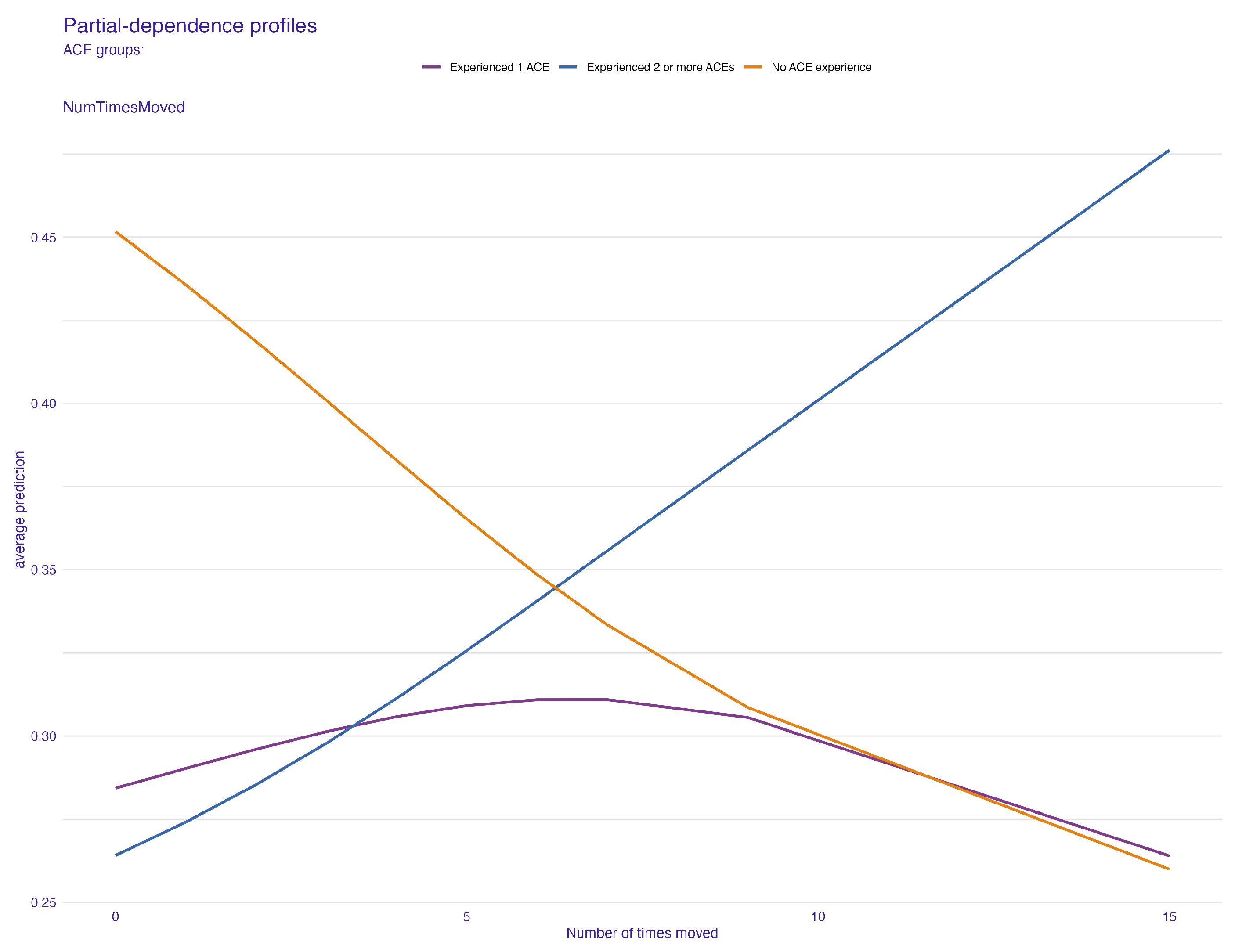
4.2. The Role of Frequent Relocations
5. Limitations of the Study
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Webster, E.M. The impact of adverse childhood experiences on health and development in young children. Glob. Pediatr. Health 2022, 9, 2333794X221078708. [Google Scholar] [CrossRef]
- Felitti, V.; Anda, R.; Nordenberg, D.; Williamson, D. Adverse childhood experiences and health outcomes in adults: The Ace study. J. Fam. Consum. Sci. 1998, 90, 31. [Google Scholar]
- Briggs, E.C.; Amaya-Jackson, L.; Putnam, K.T.; Putnam, F.W. All adverse childhood experiences are not equal: The contribution of synergy to adverse childhood experience scores. Am. Psychol. 2021, 76, 243. [Google Scholar] [CrossRef]
- Anda, R.F.; Felitti, V.J.; Bremner, J.D.; Walker, J.D.; Whitfield, C.; Perry, B.D.; Dube, S.R.; Giles, W.H. The enduring effects of abuse and related adverse experiences in childhood: A convergence of evidence from neurobiology and epidemiology. Eur. Arch. Psychiatry Clin. Neurosci. 2006, 256, 174–186. [Google Scholar] [CrossRef]
- Mersky, J.P.; Choi, C.; Lee, C.P.; Janczewski, C.E. Disparities in adverse childhood experiences by race/ethnicity, gender, and economic status: Intersectional analysis of a nationally representative sample. Child Abus. Negl. 2021, 117, 105066. [Google Scholar] [CrossRef]
- Kerker, B.D.; Zhang, J.; Nadeem, E.; Stein, R.E.; Hurlburt, M.S.; Heneghan, A.; Landsverk, J.; Horwitz, S.M. Adverse childhood experiences and mental health, chronic medical conditions, and development in young children. Acad. Pediatr. 2015, 15, 510–517. [Google Scholar] [CrossRef]
- Finkelhor, D.; Turner, H.; LaSelva, D. Receipt of behavioral health services among us children and youth with adverse childhood experiences or mental health symptoms. JAMA Netw. Open 2021, 4, e211435. [Google Scholar] [CrossRef]
- Substance Abuse and Mental Health Services Administration (SAMHSA). 2012 National Survey on Drug Use and Health (NSDUH); S. Prepared by Office of Applied Studies (OAS), RTI International (RTI International is a trade name of Research Triangle Institute), Eds.; Substance Abuse and Mental Health Services Administration: Rockville, MD, USA, 2020.
