Semantic Information for Robot Navigation: A Survey


Abstract
:1. Introduction
- Human-friendly models. The robot models the environment with the same concepts that humans understand.
- Autonomy. The robot is able to draw its own conclusions about the place to which it has to go.
- Robustness. The robot is able to complete missing information, such as failures by detecting objects.
- Improves the location: The robot constantly perceives elements congruent with the knowledge about its location. For example, if it perceives a sofa, it confirms that it is in a living room.
- Efficiency: When calculating a route, you do not need to explore the entire environment. It is possible to focus on a specific area for partial exploration.
2. Acquisition of Semantic Information in Robot Navigation
2.1. Human-Assisted Information Acquisition
2.2. Fully Automated Information Acquisition
2.2.1. Understanding the Environment
- Indoor single scene interpretation. Different works converge here. Mueller and Behnke proposed a framework to perform semantic annotations of RGB-D data [63]. Authors used the implementation of a Random Forests classifier to group the scenes, and SVM to predict objects and indoor scenes. The model is based on Conditional Random Field (CRF) to provide unary features. Another approach that is also supported by CRF and Random Forests is presented in Wolf et al. [64], while in Gutierrez-Gomez et al. [65] authors proposed segmenting the scene into fragments of neighbouring 3D points. Having in mind low-level features such as textures or normal entropy, researchers manage to differentiate the areas of the scene that change over time from those that are static. This makes it easier to recognize places when the robot returns to visit a place.
