NTARC: A Data Model for the Systematic Review of Network Traffic Analysis Research


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- low-intrusive (i.e., privacy respectful),
- fast and lightweight,
- applicable to big volumes of traffic,
- suitable for embedding in network middle-boxes.
2. Scientific Data Repositories and Data Sharing Initiatives
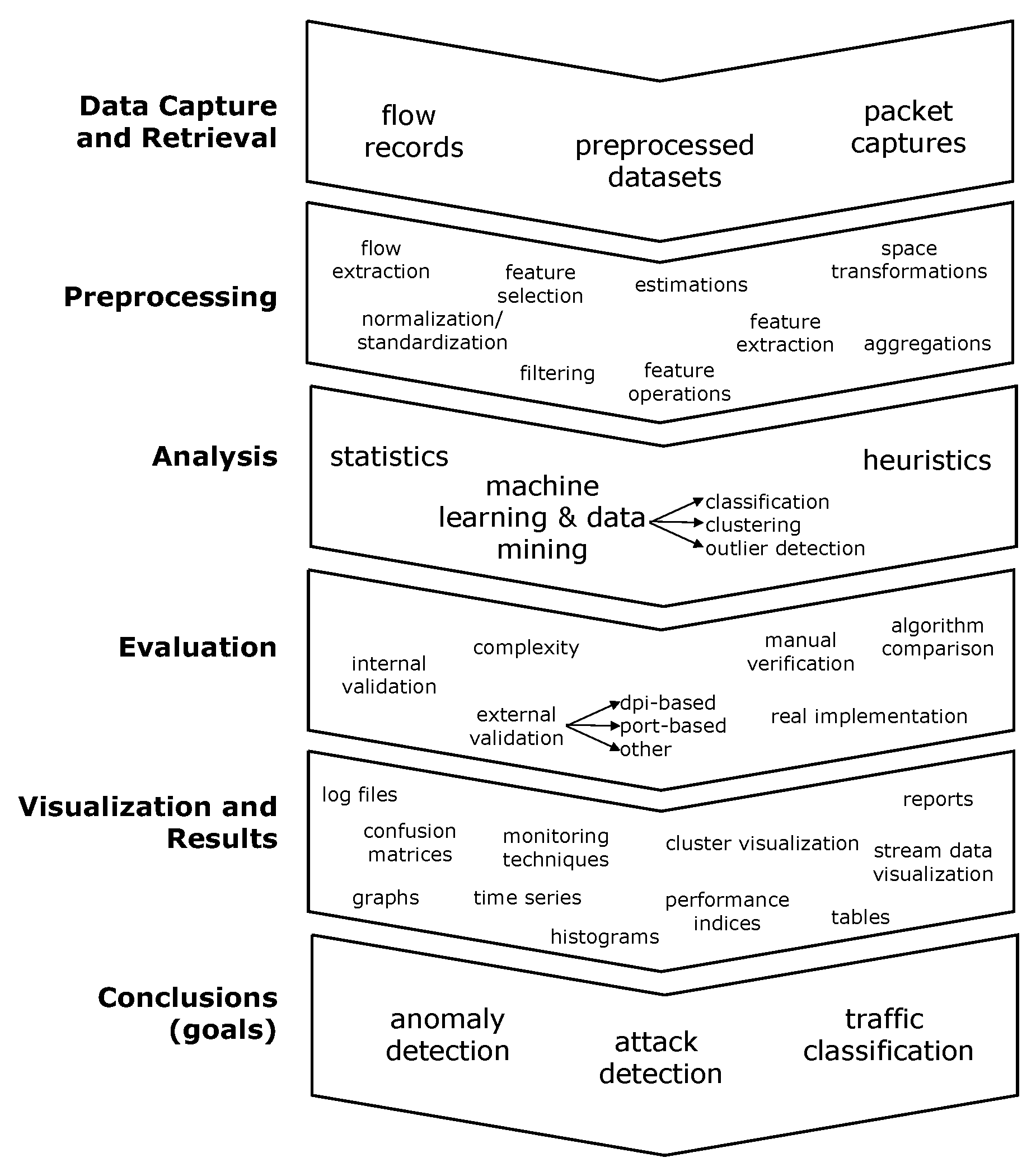
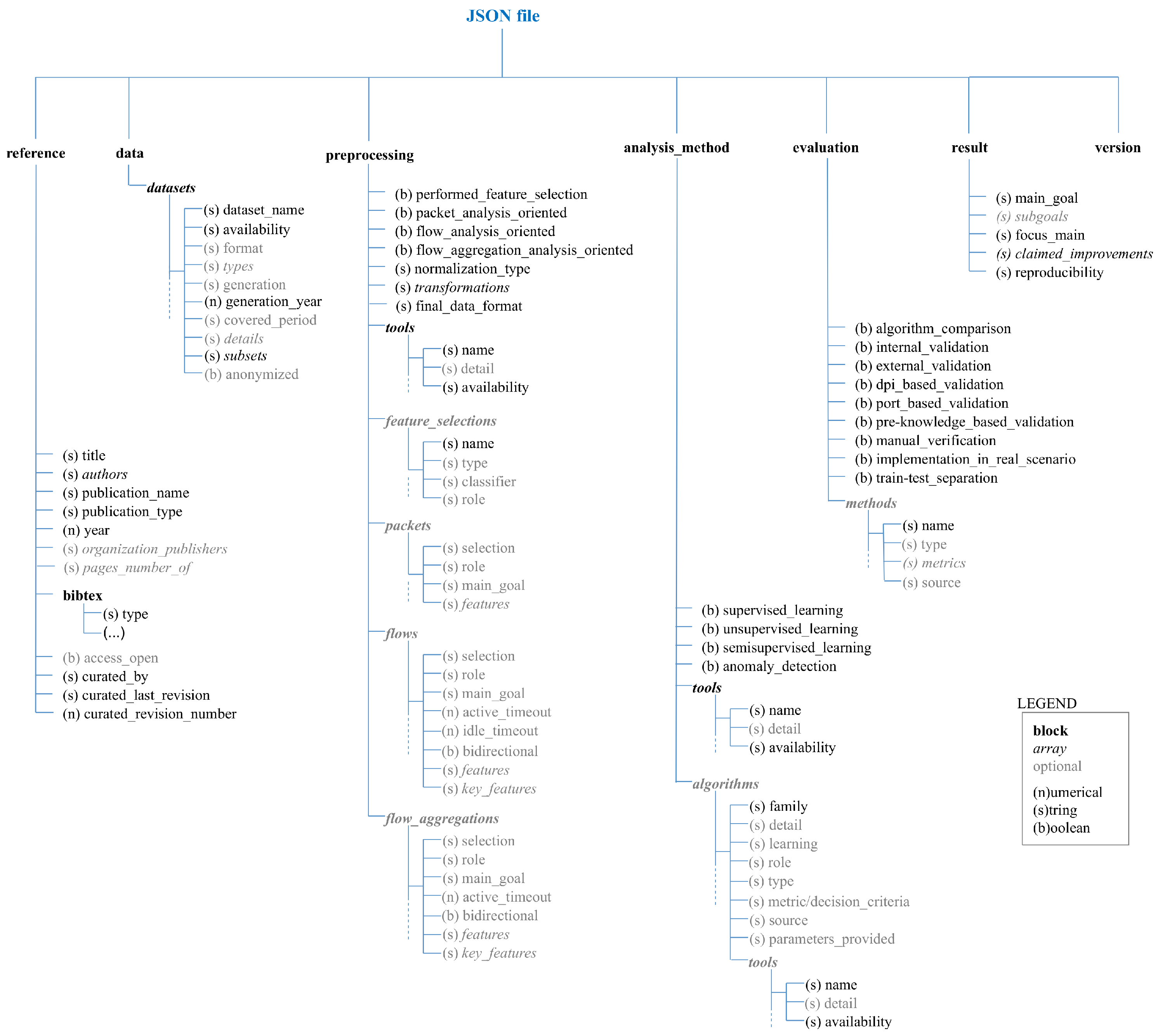
3. NTARC Data Structures
- The reference block:This block collects information that identifies the scientific work, the publication media, and the curation process itself.
- The data block:This block stores information about the network traffic data used. It is not intended to refer to the original dataset version, but the version retrieved by the paper authors, which might have been modified. Here, we find one of the anchors that facilitates comparative analysis, since the scope of the data is always NTA and is provided in the shape of either packet captures, flow records, or preprocessed data derived from packet captures or flow records.The data block consists of one or several datasets. By definition, two datasets must be reported separately when they clearly come from different setups, projects, or sensor environments; otherwise, they must be defined as subsets.