- Hughes, K.; Bellis, M.A.; Hardcastle, K.A.; Sethi, D.; Butchart, A.; Mikton, C.; Jones, L.; Dunne, M.P. The effect of multiple adverse childhood experiences on health: A systematic review and meta-analysis. Lancet Public Health 2017, 2, e356–e366. [Google Scholar] [CrossRef]
- Danese, A.; McEwen, B.S. Adverse childhood experiences, allostasis, allostatic load, and age-related disease. Physiol. Behav. 2012, 106, 29–39. [Google Scholar] [CrossRef]
- Bellis, M.A.; Hughes, K.; Leckenby, N.; Perkins, C.; Lowey, H. National household survey of adverse childhood experiences and their relationship with resilience to health-harming behaviors in England. BMC Med. 2014, 12, 1–10. [Google Scholar] [CrossRef]
- Turney, K.; Wildeman, C. Adverse childhood experiences among children placed in and adopted from foster care: Evidence from a nationally representative survey. Child Abus. Negl. 2017, 64, 117–129. [Google Scholar] [CrossRef]
- Merrick, M.T.; Ford, D.C.; Ports, K.A.; Guinn, A.S. Prevalence of adverse childhood experiences from the 2011–2014 behavioral risk factor surveillance system in 23 states. JAMA Pediatr. 2018, 172, 1038–1044. [Google Scholar] [CrossRef]
- Bair-Merritt, M.H.; Blackstone, M.; Feudtner, C. Physical health outcomes of childhood exposure to intimate partner violence: A systematic review. Pediatrics 2006, 117, e278–e290. [Google Scholar] [CrossRef]
- Bethell, C.D.; Carle, A.; Hudziak, J.; Gombojav, N.; Powers, K.; Wade, R.; Braveman, P. Methods to assess adverse childhood experiences of children and families: Toward approaches to promote child well-being in policy and practice. Acad. Pediatr. 2017, 17, S51–S69. [Google Scholar] [CrossRef]
- Finkelhor, D.; Shattuck, A.; Turner, H.A.; Hamby, S.L. The lifetime prevalence of child sexual abuse and sexual assault assessed in late adolescence. J. Adolesc. Health 2014, 55, 329–333. [Google Scholar] [CrossRef]
- Kuhn, M.; Wickham, H. Tidymodels: A Collection of Packages for Modeling and Machine Learning Using Tidyverse Principles; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2020. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2023. [Google Scholar]
- Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons: New York, NY, USA, 2013; Volume 398. [Google Scholar]
- Schliep, K.; Hechenbichler, K. kknn: Weighted k-Nearest Neighbors, R Package Version 1.3.1; R Team: Vienna, Austria, 2016.
