Towards a Better Understanding of Transfer Learning for Medical Imaging: A Case Study

 ,
,  ,
,  ,
, 
 ,
, 

Abstract
:Featured Application
Abstract
1. Introduction
2. Review of the State-of-the-Art
2.1. CNNs in Image Classification
2.2. Deep Convolutional Neural Networks (DCNNs)
3. Challenges and Research Gap
3.1. Challenges in DFU Classification
- Lack of training data due to costly and time-consuming data collecting and labeling by experts.
- Patient’s ethnicity.
- Low contrast between target objects and background.
- Various image qualities (different capturing devices).
- Heterogeneous and complex shapes.
- Lack of a robust and effective deep learning model to differentiate between DFU classes.
3.2. Research Problem in Transfer Learning
4. Aim and Contribution
4.1. Aim
- To address the issue of lack of training data for DFU classification.
- To test whether the type of images used for TL affects the performance or not.
- To improve the performance of the DFU classification task.
- To employ DCNN in the task of DFU classification.
4.2. Contributions
- A new dataset has been collected which containing 1200 images of feet that have been manually labeled by a DFU expert as normal and abnormal.
- A hybrid deep learning model has been designed that combines traditional and parallel convolutional layers along with residual connections.
- Several training scenarios have been performed with the proposed hybrid model.
- Two pre-trained deep learning models (VGG19, ResNet50) have been trained with target datasets.
- It has been empirically proven that TL from the same domain of the target dataset can significantly improve performance.
- The performance of DFU classification has been improved by attaining F1-score value of 97.6%.
5. Methodology
5.1. Datasets
5.1.1. Target Datasets
5.1.2. Pre-Train Datasets
5.2. Convolutional Neural Networks (CNNs)
5.2.1. Convolutional Layer
5.2.2. Pooling Layers
5.2.3. Batch Normalization
5.2.4. Dropout
5.2.5. Fully Connected Layers
5.2.6. Loss Layers
5.3. Transfer Learning
- The proposed model has trained on transfer learning datasets (Dataset C once then Dataset D) for transfer learning purposes.
- The pre-trained model has been loaded.
- The final layers have been replaced with new layers to learn features specific to the target task.
- The fine-tuned model has trained with the target dataset.
- The model accuracy has been assessed.
- The results have been deployed.
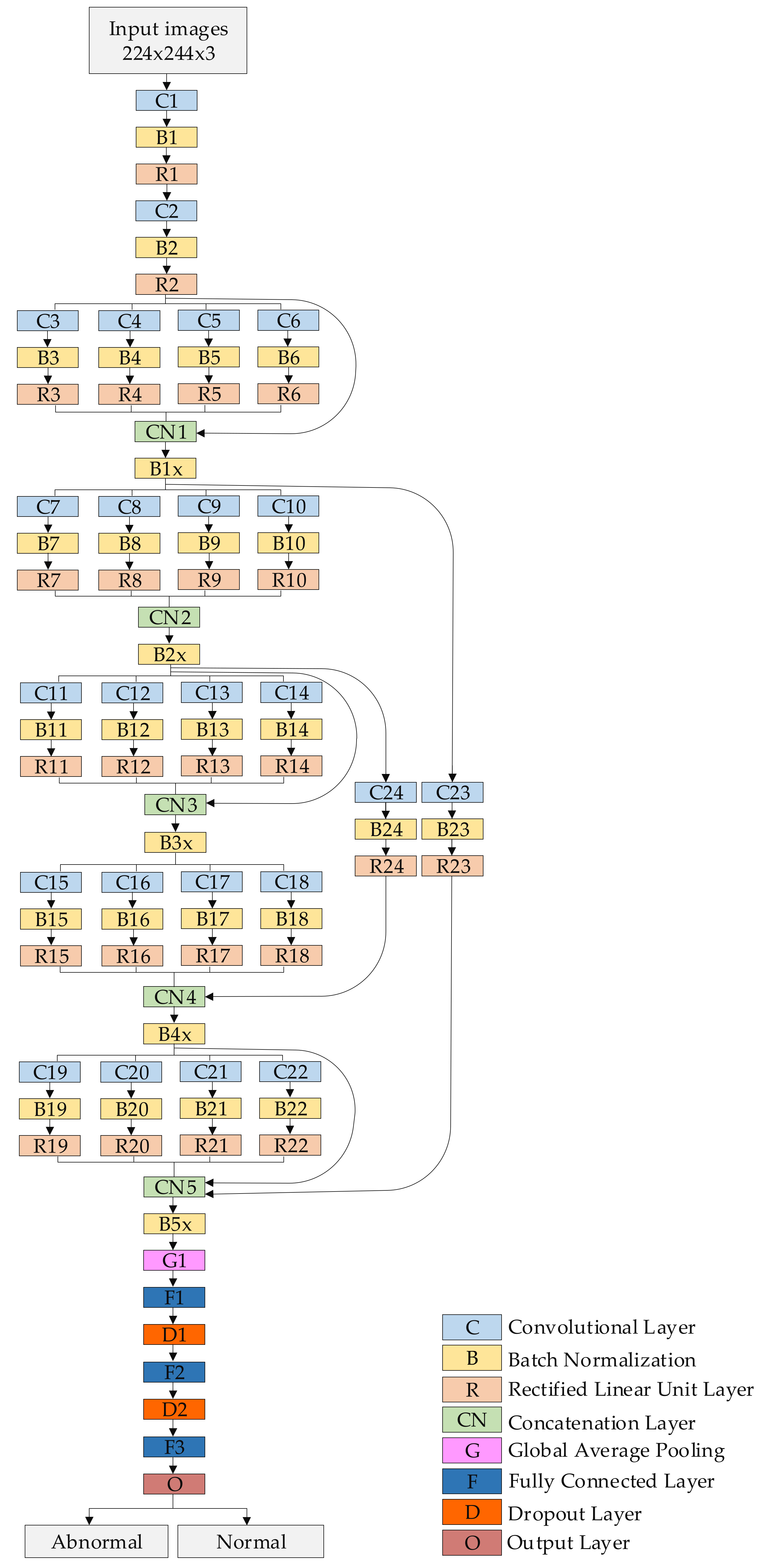
5.4. Proposed Model
5.5. Training Scenarios
- Scenario 1: Training the proposed model from scratch with original images from target datasets.
- Training with Dataset A
- Training with Dataset B
- Scenario 2: Training the proposed model with Dataset C for TL purpose then fine-tuning the model to train it with A and B from Scenario 1.
- Scenario 3: Training the proposed model with Dataset D for TL purpose then fine-tuning the model to train it with A and B from Scenario 1.
- Scenario 4: Fine-tuning two pre-trained state-of-the-art models (VGG19, ResNet50) then training them with A and B from Scenario 1. These two models had previously been trained with the ImageNet dataset containing nature images.
