MAKEDONKA: Applied Deep Learning Model for Text-to-Speech Synthesis in Macedonian Language

 , ,
, ,  ,
,  and
and
Abstract
:1. Introduction
- Development of the first open-source TTS model for Macedonian language.
- Development of the first high-quality speech dataset for Macedonian language required for training TTS model, which consists of 10,433 short audio clips of a single female speaker.
- Retraining an architecture of fully end-to-end TTS synthesis, from text records to inference for Macedonian language.
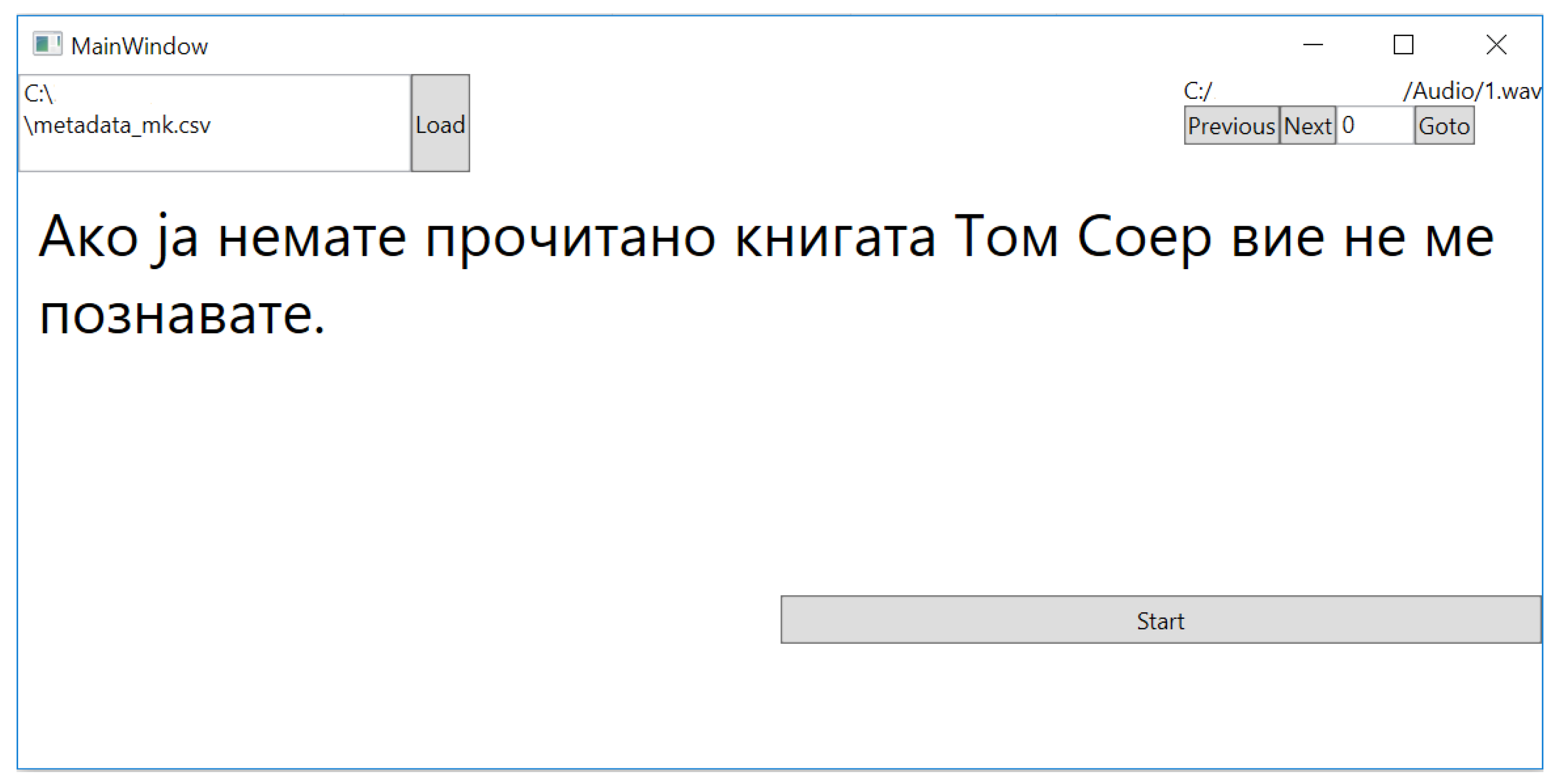
- The development of a speech recorder tool for recording and matching the audio clips to the corresponding text transcriptions, suitable for easier creation of any language dataset needed for TTS model training.