- Indoor large scale interpretation. This category includes works such as the proposal of Hermans et al. that proposed a method for semantic segmentation of 3D scenes in different places [66]. The 3D reconstruction process is carried out by adding new scenes to those previously acquired. The locations are then labelled with distance, colour, and normal orientation information. Ranganathan, proposed an online method that segments RGB streams and labels inferring the parameters in a Bayesian model [67].
3. Representation of Semantic Knowledge
3.1. Ontologies
3.2. Cognitive Maps
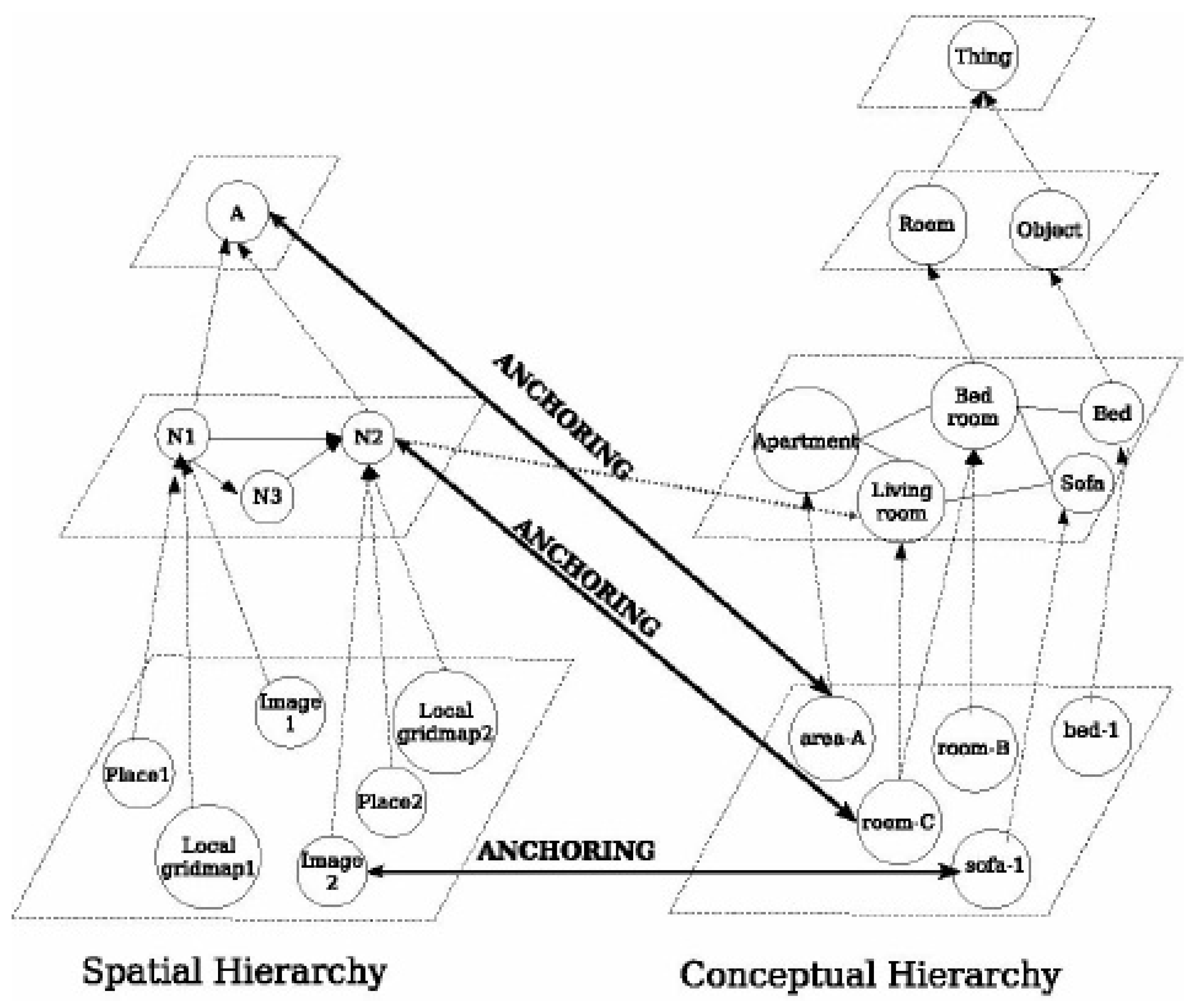
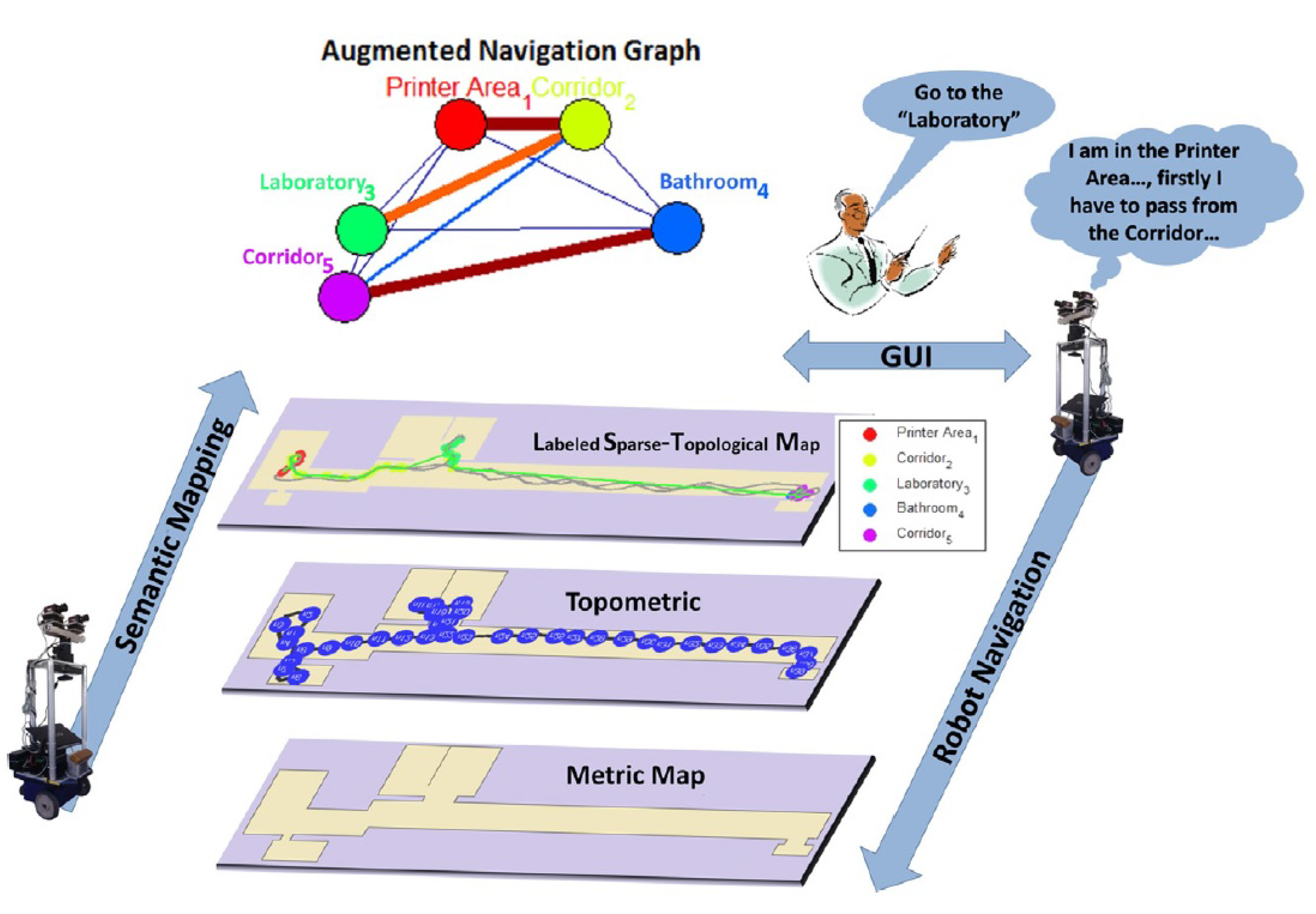
3.3. Semantic Maps
- Objects. Each object class corresponds to a property associated with the place. A particular location is expected to display a certain number of a particular type of object, and a certain amount of them is observed.
- Door. Determines whether a location is determined by a door.
- Shape. The geometric form of the room extracted from the information of laser sensors.
- Size. The relative size of the room extracted from the sensory information of the laser.
- Appearance. The visual appearance of a place.
- Associated space. The amount of free space visible around a placeholder not assigned to any place.
A semantic map in a mobile robot is a map that contains, in addition to spatial information about the environment, assignments of mapped features of known class entities. In addition to the knowledge of these entities, regardless of the content of the map, some kind of knowledge base must be available with an associated reasoning engine for inferences [83].