- The preprocessing block:This block summarizes all transformation and modification processes that datasets underwent previous to the main analysis (e.g., normalization, dimensionality reduction, feature extraction, filtering). The stored information is limited to the preprocessing specifically mentioned in the paper as a part of the presented methodology. This block also captures the set of network traffic features and/or flow keys that were used to represent traffic during subsequent analysis.Most fields in this block are binary and mandatory, allowing a fast curation of relevant preprocessing aspects. Subsequent blocks (e.g., feature_selections, packets, flows, and flow_aggregations) are optional, being suitable for cases where a more detailed, fine-grained definition is desired. Specifically, packets, flows, and flow_aggregations are blocks that indicate the type of traffic objects to analyze during experiments. The habitual trend is focusing on only one of these traffic objects.
- The analysis_method block:This block depicts the analysis. It captures relevant details of the analysis methodology and identifies the algorithms used. Note that here, tools are repeated at two context levels: general for the analysis method and specific for algorithms.
- The evaluation block:This block gathers information to understand how analysis outcomes were validated, evaluated, and interpreted. It basically registers the metrics used and the perspectives that the authors found relevant to assess the analysis success or failure.
- The result block:In this block, goals, sub-goals, and improvements claimed by the authors are collected. It also defines the focus of the paper and if the published work meets reproducibility standards [35].
4. Tools Developed for NTARC
4.1. JSON Schema
4.2. NTARC Editor
4.3. Verification Tool
4.4. NTARC Extraction Library
4.5. Content Validation
5. Dissemination Initiatives
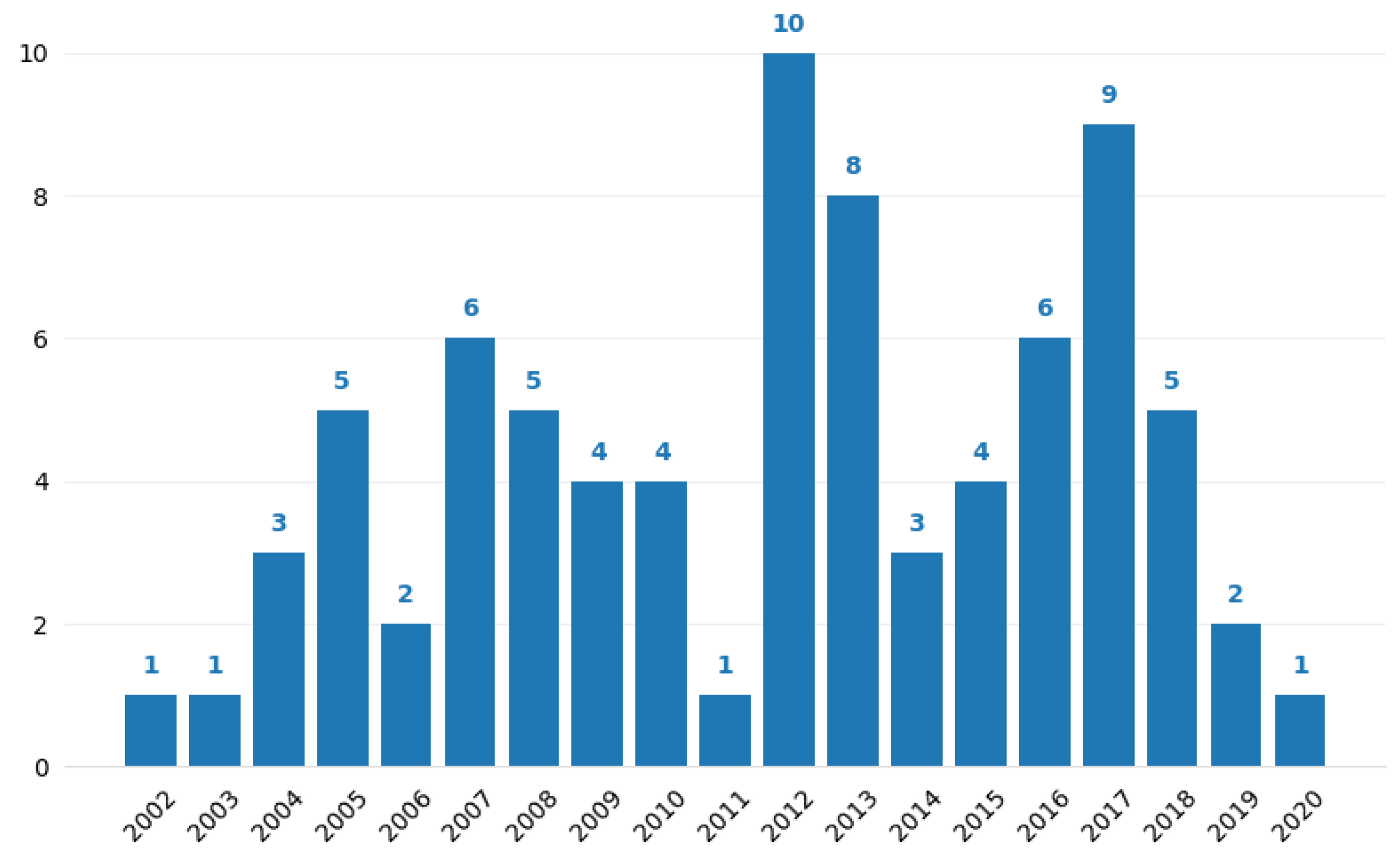
6. The NTARC Database
- Papers matching the structure in Figure 1.
- Citations. Highly referenced papers were the priority.
- Year of publication. Recent papers were the priority.
- Publication medium. Papers published in top peer-reviewed journals and conferences were the priority (based on high scientometric indices, e.g., the impact factor).
7. Analysis of NTA Research (NTARC Database)
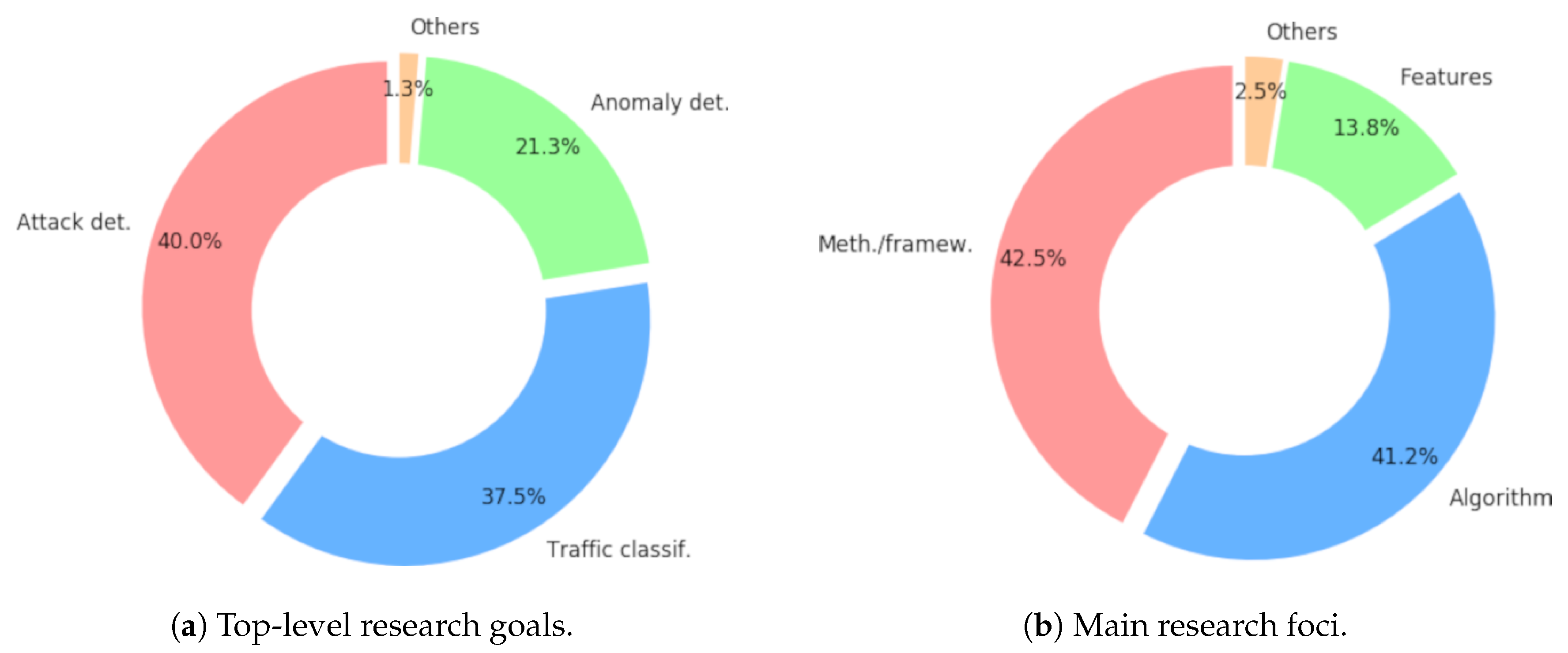
7.1. Research Goals
- Attack detection. This is whenever the applicability of the proposal detects attacks in network traffic, meaning the identification of traffic associated with malicious behavior. An example is the work by Potluri and Diedrich in [116].