- Establishment of guidelines for other researchers via discussion of the experience using state-of-the-art Deep learning networks architectures for TTS modelling.
2. Related Work
3. Methods and Methodology
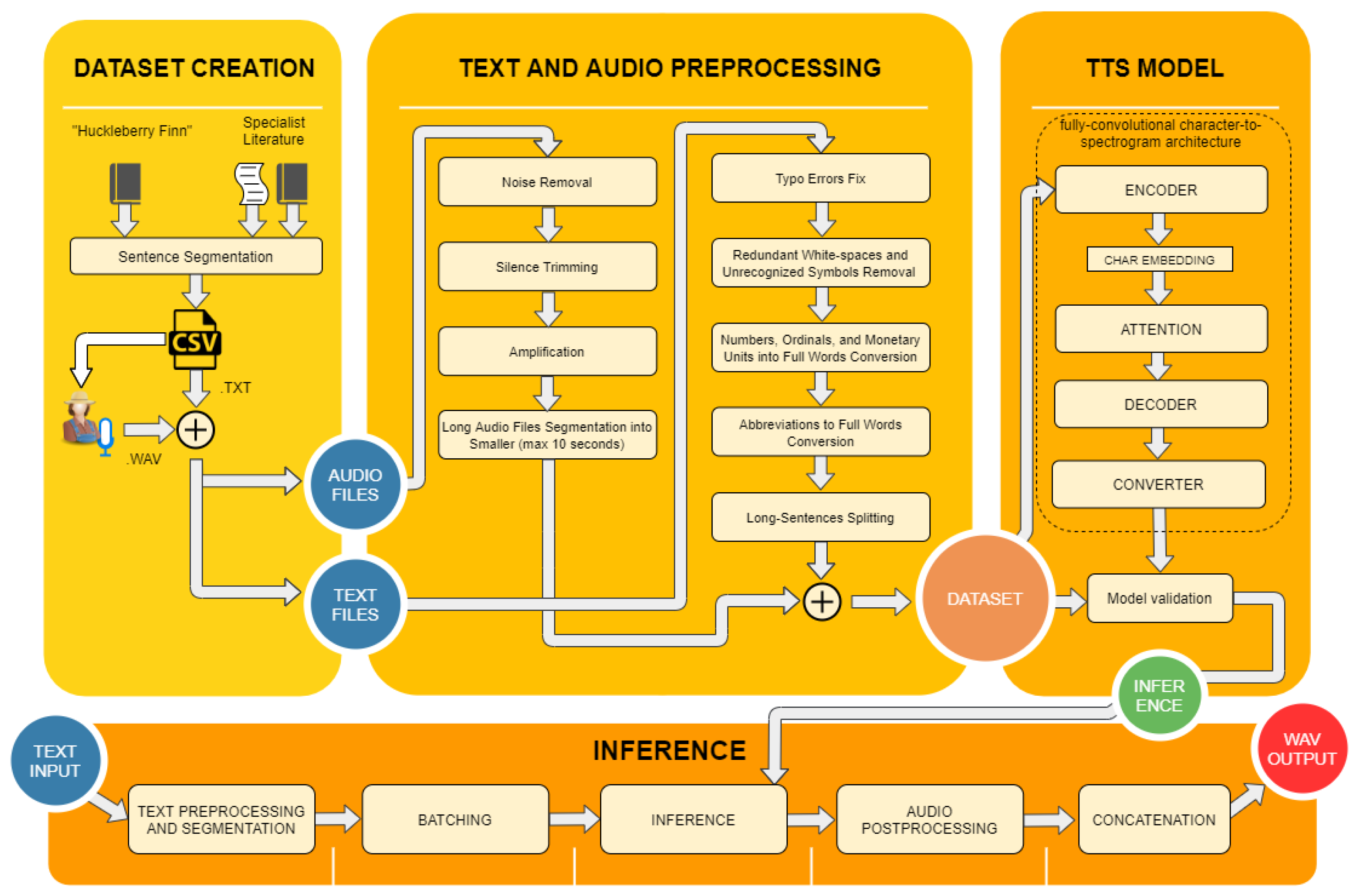
3.1. Dataset Creation
3.2. Corpus Preprocessing
3.3. Deep Learning Approach
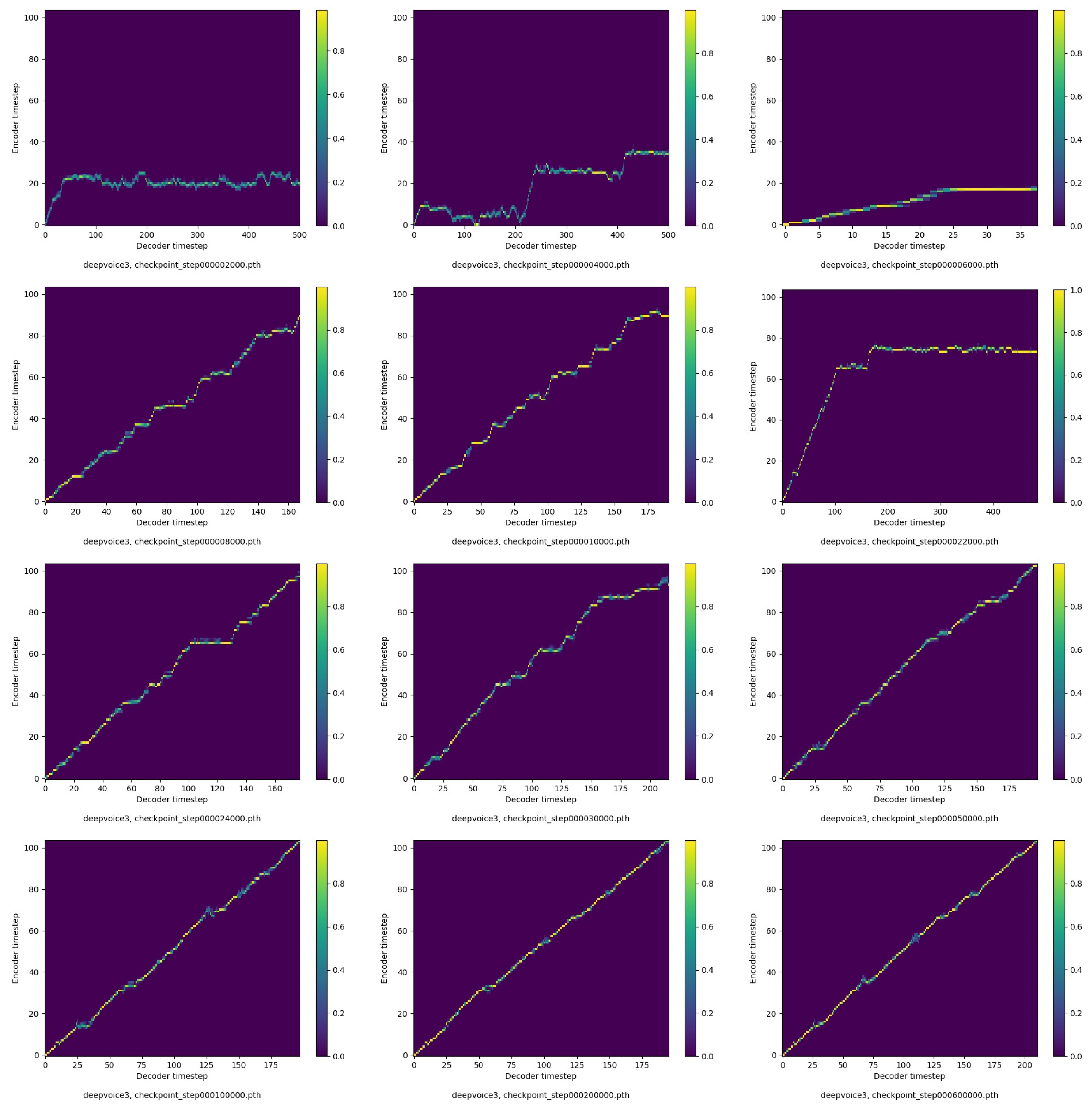
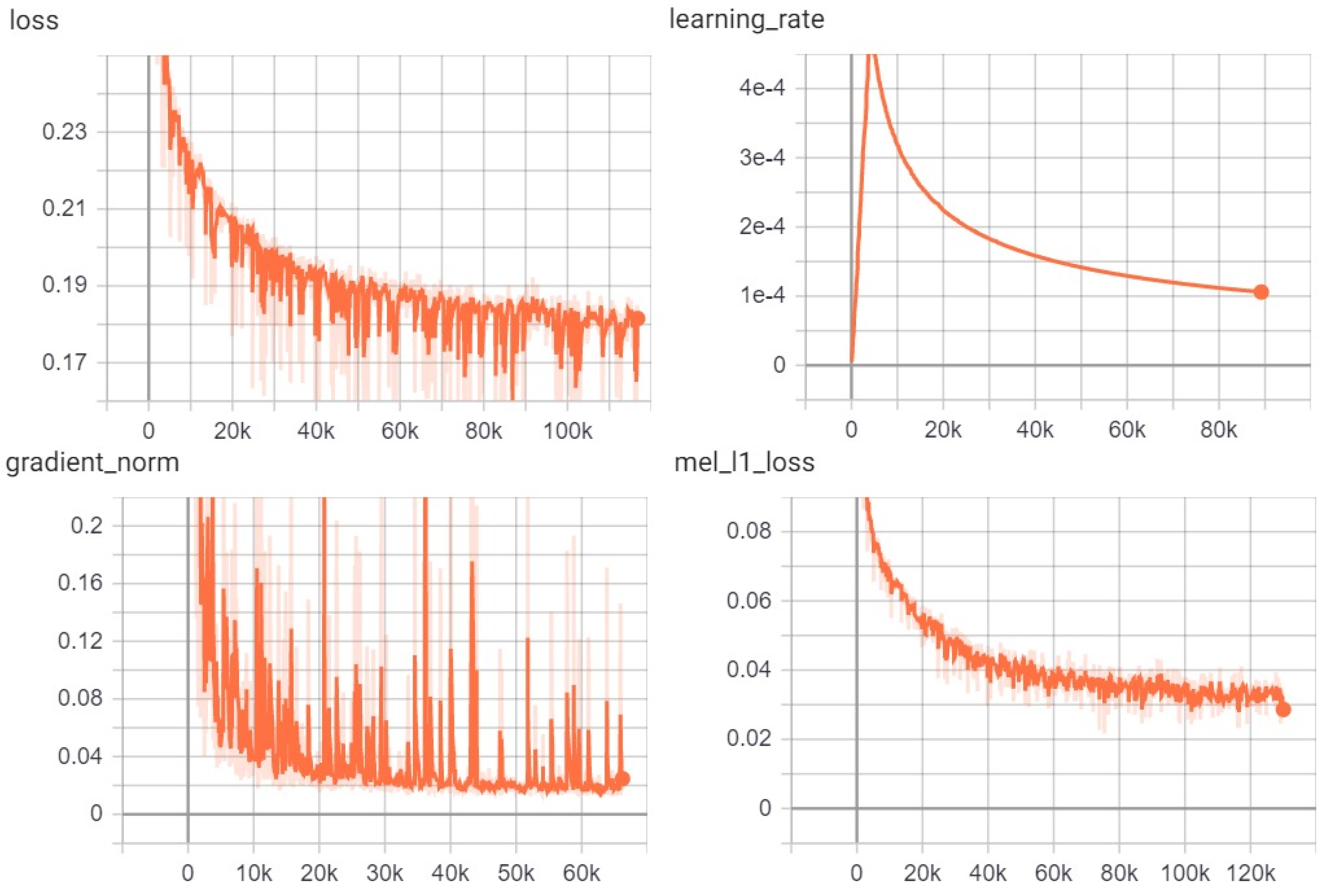
4. Results
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ning, Y.; He, S.; Wu, Z.; Xing, C.; Zhang, L.J. A review of deep learning based speech synthesis. Appl. Sci. 2019, 9, 4050. [Google Scholar] [CrossRef] [Green Version]
- Murray, I.R. Simulating Emotion in Synthetic Speech. Ph.D. Thesis, University of Dundee, Dundee, UK, 1989. [Google Scholar]
- Tokuda, K.; Yoshimura, T.; Masuko, T.; Kobayashi, T.; Kitamura, T. Speech parameter generation algorithms for HMM-based speech synthesis. In Proceedings of the 2000 IEEE International Conference on Acoustics, Speech, and Signal Processing (Cat. No. 00CH37100), Istanbul, Turkey, 5–9 June 2000; Volume 3, pp. 1315–1318. [Google Scholar]
- Yoshimura, T.; Tokuda, K.; Masuko, T.; Kobayashi, T.; Kitamura, T. Simultaneous modeling of spectrum, pitch and duration in HMM-based speech synthesis. In Proceedings of the Sixth European Conference on Speech Communication and Technology, Budapest, Hungary, 5–9 September 1999. [Google Scholar]
- Yamagishi, J.; Nose, T.; Zen, H.; Ling, Z.H.; Toda, T.; Tokuda, K.; King, S.; Renals, S. Robust speaker-adaptive HMM-based text-to-speech synthesis. IEEE Trans. Audio Speech Lang. Process. 2009, 17, 1208–1230. [Google Scholar] [CrossRef] [Green Version]
- Ratnaparkhi, A. A Simple Introduction to Maximum Entropy Models for Natural Language Processing; IRCS Technical Reports Series; University of Pennsylvania: Philadelphia, PA, USA, 1997; p. 81. [Google Scholar]
