1. Introduction
One of the most common design issues in object-oriented systems is having a class with many responsibilities. During the maintenance and evolution activities of a system, new responsibilities may need to be added to the system. Due to time limits, software developers usually feel it is not necessary to create a separate class for a new responsibility and that responsibility can be added to one of the existing classes [
1]. After several cycles of maintenance and evolution, some classes in the system will end up having many responsibilities which will increase the maintenance cost of the system because a class with many responsibilities requires more effort and time to understand and maintain. In addition, a class with many responsibilities has many reasons to change because each responsibility the class has is an axis of change [
2]. Such a class needs to be refactored in order to improve its understandability and maintainability. The refactoring technique that is usually applied to overcome this issue is called Extract Class refactoring. It refers to the process of splitting a class that has many responsibilities into a set of smaller classes, each of which has one responsibility and one reason to change [
1].
Manually performing the process of the Extract Class refactoring costs much time and effort. Thus, several approaches (see, e.g., in [
3,
4,
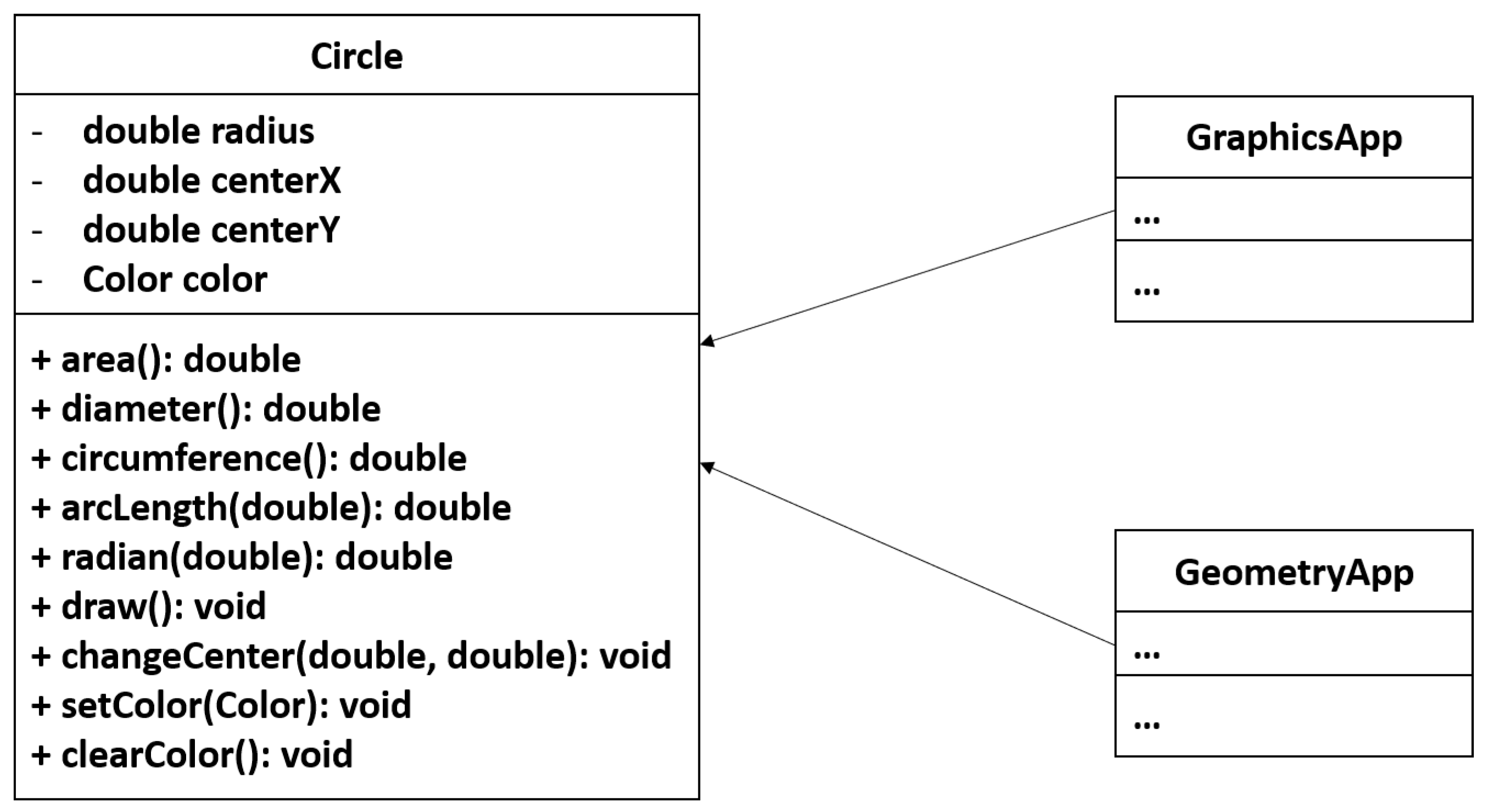
5]) have been introduced in the literature to automate and support the Extract Class refactoring. These approaches conduct the Extract Class refactoring based on factors internal to the class to be refactored such as structural and semantic dependency between the methods of the class. However, this internal view of the class is inadequate in many cases to automatically determine the responsibilities of the class and to highlight potential reasons that can cause changes to the class. For instance, consider the class
Circle shown in
Figure 1 that has four attributes and nine methods. The class has two client classes:
GeometryApp and
GraphicsApp. We refer to these two classes as clients of the class
Circle because they use methods in the class (see
Section 3). The class
