Efficient Computation Offloading in Multi-Tier Multi-Access Edge Computing Systems: A Particle Swarm Optimization Approach

 , , , , and
, , , , and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- We investigated a two-tier computation-offloading strategy using multi-user multi-server MEC in 5G HetNets.
- We addressed joint resource allocation and computation-offloading decisions in order to minimize the total computing overhead of MDs, including completion time and energy consumption. The optimization problem was formulated as a mixed-integer nonlinear program (MINLP) problem of NP-hard complexity based on the inclusion of both continuous (resource allocation) and discrete (offloading decision) variables. This problem is highly complex and difficult to solve optimally in polynomial time. To address this, we divided the original problem into two subproblems: computational resource allocation and computation-offloading decisions.
- Numerical simulations showed that the proposed algorithm achieved outstanding performance in terms of total computing overhead relative to several baseline schemes as well as guaranteeing the convergence of our solution.
2. Related Work
3. Network Setting and Computational Model
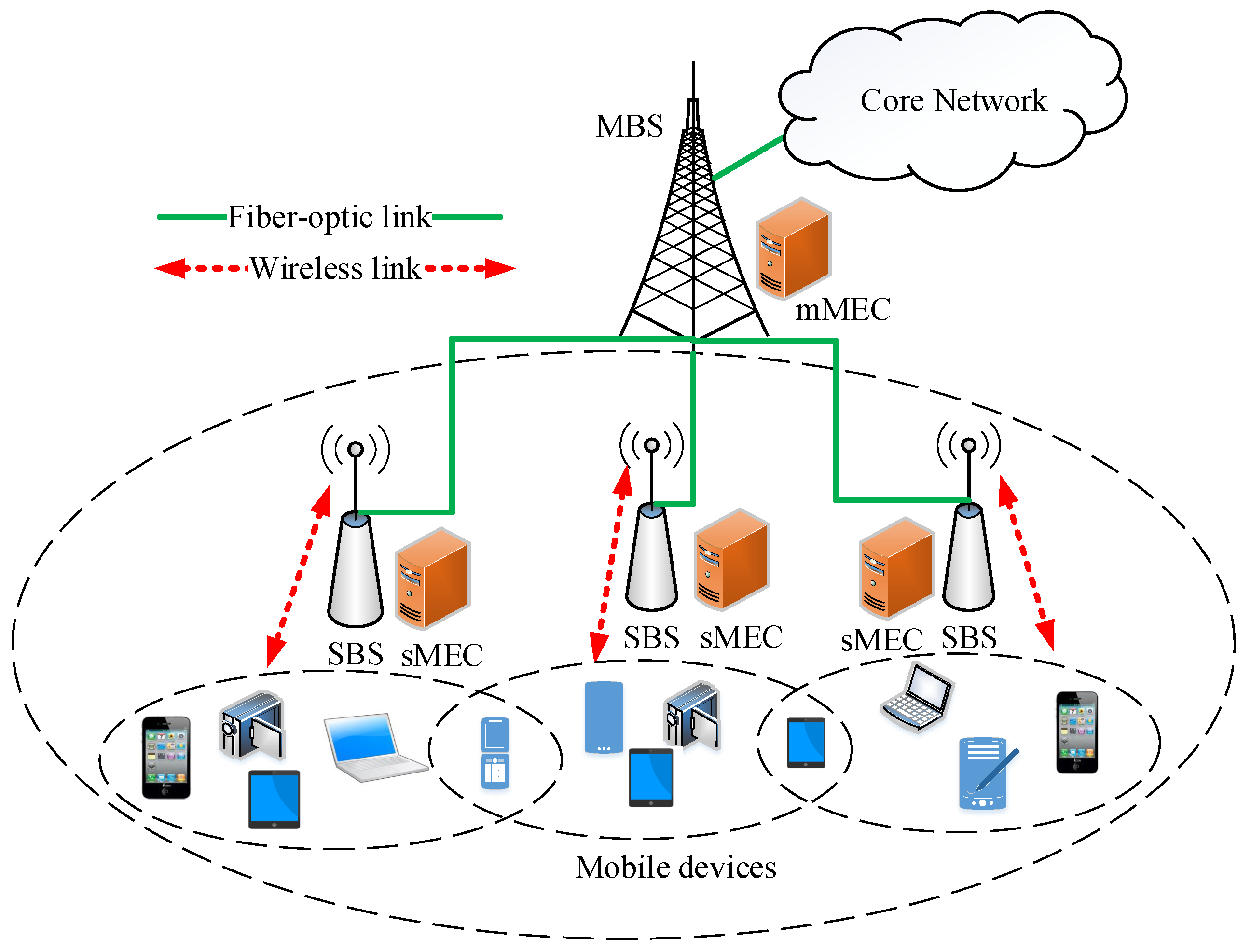
3.1. Scenario Description
3.2. Communication Model
3.3. Local Execution Model
3.4. Computation-Offloading Model
3.4.1. sMEC Offloading
3.4.2. mMEC Offloading
4. Problem Formulation and Analysis
5. Joint Optimization of Resource Allocation and Computation-Offloading Decisions
5.1. Computational Resource Allocation
5.2. Computation-Offloading Decision
| Algorithm 1: The standard binary particle swarm optimization (BPSO) algorithm. |
 |
5.3. The Proposed Algorithm JROPSO
| Algorithm 2: PSO-based joint resource allocation and computational offloading decision algorithm (JROPSO) |
 |
6. Performance Evaluation
6.1. Simulation Settings
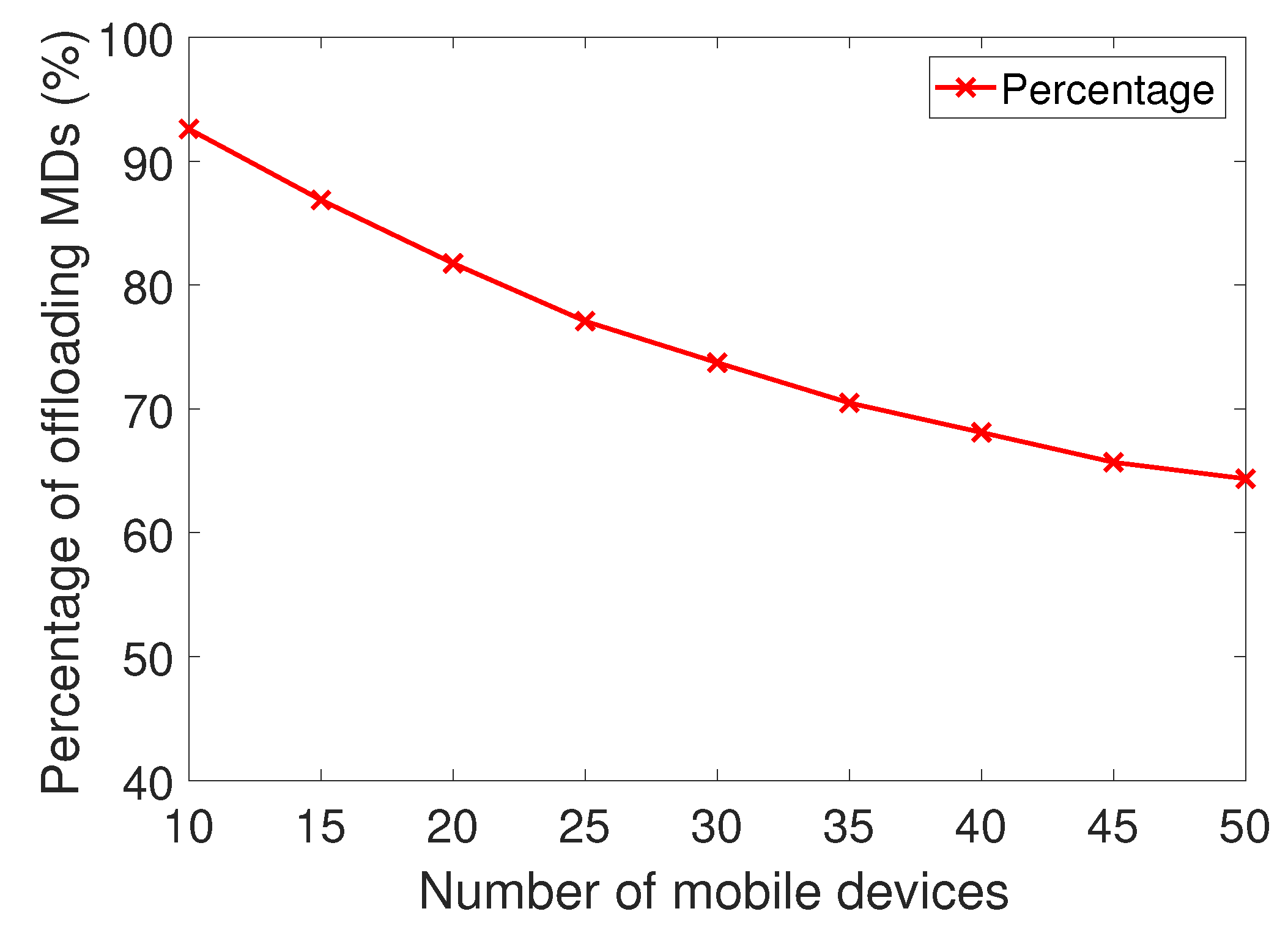
6.2. Simulation Results
- Local Computing Only (LCO): all of the MDs execute their computational tasks locally in the absence of computation offloading.