4. Semantic Navigation
4.1. Principles of Semantic Navigation
4.2. Elements of the Semantic Navigation
5. Open Issues and Questions
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kostavelis, I.; Gasteratos, A. Semantic maps from multiple visual cues. Expert Syst. Appl. 2017, 68, 45–57. [Google Scholar] [CrossRef]
- Kostavelis, I.; Gasteratos, A. Semantic mapping for mobile robotics tasks: A survey. Robot. Auton. Syst. 2015, 66, 86–103. [Google Scholar] [CrossRef]
- Kollar, T.; Roy, N. Utilizing object-object and object-scene context when planning to find things. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Kobe, Japan, 12–17 May 2009. [Google Scholar]
- Arras, K. Featur-Based Robot Navigation in Know and Unknow Environments. Ph.D. Thesis, Swiss Federal Institute of Technology Lausanne (EPFL), Lausanne, Switzerland, 2003. [Google Scholar]
- Chatila, R.; Laumond, J. Position referencing and consistent world modeling for mobile robots. In Proceedings of the IEEE International Conference on Robotics and Automation, St. Louis, MO, USA, 25–28 March 1985. [Google Scholar]
- Jiang, G.; Yin, L.; Jin, S.; Tian, C.; Ma, X.; Ou, Y. A Simultaneous Localization and Mapping (SLAM) Framework for 2.5D Map Building Based on Low-Cost LiDAR and Vision Fusion. Appl. Sci. 2019, 9, 2105. [Google Scholar] [CrossRef] [Green Version]
- Choset, H.; Nagatani, K. Topological Simultaneous Localization And Mapping (SLAM): Toward exact localization without explicit localization. IEEE Trans. Robot. Autom. 2001, 17, 125–137. [Google Scholar] [CrossRef]
- Tapus, A. Topological SLAM-Simultaneous Localization And Mapping with Fingerprints of Places. Ph.D. Thesis, Swiss Federal Institute of Technology Lausanne (EPFL), Lausanne, Switzerland, 2005. [Google Scholar]
- Wang, F.; Liu, Y.; Xiao, L.; Wu, C.; Chu, H. Topological Map Construction Based on Region Dynamic Growing and Map Representation Method. Appl. Sci. 2019, 9, 816. [Google Scholar] [CrossRef] [Green Version]
- Thrun, S. Learning metric-topological maps for indoor mobile robot navigation. Artif. Intell. 1998, 99, 21–71. [Google Scholar] [CrossRef] [Green Version]
- Tomatis, N.; Nourbakhsh, I.; Siegwart, R. Hybrid simultaneous localization and map building: A natural integration of topological and metric, Robotics and Autonomous Systems. Robot. Auton. Syst. 2003, 44, 3–14. [Google Scholar] [CrossRef] [Green Version]
- Gruber, T.R. Toward Principles for the Design of Ontologies Used for Knowledge Sharing. Int. J. Hum. Comput. Stud. 1995, 43, 907–928. [Google Scholar] [CrossRef]
- Galindo, C.; Saffiotti, A.; Coradeschi, S.; Buschka, P.; Fernández-Madrigal, J.A.; González, J. Multi-hierarchical semantic maps for mobile robotics. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AL, Canada, 2–6 August 2005. [Google Scholar]
- Fernández-Rodicio, E.; Castro-González, Á.; Castillo, J.C.; Alonso-Martin, F.; Salichs, M.A. Composable Multimodal Dialogues Based on Communicative Acts. In Social Robotics; Springer International Publishing: Cham, Switzerland, 2018; pp. 139–148. [Google Scholar]
- Zender, H.; Mozos, O.M.; Jensfelt, P.; Kruijff, G.J.M.; Burgard, W. Conceptual spatial representations for indoor mobile robots. Robot. Auton. Syst. (RAS) 2008, 56, 493–502. [Google Scholar] [CrossRef] [Green Version]
- Nieto-Granda, C.; Rogers, J.G.; Trevor, A.J.B.; Christensen., H.I. Semantic Map Partitioning in Indoor Environments using Regional Analysis. In Proceedings of the IEEEl/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 December 2010. [Google Scholar]
- Pronobis, A.; Jensfelt., P. Large-scale semantic mapping and reasoning with heterogeneous modalities. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation (ICRA’12), St. Paul, MN, USA, 14–18 May 2012. [Google Scholar]
- Peltason, J.; Siepmann, F.H.K.; Spexard, T.P.; Wrede, B.; Hanheide, M.; Topp, E.A. Mixed-initiative in human augmented mapping. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009. [Google Scholar]
- Crespo, J.; Barber, R.; Mozos, O. Relational Model for Robotic Semantic Navigation in Indoor Environments. J. Intell. Robot. Syst. 2017, 86, 617–639. [Google Scholar] [CrossRef]
- Barber, R.; Crespo, J.; Gomez, C.; Hernandez, A.C.; Galli, M. Mobile Robot Navigation in Indoor Environments: Geometric, Topological, and Semantic Navigation. In Applications of Mobile Robots; IntechOpen: London, UK, 2018. [Google Scholar] [CrossRef] [Green Version]
- Kruijff, G.J.M.; Zender, H.; Jensfelt, P.; Christensen, H.I. Clarification Dialogues in Human-augmented Mapping. In Proceedings of the 1st ACM SIGCHI/SIGART Conference on Human-robot Interaction, HRI ’06, Salt Lake City, UT, USA, 2–3 March 2006. [Google Scholar]
- Hemachandra, S.; Kollar, T.; Roy, N.; Teller, S.J. Following and interpreting narrated guided tours. In Proceedings of the Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011. [Google Scholar]
- Gemignani, G.; Capobianco, R.; Bastianelli, E.; Bloisi, D.D.; Iocchi, L.; Nardi, D. Living with robots: Interactive environmental knowledge acquisition. Robot. Auton. Syst. 2016, 78, 1–16. [Google Scholar] [CrossRef]