GeometryApp performs some computational geometry. Thus, it uses the methods that provide geometric computations (e.g.,
) in the class
Circle, but never uses the methods that provide drawing services (e.g.,
). The other client class (i.e.,
GraphicsApp) uses the methods that provide drawing features in the class
Circle because it draws shapes on screen including circles.
It is obvious that the class
Circle has two responsibilities: one responsibility is to perform computational geometry and the other responsibility is to perform drawings on the screen. This may lead to increasing the cost and effort of future changes of the class. Assume that the client class
Graphics exerts a change on the method
in the class
Circle. This change may affect the client class
Geometry because it depends on the class
Circle. Therefore,
Geometry may need to be recompiled and retested even though it never uses the method
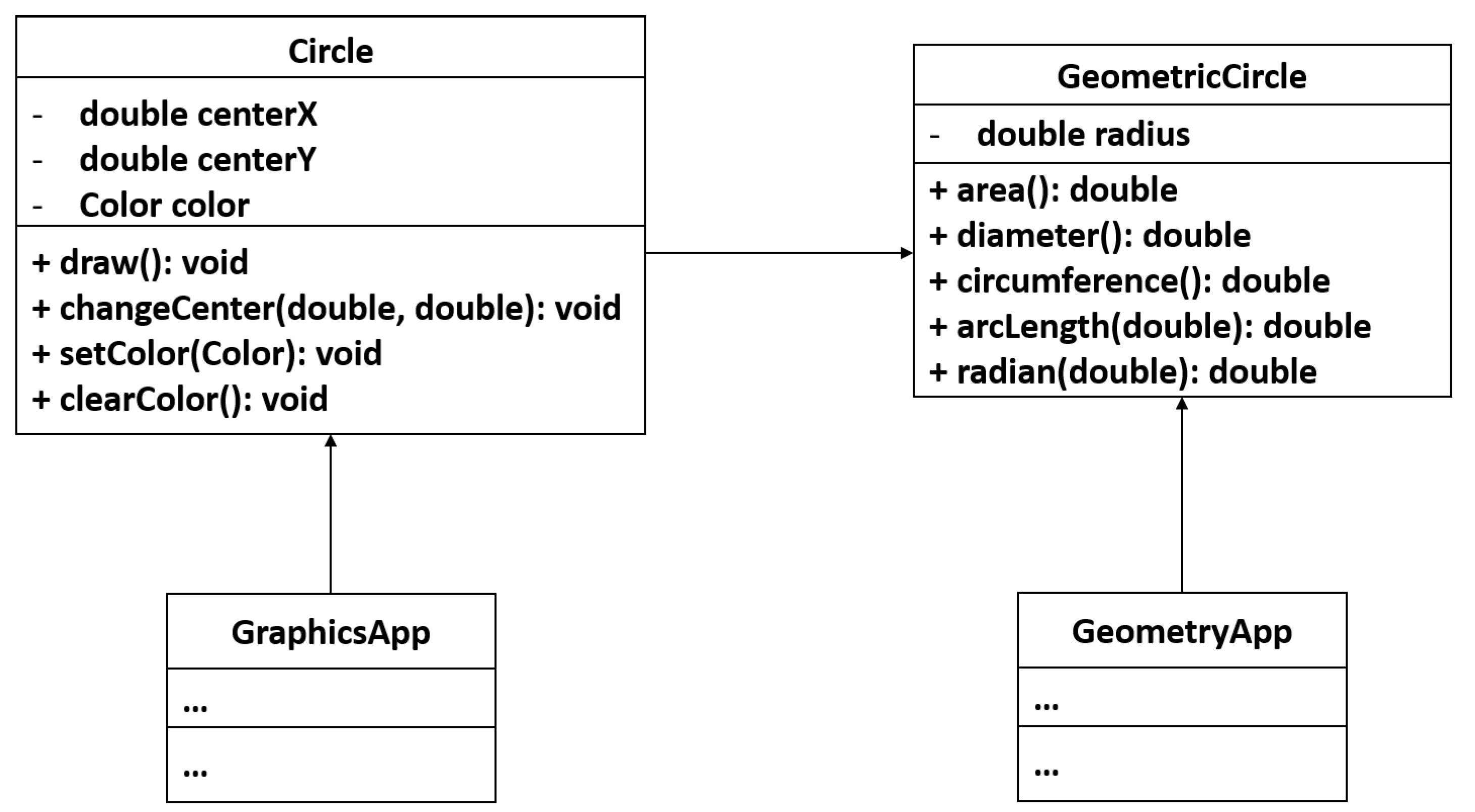
. In order to address this issue, we need to perform the Extract Class refactoring by splitting these two responsibilities into two separate classes as shown in
Figure 2. Existing approaches of the Extract Class refactoring may fail to suggest the refactoring solution shown in
Figure 2 because they perform the Extract Class refactoring based on structural and semantic relationships between the methods of the class. The structural relationships between methods in these approaches are measured based on the shared attributes between the methods while the semantic relationships are measured based on the common vocabularies in the documents, e.g., identifiers and comments of the methods. Thus, most of the methods of the class
Circle are—to some degree—structurally and semantically related to each other because they likely share attributes and vocabularies, e.g., radius.
To overcome the above issue, this study proposes a novel approach that performs the Extract Class refactoring based on the similarities in terms of clients between the methods of the class in question. The proposed approach can be more beneficial than the traditional refactoring techniques that consider the internal view of the class when performing the extract class refactoring. It identifies the different responsibilities of a class based on the usage of its clients. The intuition behind this is that if there are different sets of methods in the class that are used by different sets of clients than the class has different responsibilities from the perspective of its clients [
