Cognitive Aspects-Based Short Text Representation with Named Entity, Concept and Knowledge


Abstract
:1. Introduction
- We propose a novel multi-level model to learn the short text representation from different aspects respectively. To capture more semantic information, We use the named entity-based approach to obtain the external knowledge information—entity, concept, and knowledge graph. Such external knowledge information is utilized to enrich the short text semantic representation.
- To capture the category-related informative representation in terms of multi-level features, we build a joint model by using CNN-based Attention network to capture their respective attentive representations, and then the embeddings learned from different aspects are concatenated for the short text representation.
- We conduct extensive experiments on three datasets for short text classification. The results show that our model outperforms the state-of-the-art methods.
2. Related Work
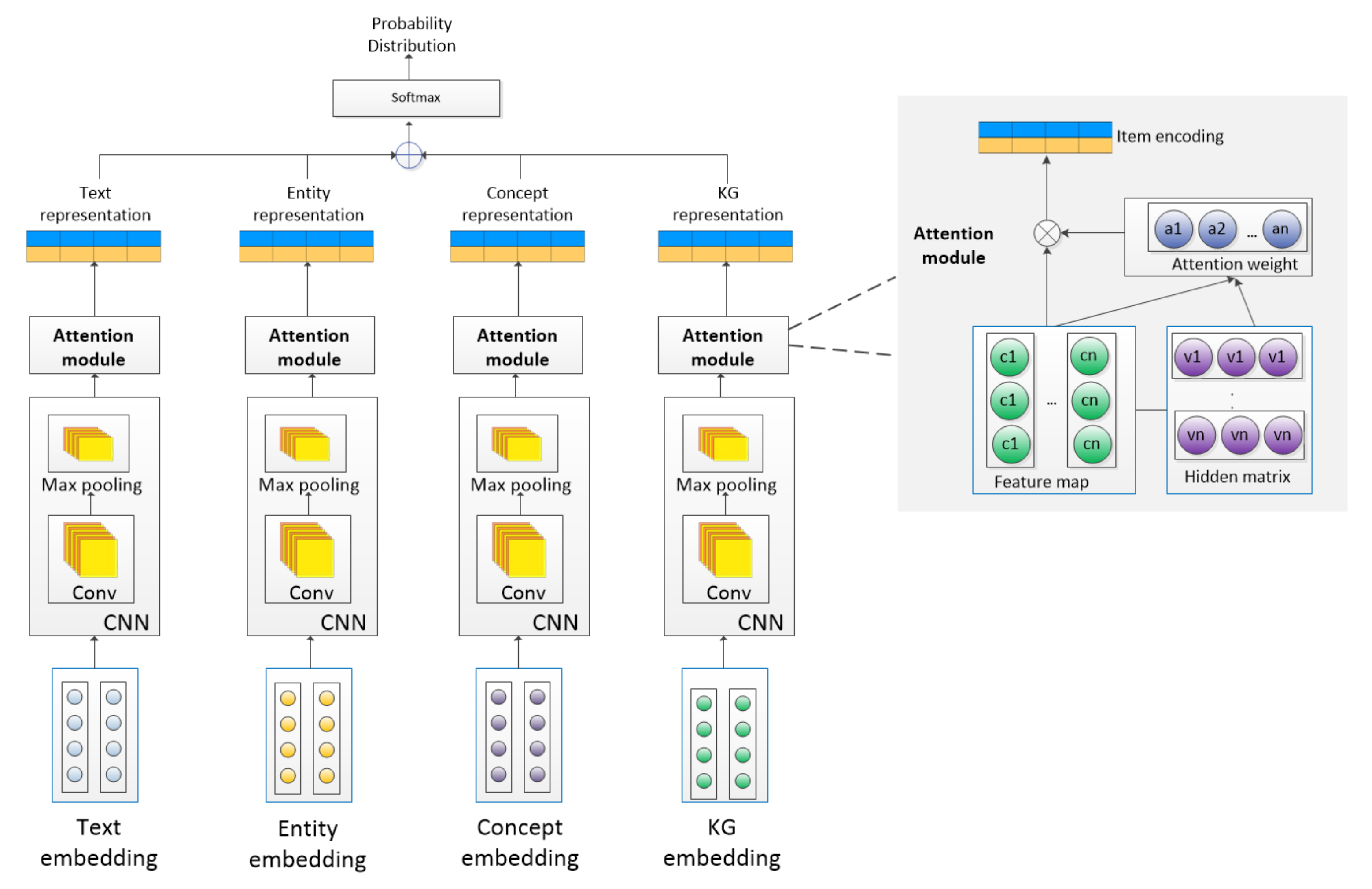
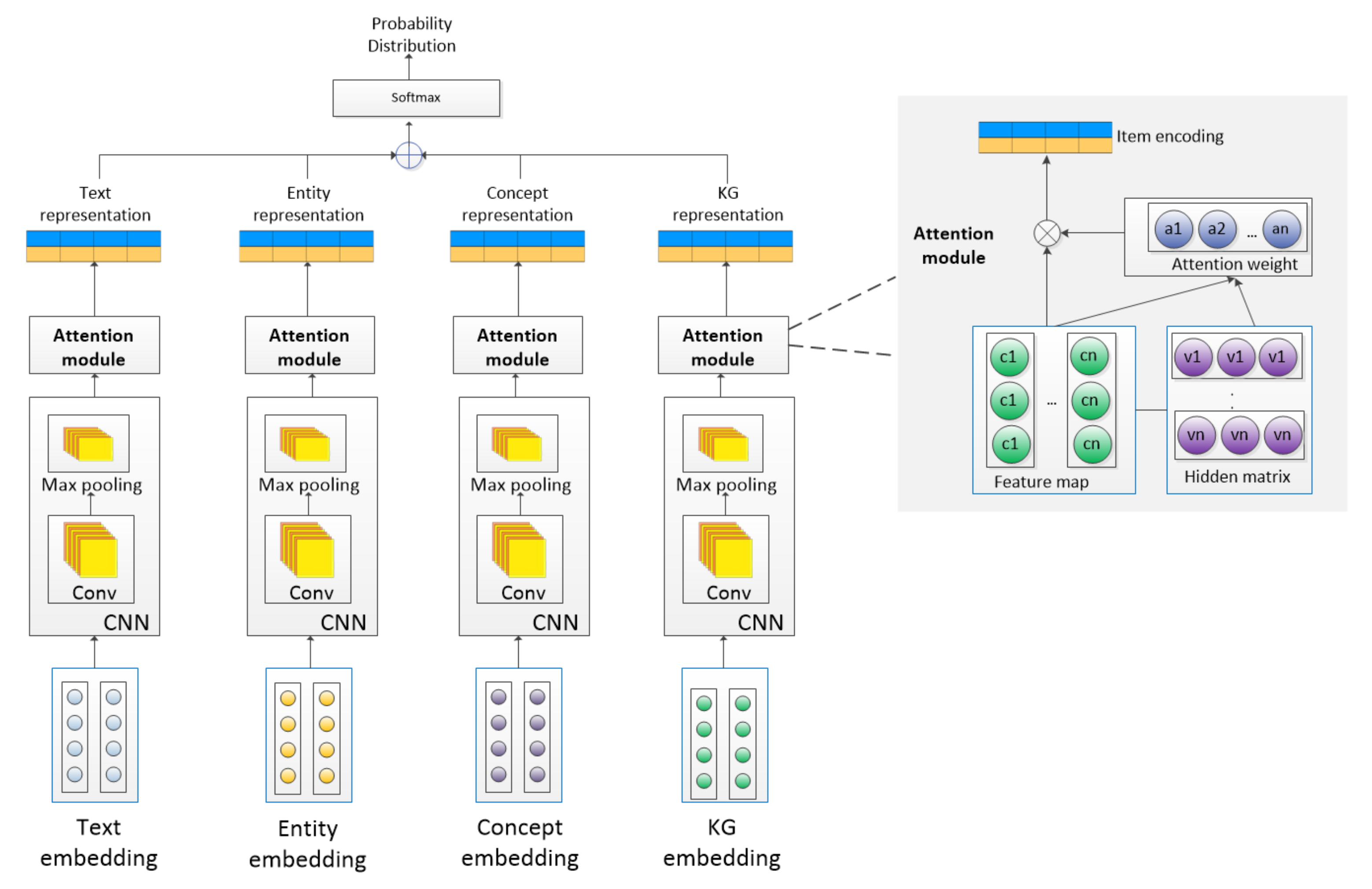
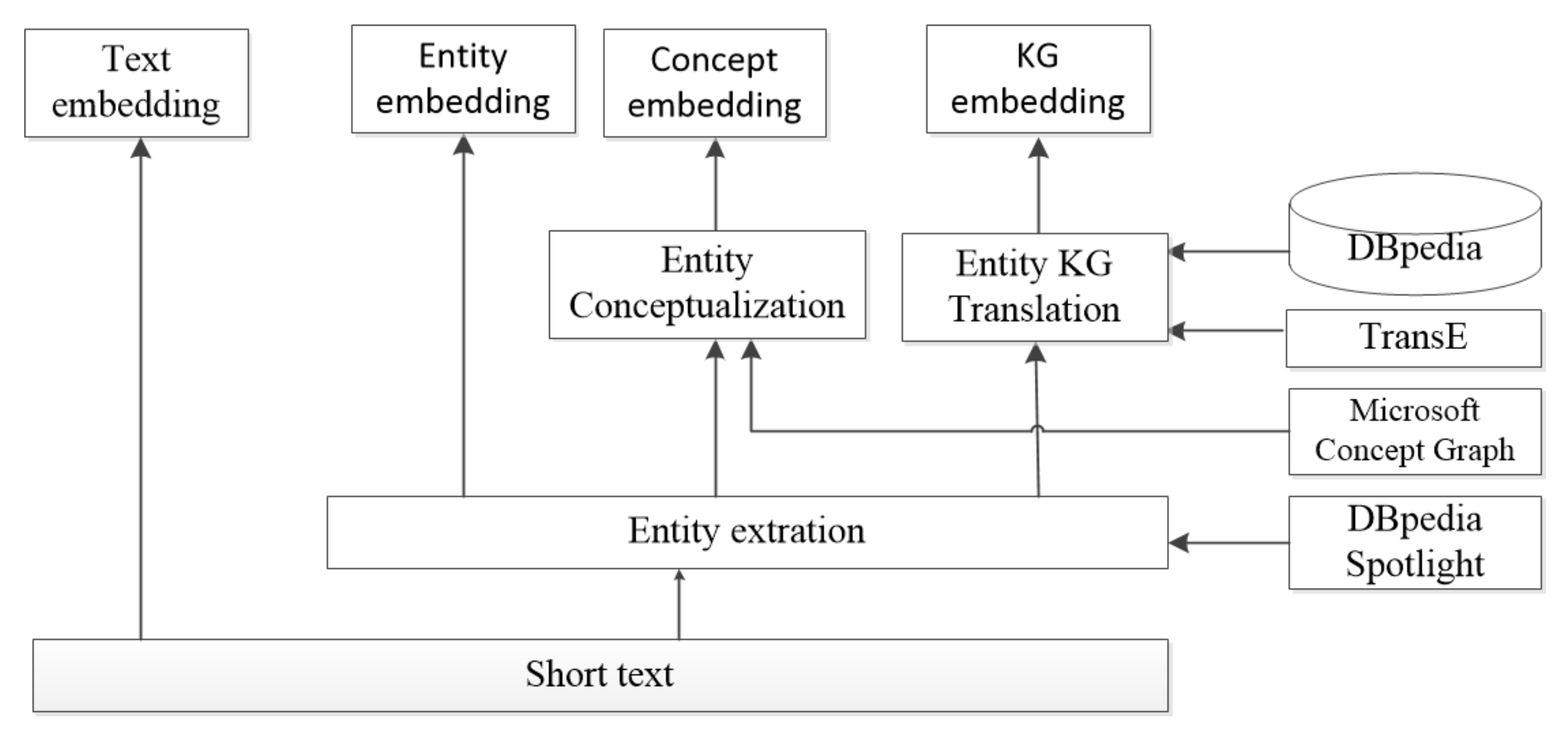