- Goerke, N.; Braun, S. Building Semantic Annotated Maps by Mobile Robots. In Proceedings of the Towards Autonomous Robotic Systems, Londonderry, UK, 15 May 2009. [Google Scholar]
- Brunskill, E.; Kollar, T.; Roy, N. Topological mapping using spectral clustering and classification. In Proceedings of the IEEE/RSJ Conference on Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007. [Google Scholar]
- Friedman, S.; Pasula, H.; Fox, D. Voronoi random fields: Extracting the topological structure of indoor environments via place labeling. In Proceedings of the International Joint Conference on Artificial Intelligence, Hyderabad, India, 6–12 January 2007. [Google Scholar]
- Wu, J.; Christensen, H.I.; Rehg, J.M. Visual place categorization: Problem, dataset, and algorithm. In Proceedings of the IROS’09, St. Louis, MO, USA, 10–15 October 2009. [Google Scholar]
- Tian, B.; Shim, V.A.; Yuan, M.; Srinivasan, C.; Tang, H.; Li, H. RGB-D based cognitive map building and navigation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013. [Google Scholar]
- Crespo, J.; Gómez, C.; Hernández, A.; Barber, R. A Semantic Labeling of the Environment Based on What People Do. Sensors 2017, 17, 260. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lowe, D. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Ekvall, S.; Kragic, D.; Jensfelt, P. Object detection and mapping for service robot tasks. Robotica 2007, 25, 175–187. [Google Scholar] [CrossRef]
- Ekvall, S.; Kragic, D. Receptive field cooccurrence histograms for object detection. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AL, Canada, 2–6 August 2005; pp. 84–89. [Google Scholar]
- López, D. Combining Object Recognition and Metric Mapping for Spatial Modeling with Mobile Robots. Master’s Thesis, Royal Institute of Technology, Stockholm, Sweden, 2007. [Google Scholar]
- Aydemir, A.; Göbelbecker, M.; Pronobis, A.; Sjöö, K.; Jensfelt., P. Plan-based object search and exploration using semantic spatial knowledge in the real world. In Proceedings of the 5th European Conference on Mobile Robots (ECMR11), Örebro, Sweden, 7–9 September 2011. [Google Scholar]
- Garvey, T.D. Perceptual Strategies for Purposive Vision; SRI International: Menlo Park, CA, USA, 1976. [Google Scholar]
- Mozos, O.M.; Marton, Z.C.; Beetz, M. Furniture models learned from the WWW—Using web catalogs to locate and categorize unknown furniture pieces in 3D laser scans. IEEE Robot. Autom. Mag. 2011, 18, 22–32. [Google Scholar] [CrossRef] [Green Version]
- Joho, D.; Burgard, W. Searching for Objects: Combining Multiple Cues to Object Locations Using a Maximum Entropy Model. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Anchorage, AK, USA, 3–7 May 2010. [Google Scholar]
- Astua, C.; Barber, R.; Crespo, J.; Jardon, A. Object Detection Techniques Applied on Mobile Robot Semantic Navigation. Sensors 2014, 14, 6734–6757. [Google Scholar] [CrossRef] [Green Version]
- Blodow, N.; Goron, L.C.; Marton, Z.C. Autonomous semantic mapping for robots performing everyday manipulation tasks in kitchen environments. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), San Francisco, CA, USA, 25–30 September 2011. [Google Scholar]
- Vasudevan, S.; Siegwart, R. A Bayesian approach to Conceptualization and Place Classification: Incorporating Spatial Relationships (distances) between Objects towards inferring concepts. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), San Diego, CA, USA, 29 October–2 November 2007. [Google Scholar]
- Vasudevan, S.; Harati, A.; Siegwart, R. A Bayesian Conceptualization of Space for Mobile Robots: Using the Number of Occurrences of Objects to Infer Concepts. In Proceedings of the European Conference on Mobile Robotics (ECMR), Freiburg, Germany, 19–21 September 2007. [Google Scholar]
- Miyamoto, R.; Adachi, M.; Nakamura, Y.; Nakajima, T.; Ishida, H.; Kobayashi, S. Accuracy improvement of semantic segmentation using appropriate datasets for robot navigation. In Proceedings of the 2019 6th International Conference on Control, Decision and Information Technologies (CoDIT), Paris, France, 23–26 April 2019; pp. 1610–1615. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Mousavian, A.; Toshev, A.; Fišer, M.; Košecká, J.; Wahid, A.; Davidson, J. Visual representations for semantic target driven navigation. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8846–8852. [Google Scholar]
- Luo, J.; Wang, J.; Xu, H.; Lu, H. Real-time people counting for indoor scenes. Signal Process. 2016, 124, 27–35. [Google Scholar] [CrossRef]
- Aguirre, E.; Garcia-Silvente, M.; Plata, J. Leg Detection and Tracking for a Mobile Robot and Based on a Laser Device, Supervised Learning and Particle Filtering. In ROBOT2013: First Iberian Robotics Conference; Armada, M.A., Sanfeliu, A., Ferre, M., Eds.; Springer International Publishing: Cham, Switzerland, 2014; Volume 252, pp. 433–440. [Google Scholar]
