Comparing Deep Learning and Statistical Methods in Forecasting Crowd Distribution from Aggregated Mobile Phone Data




Abstract
:1. Introduction
2. Dataset
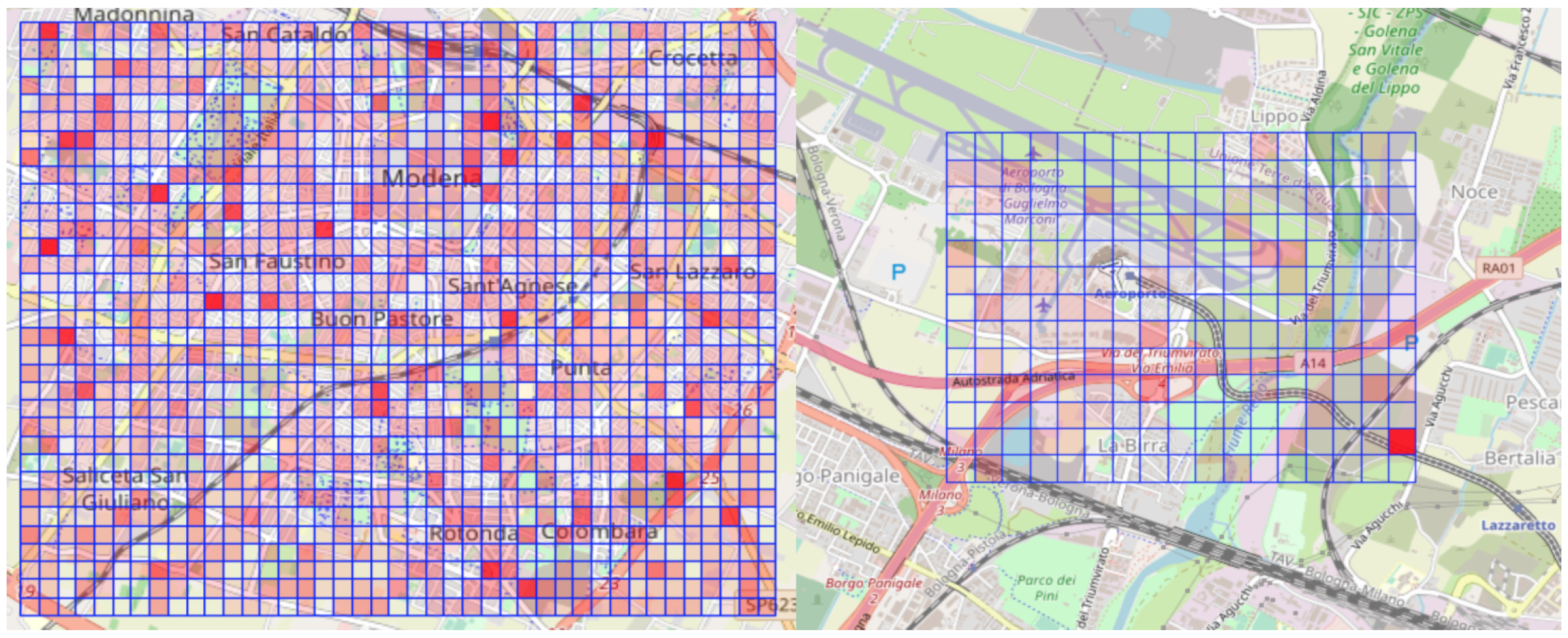
2.1. Dataset as a Grid over the Urban Area
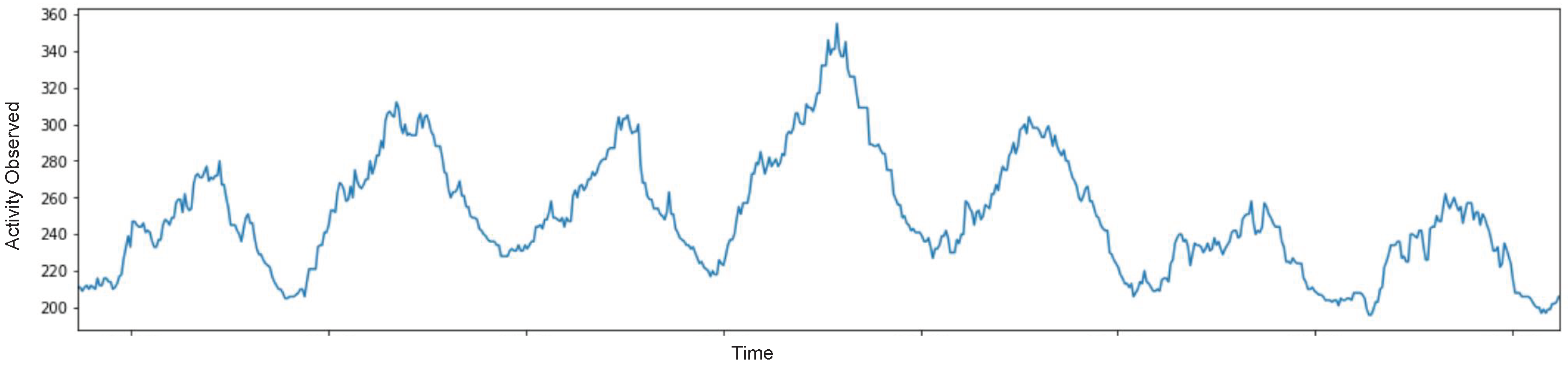
2.2. Dataset as Time Series of People Presence
3. Methodology
3.1. Auto-Correlation in the Time-Series
3.2. Data Transformation
3.3. Statistical Methods
3.3.1. Seasonal Average
3.3.2. Autoregressive Models
3.3.3. The Arima Model
- a, which is the lag order or the number of lag observations included in the model;
- d, which is the number of times that the raw observations are differentiated;
- q, which is the size of the moving average window used to compute the mean.
3.3.4. Holt-Winters Exponential Smoothing
- y is the observation in time t
- S is the smoothed observation
- b is the trend factor
- I is the seasonal index
- L is the number of periods is a season
- is the forecast at m periods ahead
3.3.5. Prophet
3.4. Deep Learning Neural Networks-Based Forecasting Methods
3.4.1. Multilayer Perceptron
3.4.2. Convolutional Neural Networks
3.4.3. Long Short-Term Memory Networks
3.4.4. Hybrid Cnn-Lstm Model
3.5. Tuning the Forecasting Methods
3.5.1. Statistical Methods Parameters
- ARIMA. To find the best set of parameters for the ARIMA model, we performed a grid-search by trying different combinations of values for its three parameters a, d and q. The grid-search algorithms finds the best set of parameters for ARIMA by using as an optimization criteria the Root Mean Square Error of the residuals of the fitting process. Only the set of parameters yielding the lowest Root Mean Square Error was picked for performing forecast.
- Exponential Smoothing. As with what we did with ARIMA, also for ETS we tuned the parameters of the model by performing a grid-search with as criteria of optimization the RMSE error. Also in this case, only the set of parameters that yields the lowest RSME is picked, and this was done for every time series of each cell in the grid.
- Autoregression. For this forecasting model the Statsmodels library feature allows automatically selecting an appropriate lag value in order to make predictions.
- Prophet. For Prophet, instead, we did not optimize any parameter, but simply relied on the capability of its implementation to adapt to data as described by its creators in [9].
3.5.2. Deep Learning Methods Hyper-Parameters
- For the MLP neural network, we used a single hidden layer with 100 neurons. We analyzed the trend of the loss function with a different number of nodes from 100 to 900, observing no major differences. Regarding the number of hidden layers we empirically discovered that by adding more than one layer to MLP neural network we would just increase the time of training without benefits on the forecasting performance.
- For the CNN, we used a convolutional layer with 64 filters, a max-pooling with size equal to 2, followed by a dense layer with 50 neurons. Even in this case, we observed no significant changes with more complex architectures. As already said, the Adam optimizer was used during training.
