Featured Application
Porosity/permeability inversion in petroleum engineering; Log-conductivity inversion with heads and tracer data in hydrogeology; Source contribution identification in air pollution monitoring.
Abstract
Assimilation of spatio-temporal data poses a challenge when allowing non-Gaussian features in the prior distribution. It becomes even more complex with nonlinear forward and likelihood models. The ensemble Kalman model and its many variants have proven resilient when handling nonlinearity. However, owing to the linearized updates, conserving the non-Gaussian features in the posterior distribution remains an issue. When the prior model is chosen in the class of selection-Gaussian distributions, the selection Ensemble Kalman model provides an approach that conserves non-Gaussianity in the posterior distribution. The synthetic case study features the prediction of a parameter field and the inversion of an initial state for the diffusion equation. By using the selection Kalman model, it is possible to represent multimodality in the posterior model while offering a 20 to 30% reduction in root mean square error relative to the traditional ensemble Kalman model.
1. Introduction
Data assimilation of spatio-temporal models is a challenge in many fields of study, including, but not limited to, air pollution mapping, weather forecast, petroleum engineering, and ground water flow assessment. Over the years, methods have been developed to handle increasingly complex problems. It started with the Kalman filter as presented in the seminal publication [1]. The Kalman filter is based on a Gaussian initial model and Gauss-linear forward and observation models. It defined the foundation for data assimilation and is still used in many assimilation studies. The extended Kalman filter (EKF) [2] appeared as a natural methodological extension that allowed for nonlinearity in the Kalman filter framework by linearization. The ensemble Kalman filter (EnKF) [3,4] defined a Monte Carlo approach to the filter and it became popular as it allowed for nonlinearity in the forward and observation models without having to evaluate analytical gradients. The EnKF and its variants have proven to be efficient in solving high-dimensional and nonlinear problems, see [5,6]. In the EnKF, the initial ensemble members represent the initial state which may not have an analytical expression. The forward model then propagates the ensemble members forward in time. Pseudo observations are generated using the observation model. The conditioning of each ensemble member is made with the Kalman weights estimated from the ensemble to give the best linear update. In cases where the initial model is non-Gaussian, the distribution of the variable of interest conditioned on the data will tend toward Gaussianity as observations are assimilated due to the linear assimilation rule.
Non-Gaussian initial distributions may be conserved by using a univariate transform into Gaussian marginals while assuming multi-Gaussianity in the transformed space. A univariate back transform is then used to return to the original space. This approach has a long history in traditional statistics, geostatistics, and more recently in ensemble methods for data assimilation, which is referred to as copulas [7], normal score transform [8], and Gaussian anamorphosis [9], respectively. The latter has shown to improve the performance of the EnKF in many applications [10,11]. There are however some unresolved issues since Gaussian anamorphosis transforms the marginal distributions rather than the full distribution, and the effect on the resulting variables interdependence is uncertain.
The Ensemble Randomized Maximum Likelihood Filter (EnRML) [12] and its close relative the Iterative EnKF (IEnKF) [6] are primarily used to handle nonlinearities in the forward and observation models, but they will also retain certain non-Gaussian features in the filtering distribution. These filters require gradient evaluations to execute the update which can be complicated even if the adjoint state method is used. One alternative is to evaluate the gradient using the ensemble itself [13], but this approach introduces an approximation with unclear consequences, particularly in models with multimodal marginals.
Multimodality in the prior model can be represented using categorical auxiliary variables to construct Gaussian mixture prior models [14,15,16]. In a spatial setting, these models appear as a combination of Gaussian random fields whose parameters depend on the value taken by the categorical variable, but in order to retain spatial dependence, the categorical variable must also have a spatial dependence. This indicator spatial variable can be modeled as a Markov [17] or truncated pluri-Gaussian [18] random field. For both of these models, there are challenges related to temporal data assimilation, although some encouraging examples have been developed [19].
We define and study an alternative prior model, the selection-Gaussian random field [20,21], which may represent multimodality, skewness, and peakedness. This random field model is conjugate with respect to Gauss-linear forward and observation models, similarly to the Gaussian random field model. The posterior distribution is therefore analytically tractable under these assumptions [22]. For general forward and observation models, ensemble based algorithms along the lines of the EnKF can be designed. Such selection ensemble Kalman algorithms are the focus of this study, and they are evaluated on a couple of examples.
In Section 2, we introduce the selection ensemble Kalman model. It provides a framework for the use of the selection-Gaussian distribution as a prior in data assimilation. This framework is then used for ensemble filtering and smoothing through the selection EnKF (SEnKF) and the selection EnKS (SEnKS) algorithms. In Section 3, a synthetic case study of the diffusion equation, with two distinct test cases, showcases the ability of the proposed approaches to assess a parameter field and the initial state of a dynamic field. Results from the SEnKF and the SEnKS are compared to that of the traditional EnKF and the EnKS, respectively. In Section 4, potential shortcomings are discussed and the results are put into perspective with respect to applicability in more realistic applications. In Section 5, conclusions are presented.
In this paper, denotes the probability density function (pdf) of a random variable , denotes the pdf of the Gaussian n-vector with expectation n-vector and covariance -matrix . Furthermore, denotes the probability of the aforementioned Gaussian n-vector to be in . We also use to denote the all-ones n-vector, to denote the identity -matrix and to denote the indicator function that equals 1 when S is true and 0 otherwise. We consider log-diffusivity to be an adimensional quantity and it will therefore not be given a unit.
2. Materials and Methods
Consider the unknown temporal n-vector for . Let denote the variable of interest and let denote . Assume that the temporal m-vectors of observations for are available, and define and accordingly. The model specified hereafter defines a hidden Markov (HM) model [23] as displayed in Figure 1.
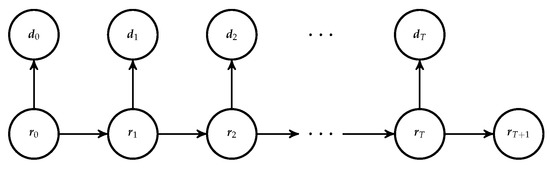
Figure 1.
Graph of the hidden Markov model.
Prior model: The prior model on consists of an initial and a forward model,
where is the pdf of the initial state and defines the forward model.