6,
7,
8]. In addition, the proposed approach supports the adherence to the
Interface Segregation Principle (ISP), which is an important object-oriented design principle that states “no client should be forced to depend on methods it does not use” [
2]. Our proposed approach is not meant to replace the existing approaches of the Extract Class refactoring but to complement them because considering the structural and semantic relationships between the methods of class can be useful in many cases of the Extract Class refactoring.
The paper extends a previous short paper [
9] that only presented an initial overview of the proposed approach without an empirical evaluation. In this paper, however, we present and extensively discuss the proposed approach for the Extract Class refactoring. In addition, we conduct an extensive empirical experimentation to evaluate the proposed approach based on real classes selected from two open source systems. The rest of the paper is organized as follows. In
Section 2, we present and discuss related work.
Section 3 presents the proposed approach. In
Section 4, we present the empirical evaluation of the proposed approach.
Section 5 gives the conclusion and future work.
2. Related Work
Martin Fowler [
1] who introduced the Extract Class refactoring suggested to perform the Extract Class refactoring on a given class by first identifying each subset of data and methods that contribute to a single responsibility and next extracting them into a separate class. However, identifying the different responsibilities and identifying the data and methods of each responsibility depends on the experience of the software engineer who is performing the refactoring and it can not be done in an objective way. Therefore, many approaches have been introduced in the literature to try to support and automate the Extract Class refactoring, see, e.g., in [
3,
4,
5,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22]. In the following, we discuss and summarize the approaches that are mostly relevant to our approach.