- For the Encoder-Decoder LSTM, we used two layers containing 20 neurons each which we chose as a trade-off between simplicity and performance, similarly to what we did for MLP and CNN. As already said, the Adam optimizer was used during training.
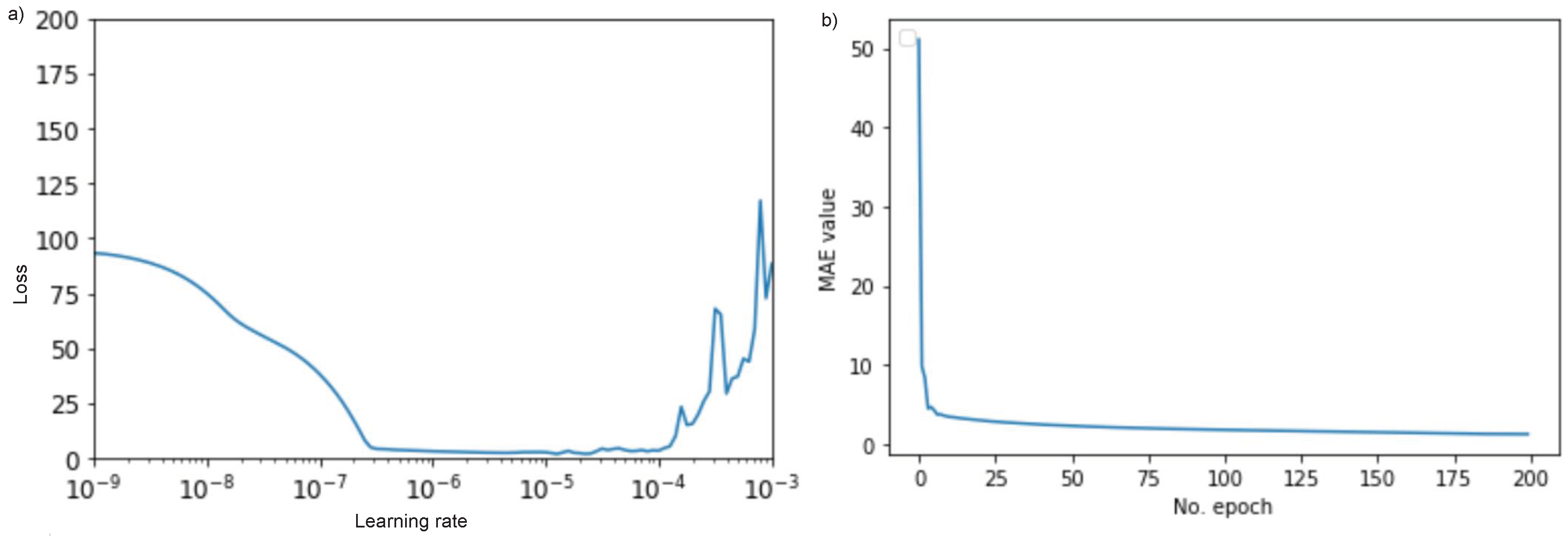
- The CNN-LSTM architecture as shown in Figure 9 has one convolutional layer with 64 filters. Its output can then be interpreted by an LSTM decoder which contains 2 levels of 64 neurons each. Before the final output layer, two dense layers with 32 and 16 neurons, respectively, are used. For this model, we used the SGD optimizer and by experimenting with the learning rate as shown in Figure 8a we were able to pick the one that gives a stable decreasing loss as in Figure 8b. We have prepared a repository on Github with the CNN-LSTM (https://github.com/alketcecaj12/cnn-lstm) model with data from one cell.
3.6. Model Evaluation and Forecasting Performance Measures
- Mean Absolute Percentage Error (MAPE), which is scale-independent forecasting measure and is defined as:where is the observation at time t and is the corresponding predicted value. In simpler terms, MAPE is the average error in percentage of the observation we are trying to forecast. MAPE is thus scale-independent, so it represents the perfect fit for our grid dataset composed of thousands of cells where each cell may have levels of mobile activity in a very different scale.