- Without MBS (WMBS): The proposed algorithm JROPSO is implemented without MBS.
- Only offloading in a 2-tier system (OF): offloading only to sMECs and mMEC, with computation resource allocation optimized for sMECs.
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mach, P.; Becvar, Z. Mobile Edge Computing: A Survey on Architecture and Computation Offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef] [Green Version]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A Survey on Mobile Edge Computing: The Communication Perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef] [Green Version]
- Y.3508: Cloud Computing—Overview and High-Level Requirements of Distributed Cloud; Recommendation Y.3508; ITU Publications: Geneva, Switzerland, 2019.
- Pham, Q.; Nguyen, T.H.; Han, Z.; Hwang, W. Coalitional Games for Computation Offloading in NOMA-Enabled Multi-Access Edge Computing. IEEE Trans. Veh. Technol. 2019. [Google Scholar] [CrossRef]
- Pham, Q.V.; Fang, F.; Vu, H.; Le, M.; Ding, Z.; Le, L.B.; Hwang, W. A Survey of Multi-Access Edge Computing in 5G and Beyond: Fundamentals, Technology Integration, and State-of-the-Art. arXiv 2019, arXiv:1906.08452. [Google Scholar]
- Ramazanali, H.; Mesodiakaki, A.; Vinel, A.; Verikoukis, C. Survey of user association in 5G HetNets. In Proceedings of the 2016 8th IEEE Latin-American Conference on Communications (LATINCOM), Medellin, Colombia, 15–17 November 2016; pp. 1–6. [Google Scholar]
- Huynh, L.N.T.; Pham, Q.V.; Nguyen, Q.D.; Pham, X.Q.; Nguyen, V.; Huh, E.N. Energy-Efficient Computation Offloading with Multi-MEC Servers in 5G Two-Tier Heterogeneous Networks. In Proceedings of the 13th International Conference on Ubiquitous Information Management and Communication (IMCOM), Phuket, Thailand, 4–6 January 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 120–129. [Google Scholar]
- Hu, Y.C.; Patel, M.; Sabella, D.; Sprecher, N.; Young, V. Mobile edge computing—A key technology towards 5G. ETSI White Pap. 2015, 11, 1–16. [Google Scholar]
- Chen, X.; Jiao, L.; Li, W.; Fu, X. Efficient Multi-User Computation Offloading for Mobile-Edge Cloud Computing. IEEE/ACM Trans. Netw. 2016, 24, 2795–2808. [Google Scholar] [CrossRef] [Green Version]
- Lyu, X.; Tian, H.; Sengul, C.; Zhang, P. Multiuser Joint Task Offloading and Resource Optimization in Proximate Clouds. IEEE Trans. Veh. Technol. 2017, 66, 3435–3447. [Google Scholar] [CrossRef]
- Hao, Y.; Chen, M.; Hu, L.; Hossain, M.S.; Ghoneim, A. Energy Efficient Task Caching and Offloading for Mobile Edge Computing. IEEE Access 2018, 6, 11365–11373. [Google Scholar] [CrossRef]
- Tao, X.; Ota, K.; Dong, M.; Qi, H.; Li, K. Performance Guaranteed Computation Offloading for Mobile-Edge Cloud Computing. IEEE Wirel. Commun. Lett. 2017, 6, 774–777. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Mao, Y.; Leng, S.; Zhao, Q.; Li, L.; Peng, X.; Pan, L.; Maharjan, S.; Zhang, Y. Energy-Efficient Offloading for Mobile Edge Computing in 5G Heterogeneous Networks. IEEE Access 2016, 4, 5896–5907. [Google Scholar] [CrossRef]
- Pham, Q.V.; Le, L.B.; Chung, S.H.; Hwang, W.J. Mobile Edge Computing With Wireless Backhaul: Joint Task Offloading and Resource Allocation. IEEE Access 2019, 7, 16444–16459. [Google Scholar] [CrossRef]
- Wang, C.; Yu, F.R.; Liang, C.; Chen, Q.; Tang, L. Joint Computation Offloading and Interference Management in Wireless Cellular Networks with Mobile Edge Computing. IEEE Trans. Veh. Technol. 2017, 66, 7432–7445. [Google Scholar] [CrossRef]