Simon et al. [
11] developed a visualization tool that supports four types of refactoring techniques including the Extract Class refactoring. The tool uses structural metrics to identify refactoring opportunities in the system in question. Marinescu [
12] proposed an approach called detection strategy to support software engineers in the identification of software modules, e.g., classes, that have a particular design flaw, e.g., a class that has many responsibilities. The approach suggests to formulate metrics-based rules that can directly capture software modules that are affected by a design flaw. The process of formulating metrics-based rules for detecting a design flaw consists of four steps. First, the symptoms of the design flaw are determined, e.g., the symptoms of the design flaw God Class include high class complexity, low class cohesion, and the access of foreign data. Second, an appropriate metric is chosen to measure each symptom, e.g,
[
23] to measure cohesion. Third, a filtering mechanism, e.g., less than filter, is used with each metric to detect the symptom, e.g., a value of
that is more than 10 is considered low class cohesion. The final step is to correlate the symptoms using
/
operators to detect the design flaw. Once a design flaw is detected, a refactoring opportunity exists. Similar to the work in [
12], a recent work [
24] proposed a metric-based detection technique for a set of bad smells (also known as design flaws or defects) including “Large Class” bad smell. The authors used size and cohesion metrics to detect large classes. They suggested four types of refactoring operations including the Extract Class refactoring to solve the bad smell Large Class.
Fokaefs et al. [
3] proposed an approach for the Extract Class refactoring which employs an agglomerative clustering algorithm based on the Jaccard distance between the methods of the class to be refactored. Structural similarity between two methods of the class is used to calculate the Jaccard distance between the two methods. The higher the Jaccard distance between the two methods is, the more probably the two methods will be in the same cluster. The resulting clusters represent the Extract Class opportunities that can be identified in the class to be refactored. Similar to the work in [
3], Fokaefs et al. [
10] introduced a tool that can identify Extract Class refactoring opportunities in God Classes. A software engineer can select one of the suggested refactoring opportunities and the tool will automatically apply it. The tool is as an extension of the JDeodorant Eclipse plugin and it employs structural metrics for extracting a class with higher cohesion from the class to be refactored.
Bavota et al. [
4] introduced an approach that splits the class to be refactored into two classes with higher cohesion than the original class based on structural and semantic similarities between the methods of class. The class is represented as a weighted graph where the nodes of the graph represent the methods of the class and the weighted edges of the graph represent the degree of structural and semantic similarities between the methods of the class. The approach uses the Max Flow-Min Cut algorithm [
25] to split the weighed graph representing the original class into two weighted subgraphs representing the two classes that can be extracted from the original class. Moreover, Bavota et al. [
5] introduced another approach that can automatically decompose the class to be refactored into two or more classes. The class is represented as a weighted graph in similar manner of their previous approach. Instead of using the Max Flow-Min Cut algorithm, they used a two-step clustering algorithm that removes the edges of the graph that have light weights to split the graph into a set of subgraphs representing the classes that can be extracted from the original class. Similarly, the authors of [
26] introduced an automated refactoring approach based on complex network theory. The approach automatically identifies three types of refactoring opportunities: Move Method, Move Field, and Extract Class, to remove the bad smells caused by the low cohesion and high coupling in a given system.
On a further note, the authors of [
27] conducted a systemic literature review to investigate the impact of refactoring on the design quality attributes. The author discussed and summarized results from 76 studies focusing on the impact of different refactoring scenarios including the Extract Class refactoring on quality attributes, e.g., cohesion. The presented results concluded that the Extract Class refactoring potentially improves the cohesion. To this end, it becomes clear that although the rich literature is a good addition to our view of the Extract Class refactoring, it only considers internal factors to the class to be refactored. The main limitation observed here is the applicability factor as they are not sufficient in many cases to identify ideal Extract Class refactoring opportunities within a class. In this paper, however, we introduce a new and innovative approach that automatically suggests a set of classes that can be extracted from a given class considering factors external to the class.
3. Extract Class Refactoring Based on Clients
In this section, we present basic definitions that reflect a theoretical model for an object-oriented system, and we follow with the proposed approach for the Extract Class refactoring.
3.1. A Theoretical Model
The proposed approach can be theoretically modeled based on the following set of definitions.
Definition 1 (Classes). is the set of classes that composes an object-oriented system, where n is a finite number of classes within the set {S}.
For example, the set of classes of the system
S shown in
Figure 3 is
.
Definition 2 (Methods of a class). Let . Then is the set of methods implemented in the class c, where k is a finite number of methods within the set {}.
The set of methods of the class
A shown in
Figure 3 is
.
Definition 3 (Clients of a method). Let and . Then, { and invokes or may, because of polymorphism, invoke {m} that is the set of clients of m}.
For Example,
is the set of clients of the methods
in the class
A shown in
Figure 3. The classes
B,
C, and
D are clients of the method
because each of them has a method that invokes the method
(i.e.,
,
, and
for
B,
C, and
D, respectively).