3. The ECKA Method
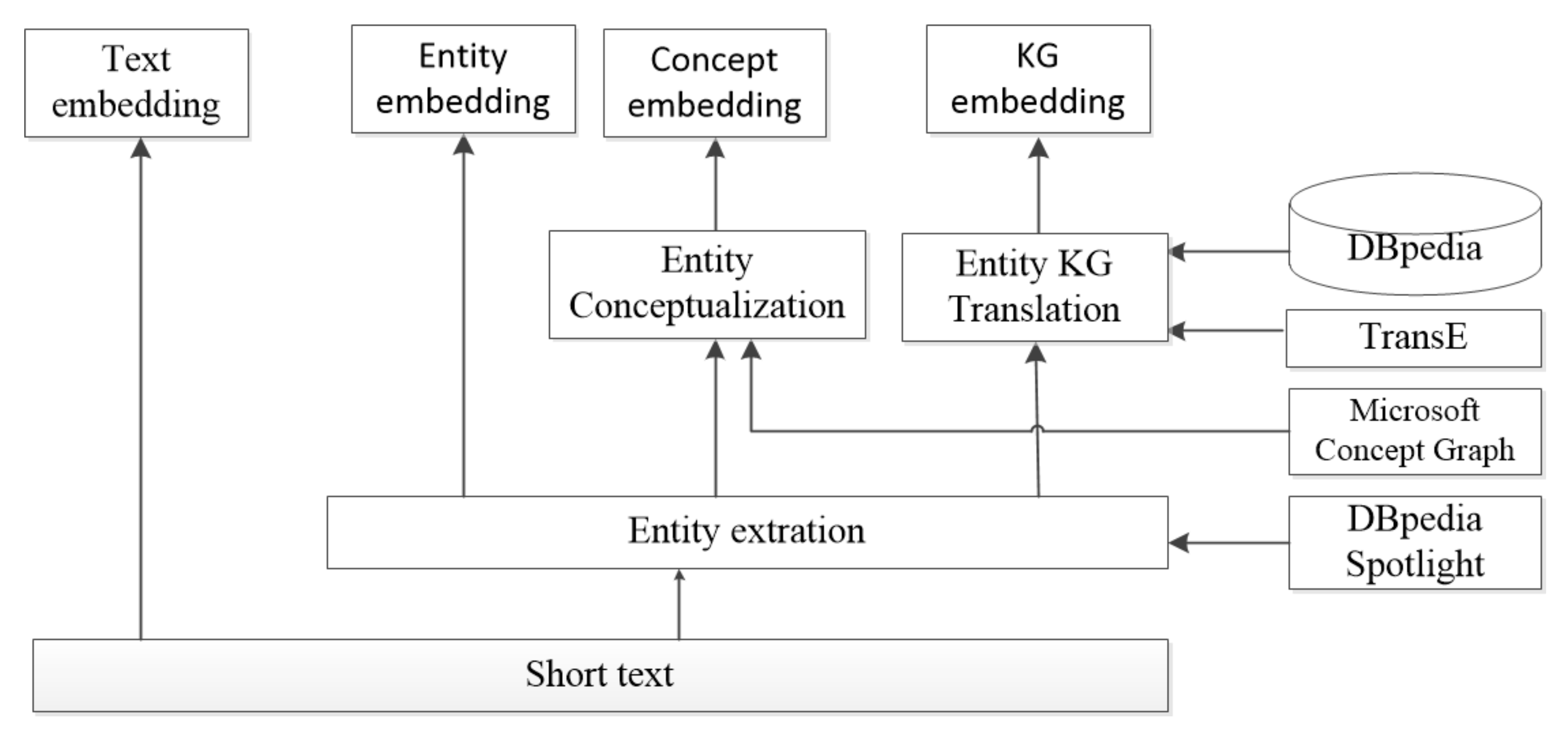
3.1. Semantic Information Retrieval Module
3.2. Feature Extraction Module
3.2.1. The Input Layer
- The Word set: The word set contains all the words in each short text. W = .
- The Entity Set: E = , represents the entities extracted from short text through the DBpedia Spotlight.
- The Concept Set: The concept of each entity is retrieved from the Microsoft Concept Graph, and the concept set can be represented as C = .
- The Knowledge set: This set is denoted as KE = , it is the same as the entity set, but its representation is learned from different aspects respectively.
3.2.2. The Embedding Layer
3.2.3. The Representation Layer
3.3. The Attention Module
4. Experiments
4.1. Datasets
4.2. Data Preprocessing
- Tokenization—Tokenization means splitting text into minimal meaningful units. In our model, the short text will be split into single words.
- Stemming—We use the NLTK’s PorterStemmer for the word’s stemming.
- Stop words removal—Stop words are common but meaningless words. Stop words removal is done by the NLTK stopwords collection.