(a) Initial distribution: The distribution for the initial state is assumed to be in the class of selection-Gaussian distributions [20,21]. Consider a Gaussian -vector ,
with n-vectors and , -matrix , and where , , and are all three covariance -matrices with . Define a selection set of dimension n and let ; then, is in the class of selection-Gaussian distribution and its pdf is,
Note that the class of Gaussian distributions constitutes a subset of the class of selection-Gaussian distributions with . The dependence in represented by and the selection subset A are crucial user-defined parameters with the latter being temporally constant. The selection-Gaussian model may represent multimodal, skewed, and/or peaked marginal distributions, see [21]. In this study, the initial distribution is defined to be a discretized stationary selection-Gaussian random field with parametrization,
For a given spatial correlation -matrix , a stationary selection-Gaussian random field is fully parametrized by . Similarly, a stationary Gaussian random field is parametrized by .
(b) Forward model: The forward model given the initial state is defined as
with
where is the forward model with random n-vector , independent and identically distributed (iid) for each t. This forward model may be nonlinear, but, since it only involves the variable at the previous time step , it defines a first-order Markov chain. Note that cannot generally be written in closed form.
Likelihood model: The likelihood model for is defined as conditional independent with single-site response,
with
where is the likelihood function with random m-vector , iid for each t. Note that cannot generally be written in closed form.
Posterior model: The posterior model for the HM model in Figure 1 is given by
and is also a Markov chain, see [23,24]. This model is denoted the selection ensemble Kalman model. If the forward and likelihood models are Gauss-linear, the posterior model is also selection-Gaussian and analytically tractable, see [22]. When the forward and/or likelihood models are nonlinear, however, approximate or sampling based assessment of the posterior model must be made. For this purpose, we introduce the selection ensemble Kalman filter (SEnKF) and smoother (SEnKS) in the spirit of the traditional ensemble Kalman model [3].
The traditional EnKF algorithm aims at assessing the forecast pdf , and it is justified by general HM model recursions, see [23]. The algorithm is initiated by
and utilizes the recursion for ,
The expressions are represented by an ensemble of realizations, which in each recursion is conditioned using a linearized approximation with Kalman weights estimated from the ensemble. Thereafter, the ensemble is forwarded to the next time step. The SEnKF introduced in this study relies on the same relations as above, but it operates on the augmented -vector , see Equation (2). Hence, the forward model is defined as
where the auxiliary n-vector is temporally constant.
The likelihood model is defined as
The SEnKF algorithm provides an ensemble representation of
and, based on this ensemble, empirical sampling based inference, see [21], is used to obtain the forecast of interest:
The SEnKF algorithm is specified in Algorithm A1 in Appendix A.
The traditional EnKS algorithm aims at evaluating the interpolation pdf with corresponding HM model recursions, see [23]. The algorithm is initiated by
and the recursions for ,
The expressions are represented by an ensemble of realizations. Forwarding is made on the ensemble and the conditioning is empirically linearized. Note that the dimension of the model increases very fast, one may therefore only store the interpolation pdf at the time point s of interest. The SEnKS introduced in this study relies on the relations defined above and uses an extended -vector as defined in Equation (2). The forward and likelihood models are identical to those defined for the filter. The SEnKS algorithm provides an ensemble representation of
and by using empirical sampling based inference, see [21], the interpolation of interest is assessed,
The SEnKS algorithm is specified in Algorithm A2 in the Appendix A. Both algorithms, SEnKF and SEnKS, contain empirically linearized conditioning and asymptotic results, when the ensemble size goes to infinity, and are consistent only for Gauss-linear forward and likelihood models. Under these assumptions, the model is analytically tractable; however, see [22]. In spite of this lack of asymptotic consistency for general HM models, the ensemble Kalman scheme has proven surprisingly reliable for high-dimensional, weakly nonlinear models even with very modest ensemble sizes [25].
3. Results
We consider two test cases to illustrate the relevance of the selection ensemble Kalman algorithms presented in Section 2. The model, common to both test cases, is based on the diffusion equation. The test cases are designed such that it will be opportune to consider bi-modal initial distributions. In the first test case, we compare the SEnKF to the traditional EnKF with a focus on predicting the diffusivity field that contains a high diffusivity channel. In the second test case, we compare the SEnKS to the traditional EnKS with a focus on evaluating the initial temperature field that is divided into two distinct areas where the initial temperature is substantially higher in one than in the other.
3.1. Model
Consider a discretized spatio-temporal random field, where and that represents temperature (C). Let a discretized spatial random field, ; with representing diffusivity (). Let be the spatial reference on the regular spatial grid on the domain D, while t is the temporal reference on the regular temporal grid . The number of spatial grid nodes is , and they are placed every 10 cm vertically and horizontally. The discretized temperature field at time t may be represented by the n-vector and the diffusivity field by the n-vector . Both are assumed to be unknown. Note that the Kalman models are defined on the joint variable .
Assume that, given the initial temperature field, the field evolves according to the diffusion equation:
with the outer normal to the domain and q a source term. The expression in Equation (20) is discretized using finite differences and the forward model is defined as
with . Convergence and stability of the numerical method are easily ensured for the finite difference scheme that is used. The initial temperature field is considered unknown in the test cases.
The forward model is assumed to be perfect in the sense that there is no model error. The forward model in Equation (6) then takes the form,
This forward model is nonlinear due to the product of and in Equation (20). Consequently, the assumption of Gauss-linearity required for both the traditional Kalman model [1] and the selection Kalman model [22] is violated and necessitates ensemble based algorithms.
The observations are acquired in a location pattern on the spatial grid at each temporal node in , providing the set of observations m-vectors , . The corresponding likelihood model is defined as
where the observation -matrix is a binary selection matrix, while the centered Gaussian m-vector with the covariance -matrix , and represents independent observation errors. This likelihood model is in Gauss-linear form.
3.2. Test Case 1: Predicting the Parameter Field
The focus of this test case is to predict the unknown diffusivity field based on the observations . Because diffusivity is constant in time, smoothing and filtering give an identical prediction of the field. However, filtering is preferred because it does not require updating the ensemble at all future times in addition to the previous one, see [26]. The posterior model is evaluated using the SEnKF, see Appendix A and the results are compared to those from the traditional EnKF algorithm.
