On the basis of the first 2 experts, expert 3 carries out feature fusion of various levels. In addition to pre-fusion of the spectrogram and the model, LLD and its related HSFs are also introduced. Finally, the 2 types of features are used together to train the model.
3.4.1. Feature Selection and Integration
In the task of speech emotion recognition, the original speech features commonly used include Mel-frequency cepstral coefficient (MFCC), fundamental frequency, energy characteristics, and formants. The existing methods of fusing speech emotion features often have problems such as increased space and time complexity. To effectively solve the problem of excessive dimensionality, the dimension features with the greatest contribution to speech emotion recognition can be selected from the speech emotion feature parameters.
Table 1 lists the most important 20-dimensional original speech features and their commonly used HSF information. Through the feature selection method, it is determined that the features involved in
Table 1 make the greatest contribution in the process of speech emotion recognition.
Spectral features are recognized as characteristic parameters based on the auditory characteristics of the human ear and the mechanism of speech production. The extraction principle of the MFCC is designed based on the ear’s auditory mechanism. It is the most frequently used and most effective spectral feature in speech emotion recognition.
The MFCC can be composed of 13 parameters, delta and delta delta. In the basic discriminative environment of sentiment classification, the validity of the first and second parameters of MFCC is the highest.
In addition to the MFCC, the Alpha Ratio is obtained by using energy of 50–1000 Hz and 1–5 kHz and the Hammarberg index, obtained by dividing the strongest energy peak of 0–2 kHz with the strongest energy peak of 2–5 kHz. Spectral slope 0–500 Hz, the logarithmic power of the Mel band, and spectral flux are also extracted as important parts of the feature set.
Since the pitch frequency has a certain relationship with the individual’s physiological structure, age, gender, and pronunciation habits, it can generally be used to mark the person’s emotional expression.
The pitch period is the length of time that the vocal cords vibrate during pronunciation. When a voiced sound is produced, a quasi-periodic excitation pulse train is generated, resulting in vibration of the vocal cords.
Energy characteristics are generally related to sound quality. They describe the nature of the glottis excitation signal, including the vocalist’s voice and breathing; the performance of energy characteristics varies from emotion to emotion. By evaluating them, the emotional state can be distinguished. In addition, Shimmer and Loudness energy features are selected. Shimmer represents the difference in amplitude peaks between adjacent pitch periods. An estimate of Loudness that can be obtained from the spectrum, the spectral flux of two adjacent frames, can be calculated from the energy.