4.3. Baselines
4.4. Parameter Setting
4.5. Result Analysis
4.5.1. Multiple Sources vs. Single Source
4.5.2. Comparison of ECKA Variants on Multiple Sources
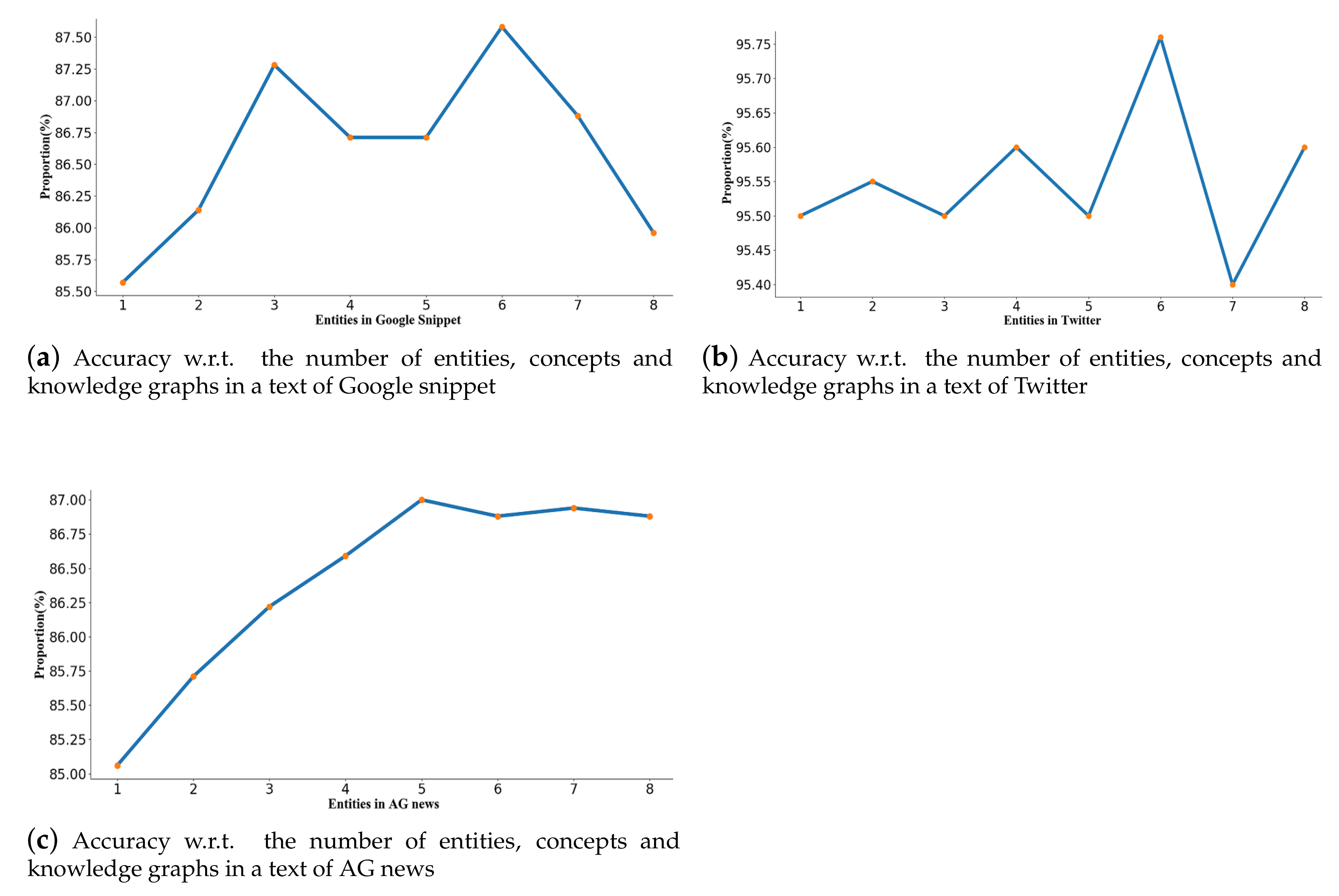
4.6. Parameter Sensitivity
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| BiLSTM | Bidirectional Long Short Term Memory |
| BoW | Bag of Words |
| CNN | Convolutional Neural Networks |
| ECKA | Entity-based Concept Knowledge-Aware model |
| GRU | Gated Recurrent Unit |
| KG | Knowledge Graph |
| KNN | K Nearest Neighbor |
| LSTM | Long Short Term Memory |
| NLP | Natural Language Processing |
| RNN | Recurrent Neural Networks |
| SVM | Support Vector Machine |
References
- Gubbi, J.; Buyya, R.; Marusic, S.; Palaniswami, M. Internet of Things (IoT): A vision, architectural elements, and future directions. Future Gener. Comput. Syst. 2013, 29, 1645–1660. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Wang, Z.; Li, Z.; Wen, J.R. Concept-based short text classification and ranking. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 1069–1078. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Flisar, J.; Podgorelec, V. Document enrichment using DBPedia ontology for short text classification. In Proceedings of the 8th International Conference on Web Intelligence, Mining and Semantics, Novi Sad, Serbia, 25–27 June 2018; pp. 1–9. [Google Scholar]
- Chen, J.; Hu, Y.; Liu, J.; Xiao, Y.; Jiang, H. Deep short text classification with knowledge powered attention. Proc. AAAI Conf. Artif. Intell. 2019, 33, 6252–6259. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Wang, Z.; Zhang, D.; Yan, J. Combining Knowledge with Deep Convolutional Neural Networks for Short Text Classification. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 2915–2921. [Google Scholar]
- Cao, L. Metasynthetic Computing and Engineering of Complex Systems; Advanced Information and Knowledge Processing; Springer: London, UK, 2015. [Google Scholar]
- Hu, L.; Jian, S.; Cao, L.; Chen, Q. Interpretable Recommendation via Attraction Modeling: Learning Multilevel Attractiveness over Multimodal Movie Contents. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3400–3406. [Google Scholar]