- Monroy, J.; Ruiz-Sarmiento, J.; Moreno, F.; Galindo, C.; Gonzalez-Jimenez, J. Olfaction, Vision, and Semantics for Mobile Robots. Results of the IRO Project. Sensors 2019, 19, 3488. [Google Scholar] [CrossRef] [Green Version]
- Kostavelis, I.; Gasteratos, A. Learning spatially semantic representations for cognitive robot navigation. Robot. Auton. Syst. 2013, 61, 1460–1475. [Google Scholar] [CrossRef]
- Drouilly, R.; Rives, P.; Morisset, B. Semantic Representation For Navigation In Large-Scale Environments. In Proceedings of the IEEE International Conference on Robotics and Automation, ICRA’15, Seattle, WA, USA, 26–30 May 2015. [Google Scholar]
- Cleveland, J.; Thakur, D.; Dames, P.; Phillips, C.; Kientz, T.; Daniilidis, K.; Bergstrom, J.; Kumar, V. An automated system for semantic object labeling with soft object recognition and dynamic programming segmentation. In Proceedings of the 2015 IEEE International Conference on Automation Science and Engineering (CASE), Gothenburg, Sweden, 24–28 August 2015; pp. 683–690. [Google Scholar]
- Rituerto, J.; Murillo, A.C.; Košecka, J. Label propagation in videos indoors with an incremental non-parametric model update. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), San Francisco, CA, USA, 25–30 September 2011; pp. 2383–2389. [Google Scholar]
- Shi, L.; Kodagoda, S.; Dissanayake, G. Multi-class classification for semantic labeling of places. In Proceedings of the 2010 11th International Conference on Control Automation Robotics & Vision (ICARCV), Singapore, 7–10 December 2010; pp. 2307–2312. [Google Scholar]
- Lowe, G. SIFT—The scale invariant feature transform. Int. J. 2004, 2, 91–110. [Google Scholar]
- Polastro, R.; Corrêa, F.; Cozman, F.; Okamoto, J., Jr. Semantic mapping with a probabilistic description logic. In Advances in Artificial Intelligence—SBIA 2010; Springer: Berlin, Germany, 2010; pp. 62–71. [Google Scholar]
- Hernandez, A.C.; Gomez, C.; Barber, R. MiNERVA: Toposemantic Navigation Model based on Visual Information for Indoor Enviroments. IFAC-PapersOnLine 2019, 52, 43–48. [Google Scholar] [CrossRef]
- Wang, L.; Zhao, L.; Huo, G.; Li, R.; Hou, Z.; Luo, P.; Sun, Z.; Wang, K.; Yang, C. Visual semantic navigation based on deep learning for indoor mobile robots. Complexity 2018, 2018, 1627185. [Google Scholar] [CrossRef]
- Mozos, O.M.; Triebel, R.; Jensfelt, P.; Rottmann, A.; Burgard, W. Supervised semantic labeling of places using information extracted from sensor data. Robot. Auton. Syst. 2007, 55, 391–402. [Google Scholar] [CrossRef] [Green Version]
- Sousa, P.; Araujo, R.; Nunes, U. Real-time labeling of places using support vector machines. In Proceedings of the ISIE 2007—IEEE International Symposium on Industrial Electronics, Vigo, Spain, 4–7 June 2007; pp. 2022–2027. [Google Scholar]
- Pronobis, A.; Martinez Mozos, O.; Caputo, B.; Jensfelt, P. Multi-modal Semantic Place Classification. Int. J. Robot. Res. 2010, 29, 298–320. [Google Scholar] [CrossRef]
- Mozos, O.M.; Stachniss, C.; Burgard, W. Supervised learning of places from range data using adaboost. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation—ICRA 2005, Barcelona, Spain, 18–22 April 2005; pp. 1730–1735. [Google Scholar]
- Rottmann, A.; Mozos, O.M.; Stachniss, C.; Burgard, W. Semantic Place Classification of Indoor Environments With Mobile Robots using Boosting. In Proceedings of the National Conference on Artificial Intelligence (AAAI), Pittsburgh, PA, USA, 9–13 July 2005. [Google Scholar]
- Charalampous, K.; Kostavelis, I.; Gasteratos, A. Recent trends in social aware robot navigation: A survey. Robot. Auton. Syst. 2017, 93, 85–104. [Google Scholar] [CrossRef]
- Müller, A.C.; Behnke, S. Learning depth-sensitive conditional random fields for semantic segmentation of RGB-D images. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 6232–6237. [Google Scholar]
- Wolf, D.; Prankl, J.; Vincze, M. Fast semantic segmentation of 3D point clouds using a dense CRF with learned parameters. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 4867–4873. [Google Scholar] [CrossRef]
- Gutiérrez-Gómez, D.; Mayol-Cuevas, W.; Guerrero, J.J. What should I landmark? Entropy of normals in depth juts for place recognition in changing environments using RGB-D data. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 5468–5474. [Google Scholar] [CrossRef]
- Hermans, A.; Floros, G.; Leibe, B. Dense 3D semantic mapping of indoor scenes from RGB-D images. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 2631–2638. [Google Scholar] [CrossRef]
- Ranganathan, A. PLISS: Labeling places using online changepoint detection. Auton. Robot. 2012, 32, 351–368. [Google Scholar] [CrossRef]
- Galvez-López, D.; Tardos, J.D. Bags of Binary Words for Fast Place Recognition in Image Sequences. IEEE Trans. Robot. 2012, 28, 1188–1197. [Google Scholar] [CrossRef]
- Maffra, F.; Chen, Z.; Chli, M. Tolerant place recognition combining 2D and 3D information for UAV navigation. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 2542–2549. [Google Scholar]