Equivalent Sound Level is a way to describe the level of sound over time. It can track all fluctuations, calculate the average energy at the end of the measurement, obtain the information in decibels, and then take the logarithm. At the level of valence, this feature is more accurate for describing speech with greater mood swings.
Performing an HSF representation on the LLD features to obtain global features of the segmented speech information, the HSF representation methods used here are sma, sma mean, and stddev. Sma represents a smooth global result by a moving average filter with window length n. Mean represents the mean of LLD, and stddev represents the standard deviation of LLD. In addition, statistical functions such as rising slope and 20th percentile are used.
For global features, the LLD and its HSF results are extracted in batches to obtain the best combination and a simplified version of the feature set, which is the first level input of expert 3.
3.4.2. Design of Feature Extraction Model Based on CRNN
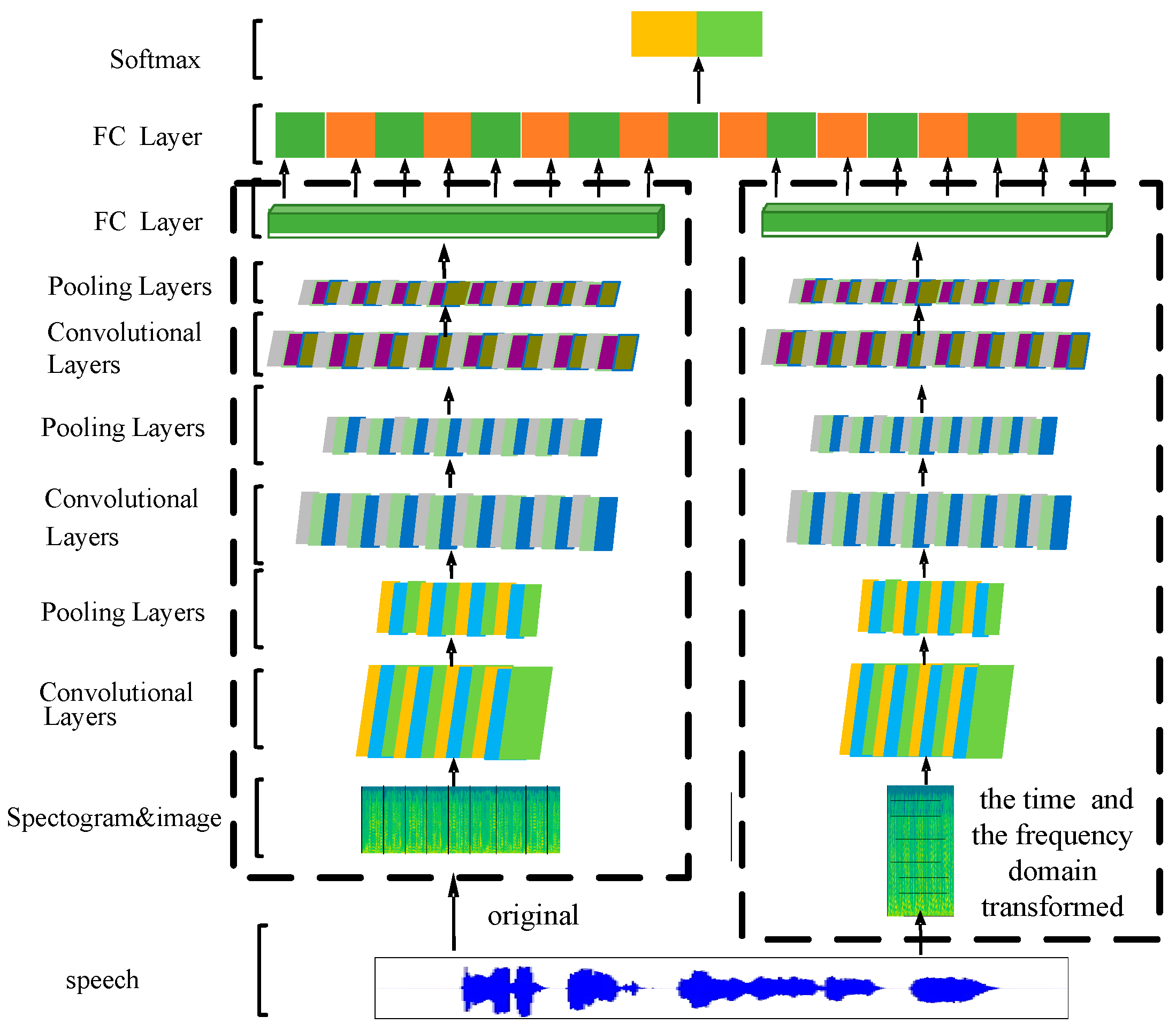
When modeling speech signals, time-dependent models are often used, highlighting the effects of significant regions. Aiming at the requirements, a speech emotion recognition model based on CRNN is proposed. The model is mainly designed for the time domain features of the spectrogram. On the basis of segmentation of speech, the mode of spatial spectrum representing emotional information was effectively studied, and a multi-layer bi-directional LSTM structure was designed. The model is shown in
Figure 3. The output of this model was used as the input to the second level of expert 3, which represents local features with timing relationships.
The CRNN model consists of 2 parts, CNN and RNN. The former is based on the traditional CNN model, which is mainly used to extract the frequency domain features of the spectrogram. For pre-segmented speech, the features of CNN learning for each segment can be obtained. The input image is convoluted into 6 steps (3 consecutive sets of convolution and pooling operations) to generate a set of features. Then the features are sent to the RNN model, where a multi-layer bi-directional LSTM network is used, where each time step corresponds to a segment of the original speech input, thereby preserving long-term dependencies between regions.
The goal of designing the CRNN model is not to directly judge the speech emotion, but to use the model obtained from the CRNN training for secondary verification. When verifying, the result is directly computed after the penultimate full connection. The result is used as the local feature for subsequent feature fusion. The model takes into account the characteristics of the time and frequency domains of the spectrogram. Using the spectrogram as the input of the network, the parameters of the CNN convolutional layer are trained, and the feature map output by the CNN is reconstructed. At this point, the advantages of CNN for image recognition and the characteristics of the RNN’s ability to process serialized data are fully utilized.