The true diffusivity n-vector is displayed in Figure 2. The diffusivity is always positive. To ensure that ensemble updates do not lead to negative diffusivity values, we work on . The figure shows a channel in which the diffusivity is higher than in the rest of the field. The diffusivity field is formally defined as
where is the low diffusivity area and is the high diffusivity channel. The parameter values are and . The true temperature field is initially at C and the heat source on the lower border of the high diffusivity channel starts pumping in heat at at a constant volumetric rate , see Figure 2. The temporal evoluation of the temperature field, shown in Figure 3, is obtained by solving the diffusion equation in Equation (20) for the log-diffusivity field in Figure 2 and the initial temperature field defined above. The temperature observations , see Figure 4, are then collected from the five locations shown in Figure 2 using the likelihood model defined in Equation (23). The measurements are taken every second from to . As the heat from the source diffuses mostly along the high diffusivity channel, the observed temperature increases substantially at observation locations within the channel.
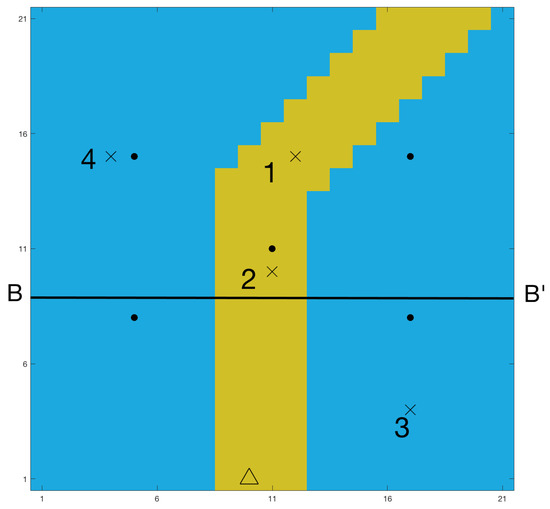
Figure 2.
Initial log-diffusivity field with observation locations , monitoring locations ×, and heat source ∆.
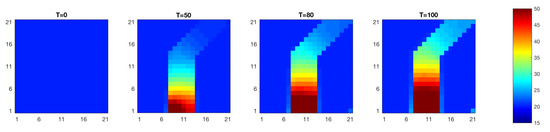
Figure 3.
True temperature (C) field evolution over time.
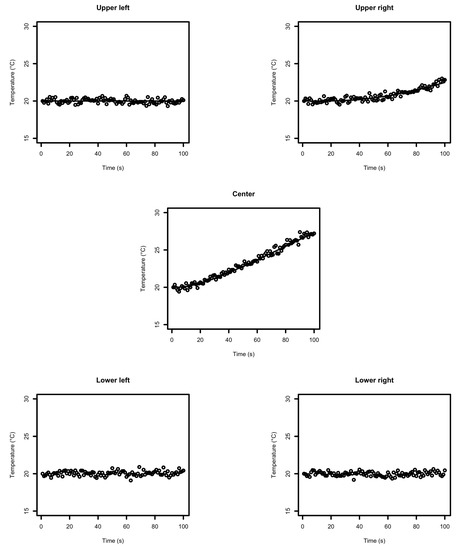
Figure 4.
Data collected over time () and true temperature evolution (line) at the data collection points.
The unknown initial field for log-diffusivity is assigned a stationary selection-Gaussian random field prior model with parameters , see [21] and Equation (2). The parameter values for the prior model are listed in Table 1.

Table 1.
Parameter values for the selection-Gaussian initial distribution for the initial log-diffusivity field.
The unknown initial temperature field is assigned a stationary Gaussian random field prior model with parameters with expectation and variance levels and , respectively. The variance level is relatively large as we assume little prior knowledge of the initial temperature field. For both prior models, the spatial correlation ()-matrix is defined by the second order exponential spatial correlation function , with interdistance .
Figure 5 contains realizations from the prior model of the log-diffusivity field and their associated spatial histograms. The prior model is specified to be spatially stationary except for boundary effects with bi-modal spatial histograms. The selection set for the prior model is chosen to obtain bi-modal marginal distributions with a very dominant mode centered slightly above the value for and a very small mode centered slightly below the value for . The prior is therefore not centered at the true values. Note that the joint random field will appear as a bi-variate selection-Gaussian random field, see [21].
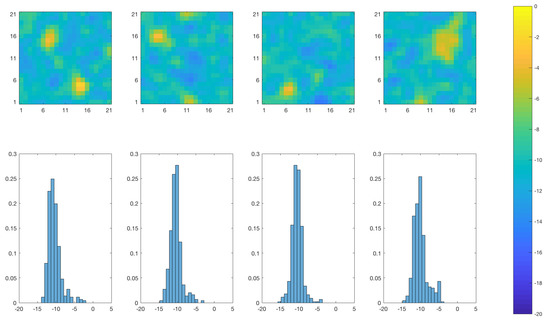
Figure 5.
Realizations from the initial selection-Gaussian distribution of the log diffusivity at time (upper panels) and associated spatial histogram (lower panels). Lower panels: the horizontal axes represent the log-diffusivity, the vertical axes represent the relative prevalence of each log-diffusivity value for the realization in the panel right above.
The SEnKF operates on the -vector , and therefore we generate an initial ensemble with = 10,000 ensemble members that are sampled from the Gaussian -vector with pdf,
The EnKF operates on the -vector , and therefore we generate an initial ensemble with = 10,000 ensemble members that are sampled from the selection-Gaussian distribution . The variables and are independent, so we generate them independently: 10,000 samples from the selection-Gaussian n-vector with parameters and 10,000 samples from the Gaussian n-vector with parameters . It is important to understand that both ensemble algorithms are initiated with an ensemble from an identical selection-Gaussian random field prior model for at , which reflects the bi-modality of the prior model. Due to the size of the ensemble relative to the dimension of the problem, we are using neither localization nor inflation in the algorithms.
To illustrate the differences between the SEnKF and the EnKF, we present the following results for both algorithms:
- The marginal posterior distributions of the log-diffusivity field at four monitoring locations denoted on Figure 2, at time .
- The marginal maximum a posteriori (MMAP) prediction of the log-diffusivity field at time at time .
- Realizations from the posterior distribution at time .
- The root mean square errors (RMSE) of the MMAP prediction of the log-diffusivity field relative to the true log-diffusivity field at time .