- Anomaly detection. This is if the paper aims to detect anomalies in network traffic, meaning traffic that is abnormal, breaks expected patterns, or cannot be defined as following normal behaviors. Such anomalies do not have to be necessarily malicious, and the authors do not address a priori any particular attack, scheme, or traffic class. An example is the work by Bhuyan et al. in [117].
- Traffic classification. The is whenever the methods in the paper identify specific classes in network traffic. Such papers are not focused oin the identification of attacks; otherwise, attack detection would be the appropriate goal. An example is the work by Wright et al. in [118].
7.1.1. Attack Detection
7.1.2. Anomaly Detection
- Harmless, legitimate traffic is often also anomalous and a source of deviations as well.
- Neither attacks, nor anomalies have to appear isolated, but can occur as bursty events or small clusters.
- The feature space and the underlying distributions of real traffic have a strong, decisive impact oin the performance of unsupervised analysis methods.
- Clear, unambiguous definitions of the type of anomalies.
- The study of the selected NTA features and the problem spaces drawn by feature sets.
- The use of datasets with distributions that are representative of real-life scenarios. For instance, testing unsupervised detection frameworks with synthetically crafted IDS datasets is not recommended.
7.1.3. Traffic Classification
7.2. Research Foci
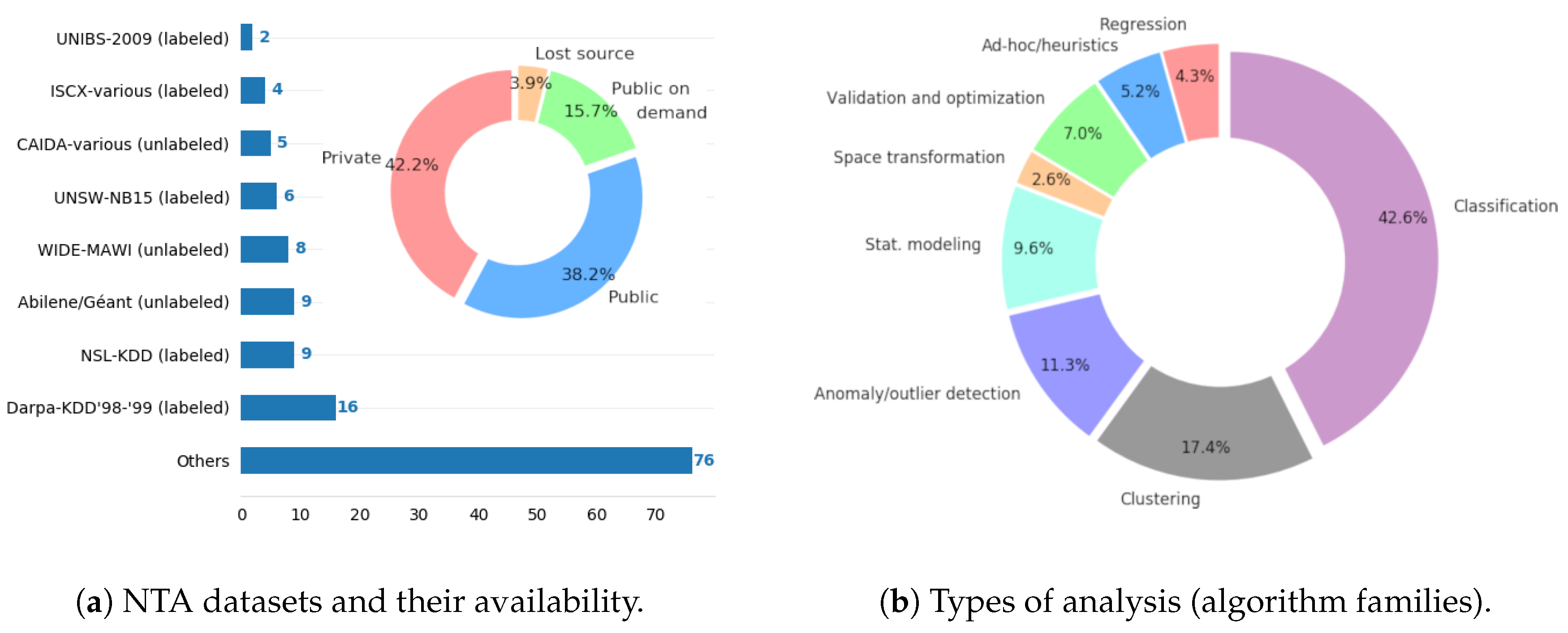
7.3. Used Datasets
7.4. Features
| (1) octetTotalCount, | (2) ipTotalLength, |
| (3) destinationTransportPort, | (4) sourceTransportPort, |
| (5) flowDurationMilliseconds, | (6) packetTotalCount, |
| (7) destinationIPv4Address, | (8) sourceIPv4Address, |
| (9) protocolIdentifier, | (10) server_to_client, |
| (11) client_to_server, | (12) interPacketTime. |
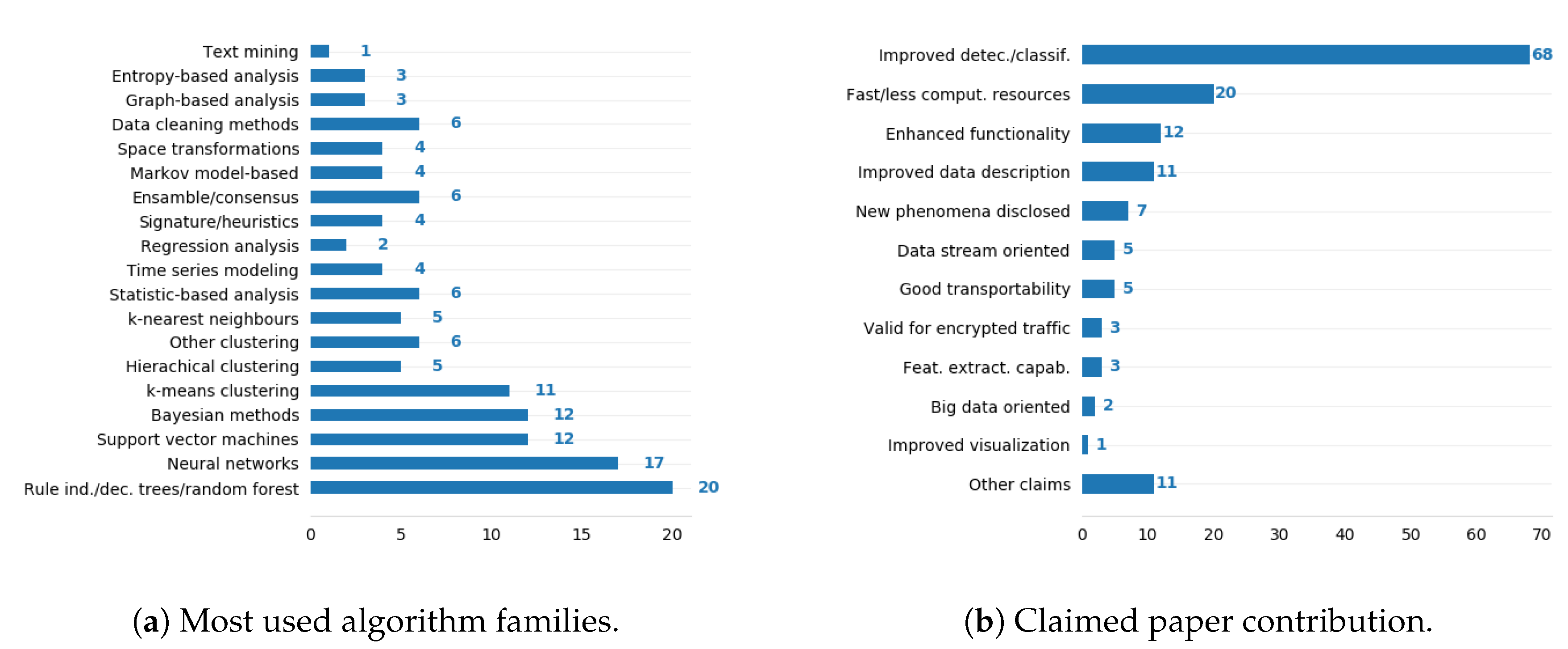
7.5. Predominant Algorithms
- Rule induction, decision trees, and random forests:Using decision trees and similar approaches has strong grounds given the peculiarities of network traffic data. Such methods are robust, easy to adjust, not affected by irrelevant features, capable of working with mixed datasets (i.e., numerical and categorical data together), and provide interpretable solutions that help create knowledge and understand the contribution of network features. On the other hand, a main drawback is that class imbalance severely affects such methods. This situation is typical in network traffic datasets, in which differences in class representations can account for several orders of magnitude.