- Gu, L.; Gao, Y.; Liu, F.H.; Picheny, M. Concept-based speech-to-speech translation using maximum entropy models for statistical natural concept generation. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 377–392. [Google Scholar] [CrossRef]
- Sridhar, V.K.R.; Bangalore, S.; Narayanan, S.S. Exploiting acoustic and syntactic features for automatic prosody labeling in a maximum entropy framework. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 797–811. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Coorman, G.; Deprez, F.; De Bock, M.; Fackrell, J.; Leys, S.; Rutten, P.; DeMoortel, J.; Schenk, A.; Van Coile, B. Speech Synthesis Using Concatenation of Speech Waveforms. U.S. Patent 6,665,641, 12 January 2003. [Google Scholar]
- Moulines, E.; Charpentier, F. Pitch-synchronous waveform processing techniques for text-to-speech synthesis using diphones. Speech Commun. 1990, 9, 453–467. [Google Scholar] [CrossRef]
- Charpentier, F.; Stella, M. Diphone synthesis using an overlap-add technique for speech waveforms concatenation. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal (ICASSP’86), Tokyo, Japan, 7–11 April 1986; Volume 11, pp. 2015–2018. [Google Scholar]
- Zen, H.; Tokuda, K.; Black, A.W. Statistical parametric speech synthesis. Speech Commun. 2009, 51, 1039–1064. [Google Scholar] [CrossRef]
- Ze, H.; Senior, A.; Schuster, M. Statistical parametric speech synthesis using deep neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–30 May 2013; pp. 7962–7966. [Google Scholar]
- Zen, H.; Senior, A. Deep mixture density networks for acoustic modeling in statistical parametric speech synthesis. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 3844–3848. [Google Scholar]
- Lu, H.; King, S.; Watts, O. Combining a vector space representation of linguistic context with a deep neural network for text-to-speech synthesis. In Proceedings of the Eighth ISCA Workshop on Speech Synthesis, Barcelona, Spain, 31 August–2 September 2013. [Google Scholar]