6. Experimental Results
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Shahbazian, H.; Yazdanpanah, L.; Latifi, S.M. Risk assessment of patients with diabetes for foot ulcers according to risk classification consensus of International Working Group on Diabetic Foot (IWGDF). Pak. J. Med. Sci. 2013, 23, 730. [Google Scholar] [CrossRef]
- Ramachandran, A.; Snehalatha, C.; Shetty, A.S.; Nanditha, A. Trends in prevalence of diabetes in Asian countries. World J. Diabetes 2012, 3, 110. [Google Scholar] [CrossRef] [PubMed]
- Shaw, J.E.; Sicree, R.A.; Zimmet, P.Z. Global estimates of the prevalence of diabetes for 2010 and 2030. Diabetes Res. Clin. Pract. 2010, 87, 4–14. [Google Scholar] [CrossRef] [PubMed]
- Whiting, D.R.; Guariguata, L.; Weil, C.; Shaw, J. IDF diabetes atlas: Global estimates of the prevalence of diabetes for 2011 and 2030. Diabetes Res. Clin. Pract. 2011, 94, 311–321. [Google Scholar] [CrossRef]
- Aalaa, M.; Malazy, O.T.; Sanjari, M.; Peimani, M.; Mohajeri-Tehrani, M.R. Nurses’ role in diabetic foot prevention and care; a review. J. Diabetes Metab. Disord. 2012, 11, 24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alavi, A.; Sibbald, R.G.; Mayer, D.; Goodman, L.; Botros, M.; Armstrong, D.G.; Woo, K.; Boeni, T.; Ayello, E.A.; Kirsner, R.S. Diabetic foot ulcers: Part II. Management. J. Am. Acad. Dermatol. 2014, 70, 21.e1–21.e24. [Google Scholar] [CrossRef] [PubMed]
- Cavanagh, P.R.; Lipsky, B.A.; Bradbury, A.W.; Botek, G. Treatment for diabetic foot ulcers. Lancet 2005, 366, 1725–1735. [Google Scholar] [CrossRef]
- Leone, S.; Pascale, R.; Vitale, M.; Esposito, S. Epidemiology of diabetic foot. Infez Med 2012, 20, 8–13. [Google Scholar]
- Richard, J.L.; Schuldiner, S. Epidemiology of diabetic foot problems. Rev. Med. Interne 2008, 29, S222–S230. [Google Scholar] [CrossRef]
- Nather, A.; Bee, C.S.; Huak, C.Y.; Chew, J.L.; Lin, C.B.; Neo, S.; Sim, E.Y. Epidemiology of diabetic foot problems and predictive factors for limb loss. J. Diabetes Complicat. 2008, 22, 77–82. [Google Scholar] [CrossRef]
- Bakri, F.G.; Allan, A.H.; Khader, Y.S.; Younes, N.A.; Ajlouni, K.M. Prevalence of diabetic foot ulcer and its associated risk factors among diabetic patients in Jordan. Jordan Med. J. 2012, 171, 1–16. [Google Scholar]
- Iraj, B.; Khorvash, F.; Ebneshahidi, A.; Askari, G. Prevention of diabetic foot ulcer. Int. J. Prev. Med. 2013, 4, 373. [Google Scholar] [PubMed]
- Fard, A.S.; Esmaelzadeh, M.; Larijani, B. Assessment and treatment of diabetic foot ulcer. Int. J. Clin. Pract. 2007, 61, 1931–1938. [Google Scholar] [CrossRef] [PubMed]
- Snyder, R.J.; Hanft, J.R. Diabetic foot ulcers—Effects on quality of life, costs, and mortality and the role of standard wound care and advanced-care therapies in healing: A review. Ostomy/Wound Manag. 2009, 55, 28–38. [Google Scholar]
- Liu, C.; van Netten, J.J.; Van Baal, J.G.; Bus, S.A.; van Der Heijden, F. Automatic detection of diabetic foot complications with infrared thermography by asymmetric analysis. J. Biomed. Opt. 2015, 20, 026003. [Google Scholar] [CrossRef] [Green Version]