- Neural networks and support vector machines:These two algorithm families share some common drawbacks. They behave as black boxes (i.e., knowledge extraction is hard, if not unfeasible), involve high computational costs, require complex parameterizations, are prone to suffer instability, and commonly demand feature transformations and painful increments of dimensionality. Nevertheless, ideally, both options are able to obtain highly accurate results. The last years’ growth of data availability in big volumes and the increase of computational power have entailed a considerable technology push favoring them. Both support vector machines and neural networks are suitable for network traffic data spaces, which are normally high-dimensional, and the class shapes are not necessarily globular. Validation, implications of noise, local-minima problems, and lack of robustness—especially when considering adversarial settings—are issues often obviated, but key in real applications, which must endure with minimal degradation. Noteworthy is the fact that, as of 2016, deep learning has captured the majority of supervised learning proposals.
- Probabilistic and Bayesian methods:These methods are often used due to their simplicity, high speed, suitability for high-dimensional data, and the fact that probabilistic decision-making is appropriate for feature vectors that contain very different types of properties. However, naive solutions assume that features are independent, and more complex Bayesian methods require the modeling of such dependencies. In this regard, network traffic features are prone to show high correlation [127], a fact that in principle advises against Bayes-based approaches.
- Clustering:NTA unsupervised methods consist mainly of clustering. Unsupervised methods are more often applied as parts of the analysis frameworks than supervised methods. Clustering is frequently used for data reduction or space simplifications, also after other space transformations (e.g., PCA, graph representation, SOM). Therefore, their suitability must be assessed within the corresponding framework. Two main trends are observed here: prioritizing fastness (K-means and K-means variants) or accuracy (e.g., hierarchical clustering, DBSCAN). K-means is a simple, fast algorithm, but unstable and prone to generate suboptimal results. Hence, internal validation is almost mandatory, though it is actually not often incorporated in detection frameworks (Figure 7a). On the other hand, hierarchical clustering and other popular clustering options like DBSCAN or OPTICS are more accurate and robust, but computationally costly and less flexible for stream data and evolving scenarios. Their incorporation into real, stand-alone detection systems is therefore difficult.
7.6. Claimed Contribution
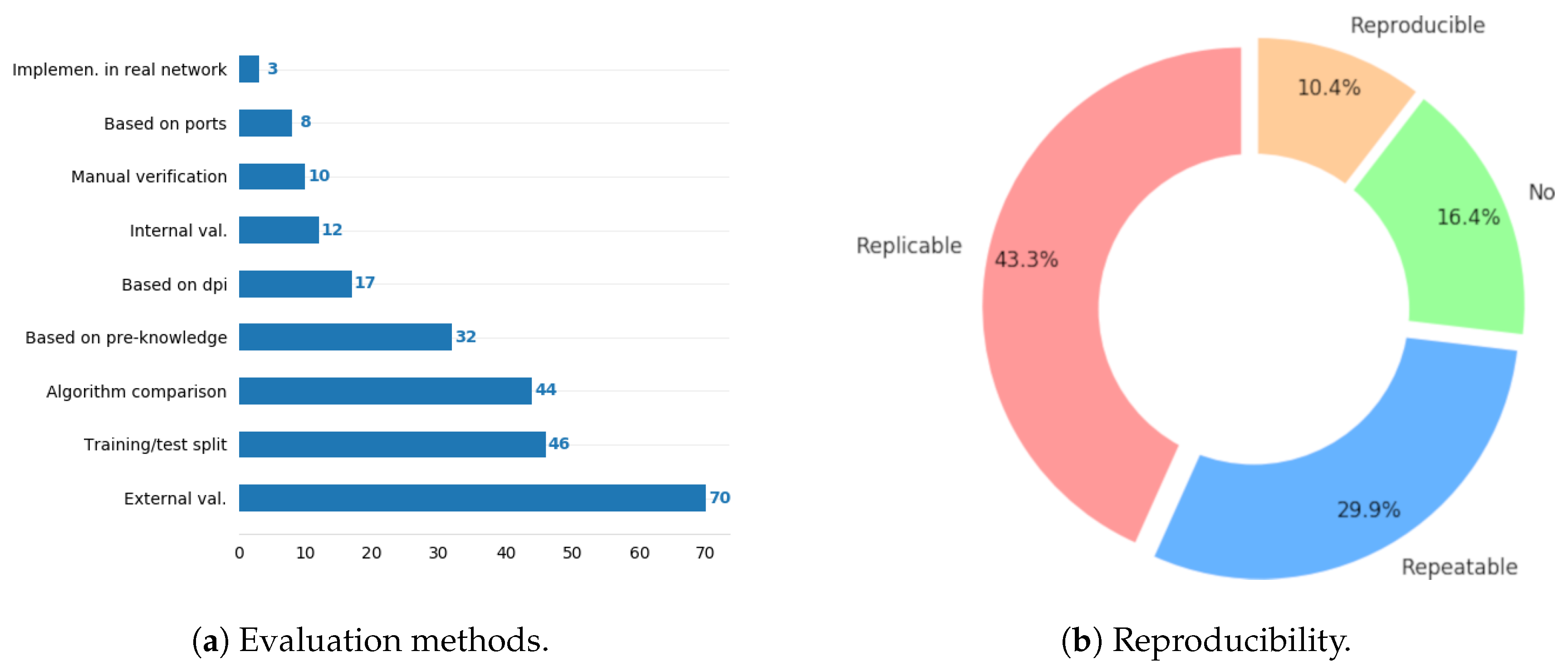
7.7. Reproducibility
- Reproducible: Experiments are fully reproducible by a different team based oin the information given in the paper. The setup, parameters, tools, and datasets are described and/or provided (references to valid links) in a clear and open way. Results are expected to be the same or very similar.
- Replicable: The experiment can be replicated by a different team, but with a different setup. The methodology is clearly explained, at least at a theoretical level. Not all parameters or tools are provided, but readers obtain enough know-how from the paper and references to develop their own setups based oin the provided descriptions.
- Repeatable: The methodologies and setups are clearly described with scientific rigor; however, experiments can only be repeated by the authors given that some resources are not publicly available (e.g., they use datasets that are not openly available).
- No: Important information about the part of the methodology is missing in a way that the experiment cannot be repeated in comparable conditions. Papers show findings or results, but it is not clear how they were obtained (information is hidden, omitted, or simply missing).