- Wang, Y.; Skerry-Ryan, R.; Stanton, D.; Wu, Y.; Weiss, R.J.; Jaitly, N.; Yang, Z.; Xiao, Y.; Chen, Z.; Bengio, S.; et al. Tacotron: Towards end-to-end speech synthesis. arXiv 2017, arXiv:1703.10135. [Google Scholar]
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z.; Chen, Z.; Zhang, Y.; Wang, Y.; Skerrv-Ryan, R.; et al. Natural tts synthesis by conditioning wavenet on mel spectrogram predictions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 5–20 April 2018; pp. 4779–4783. [Google Scholar]
- Yasuda, Y.; Wang, X.; Takaki, S.; Yamagishi, J. Investigation of enhanced Tacotron text-to-speech synthesis systems with self-attention for pitch accent language. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2019), Brighton, UK, 12–17 May 2019; pp. 6905–6909. [Google Scholar]
- Ren, Y.; Ruan, Y.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T.Y. Fastspeech: Fast, robust and controllable text to speech. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 3171–3180. [Google Scholar]
- Ren, Y.; Hu, C.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T.Y. FastSpeech 2: Fast and High-Quality End-to-End Text-to-Speech. arXiv 2020, arXiv:2006.04558. [Google Scholar]
- Arik, S.Ö.; Chrzanowski, M.; Coates, A.; Diamos, G.; Gibiansky, A.; Kang, Y.; Li, X.; Miller, J.; Ng, A.; Raiman, J.; et al. Deep voice: Real-time neural text-to-speech. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 195–204. [Google Scholar]
- Gibiansky, A.; Arik, S.; Diamos, G.; Miller, J.; Peng, K.; Ping, W.; Raiman, J.; Zhou, Y. Deep voice 2: Multi-speaker neural text-to-speech. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 2962–2970. [Google Scholar]
- Ping, W.; Peng, K.; Gibiansky, A.; Arik, S.O.; Kannan, A.; Narang, S.; Raiman, J.; Miller, J. Deep voice 3: Scaling text-to-speech with convolutional sequence learning. arXiv 2017, arXiv:1710.07654. [Google Scholar]