- Lu, D.V.; Hershberger, D.; Smart, W.D. Layered costmaps for context-sensitive navigation. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 709–715. [Google Scholar] [CrossRef]
- Wong, L.L.; Kaelbling, L.P.; Lozano-Perez, T. Not Seeing is Also Believing: Combining Object and Metric Spatial Information. In Proceedings of the IEEE Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014. [Google Scholar]
- Zhao, Z.; Chen, X. Semantic Mapping for Object Category and Structural Class. In Proceedings of the International Conference on Intelligent Robots and Systems (IROS), Chicago, IL, USA, 14–18 September 2014. [Google Scholar]
- Deeken, H.; Wiemann, T.; Lingemann, K.; Hertzberg, J. SEMAP—A semantic environment mapping framework. In Proceedings of the 2015 European Conference on Mobile Robots (ECMR), Lincoln, UK, 2–4 September 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Walter, M.R.; Hemachandra, S.; Homberg, B.; Tellex, S.; Teller, S. Learning Semantic Maps from Natural Language Descriptions. In Proceedings of the 2013 Robotics: Science and Systems IX Conference, Berlin, Germany, 24–28 June 2013. [Google Scholar]
- Hemachandra, S.; Walter, M.R. Information-theoretic dialog to improve spatial-semantic representations. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 5115–5121. [Google Scholar] [CrossRef]
- Ko, D.W.; Yi, C.; Suh, I.H. Semantic mapping and navigation: A Bayesian approach. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013. [Google Scholar]
- Patel-Schneider, P.; Abrtahams, M.; Alperin, L.; McGuinness, D.; Borgida, A. NeoClassic Reference Manual: Version 1.0; Technical Report; AT&T Labs Research, Artificial Intelligence Principles Research Department: Florham Park, NJ, USA, 1996. [Google Scholar]
- Crespo, J. Arquitectura y Diseno de un Sistema Completo de Navegacion Semantica. Descripcion de su Ontologia y Gestion de Conocimiento. Ph.D. Thesis, Universidad Carlos III de Madrid, Madrid, Spain, 2017. [Google Scholar]
- Ruiz-Sarmiento, J.R.; Galindo, C.; Gonzalez-Jimenez, J. Building Multiversal Semantic Maps for Mobile Robot Operation. Knowl.-Based Syst. 2017, 119, 257–272. [Google Scholar] [CrossRef]
- Uschold, M.; Gruninger, M. Ontologies: Principles, methods and applications. Knowl. Eng. Rev. 1996, 11, 93–136. [Google Scholar] [CrossRef] [Green Version]
- Galindo, C.; Fernández-Madrigal, J.A.; González, J.; Saffiotti, A. Robot task planning using semantic Maps. Robot. Auton. Sist. 2008, 56, 955–966. [Google Scholar] [CrossRef] [Green Version]
- Galindo, C.; Saffiotti, A. Inferring robot goals from violations of semantic knowledge. Robot. Auton. Syst. 2013, 61, 1131–1143. [Google Scholar] [CrossRef]
- Nüchter, A.; Hertzberg, J. Towards semantic maps for mobile robots. Robot. Auton. Syst. 2008, 56, 915–926. [Google Scholar] [CrossRef] [Green Version]
- Tenorth, M.; Kunze, L.; Jain, D.; Beetz, M. KNOWROB-MAP—Knowledge-Linked Semantic Object Maps. In Proceedings of the IEEE-RAS International Conference on Humanoid Robots, Nashville, TN, USA, 6–8 December 2010. [Google Scholar]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved techniques for grid mapping with Rao-Blackwellized particle filters. IEEE Trans. Robot. 2007, 23, 34. [Google Scholar] [CrossRef] [Green Version]
- Beeson, P.; Jong, N.K.; Kuipers, B. Towards autonomous topological place detection using the extended voronoi graph. In Proceedings of the IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005. [Google Scholar]
- Prestes, E.; Carbonera, J.L.; Fiorini, S.R.; Jorge, V.A.; Abel, M.; Madhavan, R.; Locoro, A.; Goncalves, P.E.; Barreto, M.; Habib, M.; et al. Towards a Core Ontology for Robotics and Automation. Robot. Auton. Syst. 2013, 61, 1193–1204. [Google Scholar] [CrossRef]
- Studer, R.; Benjamins, V.; Fensel, D. Knowledge engineering: Principles and methods. Data Knowl. Eng. 1998, 25, 161–197. [Google Scholar] [CrossRef] [Green Version]
- Guarino, N. Formal Ontology and Information Systems. In Proceedings of the First International Conference On Formal Ontology In Information Systems, Trento, Italy, 6–8 June 1998. [Google Scholar]
- Gómez-Pérez, A.; Fernández-López, M.; Corcho, O. Ontological Engineering: With Examples from the Areas of Knowledge Management, e-Commerce and the Semantic Web. (Advanced Information and Knowledge Processing); Springer: New York, NY, USA, 2007. [Google Scholar]
- Vasudevan, S.; Gächter, S.; Nguyen, V.; Siegwart, R. Cognitive maps for mobile robots—An object based approach. Robot. Auton. Syst. 2007, 55, 359–371. [Google Scholar] [CrossRef] [Green Version]
- Milford, M.; Wyeth, G. Mapping a suburb with a single camera using a biologically inspired slam system. IEEE Trans. Robot. 2008, 24, 1038–1153. [Google Scholar] [CrossRef] [Green Version]
- Shim, V.A.; Tian, B.; Yuan, M.; Tang, H.; Li, H. Direction-driven navigation using cognitive map for mobile robots. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 2639–2646. [Google Scholar]