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| NTA | Network Traffic Analysis |
| NTARC | Network Traffic Analysis Research Curation |
| JSON | JavaScript Object Notation |
| XML | Extensible Markup Language |
| QoS | Quality of Service |
| RFC | Request for Comments |
| CMR | NASA’s Common Metadata Repository |
| SOLE | Science Object Linking and Embedding |
| DCC | Digital Curation Center |
| NDSA | National Digital Stewardship Alliance |
| RDA | Research Data Alliance |
| CODATA | Committee on Data for Science and Technology |
| LODD | Linking Open Drug Data |
| W3C | World Wide Web Consortium |
| HCLSIG | Health Care and Life Sciences Interest Group |
| CAIDA | Center for Applied Internet Data Analysis |
| IMDC | Internet Measurement Data Catalog |
| HTML | Hypertext Markup Language |
| CSS | Cascading Style Sheets |
| API | Application Programming Interface |
| IDS | Intrusion Detection System |
| KDD | Knowledge Discovery in Databases |
| CIC | Canadian Institute for Cybersecurity |
| ISCX | Installation Support Center of Expertise |
| MAWI | Measurement and Analysis oin the WIDE Internet |
| IANA | Internet Assigned Numbers Authority |
| TCP | Transmission Control Protocol |
| IP | Internet Protocol |
| IPFIX | IP Flow Information Export |
| PCA | Principal Component Analysis |
| SOM | Self-Organizing Maps |
| DBSCAN | Density-Based Spatial Clustering |
| OPTICS | Ordering Points to Identify the Clustering Structure |
References
- Li, B.; Springer, J.; Bebis, G.; Gunes, M.H. A survey of network flow applications. J. Netw. Comput. Appl. 2013, 36, 567–581. [Google Scholar] [CrossRef]
- Quittek, J.; Zseby, T.; Claise, B.; Zander, S. Requirements for IP Flow Information Export (IPFIX); RFC 3917; IETF Network Working Group, The Internet Society: Reston, VA, USA, 2004. [Google Scholar]
- Kim, H.; Claffy, K.; Fomenkov, M.; Barman, D.; Faloutsos, M.; Lee, K. Internet Traffic Classification Demystified: Myths, Caveats, and the Best Practices. In Proceedings of the 2008 ACM CoNEXT Conference, New York, NY, USA, 10–12 December 2008; pp. 11:1–11:12. [Google Scholar]
- Ahmed, M.; Naser Mahmood, A.; Hu, J. A Survey of Network Anomaly Detection Techniques. J. Netw. Comput. Appl. 2016, 60, 19–31. [Google Scholar] [CrossRef]
- Callado, A.; Kamienski, C.; Szabo, G.; Gero, B.P.; Kelner, J.; Fernandes, S.; Sadok, D. A Survey on Internet Traffic Identification. IEEE Commun. Surv. Tutor. 2009, 11, 37–52. [Google Scholar] [CrossRef]
- Bhuyan, M.H.; Bhattacharyya, D.K.; Kalita, J.K. Network anomaly detection: Methods, systems and tools. IEEE Commun. Surv. Tutor. 2014, 16, 303–336. [Google Scholar] [CrossRef]
- Munafò, M.R.; Nosek, B.A.; Bishop, D.V.M.; Button, K.S.; Chambers, C.D.; Percie du Sert, N.; Simonsohn, U.; Wagenmakers, E.J.; Ware, J.J.; Ioannidis, J.P.A. A manifesto for reproducible science. Nat. Hum. Behav. 2017, 1, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Ferreira, D.C. NTARC Database (GitHub). 2018. Available online: https://github.com/CN-TU/nta-meta-analysis (accessed on 25 April 2020).
- Ardestani, S.B.; Håkansson, C.J.; Laure, E.; Livenson, I.; Stranák, P.; Dima, E.; Blommesteijn, D.; van de Sanden, M. B2SHARE: An Open eScience Data Sharing Platform. In Proceedings of the 2015 IEEE 11th International Conference on e-Science, Munich, Germany, 31 August–4 September 2015; pp. 448–453. [Google Scholar]
- Singh, J. FigShare. J. Pharmacol. Pharmacother. 2011, 2, 138–139. [Google Scholar] [CrossRef]
- Chard, K.; Pruyne, J.; Blaiszik, B.; Ananthakrishnan, R.; Tuecke, S.; Foster, I. Globus Data Publication as a Service: Lowering Barriers to Reproducible Science. In Proceedings of the IEEE 11th International Conference on e-Science, Munich, Germany, 31 August–4 Septembe 2015; pp. 401–410. [Google Scholar]
- TU Delft Library. 4TU.Centre for Research Data. 2017. Available online: https://data.4tu.nl/ (accessed on 25 April 2020).
- CERN Data Centre and Invenio. Zenodo, 2013. Last Updated: July 2017. Available online: https://zenodo.org/ (accessed on 25 April 2020).
- The Dataverse Network: An Open-source Application for Sharing, Discovering and Preserving Data. D-Lib Mag. 2011, 17, 2.
- Greenberg, J.; White, H.C.; Carrier, S.; Scherle, R. A Metadata Best Practice for a Scientific Data Repository. J. Libr. Metadata 2009, 9, 194–212. [Google Scholar] [CrossRef]
- Assante, M.; Candela, L.; Castelli, D.; Tani, A. Are scientific data repositories coping with research data publishing? Data Sci. J. 2016, 15, 6. [Google Scholar]
- EarthData-NASA. Common Metadata Repository (CMR), Earth Science Data & Information System Project (ESDIS), 2017. Last Updated: June 2017. Available online: https://earthdata.nasa.gov/about/science-system-description/eosdis-components/common-metadata-repository (accessed on 25 April 2020).
- Devarakonda, R.; Palanisamy, G.; Green, J.M. Digitizing scientific data and data retrieval techniques. arXiv 2010, arXiv:1010.3983v2. [Google Scholar]
- Harrison, K.A.; Wright, D.G.; Trembath, P. Implementation of a workflow for publishing citeable environmental data: Successes, challenges and opportunities from a data centre perspective. Int. J. Digit. Libr. 2017, 18, 133–143. [Google Scholar] [CrossRef] [Green Version]
- Bardi, A.; Manghi, P. Enhanced Publications: Data Models and Information Systems. LIBER Q. 2014, 23, 240–273. [Google Scholar] [CrossRef] [Green Version]
- Candela, L.; Castelli, D.; Manghi, P.; Tani, A. Data journals: A survey. J. Assoc. Inf. Sci. Technol. 2015, 66, 1747–1762. [Google Scholar] [CrossRef] [Green Version]
- Bardi, A.; Manghi, P. Enhanced Publication Management Systems: A Systemic Approach Towards Modern Scientific Communication. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1051–1052. [Google Scholar]
- Pham, Q.; Malik, T.; Foster, I.; Di Lauro, R.; Montella, R. SOLE: Linking Research Papers with Science Objects. In Provenance and Annotation of Data and Processes: 4th International Provenance and Annotation Workshop, IPAW; Groth, P., Frew, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 203–208. [Google Scholar]
- Group, N.P. About the Scientific Data Journal. 2014. Available online: https://researchdata.springernature.com/users/69239-scientific-data (accessed on 25 April 2020).
- Cragin, M.H.; Palmer, C.L.; Carlson, J.R.; Witt, M. Data sharing, small science and institutional repositories. Philos. Trans. R. Soc. Math. Phys. Eng. Sci. 2010, 368, 4023–4038. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Council, N.R. Preparing the Workforce for Digital Curation; The National Academies Press: Washington, DC, USA, 2015. [Google Scholar]
- Samwald, M.; Jentzsch, A.; Bouton, C.; Kallesøe, C.S.; Willighagen, E.; Hajagos, J.; Marshall, M.S.; Prud’hommeaux, E.; Hassanzadeh, O.; Pichler, E.; et al. Linked open drug data for pharmaceutical research and development. J. Cheminform. 2011, 3, 19. [Google Scholar] [CrossRef] [Green Version]
- Shannon, C.; Moore, D.; Keys, K.; Fomenkov, M.; Huffaker, B.; Claffy, K. The Internet Measurement Data Catalog. SIGCOMM Comput. Commun. Rev. 2005, 35, 97–100. [Google Scholar] [CrossRef]
- CAIDA (Center for Applied Internet Data Analysis). Internet Traffic Classification, 2015. Last Updated: May, 2015. Available online: http://www.caida.org/research/traffic-analysis/classification-overview/ (accessed on 20 February 2020).
- IMPACT. Information Marketplace for Policy and Analysis of Cyber-Risk & Trust. 2017. Available online: https://www.impactcybertrust.org/ (accessed on 25 April 2020).
- Borenstein, M.; Hedges, L.V.; Higgins, J.P.T.; Rothstein, H.R. Introduction to Meta-Analysis; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2009; pp. 409–414. [Google Scholar]
- Haidich, A.B. Meta-analysis in medical research. Hippokratia 2010, 14, 29. [Google Scholar]
- Bray, T. RFC 7159: The JavaScript Object Notation (JSON) Data Interchange Format; Technical Report; Internet Engineering Task Force (IETF): Fremont, CA, USA, 2014. [Google Scholar]
- Ferreira, D.C.; Iglesias, F.; Vormayr, G.; Bachl, M.; Zseby, T. A Meta-Analysis Approach for Feature Selection in Network Traffic Research. In Proceedings of the Reproducibility Workshop, Los Angeles, CA, USA, 21–25 August 2020; ACM: New York, NY, USA, 2017; pp. 17–20. [Google Scholar]
- Association for Computing Machinery (ACM). ACM Result and Artifact Review and Badging Publication Policy. 2017. Available online: https://www.acm.org/publications/policies/artifact-review-badging (accessed on 25 April 2020).