- Tachibana, H.; Uenoyama, K.; Aihara, S. Efficiently trainable text-to-speech system based on deep convolutional networks with guided attention. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4784–4788. [Google Scholar]
- Ping, W.; Peng, K.; Chen, J. Clarinet: Parallel wave generation in end-to-end text-to-speech. arXiv 2018, arXiv:1807.07281. [Google Scholar]
- Oord, A.V.D.; Li, Y.; Babuschkin, I.; Simonyan, K.; Vinyals, O.; Kavukcuoglu, K.; Driessche, G.V.D.; Lockhart, E.; Cobo, L.C.; Stimberg, F.; et al. Parallel wavenet: Fast high-fidelity speech synthesis. arXiv 2017, arXiv:1711.10433. [Google Scholar]
- Josifovski, L.; Mihajlov, D.; Djordjevik, D. Text-to-Speech Conversion for Macedonian as Part of a System for Support of Humans with Damaged Sight. In Proceedings of the 18th International Conference on Information Technology Interfaces (ITI), Pula, Croatia, 18–21 June 1996; Volume 96, pp. 61–66. [Google Scholar]
- Josifovski, L.; Mihajlov, D.; Gorgevik, D. Speech synthesizer based on time domain syllable concatenation. In Proceedings of the SPECOM, Cluj-Napoca, Romania, 27–30 October 1997; Volume 97, pp. 165–170. [Google Scholar]
- Delić, V.; Sečujski, M.; Pekar, D.; Jakovljević, N.; Mišković, D. A Review of AlfaNum Speech Technologies for Serbian, Croatian and Macedonian. In Proceedings of the International Language Technologies Conference IS-LTC, Ljubljana, Slovenia, 9–10 October 2006; Volume 6, pp. 257–260. [Google Scholar]
- Gerazov, B.; Ivanovski, Z.; Bilibajkic, R. Modeling Macedonian intonation for text-to-speech synthesis. In Proceedings of the DOGS 2010, Iriski Venac, Serbia, 16–18 December 2010; pp. 16–18. [Google Scholar]
- Gerazov, B.; Ivanovski, Z. Analysis of intonation in the Macedonian language for the purpose of text-to-speech synthesis. In Proceedings of the EAA EUROREGIO 2010, Ljubljana, Slovenia, 15–18 September 2010. [Google Scholar]
- Gerazov, B.; Ivanovski, Z. Analysis of intonation dynamics in Macedonian for the purpose of text to speech synthesis. In Proceedings of the TELFOR 2010, Belgrade, Serbia, 23–25 November 2010. [Google Scholar]