- Root Mean Squared Error (RMSE), a widely employed error measure defined as:
- Maximum Absolute Error (MAXAE) considers the maximum error (in absolute value) that a given predictor can make, thus taking into account the worst-case scenario.
4. Experiments
- We first consider a 24-h-forward forecasting scenario, which allows comparing the different methods by using the forecasting performance measures mentioned in Section 3.6.
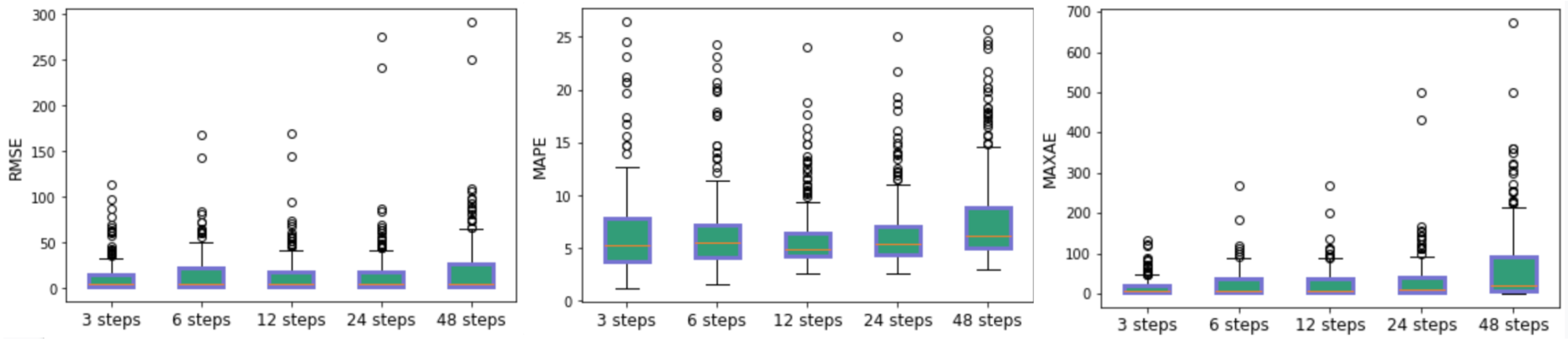
- As a second experiment, we analyze the variation in the prediction error as a function of the number of steps to forecast. So in this case we show how varies each of forecasting measure by increasing the number of steps to forecast.
- Finally, we separately compare the considered approaches on two different types of cells in our dataset, namely those with regular and periodic time series, and those with high variability, i.e., cells which contain strong anomalies and irregular trends. Two example time series, one for each cell category, are shown in Figure 10a,b respectively. We first define a criterion to distinguish between the two types of cells, and then evaluate the performance of deep learning and statistical methods for both types.