- Ferreira, D.C.; Bachl, M.; Vormayr, G.; Iglesias, F.; Zseby, T. NTARC Specification (Version v3.0.0). 12 November 2018. Available online: http://doi.org/10.5281/zenodo.1484190 (accessed on 25 April 2020).
- Vormayr, G. Editor for the NTARC data format (Version v3.1.6). 28 November 2018. Available online: http://doi.org/10.5281/zenodo.1625380 (accessed on 25 April 2020).
- Wright, A.; Andrews, H. JSON Schema: A Media Type for Describing JSON Documents. Internet Engineering Task Force, IETF Secretariat (Internet Draft). 19 March 2018. Available online: https://json-schema.org/draft-07/json-schema-core.html (accessed on 25 April 2020).
- Electron. Available online: https://electronjs.org (accessed on 2 February 2018).
- Ferreira, D.C. NTARC Verification Tool (Github). 2018. Available online: https://github.com/CN-TU/nta-meta-analysis-verification (accessed on 25 April 2020).
- Sinha, A.; Shen, Z.; Song, Y.; Ma, H.; Eide, D.; Hsu, B.J.P.; Wang, K. An Overview of Microsoft Academic Service (MAS) and Applications. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 243–246. [Google Scholar]
- Ferreira, D.C. NTARC Extractor Library (Github). 2018. Available online: https://github.com/CN-TU/nta-meta-analysis-library (accessed on 25 April 2020).
- Ferreira, D.C.; Bachl, M.; Vormayr, G.; Iglesias, F.; Zseby, T. Curated Research on Network Traffic Analysis (Version 2020.2) [Data set]. 10 February 2020. Available online: http://doi.org/10.5281/zenodo.3661423 (accessed on 25 April 2020).
- Barford, P.; Kline, J.; Plonka, D.; Ron, A. A Signal Analysis of Network Traffic Anomalies. In Proceedings of the ACM SIGCOMM Workshop on Internet Measurement, Marseille, France, 6–8 November 2002; pp. 71–82. [Google Scholar]
- Mahoney, M.V.; Chan, P.K. Learning rules for anomaly detection of hostile network traffic. In Proceedings of the 3rd IEEE International Conference on Data Mining, Melbourne, FL, USA, 22 November 2003; pp. 601–604. [Google Scholar]
- Lakhina, A.; Crovella, M.; Diot, C. Characterization of Network-Wide Anomalies in Traffic Flows. In Proceedings of the 4th ACM SIGCOMM Conference on Internet Measurement, Taormina, Sicily, Italy, 25–27 October 2004; pp. 201–206. [Google Scholar]
- Lakhina, A.; Crovella, M.; Diot, C. Diagnosing Network-Wide Traffic Anomalies. In Proceedings of the Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications (SIGCOMM ’04), Portland, OR, USA, 30 August–3 September 2004; pp. 219–230. [Google Scholar]
- Wang, K.; Stolfo, S.J. Anomalous Payload-based Network Intrusion Detection. In Proceedings of the International Workshop on Recent Advances in Intrusion Detection, French Riviera, France, 15–17 September 2004. [Google Scholar]
- Gu, Y.; McCallum, A.; Towsley, D. Detecting Anomalies in Network Traffic Using Maximum Entropy Estimation. In Proceedings of the 5th ACM SIGCOMM Conference on Internet Measurement, Berkeley, CA, USA, 19–21 October 2005; pp. 345–350. [Google Scholar]
- Karagiannis, T.; Papagiannaki, K.; Faloutsos, M. BLINC: Multilevel Traffic Classification in the Dark. In Proceedings of the ACM SIGCOMM Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Philadelphia, PA, USA, 22–26 August 2005; pp. 229–240. [Google Scholar]
- Lakhina, A.; Crovella, M.; Diot, C. Mining Anomalies Using Traffic Feature Distributions. In Proceedings of the ACM SIGCOMM Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Philadelphia, PA, USA, 22–26 August 2005; Volume 35, pp. 217–228. [Google Scholar]
- Moore, A.W.; Zuev, D. Internet Traffic Classification Using Bayesian Analysis Techniques. In Proceedings of the ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems, Banff, AB, Canada, 6–10 June 2005; Volume 33, pp. 50–60. [Google Scholar]
- Thottan, M.; Ji, C. Anomaly Detection in IP Networks. IEEE Trans. Signal Process. 2005, 51, 2191–2204. [Google Scholar] [CrossRef] [Green Version]
- Williams, N.; Zander, S.; Armitage, G. A preliminary performance comparison of five machine learning algorithms for practical ip traffic flow classification. ACM SIGCOMM Comput. Commun. Rev. 2006, 36, 5–16. [Google Scholar] [CrossRef]
- Wright, C.; Monrose, F.; Masson, G. on inferring application protocol behaviors in encrypted network traffic. J. Mach. Learn. Res. 2006, 7, 2745–2769. [Google Scholar]
- Auld, T.; Moore, A.W.; Gull, S.F. Bayesian Neural Networks for Internet Traffic Classification. IEEE Trans. Neural Netw. 2007, 18, 223–239. [Google Scholar] [CrossRef] [PubMed]
- Crotti, M.; Dusi, M.; Gringoli, F.; Salgarelli, L. Traffic Classification through Simple Statistical Fingerprinting. ACM SIGCOMM Comput. Commun. Rev. 2007, 37, 7–16. [Google Scholar] [CrossRef]
- Erman, J.; Mahanti, A.; Arlitt, M.; Williamson, C. Identifying and Discriminating Between Web and Peer-to-Peer Traffic in the Network Core. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; Volume 16, pp. 883–892. [Google Scholar]
- Erman, J.; Mahanti, A.; Arlitt, M.; Cohen, I.; Williamson, C. Offline/realtime traffic classification using semi-supervised learning. Perform. Eval. 2007, 64, 1194–1213. [Google Scholar] [CrossRef]
- Liu, Y.; Li, W.; Li, Y. Network Traffic Classification Using K-means Clustering. In Proceedings of the Second International Multisymposium on Computer and Computational Sciences, Iowa City, IA, USA, 13–15 August 2007; Volume 1, pp. 360–365. [Google Scholar]
- Ringberg, H.; Soule, A.; Rexford, J.; Diot, C. Sensitivity of PCA for traffic anomaly detection. In Proceedings of the 2007 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems, San Diego, CA, USA, 12–17 June 2007; Volume 35, pp. 109–120. [Google Scholar]
- Dainotti, A.; De Donato, W.; Pescape, A.; Rossi, P.S. Classification of Network Traffic via Packet-Level Hidden Markov Models. In Proceedings of the IEEE GLOBECOM—Global Telecommunications Conference, New Orleans, LA, USA, 30 November–4 December 2008; pp. 1–5. [Google Scholar]
- Gu, G.; Perdisci, R.; Zhang, J.; Lee, W. BotMiner: Clustering analysis of network traffic for protocol- and structure-independent botnet detection. In Proceedings of the 17th Conference on Security Symposium USENIX, San Jose, CA, USA, 28 July–1 August 2008; pp. 139–154. [Google Scholar]
- Nychis, G.; Sekar, V.; Andersen, D.G.; Kim, H.; Zhang, H. An empirical evaluation of entropy-based traffic anomaly detection. In Proceedings of the ACM SIGCOMM Conference on Internet Measurement, Vouliagmeni, Greece, 20–22 October 2008. [Google Scholar]
- Yang, A.M.; Jiang, S.Y.; Deng, H. A P2P Network Traffic Classification Method Using SVM. In Proceedings of the International Conference for Young Computer Scientists, Hunan, China, 18–21 November 2008; pp. 398–403. [Google Scholar]
- Zhao, J.; Huang, X.; Sun, Q.; Ma, Y. Real-time feature selection in traffic classification. J. China Univ. Posts Telecomm. 2008, 15, 68–72. [Google Scholar] [CrossRef]
- Alshammari, R.; Zincir-Heywood, A.N. Machine Learning Based Encrypted Traffic Classification: Identifying SSH and Skype. In Proceedings of the IEEE Symposium on Computational Intelligence for Security and Defense Applications (CISDA), Ottawa, ON, Canada, 8–10 July 2009; pp. 1–8. [Google Scholar]
- Este, A.; Gringoli, F.; Salgarelli, L. Support vector Machines for TCP traffic classification. Comput. Netw. 2009, 53, 2476–2490. [Google Scholar] [CrossRef]
- Kind, A.; Stoecklin, M.P.; Dimitropoulos, X. Histogram-based traffic anomaly detection. IEEE Trans. Netw. Serv. Manag. 2009, 6, 110–121. [Google Scholar] [CrossRef]