Figure 6 and Figure 7 show the marginal posterior pdfs at the four monitoring locations at time for the SEnKF and EnKF algorithms, respectively. Monitoring locations 1 and 2 are placed within the high diffusivity area while the two other locations are placed far into the low diffusivity area. At , all pdfs are identical, in all locations due to the stationary prior model and for both algorithms due to identical prior models. The SEnKF results appear to preserve bi-modality as observations are assimilated. As more data are made available, the high value mode increases at monitoring locations 1 and 2 that are inside the high diffusivity area. The low value mode remains dominant at monitoring locations within the low diffusivity areas. These results reflect expected behaviors. The traditional EnKF results are significantly different since the bi-modality of the marginal pdfs disappears already at . The marginal pdfs are Gaussian-like and are gently moved toward high and low values depending on which diffusivity area the monitoring locations are in. This regression toward the mean effect of the EnKF is generally recognized as it gives the best prediction in the squared error sense [27].
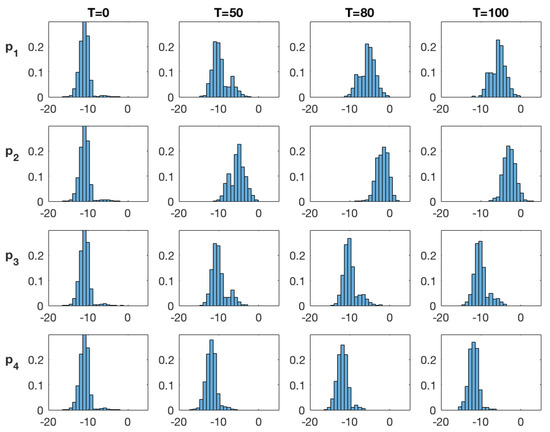
Figure 6.
SEnKF approach: Marginal posterior distribution of the log diffusivity at time at the monitoring locations () denoted ().
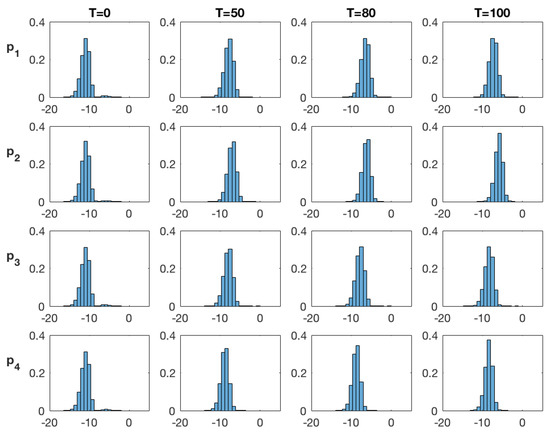
Figure 7.
EnKF approach: Marginal posterior distribution of the log diffusivity at time at the monitoring locations () denoted ().
Figure 8 displays the MMAP predictions based on the SEnKF and the traditional EnKF at time . At , the predictions from the two algorithms are identical since they use identical prior models. As observations are assimilated, the SEnKF predictions reproduce the high diffusivity area relatively well, with clear contrast. The traditional EnKF predictions also indicate the diffusivity areas, but with less contrast. Figure 9 displays the MMAP prediction at along the section B-B’ shown in Figure 2. The high contrast reliable reconstruction of the high diffusivity channel by the SEnKF algorithm is confirmed. The traditional EnKF predictions appear less reliable. The highest density interval (HDI) [28] covers the true diffusivity values for the SEnKF while these values are far outside the interval for the traditional EnKF results. The results are consistent with the observations made regarding the marginal posterior pdfs in Figure 6 and Figure 7.
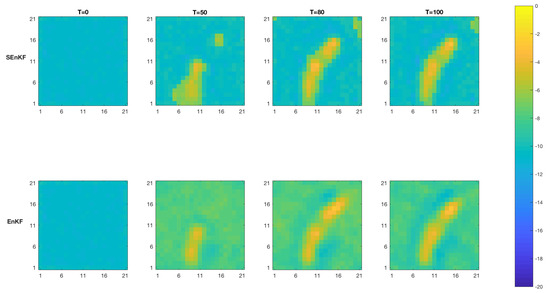
Figure 8.
MMAP predictions of the log diffusivity field at time (upper panels—SEnKF approach, lower panels—EnKF approach).
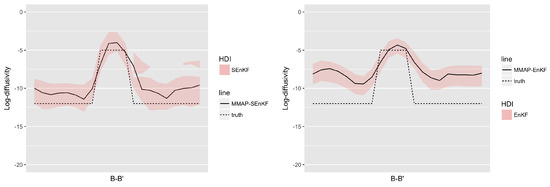
Figure 9.
MMAP predictions of the log diffusivity field with HDI in cross section B-B’ at time with SEnKF (left) and with EnKF (right).
Figure 10 and Figure 11 show realizations and spatial histograms from the posterior distribution of the log-diffusivity at time for the SEnKF and traditional EnKF algorithms, respectively. The realizations from the SEnKF largely reproduce the channel with clear contrast while the realizations from the EnKF also reproduce the channel, but with much less contrast. The spatial histograms also underline the difference in contrast in that they are clearly bi-modal for the SEnKS and much more Gaussian-like for the EnKS.
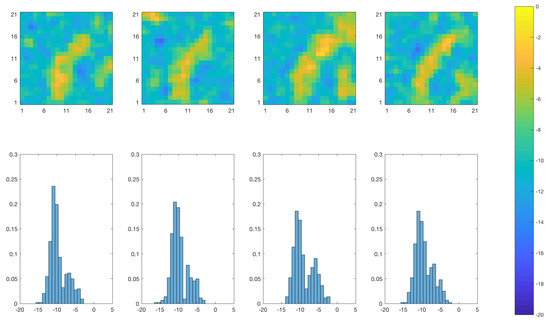
Figure 10.
SEnKF approach: Realizations of the posterior distribution of the log diffusivity at time (upper panels) and associated spatial histogram (lower panels). Lower panels: the horizontal axes represent the log-diffusivity, the vertical axes represent the relative prevalence of each log-diffusivity value for the realization in the panel right above.
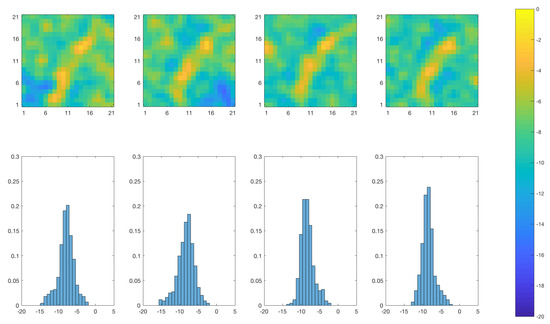
Figure 11.