Definition 4 (Degree of client-based similarity between two methods).
Let and . Then, the degree of client-based similarity between the method and the method is defined by The value of ranges from where 0 means the methods share no common clients while 1 refer to the methods that have the same set of clients.
Consider the methods
and
in the class
A shown in
Figure 3. The clients of
is
and the clients of
is
. Using these two sets, we compute the degree of client-based similarity between the two methods as follows,
Definition 5 (Degree of client-based similarity between a method and a set of methods).
Let , , , and . Then, the degree of client-based similarity between the method m and the set of methods is defined by For example, the degree of client-based similarity between the method
in the class
A shown in
Figure 3 and the two methods
as follows,
Definition 6 (Cohesion Based on Client Similarity).
Let . Then, the Cohesion Based on Client Similarity (CBCS) for the class c is the ratio of the summation of the client-based similarity between each pair of methods in the class c to the total number of pairs of methods in c. It is formally defined as follows, when k is the number of methods in the class c. In order to better understand the way that the
is computed for a class, we compute it for the class
A shown in the illustrative example presented in
Figure 3.
3.2. Our Approach of the Extract Class Refactoring
The main steps of our approach are shown in
Figure 4. Given a class to be refactored, we first extract the methods of the class. Then, we determine the clients of each method using Definition 3. Once we have the clients of each method in the class, we compute the degree of client-based similarity between each pair of methods in the class using Definition 4 and store the results in a
matrix where
k is the number of methods in the class. The entry [
i][
j] of the
matrix holds the degree of client-based similarity between the method
and the method
.
Next, Algorithm 1 is applied which takes an input the set of methods in the class to be refactored, the matrix that holds the degree of client-based similarity between each pair of methods, and a threshold value. The algorithm returns a clutter, i.e., a family, of subsets from the input set of methods as an output. The algorithm classifies the input set of methods into different subsets of methods based on the client-based similarities between the methods. The input threshold value is used to determine if a method to be classified is added to an existing subset of methods or added to a new subset. Therefore, if the threshold value is high and the client-based similarities between the methods of the class to be refactored are generally low, each method will probably be added into a different subset, which means each extracted class will have only one method. To overcome this issue, the median of the non-zero client-based similarities of all pairs of methods in the class can be chosen as a threshold value.
Finally, Algorithm 2 is applied to avoid the extraction of classes that have a small number of methods (e.g., one method). The algorithm takes as an input the clutter F resulting from Algorithm 1, the minimum number of methods that each extracted class can have, and the matrix that holds the degree of client-based similarity between each pair of methods. The algorithm returns as an output a clutter of subsets such that each subset has a number of methods that is equal or more than the input minimum number of methods. Algorithm 2 merges any subset that has less number of methods than the input minimum number of methods with the subset that has the highest average of the client-based similarities. Each subset in the output of Algorithm 2 represents a candidate class that can be extracted from the class to be refactored.
The attributes as well as private and protected methods of the class are not considered in this work. However, they can be automatically distributed among the extracted classes suggested by our approach based the use of the attributes as well as private and protected methods by the public methods in the extracted classes. Each attribute can be added to the extracted class that has the highest number of methods that use the attribute; similarly, private and protected methods are distributed in the same way. Our approach automatically suggests the set of classes that can be extracted from a given class. A software engineer may evaluate the suggested classes and approve them or make some changes to them by moving the methods and attributes between suggested classes.
| Algorithm 1: ExtractClassRefactoring(, matrix) |
![Applsci 10 06038 i001]() |
3.3. An Application Example
In order to consider an example to show how the proposed approach can be applied, let class X be the class to be refactored. Let . Let the clients of each method in X be the following,
,
,
,
,
,
, and
.
| Algorithm 2: mergeSmallClasses(, matrix) |
![Applsci 10 06038 i002]() |
Given the above sets, we can compute the client-based similarity between each pair of methods of class
X using Definition 4. The matrix shown in
Table 1 holds the client-based similarity between each pair of methods of class
X. The entry [
i][
j] of the matrix holds the value of
.
Algorithm 1 is applied next to perform the Extract Class refactoring on the class
X. The algorithm takes three inputs:
, a
value, and the matrix shown in
Table 1. We set the value of
to 0.5, which is the median of the values in the matrix in
Table 1 excluding the zero values and the main diagonal of the matrix. The output of Algorithm 1 is the following clutter of subsets,
Each subset represents a class that can be extracted from X.