- Zhani, M.F.; Elbiaze, H.; Kamoun, F. Analysis and Prediction of Real Network Traffic. JNW 2009, 4, 855–865. [Google Scholar] [CrossRef]
- Dewaele, G.; Himura, Y.; Borgnat, P.; Fukuda, K.; Abry, P.; Michel, O.; Fontugne, R.; Cho, K.; Esaki, H. Unsupervised host behavior classification from connection patterns. Int. J. Netw. Manag. 2010, 20, 317–337. [Google Scholar] [CrossRef] [Green Version]
- Lim, Y.; Kim, H.; Jeong, J.; Kim, C.; Kwon, T.T.; Choi, Y. Internet Traffic Classification Demystified: On the Sources of the Discriminative Power. In Proceedings of the 6th International Conferenceon Co-NEXT, Philadelphia, PA, USA, 30 November–3 December 2010. [Google Scholar]
- Shrivastav, A.; Tiwari, A. Network Traffic Classification using Semi-Supervised Approach. In Proceedings of the IEEE International Conference on Machine Learning and Computing (ICMLC), Qingdao, China, 11–14 July 2010; pp. 345–349. [Google Scholar]
- Zeidanloo, H.R.; Manaf, A.B.; Vahdani, P.; Tabatabaei, F.; Zamani, M. Botnet Detection Based on Traffic Monitoring. In Proceedings of the International Conference on Networking and Information Technology, Bradford, UK, 29 June–1 July 2010; pp. 97–101. [Google Scholar]
- Amiri, F.; Yousefi, M.R.; Lucas, C.; Shakery, A.; Yazdani, N. Mutual information-based feature selection for intrusion detection systems. J. Netw. Comput. Appl. 2011, 34, 1184–1199. [Google Scholar] [CrossRef]
- Agarwal, B.; Mittal, N. Hybrid Approach for Detection of Anomaly Network Traffic using Data Mining Techniques. Procedia Technol. 2012, 6, 996–1003. [Google Scholar] [CrossRef]
- Bujlow, T.; Riaz, T.; Pedersen, J.M. A method for classification of network traffic based on C5.0 Machine Learning Algorithm. In Proceedings of the International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 30 January–2 February 2012; pp. 237–241. [Google Scholar]
- Catania, C.A.; Bromberg, F.; Garino, C.G. An autonomous labeling approach to support vector machines algorithms for network traffic anomaly detection. Expert Syst. Appl. 2012, 39, 1822–1829. [Google Scholar] [CrossRef]
- Grimaudo, L.; Mellia, M.; Baralis, E. Hierarchical learning for fine grained internet traffic classification. In Proceedings of the 8th International Wireless Communications and Mobile Computing Conference (IWCMC), Limassol, Cyprus, 27–31 August 2012; pp. 463–468. [Google Scholar]
- Jin, Y.; Duffield, N.; Jeffrey, E.; Haffner, P.; Sen, S.; Zhang, Z.L. A Modular Machine Learning System for Flow-Level Traffic Classification in Large Networks. ACM Trans. Knowl. Discov. Data 2012, 6, 1–34. [Google Scholar] [CrossRef]
- Nguyen, T.; Armitage, G.; Branch, P.; Zander, S. Timely and Continuous Machine-Learning-Based Classification for Interactive IP Traffic. IEEE/ACM Trans. Netw. (TON) 2012, 20, 1880–1894. [Google Scholar] [CrossRef]
- Yin, C.; Li, S.; Li, Q. Network traffic classification via HMM under the guidance of syntactic structure. Comput. Netw. 2012, 56, 1814–1825. [Google Scholar] [CrossRef]
- Zargari, S.; Voorhis, D. Feature Selection in the Corrected KDD-dataset. In Proceedings of the 3rd International Conference on Emerging Intelligent Data and Web Technologies (EIDWT), Bucharest, Romania, 19–21 September 2012; pp. 174–180. [Google Scholar]
- Zhang, H.; Lu, G.; Qassrawi, M.T.; Zhang, Y.; Yu, X. Feature selection for optimizing traffic classification. Comput. Commun. 2012, 35, 1457–1471. [Google Scholar] [CrossRef]
- Zhang, J.; Xiang, Y.; Zhou, W.; Wang, Y. Unsupervised traffic classification using flow statistical properties and IP packet payload. J. Comput. Syst. Sci. 2012, 79, 573–585. [Google Scholar] [CrossRef]
- Comar, P.M.; Liu, L.; Saha, S.; Tan, P.N.; Nucci, A. Combining supervised and unsupervised learning for zero-day malware detection. In Proceedings of the IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 2022–2030. [Google Scholar]
- Fiore, U.; Palmieri, F.; Castiglione, A.; De Santis, A. Network anomaly detection with the restricted Boltzmann machine. Neurocomputing 2013, 122, 13–23. [Google Scholar] [CrossRef]
- Huang, S.Y.; Huang, Y. Network forensic analysis using growing hierarchical SOM. In Proceedings of the International Conference on Data Mining Workshops, Dallas, TX, USA, 7–10 December 2013; pp. 536–543. [Google Scholar]
- Jadidi, Z.; Sheikhan, M. Flow-Based Anomaly Detection Using Neural Network Optimized with GSA Algorithm. In Proceedings of the 33rd International Conference on Distributed Computing Systems Workshops, Philadelphia, PA, USA, 8–11 July 2013; pp. 76–81. [Google Scholar]
- Zhang, F.; Wang, D. An effective feature selection approach for network intrusion detection. In Proceedings of the IEEE 8th International Conference on Networking, Architecture and Storage (NAS), Shaanxi, China, 17–19 July 2013; pp. 307–311. [Google Scholar]
- Zhang, J.; Chen, C.; Xiang, Y.; Zhou, W.; Vasilakos, A.V. An Effective Network Traffic Classification Method with Unknown Flow Detection. IEEE Trans. Netw. Serv. Manag. 2013, 10, 133–147. [Google Scholar] [CrossRef]
- Zhang, J.; Xiang, Y.; Wang, Y.; Zhou, W.; Xiang, Y.; Guan, Y. Network Traffic Classification Using Correlation Information. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 104–117. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, C.; Xiang, Y.; Zhou, W. Robust network traffic identification with unknown applications. In Proceedings of the 8th ACM SIGSAC Symposium on Information, Computer and Communications Security, Berlin, Germany, 4–8 November 2013; pp. 405–414. [Google Scholar]
- Jun, J.H.; Ahn, C.W.; Kim, S.H. DDoS attack detection by using packet sampling and flow features. In Proceedings of the 29th Annual ACM Symposium on Applied Computing, Gyeongju, Korea, 24–28 March 2014; pp. 711–712. [Google Scholar]
- Ma, X.; Chen, Y. DDoS Detection Method Based on Chaos Analysis of Network Traffic Entropy. IEEE Comm. Lett. 2014, 18, 114–117. [Google Scholar] [CrossRef]
- Singh, K.; Guntuku, S.C.; Thakur, A.; Hota, C. Big data analytics framework for peer-to-peer botnet detection using random forests. Inf. Sci. 2014, 278, 488–497. [Google Scholar] [CrossRef]
- Qin, X.; Xu, T.; Wang, C. DDoS attack detection using flow entropy and clustering technique. In Proceedings of the 11th International Conference on Computational Intelligence and Security (CIS), Angkor Wat, Cambodia, 15–17 July 2015; pp. 412–415. [Google Scholar]
- Singh, R.; Kumar, H.; Singla, R. An intrusion detection system using network traffic profiling and online sequential extreme learning machine. Expert Syst. Appl. 2015, 42, 8609–8624. [Google Scholar] [CrossRef]
- van der Toorn, O.; Hofstede, R.; Jonker, M.; Sperotto, A. A first look at HTTP(S) intrusion detection using NetFlow/IPFIX. In Proceedings of the IFIP/IEEE International Symposium on Integrated Network Management (IM), Ottawa, ON, Canada, 11–15 May 2015; pp. 862–865. [Google Scholar]
- Zhang, J.; Chen, X.; Xiang, Y.; Zhou, W.; Wu, J. Robust network traffic classification. IEEE/ACM Trans. Netw. (TON) 2015, 23, 1257–1270. [Google Scholar] [CrossRef]
- Ambusaidi, M.A.; He, X.; Nanda, P.; Tan, Z. Building an Intrusion Detection System Using a Filter-Based Feature Selection Algorithm. IEEE Trans. Comput. 2016, 65, 2986–2998. [Google Scholar] [CrossRef] [Green Version]
- Anderson, B.; McGrew, D. identifying encrypted malware traffic with contextual flow data. In Proceedings of the ACM Workshop on Artificial Intelligence and Security, Vienna, Austria, 28 October 2016; pp. 35–46. [Google Scholar]