4.1. 24-h-Ahead Forecasting Analysis
4.2. Performance Along Different Forecasting Horizons
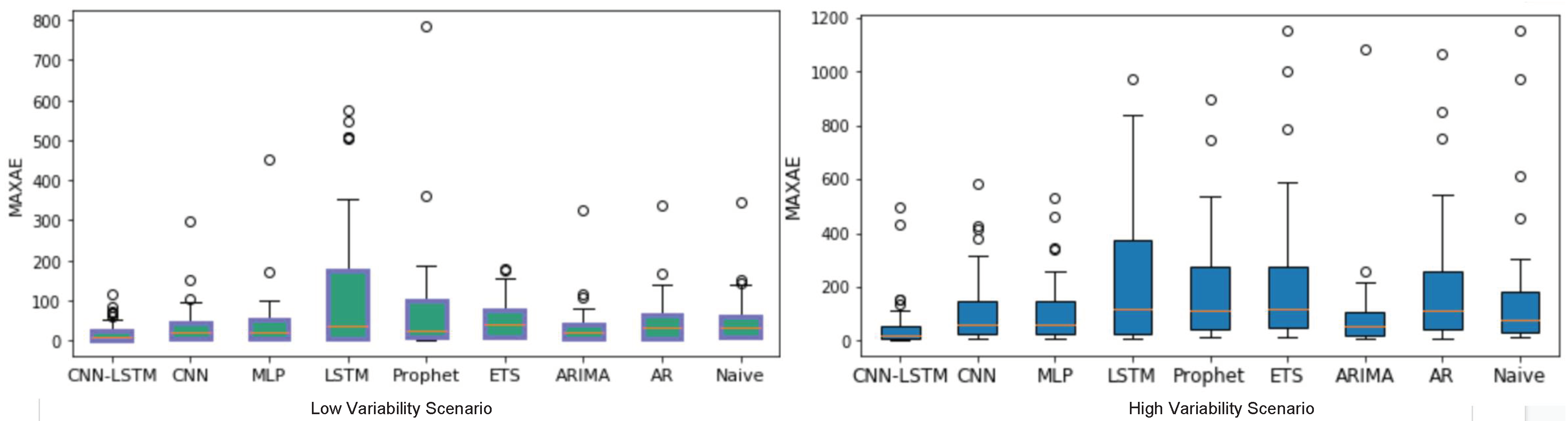
4.3. Low- and High-Variability Cells
- Both statistical and deep learning methods show interesting results. In particular, the ARIMA statistical method and the CNN-LSTM deep learning model have proven to be the top-performers for each category.
- Performance measures such as RMSE and MAPE show that both ARIMA and CNN-LSTM are capable of delivering good forecasting results. These two measures show that none of such methods is significantly better than the other.
- The MAXAE measure shows that deep learning methods such as CNN-LSTM are significantly better than the statistical methods such as ARIMA in handling the anomalies in particular in high variability context and keeping the MAXAE low even for longer forecasting horizons.
- The ease of use of deep learning methods when compared to statistical methods makes them a better choice when the forecasting service has to be delivered for thousands of different time series as we do in this work. In this sense they provide a one-size-fits-all solution which as our work shows can yield interesting results.
5. Related Work
- as a major novelty, the type of data—aggregated mobile phone activity—being used is different from that of other works reviewed in this section, for what concerns both time granularity and spatial extension.
- the set of statistical and deep learning methods that are used for the comparative performance analysis as well as the performance measures used for such analysis.
- the experimental investigation of our research which does not aim to establish a winner between the forecasting methods but to contextualize which one is best in which context.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mamei, M.; Colonna, M. Estimating attendance from cellular network data. Int. J. Geogr. Inf. Sci. 2016, 30, 1281–1301. [Google Scholar] [CrossRef] [Green Version]
- Calabrese, F.; Ratti, C.; Colonna, M.; Lovisolo, P.; Parata, D. Real-Time Urban Monitoring Using Cell Phones: A Case Study in Rome. IEEE Trans. Intell. Transp. Syst. 2011, 12, 141–151. [Google Scholar] [CrossRef]
- Khodabandelou, G.; Gauthier, V.; El-Yacoubi, M.; Fiore, M. Population estimation from mobile network traffic metadata. In Proceedings of the 17th International Symposium on a World of Wireless, Mobile and Multimedia Networks (WOWMOM), Coimbra, Portugal, 21–24 June 2016. [Google Scholar]
- Khodabandelou, G.; Gauthier, V.; Fiore, M.; El-Yacoubi, M.A. Estimation of Static and Dynamic Urban Populations with Mobile Network Metadata. IEEE Trans. Mob. Comput. 2019, 18, 2034–2047. [Google Scholar] [CrossRef] [Green Version]