- Zhang, J.; Hu, X.; Ning, Z.; Ngai, E.C.; Zhou, L.; Wei, J.; Cheng, J.; Hu, B. Energy-Latency Tradeoff for Energy-Aware Offloading in Mobile Edge Computing Networks. IEEE Internet Things J. 2018, 5, 2633–2645. [Google Scholar] [CrossRef]
- Lee, J.; Lee, J. Hierarchical Mobile Edge Computing Architecture Based on Context Awareness. Appl. Sci. 2018, 8, 1160. [Google Scholar] [CrossRef] [Green Version]
- Guo, H.; Liu, J. Collaborative Computation Offloading for Multiaccess Edge Computing Over Fiber–Wireless Networks. IEEE Trans. Veh. Technol. 2018, 67, 4514–4526. [Google Scholar] [CrossRef]
- Liu, F.; Huang, Z.; Wang, L. Energy-Efficient Collaborative Task Computation Offloading in Cloud-Assisted Edge Computing for IoT Sensors. Sensors 2019, 19, 1105. [Google Scholar] [CrossRef] [Green Version]
- Ryu, J.W.; Pham, Q.V.; Luan, H.N.T.; Hwang, W.J.; Kim, J.D.; Lee, J.T. Multi-Access Edge Computing Empowered Heterogeneous Networks: A Novel Architecture and Potential Works. Symmetry 2019, 11, 842. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Li, Q.; Gong, Y.; Zhang, K. Computation Offloading and Resource Allocation for Cloud Assisted Mobile Edge Computing in Vehicular Networks. IEEE Trans. Veh. Technol. 2019, 68, 7944–7956. [Google Scholar] [CrossRef]
- Wang, J.; Feng, D.; Zhang, S.; Tang, J.; Quek, T.Q.S. Computation Offloading for Mobile Edge Computing Enabled Vehicular Networks. IEEE Access 2019, 7, 62624–62632. [Google Scholar] [CrossRef]
- Fan, X.; Cui, T.; Cao, C.; Chen, Q.; Kwak, K.S. Minimum-Cost Offloading for Collaborative Task Execution of MEC-Assisted Platooning. Sensors 2019, 19, 847. [Google Scholar] [CrossRef] [Green Version]
- Lamb, Z.W.; Agrawal, D.P. Analysis of Mobile Edge Computing for Vehicular Networks. Sensors 2019, 19, 1303. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tran, T.X.; Pompili, D. Adaptive Bitrate Video Caching and Processing in Mobile-Edge Computing Networks. IEEE Trans. Mob. Comput. 2019, 18, 1965–1978. [Google Scholar] [CrossRef]
- Long, C.; Cao, Y.; Jiang, T.; Zhang, Q. Edge Computing Framework for Cooperative Video Processing in Multimedia IoT Systems. IEEE Trans. Multimed. 2018, 20, 1126–1139. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. S-shaped versus V-shaped transfer functions for binary Particle Swarm Optimization. Swarm Evol. Comput. 2013, 9, 1–14. [Google Scholar] [CrossRef]
- Xu, J.; Guo, C.; Zhang, H. Joint channel allocation and power control based on PSO for cellular networks with D2D communications. Comput. Netw. 2018, 133, 104–119. [Google Scholar] [CrossRef]
- Girmay, G.G.; Pham, Q.; Hwang, W. Joint channel and Power Allocation for Device-to-Device Communication on Licensed and Unlicensed Band. IEEE Access 2019, 7, 22196–22205. [Google Scholar] [CrossRef]
- Mao, Y.; Zhang, J.; Song, S.H.; Letaief, K.B. Power-Delay Tradeoff in Multi-User Mobile-Edge Computing Systems. In Proceedings of the 2016 IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016; pp. 1–6. [Google Scholar]
- Deng, M.; Tian, H.; Lyu, X. Adaptive sequential offloading game for multi-cell Mobile Edge Computing. In Proceedings of the 2016 23rd International Conference on Telecommunications (ICT), Thessaloniki, Greece, 16–18 May 2016; pp. 1–5. [Google Scholar]
- Al-Shuwaili, A.; Simeone, O. Energy-Efficient Resource Allocation for Mobile Edge Computing-Based Augmented Reality Applications. IEEE Wirel. Commun. Lett. 2017, 6, 398–401. [Google Scholar] [CrossRef]
- Kan, T.; Chiang, Y.; Wei, H. Task offloading and resource allocation in mobile-edge computing system. In Proceedings of the 2018 27th Wireless and Optical Communication Conference (WOCC), Hualien, Taiwan, 30 April–1 May 2018; pp. 1–4. [Google Scholar]