- Rebai, K.; Azouaoui, O.; Achour, N. Bio-inspired visual memory for robot cognitive map building and scene recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 2985–2990. [Google Scholar]
- Carpenter, G.A.; Grossberg, S.; Rosen, D.B. Fuzzy ART: Fast Stable Learning and Categorization of Analog Patterns by an Adaptive Resonance System. Neural Netw. 1991, 4, 759–771. [Google Scholar] [CrossRef] [Green Version]
- Ulrich, I.; Nourbakhsh, I. Appearance-Based Place Recognition for Topological Localization. In Proceedings of the IEEE International Conference on Robotics and Automation, San Francisco, CA, USA, 24–28 April 2000. [Google Scholar]
- Siagian, C.; Itti, L. Biologically inspired mobile robot vision localization. IEEE Trans. Robot. 2009, 25, 861–873. [Google Scholar] [CrossRef] [Green Version]
- Wu, H.; Tian, G.H.; Li, Y.; Zhou, F.y.; Duan, P. Spatial semantic hybrid map building and application of mobile service robot. Robot. Auton. Syst. 2014, 62, 923–941. [Google Scholar] [CrossRef]
- Blanco, J.; González, J.; Fernández-Madrigal, J.A. Subjective local maps for hybrid metric-topological SLAM. Robot. Auton. Syst. 2009, 57, 64–74. [Google Scholar] [CrossRef]
- Li, X.; Wang, D.; Ao, H.; Belaroussi, R.; Gruyer, D. Fast 3D Semantic Mapping in Road Scenes. Appl. Sci. 2019, 9, 631. [Google Scholar] [CrossRef] [Green Version]
- Naik, L.; Blumenthal, S.; Huebel, N.; Bruyninckx, H.; Prassler, E. Semantic mapping extension for OpenStreetMap applied to indoor robot navigation. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 3839–3845. [Google Scholar]
- Kuipers, B. The Spatial Semantic Hierarchy. Artif. Intell. 2000, 119, 191–233. [Google Scholar] [CrossRef] [Green Version]
- Beeson, P.; MacMahon, M.; Modayil, J.; Murarka, A.; Kuipers, B.; Stankiewicz, B. Integrating Multiple Representations of Spatial Knowledge for Mapping, Navigation, and Communication; Interaction Challenges for Intelligent Assistants: Palo Alto, CA, USA, 2007; pp. 1–9. [Google Scholar]
- Stevens, A.; Coupe, P. Distorsions in Judged Spatial Relations. Cogn. Psychol. 1978, 10, 422–437. [Google Scholar] [CrossRef]
- MacNamara, T. Mental Representations of Spatial Relations. Cogn. Psychol. 1986, 18, 87–121. [Google Scholar] [CrossRef]
- Brown, R. How shall a thing be called? Psychol. Rev. 1958, 65, 14. [Google Scholar] [CrossRef] [Green Version]
- Rosch, E. Cognition and Categorization; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 1978. [Google Scholar]
- Crespo, J.; Barber, R.; Mozos, O.M. An Inferring Semantic System Based on Relational Models for Mobile Robotics. In Proceedings of the IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Vila Real, Portugal, 8–10 April 2015; pp. 83–88. [Google Scholar]
- Sun, N.; Yang, E.; Corney, J. Semantic path planning for indoor navigation and household tasks. In Proceedings of the 20th Towards Autonomous Robotic Systems Conference (TAROS 2019), London, UK, 3–5 July 2019. [Google Scholar]
- Moravec, H. Sensor fusion in certainty grids for mobile robots. AI Mag. 1988, 9, 61–74. [Google Scholar]
- Kostavelis, I.; Charalampous, K.; Gasteratos, A.; Tsotsos, J.K. Robot navigation via spatial and temporal coherent semantic maps. Eng. Appl. Artif. Intell. 2016, 48, 173–187. [Google Scholar] [CrossRef]
- Yang, W.; Wang, X.; Farhadi, A.; Gupta, A.; Mottaghi, R. Visual Semantic Navigation using Scene Priors. arXiv 2018, arXiv:1810.06543. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the International Conference on Learning Representations (ICLR’2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Patnaik, S. Robot Cognition and Navigation: An Experiment with Mobile Robots (Cognitive Technologies); Springer Science & Business Media: Berlin, Germany, 2005. [Google Scholar]
- de Lucca Siqueira, F.; Plentz, P.D.M.; Pieri, E.R.D. Semantic trajectory applied to the navigation of autonomous mobile robots. In Proceedings of the 2016 IEEE/ACS 13th International Conference of Computer Systems and Applications (AICCSA), Agadir, Morocco, 29 November–2 December 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Marino, A.; Parker, L.; Antonelli, G.; Caccavale, F. Behavioral control for multi-robot perimeter patrol: A Finite State Automata approach. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 831–836. [Google Scholar] [CrossRef]
- Zhang, K.; Chen, Q. Route natural language processing method for robot navigation. In Proceedings of the 2016 IEEE International Conference on Information and Automation (ICIA), Ningbo, China, 1–3 August 2016; pp. 915–920. [Google Scholar] [CrossRef]
- Talbot, B.; Lam, O.; Schulz, R.; Dayoub, F.; Upcroft, B.; Wyeth, G. Find my office: Navigating real space from semantic descriptions. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 5782–5787. [Google Scholar] [CrossRef] [Green Version]
- Aotani, Y.; Ienaga, T.; Machinaka, N.; Sadakuni, Y.; Yamazaki, R.; Hosoda, Y.; Sawahashi, R.; Kuroda, Y. Development of Autonomous Navigation System Using 3D Map with Geometric and Semantic Information. J. Robot. Mechatron. 2017, 29, 639–648. [Google Scholar] [CrossRef]