- Van Netten, J.J.; Prijs, M.; van Baal, J.G.; Liu, C.; van Der Heijden, F.; Bus, S.A. Diagnostic values for skin temperature assessment to detect diabetes-related foot complications. Diabetes Technol. Ther. 2014, 16, 714–721. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Pedersen, P.C.; Agu, E.; Strong, D.M.; Tulu, B. Area determination of diabetic foot ulcer images using a cascaded two-stage SVM-based classification. IEEE Trans. Biomed. Eng. 2016, 64, 2098–2109. [Google Scholar] [CrossRef]
- Goyal, M.; Yap, M.H.; Reeves, N.D.; Rajbhandari, S.; Spragg, J. Fully convolutional networks for diabetic foot ulcer segmentation. In Proceedings of the International Conference on Systems, Man, and Cybernetics (SMC), Banff, AB, Canada, 5–8 October 2017; pp. 618–623. [Google Scholar]
- Wannous, H.; Lucas, Y.; Treuillet, S. Enhanced assessment of the wound-healing process by accurate multiview tissue classification. IEEE Trans. Med. Imaging 2010, 30, 315–326. [Google Scholar] [CrossRef] [Green Version]
- Kolesnik, M.; Fexa, A. Multi-dimensional color histograms for segmentation of wounds in images. In Proceedings of the International Conference Image Analysis and Recognition, Toronto, ON, Canada, 28–30 September 2005; Springer: Berlin/Heidelberg, Germany; pp. 1014–1022. [Google Scholar]
- Kolesnik, M.; Fexa, A. How robust is the SVM wound segmentation? In Proceedings of the 7th Nordic Signal Processing Symposium-NORSIG, Reykjavik, Iceland, 7–9 June 2006; pp. 50–53. [Google Scholar]
- Veredas, F.; Mesa, H.; Morente, L. Binary tissue classification on wound images with neural networks and bayesian classifiers. IEEE Trans. Med. Imaging 2010, 29, 410–427. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Bajwa, M.N.; Muta, K.; Malik, M.I.; Siddiqui, S.A.; Braun, S.A.; Homey, B.; Dengel, A.; Ahmed, S. Computer-aided diagnosis of skin diseases using deep neural networks. Appl. Sci. 2020, 10, 2488. [Google Scholar] [CrossRef] [Green Version]
- Alzubaidi, L.; Fadhel, M.A.; Al-Shamma, O.; Zhang, J.; Duan, Y. Deep learning models for classification of red blood cells in microscopy images to aid in sickle cell anemia diagnosis. Electronics 2020, 9, 427. [Google Scholar] [CrossRef] [Green Version]
- Luján-García, J.E.; Yáñez-Márquez, C.; Villuendas-Rey, Y.; Camacho-Nieto, O. A transfer learning method for pneumonia classification and visualization. Appl. Sci. 2020, 10, 2908. [Google Scholar] [CrossRef] [Green Version]
- Alzubaidi, L.; Al-Shamma, O.; Fadhel, M.A.; Zhang, J.; Duan, Y. Optimizing the performance of breast cancer classification by employing the same domain transfer learning from hybrid deep convolutional neural network model. Electronics 2020, 9, 445. [Google Scholar] [CrossRef] [Green Version]
- Goyal, M.; Reeves, N.D.; Davison, A.K.; Rajbhandari, S.; Spragg, J.; Yap, M.H. DFUNET: Convolutional neural networks for diabetic foot ulcer classification. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Alzubaidi, L.; Fadhel, M.A.; Oleiwi, S.R.; Al-Shamma, O.; Zhang, J. DFU_QUTNet: Diabetic foot ulcer classification using novel deep convolutional neural network. Multimed. Tools Appl. 2020, 79, 15655–15677. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Wang, J.; Yang, J.; Yu, K.; Lv, F.; Huang, T.; Gong, Y. Locality-constrained linear coding for image classification. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3360–3367. [Google Scholar]