EnKF approach: Realizations of the posterior distribution of the log diffusivity at time (upper panels) and associated spatial histogram (lower panels). Lower panels: the horizontal axes represent the log-diffusivity, the vertical axes represent the relative prevalence of each log-diffusivity value for the realization in the panel right above.
Table 2 shows that the RMSE of the MMAP prediction relative to the true diffusivity field for the SEnKF is approximately 30% lower than for the EnKF.
Table 2.
RMSE comparing the MMAP prediction and the true log diffusivity field at time .
This test case clearly illustrates the SEnKF’s ability to conserve multimodality in the posterior distribution and it leads to predictions with better constrast and accuracy. We conclude that the reconstruction of the true diffusivity field is done more reliably by the SEnKF algorithm than by the EnKF algorithm.
3.3. Test Case 2: Reconstructing the Initial Field
The focus of the study is to evaluate the unknown initial state of the temperature field based on the observations . The posterior model is assessed using the SEnKS, see Appendix A, and the results are compared to those from the traditional EnKS.
The true initial temperature field is set at 20 C except for a square shaped region with temperature set at 45 C, see Figure 12. The temperature field is formally defined as
where is the low temperature area and is the high temperature area, and = 20 C and = 45 C. Figure 12 shows the true log-diffusivity n-vector . The diffusivity is always positive. To ensure that ensemble updates do not lead to negative diffusivity values, we work on . The heat contained in the high temperature area will diffuse towards the rest of the field according to the diffusion equation in Equation (20), see Figure 13. The temporal observations are collected at five different observation locations according to the likelihood model in Equation (23), see Figure 12. Figure 14 displays the observations where it is clear that the observed temperature increases substantially only at the observation locations close to the high temperature area. The measurements are taken every second from T = 0 to T = 50.
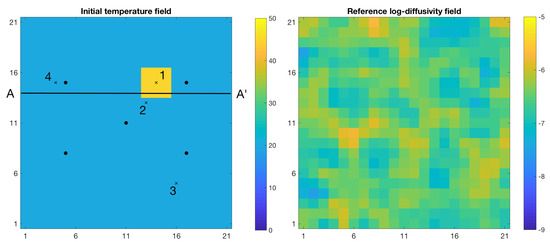
Figure 12.
Initial temperature (C) field (left) with data collection points and monitoring locations × and reference log-diffusivity field (right).
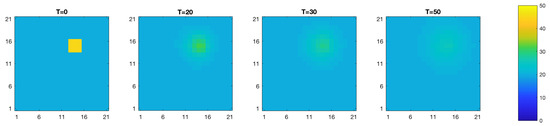
Figure 13.
True temperature (C) field evolution over time.
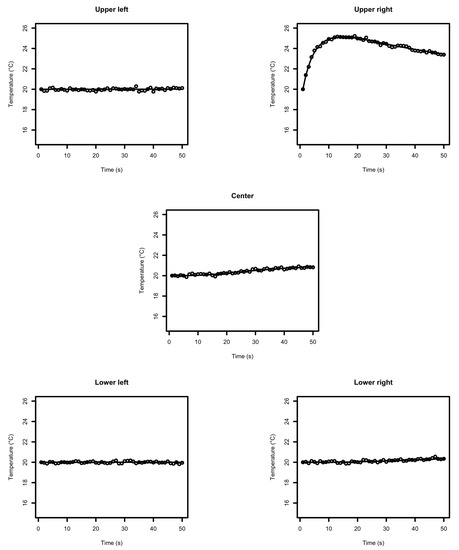
Figure 14.
Data collected over time (points) and true temperature (C) evolution at the data collection points (line).
The unknown initial temperature field is assigned a stationary selection-Gaussian random field prior model with parameters . The parameter values are listed in Table 3. The unknown log-diffusivity field is assigned a stationary Gaussian random field prior model with parameters with expectation and variance levels and , respectively. For both prior models, the spatial correlation ()-matrix is defined by the second order exponential spatial correlation function , with interdistance .
Table 3.
Parameter values for the selection-Gaussian initial distribution for the initial temperature prior model.
Figure 15 contains four realizations from the prior model of the temperature field and their spatial histograms. The marginal initial distributions of the realizations are bi-modal and spatially stationary except for boundary effects. The selection set in the prior model is chosen to obtain a bi-modal marginal distribution with one large mode approximately centered about 20 C and a smaller mode centered close to 45 C.
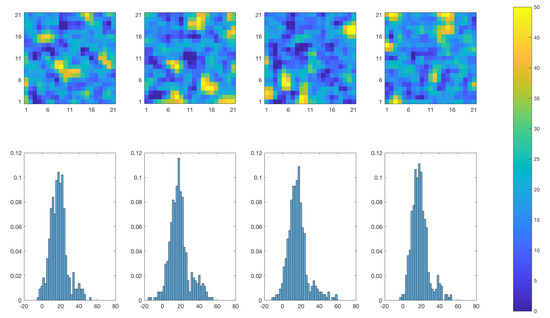
Figure 15.
Realizations from the selection-Gaussian initial distribution of the initial temperature field at time (upper panels) and associated spatial histogram (lower panels). Upper panels: the colorbar gives the temperature in C. Lower panels: the horizontal axes represent the temperature (C), the vertical axes represent the relative prevalence of each temperature value for the realization right above.
The SEnKS operates on the -vector , and therefore we generate an initial ensemble with = 10,000 ensemble members that are sampled from the Gaussian -vector with pdf,
The EnKS operates on the -vector , and therefore we generate an initial ensemble with = 10,000 ensemble members that are sampled from selection-Gaussian distribution . The variables and are independent, so we generate them independently: 10,000 samples from the selection-Gaussian n-vector with parameters and 10,000 samples from the Gaussian n-vector with parameters . Due to the size of the ensemble relative to the dimension of the problem, we used neither localization nor inflation in the algorithms.
To illustrate the differences between the SEnKS and the EnKS we present the following results for both algorithms:
- The marginal posterior distributions of the initial temperature field at four monitoring locations denoted on Figure 12, at time .
- The marginal maximum a posteriori (MMAP) prediction of the initial temperature field at time at time .
- Realizations from the posterior distribution of the initial temperature field at time .