- Song, I.; Guedea, F.; Karray, F.; Dai, Y.; El Khalil, I. Natural language interface for mobile robot navigation control. In Proceedings of the 2004 IEEE International Symposium on Intelligent Control, Taipei, Taiwan, 4 September 2004; pp. 210–215. [Google Scholar]
- Druzhkov, P.N.; Kustikova, V.D. A survey of deep learning methods and software tools for image classification and object detection. Pattern Recognit. Image Anal. 2016, 26, 9–15. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.W.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. arXiv 2018, arXiv:1809.02165. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acquisition by Human Interaction | Autonomous Acquisition | ||||
|---|---|---|---|---|---|
| Paper | Place Labeling | Learning Objects and Relationships | Laser Range Data | Segmentation | Object Detection |
| [19] | YES | YES (BOTH) | NO | NO | YES |
| [15] | YES | YES (BOTH) | YES | YES | YES |
| [16] | YES | NO | YES | NO | YES |
| [17] | YES | YES (OBJECTS) | YES | YES | YES |
| [74] | YES | NO | NO | NO | NO |
| [75] | YES | NO | NO | NO | NO |
| [21] | YES | DOORS | NO | NO | NO |
| [23] | NO | YES (OBJECTS) | NO | YES | YES |
| [13] | NO | NO | YES | NO | YES |
| [24] | NO | NO | YES | NO | NO |
| [25] | NO | NO | YES | YES | NO |
| [28] | NO | NO | YES | NO | YES |
| Features | ||||||
|---|---|---|---|---|---|---|
| Ref | Reasoning System | Object Detection | Environments Elements Taken into Account | Place Classification | User Interaction | Learning Possibility |
| [115] | Behavior tree, FSM | Unused or unspecified | Weather, task location, energy source location, events, a room, a position, etc. | Environment context | Unused or unspecified | No |
| [119] | Unused or unspecified | A version of the Convolutional Neural Network (CNN) | Roads, buildings (red), road markers, lawns, vehicle, pedestrian, bike, sky, fence, pole, etc. | They classified 11 classes for example, Road and Tree | Unused or unspecified | Unused or unspecified |
| [118] | The used spatial constraints as a mass in a point-mass system | Unused or unspecified | Unused or unspecified | Unused or unspecified | Unused or unspecified | Unused or unspecified |
| [117] | Extracting useful navigation information from semantic roles | This paper use the NLPIR Chinese word segmentation system | Manual labeling | Speech Recognition Library (SRL) | Unused or unspecified | |
| [15] | A description-logic reasoner | A component for detecting and following people [25] and a method based on [32] | Doorways, Corridors, rooms. Smaller objects, like cups, books, etc. | Based on functionality, it depends on the objects inside the area | Speech recognition | Yes |
| [111] | Unused or unspecified | Unused but they claim that they will use object recognition | The norm between the detected features and the visual words is calculated and the representative histogram is formed | A frame is acquired, converted into an appearance based histogram and the SVM infers the label of the place | Unused or unspecified | Unused or unspecified |
| [120] | Unused or unspecified | Extracting 2D straight segments as a basic primitive and using ground-hypothesis | Edges and environment images features | Unused or unspecified | Unused or unspecified | No |
| [103] | The Hybrid Spatial Semantic Hierarchy (HSSH) frame-work | Unused or unspecified | gateways and path fragments | Using gateways and path fragments, they formulate a criterion for detecting topological places | Clicking or drawing on the LPM display | No |
| [19] | A reasoning system based on a relational BD implementation | Object and label detection | Objects in the environment and labels | Classification according to room utility | The keyboard can be used. They also used a voice dialog system. | Yes |
| [49] | A semantic cost function that takes into account high-level image constraints | Unused or unspecified | It uses object position in images | Unused or unspecified | There is no interaction | Unused or unspecified |
| [79] | Unspecified | objects are characterized through geometric and appearance features | Objects | Depending on the objects that are anchored with types of room | Unused or unspecified | Several processes of obtaining semantic knowledge are analyzed but not used yet |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Crespo, J.; Castillo, J.C.; Mozos, O.M.; Barber, R. Semantic Information for Robot Navigation: A Survey. Appl. Sci. 2020, 10, 497. https://doi.org/10.3390/app10020497
Crespo J, Castillo JC, Mozos OM, Barber R. Semantic Information for Robot Navigation: A Survey. Applied Sciences. 2020; 10(2):497. https://doi.org/10.3390/app10020497
Chicago/Turabian StyleCrespo, Jonathan, Jose Carlos Castillo, Oscar Martinez Mozos, and Ramon Barber. 2020. "Semantic Information for Robot Navigation: A Survey" Applied Sciences 10, no. 2: 497. https://doi.org/10.3390/app10020497