- Rasheed, N.; Khan, S.A.; Khalid, A. Tracking and abnormal behavior detection in video surveillance using optical flow and neural networks. In Proceedings of the 28th International Conference on Advanced Information Networking and Applications Workshops, Victoria, BC, Canada, 13–16 May 2014; pp. 61–66. [Google Scholar]
- Geiger, A.; Lauer, M.; Wojek, C.; Stiller, C.; Urtasun, R. 3D traffic scene understanding from movable platforms. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1012–1025. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Lim, J.; Yang, M.-H. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Weinberger, K.; Saul, L. Distance metric learning for large margin nearest neighbor classification. J. Mach. Learn. Res. 2009, 10, 207–244. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Fung, G.; Mangasarian, O.L.; Shavlik, J. Knowledge-based support vector machine classifiers. In The Neural Information Processing Systems Foundation (NIPS 2002); MIT Press: Cambridge, MA, USA, 2002; pp. 521–528. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. In Proceedings of the International Conference on Learning Representations Workshop, Banff, AB, Canada, 14–16 April 2014; pp. 1–8. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Bengio, Y. Learning deep architectures for AI. Found. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Cireşan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3642–3649. [Google Scholar]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Guo, J.; Zhang, S.; Li, J. Hash learning with convolutional neural networks for semantic based image retrieval. In Proceedings of the Pacific-Asia Conference Knowledge Discovery Data Mining, Auckland, New Zealand, 19–22 April 2016; pp. 227–238. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-based convolutional networks for accurate object detection and semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Koziarski, M.; Cyganek, B. Image recognition with deep neural networks in presence of noise—Dealing with and taking advantage of distortions. Integr. Comput. Aided Eng. 2017, 24, 337–349. [Google Scholar] [CrossRef]
- Shang, W.; Sohn, K.; Almeida, D.; Lee, H. Understanding and improving convolutional neural networks via concatenated rectified linear units. In Proceedings of the 33rd International Conference on International Conference on Machine Learning (ICML), New York, NY, USA, 19–24 June 2016; pp. 3276–3284. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Lv, E.; Wang, X.; Cheng, Y.; Yu, Q. Deep convolutional network based on pyramid architecture. IEEE Access 2018, 6, 43125–43135. [Google Scholar] [CrossRef]
- Targ, S.; Almeida, D.; Lyman, K. ResNet in ResNet: Generalizing residual architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Veit, A.; Wilber, M.J.; Belongie, S. Residual networks behave like ensembles of relatively shallow networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 550–558. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4 Inception-ResNet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Larsson, G.; Maire, M.; Shakhnarovich, G. FractalNet: Ultra-Deep Neural Networks Without Residuals. arXiv 2016, arXiv:1605.07648. [Google Scholar]