- The root mean square errors (RMSE) of the MMAP prediction of the initial temperature field relative to the true initial temperature field at time .
The marginal posterior pdfs at the four monitoring locations at time T = 0,20,30,50 are displayed in Figure 16 and Figure 17 for the SEnKS and EnKS algorithms, respectively. At , the prior models for both algorithms are identical and so are the marginal pdfs. Monitoring location 1 is placed inside the high temperature area. As observations are assimilated, the marginal pdf from the SEnKS remain bi-modal, but the high value mode increases steadily. For the other monitoring locations, all placed outside the high temperature area, the bi-modality is reproduced but with a dominant low value mode. The relative size of the modes reflects the distance to the high temperature area and the observation locations. The marginal pdfs from the EnKS lose their bi-modality after a few assimilation steps and from then on the Gaussian-like marginal pdfs are only slightly shifted by the assimilation of observations.
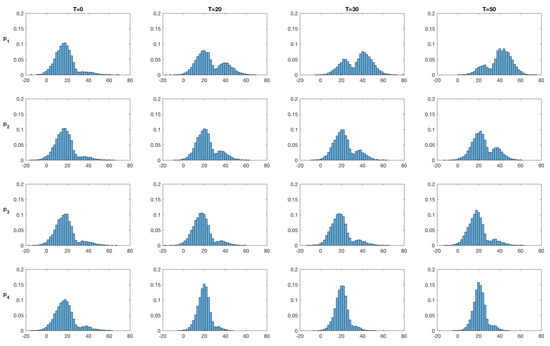
Figure 16.
SEnKS approach: Marginal posterior distributions of the initial temperature at time at monitoring locations () denoted (). The horizontal axes representing temperature are expressed in C.
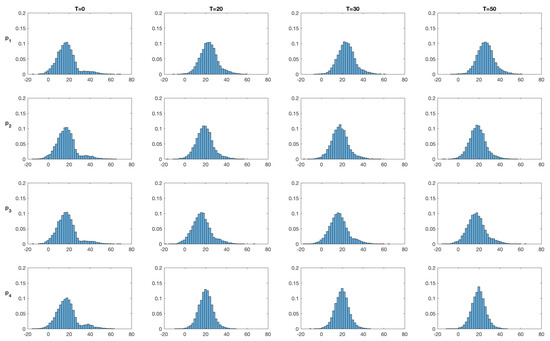
Figure 17.
EnKS approach: Marginal posterior distributions of the initial temperature at time at monitoring locations () denoted (). The horizontal axes representing temperature are expressed in C.
Figure 18 displays the MMAP predictions of the initial temperature field based on the SEnKS and the traditional EnKS at time . For the SEnKS, the high temperature area is clearly identifiable with clear contrast from time while for the EnKS the high temperature area is hardly ever identifiable on the MMAP predictions that show little contrast. Figure 19 displays the MMAP prediction of the initial temperature field at along the section A-A’, see Figure 12, for the SEnKS and the traditional EnKS. The SEnKS clearly identifies the high temperature area and the HDI covers the truth, while the EnKS clearly fails to identify the high temperature area and the HDI does not even cover it.
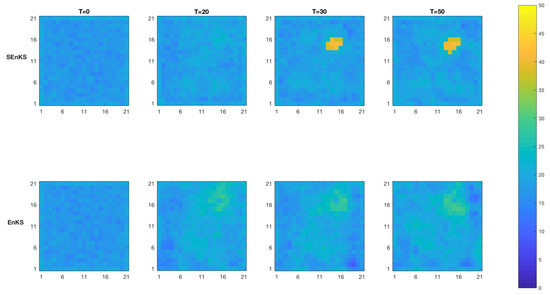
Figure 18.
MMAP predictions of the initial temperature (C) field at time for the SEnKS approach (upper) and the EnKS approach (lower).
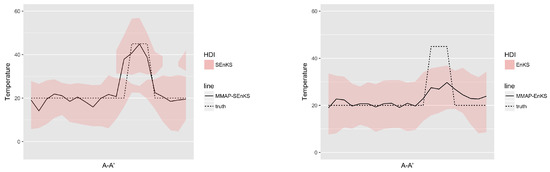
Figure 19.
MMAP predictions of the initial temperature (C) field with HDI in cross section A-A’ at time with SEnKS (left) and with EnKS (right).
Realizations of the posterior model at based on the SEnKS and the traditional EnKS algorithms are displayed in Figure 20 and Figure 21, respectively. The SEnKS produces realizations that appear bi-modal while the ensemble members from the EnKS display more symmetric spatial histograms. Even though the differences between the realizations are quite subtle, they are consistent with previous results.
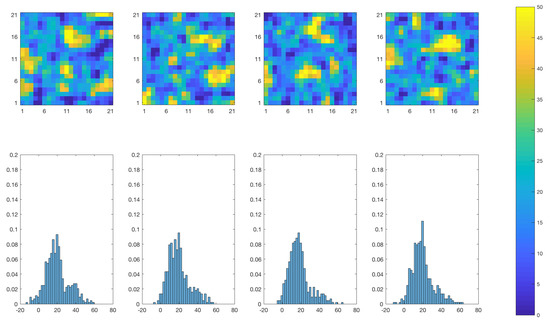
Figure 20.
SEnKS approach: Realizations from the posterior distribution of the initial temperature field at time . Upper panels: the colorbar gives the temperature in C. Lower panels: the horizontal axes represent the temperature (C), the vertical axes represent the relative prevalence of each temperature value for the realization right above.
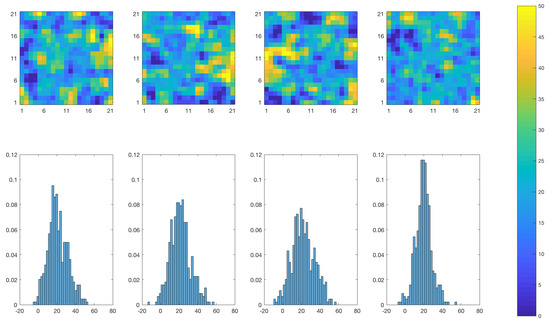
Figure 21.
EnKS approach: Realizations from the posterior distribution of the initial temperature field at time . Upper panels: the colorbar gives the temperature in C. Lower panels: the horizontal axes represent the temperature (C), the vertical axes represent the relative prevalence of each temperature value for the realization right above.