Algorithm 2 can be applied next to avoid extracting classes with a small number of methods. The algorithm takes three inputs: the clutter
F (i.e., the output of Algorithm 1);
, which is a chosen value for the minimum number of methods that each extracted class can have; and the matrix shown in
Table 1. In this example,
. The following is the output of Algorithm 2,
The output of Algorithm 2 shows that the subset is merged with the subset . Thus, two classes are suggested to be extracted from the original class X in our example. The first extracted class has the following set of methods and the second extracted class has the following set of methods .
4. Empirical Evaluations Utilizing Open Source Systems
To evaluate the proposed approach, we considered two real systems in this study:
Tomcat [
28] version
and
Ant [
29] version
. Both of the two systems are open source, object-oriented, and written in Java.
Tomcat is a system used to implement
Java Servlet, JavaServer Pages, and JavaWebSocket technologies and
Ant is a Java library and command-line tool used mainly to build Java applications. Ten large classes are selected from each system based on the following two criteria. (1) The class has at least 8 public methods and (2) the cardinality of the union of the clients of the methods is at least 2.
Table 2 and
Table 3 report the name of the
Blob, the name of the package to which the class belongs, the number of public methods in the class (#Methods), and the cardinality of the union of the clients of each method in the class (#Clients).
Our goal in the empirical evaluation is to investigate if the proposed refactoring approach can suggest to extract classes with cohesive responsibilities from a given class that has many non-cohesive responsibilities. For this purpose, we formulate the following research question.
RQ: Do the extracted classes suggested by the proposed approach have higher cohesion than the original classes?
To answer the above research question, we compare the cohesion of the original classes with the cohesion of the extracted classes. We measure class cohesion using
given in Definition 6.
is a variation of
which was proposed and validated in a previous works [
7,
8]. The original metric
measures the cohesion of a class based on the ratio of the summation of client-based class cohesion per each client of the class to the total number of clients of the class, where the client-based class cohesion per a client is defined as the number of methods used by the client divided by the total number of methods in the class. The reason of why we consider
instead of
is that
computes the similarities between each pair of methods in the class in order to measure the class cohesion while
does not, and cohesion metrics that compute the similarities between the methods are better in identifying the non-cohesive (dissimilar) methods that need to be separated into different classes [
30].
We developed two tools to automate the application of our proposed approach. The first tool is implemented in
Java and it is based on
Eclipse JDT [
31]. The tool automatically extracts the public methods of the classes of the considered system and the clients of each method, and calculates the client-based similarity between each pair of methods using Definition 4. The input of the tool is the source code of the system and output are the set of public methods of each class and a
matrix that has the client-based similarity between each pair of public methods in the class, where
k is the number of public methods in the class. The second tool we developed is a Python tool that takes the output of the Java tool and automatically applies Algorithm 1 and Algorithm 2. The output of the Python tool is the set of classes that are suggested to be extracted from the class in question. In addition, the python tool calculates the value of
for the original class and for each class suggested to be extracted from the original class.
The research question of our empirical study investigates whether the cohesion of the extracted classes identified by our approach is higher than the cohesion of the original classes. We believe that the extracted classes will have higher cohesion values than the original classes. Thus, we set up the following null and alternative hypotheses for our research question.
H0: The difference between the CBCS values of the original classes and the CBCS values of the extracted classes suggested by our approach is 0.
H1: The original classes have less CBCS values than CBCS values of the extracted classes suggested by our approach.
4.1. Results And Discussions
Using our tools, we applied the proposed approach on the two considered systems.
Table 4 and
Table 5 report the results for the ten classes selected from
Tomcat system and the ten classes selected from
Ant system, respectively. We set the refactoring threshold (i.e.,
used in Algorithm 1) for each considered class to the median of the values of the client-based similarities between all the pairs of the methods in the class excluding the zero values and the main diagonal entries. We set the minimum number of methods each extracted class can have to 2, i.e.,
used in Algorithm 2. This is due to unreasonability to extract classes that have only one method. The results in
Table 4 and
Table 5 lead to the following observations.
The cohesion (i.e., values) of the extracted classes suggested by our approach are higher than the original classes for all the selected classes.
In most of the cases, the values of the extracted classes increased to more than two times that of the value in original class.