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the 1996 ICML, Bari, Italy, 3–6 July 1996; Volume 96, pp. 148–156. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K.; Mitchell, R.; Cano, I.; Zhou, T.; et al. xgboost: Extreme Gradient Boosting, R Package Version 1.7.5.1; R Team: Vienna, Austria, 2023.
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: New York, NY, USA, 2013; Volume 26. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Flach, P.A. ROC analysis. In Encyclopedia of Machine Learning and Data Mining; Springer: New York, NY, USA, 2016; pp. 1–8. [Google Scholar]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Powers, D.M.W. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2011, arXiv:2010.16061. [Google Scholar]
- Brodersen, K.H.; Ong, C.S.; Stephan, K.E.; Buhmann, J.M. The balanced accuracy and its posterior distribution. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; IEEE: New York, NY, USA, 2010; pp. 3121–3124. [Google Scholar]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 1–13. [Google Scholar] [CrossRef]
- Hand, D.J.; Till, R.J. A simple generalisation of the area under the ROC curve for multiple class classification problems. Mach. Learn. 2001, 45, 171–186. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning, 2nd ed.; Independently Published: Chicago, IL, USA, 2022. [Google Scholar]
- Fisher, A.; Rudin, C.; Dominici, F. All Models are Wrong, but Many are Useful: Learning a Variable’s Importance by Studying an Entire Class of Prediction Models Simultaneously. J. Mach. Learn. Res. 2019, 20, 1–81. [Google Scholar]
- Biecek, P.; Burzykowski, T. Explanatory Model Analysis; Chapman and Hall/CRC: New York, NY, USA, 2021. [Google Scholar]
- Apley, D.W.; Zhu, J. Visualizing the effects of predictor variables in black box supervised learning models. J. R. Stat. Soc. Ser. Stat. Methodol. 2020, 82, 1059–1086. [Google Scholar] [CrossRef]
- Greenwell, B.M. pdp: An R package for constructing partial dependence plots. R J. 2017, 9, 421. [Google Scholar] [CrossRef]
- Biecek, P. DALEX: Explainers for complex predictive models in R. J. Mach. Learn. Res. 2018, 19, 1–5. [Google Scholar]
- Maksymiuk, S.; Gosiewska, A.; Biecek, P. Landscape of R packages for eXplainable Artificial Intelligence. arXiv 2020, arXiv:2009.13248. [Google Scholar]
- Baglivio, M.T.; Epps, N.; Swartz, K.; Huq, M.S.; Sheer, A.; Hardt, N.S. The prevalence of adverse childhood experiences (ACE) in the lives of juvenile offenders. J. Juv. Justice 2014, 3, 1–23. [Google Scholar]
- Fomby, P.; Cherlin, A.J. Family instability and child well-being. Am. Sociol. Rev. 2007, 72, 181–204. [Google Scholar] [CrossRef]
- Gershoff, E.T.; Aber, J.L.; Raver, C.C.; Lennon, M.C. Income is not enough: Incorporating material hardship into models of income associations with parenting and child development. Child Dev. 2007, 78, 70–95. [Google Scholar] [CrossRef]
- Brown, S.L.; Manning, W.D.; Stykes, J.B. Family structure and child well-being: Integrating family complexity. J. Marriage Fam. 2015, 77, 177–190. [Google Scholar] [CrossRef]
- Adam, E.K.; Chase-Lansdale, P.L. Home sweet home(s): Parental separations, residential moves, and adjustment problems in low-income adolescent girls. Dev. Psychol. 2002, 38, 792. [Google Scholar] [CrossRef]