- Gerazov, B.; Ivanovski, Z. The Construction of a Mixed Unit Inventory for Macedonian Text-to-Speech Synthesis. In Proceedings of the International Scientific-Professional Symposium INFOTEH, Jahorina, Bosnia and Herzegovina, 16–18 March 2011. [Google Scholar]
- Gerazov, B.; Ivanovski, Z. Diphone Analysis of the Macedonian Language for the Purpose of Text-to-Speech Synthesis. In Proceedings of the ICEST 2009, Veliko Tarnovo, Bulgaria, 25–27 June 2009. [Google Scholar]
- Gerazov, B.; Ivanovski, Z. Generation of pitch curves for Macedonian text-to-speech synthesis. In Proceedings of the 6th Forum Acusticum, Aalborg, Denmark, 27 June–1 July 2011. [Google Scholar]
- Kochanski, G.; Shih, C. Prosody modeling with soft templates. Speech Commun. 2003, 39, 311–352. [Google Scholar] [CrossRef]
- Taylor, P. Text-To-Speech Synthesis; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Taylor, P. Analysis and synthesis of intonation using the tilt model. J. Acoust. Soc. Am. 2000, 107, 1697–1714. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gerazov, B.; Peev, G.; Hristov, M.; Ivanovski, Z. Towards speech emotion recognition in Macedonian. In Proceedings of the ETAI 2015, Ohrid, North Macedonia, 24–26 September 2015. [Google Scholar]
- Chungurski, S.; Kraljevski, I.; Mihajlov, D.; Arsenovski, S. Concatenative speech synthesizers and speech corpus for Macedonian language. In Proceedings of the 30th International Conference on Information Technology Interfaces (ITI 2008), Dubrovnik, Croatia, 23–26 June 2008; pp. 669–674. [Google Scholar]
- Kraljevski, I.; Strecha, G.; Wolff, M.; Jokisch, O.; Chungurski, S.; Hoffmann, R. Cross-language acoustic modeling for Macedonian speech technology applications. In Proceedings of the International Conference on ICT Innovations 2012, Ohrid, North Macedonia, 13–15 September 2012; pp. 35–45. [Google Scholar]