- Cao, L. Data Science Thinking: The Next Scientific, Technological and Economic Revolution; Data Analytics; Springer International Publishing: Cham, Switzerland, 2018. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; Van Kleef, P.; Auer, S.; et al. DBpedia—A large-scale, multilingual knowledge base extracted from Wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef] [Green Version]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008; pp. 1247–1250. [Google Scholar]
- Fabian, M.S.; Gjergji, K.; Gerhard, W.E.I.K.U.M. Yago: A core of semantic knowledge unifying wordnet and wikipedia. In Proceedings of the 16th International World Wide Web Conference, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Wang, H.; Zhang, F.; Xie, X.; Guo, M. DKN: Deep knowledge-aware network for news recommendation. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1835–1844. [Google Scholar]
- Gao, J.; Xin, X.; Liu, J.; Wang, R.; Lu, J.; Li, B.; Fan, X.; Guo, P. Fine-Grained Deep Knowledge-Aware Network for News Recommendation with Self-Attention. In Proceedings of the 2018 IEEE/WIC/ACM International Conference on Web Intelligence (WI), Santiago, Chile, 3–6 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 81–88. [Google Scholar]
- Türker, R. Knowledge-Based Dataless Text Categorization. In Proceedings of the European Semantic Web Conference, Auckland, New Zealand, 26–30 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 231–241. [Google Scholar]
- Daiber, J.; Jakob, M.; Hokamp, C.; Mendes, P.N. Improving efficiency and accuracy in multilingual entity extraction. In Proceedings of the 9th International Conference on Semantic Systems, Graz, Austria, 4–6 September 2013; pp. 121–124. [Google Scholar]
- Liu, H.; Singh, P. ConceptNet—A practical commonsense reasoning tool-kit. BT Technol. J. 2004, 22, 211–226. [Google Scholar] [CrossRef]
- Ji, L.; Wang, Y.; Shi, B.; Zhang, D.; Wang, Z.; Yan, J. Microsoft concept graph: Mining semantic concepts for short text understanding. Data Intell. 2019, 1, 238–270. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, H. Understanding Short Texts. 2016. Available online: https://www.microsoft.com/en-us/research/publication/understanding-short-texts/ (accessed on 15 October 2019).