Table 4 shows that RMSE of the MMAP prediction relative to the true initial temperature field for the SEnKS is approximately lower than for the EnKS.
Table 4.
RMSE comparing the MMAP prediction of the initial temperature field and the initial temperature field at time .
This test case clearly illustrates the ability of the SEnKS to conserve multimodality in the posterior distribution, and it leads to predictions with better contrast and accuracy. We conclude that the SEnKS algorithm provides a more reliable reconstruction of the initial state of the temperature field than the traditional EnKS algorithm. Note that the posterior model for the unknown diffusivity field can also be assessed with the two algorithms. When comparing the MMAP predictions relative to the true diffusivity field, see Figure 12, we observe that none of the algorithms provide reliable predictions. We conclude that the small scale variations in the field are not sufficiently distinct to be identified.
4. Discussion
The traditional EnKF and EnKS algorithms provide an ensemble that directly represents the posterior models and , respectively. Hence, the posterior models can be assessed by displaying statistics based on these ensembles. Reliable assessment of the posterior model in the two test cases can be obtained with approximately 1000 ensemble members. The SEnKF and SEnKS algorithms under study provide an ensemble of the augmented posterior models, and , respectively. In order to obtain the posterior models of interest, and , the conditioning on must be made by empirical sampling based inference, see [21,22]. This inference requires the estimation of the expectation vector and covariance matrix . The two test cases are defined on a -grid for both and —hence in dimension 882. The expectation and covariance will have 882 and 389,403 unique entries, respectively. Our experience from this study is that approximately 10,000 ensemble members are required to obtain reliable assessment of the posterior models of interest. To reduce the ensemble size, we have tested various localization approaches [29], without notable success, and leave the subject for further research.
5. Conclusions
Data assimilation of spatio-temporal variables with multimodal spatial histograms is challenging. Traditional ensemble Kalman algorithms enforce a regression towards the mean due to the linearized conditioning on observations, hence the multimodality is averaged out. We introduce the selection ensemble Kalman algorithms, termed SEnKF and SEnKS. These algorithms are based on recursive expressions similar to the ones justifying the traditional ensemble Kalman algorithms, but they are defined in an augmented space including the selection variable. From the two case studies, we conclude that multimodality is much better represented by the selection ensemble Kalman algorithms than by the traditional ones. We obtain RMSE reductions in the range of 20 to 30%.
The traditional ensemble Kalman algorithms provide an ensemble representation of the posterior model of interest hence making assessment of the posterior pdf simple. The selection ensemble Kalman algorithms are defined in an augmented space and conditioning on the selection variable must be made a posteriori. For this conditioning to be reliable, the ensemble size needs to be much larger than for the traditional algorithms. Hence, there is a trade-off between improved reproduction of multimodal characteristics of the phenomenon under study and the computational demands. In our case study, the ensemble size needed to be increased by approximately a factor of ten.
We have not fully explored the possibilities of robust estimation of model parameters in the conditioning of the selection variable. This robustification may reduce the ensemble size requirements. Note that parallelization in forwarding of the ensemble is possible and it will reduce the computer demands.
Author Contributions
Conceptualization, M.C. and H.O.; Formal analysis, M.C. and H.O.; Funding acquisition, H.O.; Investigation, M.C. and H.O.; Methodology, M.C. and H.O.; Project administration, H.O.; Resources, H.O.; Software, M.C.; Supervision, H.O.; Validation, M.C. and H.O.; Visualization, H.O.; Writing—original draft, M.C. and H.O. All authors have read and agreed to the published version of the manuscript.
Funding
This research and the APC are funded by the research initiative: ‘Uncertainty in Reservoir Evaluation’ at Department of Mathematical Sciences, NTNU, Trondheim, Norway.
Acknowledgments
The research is a part of the Uncertainty in Reservoir Evaluation (URE) activity at the Norwegian University of Science and Technology (NTNU), Trondheim, Norway.
Conflicts of Interest
The authors declare no conflict of interest.
Glossary
| discretized spatial variable at time t. | |
| Gaussian variables; basis and auxiliary variables, at time t. | |
| selection set. | |
| selection Gaussian variable at time t. | |
| expectation vector. | |
| covariance matrix. | |
| correlation matrix. | |
| matrix cross-correlation | |
| observation variable at time t. | |
| forward function at time t. | |
| observation function at time t. | |
| spatial correlation function. |
Appendix A
The algorithms detailed in Algorithms A1 and A2 follow the formalism in [4].
Algorithm A1 description: The SEnKF is a two-step algorithm. The first step is a traditional EnKF that evaluates . The second step consists of a sampling step where the target quantity is evaluated using from the first step.
| Algorithm A1 Selection Ensemble Kalman Filter (SEnKF) |
| A time series of ensembles is defined as and the -vector has the following covariance matrix: |
| 1. Initiate: |
| 2. No. of ensemble members |
| 3. Generate , |
| 4. Generate , |
| 5. , |
| 6. , |
| 7. Iterate: |
| 8. Conditioning: |
| 9. Estimate from |
| 10. , |
| 11. Forwarding: |
| 12. Generate , |
| 13. , |
| 14. If |
| 15. Generate , |
| 16. , |
| 17. |
| 18. Else |
| 19. |
| 20. End iterate |
| 21. Estimate from |
| 22. Assess |
| 23. |
| 24. End Algorithm |
| The ensemble represents . To assess , the sampling algorithm specified in [21] requires and which are estimated using the ensemble . |
Algorithm A2 description: The SEnKS is a two-step algorithm. The first step is a traditional EnKS that evaluates . The second step consists of a sampling step where the target quantity is evaluated using from the first step.