- Pham, Q.V.; Anh, T.L.; Tran, N.H.; Park, B.J.; Hong, C.S. Decentralized Computation Offoading and Resource Allocation for Mobile-Edge Computing: A Matching Game Approach. IEEE Access 2018, 6, 75868–75885. [Google Scholar] [CrossRef]
- Tran, T.X.; Pompili, D. Joint Task Offloading and Resource Allocation for Multi-Server Mobile-Edge Computing Networks. IEEE Trans. Veh. Technol. 2019, 68, 856–868. [Google Scholar] [CrossRef] [Green Version]
- Chen, M.; Hao, Y. Task Offloading for Mobile Edge Computing in Software Defined Ultra-Dense Network. IEEE J. Sel. Areas Commun. 2018, 36, 587–597. [Google Scholar] [CrossRef]
- Guo, H.; Liu, J.; Zhang, J.; Sun, W.; Kato, N. Mobile-Edge Computation Offloading for Ultradense IoT Networks. IEEE Internet Things J. 2018, 5, 4977–4988. [Google Scholar] [CrossRef]
- Guo, H.; Zhang, J.; Liu, J.; Zhang, H. Energy-Aware Computation Offloading and Transmit Power Allocation in Ultradense IoT Networks. IEEE Internet Things J. 2019, 6, 4317–4329. [Google Scholar] [CrossRef]
- Pham, X.Q.; Nguyen, T.D.; Nguyen, V.; Huh, E.N. Joint Node Selection and Resource Allocation for Task Offloading in Scalable Vehicle-Assisted Multi-Access Edge Computing. Symmetry 2019, 11, 58. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Zhang, H.; Li, M.; Guo, J.; Ji, H. Mobile Edge Computing Empowered Energy Efficient Task Offloading in 5G. IEEE Trans. Veh. Technol. 2018, 67, 6398–6409. [Google Scholar] [CrossRef]
- Ateya, A.A.; Muthanna, A.; Vybornova, A.; Darya, P.; Koucheryavy, A. Energy—Aware Offloading Algorithm for Multi-level Cloud Based 5G System. In Internet of Things, Smart Spaces, and Next Generation Networks and Systems; Springer International Publishing: Cham, Switzerland, 2018; pp. 355–370. [Google Scholar]
- Wan, S.; Li, X.; Xue, Y.; Lin, W.; Xu, X. Efficient computation offloading for Internet of Vehicles in edge computing-assisted 5G networks. J. Supercomput. 2019, 1–30. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the International Conference on Neural Networks (ICNN’95), Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Kennedy, J.; Eberhart, R. A discrete binary version of the particle swarm algorithm. In Proceedings of the 1997 IEEE International Conference on Systems, Man, and Cybernetics. Computational Cybernetics and Simulation, Orlando, FL, USA, 12–15 October 1997; Volume 5, pp. 4104–4108. [Google Scholar]





© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huynh, L.N.T.; Pham, Q.-V.; Pham, X.-Q.; Nguyen, T.D.T.; Hossain, M.D.; Huh, E.-N. Efficient Computation Offloading in Multi-Tier Multi-Access Edge Computing Systems: A Particle Swarm Optimization Approach. Appl. Sci. 2020, 10, 203. https://doi.org/10.3390/app10010203
Huynh LNT, Pham Q-V, Pham X-Q, Nguyen TDT, Hossain MD, Huh E-N. Efficient Computation Offloading in Multi-Tier Multi-Access Edge Computing Systems: A Particle Swarm Optimization Approach. Applied Sciences. 2020; 10(1):203. https://doi.org/10.3390/app10010203
Chicago/Turabian StyleHuynh, Luan N. T., Quoc-Viet Pham, Xuan-Qui Pham, Tri D. T. Nguyen, Md Delowar Hossain, and Eui-Nam Huh. 2020. "Efficient Computation Offloading in Multi-Tier Multi-Access Edge Computing Systems: A Particle Swarm Optimization Approach" Applied Sciences 10, no. 1: 203. https://doi.org/10.3390/app10010203
APA StyleHuynh, L. N. T., Pham, Q.-V., Pham, X.-Q., Nguyen, T. D. T., Hossain, M. D., & Huh, E.-N. (2020). Efficient Computation Offloading in Multi-Tier Multi-Access Edge Computing Systems: A Particle Swarm Optimization Approach. Applied Sciences, 10(1), 203. https://doi.org/10.3390/app10010203