- Mingov, R.; Zdravevski, E.; Lameski, P. Application of russian language phonemics to generate macedonian speech recognition model using sphinx. In Proceedings of the ICT Innovations 2016, Ohrid, North Macedonia, 5–7 September 2016. [Google Scholar]
- Ivanovska, A.; Zdravkova, K.; Erjavec, T.; Džeroski, S. Learning rules for morphological analysis and synthesis of Macedonian nouns, adjectives and verbs. In Proceedings of the 5th Slovenian and 1st International Language Technologies Conference, Ljubljana, Slovenia, 9–13 October 2006; pp. 140–145. [Google Scholar]
- Ito, K. The lj Speech Dataset. 2017. Available online: https://keithito.com/LJ-Speech-Dataset/ (accessed on 26 September 2020).
- Friedman, V. Macedonian, Slavic and Eurasian Language Resource Center (SEELRC). 2001. Available online: shorturl.at/blAC0 (accessed on 26 September 2020).
- Ping, W.; Peng, K.; Gibiansky, A.; Arik, S.O.; Kannan, A.; Narang, S.; Raiman, J.; Miller, J. Deep voice 3: 2000-speaker neural text-to-speech. In Proceedings of the ICLR, Vancouver, Canada, 30 April–3 May 2018; pp. 214–217. [Google Scholar]
- Viswanathan, M.; Viswanathan, M. Measuring speech quality for text-to-speech systems: Development and assessment of a modified mean opinion score (MOS) scale. Comput. Speech Lang. 2005, 19, 55–83. [Google Scholar] [CrossRef]
- Ribeiro, F.; Florêncio, D.; Zhang, C.; Seltzer, M. Crowdmos: An approach for crowdsourcing mean opinion score studies. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 2416–2419. [Google Scholar]
- Anh, M. Tensorflow TTS. Available online: https://github.com/TensorSpeech/TensorFlowTTS (accessed on 26 September 2020).
- Didur, I. Tacotron 2. Available online: https://github.com/ide8/tacotron2 (accessed on 26 September 2020).
- Shmyrev, N.V. Implementation of Tacotron 2 for Russian language. Available online: https://github.com/alphacep/tn2-wg (accessed on 26 September 2020).