- Zhao, L.; Wang, J.; Li, X.; Tu, Z.; Zeng, W. On the connection of deep fusion to ensembling. arXiv 2016, arXiv:1611.07718. [Google Scholar]
- Wang, J.; Wei, Z.; Zhang, T.; Zeng, W. Deeply-fused nets. arXiv 2016, arXiv:1605.07716. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Shin, H.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A survey on deep transfer learning. In Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; Springer: Cham, Switzerland; pp. 270–279. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Cook, D.; Feuz, K.D.; Krishnan, N.C. Transfer learning for activity recognition: A survey. Knowl. Inf. Syst. 2013, 36, 537–556. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cao, X.; Wang, Z.; Yan, P.; Li, X. Transfer learning for pedestrian detection. Neurocomputing 2013, 100, 51–57. [Google Scholar] [CrossRef]
- Raghu, M.; Zhang, C.; Kleinberg, J.; Bengio, S. Transfusion: Understanding transfer learning for medical imaging. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 3342–3352. [Google Scholar]
- Animals. Available online: https://www.kaggle.com/alessiocorrado99/animals10#translate.py (accessed on 15 January 2020).
- Wounds. Available online: https://github.com/produvia/deep-learning-for-wound-care. (accessed on 15 January 2020).
- Clinical Skin Disease. Available online: https://medicine.uiowa.edu/dermatology/education/clinical-skin-disease-images (accessed on 15 January 2020).
- Codella, N.; Rotemberg, V.; Tschandl, P.; Celebi, M.E.; Dusza, S.; Gutman, D.; Helba, B.; Kalloo, A.; Liopyris, K.; Marchetti, M.; et al. A Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (ISIC). arXiv 2019, arXiv:1902.03368. [Google Scholar]
- Combalia, M.; Codella, N.C.; Rotemberg, V.; Helba, B.; Vilaplana, V.; Reiter, O.; Carrera, C.; Barreiro, A.; Halpern, A.C.; Puig, S.; et al. BCN20000: Dermoscopic lesions in the wild. arXiv 2019, arXiv:1908.02288. [Google Scholar]
- Animals1. Available online: https://www.kaggle.com/nafisur/dogs-vs-cats (accessed on 22 January 2020).
- Animals2. Available online: https://www.kaggle.com/gpiosenka/100-bird-species (accessed on 22 January 2020).
- Animals3. Available online: https://www.kaggle.com/navneetsurana/animaldataset (accessed on 22 January 2020).
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name of Layer | Filter Size (FS) and Stride (S) | Activations |
|---|---|---|
| Input layer | - | 224 × 224 × 3 |
| C1, B1, R1 | FS = 3 × 3, S = 1 | 224 × 224 × 16 |
| C2, B2, R2 | FS = 5 × 5, S = 2 | 112 × 112 × 16 |
| C3, B3, R3 | FS = 1 × 1, S = 1 | 112 × 112 × 16 |
| C4, B4, R4 | FS = 3 × 3, S = 1 | 112 × 112 × 16 |
| C5, B5, R5 | FS = 5 × 5, S = 1 | 112 × 112 × 16 |
| C6, B6, R6 | FS = 7 × 7, S = 1 | 112 × 112 × 16 |
| CN1 | Five inputs | 112 × 112 × 80 |
| B1x | Batch Normalization Layer | 112 × 112 × 80 |
| C7, B7, R7 | FS = 1 × 1, S = 2 | 56 × 56 × 32 |
| C8, B8, R8 | FS = 3 × 3, S = 2 | 56 × 56 × 32 |
| C9, B9, R9 | FS = 5 × 5, S = 2 | 56 × 56 × 32 |
| C10, B10, R10 | FS = 7 × 7, S = 2 | 56 × 56 × 32 |
