A Bayesian Neo-Normal Mixture Model (Nenomimo) for MRI-Based Brain Tumor Segmentation

 ,
,  ,
,
Abstract
:1. Introduction
2. Neo-Normal Mixture Model
2.1. Finite Mixture Model
2.2. Neo-Normal Distribution
3. Bayesian Coupled with Markov Chain Monte Carlo Approach
3.1. Bayesian Approach for FSSN Mixture Model
- (a)
- The full conditional posterior for the location parameter , is given by:
- (b)
- The full conditional posterior for parameter , is given by Equation (10):
- (c)
- Equation (11) shows the full conditional posterior for parameter , :
- (d)
- Equation (12) shows the full conditional posterior distribution parameter , :This is a Dirichlet distribution.
- (e)
- The label , and , only has two possible values, i.e., 0 or 1. For each , there are possible mixture components, so follows the multinomial distribution where:
| Algorithm 1: Gibbs sampling for the Fernandez–Steel skew normal-mixture model (FSSN-MM) |
|
3.2. Bayesian Approach for MSNBurr Mixture Model
- (a)
- The full conditional posterior for , is shown in Equation(14):
- (b)
- The following Equation (15) shows the full conditional posterior for , :
- (c)
- The full conditional posterior of , is given bellow:
- (d)
- The full conditional posterior for , is as shown in Equation (12).
- (e)
- The full conditional posterior of the label follows the multinomial distribution, where , as in Equation (13).
| Algorithm 2: Gibbs sampling for the modified stable to normal from Burr-mixture model (MSNBurr-MM). |
|
4. Cluster Validation and Comparison Tools
5. Result and Discussion
5.1. Application for Data Simulation
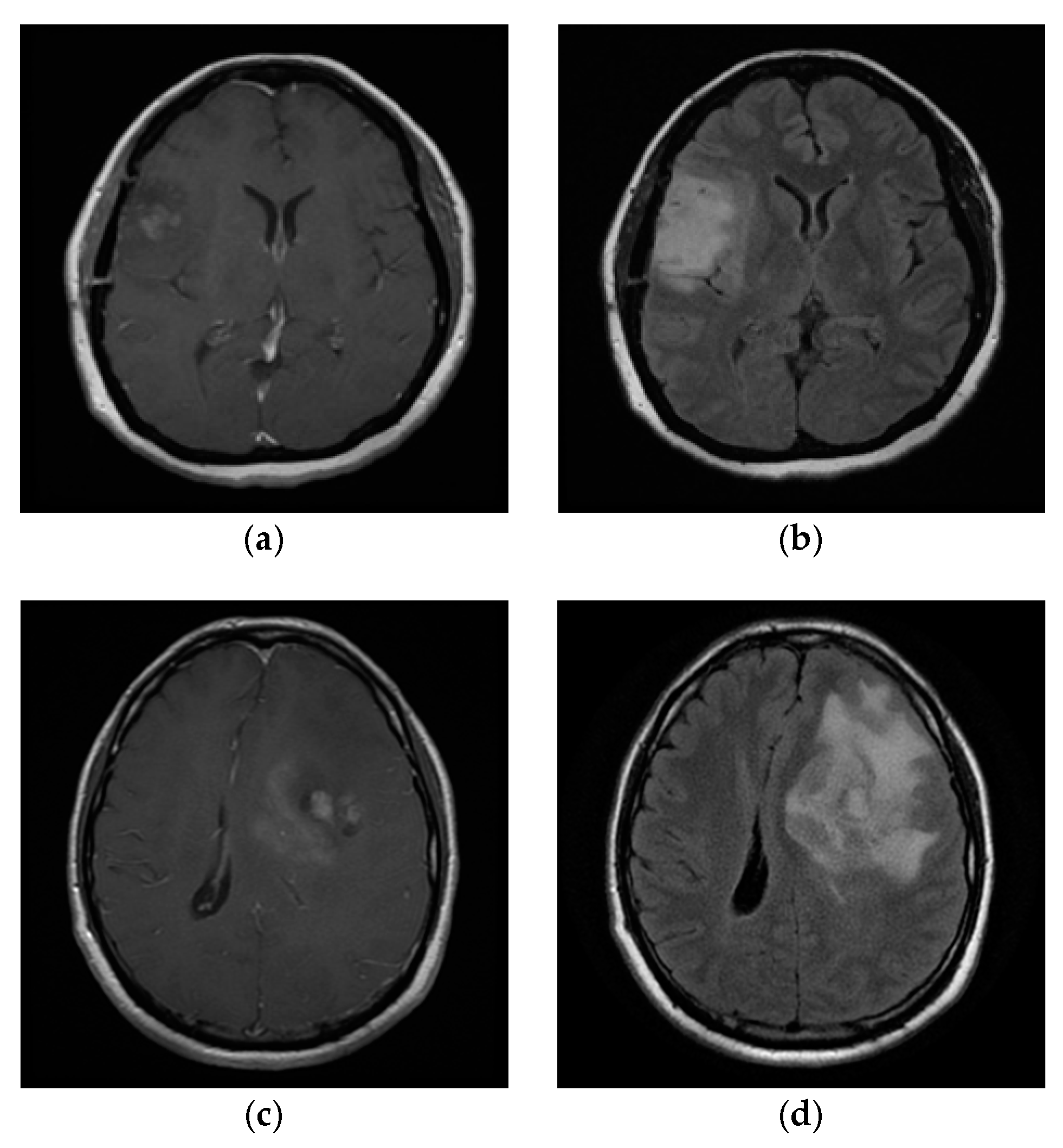
5.2. Application for MRI-Based Brain Tumor
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Joint Posterior Density for Nenomimo
- (a)
- The prior density for is:where and are the mean and variance from the data, respectively; and .