In some cases, the extracted classes have relatively low values (e.g., classes extracted from NoBodyResponse class in Tomcat). We investigated these cases and we found the main reason behind that is the values of the client-based similarities between most of the pairs of methods in the original class are 0.
The number of extracted classes varies from cases to cases. Two factors can influence the number of the extracted classes: the refactoring threshold and the number of methods in the original class. The higher the value of the refactoring threshold is, the more likely the number of extracted classes will increase (e.g., the cases of the classes Extension and VAJBuildInfo in Ant system). Similarly, the higher the number of methods in the original class, the more classes will probably be extracted (e.g., the case of the class Request in Tomcat system).
We further conducted the paired samples
t-test using the
R software [
32] in order to test our null
H0 and alternative
H1 hypotheses (see
Table 6). The paired samples
t-test is a statistical procedure used to compare the means between two related sets of samples of the same size. In our case, the two sets are the
values of the original classes and the averages of
values of the extracted classes suggested by our approach for each original class (the reader is directed to data presented in
Table 4 and
Table 5). In other words, a pair of samples has the
of an original class and the average of the
values of the classes extracted from that original class. We considered the averages of
values of extracted classes instead of
value of each extracted class because the total number of the extracted classes are greater the number of the original classes. The results shown in
Table 6 are statistically significant because the
p-values are less than
. Based on these results, we can reject the null hypothesis
H0 and accept the alternative
H1.
4.2. Threats to Validity
Several issues may affect the validity of the results in our empirical study. The first issue is that we evaluated our approach by comparing the cohesion of extracted classes to the cohesion of the original classes and the metric used to measure cohesion (i.e., ) is based on information that is used in our refactoring approach. measures the cohesion based on the client-based similarity between each pair of methods in the class and our approach uses the client-based similarity to identify pairs of methods that should belong to the same extracted class. Thus, it is most likely the extracted classes will have higher values than the original class. However, our main purpose was to show an empirical evidence based on real classes that extracted classes resulting from our algorithms have higher values than the original classes.
Another issue is that we did not evaluate the extracted classes in terms of coupling. Coupling refers to the degree of relatedness between classes. Cohesion and coupling are two quality attributes that can have an inverse relationship, meaning the improvement of one quality attribute can lead to the deterioration of the other quality attribute [
13,
14]. Thus, we need to keep balance between cohesion and coupling when performing the extract class refactoring [
5,
30]. However, the focus of this paper is to use the client-based cohesion to support the extract class refactoring, as they have not been exploited in previous approaches. Employing metrics of coupling and other aspects of cohesion, such as structural and semantic cohesion, together with the metrics of client-based similarity to support the Extract Class refactoring, is left for future research.
The last issue which may affect the validity of our results is that the extracted classes suggested by the proposed approach were not evaluated by software engineers. It is important to evaluate the solutions suggested by newly proposed refactoring approaches by a number of software engineers [
5]. If the majority of the evaluators (i.e., Software Engineers) are not satisfied with solutions suggested by a refactoring approach, the applicability of the approach is questionable. However, solutions that improve important attributes such as cohesion are expected to satisfy software engineers. Thus, we evaluated our approach based on cohesion using the metric
. Several well-known papers in the literature (see, e.g., in [
15,
16,
17,
18]) have used quality metrics to evaluate newly proposed refactoring techniques.
5. Conclusions and Future Work
Software systems that have a long lifetime (e.g., enterprise systems) usually undergo evolutionary changes in order to remain useful due to various reasons including changes to business rules, user requirements, hardware, and platforms. Unfortunately, most of the programmers who are responsible for making these changes in a system modify the source code of that system rapidly without considering the resultant effects on the design of the system. As a result, the design quality of the system deteriorates, and the system becomes very difficult to understand and change. This paper has introduced a novel approach that performs the Extract Class refactoring. The proposed approach used the clients of the class to identify classes that can be extracted from that class. An empirical study on classes selected from two open source systems was conducted to evaluate the proposed approach. The results of the empirical study highlight the potential usefulness of the proposed approach. The future work should further conduct much larger empirical studies that quantitatively analyze the relationships among multiple approaches for the Extract Class refactoring, considering the approach proposed in this paper, and real cases of Extract Class refactoring for the purpose of identifying the factors that can be used to better classify and separate different responsibilities of a class.









{kind=link}
{kind=link}
{kind=link}
{kind=link}