3.4.3. Design of Multilevel Model Based on HSFs and CRNN
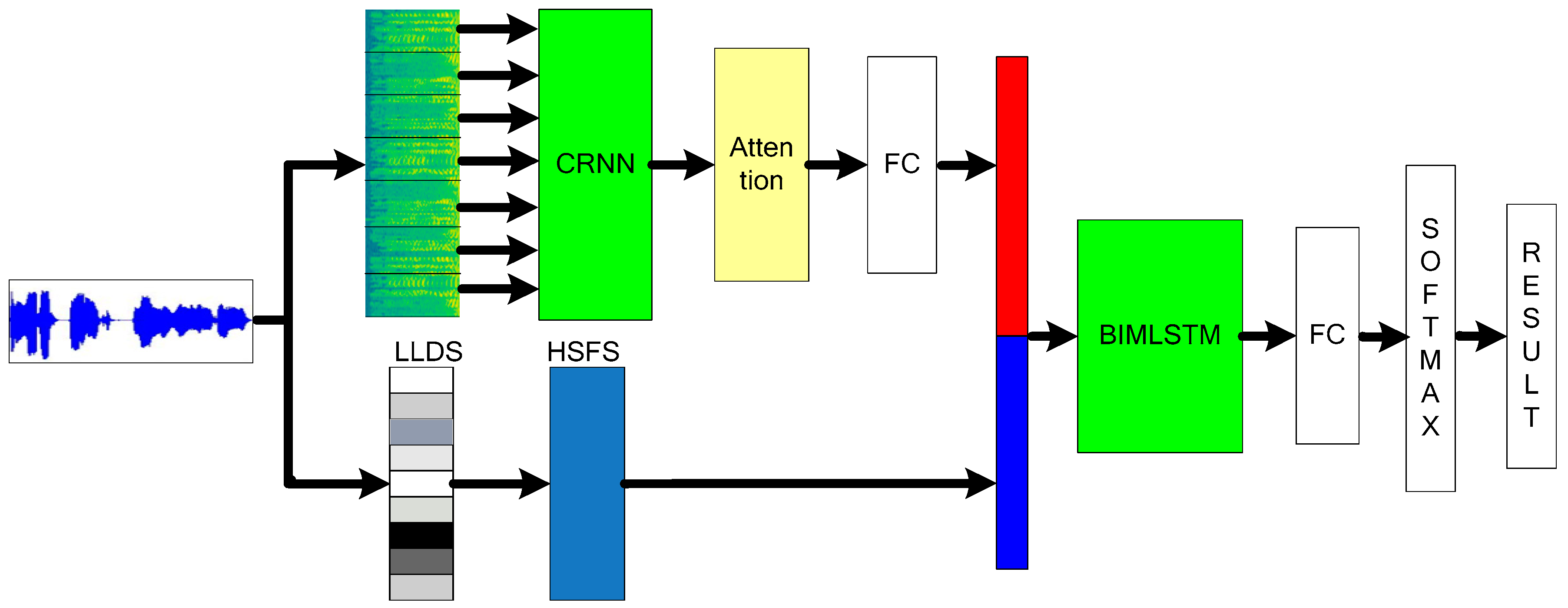
Features learned through the LLD-HSF and CRNN models describe the state of emotions from different aspects, and there are complementary characteristics between them. Combining the above learned features, expert 3 was designed and a multilevel emotion recognition model was proposed. Two types of features are connected through the hidden layer and are projected into the same space. Compared with the traditional way, the discrimination of emotion-related features is enhanced.
As shown in
Figure 4, the entire multi-level model is trained in an end-to-end manner, with given segmented speech being processed simultaneously on 2 parallel levels. On one level, these segments are input to the CRNN based on the spectrogram segmentation. The output of the CRNN model is a 32 × 513-dimensional vector, which is then added to an attention layer and a hidden layer of 128 dimensions, and the high-dimensional features are successively mapped to the low-dimensional 1024-dimensional feature space. On another level, the original waveform is segmented into frames. The LLD feature is extracted from each frame, and the corresponding HSFs are further counted to obtain a global feature vector with a size of 20 dimensions.
By linking the feature vectors of the 2 levels, on the basis of integrating the 2 types of features, they are sequentially added to a bi-directional 3-layer LSTM model, an attention channel, and a hidden layer. The hidden layer projects them into the feature space, passes them to the Softmax layer for classification, and finally outputs the classification results.
Expert 3 is characterized by the effective combination of local and global features. Local features can maximize the weight of features of certain important areas, while global features measure the standard of speech over the entire time range. Both types of features have their own characteristics and focus on the direction. An effective combination can increase the significant area while taking into account the information of all features. Multi-level fusion can improve the basic elements of local and global features. On the basis of combining attention mechanisms, the salient regions in the input features are reversely acquired, and the recognition accuracy is improved in the reverse direction.






{kind=link}
{kind=link}
{kind=link}
{kind=link}