- (b)
- The prior density for is given by:
- (c)
- The prior density for is:where , , , and
- (d)
- Prior density for .Assume that , with ; then, we can get the prior density as:where the normalized constant is a multinomial beta function that could be expressed as the following gamma function:
Appendix B. Some Direction for the Derivation of Full Conditional Posterior
References
- Global Cancer Observatory. Available online: http://gco.iarc.fr/today/data/factsheets/populations/360-indonesia-fact-sheets.pdf (accessed on 16 April 2020).
- Grün, B. Model-based Clustering. Model-based Clsutering. In Handbook of Mixture Analysis; CRC Press: Boca Raton, FL, USA, 2018; pp. 163–198. [Google Scholar]
- Bruse, J.L.; Zuluaga, M.A.; Khushnood, A.; McLeod, K.; Ntsinjana, H.N.; Hsia, T.; Sermesant, M.; Pennec, X.; Taylor, A.M.; Schievano, S. Detecting Clinically Meaningful Shape Clusters in Medical Image Data: Metrics Analysis for Hierarchical Clustering Applied to Healthy and Pathological Aortic Arches. IEEE Trans. Biomed. Eng. 2017, 64, 2373–2383. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pestunov, I.A.; Rylov, S.A.; Berikov, V.B. Hierarchical Clustering Algorithms for Segmentation of Multispectral Images. Optoelectron. Instrum. Data Process. 2015, 51, 329–338. [Google Scholar] [CrossRef]
- Rohith, J.; Ramesh, H. Colour Based Segmentation of a Landsat Image Using K-Means Clustering Algorithm. J. Imag. Process. Pattern Recogn. Progress 2017, 4, 31–38. [Google Scholar]
- Muruganandham, S.K.; Sobya, D.; Nallusamy, S.; Mandal, D.K.; Chakraborty, P.S. Study on Leaf Segmentation using K-Means and K-Medoid Clustering Algorithm for Identification of Disease. Indian J. Public Health Res. Dev. 2018, 9, 289–293. [Google Scholar] [CrossRef]
- Huang, H.; Meng, F.; Zhou, S.; Jiang, F.; Manogaran, G. Brain Image Segmentation based on FCM Clustering Algorithm and Rough Set. IEEE Access 2019, 7, 12386–12396. [Google Scholar] [CrossRef]
- Oh, M.S.; Raftery, A.E. Model-Based Clustering with Dissimilarities: A Bayesian Approach. J. Comput. Graph. Stat. 2007, 16, 559–585. [Google Scholar] [CrossRef] [Green Version]
- Greve, B.; Pigeot, I.; Huybrechts, I.; Pala, V.; Börnhorst, C.A. Comparison of Heuristic and Model-based Clustering Methods for Dietary Pattern Analysis. Public Health Nutr. 2016, 19, 255–264. [Google Scholar] [CrossRef] [PubMed]
- Rasmussen, C.E. The Infinite Gaussian mixture model. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2000; pp. 554–560. [Google Scholar]
- Ji, Z.; Huang, Y.; Sun, Q.; Cao, G.A. Spatially Constrained Generative Asymmetric Gaussian mixture model for Image Segmentation. J. Vis. Commun. Image Represent. 2016, 40, 600–626. [Google Scholar] [CrossRef]
- Zhu, H.; Pan, S.; Xie, Q. Image Segmentation by Student’s-t Mixture Models Based on Markov Random Field and Weighted Mean Template. Int. J. Signal. Process. Imag. Process. Pattern Recogn. 2016, 9, 313–322. [Google Scholar]