- Zhang, G.; Rui, X.; Poslad, S.; Song, X.; Fan, Y.; Ma, Z. Large-Scale Fine-Grained Spatial and Temporal Analysis and Prediction of Mobile Phone Users Distributions Based upon a Convolution Long Short-Term Model. Sensors 2019, 19, 2156. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gambs, S.; Killijian, M.O.; Núñez del Prado Cortez, M. De-anonymization attack on geolocated data. Special Issue on Theory and Applications in Parallel and Distributed Computing Systems. J. Comput. Syst. Sci. 2014, 80, 1597–1614. [Google Scholar] [CrossRef]
- Hyndman, R.; Athanasopoulos, G. Forecasting: Principles and Practice, 2nd ed.; OTexts: Melbourne, Australia, 2018. [Google Scholar]
- Cecaj, A.; Lippi, M.; Mamei, M.; Zambonelli, F. Forecasting Crowd Distribution in Smart Cities. In Proceedings of the IEEE International Conference on Sensing, Communication and Networking, Como, Italy, 22–26 June 2020. [Google Scholar]
- Taylor, S.J.; Letham, B. Forecasting at scale. PeerJ 2018, 72, 37–45. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Yang, J.B.; Nguyen, M.N.; San, P.P.; Li, X.L.; Krishnaswamy, S. Deep Convolutional Neural Networks on Multichannel Time Series for Human Activity Recognition. In Proceedings of the 24th International Conference on Artificial Intelligence (IJCAI’15), Buenos Aires, Argentina, 25–31 July 2015; AAAI Press: Buenos Aires, Argentina, 2015; pp. 3995–4001. [Google Scholar]
- Karim, F.; Majumdar, S.; Darabi, H.; Harford, S. Multivariate LSTM-FCNs for time series classification. Neural Netw. 2019, 116, 237–245. [Google Scholar] [CrossRef] [Green Version]
- Qin, D.; Yu, J.; Zou, G.; Yong, R.; Zhao, Q.; Zhang, B. A Novel Combined Prediction Scheme Based on CNN and LSTM for Urban PM2.5 Concentration. IEEE Access 2019, 7, 20050–20059. [Google Scholar] [CrossRef]
- Lim, C.; McAleer, M. Time series forecasts of international travel demand for Australia. Tour. Manag. 2002, 23, 389–396. [Google Scholar] [CrossRef]
- Cho, M.Y.; Hwang, J.C.; Chen, C.S. Customer short term load forecasting by using ARIMA transfer function model. In Proceedings of the 1995 International Conference on Energy Management and Power Delivery EMPD ’95, Singapore, 21–23 November 1995; Volume 1, pp. 317–322. [Google Scholar]
- Koutroumanidis, T.; Iliadis, L.; Sylaios, G.K. Time-series modeling of fishery landings using ARIMA models and Fuzzy Expected Intervals software. Environ. Model. Softw. 2006, 21, 1711–1721. [Google Scholar] [CrossRef]
- Han, P.; Wang, P.X.; Zhang, S.Y.; Zhu, D.H. Drought forecasting based on the remote sensing data using ARIMA models. Mathematical and Computer Modelling in Agriculture. Math. Comput. Model. 2010, 51, 1398–1403. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. Statistical and Machine Learning forecasting methods: Concerns and ways forward. PLoS ONE 2018, 13, e194889. [Google Scholar] [CrossRef] [Green Version]
- Rong, C.; Feng, J.; Li, Y. Deep Learning Models for Population Flow Generation from Aggregated Mobility Data. In Proceedings of the UbiComp’19: The 2019 ACM International Joint Conference on Pervasive and Ubiquitous Computing, London, UK, 9–13 September 2019; pp. 1008–1013. [Google Scholar] [CrossRef]