| Algorithm A2 Selection Ensemble Kalman Smoother (SEnKS) |
| Two time series of ensemble sets are defined as |
| for |
| and the accumulated ensemble set defined as
|
| The -vector has covariance matrix |
| The -vector has covariance matrix |
| 1. Initiate |
| 2. No. of ensemble members |
| 3. Generate , |
| 4. |
| 5. Generate , iid |
| 6. , |
| 7. |
| 8. Estimate from |
| 9. |
| 10. Iterate : |
| 11. Fowarding |
| 12. Generate , |
| 13. , |
| 14. |
| 15. Generate , iid |
| 16. , |
| 17. |
| 18. Estimate from |
| 19. |
| 20. End iterate |
| 21. |
| 22. Select |
| 23. For arbitrary , select corresponding ensemble from |
| 24. Estimate from |
| 25. Assess |
| 26. |
| 27. End Algorithm |
| The ensemble represents . To assess , the sampling algorithm in [21] requires and , which are estimated using the sub-ensemble of . |
References
- Kalman, R.E. A new approach to linear filtering and prediction problems. Trans. ASME-J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- McElhoe, B.A. An Assessment of the Navigation and Course Corrections for a Manned Flyby of Mars or Venus. IEEE Trans. Aerosp. Electron. Syst. 1966, AES-2, 613–623. [Google Scholar] [CrossRef]
- Evensen, G. Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics. J. Geophys. Res. 1994, 99, 10143. [Google Scholar] [CrossRef]
- Myrseth, I.; Omre, H. The Ensemble Kalman Filter and Related Filters. In Large Scale Inverse Problems and Quantification of Uncertainty; John Wiley & Sons, Ltd.: London, UK, 2010; chapter 11; pp. 217–246. [Google Scholar]
- Houtekamer, P.L.; Mitchell, H.L.; Pellerin, G.; Buehner, M.; Charron, M.; Spacek, L.; Hansen, B. Atmospheric Data Assimilation with an Ensemble Kalman Filter: Results with Real Observations. Mon. Weather. Rev. 2005, 133, 604–620. [Google Scholar] [CrossRef]
- Sakov, P.; Oliver, D.; Bertino, L. An Iterative EnKF for Strongly Nonlinear Systems. Mon. Weather. Rev. 2012, 140, 1988–2004. [Google Scholar] [CrossRef]
- Sklar, A. Random variables, joint distribution functions, and copulas. Kybernetika 1973, 9, 449–460. [Google Scholar]
- Isaaks, E.H.; Srivastava, R.M. Applied Geostatistics; Oxford University Press: New York, NY, USA, 1989. [Google Scholar]
- Bertino, L.; Evensen, G.; Wackernagel, H. Sequential Data Assimilation Techniques in Oceanography. Int. Stat. Rev. 2003, 71, 223–241. [Google Scholar] [CrossRef]
- Simon, E.; Bertino, L. Application of the Gaussian anamorphosis to assimilation in a 3D coupled physical-ecosystem model of the North Atlantic with the EnKF: A twin experiment. Ocean. Sci. 2009, 5, 495–510. [Google Scholar] [CrossRef]
- Xu, T.; Gomez-Hernandez, J. Characterization of non-Gaussian conductivities and porosities with hydraulic heads, solute concentrations, and water temperatures. Water Resour. Res. 2016, 52, 6111–6136. [Google Scholar] [CrossRef]
- Gu, Y.; Oliver, D. An Iterative Ensemble Kalman Filter for Multiphase Fluid Flow Data Assimilation. SPE J. 2007, 12, 438–446. [Google Scholar] [CrossRef]
- Evensen, G. Analysis of iterative ensemble smoothers for solving inverse problems. Comput. Geosci. 2018, 22, 885–908. [Google Scholar] [CrossRef]
- Dovera, L.; Della Rossa, E. Multimodal ensemble Kalman filtering using Gaussian mixture models. Comput. Geosci. 2010, 15, 307–323. [Google Scholar] [CrossRef]
- Rimstad, K.; Omre, H. Approximate posterior distributions for convolutional two-level hidden Markov models. Comput. Stat. Data Anal. 2013, 58, 187–200. [Google Scholar] [CrossRef]
- Grana, D.; Fjeldstad, T.; Omre, H. Bayesian Gaussian Mixture Linear Inversion for Geophysical Inverse Problems. Math. Geosci. 2017, 49, 493–515. [Google Scholar] [CrossRef]
- Besag, J. Spatial interaction and the statistical analysis of lattice systems. J. R. Stat. Soc. Ser. 1974, 36, 192–236. [Google Scholar] [CrossRef]
- Le Loc’h, G.; Beucher, H.; Galli, A.; Doligez, B. Improvement In The Truncated Gaussian Method: Combining Several Gaussian Functions. In Proceedings of the ECMOR IV—4th European Conference on the Mathematics of Oil Recovery; European Association of Geoscientists & Engineers: Røros, Norway, 1994. [Google Scholar] [CrossRef]
- Oliver, D.; Chen, Y. Data Assimilation in Truncated Plurigaussian Models: Impact of the Truncation Map. Math. Geosci. 2018, 50, 867–893. [Google Scholar] [CrossRef]
- Arellano-Valle, R.B.; Branco, M.D.; Genton, M.G. A unified view on skewed distributions arising from selections. Can. J. Stat. 2006, 34, 581–601. [Google Scholar] [CrossRef]
- Omre, H.; Rimstad, K. Bayesian Spatial Inversion and Conjugate Selection Gaussian Prior Models. arXiv 2018, arXiv:1812.01882. [Google Scholar]
- Conjard, M.; Omre, H. Spatio-temporal Inversion using the Selection Kalman Model. arXiv 2020, arXiv:stat.ME/2006.14343. [Google Scholar]
- Cappé, O.; Moulines, E.; Ryden, T. Inference in Hidden Markov Models (Springer Series in Statistics); Springer-Verlag: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Moja, S.; Asfaw, Z.; Omre, H. Bayesian Inversion in Hidden Markov Models with Varying Marginal Proportions. Math. Geosci. 2018, 51, 463–484. [Google Scholar] [CrossRef]
- Evensen, G. Data Assimilation; Springer-Verlag: Berlin Heidelberg, Germany, 2006; Volume 307. [Google Scholar] [CrossRef]
- Evensen, G. The Ensemble Kalman filter: Theoretical Formulation and Practical Implementation. Ocean. Dyn. 2003, 53, 343–367. [Google Scholar] [CrossRef]
- Burgers, G.; Van Leeuwen, P.J. On the Analysis Scheme in the Ensemble Kalman Filter. Mon. Weather. Rev. 1998, 126, 1719–1724. [Google Scholar] [CrossRef]
- Hyndman, R. Computing and Graphing Highest Density Regions. Am. Stat. 1996, 50, 120–126. [Google Scholar]
- Gaspari, G.; Cohn, S. Quarterly Journal of the Royal Meteorological Society. J. Comput. Graph. Stat. 1999, 125, 723–757. [Google Scholar]





















© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).