- Franczak, B.C.; Browne, P.; McNicholas, P. Mixtures of Shifted Asymmetric Laplace Distribution. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1149–1157. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deledalle, C.A.; Parameswaran, S.; Nguyen, T.Q. Image denoising with generalized Gaussian mixture model patch priors. SIAM J. Imag. Sci. 2018, 11, 2568–2609. [Google Scholar] [CrossRef] [Green Version]
- Fernandez, C.; Steel, M.F.J. On Bayesian Modelling of Fat Tails and Skewness. J. Am. Stat. Assoc. 1998, 93, 359–371. [Google Scholar] [CrossRef] [Green Version]
- Iriawan, N. Computationally Intensive Approaches to Inference in Neo-Normal Linear Models. Ph.D. Thesis, Curtin University of Technology, Perth, Australia, 2000. [Google Scholar]
- Iriawan, N.; Pravitasari, A.A.; Fithriasari, K.; Irhamah; Purnami, S.W.; Ferriastuti, W. Comparative Study of Brain Tumor Segmentation using Different Segmentation Techniques in Handling Noise. In Proceedings of the 2018 International Conference on Computer Engineering, Network and Intelligent Multimedia (CENIM), Surabaya, Indonesia, 26–27 November 2018; IEEE: Surabaya, Indonesia, 2018; pp. 289–293. [Google Scholar]
- Choir, A.S.; Iriawan, N.; Ulama, B.; Dokhi, M. MSEpBurr Distribution: Properties and Parameter Estimation. Pakistan J. Stat. Oper. Res. 2019, 15, 179–193. [Google Scholar] [CrossRef]
- Box, G.P.E.; Tiao, G.C. Bayesian Inference in Statistical Analysis, 1st ed.; Addison Wesley Publishing Company: Reading, UK, 1973. [Google Scholar]
- Azzalini, A.A. Class of Distribution which Includes the Normal Ones. Scand. J. Stat. 1985, 12, 171–178. [Google Scholar]
- Anderson, E.; Nguyen, H. When can we improve on sample average approximation for stochastic optimization? Oper. Res. Lett. 2020, 48, 566–572. [Google Scholar] [CrossRef]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Dunson, D.B.; Vehtari, A.; Rubin, D.B. Bayesian Data Analysis, 3rd ed.; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Prasetyo, R.B.; Kuswanto, H.; Iriawan, N.; Ulama, B.S.S. Binomial Regression Models with a Flexible Generalized Logit Link Function. Symmetry 2020, 12, 221. [Google Scholar] [CrossRef] [Green Version]
- Pravitasari, A.A.; Iriawan, N.; Safa, M.A.I.; Irhamah; Fithriasari, K.; Purnami, S.W.; Ferriastuti, W. MRI-Based Brain Tumor Segmentation using Modified Stable Student’s t from Burr Mixture Model with Bayesian Approach. Malays. J. Math. Sci. 2019, 13, 297–310. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Dataset | Number of Clusters (K) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 3 | 4 | 5 | 6 | 7 | 8 | 9 | |||
| Normal | GMM | IM01 | 0.5498 | 0.3488 | 0.539 | 0.4553 | 0.6949 * | 0.6936 | 0.654 |
| IM02 | 0.904 | 0.9133 * | 0.748 | 0.6909 | 0.758 | 0.795 | 0.748 | ||
| IM03 | 0.7924 | 0.803 | 0.8356 * | 0.8034 | 0.7654 | 0.7497 | 0.7138 | ||
| IM04 | 0.8875 | 0.9275 * | 0.8764 | 0.8759 | 0.8437 | 0.7868 | 0.7745 | ||