- Qiu, X.; Zhang, L.; Ren, Y.; Suganthan, P.N.; Amaratunga, G. Ensemble deep learning for regression and time series forecasting. In Proceedings of the 2014 IEEE Symposium on Computational Intelligence in Ensemble Learning (CIEL), Orlando, FL, USA, 9–12 December 2014; pp. 1–6. [Google Scholar]
- Crone, S.F.; Hibon, M.; Nikolopoulos, K. Advances in forecasting with neural networks? Empirical evidence from the NN3 competition on time series prediction. Special Section 1: Forecasting with Artificial Neural Networks and Computational Intelligence Special Section 2: Tourism Forecasting. Int. J. Forecast. 2011, 27, 635–660. [Google Scholar] [CrossRef]
- Gamboa, J.C.B. Deep Learning for Time-Series Analysis. arXiv 2017, arXiv:1701.01887. [Google Scholar]
- Tseng, F.M.; Yu, H.C.; Tzeng, G.H. Combining neural network model with seasonal time series ARIMA model. Technol. Forecast. Soc. Chang. 2002, 69, 71–87. [Google Scholar] [CrossRef]
- Babu, C.N.; Reddy, B.E. A moving-average filter based hybrid ARIMA–ANN model for forecasting time series data. Appl. Soft Comput. 2014, 23, 27–38. [Google Scholar] [CrossRef]
- Khashei, M.; Bijari, M. A novel hybridization of artificial neural networks and ARIMA models for time series forecasting. The Impact of Soft Computing for the Progress of Artificial Intelligence. Appl. Soft Comput. 2011, 11, 2664–2675. [Google Scholar] [CrossRef]
- Wang, C.H.; Cheng, H.Y.; Deng, Y.T. Using Bayesian belief network and time-series model to conduct prescriptive and predictive analytics for computer industries. Comput. Ind. Eng. 2018, 115, 486–494. [Google Scholar] [CrossRef]
- Kuremoto, T.; Kimura, S.; Kobayashi, K.; Obayashi, M. Time series forecasting using a deep belief network with restricted Boltzmann machines. Advanced Intelligent Computing Theories and Methodologies. Neurocomputing 2014, 137, 47–56. [Google Scholar] [CrossRef]
- Jiang, Y.; Song, Z.; Kusiak, A. Very short-term wind speed forecasting with Bayesian structural break model. Renew. Energy 2013, 50, 637–647. [Google Scholar] [CrossRef]
- Kocadağlı, O.; Aşıkgil, B. Nonlinear time series forecasting with Bayesian neural networks. Expert Syst. Appl. 2014, 41, 6596–6610. [Google Scholar] [CrossRef]
- Chen, G.; Hoteit, S.; Carneiro Viana, A.; Fiore, M.; Sarraute, C. Forecasting Individual Demand in Cellular Networks. In Rencontres Francophones sur la Conception de Protocoles, l’Évaluation de Performance et l’Expérimentation des Réseaux de Communication; HAL: Roscoff, France, 2018. [Google Scholar]
- Alon, I.; Qi, M.; Sadowski, R.J. Forecasting aggregate retail sales: A comparison of artificial neural networks and traditional methods. J. Retail. Consum. Serv. 2001, 8, 147–156. [Google Scholar] [CrossRef]
- Cerqueira, V.; Torgo, L.; Soares, C. Machine Learning vs Statistical Methods for Time Series Forecasting: Size Matters. arXiv 2019, arXiv:stat.ML/1909.13316. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | MAPE | RMSE | MAXAE | |||
|---|---|---|---|---|---|---|
| Mean | Std.Dev | Mean | Std.Dev | Mean | Std.Dev | |