- Gharaee, H.; Hosseinvand, H. A new feature selection IDS based on genetic algorithm and SVM. In Proceedings of the 8th International Symposium on Telecomm (IST), Tehran, Iran, 27–29 September 2016; pp. 139–144. [Google Scholar]
- Iglesias, F.; Zseby, T. Time-activity footprints in IP traffic. Comput. Netw. 2016, 107 Pt 1, 64–75. [Google Scholar] [CrossRef]
- Javaid, A.; Niyaz, Q.; Sun, W.; Alam, M. A Deep Learning Approach for Network Intrusion Detection System. In Proceedings of the 9th EAI International Conference on Bio-inspired Information and Communications Technologies ICST, New York, NY, USA, 3–5 December 2016; pp. 21–26. [Google Scholar]
- Mishra, P.; Pilli, E.S.; Varadharajant, V.; Tupakula, U. NvCloudIDS: A security architecture to detect intrusions at network and virtualization layer in cloud environment. In Proceedings of the International Conference on Advances in Computing, Communications and Informatics (ICACCI), Cebu, PA, USA, 27–29 May 2016; pp. 56–62. [Google Scholar]
- Al-Zewairi, M.; Almajali, S.; Awajan, A. Experimental Evaluation of a Multi-layer Feed-Forward Artificial Neural Network Classifier for Network Intrusion Detection System. In Proceedings of the International Conference on New Trends in Computing Sciences (ICTCS), Amman, Jordan, 11–13 October 2017; pp. 167–172. [Google Scholar]
- Anderson, B.; McGrew, D. Machine learning for encrypted malware traffic classification: Accounting for noisy labels and non-stationarity. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1723–1732. [Google Scholar]
- Ashfaq, W.R.A.R.; Wang, X.Z.; Huang, J.Z.; Abbas, H.; He, Y.L. Fuzziness based semi-supervised learning approach for intrusion detection system. Inf. Sci. 2017, 378, 484–497. [Google Scholar] [CrossRef]
- Baig, M.M.; Awais, M.M.; El-Alfy, E.S.M. A multiclass cascade of artificial neural network for network intrusion detection. J. Intell. Fuzzy Syst. 2017, 32, 2875–2883. [Google Scholar] [CrossRef]
- Bamakan, S.M.H.; Wang, H.; Shi, Y. Ramp loss K-Support Vector Classification-Regression; a robust and sparse multi-class approach to the intrusion detection problem. Knowl. Based Syst. 2017, 126, 113–126. [Google Scholar] [CrossRef]
- Iglesias, F.; Zseby, T. Pattern Discovery in Internet Background Radiation. IEEE Trans. Big Data 2019, 5, 467–480. [Google Scholar] [CrossRef]
- Taylor, V.F.; Spolaor, R.; Conti, M.; Martinovic, I. Robust Smartphone App Identification Via Encrypted Network Traffic Analysis. IEEE Trans. Inf. Forensics Secur. 2017, 13, 63–78. [Google Scholar] [CrossRef] [Green Version]
- Vlăduţu, A.; Comăneci, D.; Dobre, C. Internet traffic classification based on flows’ statistical properties with machine learning. Int. J. Netw. Manag. 2017, 27, e1929. [Google Scholar] [CrossRef]
- Mirsky, Y.; Doitshman, T.; Elocivi, Y.; Shabtai, A. Kitsune: An Ensemble of Autoencoders for Online Network Intrusion Detection. In Proceedings of the Network and Distributed System Security Symposium–NDSS 2018, San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Potluri, S.; Diedrich, C. Accelerated deep neural networks for enhanced Intrusion Detection System. In Proceedings of the IEEE 21st International Conference on Emerging Technologies and Factory Automation (ETFA), Berlin, Germany, 6–9 September 2016; pp. 1–8. [Google Scholar]
- Bhuyan, M.H.; Bhattacharyya, D.; Kalita, J. A multi-step outlier-based anomaly detection approach to network-wide traffic. Inf. Sci. 2016, 348, 243–271. [Google Scholar] [CrossRef]
- Wright, C.; Monrose, F.; Masson, G.M. HMM Profiles for Network Traffic Classification. In Proceedings of the ACM Workshop on Visualization and Data Mining for Computer Security (VizSEC/DMSEC), Washington, DC, USA, 29 October 2004; pp. 9–15. [Google Scholar]
- Vellido, A.; Martín-Guerrero, J.D.; Rossi, F.; Lisboa, P.J.G. Seeing is believing: The importance of visualization in real-world machine learning applications. In Proceedings of the ESANN 19th European Symposium on Artificial Neural Networks, Bruges, Belgium, 27–29 April 2011. [Google Scholar]
- Pang, R.; Yegneswaran, V.; Barford, P.; Paxson, V.; Peterson, L. Characteristics of Internet Background Radiation. In Proceedings of the 4th ACM SIGCOMM Conference on Internet Measurement, Taormina, Sicily, Italy, 25–27 October 2004; pp. 27–40. [Google Scholar]
- Axelsson, S. The Base-Rate Fallacy and Its Implications for the Difficulty of Intrusion Detection. In Proceedings of the 6th ACM Conference on Computer and Communications Security, Singapore, 2–4 November 1999; pp. 1–7. [Google Scholar]
- Claffy, K. The Inevitable Conflict between Data Privacy and Science. 2009. Available online: https://blog.caida.org/best_available_data/2009/01/04/the-inevitable-conflict-between-data-privacy-and-data-utility-revisited/ (accessed on 25 April 2020).
- Kenneally, E.; Claffy, K. Dialing privacy and utility: A proposed data sharing framework to advance Internet research. IEEE Secur. Priv. 2010, 8, 31–39. [Google Scholar] [CrossRef] [Green Version]
- CAIDA. Data—Overview of Datasets, Monitors, and Reports. 2020. Available online: https://www.caida.org/data/overview/ (accessed on 25 April 2020).
- MAWI Working Group. Packet Traces from WIDE Backbone. 2020. Available online: http://mawi.wide.ad.jp/mawi/ (accessed on 25 April 2020).
- Canadian Institute for Cybersecurity. Datasets. 2020. Available online: https://www.unb.ca/cic/datasets/index.html (accessed on 25 April 2020).
- Iglesias, F.; Zseby, T. Analysis of network traffic features for anomaly detection. Mach. Learn. 2015, 101, 59–84. [Google Scholar] [CrossRef] [Green Version]
- Claise, B.; Trammell, B. RFC 7012: Information Model for IP Flow Information Export (IPFIX); Technical Report; Internet Engineering Task Force (IETF): Fremont, CA, USA, 2013. [Google Scholar]
- Meghdouri, F.; Zseby, T.; Iglesias, F. Analysis of Lightweight Feature Vectors for Attack Detection in Network Traffic. Appl. Sci. 2018, 8, 2196. [Google Scholar] [CrossRef] [Green Version]
- Dainotti, A.; Pescape, A.; Claffy, K.C. Issues and future directions in traffic classification. IEEE Netw. 2012, 26, 35–40. [Google Scholar] [CrossRef] [Green Version]
- Sommer, R.; Paxson, V. Outside the Closed World: On Using Machine Learning for Network Intrusion Detection. In Proceedings of the IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 22–25 May 2010; pp. 305–316. [Google Scholar]







© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iglesias, F.; Ferreira, D.C.; Vormayr, G.; Bachl, M.; Zseby, T. NTARC: A Data Model for the Systematic Review of Network Traffic Analysis Research. Appl. Sci. 2020, 10, 4307. https://doi.org/10.3390/app10124307
Iglesias F, Ferreira DC, Vormayr G, Bachl M, Zseby T. NTARC: A Data Model for the Systematic Review of Network Traffic Analysis Research. Applied Sciences. 2020; 10(12):4307. https://doi.org/10.3390/app10124307
Chicago/Turabian StyleIglesias, Félix, Daniel C. Ferreira, Gernot Vormayr, Maximilian Bachl, and Tanja Zseby. 2020. "NTARC: A Data Model for the Systematic Review of Network Traffic Analysis Research" Applied Sciences 10, no. 12: 4307. https://doi.org/10.3390/app10124307
APA StyleIglesias, F., Ferreira, D. C., Vormayr, G., Bachl, M., & Zseby, T. (2020). NTARC: A Data Model for the Systematic Review of Network Traffic Analysis Research. Applied Sciences, 10(12), 4307. https://doi.org/10.3390/app10124307