| GGMM | IM01 | 0.8021 | 0.8263 * | 0.7412 | 0.7406 | 0.6824 | 0.6211 | 0.5488 | |
| IM02 | 0.7682 | 0.8487 | 0.8935 * | 0.8204 | 0.7581 | 0.6328 | 0.7004 | ||
| IM03 | 0.9002 * | 0.8955 | 0.7324 | 0.7101 | 0.6048 | 0.5545 | 0.6266 | ||
| IM04 | 0.8333 | 0.8859 * | 0.8479 | 0.8022 | 0.7643 | 0.7614 | 0.7321 | ||
| Neo-Normal | FSSN-MM | IM01 | 0.8725 * | 0.6412 | 0.6752 | 0.6351 | 0.5897 | 0.6325 | 0.6606 |
| IM02 | 0.8109 | 0.8636 * | 0.8464 | 0.812 | 0.8467 | 0.7929 | 0.8292 | ||
| IM03 | 0.9145 * | 0.8014 | 0.7512 | 0.7049 | 0.6854 | 0.7046 | 0.6699 | ||
| IM04 | 0.8347 | 0.9010 * | 0.9009 | 0.8794 | 0.8695 | 0.8529 | 0.7558 | ||
| MSNBurr-MM | IM01 | 0.9300 * | 0.8349 | 0.7412 | 0.7218 | 0.714 | 0.7331 | 0.7435 | |
| IM02 | 0.8428 | 0.9119 * | 0.9106 | 0.7729 | 0.7322 | 0.6731 | 0.7091 | ||
| IM03 | 0.9157 * | 0.8014 | 0.7491 | 0.7072 | 0.6938 | 0.6931 | 0.6912 | ||
| IM04 | 0.8364 | 0.9230 * | 0.8647 | 0.8009 | 0.801 | 0.7647 | 0.7577 | ||
| Sample Image | FSSN-MM | MSNBurr-MM | |||||||
|---|---|---|---|---|---|---|---|---|---|
| IM01 | 1 | 0.084 | 1.569 | 4.856 | 26.468 | 0.076 | 1.575 | 3.774 | 14.024 |
| 2 | 0.862 | 89.569 | 7.992 | 0.904 | 0.861 | 87.891 | 6.678 | 0.864 | |
| 3 | 0.054 | 165.001 | 6.719 | 3.566 | 0.063 | 163.257 | 7.138 | 2.555 | |
| IM02 | 1 | 0.163 | 2.684 | 4.777 | 4.625 | 0.186 | 2.887 | 4.576 | 4.128 |
| 2 | 0.487 | 113.521 | 7.562 | 11.061 | 0.501 | 112.372 | 5.123 | 10.784 | |
| 3 | 0.196 | 158.01 | 5.324 | 7.225 | 0.196 | 154.753 | 4.852 | 8.211 | |
| 4 | 0.154 | 197.731 | 7.789 | 0.916 | 0.117 | 198.262 | 5.476 | 0.913 | |
| IM03 | 1 | 0.079 | 0.379 | 2.149 | 10.251 | 0.074 | 0.375 | 2.14 | 9.321 |
| 2 | 0.813 | 103.168 | 6.611 | 1.083 | 0.839 | 103.194 | 6.62 | 0.992 | |
| 3 | 0.108 | 197.113 | 7.708 | 13.934 | 0.087 | 197.263 | 7.685 | 18.858 | |
| IM04 | 1 | 0.054 | 0.475 | 2.379 | 17.343 | 0.069 | 0.445 | 3.469 | 16.321 |
| 2 | 0.665 | 96.015 | 5.555 | 7.236 | 0.564 | 122.981 | 6.278 | 5.048 | |
| 3 | 0.136 | 125.176 | 5.355 | 6.725 | 0.245 | 161.062 | 3.283 | 4.769 | |
| 4 | 0.145 | 200.36 | 7.18 | 12.089 | 0.122 | 199.908 | 4.476 | 8.866 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pravitasari, A.A.; Iriawan, N.; Fithriasari, K.; Purnami, S.W.; Irhamah; Ferriastuti, W. A Bayesian Neo-Normal Mixture Model (Nenomimo) for MRI-Based Brain Tumor Segmentation. Appl. Sci. 2020, 10, 4892. https://doi.org/10.3390/app10144892
Pravitasari AA, Iriawan N, Fithriasari K, Purnami SW, Irhamah, Ferriastuti W. A Bayesian Neo-Normal Mixture Model (Nenomimo) for MRI-Based Brain Tumor Segmentation. Applied Sciences. 2020; 10(14):4892. https://doi.org/10.3390/app10144892
Chicago/Turabian StylePravitasari, Anindya Apriliyanti, Nur Iriawan, Kartika Fithriasari, Santi Wulan Purnami, Irhamah, and Widiana Ferriastuti. 2020. "A Bayesian Neo-Normal Mixture Model (Nenomimo) for MRI-Based Brain Tumor Segmentation" Applied Sciences 10, no. 14: 4892. https://doi.org/10.3390/app10144892