- Simpson, G.A.; Fowler, M.G. Geographic mobility and children’s emotional/behavioral adjustment and school functioning. Pediatrics 1994, 93, 303–309. [Google Scholar] [CrossRef]
- Wood, D.; Halfon, N.; Scarlata, D.; Newacheck, P.; Nessim, S. Impact of family relocation on children’s growth, development, school function, and behavior. JAMA 1993, 270, 1334–1338. [Google Scholar] [CrossRef]
- Anda, R.F.; Butchart, A.; Felitti, V.J.; Brown, D.W. Building a framework for global surveillance of the public health implications of adverse childhood experiences. Am. J. Prev. Med. 2010, 39, 93–98. [Google Scholar] [CrossRef]
- Merrick, M.T.; Ports, K.A.; Ford, D.C.; Afifi, T.O.; Gershoff, E.T.; Grogan-Kaylor, A. Unpacking the impact of adverse childhood experiences on adult mental health. Child Abus. Negl. 2017, 69, 10–19. [Google Scholar] [CrossRef]
- Finkelhor, D.; Ormrod, R.K.; Turner, H.A. The developmental epidemiology of childhood victimization. J. Interpers. Violence 2009, 24, 711–731. [Google Scholar] [CrossRef]
- Reuben, A.; Moffitt, T.E.; Caspi, A.; Belsky, D.W.; Harrington, H.; Schroeder, F.; Hogan, S.; Ramrakha, S.; Poulton, R.; Danese, A. Lest we forget: Comparing retrospective and prospective assessments of adverse childhood experiences in the prediction of adult health. J. Child Psychol. Psychiatry 2016, 57, 1103–1112. [Google Scholar] [CrossRef]
- Bethell, C.D.; Newacheck, P.; Hawes, E.; Halfon, N. Adverse childhood experiences: Assessing the impact on health and school engagement and the mitigating role of resilience. Health Aff. 2014, 33, 2106–2115. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | AUC | F1 Score | Recall | Precision | Accuracy | MCC |
|---|---|---|---|---|---|---|
| Logistic Regression | 0.783 | 0.680 | 0.704 | 0.674 | 0.701 | 0.440 |
| KNN | 0.710 | 0.632 | 0.652 | 0.621 | 0.641 | 0.323 |
| Decision tree | 0.500 | 0.762 | 0.615 | 0.615 | 0.500 | - |
| Random forest | 0.768 | 0.676 | 0.700 | 0.668 | 0.689 | 0.425 |
| Adaptive Boosting | 0.757 | 0.669 | 0.686 | 0.661 | 0.685 | 0.405 |
| XGBoost | 0.785 | 0.688 | 0.704 | 0.681 | 0.706 | 0.444 |
| Neural Network | 0.788 | 0.687 | 0.707 | 0.683 | 0.708 | 0.451 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Codjoe, P.M.; Tawiah, N.A.; Alhassan, D. Childhood Environmental Instabilities and Their Behavioral Implications: A Machine Learning Approach to Studying Adverse Childhood Experiences. Behav. Sci. 2024, 14, 487. https://doi.org/10.3390/bs14060487
Codjoe PM, Tawiah NA, Alhassan D. Childhood Environmental Instabilities and Their Behavioral Implications: A Machine Learning Approach to Studying Adverse Childhood Experiences. Behavioral Sciences. 2024; 14(6):487. https://doi.org/10.3390/bs14060487
Chicago/Turabian StyleCodjoe, Priscilla Mansah, Nii Adjetey Tawiah, and Daniel Alhassan. 2024. "Childhood Environmental Instabilities and Their Behavioral Implications: A Machine Learning Approach to Studying Adverse Childhood Experiences" Behavioral Sciences 14, no. 6: 487. https://doi.org/10.3390/bs14060487
APA StyleCodjoe, P. M., Tawiah, N. A., & Alhassan, D. (2024). Childhood Environmental Instabilities and Their Behavioral Implications: A Machine Learning Approach to Studying Adverse Childhood Experiences. Behavioral Sciences, 14(6), 487. https://doi.org/10.3390/bs14060487