- Wang, Z.; Wang, H.; Wen, J.R.; Xiao, Y. An inference approach to basic level of categorization. In Proceedings of the 24th Acm International on Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2019; pp. 653–662. [Google Scholar]
- Wang, Z.; Zhao, K.; Wang, H.; Meng, X.; Wen, J.R. Query understanding through knowledge-based conceptualization. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Hua, W.; Wang, Z.; Wang, H.; Zheng, K.; Zhou, X. Short text understanding through lexical-semantic analysis. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Korea, 13–17 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 495–506. [Google Scholar]
- Wang, Z.; Wang, H.; Hu, Z. Head, modifier, and constraint detection in short texts. In Proceedings of the 2014 IEEE 30th International Conference on Data Engineering, Chicago, IL, USA, 31 March–4 April 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 280–291. [Google Scholar]
- Song, Y.; Wang, H.; Wang, Z.; Li, H.; Chen, W. Short text conceptualization using a probabilistic knowledgebase. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge graph embedding: A survey of approaches and applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Phan, X.H.; Nguyen, L.M.; Horiguchi, S. Learning to classify short and sparse text & web with hidden topics from large-scale data collections. In Proceedings of the 17th international conference on World Wide Web, Beijing, China, 21–25 April 2008; pp. 91–100. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Training | Testing | Features | Value |
|---|---|---|---|---|
| Business | 1200 | 300 | Avg.Len per document | 12 |
| Computers | 1200 | 300 | Total entity | 1,494,181 |
| Cul-Arts-Ent. | 1880 | 330 | Total document | 12,240 |
| Edu-Sci | 2360 | 300 | ||
| Engineering | 220 | 150 | ||
| Health | 880 | 300 | ||
| Politics-Society | 1200 | 300 | ||
| Sports | 1120 | 200 | ||
| Total | 10,060 | 2180 |
| Category | Training | Testing | Features | Values |
|---|---|---|---|---|
| Politics | 2241 | 959 | Avg.Len per document | 18 |
| Sports | 2326 | 999 | Total entity | 1,586,965 |
| Total document | 6,525 | |||
| Total | 4567 | 1958 |
| Category | Training | Testing | Features | Value |
|---|---|---|---|---|
| World | 30,000 | 1900 | Avg.Len per document | 7 |
| Sport | 30,000 | 1900 | Total entity | 2,270,042 |
| Business | 30,000 | 1900 | Total document | 127,600 |
| Sci/Tec | 30,000 | 1900 | ||
| Total | 120,000 | 7600 |
| Google Snippet | AG News | ||
|---|---|---|---|
| BoW+TFIDF | 94.25 | 61.84 | 72.7 |
| CNN | 95.14 | 85.21 | 83.97 |
| LSTM | 94.99 | 81.54 | 83.18 |
| Bi-LSTM | 95.10 | 84.86 | 83.5 |
| GRU | 94.99 | 80.92 | 82.98 |
| Attention | 94.43 | 84.73 | 83.34 |
| KBSTC | - | 72 | 67.9 |
| WCCNN | 95.09 | 85.83 | 85.57 |
| ECKA (proposed) | 95.76 | 87.59 | 86.93 |
| Variants | Google Snippet | Ag News | |
|---|---|---|---|
| ECKA with word only | 95.19 | 83.70 | 84.13 |
| ECKA with word and entity | 95.60 | 86.4 | 86.75 |
| ECKA with word and concept | 95.50 | 86.28 | 85.15 |
| ECKA with word and KG | 95.65 | 86.62 | 84.22 |
| ECKA with word and entity, concept and KG | 95.76 | 87.59 | 86.93 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, W.; Liu, Q.; Cao, L. Cognitive Aspects-Based Short Text Representation with Named Entity, Concept and Knowledge. Appl. Sci. 2020, 10, 4893. https://doi.org/10.3390/app10144893
Hou W, Liu Q, Cao L. Cognitive Aspects-Based Short Text Representation with Named Entity, Concept and Knowledge. Applied Sciences. 2020; 10(14):4893. https://doi.org/10.3390/app10144893
Chicago/Turabian StyleHou, Wenfeng, Qing Liu, and Longbing Cao. 2020. "Cognitive Aspects-Based Short Text Representation with Named Entity, Concept and Knowledge" Applied Sciences 10, no. 14: 4893. https://doi.org/10.3390/app10144893
APA StyleHou, W., Liu, Q., & Cao, L. (2020). Cognitive Aspects-Based Short Text Representation with Named Entity, Concept and Knowledge. Applied Sciences, 10(14), 4893. https://doi.org/10.3390/app10144893