| CN2 | Four inputs | 56 × 56 × 128 |
| B2x | Batch Normalization Layer | 56 × 56 × 128 |
| C11, B11, R11 | FS = 1 × 1, S = 1 | 56 × 56 × 32 |
| C12, B12, R12 | FS = 3 × 3, S = 1 | 56 × 56 × 32 |
| C13, B13, R13 | FS = 5 × 5, S = 1 | 56 × 56 × 32 |
| C14, B14, R14 | FS = 7 × 7, S = 1 | 56 × 56 × 32 |
| CN3 | Five inputs | 56 × 56 × 256 |
| B3x | Batch Normalization Layer | 56 × 56 × 256 |
| C15, B15, R15 | FS = 1 × 1, S = 2 | 28 × 28 × 64 |
| C16, B16, R16 | FS = 3 × 3, S = 2 | 28 × 28 × 64 |
| C17, B17, R17 | FS = 5 × 5, S = 2 | 28 × 28 × 64 |
| C18, B18, R18 | FS = 7 × 7, S = 2 | 28 × 28 × 64 |
| CN4 | Five inputs | 28 × 28 × 272 |
| B4x | Batch Normalization Layer | 28 × 28 × 272 |
| C19, B19, R19 | FS = 1 × 1, S = 1 | 28 × 28 × 128 |
| C20, B20, R20 | FS = 3 × 3, S = 1 | 28 × 28 × 128 |
| C21, B21, R21 | FS = 5 × 5, S = 1 | 28 × 28 × 128 |
| C22, B22, R22 | FS = 7 × 7, S = 1 | 28 × 28 × 128 |
| CN5 | Six inputs | 28 × 28 × 800 |
| B5x | Batch Normalization Layer | 28 × 28 × 800 |
| C23, B23, R23 | FS = 5 × 5, S = 4 | 28 × 28 × 16 |
| C24, B24, R24 | FS = 3 × 3, S = 2 | 28 × 28 × 16 |
| G1 | - | 1 × 1 × 800 |
| F1 | 400 FC | 1 × 1 × 400 |
| D1 | Dropout layer with learning rate:0.5 | 1 × 1 × 400 |
| F2 | 200 FC | 1 × 1 × 200 |
| D2 | Dropout layer with learning rate:0.5 | 1 × 1 × 200 |
| F3 | 2 FC | 1 × 1 × 2 |
| O (Softmax function) | Normal, Abnormal | 1 × 1 × 2 |
| Target Dataset | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|
| Dataset A | 84.8 | 88.6 | 86.6 |
| Dataset B | 82.9 | 87.5 | 85.1 |
| Target Dataset | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|
| Dataset A | 96.8 | 98.6 | 97.6 |
| Dataset B | 81.8 | 86.7 | 84.1 |
| Target Dataset | Precision (%) | Recall (%) | F1- score (%) |
|---|---|---|---|
| Dataset A | 86.5 | 92.7 | 89.4 |
| Dataset B | 91.6 | 96.9 | 94.1 |
| Models | Target Dataset | Precision (%) | Recall (%) | F1- score (%) |
|---|---|---|---|---|
| VGG19 | Dataset A | 86.4 | 90.5 | 88.4 |
| Dataset B | 89.3 | 95.2 | 92.1 | |
| ResNet50 | Dataset A | 88.2 | 93.1 | 90.5 |
| Dataset B | 93.7 | 98.9 | 96.2 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alzubaidi, L.; Fadhel, M.A.; Al-Shamma, O.; Zhang, J.; Santamaría, J.; Duan, Y.; R. Oleiwi, S. Towards a Better Understanding of Transfer Learning for Medical Imaging: A Case Study. Appl. Sci. 2020, 10, 4523. https://doi.org/10.3390/app10134523
Alzubaidi L, Fadhel MA, Al-Shamma O, Zhang J, Santamaría J, Duan Y, R. Oleiwi S. Towards a Better Understanding of Transfer Learning for Medical Imaging: A Case Study. Applied Sciences. 2020; 10(13):4523. https://doi.org/10.3390/app10134523
Chicago/Turabian StyleAlzubaidi, Laith, Mohammed A. Fadhel, Omran Al-Shamma, Jinglan Zhang, J. Santamaría, Ye Duan, and Sameer R. Oleiwi. 2020. "Towards a Better Understanding of Transfer Learning for Medical Imaging: A Case Study" Applied Sciences 10, no. 13: 4523. https://doi.org/10.3390/app10134523
APA StyleAlzubaidi, L., Fadhel, M. A., Al-Shamma, O., Zhang, J., Santamaría, J., Duan, Y., & R. Oleiwi, S. (2020). Towards a Better Understanding of Transfer Learning for Medical Imaging: A Case Study. Applied Sciences, 10(13), 4523. https://doi.org/10.3390/app10134523