| LSTM | 32.3 | 41.6 | 66.5 | 122.6 | 182.5 | 220.1 |
| ETS | 28.8 | 9.2 | 48.6 | 61.7 | 130.74 | 164.6 |
| AR | 19.7 | 10.3 | 36.9 | 49.6 | 116.3 | 149.8 |
| CNN | 12.0 | 9.1 | 20.5 | 26.7 | 68.8 | 90.88 |
| MLP | 11.6 | 7.4 | 21.5 | 27.4 | 72.5 | 93.1 |
| Naive | 9.0 | 2.4 | 17.7 | 20.7 | 91.8 | 132.5 |
| Prophet | 8.8 | 4.8 | 58.8 | 98.5 | 134.6 | 173.2 |
| CNN-LSTM | 7.9 | 3.7 | 14.9 | 28.6 | 32.6 | 54.79 |
| ARIMA | 7.7 | 3.9 | 13.9 | 15.9 | 57.0 | 69.9 |
| Methods | MAPE | ||||
|---|---|---|---|---|---|
| 3 Steps | 6 Steps | 12 Steps | 24 Steps | 48 Steps | |
| LSTM | 4.78 | 5.95 | 19.6 | 32.34 | 121.95 |
| ETS | 17.38 | 22.29 | 25.5 | 28.79 | 27.29 |
| AR | 4.29 | 8.26 | 16.5 | 19.72 | 21.34 |
| CNN | 6.15 | 8.37 | 10.22 | 11.99 | 14.23 |
| MLP | 6.35 | 7.68 | 9.48 | 11.63 | 14.06 |
| Prophet | 3.17 | 6.87 | 7.69 | 8.74 | 11.8 |
| ARIMA | 5.65 | 6.26 | 6.66 | 7.44 | 9.21 |
| CNN-LSTM | 6.45 | 6.41 | 5.93 | 6.35 | 7.8 |
| Methods | RMSE | ||||
|---|---|---|---|---|---|
| 3 Steps | 6 Steps | 12 Steps | 24 Steps | 48 Steps | |
| LSTM | 10.0 | 13.09 | 21.24 | 66.46 | 313.35 |
| ETS | 41.23 | 55.08 | 45.01 | 48.59 | 47.47 |
| AR | 8.39 | 16.75 | 32.14 | 36.95 | 39.75 |
| CNN | 12.1 | 14.93 | 17.12 | 20.5 | 23.46 |
| MLP | 11.83 | 14.45 | 17.89 | 21.53 | 25.01 |
| Prophet | 31.5 | 31.48 | 37.0 | 78.84 | 57.95 |
| ARIMA | 11.38 | 12.25 | 12.57 | 13.87 | 17.94 |
| CNN-LSTM | 12.24 | 14.72 | 13.93 | 14.93 | 20.63 |
| Methods | MAXAE | ||||
|---|---|---|---|---|---|
| 3 Steps | 6 Steps | 12 Steps | 24 Steps | 48 Steps | |
| LSTM | 43.78 | 54.57 | 78.57 | 182.51 | 868.55 |
| ETS | 123.17 | 156.53 | 126.46 | 130.74 | 132.73 |
| AR | 40.59 | 65.84 | 109.73 | 116.31 | 124.63 |
| CNN | 52.56 | 47.09 | 57.48 | 68.84 | 78.74 |
| MLP | 40.24 | 49.23 | 61.18 | 72.53 | 84.87 |
| Prophet | 39.23 | 52.52 | 63.57 | 134.56 | 122.25 |
| ARIMA | 46.11 | 51.16 | 63.15 | 62.54 | 74.16 |
| CNN-LSTM | 15.74 | 22.49 | 24.36 | 32.61 | 65.96 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cecaj, A.; Lippi, M.; Mamei, M.; Zambonelli, F. Comparing Deep Learning and Statistical Methods in Forecasting Crowd Distribution from Aggregated Mobile Phone Data. Appl. Sci. 2020, 10, 6580. https://doi.org/10.3390/app10186580
Cecaj A, Lippi M, Mamei M, Zambonelli F. Comparing Deep Learning and Statistical Methods in Forecasting Crowd Distribution from Aggregated Mobile Phone Data. Applied Sciences. 2020; 10(18):6580. https://doi.org/10.3390/app10186580
Chicago/Turabian StyleCecaj, Alket, Marco Lippi, Marco Mamei, and Franco Zambonelli. 2020. "Comparing Deep Learning and Statistical Methods in Forecasting Crowd Distribution from Aggregated Mobile Phone Data" Applied Sciences 10, no. 18: 6580. https://doi.org/10.3390/app10186580
APA StyleCecaj, A., Lippi, M., Mamei, M., & Zambonelli, F. (2020). Comparing Deep Learning and Statistical Methods in Forecasting Crowd Distribution from Aggregated Mobile Phone Data. Applied Sciences, 10(18), 6580. https://doi.org/10.3390/app10186580