- NVIDIA. Waveglow. Available online: https://github.com/NVIDIA/waveglow (accessed on 26 September 2020).
- Amato, F.; Moscato, V.; Picariello, A.; Sperlí, G. Kira: A system for knowledge-based access to multimedia art collections. In Proceedings of the 2017 IEEE 11th International Conference on Semantic Computing (ICSC), San Diego, CA, USA, 30 January–1 February 2017; pp. 338–343. [Google Scholar]
- Amato, F.; Moscato, V.; Picariello, A.; Sperlí, G. Recommendation in social media networks. In Proceedings of the 2017 IEEE Third International Conference on Multimedia Big Data (BigMM), Laguna Hills, CA, USA, 19–21 April 2017; pp. 213–216. [Google Scholar]
- Amato, F.; Castiglione, A.; Moscato, V.; Picariello, A.; Sperlì, G. Multimedia summarization using social media content. Multimed. Tools Appl. 2018, 77, 17803–17827. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | |
|---|---|
| “replace_pronunciation_prob”: 0.0, | “converter_channels”: 256, |
| “speaker_embed_dim”: 16, | “query_position_rate”: 1.0, |
| “num_mels”: 80, | “key_position_rate”: 1.385, |
| “fmin”: 125, | “num_workers”: 2, |
| “fmax”: 7600, | “masked_loss_weight”: 0.5, |
| “fft_size”: 1024, | “priority_freq”: 3000, |
| “hop_size”: 256, | “priority_freq_weight”: 0.0, |
| “sample_rate”: 22050, | “binary_divergence_weight”: 0.1, |
| “preemphasis”: 0.97, | “guided_attention_sigma”: 0.2, |
| “min_level_db”: −100, | “batch_size”: 32, |
| “ref_level_db”: 20, | “adam_beta1”: 0.5, |
| “rescaling_max”: 0.999, | “adam_beta2”: 0.9, |
| “downsample_step”: 4, | “adam_eps”: 0.000006, |
| “outputs_per_step”: 1, | “initial_learning_rate”: 0.0005, |
| “embedding_weight_std”: 0.1, | “nepochs”: 2000, |
| “speaker_embedding_weight_std”: 0.01, | “weight_decay”: 0.0, |
| “padding_idx”: 0, | “clip_thresh”: 0.1, |
| “max_positions”: 512, | “checkpoint_interval”: 1000, |
| “dropout”: 0.050000000000000044, | “eval_interval”: 10000, |
| “kernel_size”: 3, | “window_ahead”: 3, |
| “text_embed_dim”: 256, | “window_backward”: 1, |
| “encoder_channels”: 512, | “power”: 1.4 |
| “decoder_channels”: 256, | |
| Experiment | Subjective Five-Scale MOS |
|---|---|
| Ground Truth | 4.6234 ± 0.2739 |
| Deep Voice 3 | 3.9285 ± 0.1210 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mishev, K.; Karovska Ristovska, A.; Trajanov, D.; Eftimov, T.; Simjanoska, M. MAKEDONKA: Applied Deep Learning Model for Text-to-Speech Synthesis in Macedonian Language. Appl. Sci. 2020, 10, 6882. https://doi.org/10.3390/app10196882
Mishev K, Karovska Ristovska A, Trajanov D, Eftimov T, Simjanoska M. MAKEDONKA: Applied Deep Learning Model for Text-to-Speech Synthesis in Macedonian Language. Applied Sciences. 2020; 10(19):6882. https://doi.org/10.3390/app10196882
Chicago/Turabian StyleMishev, Kostadin, Aleksandra Karovska Ristovska, Dimitar Trajanov, Tome Eftimov, and Monika Simjanoska. 2020. "MAKEDONKA: Applied Deep Learning Model for Text-to-Speech Synthesis in Macedonian Language" Applied Sciences 10, no. 19: 6882. https://doi.org/10.3390/app10196882
APA StyleMishev, K., Karovska Ristovska, A., Trajanov, D., Eftimov, T., & Simjanoska, M. (2020). MAKEDONKA: Applied Deep Learning Model for Text-to-Speech Synthesis in Macedonian Language. Applied Sciences, 10(19), 6882. https://doi.org/10.3390/app10196882